






























Upkar Lidder
Upkar Lidder is a Full Stack Developer and Data Wrangler with a decade of development experience in a variety of roles. He can be seen speaking at various conferences and participating in local tech groups and meetups.
Upkar Lidder
http://bit.ly/ibm-cloud-summit-2019
http://bit.ly/upkar-autoai
> ulidder@us.ibm.com > @lidderupk > upkar.dev
@lidderupk
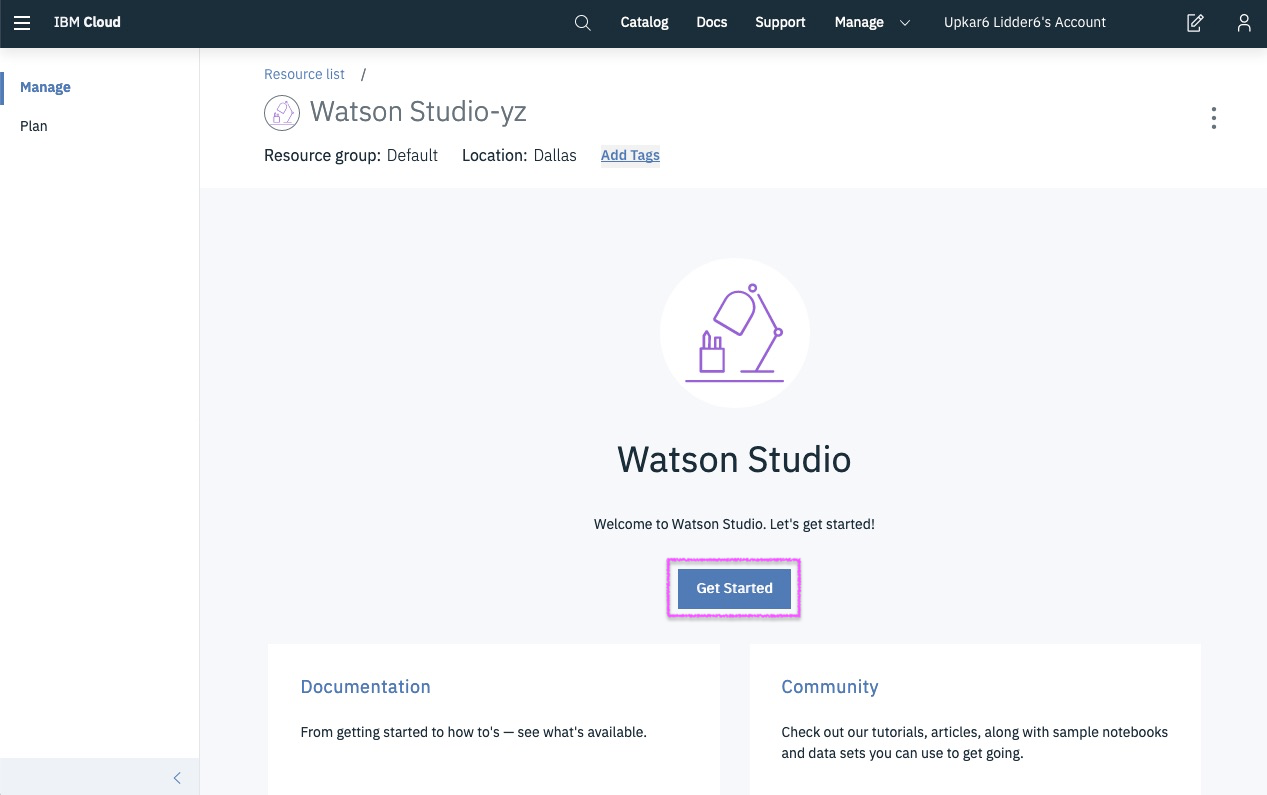
