Natural Disasters:
Prediction Models for Severity of Fatalities
Ty Mulholland
The Problem
There have been over 16,000 natural disasters in the last century.
How do countries prepare for these?
Do some countries have less advantages in disaster preparedness?

Background
- EM-DAT - International Disaster Database
- Records Natural, Technical and Complex Disasters (Famine)


Strategy
2 Ensembles
1) Fatality Occurrence (Binomial- Yes/No)
- Using caret (kNN, Rpart, SVM, treebag)
2) Fatality Levels (Multinomial- Low,High,Extreme)
- Using h2o (Naive Bayes, randomForest, GBM, Neural Net)

Data
50 Variables (28 character, 21 integer, 1 numeric)
16,623 observations
Time Period 1900-2023
Only Natural Disasters
Data
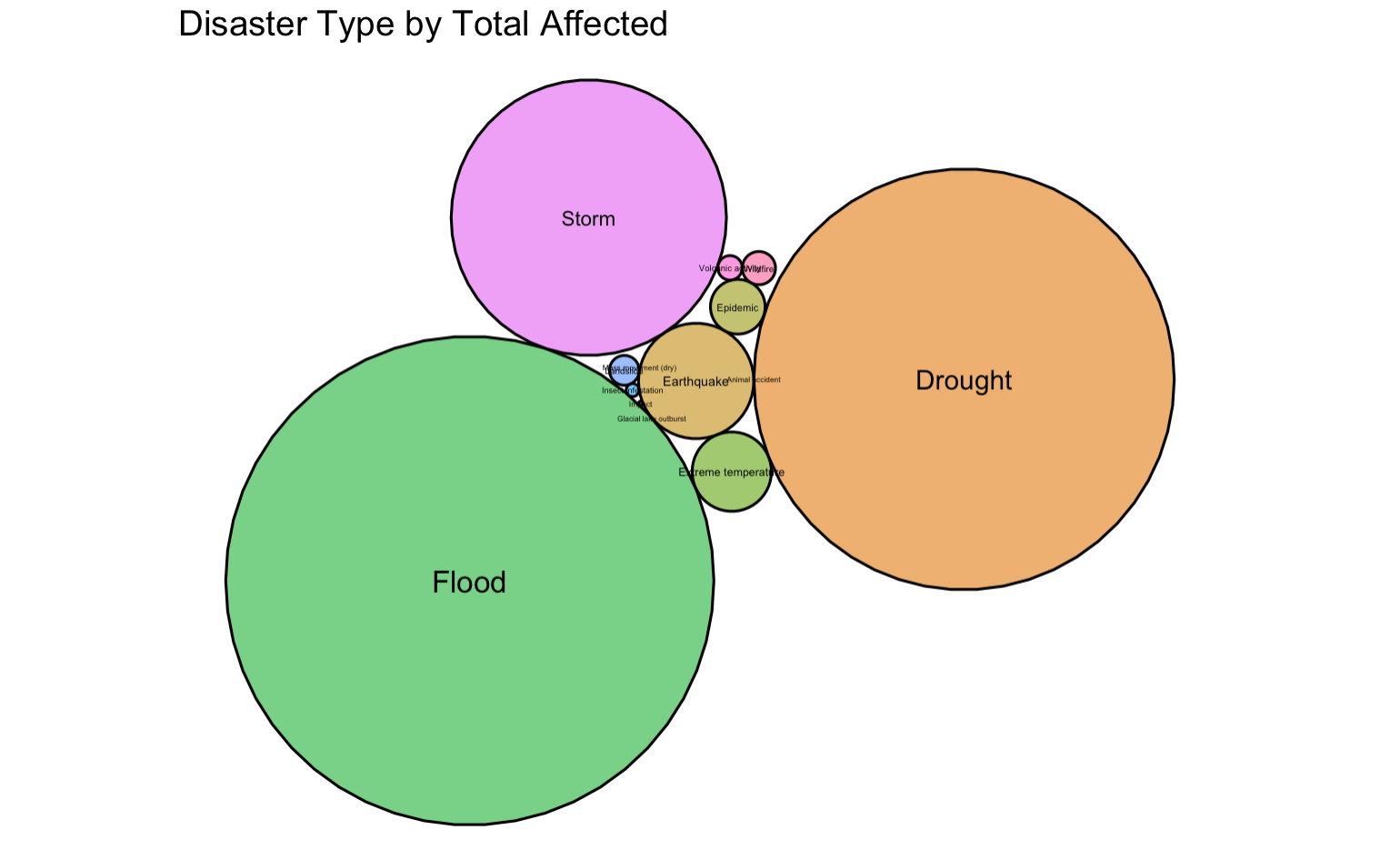
