




























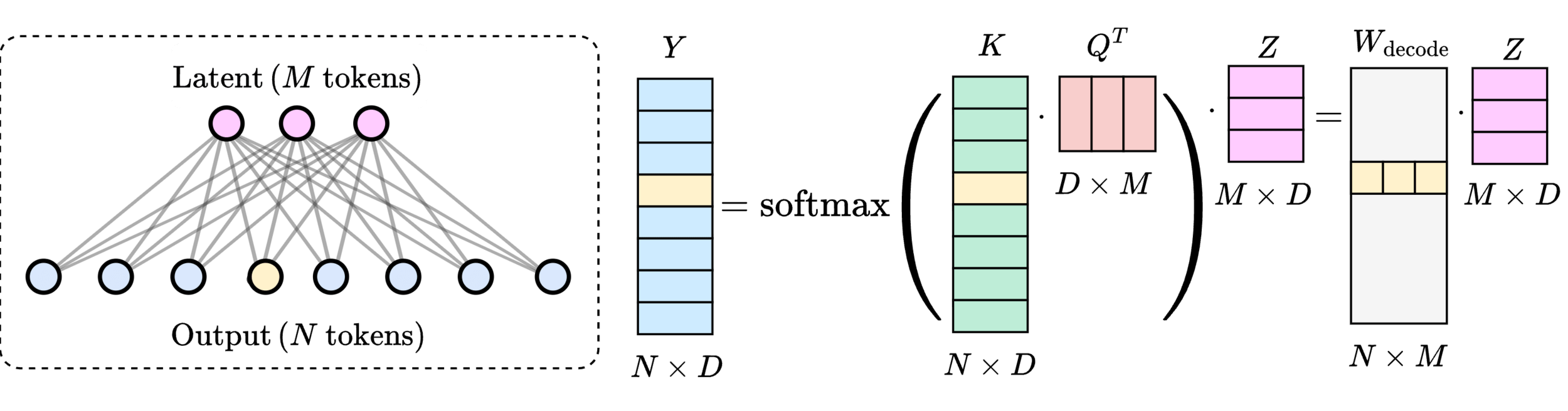






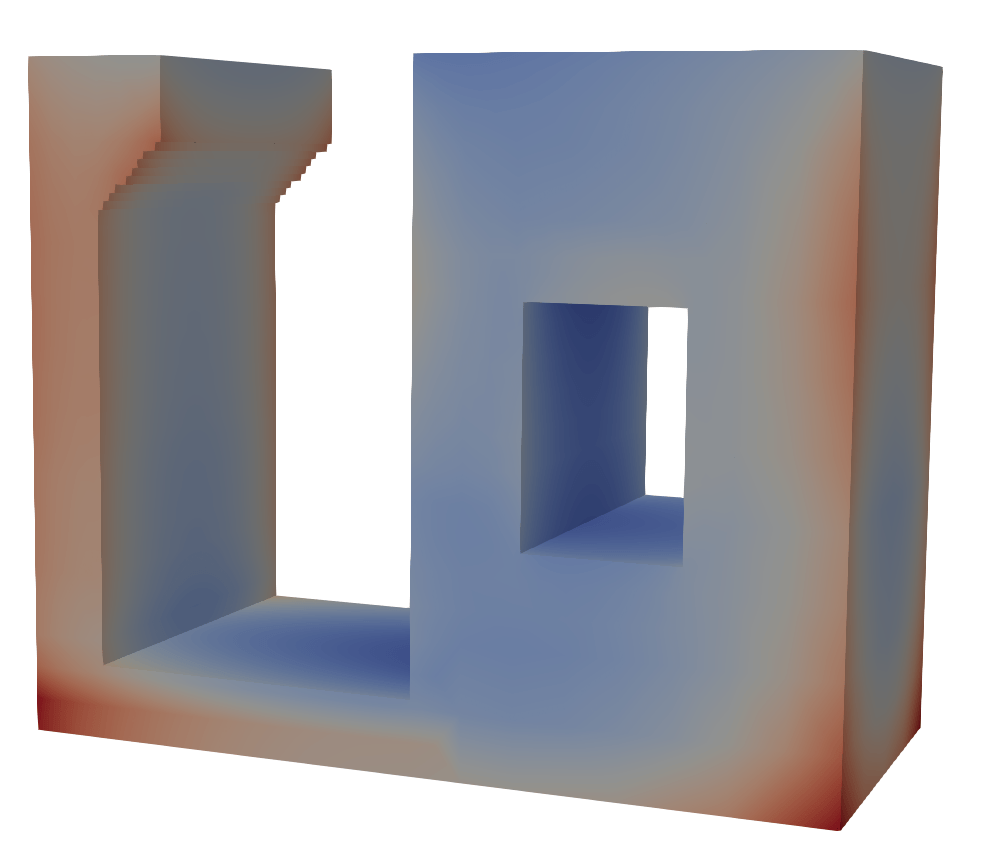










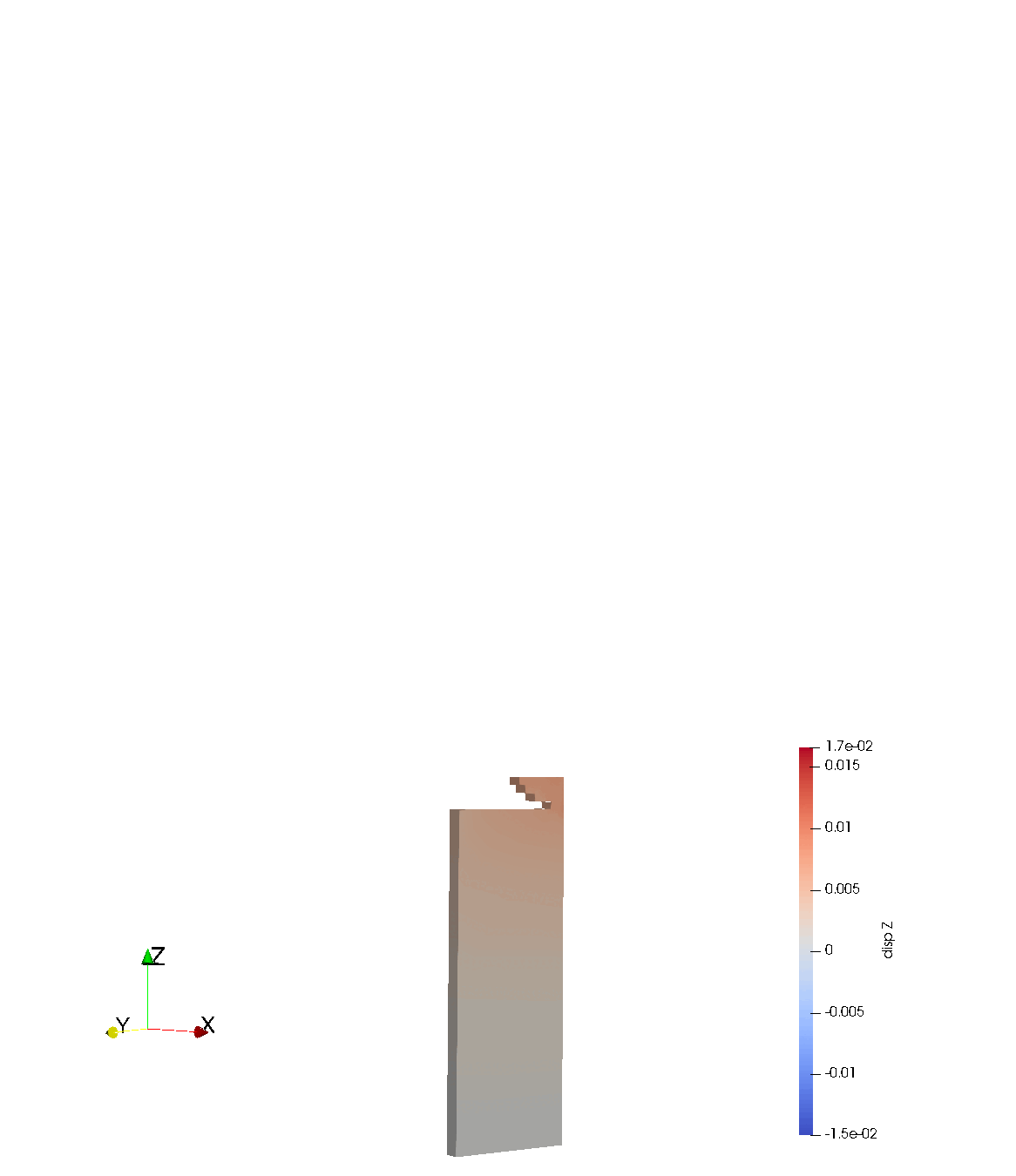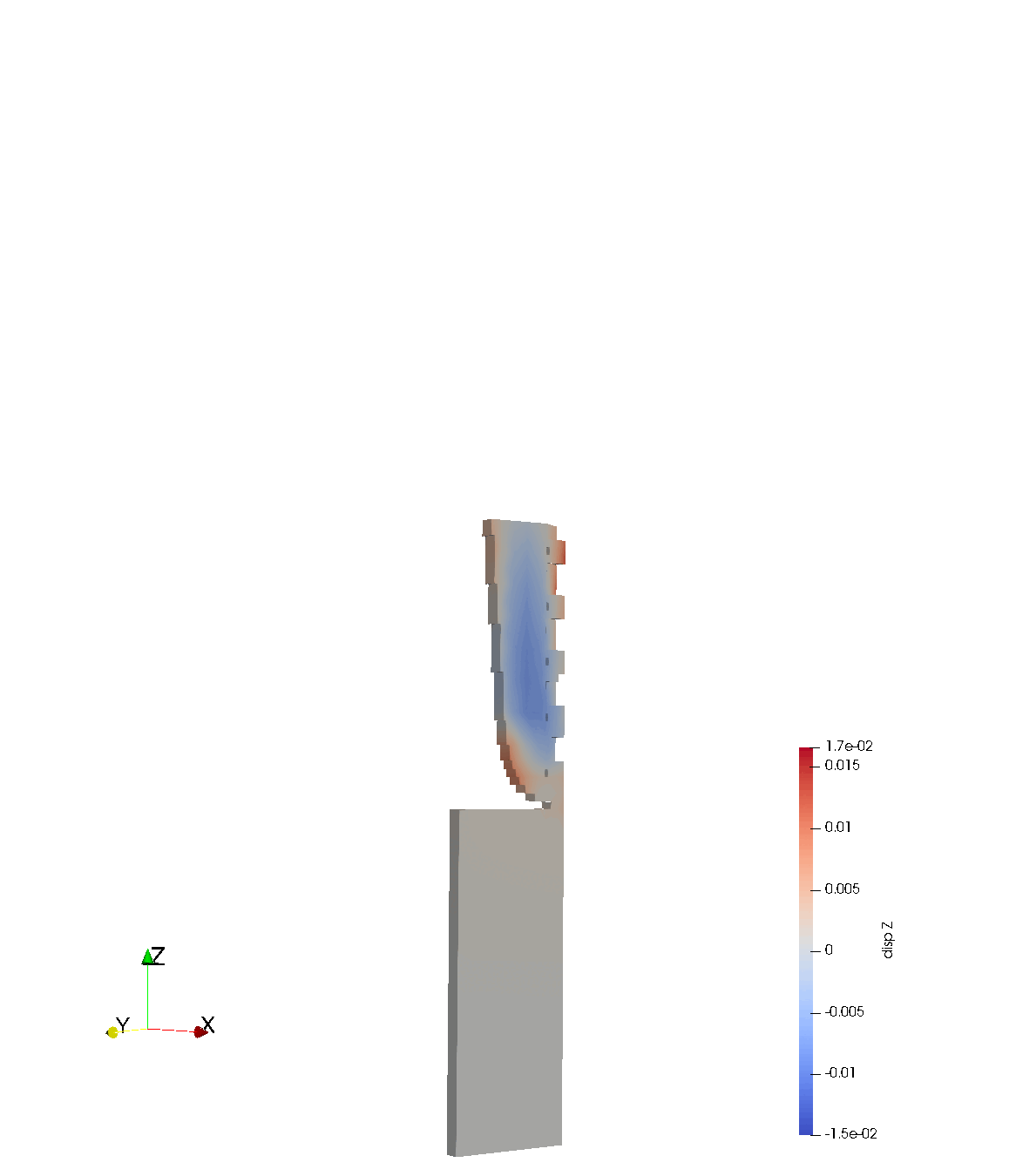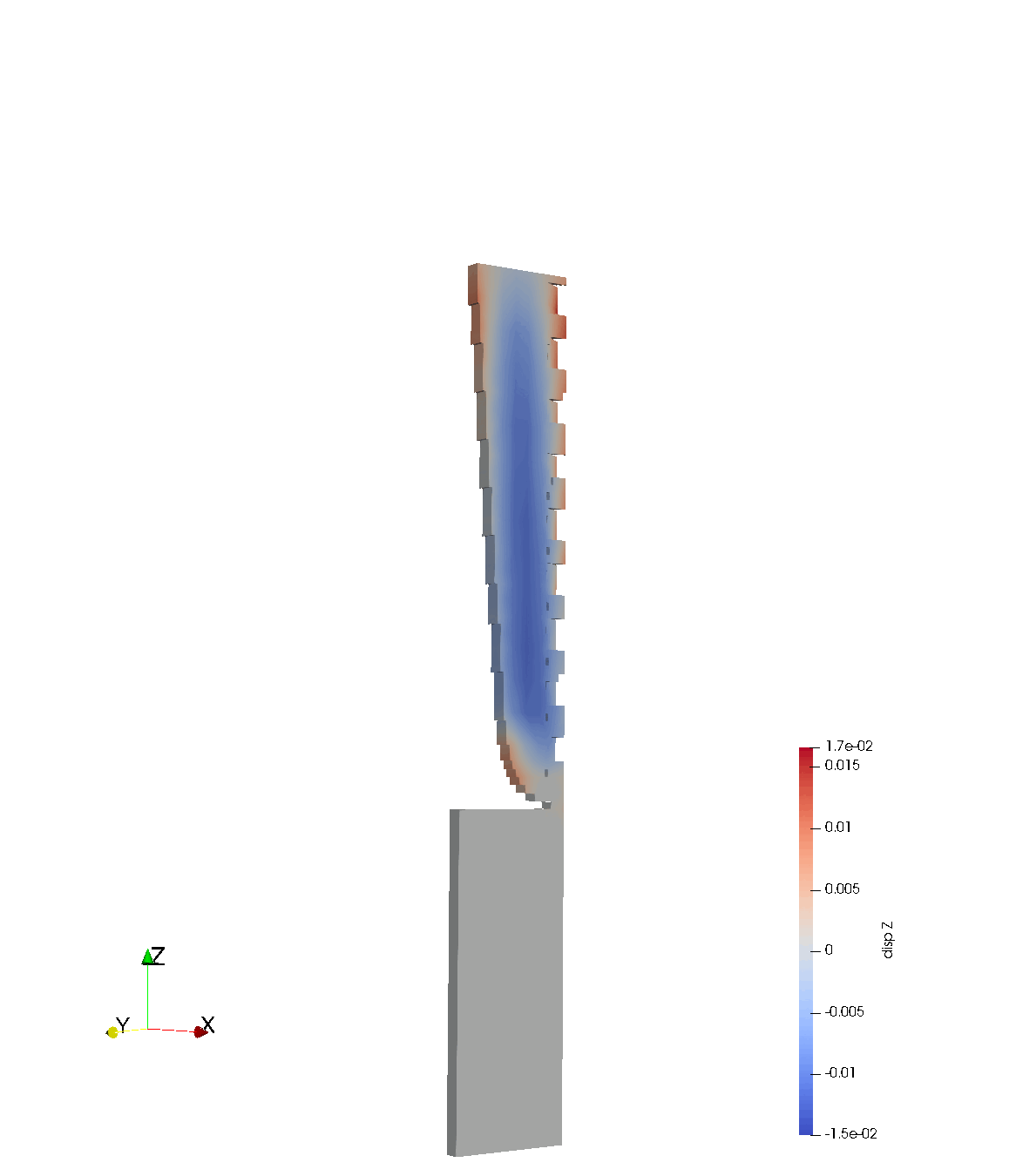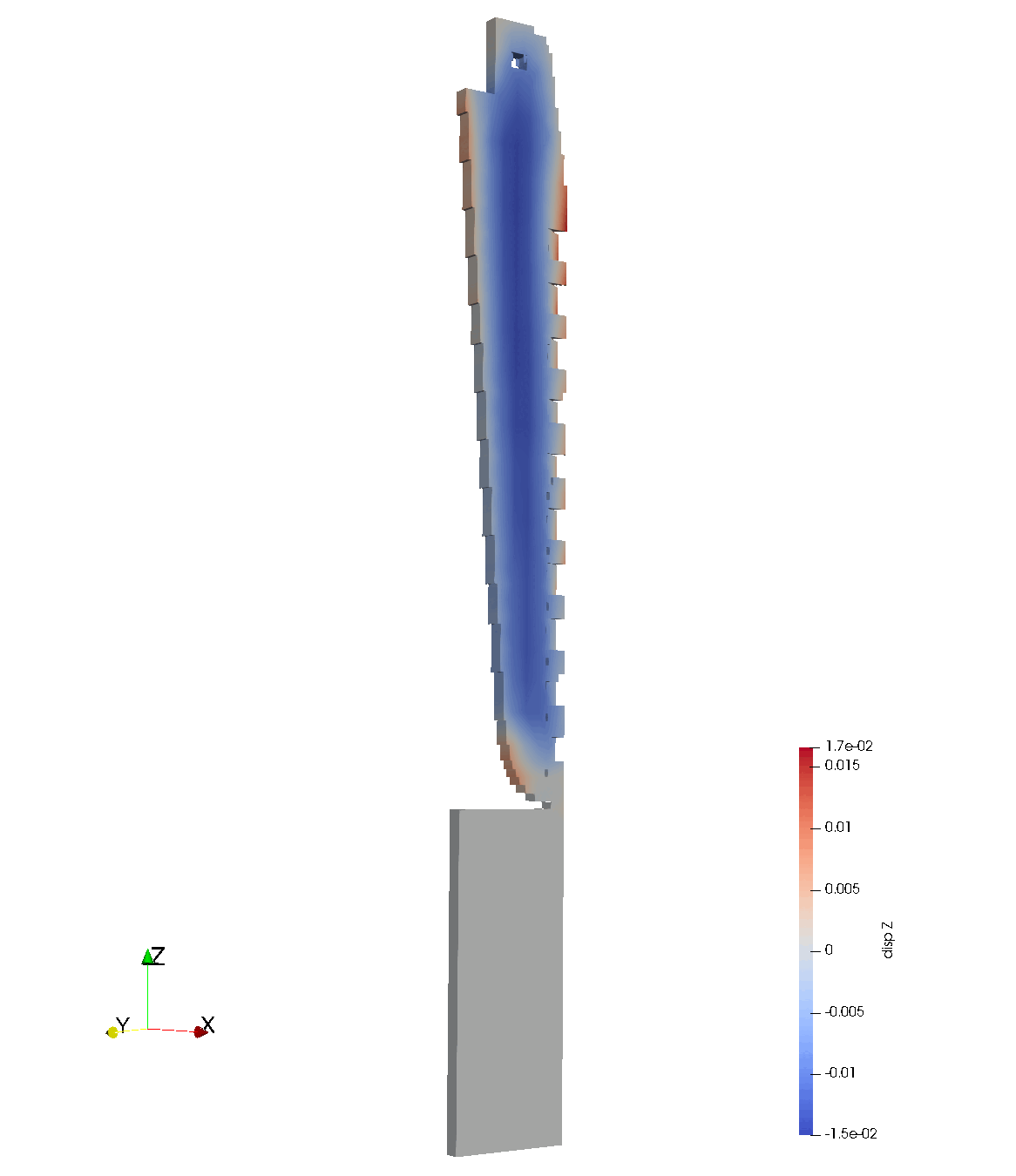


Vedant Puri