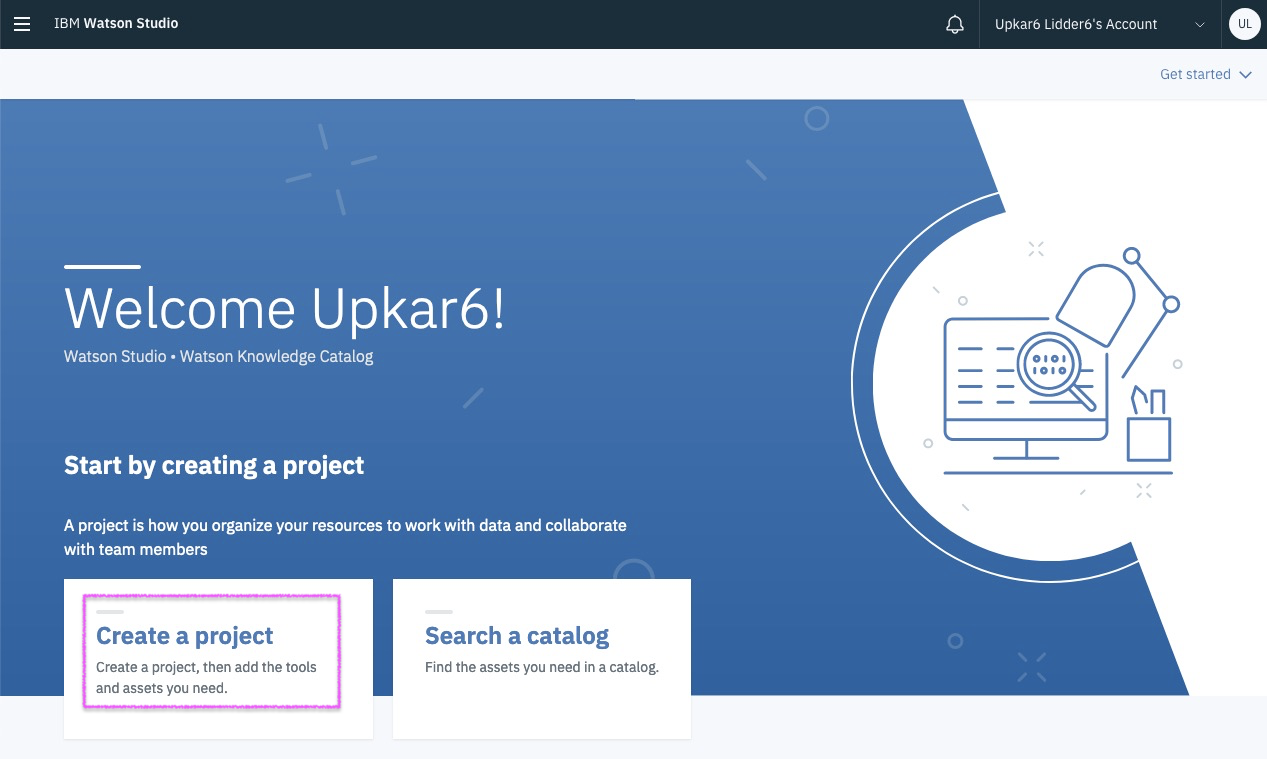
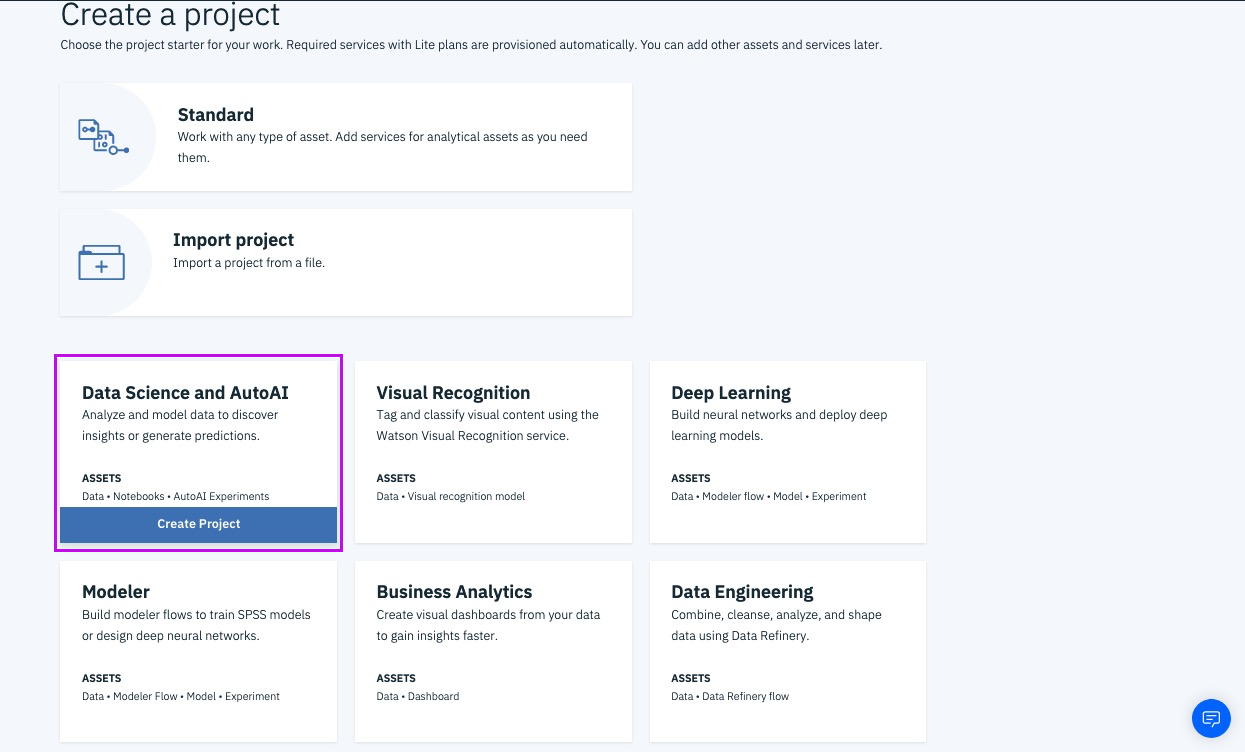
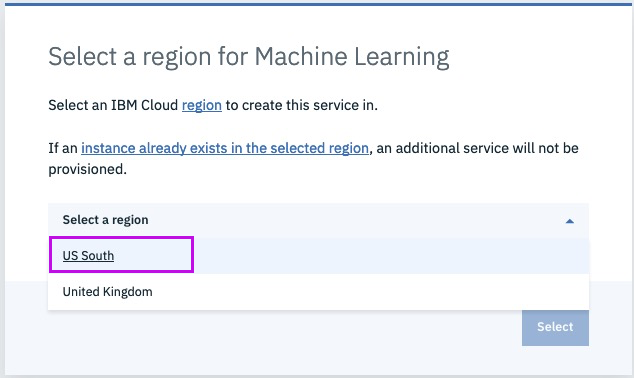
IBM Developer
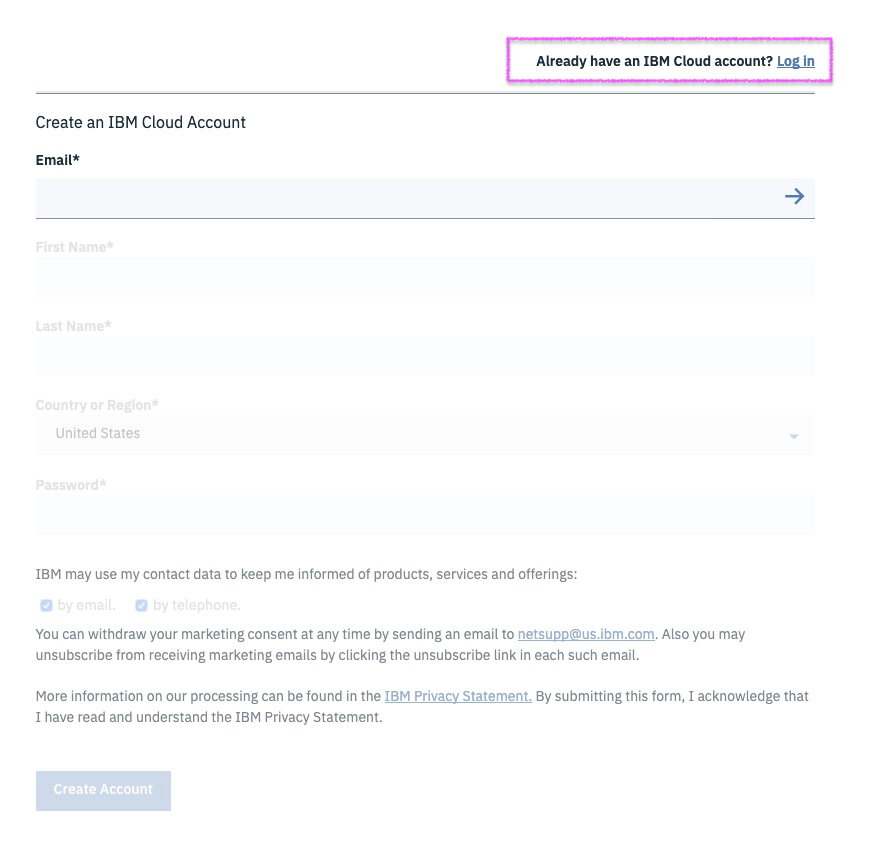
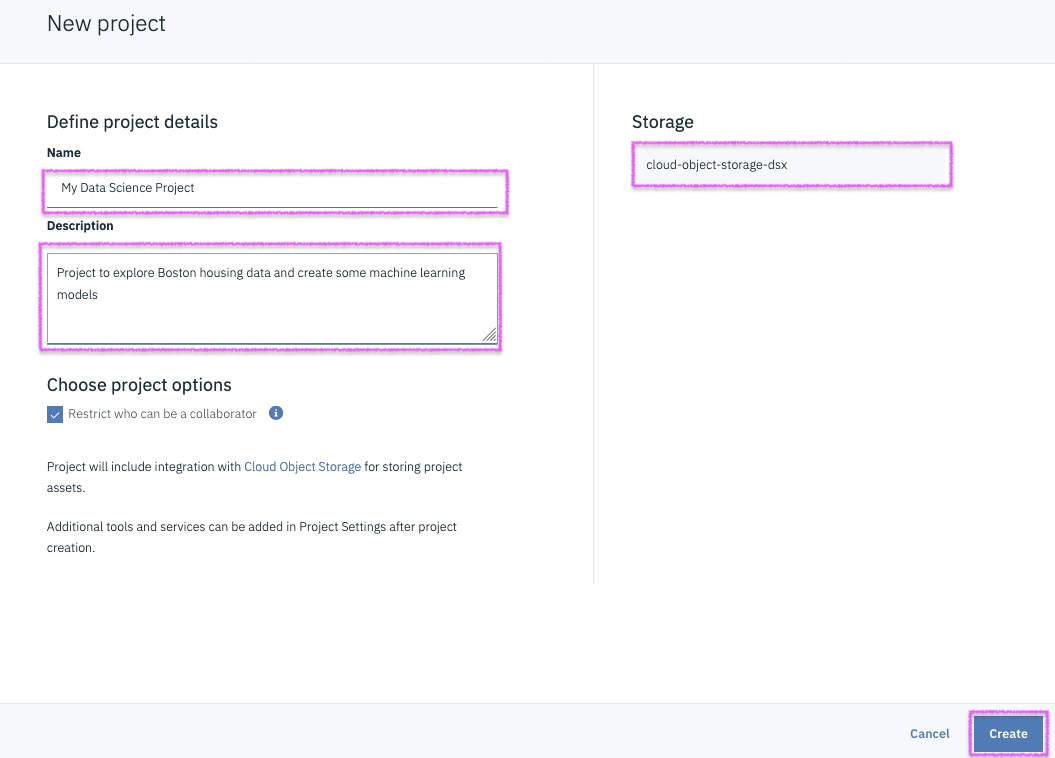
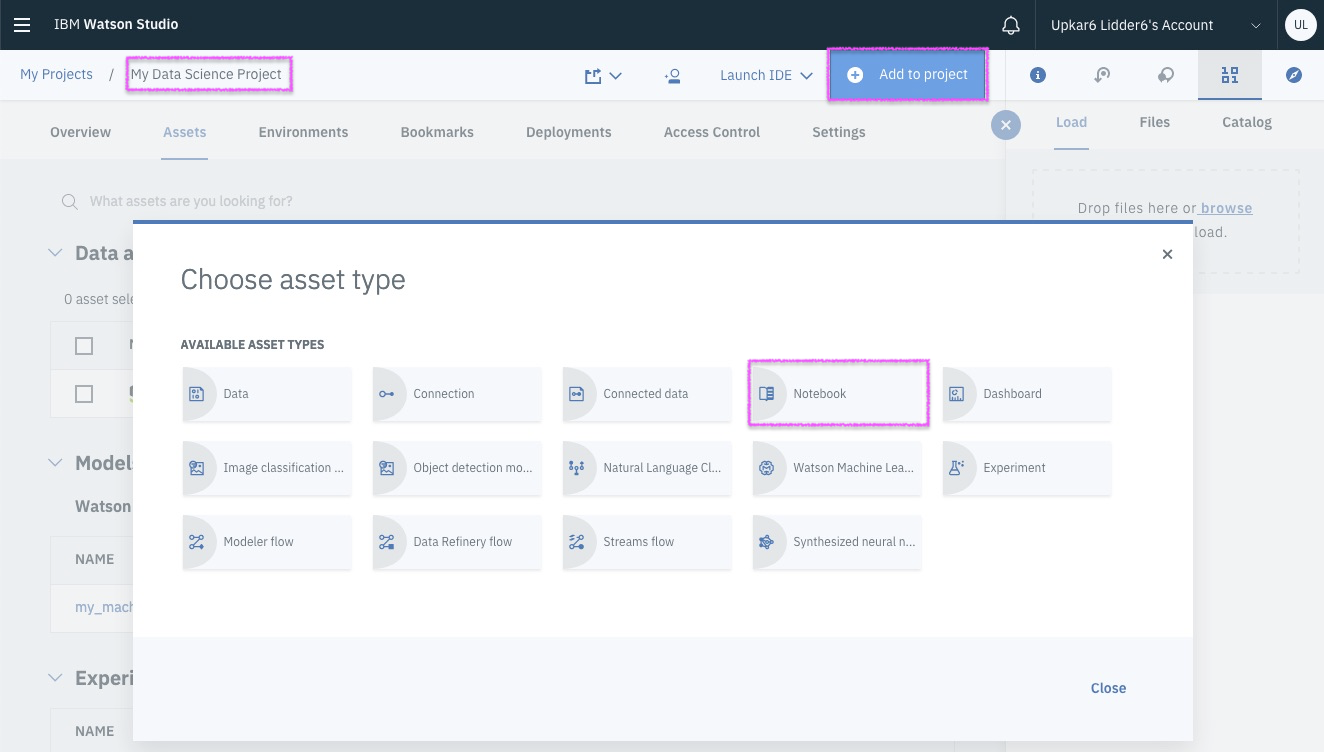
1. Create IBM Cloud Account using THIS URL
3. If you already have an account, use the above URL to sign into your IBM Cloud account.
