Is your model cold enough ?
Study of the performance of code generated by Large Language Models
+
The rest of my thesis
Tristan COIGNION
Spirals Team Seminar 2023
New Shiny Things

New Shiny Things
GitHub Copilot
AI + Green = 💔
AI uses a lot of resources for training
(e.g. BLOOM : $2-5M equivalent in cloud computing)
Is it really worth the cost ?
For inference, Large Language Models need many GPUs and electricity
My thesis : Study on LLMs for Code
What is the environmental impact of an LLM when used for coding ?
How does the time LLMs save compares to the energy they cost ?
Could LLMs be used for creating greener code ?
Study on LLMs for code generation
(ex : Copilot)
How does the performance of the generated code varies ?
Is there a difference in terms of code performance between different LLMs ?
What is being generated
Algorithm exercises solutions
- ensure longer run time with higher load
- short and easy to generate large quantities unsupervised
- but difficult to generalize to the whole programming world

Problem example on Leetcode
With which LLMs ?
- GitHub Copilot
- Codex - OpenAI
- Codegen (350M, 2B, 6B,
16B) - Salesforce - Santacoder - BigCode
- CodeT5 - Salesforce
- Incoder (1B, 6B) - Community & MetaAI
- Codeparrot - Codeparrot
Closed-source models
Open-source models
On the model's temperature
The temperature of a model is a parameter regulating the "creativity" and the randomness of the model's generations.
For every model, we made the temperature vary between 0, 0.2, 0.4, 0.6, 0.8 and 1.0.
How do we do it ?
With every model, we generated 10 solutions for 300 Leetcode problems, and we measured the run times of the valid ones.
Résultats

