A Performance Study of LLM-Generated Code on Leetcode
Coignion Tristan, Quinton Clément, Rouvoy Romain
Green Days 2024 - Toulouse

New Shiny Things

New Shiny Things
GitHub Copilot
Some definitions
Large Language Model (LLM) :
An artifical intelligence capable of generating text
Code LLM : LLMs specialized in writing code
Code Assistant : Code LLMs integrated in the IDE

LLM + Green = 💔
LLMs need a lot of computing resources
Is it really worth the cost?
Training StarCoder2-7B
=> 100,000kWh
=> 30,000kgCO2eq

How fast is the code generated by LLMs ?
Is it worth it?

- Measure the impact of the LLM
-
Measure the time gained for the developer
-
Measure the energy saved on the software
On the model's temperature
The temperature of a model is a parameter regulating the "creativity" and the randomness of the model's generations.

Our research questions
- Can Leetcode (a public repository of
algorithmic problems) be used as a dataset and a benchmark platform for evaluating LLMs ?
- Are there notable differences between the performance of the code generated by different LLMs ?
- Is there an effect of the temperature parameter of the LLM on the code's performance ?
- How efficient are the solutions generated by the LLMs compared to humans ?
The task

A competitive programming platform hosting algorithmic problems
+ Practical for performance testing
+ Practical for evaluating LLMs

The dataset
2 Datasets of problems :
-
New dataset : 204 problems published after January 1st 2023
- Old dataset (RQ1) : 300 problems from the most liked problems of Leetcode

LLMs under study

Generating the solutions
10 solutions generated by problem, temperature and model
210,120 generated solutions on the new dataset

Results

RQ1: Can Leetcode be used as a dataset and a benchmark platform for evaluating LLMs?
LLMs success rate on :
- old problems : 37% of valid solutions
- new problems (published after training) : 3% of valid solutions
Why are the LLMs 10x worse on newer questions?
RQ1: Can Leetcode be used as a dataset and a benchmark platform for evaluating LLMs?
Data contamination
=> Harder to reproduce and generalize research
=> Questions the previous research
done using Leetcode
LLMs success rate on :
- old problems : 37% of valid solutions
- new problems (after January 2023) : 3% of valid solutions
Why are they 10x worse on newer questions ?

RQ1: Can Leetcode be used as a dataset and a benchmark platform for evaluating LLMs?
Leetcode provides useful measures :
run time
memory usage
ranking (based on run time)
BUT

RQ1: Can Leetcode be used as a dataset and a benchmark platform for evaluating LLMs?
Leetcode provides useful measures like :
run time
memory usage
ranking (based on run time)
Very high variance (inability to differentiate solutions of different time complexities)
Ranking evolves over time, thus is unreliable
BUT
RQ2: Are there notable differences in performances between LLMs?
Very small differences
(Cohen's d < 0.05),
thus negligible.
LLMs seem to converge towards the same kinds of solutions
(not necessarily the best ones)

Almost (<5%) no problems where one LLM is consistently better than another.
RQ2: Are there notable differences in performances between LLMs?
Better LLMs
Faster code
⇏
RQ3: Is there an effect of the temperature on the code’s performance?
Higher temperatures => higher variance of the performance of the code
=> Higher temperatures can help in searching for faster solutions.
Temperature : Parameter controlling the "creativity" of the model
RQ4: How fast is code generated by LLMs compared to humans?
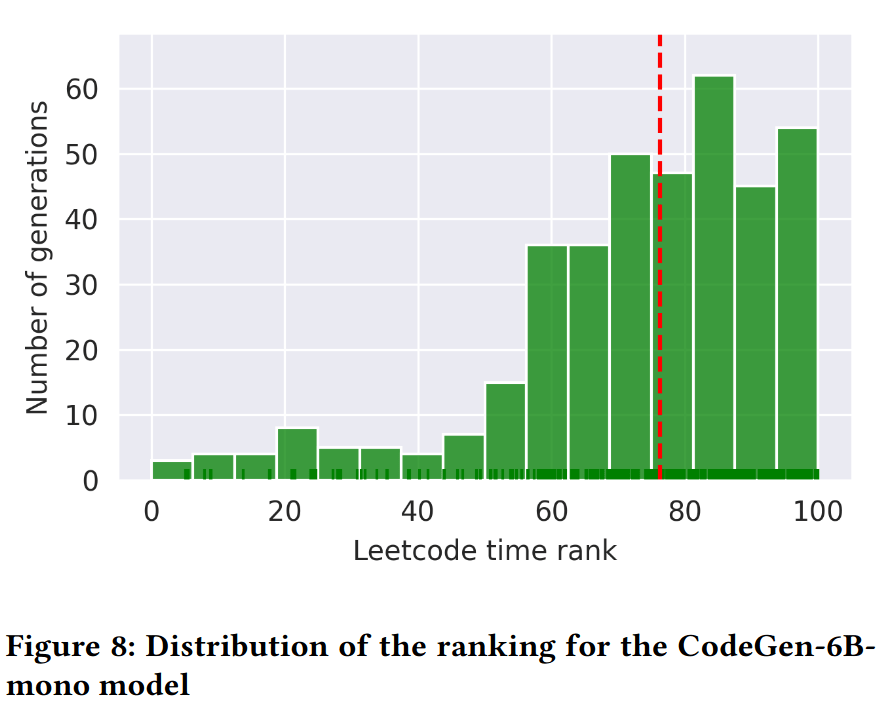
On average, the generated solutions are faster than 73% of the other submissions on Leetcode

RQ4: How fast is code generated by LLMs compared to humans*?
On average, the generated solutions are faster than 73% of the other submissions on Leetcode
* assuming the other submissions on Leetcode were made by humans
Conclusions
Leetcode should be used cautiously when evaluating LLMs because of issues of measure stability and data contamination

Performance of generated code is largely similar across different models regardless of their size, training data or architecture
Increasing the temperature parameter leads to a greater variance in performance
Perspectives
- Extend the study on other kinds of problems
- How to make LLMs produce greener code ?
- What is the energy consumption of a code assistant ?

Thanks for listening !
Any questions?

A Performance Study of LLM-generated code on Leetcode
By Tristan Coignion