2. Check your email and activate your account. Once activated, log back into your IBM Cloud account using the link above.
http://bit.ly/ibm-cloud-summit-2019
@lidderupk
IBM Developer
@lidderupk
IBM Developer
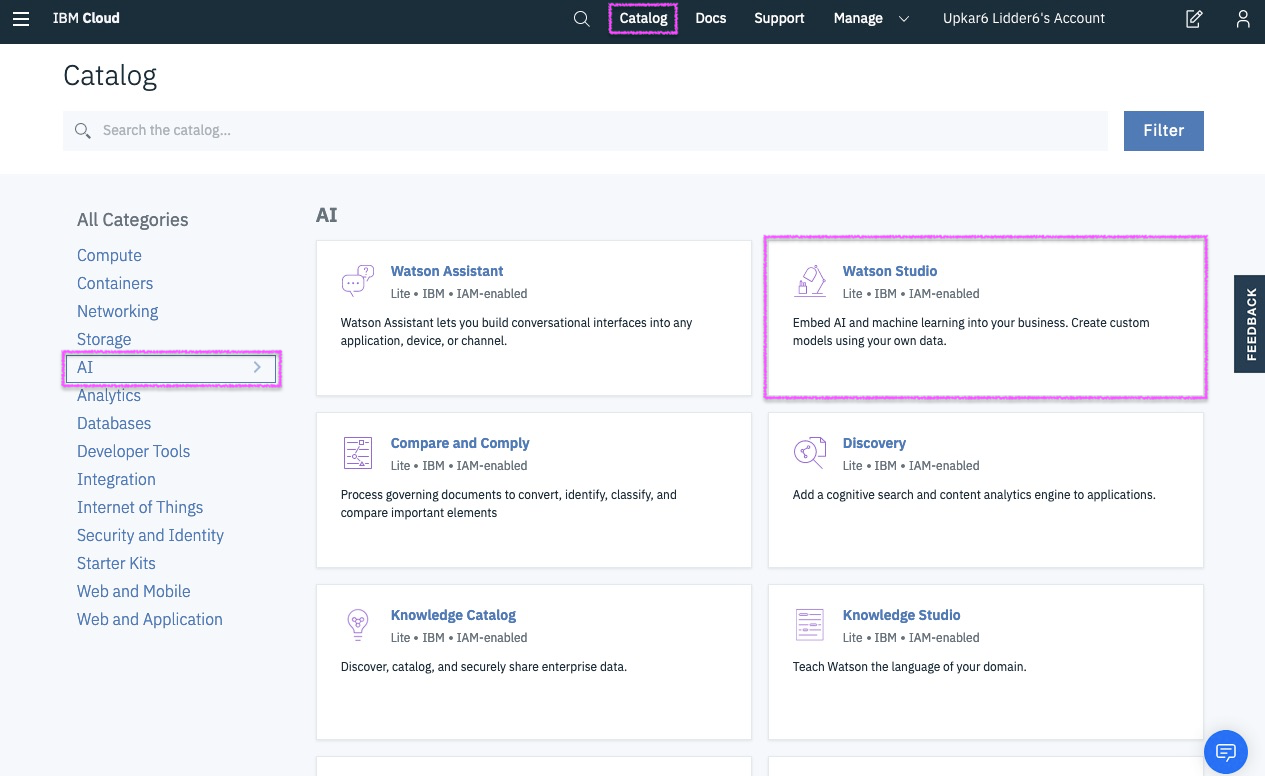
Natural Language Processing
Visual Recognition
@lidderupk
IBM Developer
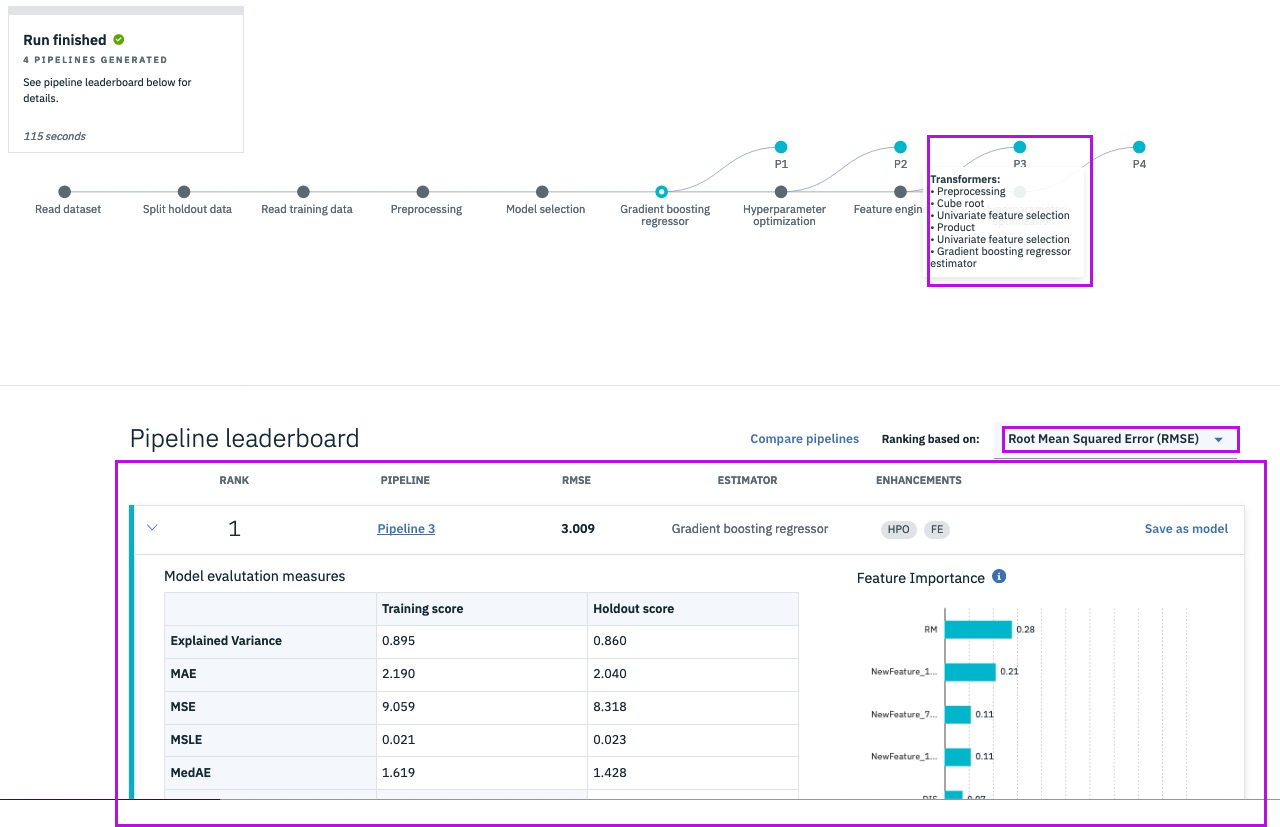
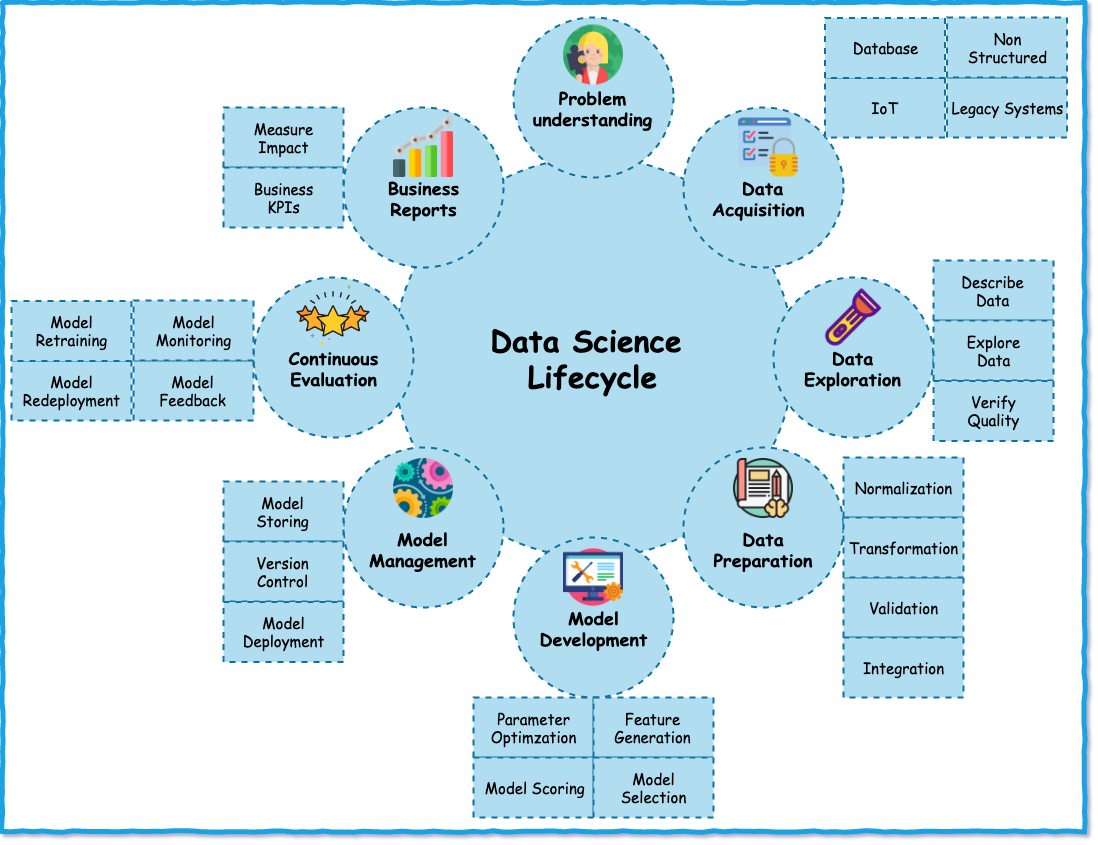
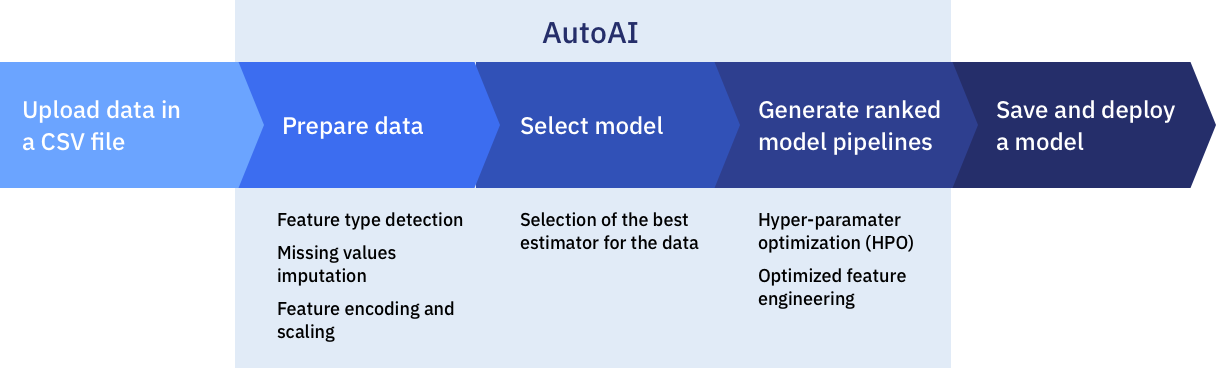