PhD student at Carnegie Mellon University
Vedant Puri
DEC 04, 2025
1
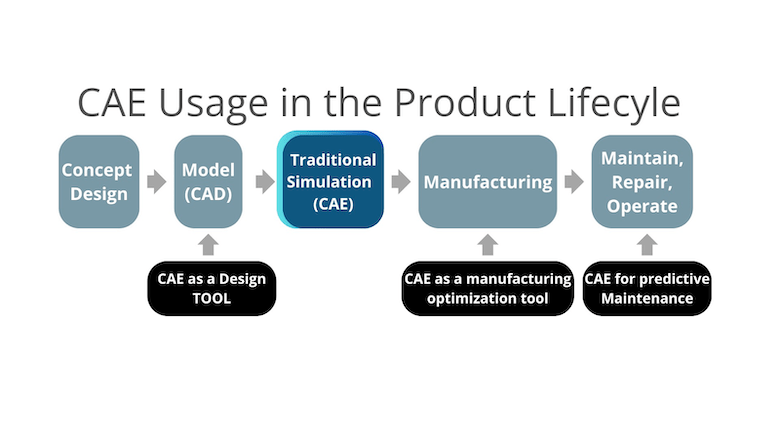
Predictive maintenance
Design space exploration
[2]
[1]
[3]
[1] CFD Direct / OpenFOAM – “OpenFOAM HPC on AWS with EFA”, cfd.direct
[2] EurekAlert — “New concrete system may reduce wind-turbine costs”
[3] Flow-3D, “FLOW-3D AM” product page, flow3d.com