Data
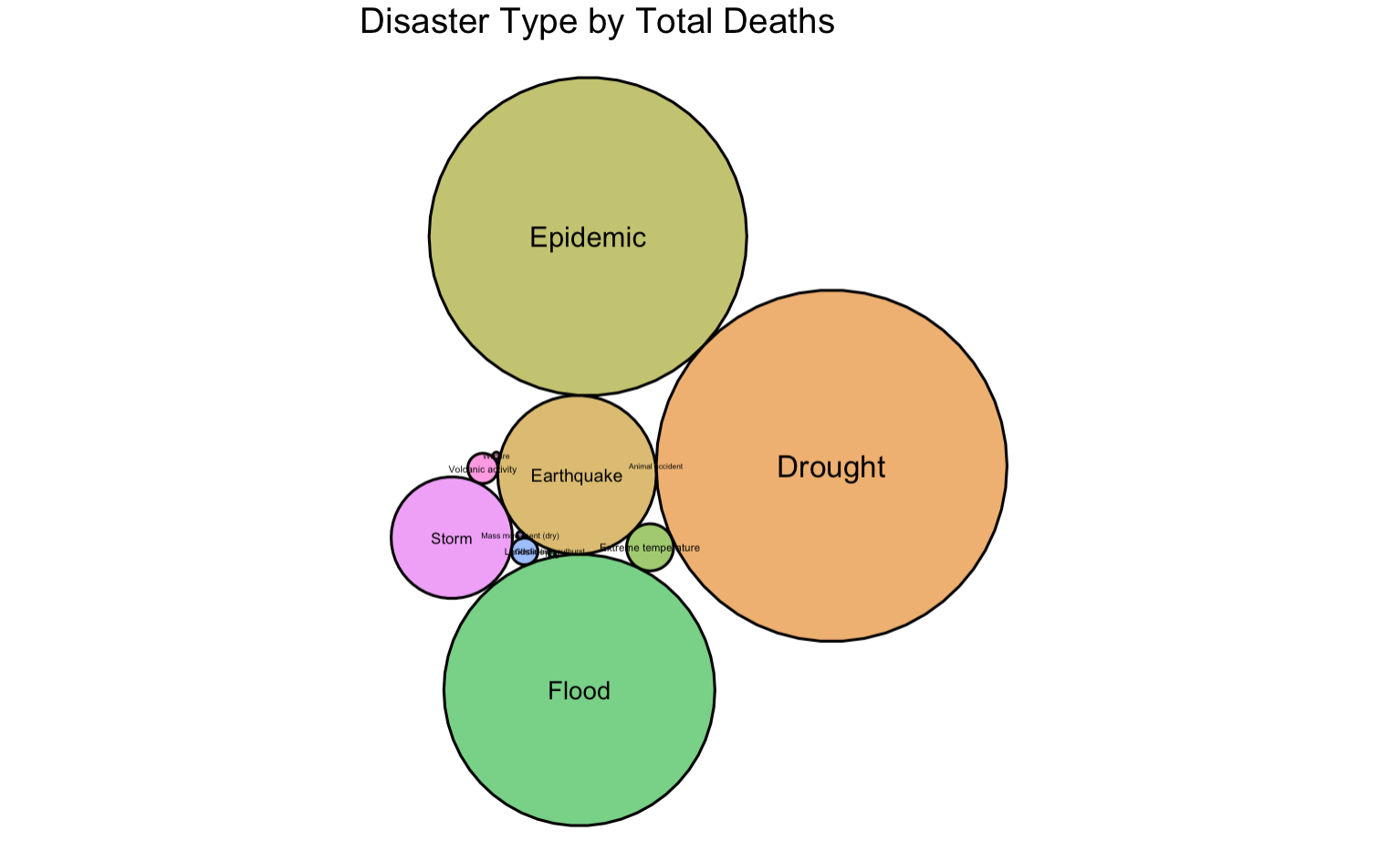
Data
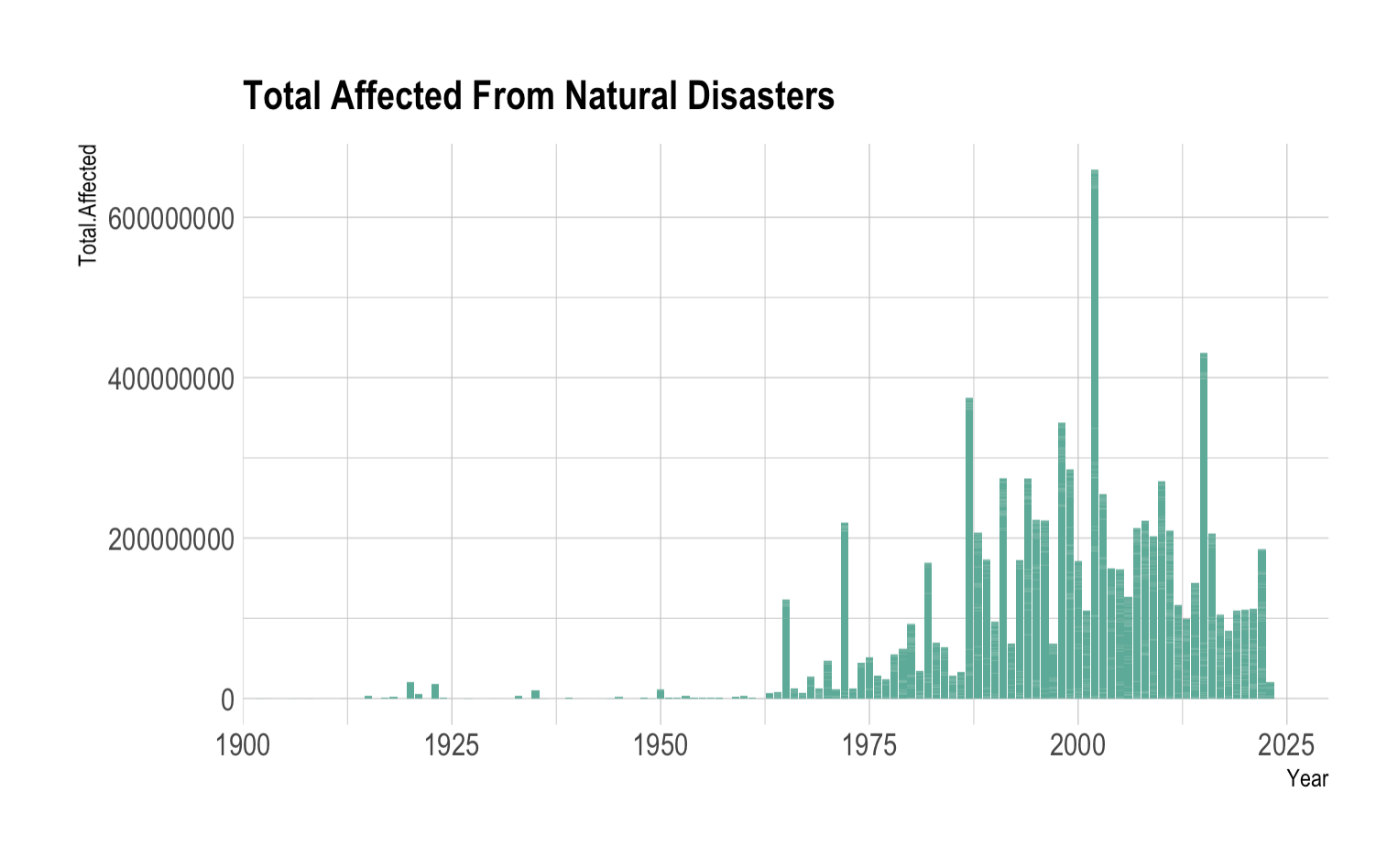
Data
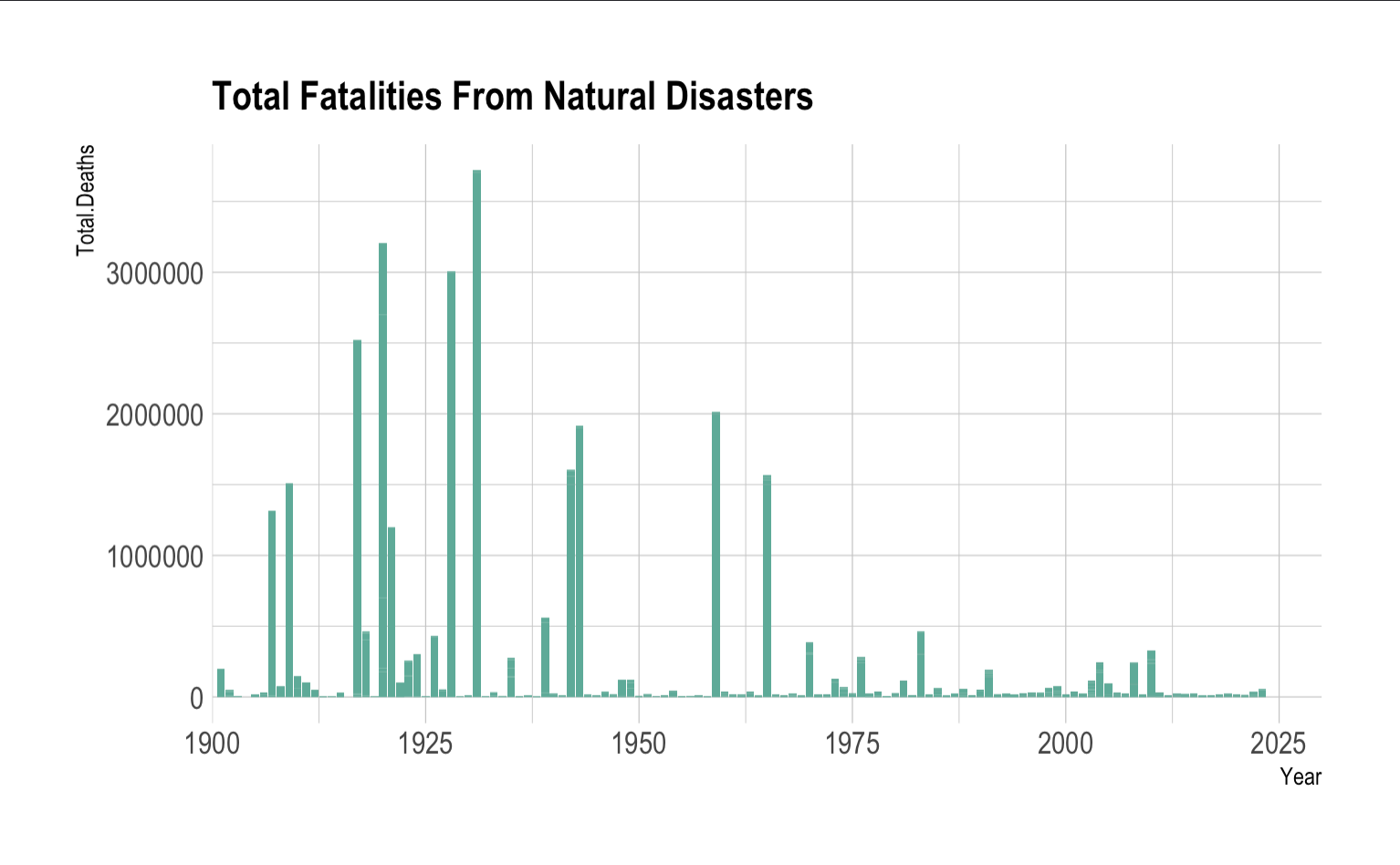
Challenges
- Data is very sparse

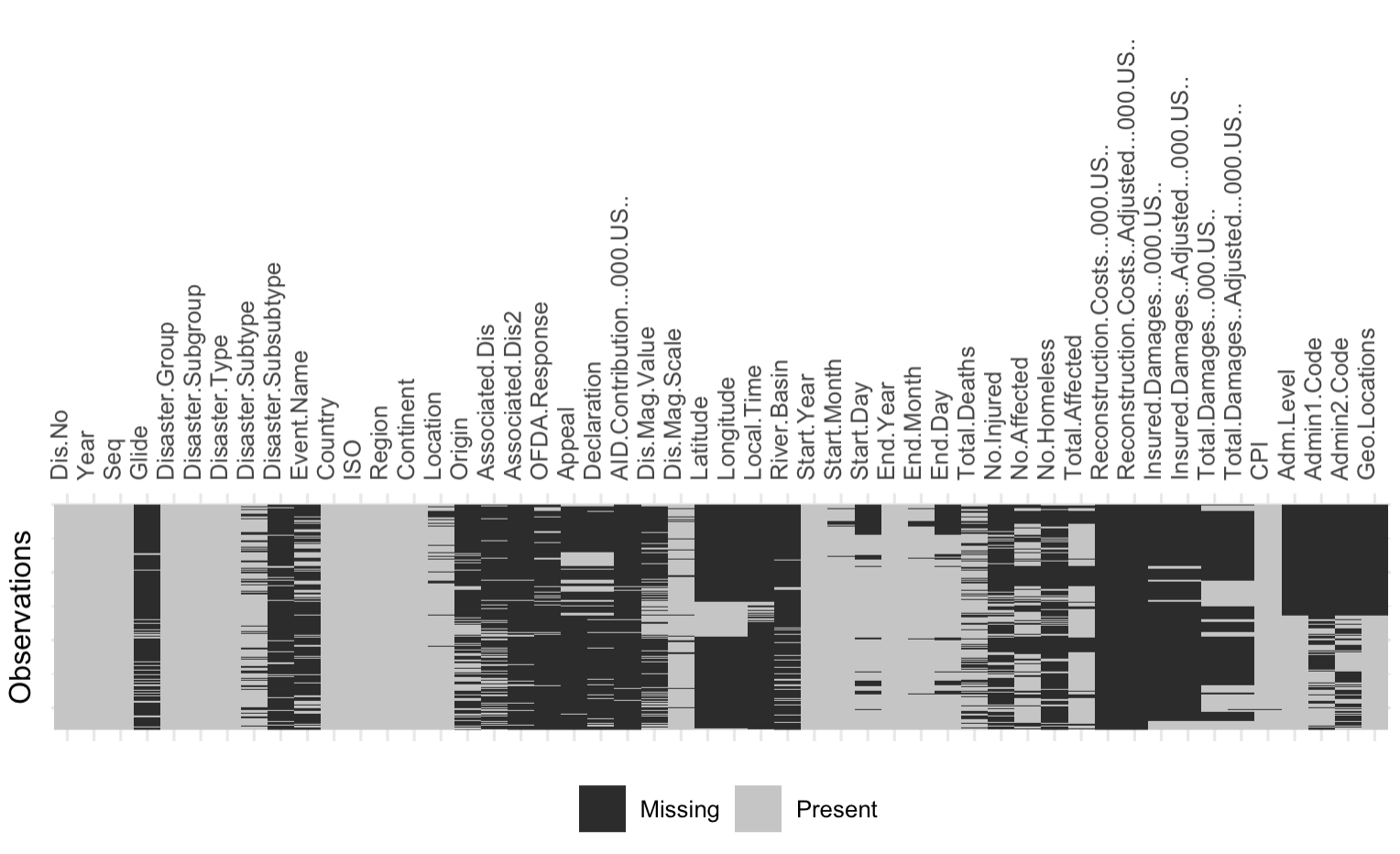
Challenges
- Much of the data is U.S. specific
"Reconstruction.Costs...000.US.."
"Reconstruction.Costs..Adjusted...000.US.."
"Insured.Damages...000.US.."
"Insured.Damages..Adjusted...000.US.."
"Total.Damages...000.US.."
"Total.Damages..Adjusted...000.US.."