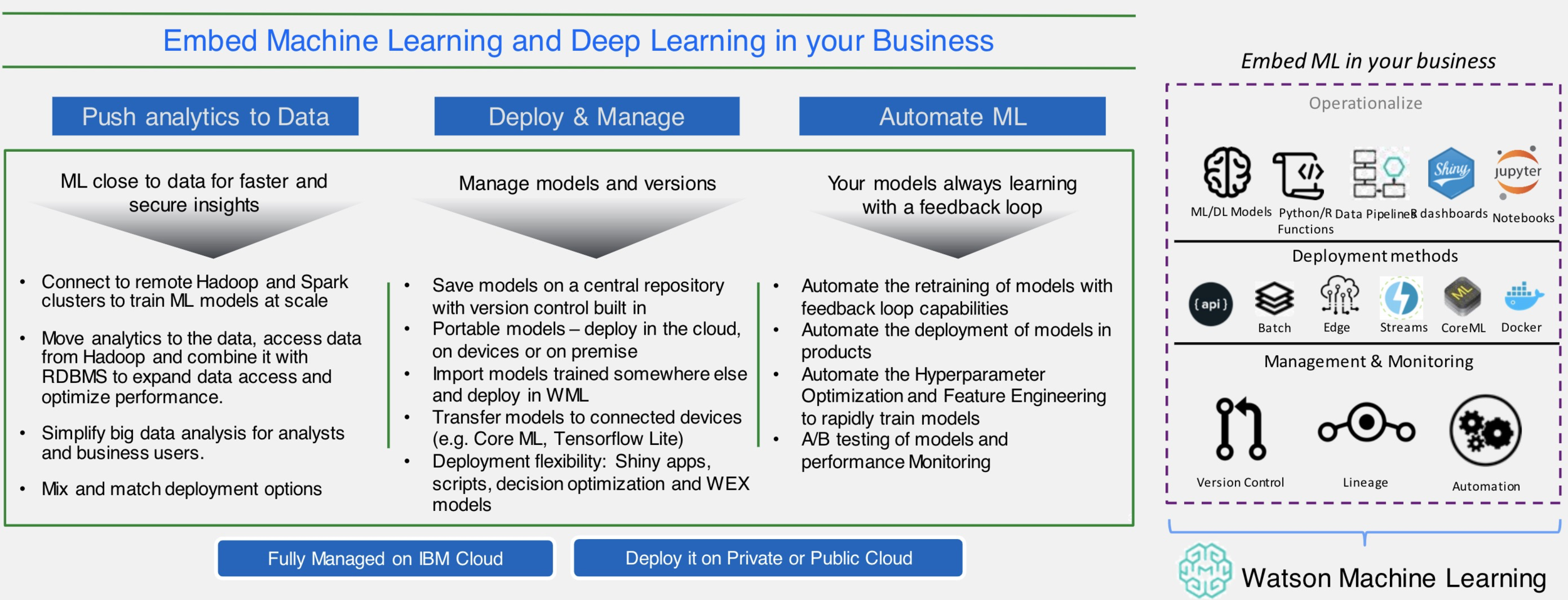
To help simplify an AI lifecycle management, AutoAI automates:
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
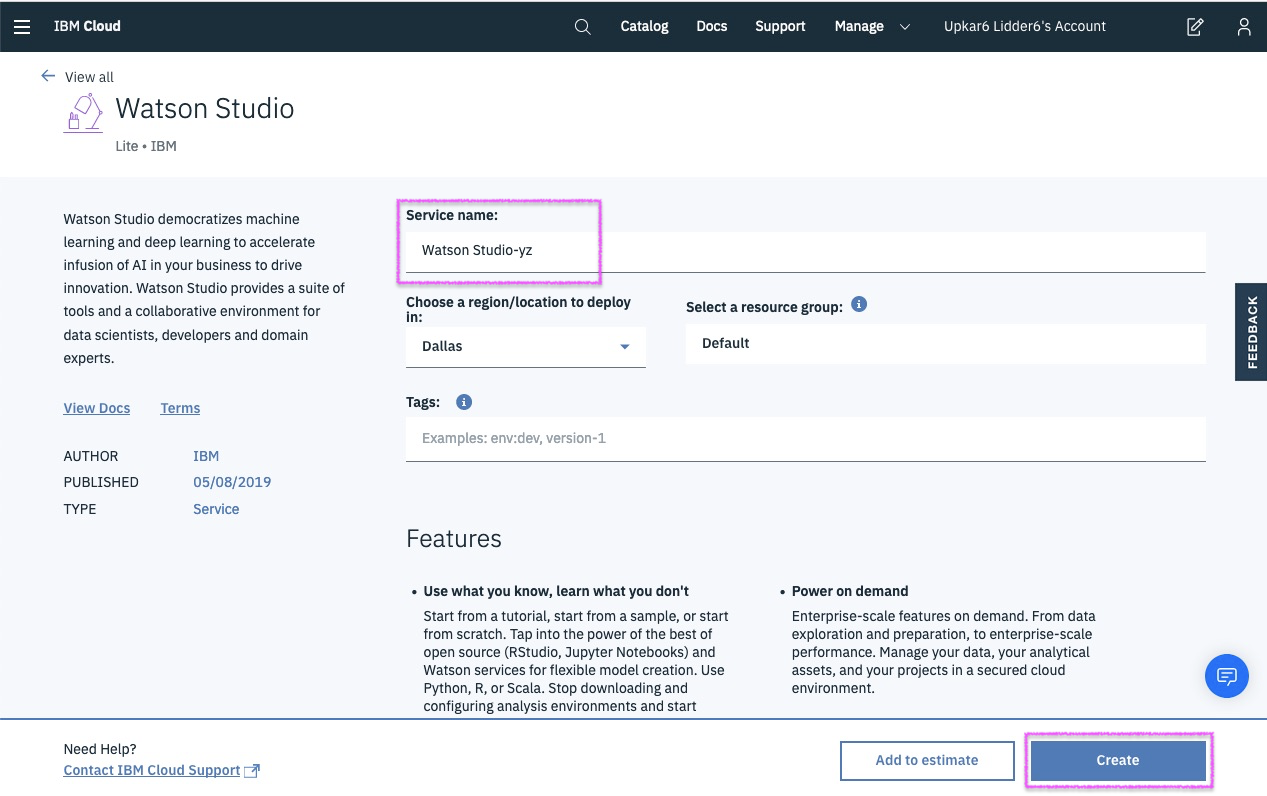
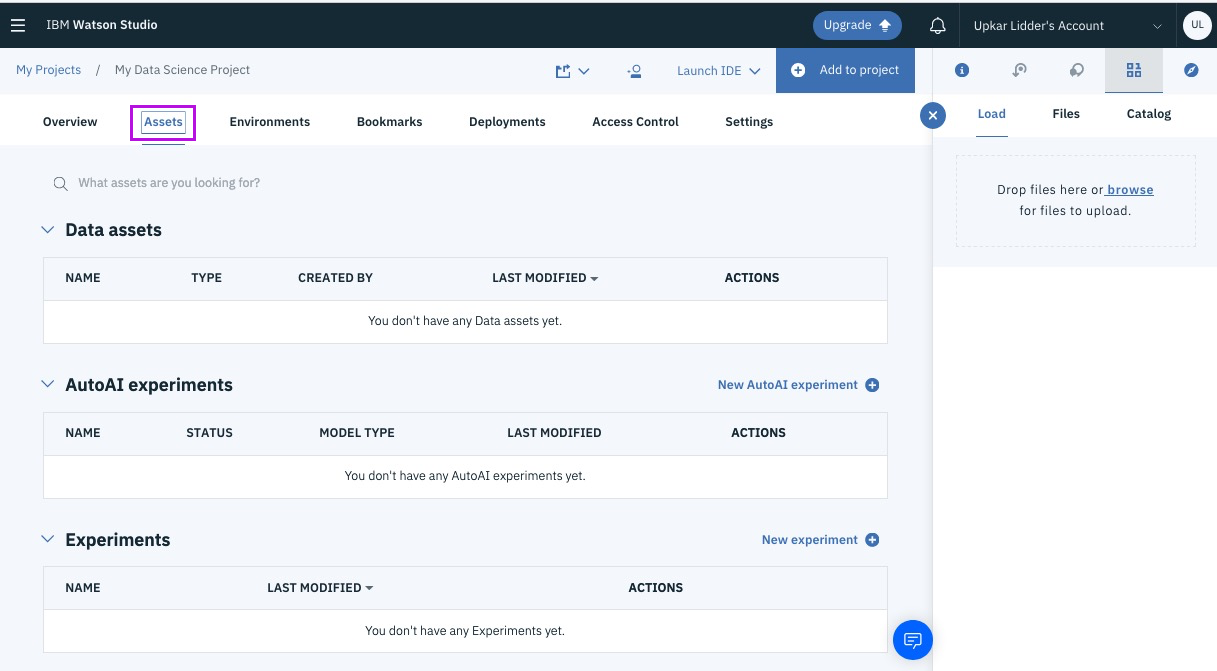
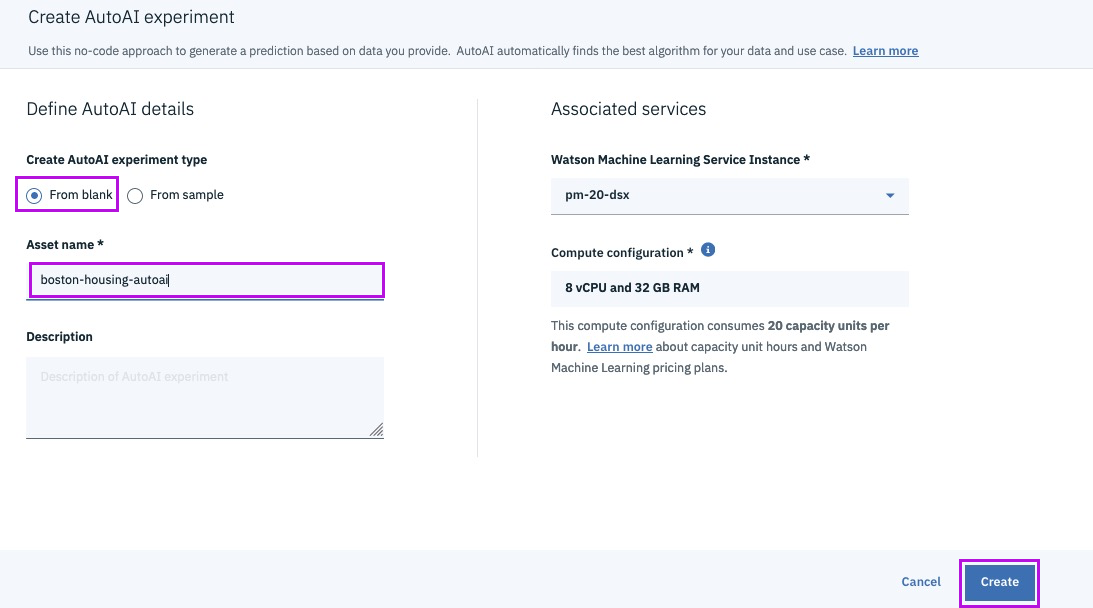
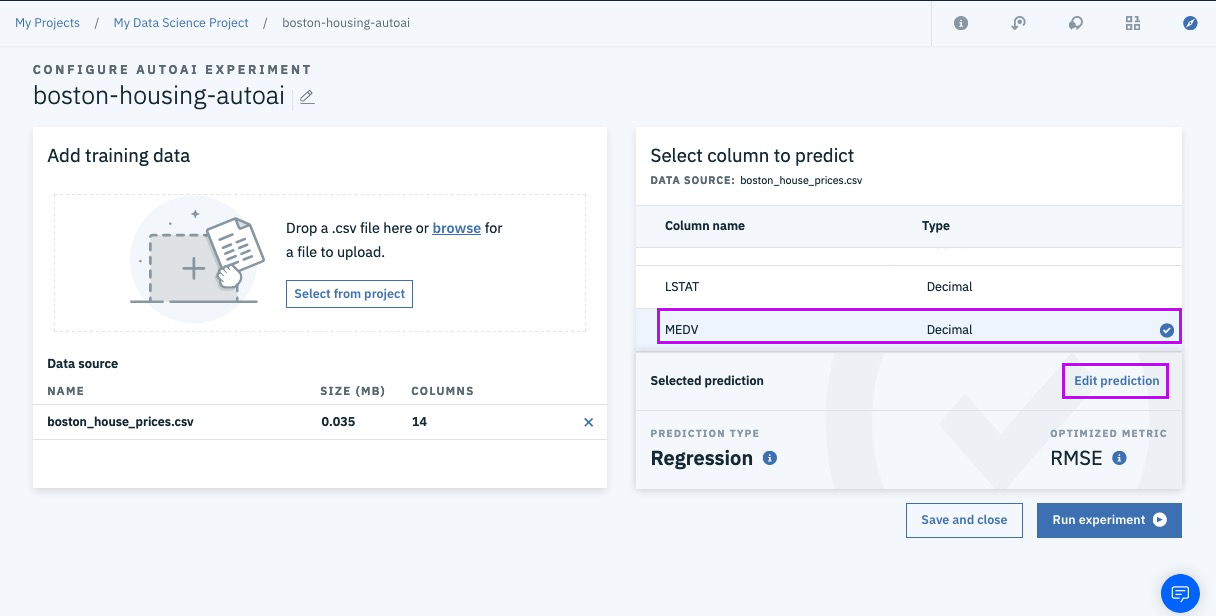
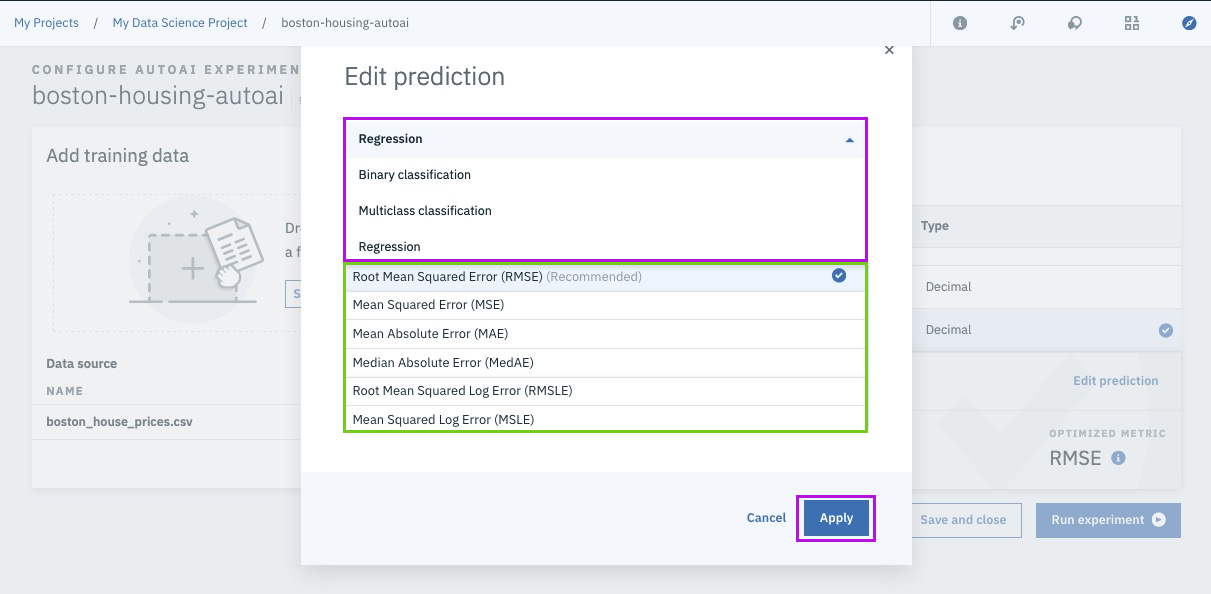
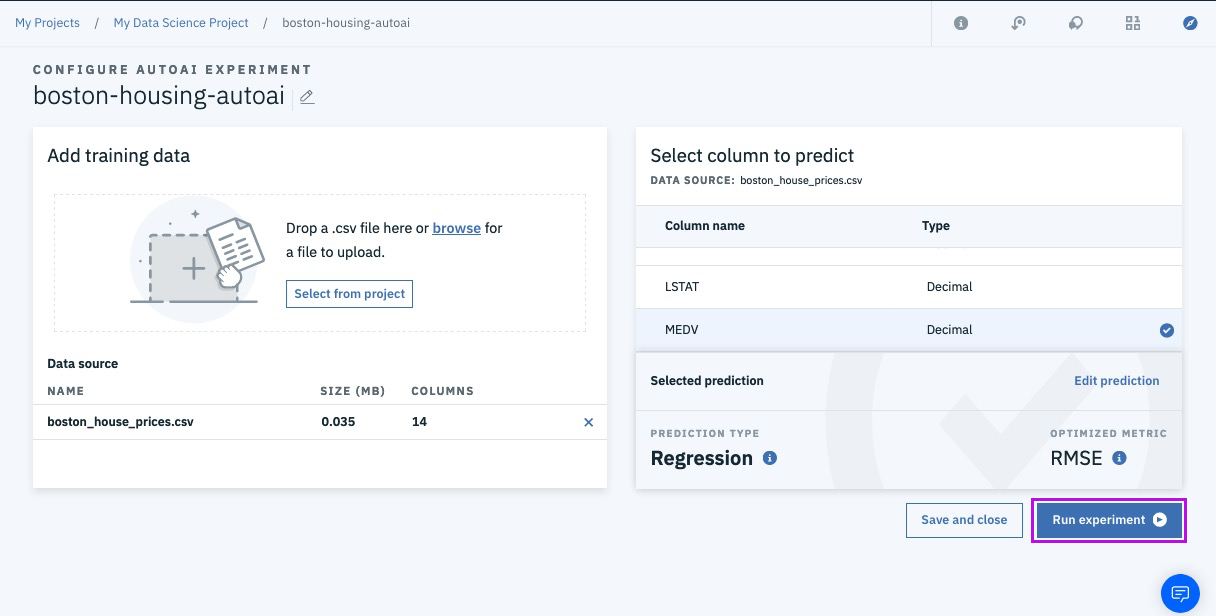
