


Trang Le
#math graduate. Postdoc fellow with Jason Moore.
Journal club discussion
Aaron R. Caldwell, Samuel N. Cheuvront
Scientific theories must be falsifiable in principle. Of course, not all justified beliefs are falsifiable in principle, but you need strong reasons for such unfalsifiable beliefs.
Paul Stearns, Lucid Philosophy
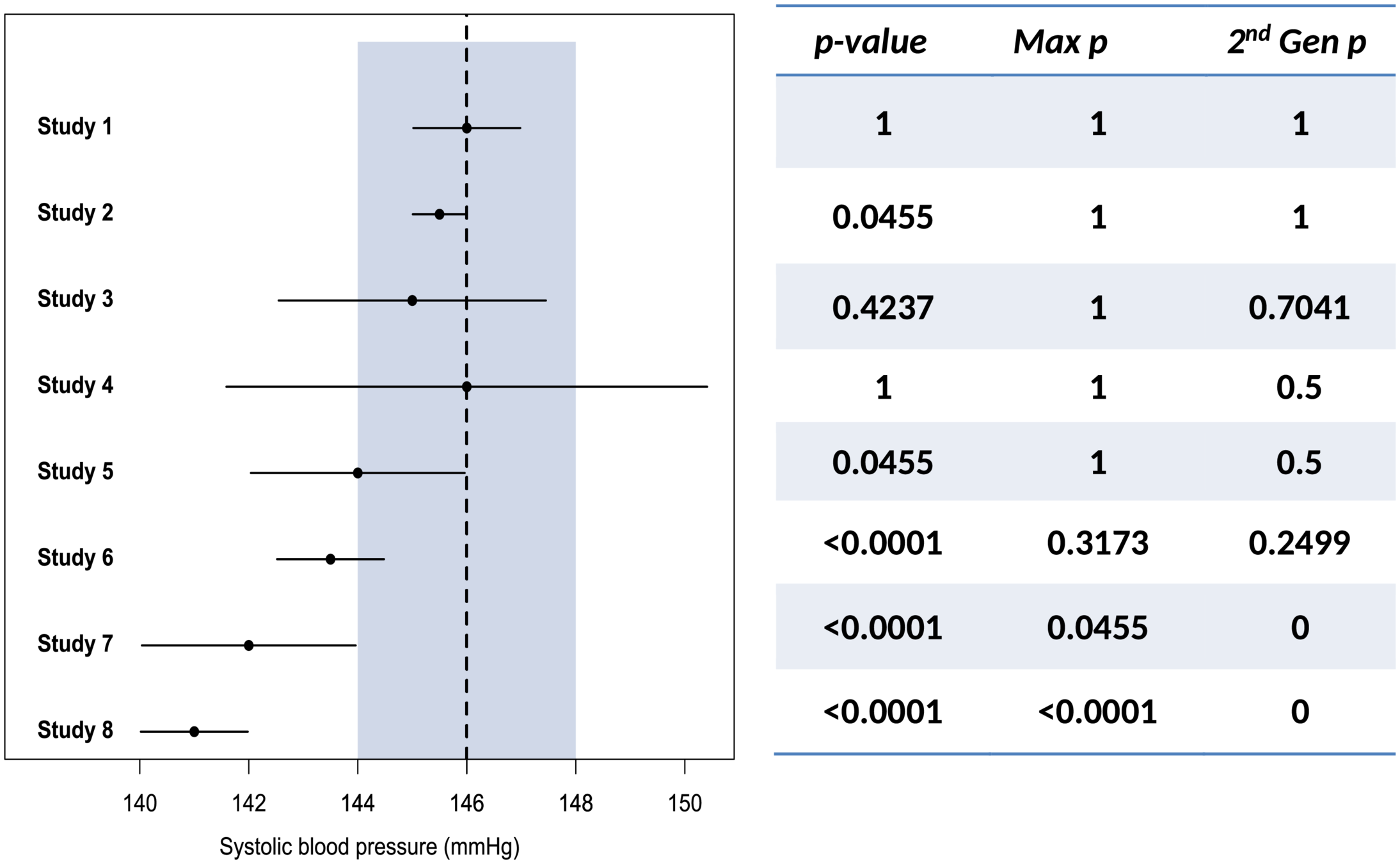
given H_0, probability of obtaining observed (or more extreme) result
instead: effect size and confidence intervals
Blume et al. 2018
http://doingbayesiandataanalysis.blogspot.com/2016/12/bayesian-assessment-of-null-values.html
When introducing a new statistical method, it is important to compare it to existing approaches and specify its relative strengths and weaknesses.