Challenges
- Almost all relevant variables were character columns
- Location- Country, Region
- Disaster Categorization- Group, Subgroup, Type, Subtype, Subsubtype
Approach
Feature Selection
- Since there were so many highly sparse variables, narrowing was logical
- Much of the data represented higher categorization (i.e Continent -> Country)
- Highly correlated variables such as No.Affected and Total.Affected
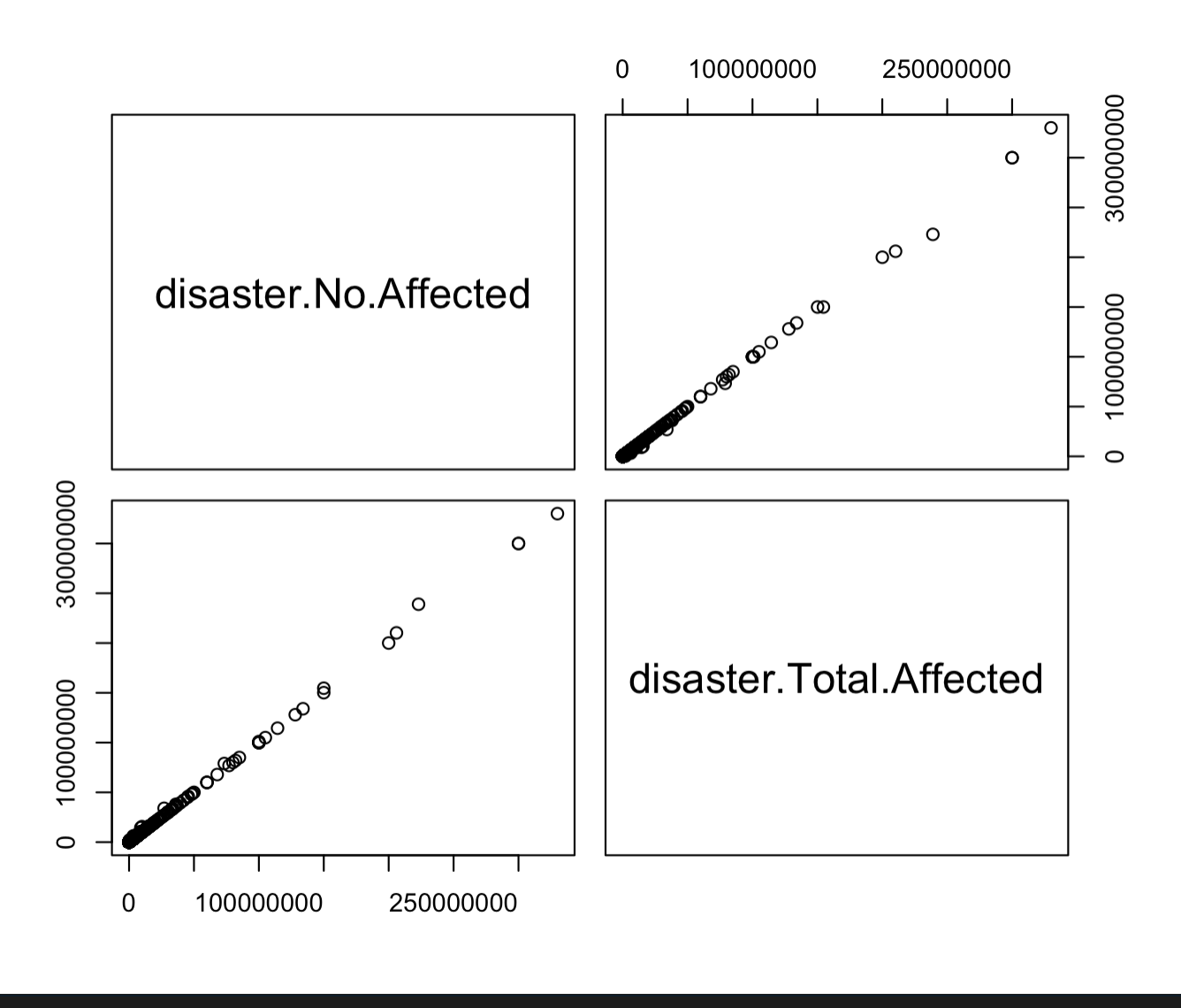
Approach
Imputation
- Mode by groups where applicable
- 0 where NA represented no observation
Variable Creation
- "Duration" field from dates of events
- Death Level - ("Low", "High", "Extreme")
- Death Occurrence - ("1", "0")
Model 1- Fatality Occurrence
Package: Caret
Methods: kNN, Rpart, SVM, treebag
Ensemble: Stacked

Accuracy
75.9%
77.01%
76.55%
78.13%
Model
kNN
Rpart
SVM
Bagging Tree (Treebag)
Stacked Ensemble
Accuracy
77.12%
76.5%
75.11%
76%
78.96%
Model 2- Fatality Level
Package: h2o
Methods: Naive Bayes, randomForest, GBM, Neural Net
Ensemble: Stacked
Model
Naive Bayes
Random Forest
Gradient Boosting
Neural Net
Stacked Ensemble
Log-loss
0.4118196
0.009557498
0.001596376
0.0766861
0.0009741652
Key Findings
- The Fatality Occurrence ensemble needs more tuning
- Could benefit from more data. Consider population density, GDP, geographic feature location data.
- Predictive trends over time would be a logical next step
Ty Mulholland
ty@tymulholland.com
@tymulholland

THANK YOU!
Copy of Copy of Copy of deck
By Ty Mulholland