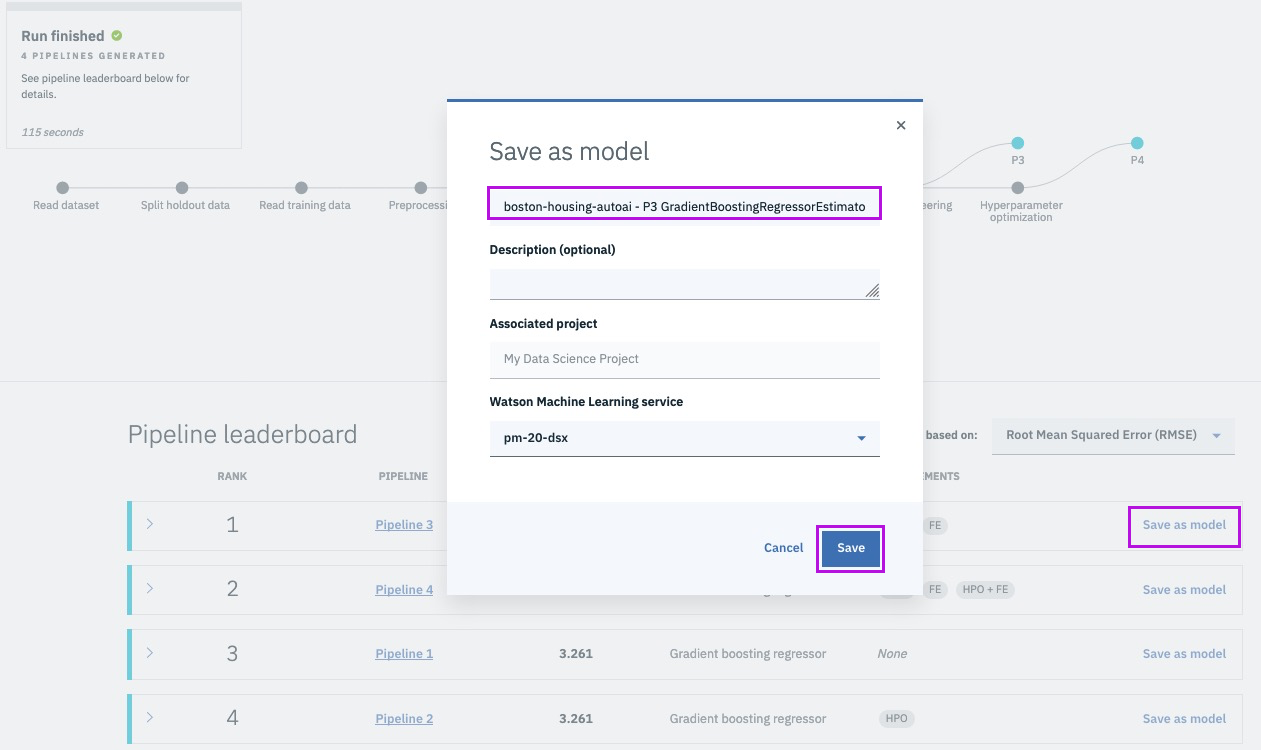
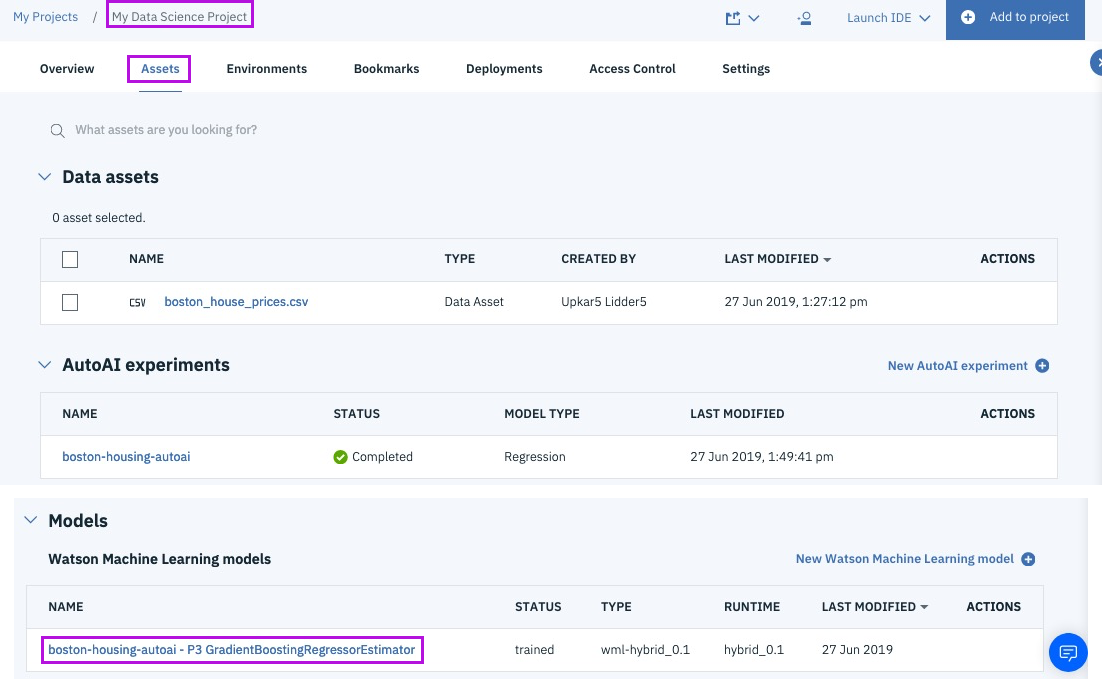
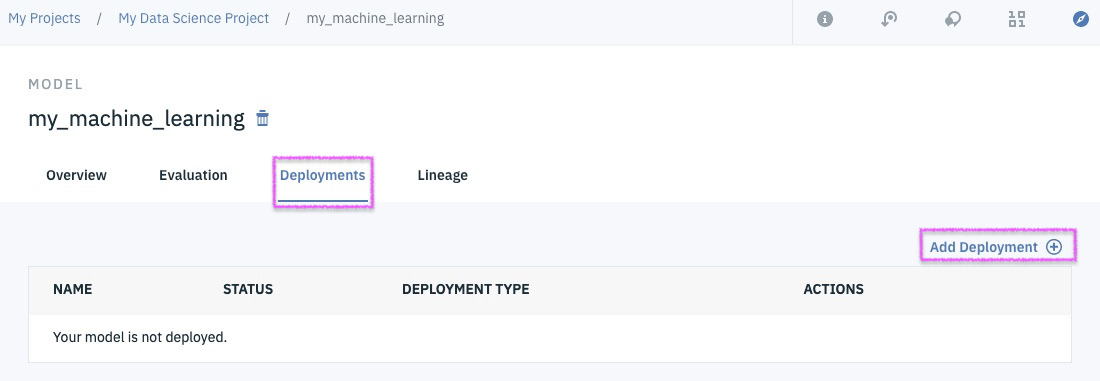
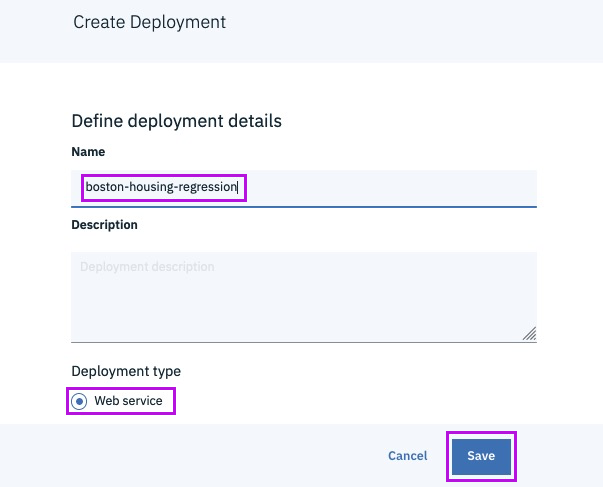
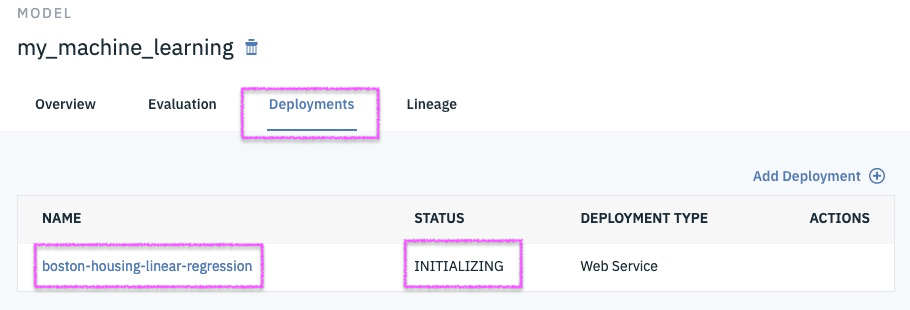
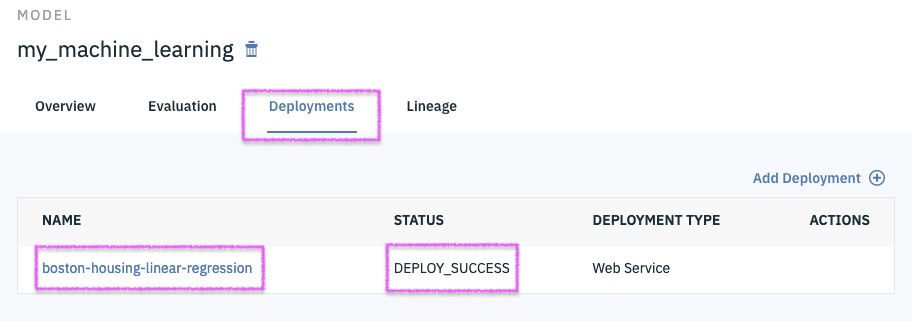
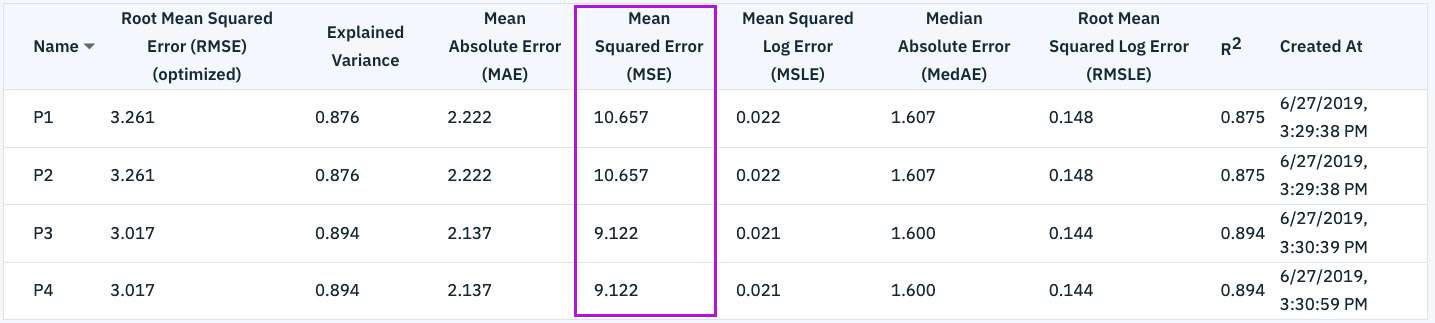
Successfully Create, Store and Deploy a Linear Regression Model on IBM Cloud using Watson Studio and Watson Machine Learning Services.