LLMs trained on English text are generally better at generating correct code
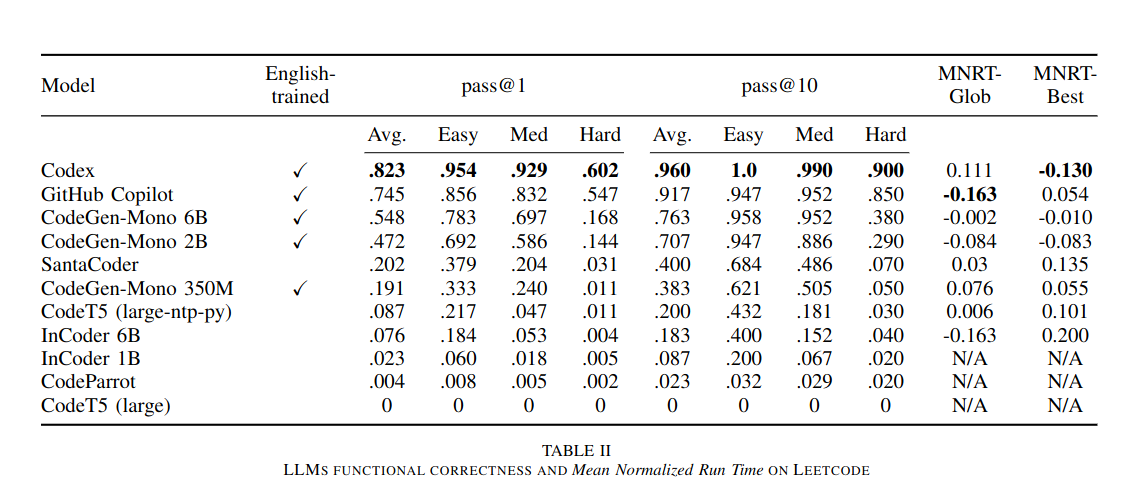
The performance of the generated code does increase with the model capabilities, but not by a lot
Measure of performance (lower is better)
When comparing Codex (success rate of 82%) and SantaCoder (success rate of 20%) code performance it appears that :
- Codex’ generated solutions are at least 5% faster than SantaCoder’s on 23 (36%) problems
- Codex' generated solutions are at least 5% slower than SantaCoder’s on 14 (22%) problems.
A very small effect
The higher the temperature, the worse the overall performance of the code
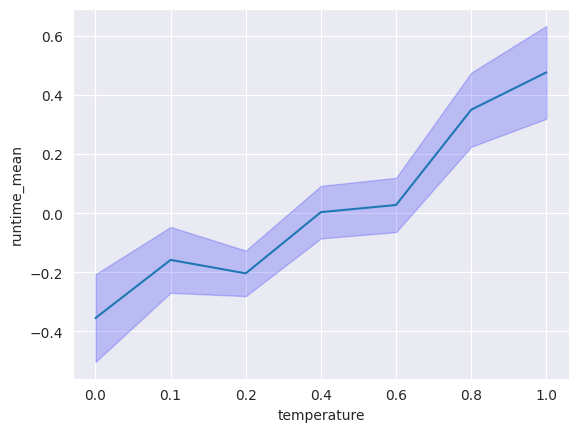
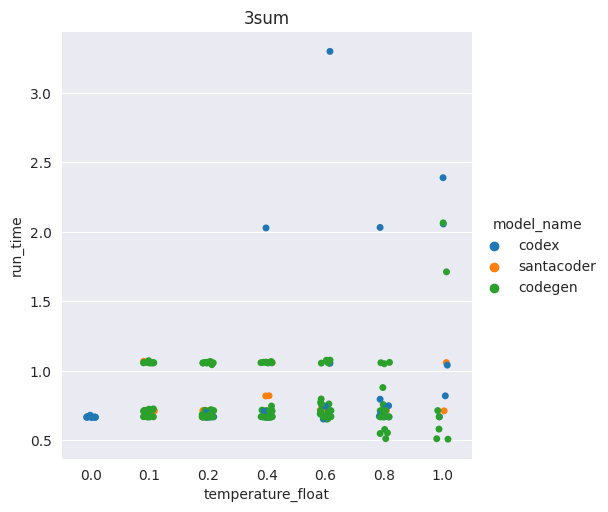
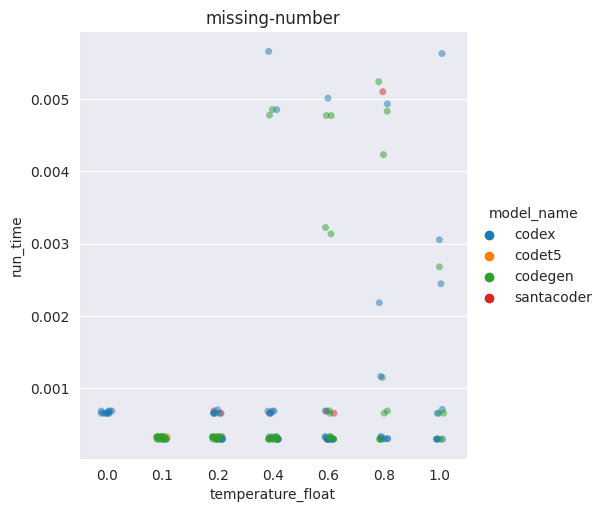
Having a higher temperature actually increases the chance of generating an inefficient solution
Examples of distributions of the runtime in seconds of the generations for two problems
(one dot = one generation) (high = slow)
Conclusion
- English-trained LLMs generate correct code more often on Leetcode-style questions.
- The higher the temperature, the worse the average performance of the generated code.
- It also seems that there is a ceiling in terms of code performance that traditional LLMs reach once they attain a certain threshold in terms of functional correctness.
Limits
- Question dataset prone to recitation
- Impossible to reproduce on Codex
- Reproducing with GPT-3.5 or GPT-4 would respectively cost $3,600 and $108,000
What's next ?
- Human study where I study the impact of a code assistant on a developer's productivity, and measure the energy used by the assistant.
- Redo this study, with a better and newer dataset less prone to recitations, while also finding ways to improve the performance of the code (e.g. prompt engineering)
Thanks for listening !
Any questions ?
Is your model cold enough ?
By Tristan Coignion