Process optimization
[1]
2
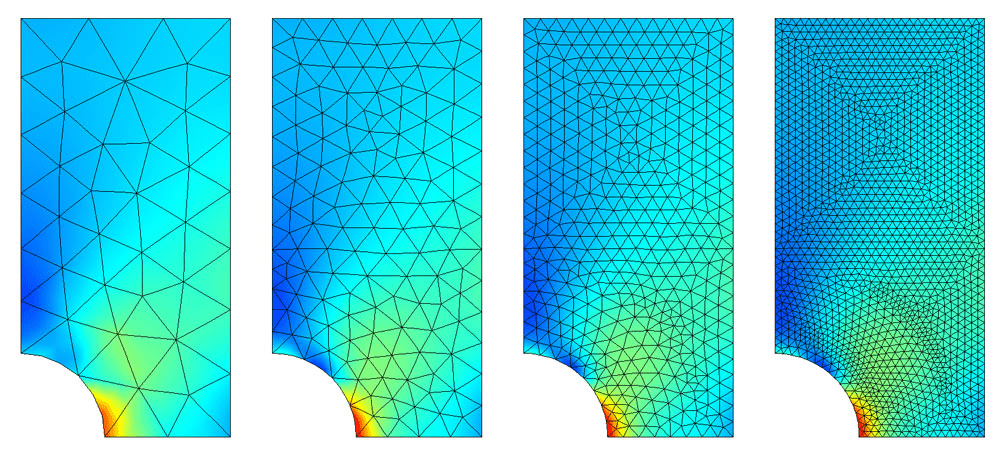
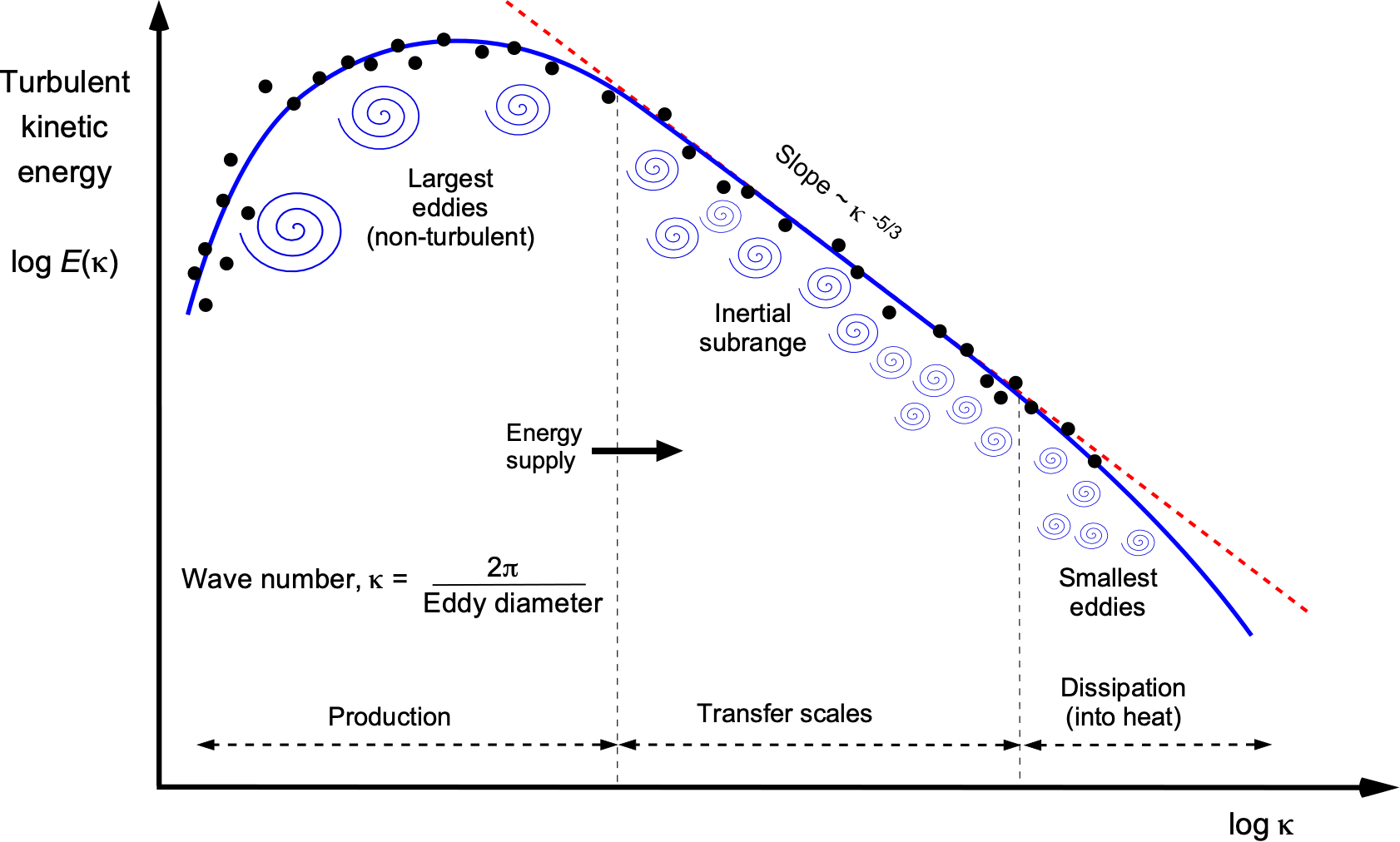
[1] COMSOL — “Mesh Refinement”
[2] Langtangen, H. P. — INF5620: Finite Element Methods (Lecture Notes)
[3] GridPro Blog — “The Art and Science of Meshing Airfoil”
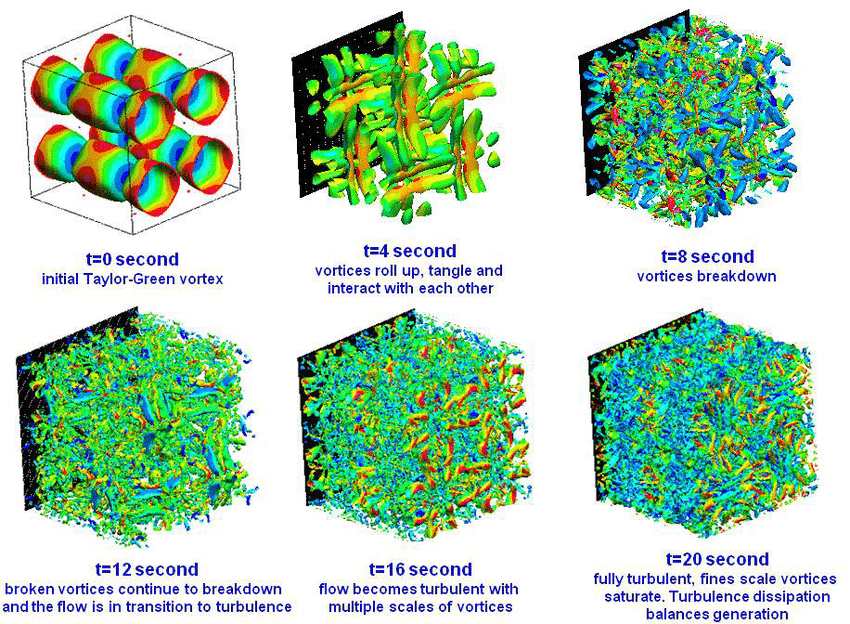