@lidderupk
IBM Developer
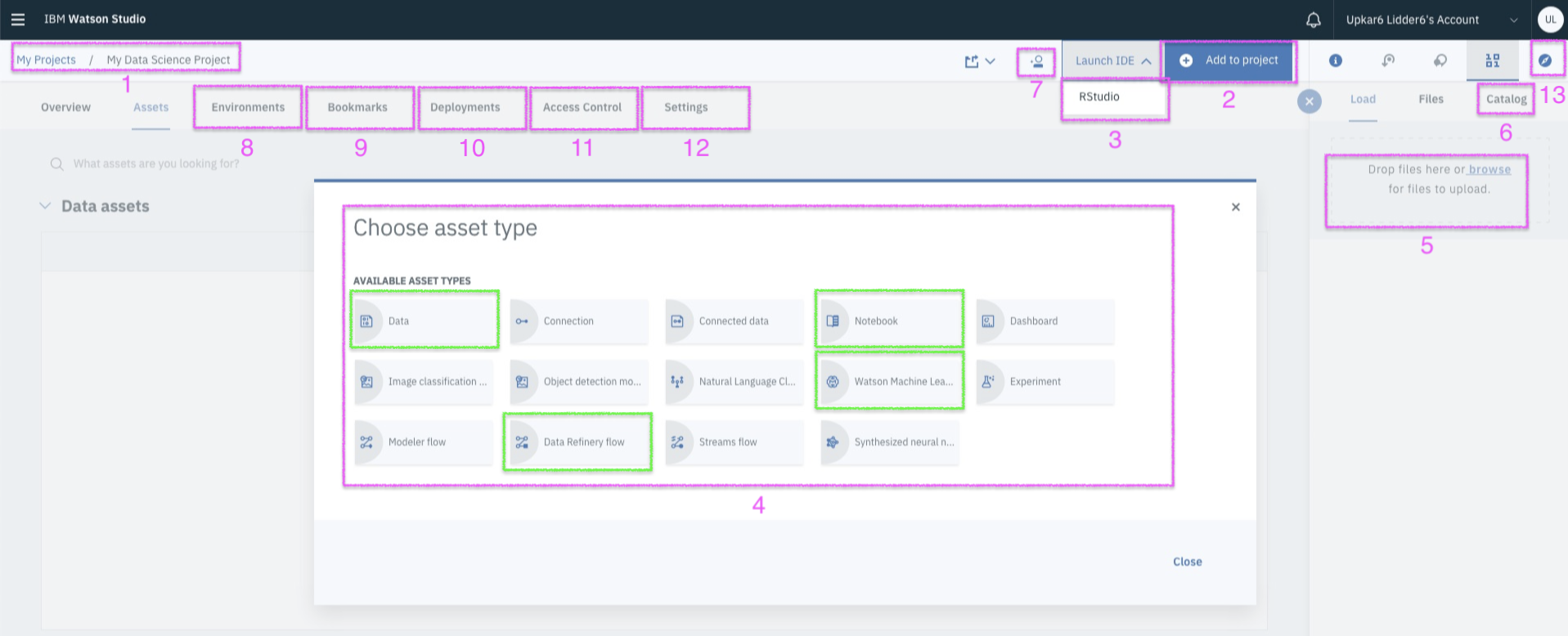
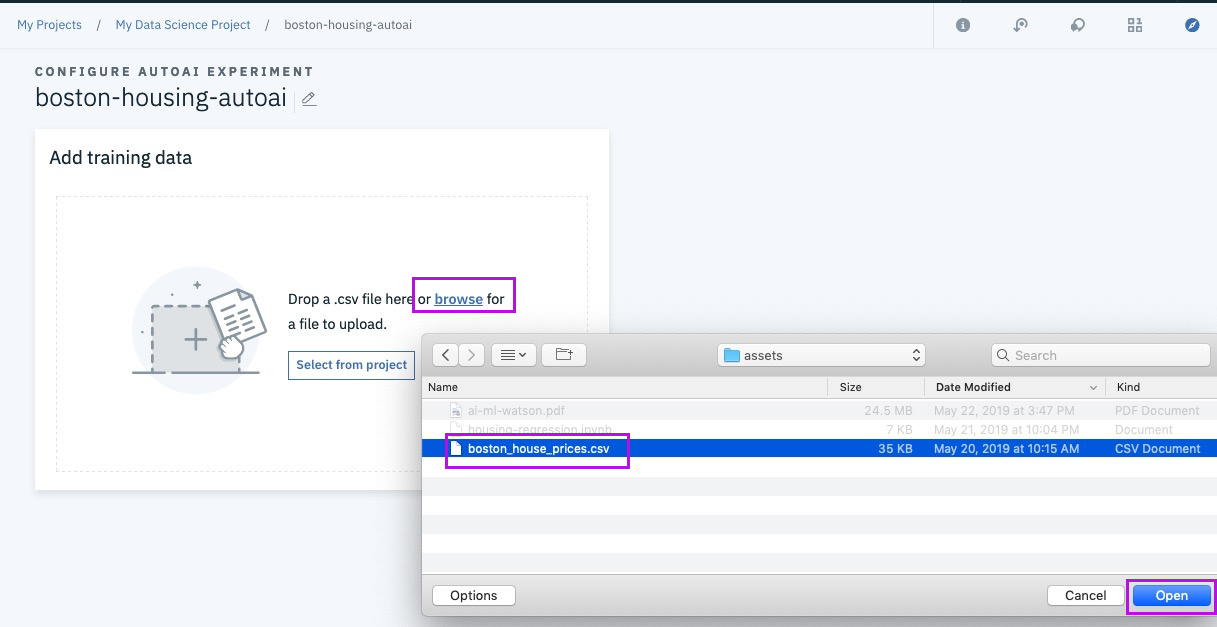
http://bit.ly/boston-house-csv
@lidderupk
IBM Developer
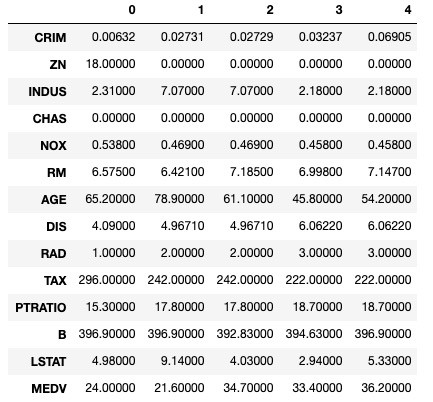
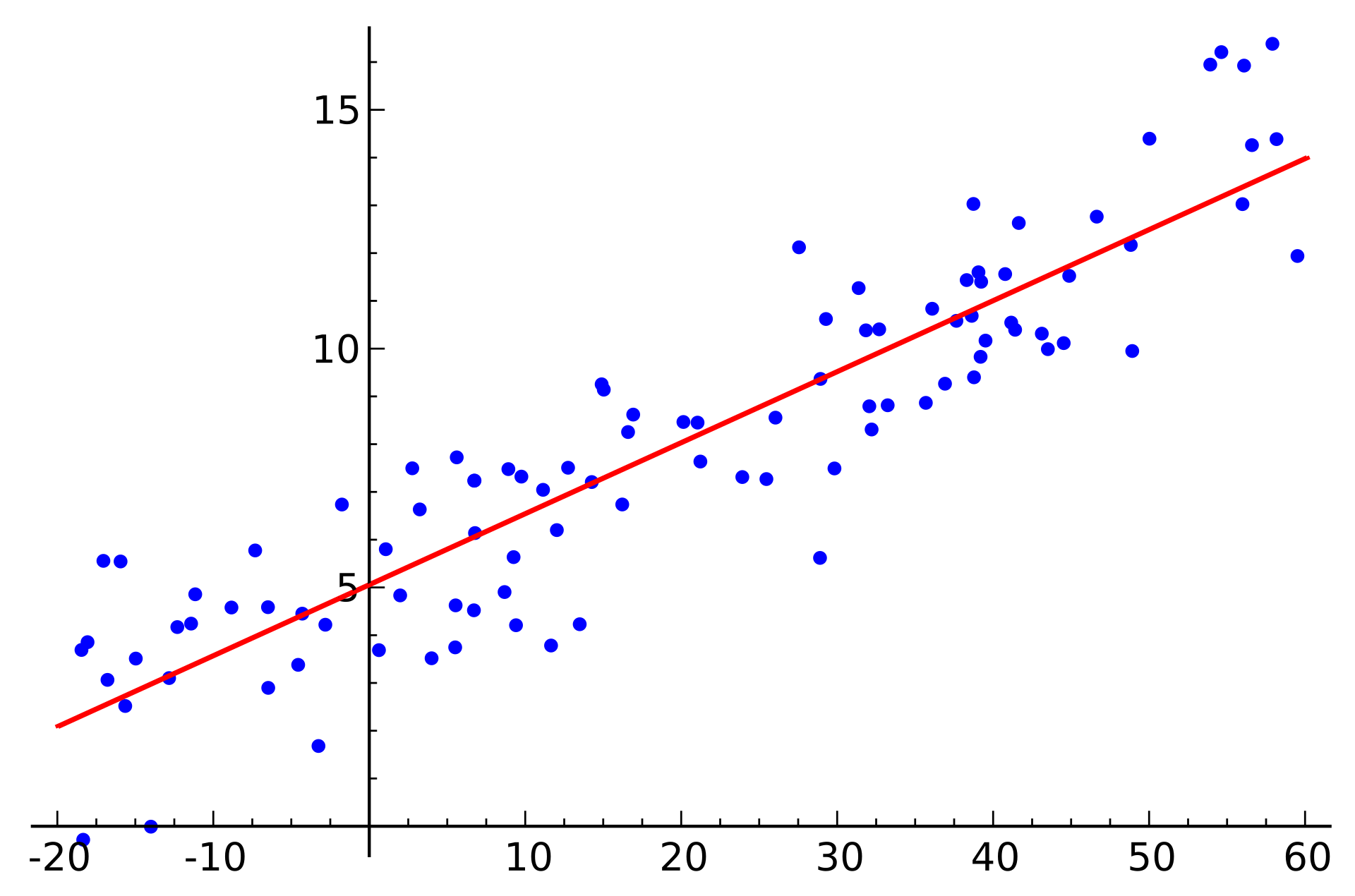
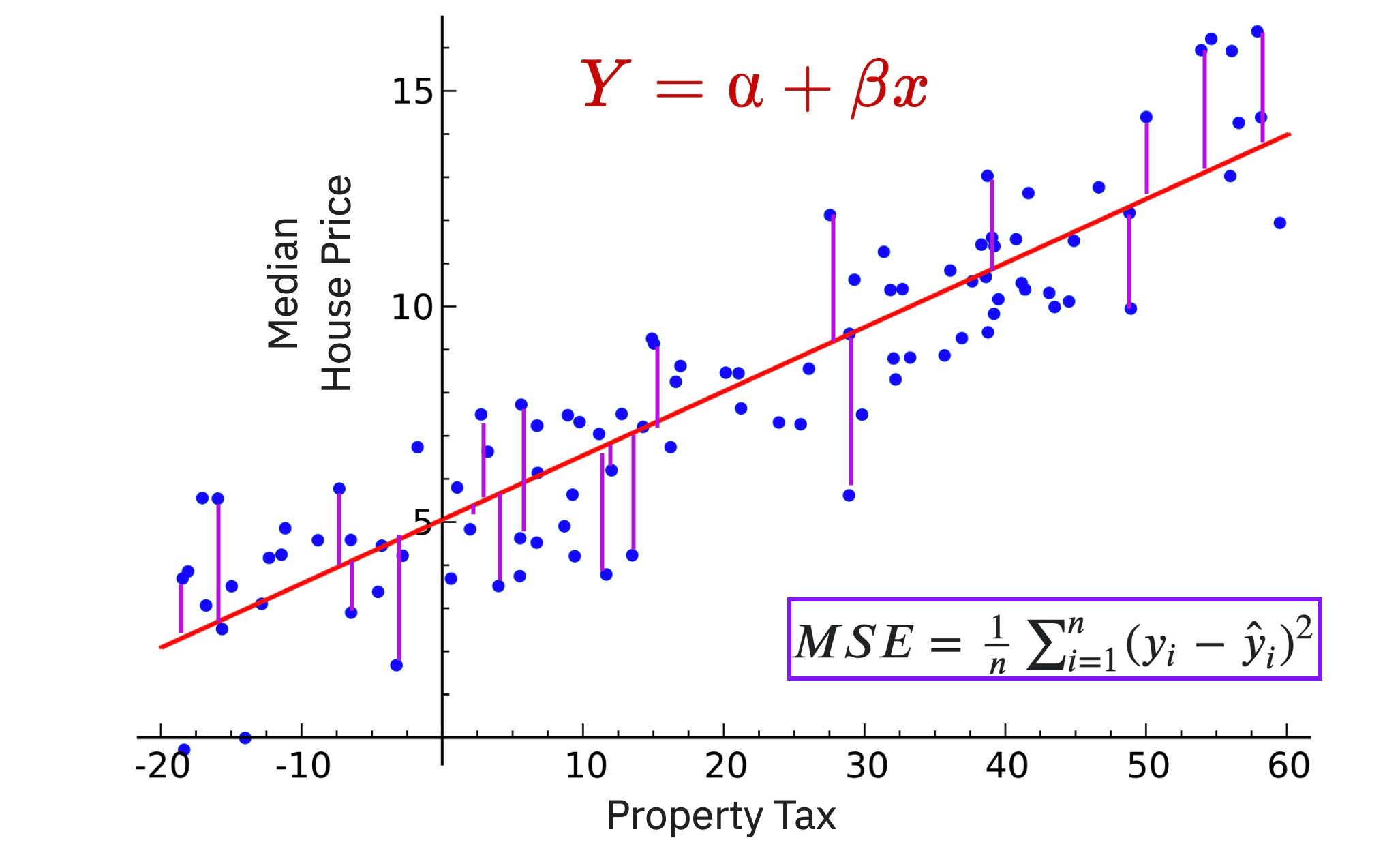
Median House Price
Property Tax
#bedrooms
@lidderupk
IBM Developer
#bedrooms
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
http://bit.ly/boston-house-csv
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
1
2
@lidderupk
IBM Developer
@lidderupk
IBM Developer
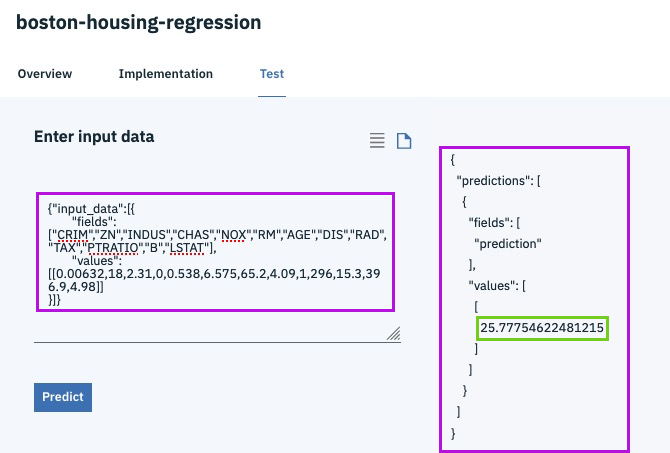
{"input_data":[{
"fields": ["CRIM","ZN","INDUS","CHAS","NOX","RM","AGE","DIS","RAD","TAX","PTRATIO","B","LSTAT"],
"values": [[0.00632,18,2.31,0,0.538,6.575,65.2,4.09,1,296,15.3,396.9,4.98]]
}]}@lidderupk
IBM Developer
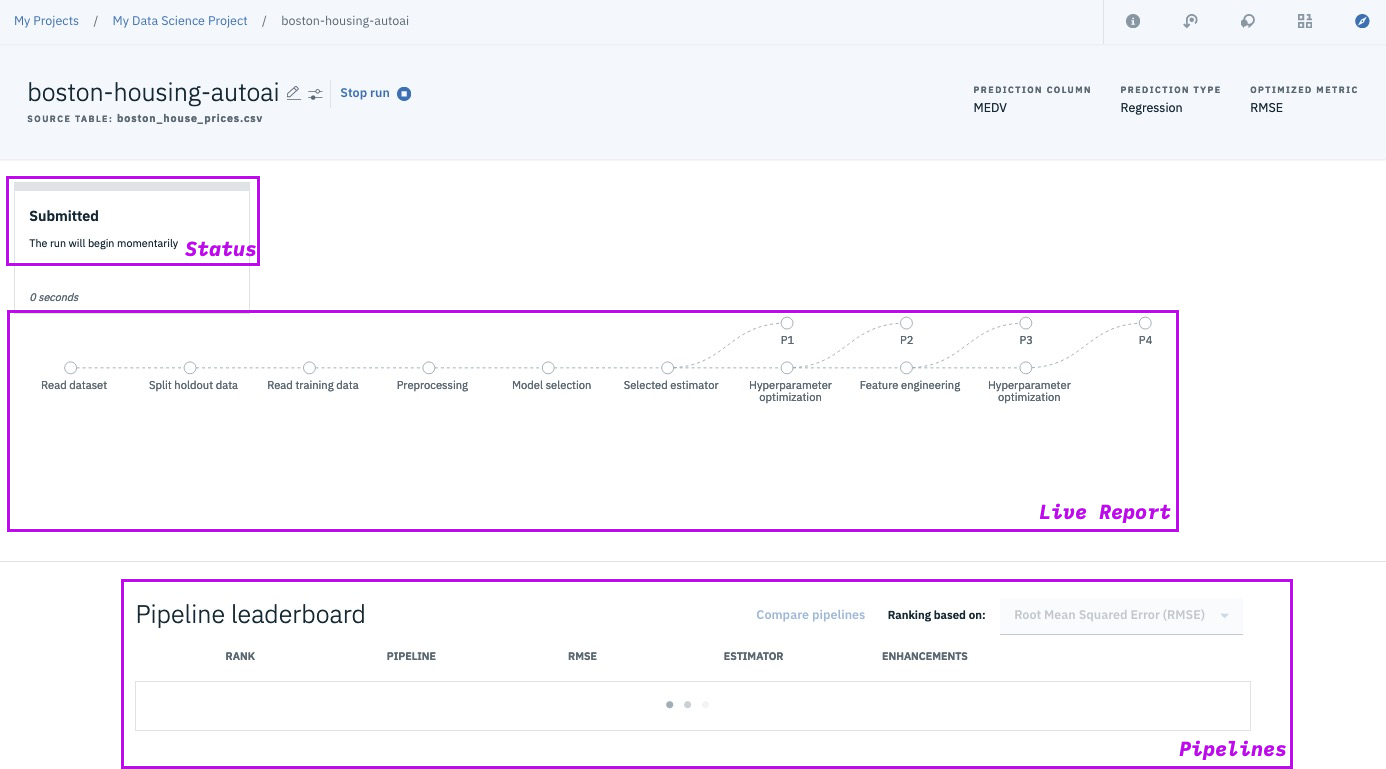
Data pre-processing
Automated model selection
Automated Feature Engineering
Hyperparameter Optimization
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
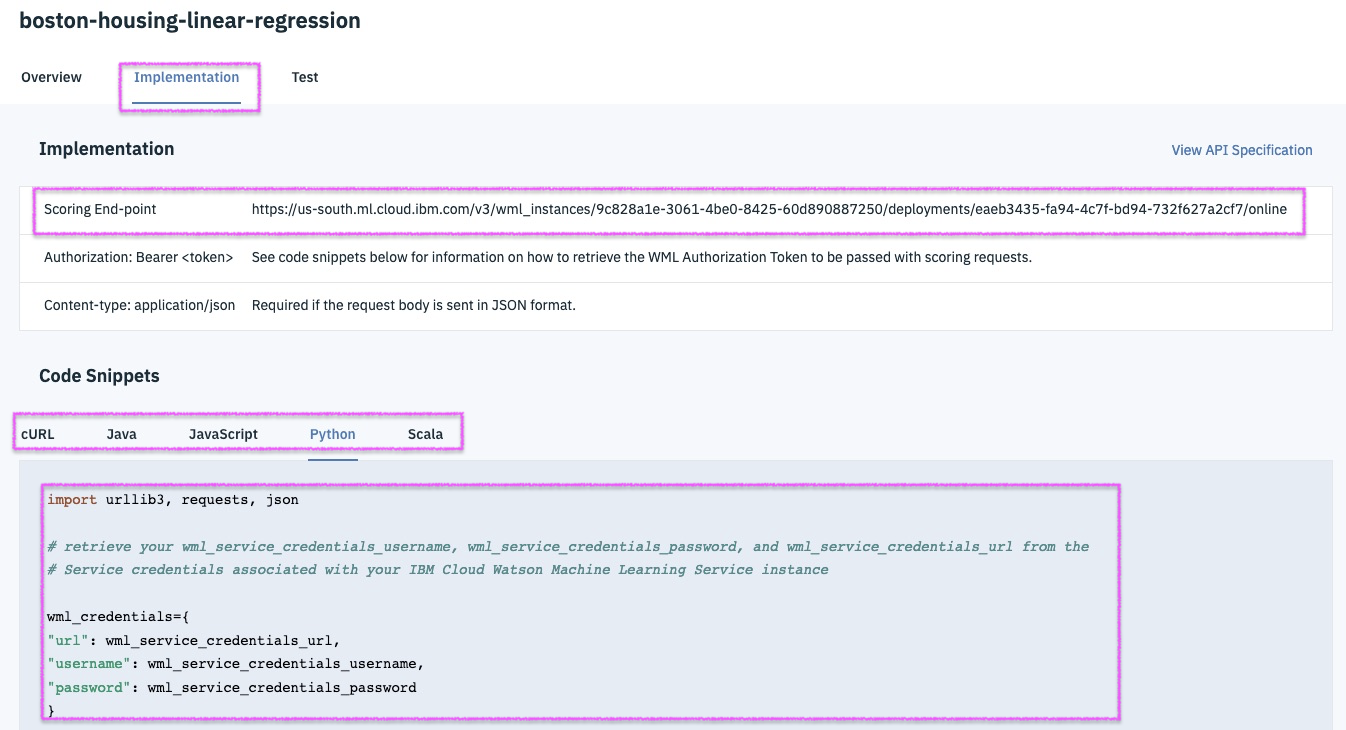
http://wml-api-pyclient.mybluemix.net/index.html
@lidderupk
IBM Developer
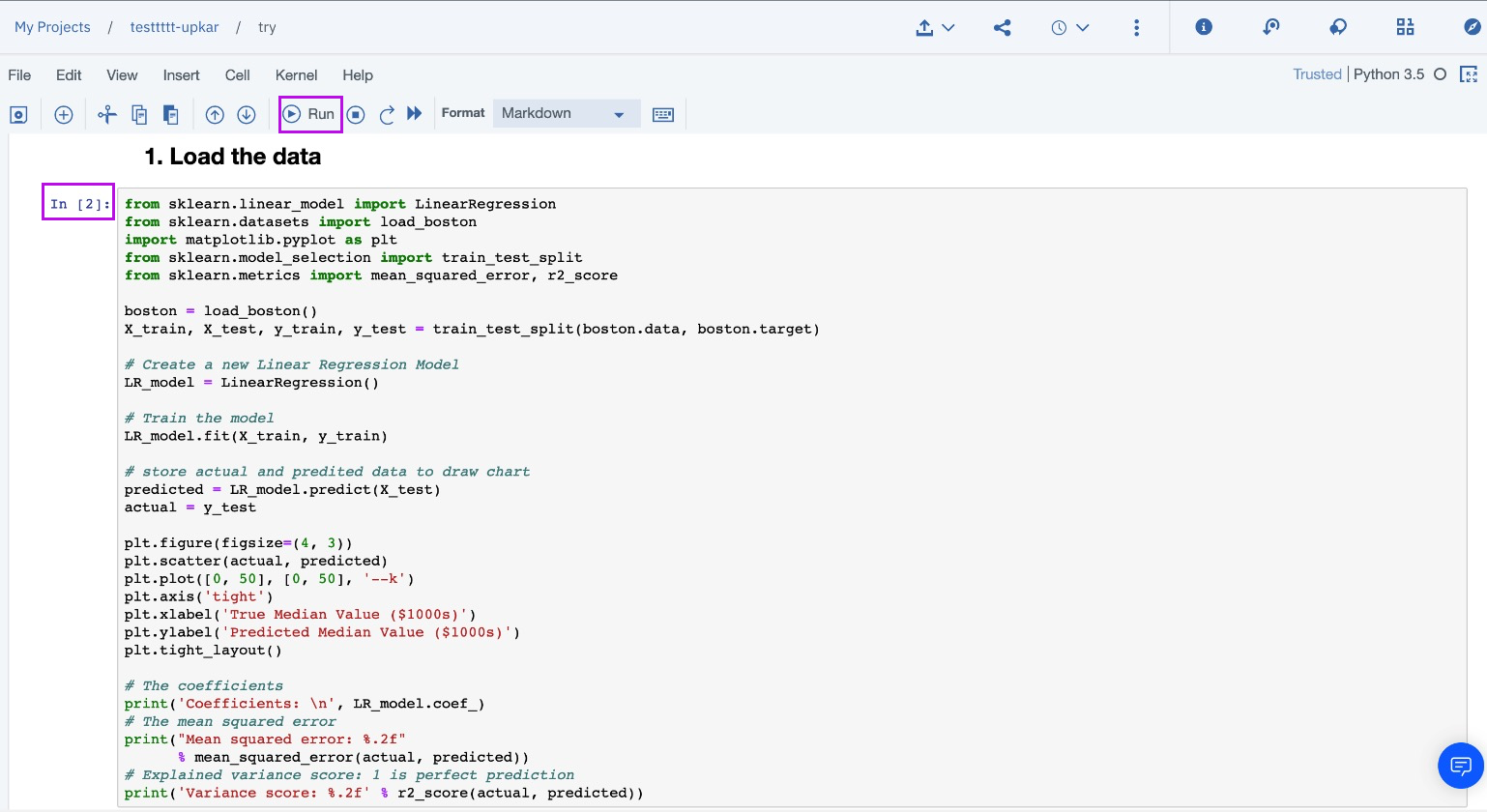
from sklearn.linear_model import LinearRegression
from sklearn.datasets import load_boston