Blume et al. (2018) claim that when using the SGPV “Adjustments for multiple comparisons are obviated” (p. 15). However, this is not correct. Given the direct relationship between TOST and SGPV highlighted in this manuscript [], not correcting for multiple comparisons will inflate the probability of concluding the absence of a meaningful effect based on the SGPV in exactly the same way as it will for equivalence tests.
measure of variation/dispersion
biased vs. unbiased
is s.d. of its sampling distribution
s.e., of a statistic
s.d., population , sample s
s.e. of the mean ~ s.d. of the sample mean = s.d. of the error in sample mean
sample mean
± 1 s.e. of the mean
median
interquartile range
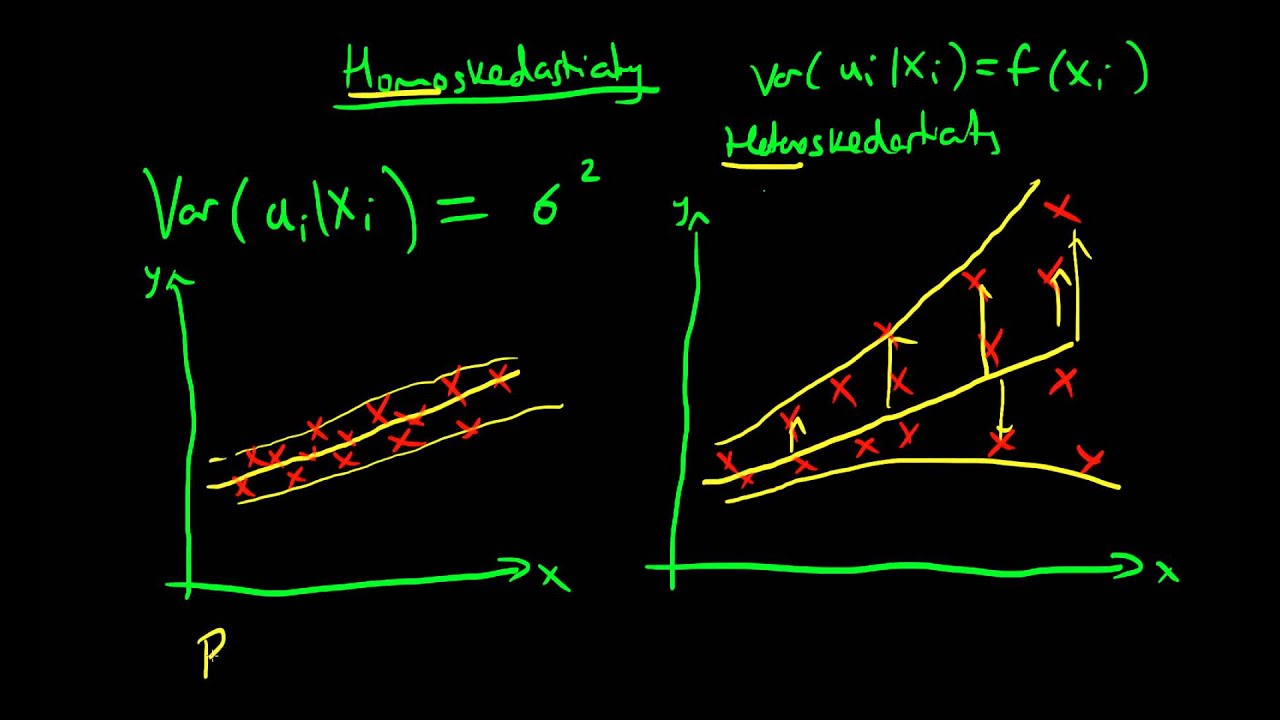
variance of the error term is stable across groups or predictor variables
variance of the error term is NOT STABLE across groups or predictor variables
probability of rejecting a false null hypothesis
Pr(reject H_0 | H_1 is true)
prior to data collection
How many times do I need to toss a coin to conclude (with 80% power) that it is rigged by a certain amount?
