Ensemble Learning
and Random Forests
Tzu-Li Tai @ NCKU TechOrange
Learning Path to Data Science - Machine Learning Session #4
Outline
- What is ensemble learning?
- Why is ensemble useful?
- Random Forests
- Hands-on Orange practice
First things first...
Who can give me a brief recap of what we have learnt already?
- Logistic Regression
- K-Nearest Neighbour
- Classification Tree (Decision Tree)
- SVM
Use 1 sentence to explain what a classifier is!
Given a set of training examples, a classification algorithm outputs a classifier.
The classifier is an hypothesis about the true function
S
S
f
f
The Hypothesis space, of a training set
H
H
f
f
h_1
h1
h_2
h2
h_3
h3
f
f
: the true function
(optimal classifier)
h
h
: different solutions
of the classifier
Ensemble Classification
- A popular technique to increase the accuracy of classifiers
- An ensemble classifier is a set of classifiers whose individual decision are combined in some way (typically by voting)
whole training data ( instances)
n
n
Classification learning algorithm
L
L
Classifier
h
h
manipulate
training data
n
n
n'
n′
n'
n′
n'
n′
L
L
L
L
L
L
h_1
h1
h_2
h2
h_m
hm
What makes a good ensemble?
The overall ensemble classifier will be more accurate than a single individual classifier if ...
- The base models are diverse
- The base models are accurate
Why Diverse?
h_{ensemble}=\{h_1,h_2,h_3\}
hensemble={h1,h2,h3}
=> Ideal if
h_1,h_2,h_3
h1,h2,h3
make different predictions
Why Accurate?
- Suppose m=20 base classifiers
- Each classifier has error rate
- If majority voting is used, > 10 wrong predictions will result in overall wrong classification result
p
p
=> Binomial distribution!
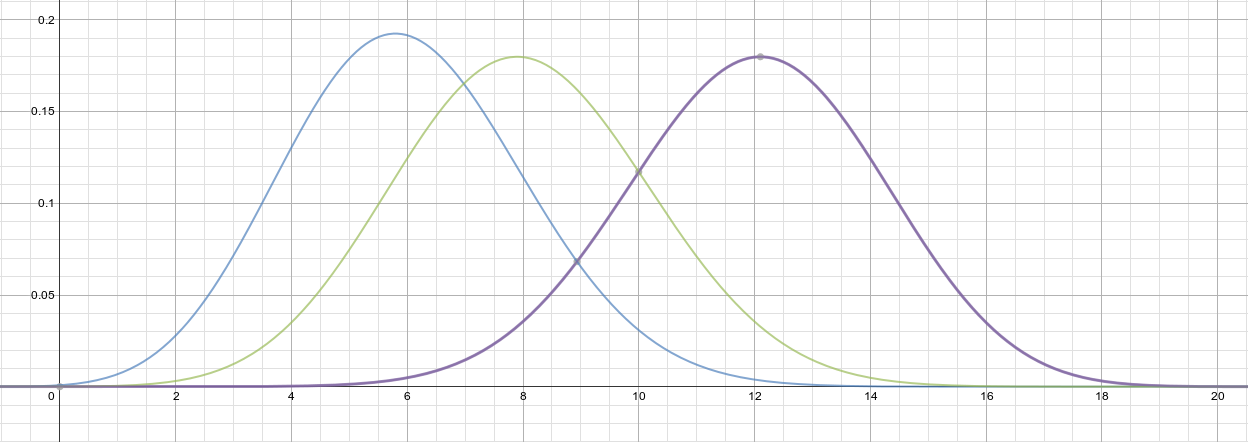
--- : p = 0.3, m = 20
--- : p = 0.4, m = 20
--- : p = 0.6, m = 20
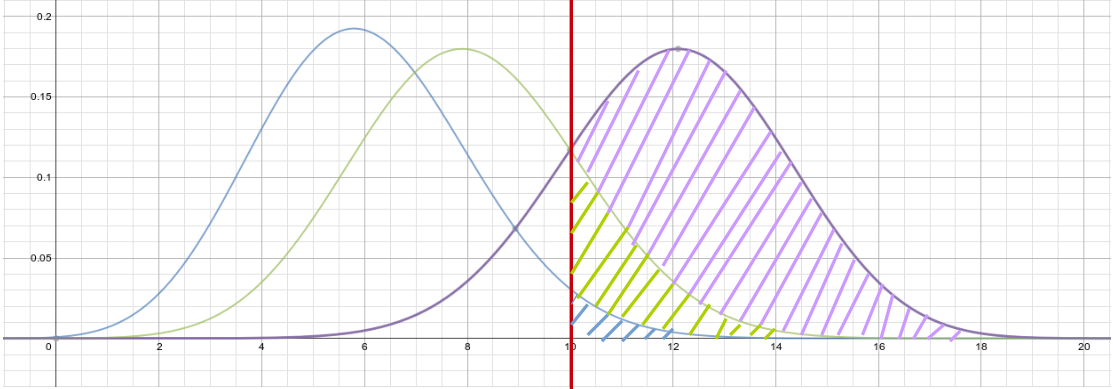
--- : Cumulative prob. P(x>10) = 0.01714
--- : Cumulative prob. P(x>10) = 0.12752
--- : Cumulative prob. P(x>10) = 0.75534
Why is ensemble better?