[4] ResearchGate — “Transition to turbulence of Taylor-Green Vortex at different time (DNS)” (figure)
[5] ORNL / U.S. Department of Energy — “DOE and Cray deliver record-setting Frontier supercomputer at ORNL”
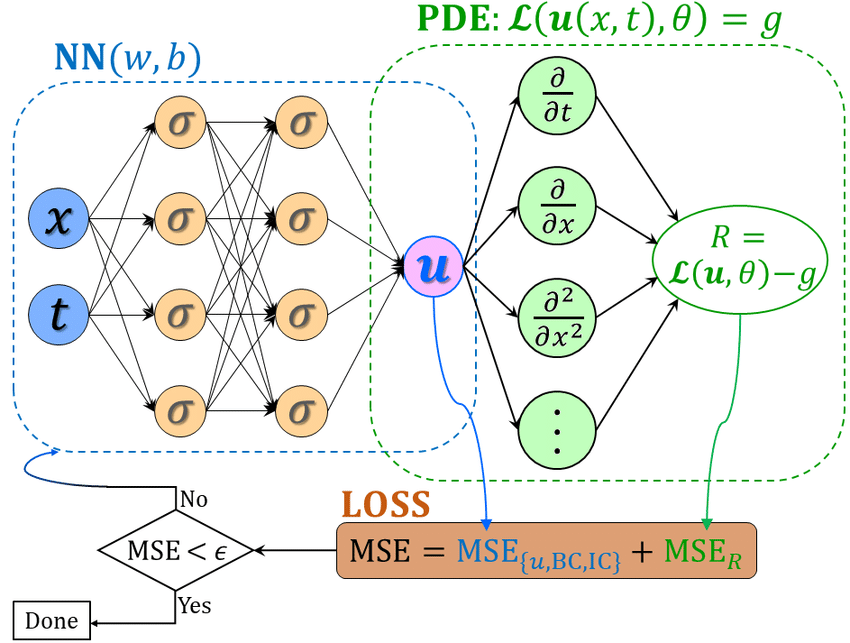
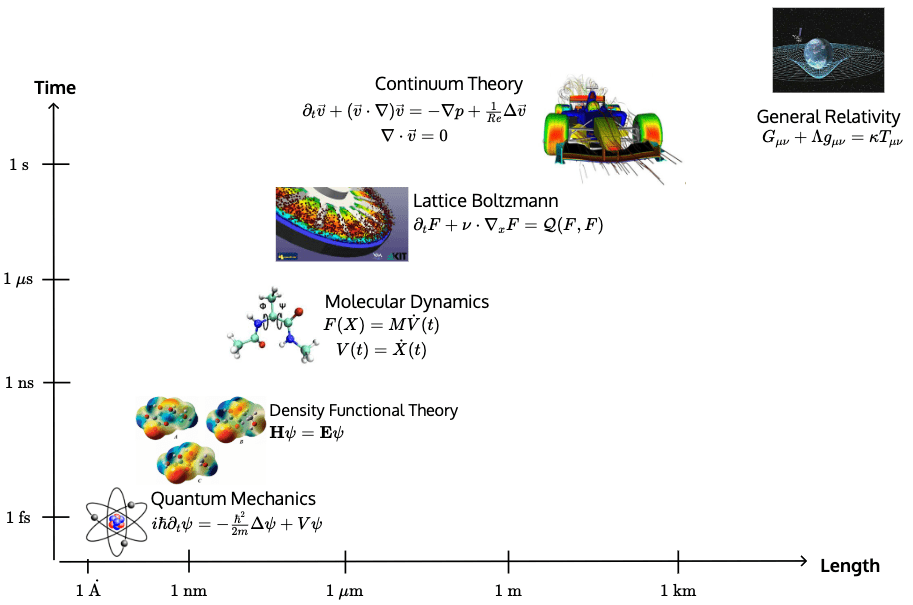
Governing Equations