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.metrics import mean_squared_error, r2_score
boston = load_boston()
X_train, X_test, y_train, y_test = train_test_split(boston.data, boston.target)
# Create a new Linear Regression Model
LR_model = LinearRegression()
# Train the model
LR_model.fit(X_train, y_train)
# store actual and predited data to draw chart
predicted = LR_model.predict(X_test)
actual = y_test
# The coefficients
print('Coefficients: \n', LR_model.coef_)
# The mean squared error
print("Mean squared error: %.2f"
% mean_squared_error(actual, predicted))
# Explained variance score: 1 is perfect prediction
print('Variance score: %.2f' % r2_score(actual, predicted))Output
👉🏽
@lidderupk
IBM Developer
AutoAI
Notebook
@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
# we will use WML to work with IBM Machine Learning Service
from watson_machine_learning_client import WatsonMachineLearningAPIClient
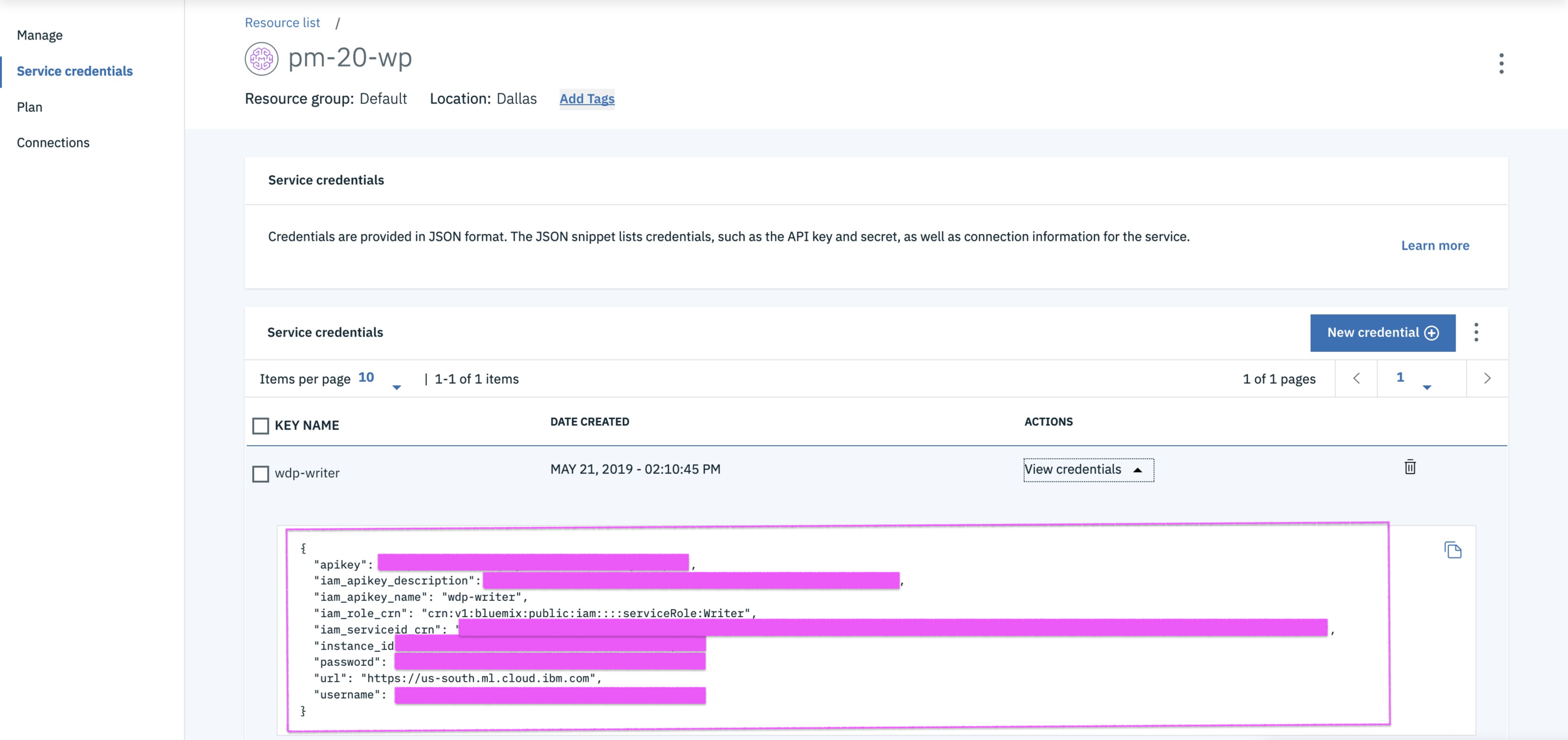
# Grab your credentials from the Watson Service section in Watson Studio or IBM Cloud Dashboard
wml_credentials = {
}
# Instantiate WatsonMachineLearningAPIClient
from watson_machine_learning_client import WatsonMachineLearningAPIClient
client = WatsonMachineLearningAPIClient( wml_credentials )