This is going to be kinda vague...
but we can put it into two categories:
- Statistical
- Computational
Statistical property
f
f
h_1
h1
h_2
h2
h_3
h3
h_4
h4
"Average"
Computational property
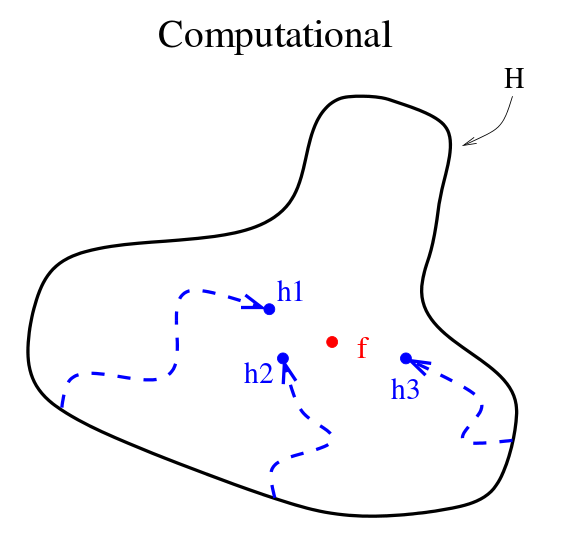
Different local search
starting points
Methods to constructing ensembles
=> manipulate training data to form m subsets to
generate m hypotheses
n
n
n'
n′
n'
n′
n'
n′
- Bagging
- Boosting
Bagging
"Bootstrap Aggregating"
n
n
training instances =>
randomly select
n
n
instances with replacement for each subset
=> each subset is expected to have the fraction
1/(1-e)=63.2\%
1/(1−e)=63.2%
of unique instances in the original training set
n
n
0.632*n
0.632∗n
0.632*n
0.632∗n
0.632*n
0.632∗n
L
L
L
L
L
L
h_1
h1
h_2
h2
h_m
hm
Boosting
=> iteratively learn from the constructed base classifiers
AdaBoost
the most famous boosting algorithm...
"Adaptive Boosting"
=> weak to strong
Adaboost
- Maintains a weight for all instances in the training data
- In each iteration , hypothesis is calculated to minimize the weighted error on the training set.
- The weighted error of is applied to the training set to update all weights of all instances in the training data
- Overall effect: Place more weight on training examples that were previously misclassified
l
l
h_l
hl
h_l
hl
Adaboost
Input:
- Training data
- Initial weights
- Error function
\{(X_1,y_1),(X_2,y_2),...,(X_n,y_n)\}, y \in \{-1,1\}
{(X1,y1),(X2,y2),...,(Xn,yn)},y∈{−1,1}
w_{1,1},w_{2,1},...,w_{n,1} = 1/n
w1,1,w2,1,...,wn,1=1/n
E(f(x),y,i)=e^{-y_if(x_i)}
E(f(x),y,i)=e−yif(xi)
Procedure:
1. for t in (1 to m iterations):
2. Apply learning algorithm to find such that
3. is minimized.
4. Calculate weighted error of ,
5. Update
6. Final ensemble classifier
h_t
ht
\epsilon _t=\sum{w_{i,t}}
ϵt=∑wi,t
\alpha _t=1/2((1-\epsilon_t)/\epsilon_t)
αt=1/2((1−ϵt)/ϵt)
h_t
ht
w_{i,t+1} = w_{i,t}*E(\alpha_th_t,y,i) = w_{i,t}e^{-y_i\alpha_th_t}
wi,t+1=wi,t∗E(αtht,y,i)=wi,te−yiαtht
h_{ensemble}=\sum\alpha_th_t
hensemble=∑αtht
Adaboost
n~~(weights =w_{i,1})
n (weights=wi,1)
n~~(weights =w_{i,2})
n (weights=wi,2)
n~~(weights =w_{i,3})
n (weights=wi,3)
n~~(weights =w_{i,m})
n (weights=wi,m)
L
L
h_1,\alpha_1
h1,α1
L
L
h_2,\alpha_2
h2,α2
L
L
h_m,\alpha_m
hm,αm
Random Forests
- A Random Forest is an ensemble classifier that uses decision trees build on bagged training data as base classifiers
- The only difference between a Random Forest and a typical bagged tree classifier is that the base trees are randomly split at each node by randomly selecting features.
Random Forests
Procedure RandomForest():
1. Sample bootstraps from the training data
2. for each bootstrap sample in :
3. BuildRandomizedTree()
4.
m
m
i
i
1 ~to~ m
1 to m
h_i =
hi=
h_{ensemble}=\sum{h_i}
hensemble=∑hi
Procedure BuildRandomizedTree():
1. Initialize root node of tree to be the whole space
2. At each node newly split:
3. Select random feature space of features
4. From , find a feature that best splits current node
R
R
r
r
R
R
Ensemble Learning and Random Forests
By Tzu-Li Tai
Ensemble Learning and Random Forests
Ensemble Learning and Random Forests, Machine Learning Lecture @ NCKU TechOrange, Date: 11/23