[1]
[2]
Discretization machinery
Repeated large system solves
[5]
Multiscale physics \(\implies\) small \(\Delta t\)
[4]
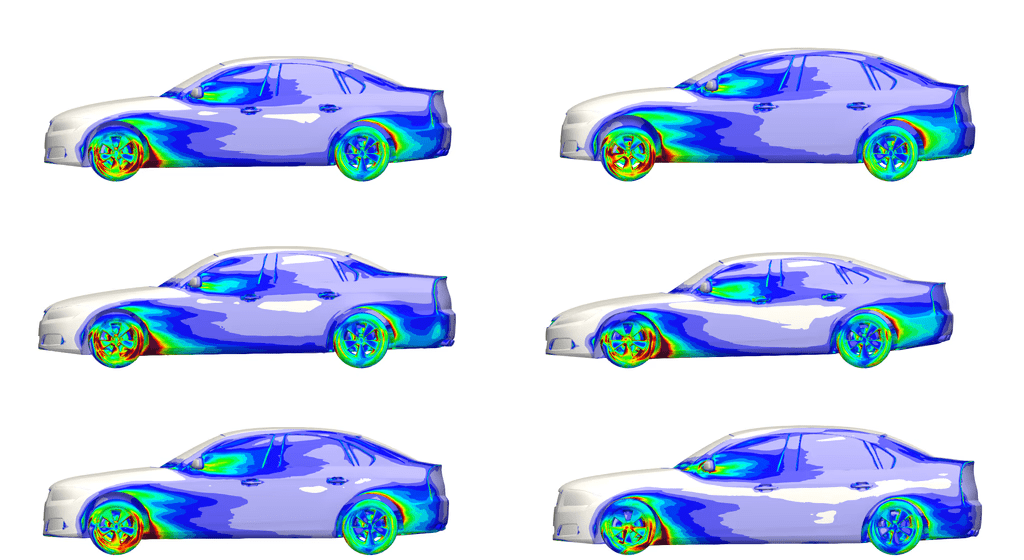
Complex geometry \(\implies\) fine meshes
[3]
Complex geometry \(\implies\) fine meshes
The cost of this procedure scales poorly for several reasons.