I tossed a coin 10 times and it seemed to not be rigged by a certain amount. What was the power of my test?
retrospective, posteriori, observed
Because you will always have low observed power when you report non-significant effects, you should never perform an observed or post-hoc power analysis, even if an editor requests it. Instead, you should explain how likely it was to observe a significant effect, given your sample, and given an expected or small effect size.
For example, say, you collected 500 participants in an independent t-test, and did not observe an effect (0.3 threshold). You had more than 90% power to observe a small effect of d = 0.3. It is always possible that the true effect size is even smaller, or that your no effect conclusion is a Type 2 error, and you should acknowledge this. At the same time, given your sample size, and assuming a certain true effect size, it might be most probable that there is no effect.
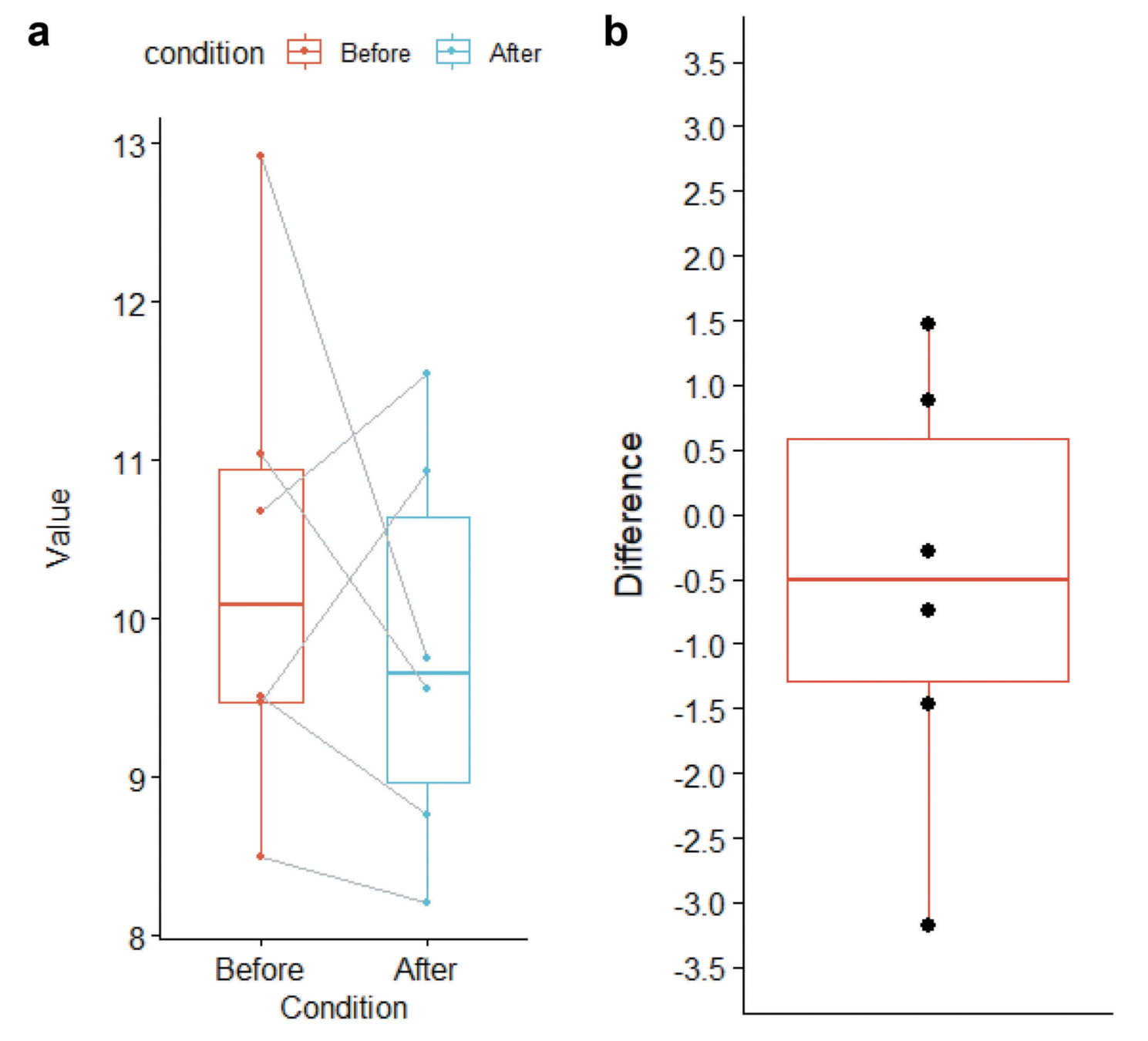
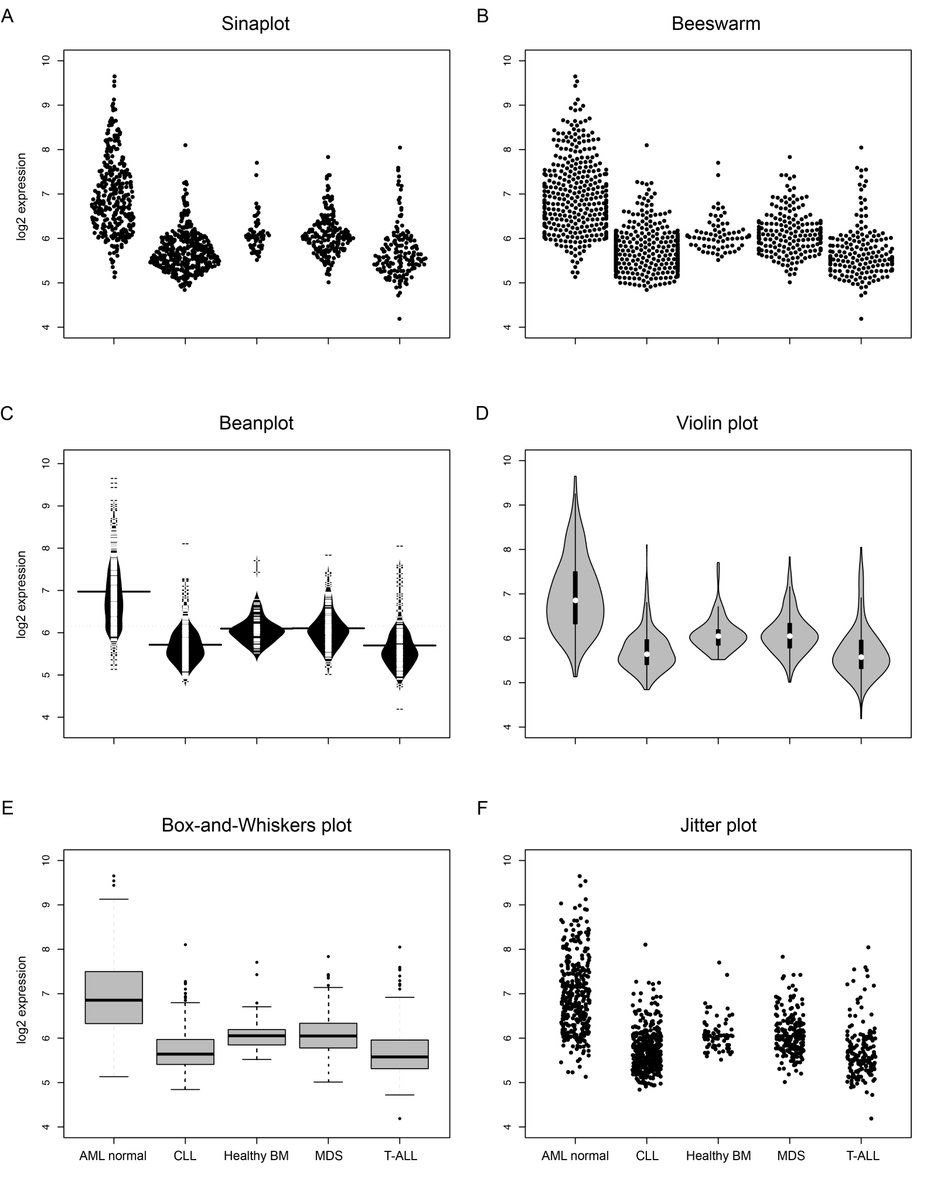
Data visualization with large samples can be overly complicated and busy if all the data points are presented. Therefore, in these situations it is advisable to present the summary statistics along with some visualization of the distribution rather than the data points
By Trang Le
Presentation on 2019-11-14, Moore lab Lunch&Learn