# store the model
published_model = client.repository.store_model(model=LR_model,
meta_props={'name':'upkar-housing-linear-reg'},
training_data=X_train, training_target=y_train)@lidderupk
IBM Developer
import json
# grab the model from IBM Cloud
published_model_uid = client.repository.get_model_uid(published_model)
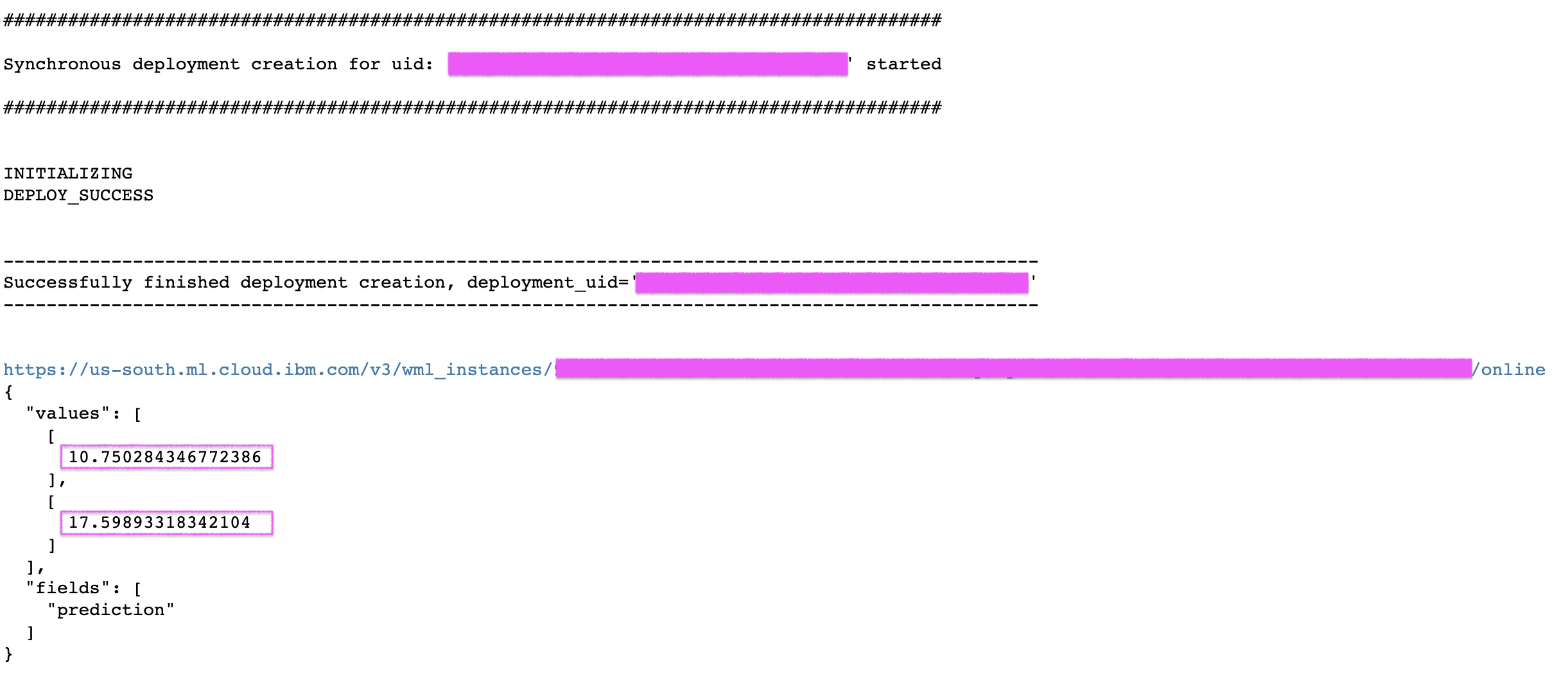
# create a new deployment for the model
model_deployed = client.deployments.create(published_model_uid, "Deployment of scikit model")
#get the scoring endpoint
scoring_endpoint = client.deployments.get_scoring_url(model_deployed)
print(scoring_endpoint)
#use the scoring endpoint to predict house median price some test data
scoring_payload = {"values": [list(X_test[0]), list(X_test[1])]}
predictions = client.deployments.score(scoring_endpoint, scoring_payload)
print(json.dumps(predictions, indent=2))@lidderupk
IBM Developer
@lidderupk
IBM Developer
@lidderupk
IBM Developer
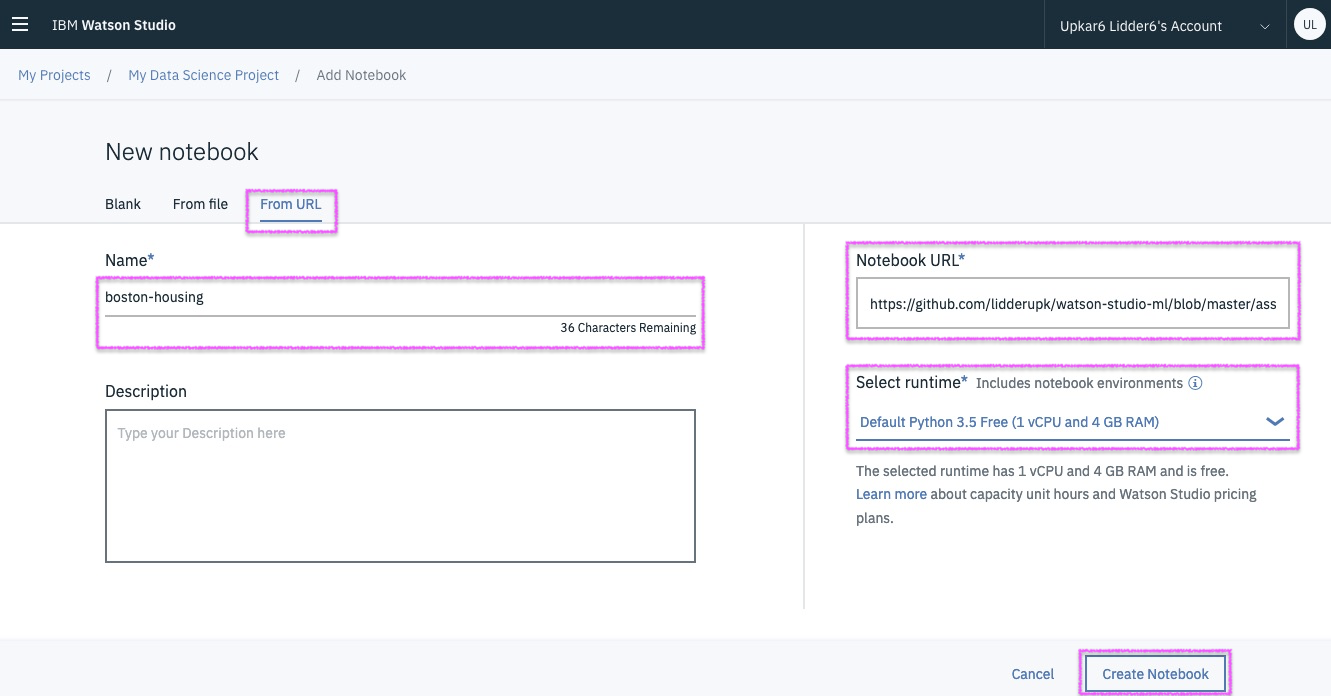
Grab the FULL URL from : http://bit.ly/boston-house-notebook
@lidderupk
IBM Developer
Grab the FULL URL from :
http://bit.ly/boston-house-notebook
@lidderupk
IBM Developer
Upkar Lidder, IBM
@lidderupk
https://github.com/lidderupk/
ulidder@us.ibm.com
@lidderupk
IBM Developer
By Upkar Lidder