3
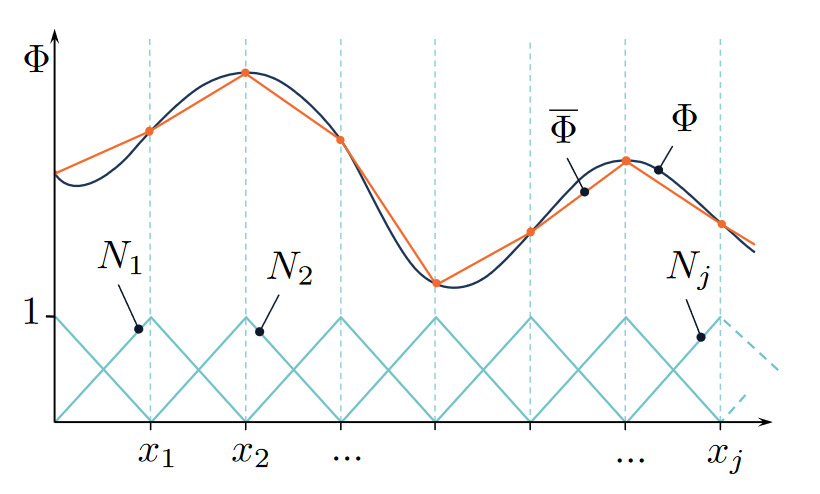
(Explicit) Weighted sum of polynomial interpolants
[1]
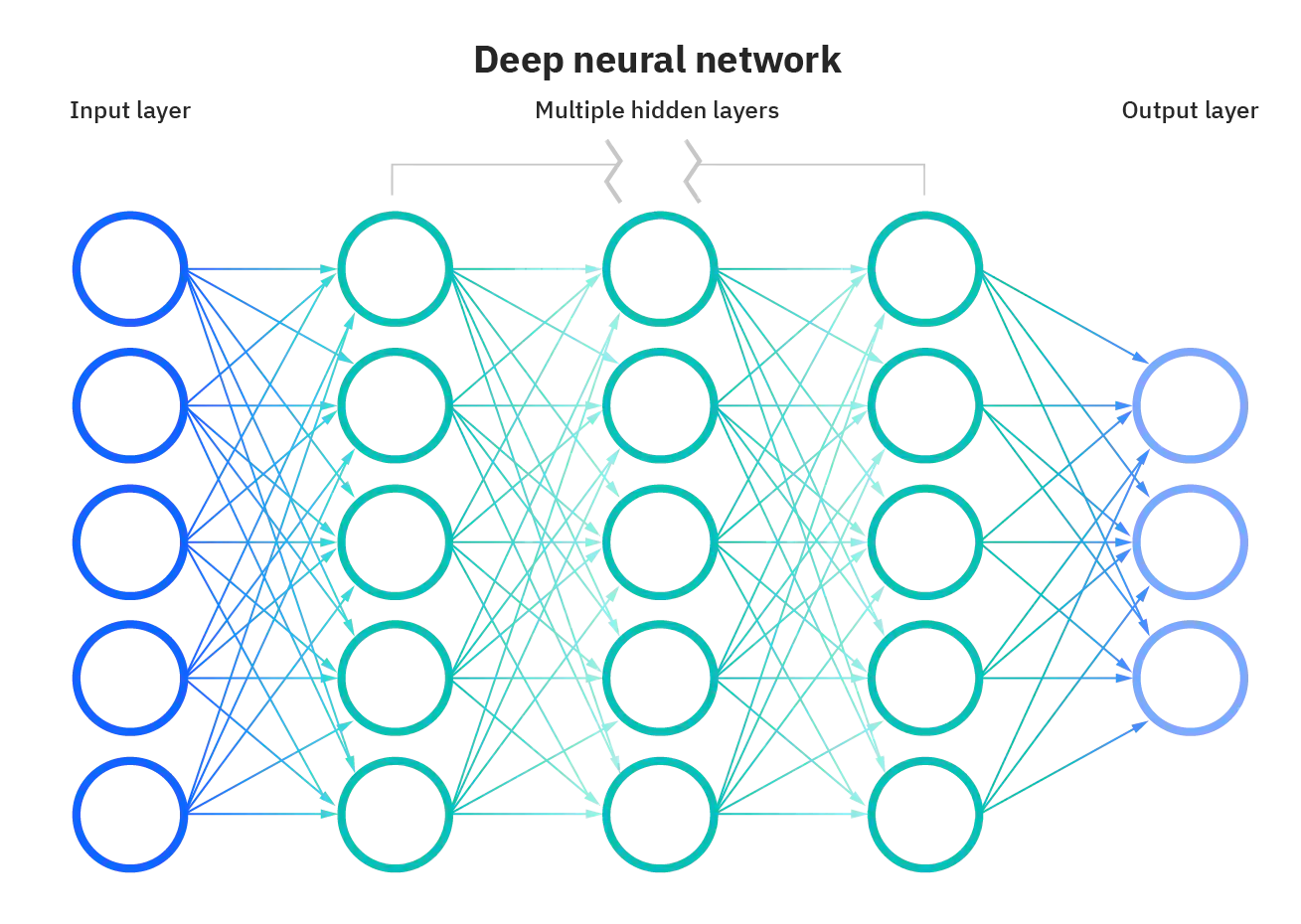
(Implicit) High-dim nonlinear feature learners
[2]
Cannot learn from data
Can learn from data
Large cost per simulation
Cheap evaluation after training
High-accuracy
Problem-specific
Robust
Up to \(0.1\%\) accuracy
[1] Math StackExchange — “Interpolation in Finite Element Method”
[2] ResearchGate — “Structure of a Deep Neural Network” (figure)
\(\text{Mesh ansatz}\)
\({u}(x)=\)
\(u(x) = \)
\(\text{Neural ansatz}\)
\(\text{Physics-based}\)
\(\text{Data-driven}\)
\(\text{Numerical}\)
\(\text{Simulation}\)
\(\text{Reduced Order}\)
\(\text{Modeling}\)
\(\text{Neural ROMs}\)
\(\text{Surrogate}\)
\(\text{Learning}\)
\(\text{Transformers}\)
\(\text{PINNs}\)
\(\text{Finite Elements}\)
\(\text{PCA/POD}\)
\(\text{Graph Networks}\)
Fast and accurate latent space traversal in neural ROMs
4
Scalable transformer models for large-scale surrogate modeling
[1]
[3]
[2]
[1] CFD Direct / OpenFOAM — “Introduction to Computational Fluid Dynamics”
[2] ResearchGate — “Schematic of a Vanilla Physics-Informed Neural Network” (figure)
[3] Kutz, J. N. — “Data-Driven Modeling & Dynamical Systems” (UW)
5
Accelerate PDE solves with structure learned from data.
Replace simulation with solution operator learned from data.
Extend surrogate methodology to transient PDE problems.
6
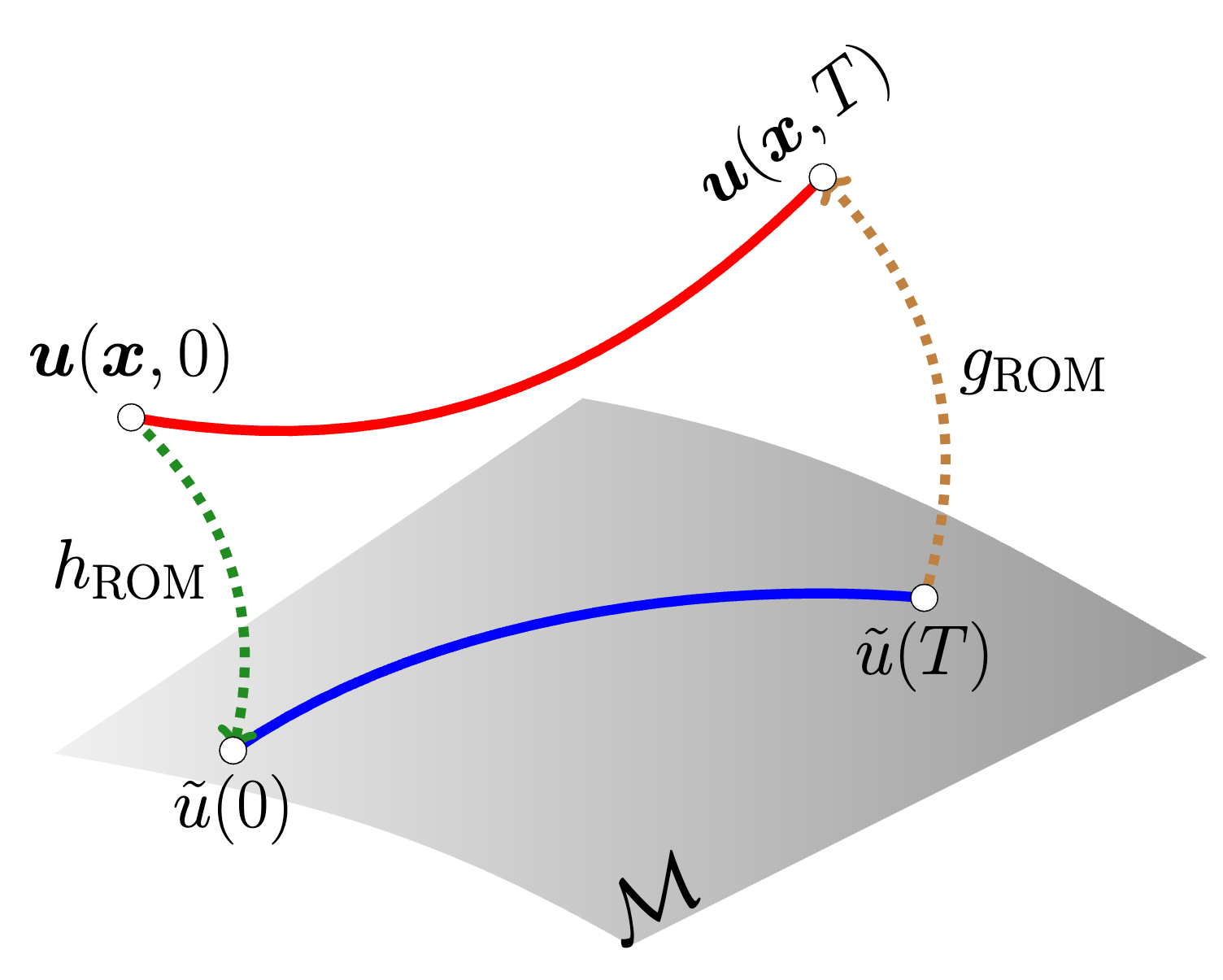
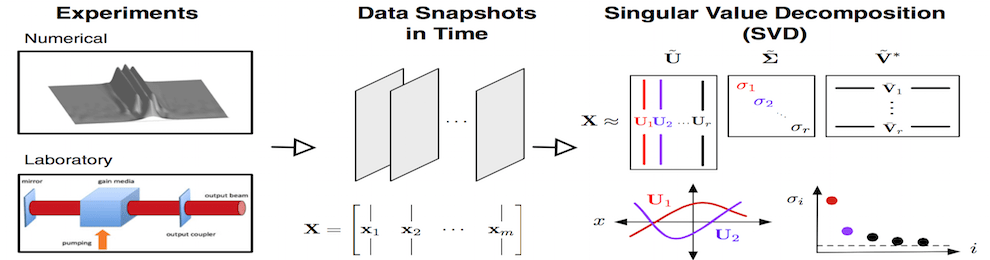
High-dimensional simulation data
Collect and compress data
Evolve ODE on low-dim manifold
Cheap online solve can be deployed for time-critical applications.
Cost savings from solving smaller ODE system.
7
Full order model (FOM)
7
Full order model (FOM)
Linear POD-ROM
7
Full order model (FOM)
Linear POD-ROM
Nonlinear ROM
8
\(\text{Encoder}\)
\(\text{Decoder}\)
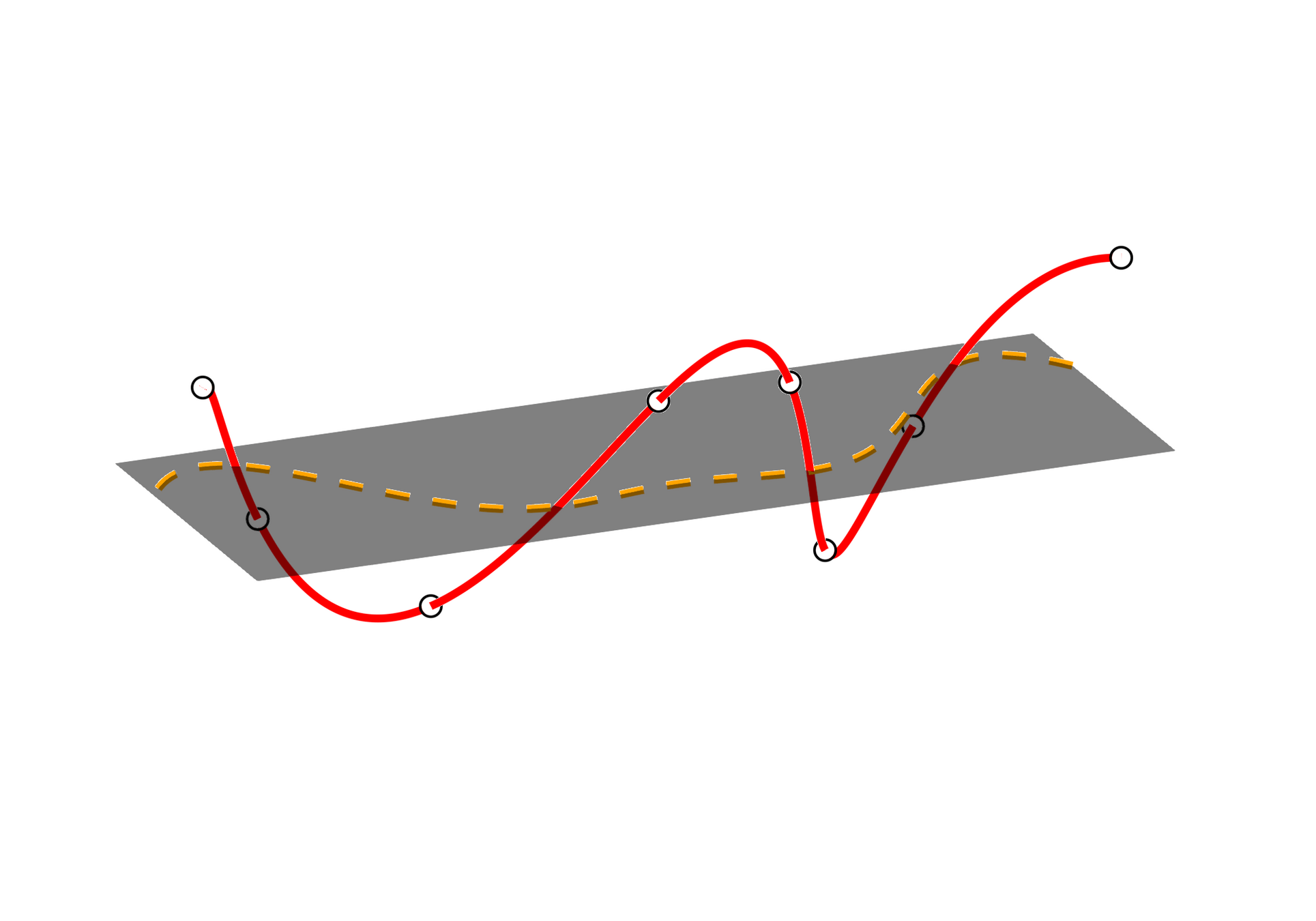
Intrinsic perspective
[1] Lee & Carlberg — Nonlinear manifold ROM via CNN autoencoders (JCP 2020)
Extrinsic perspective
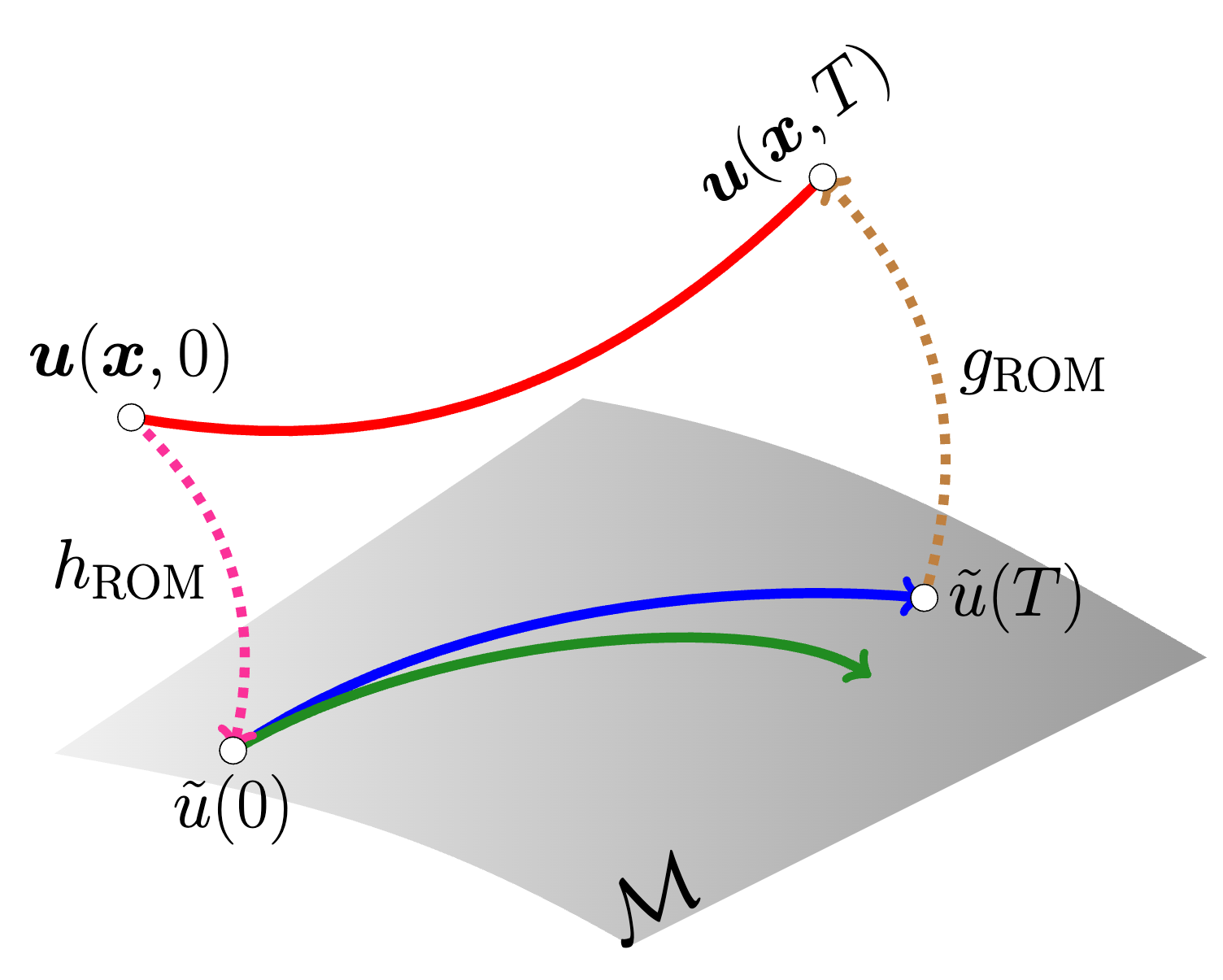
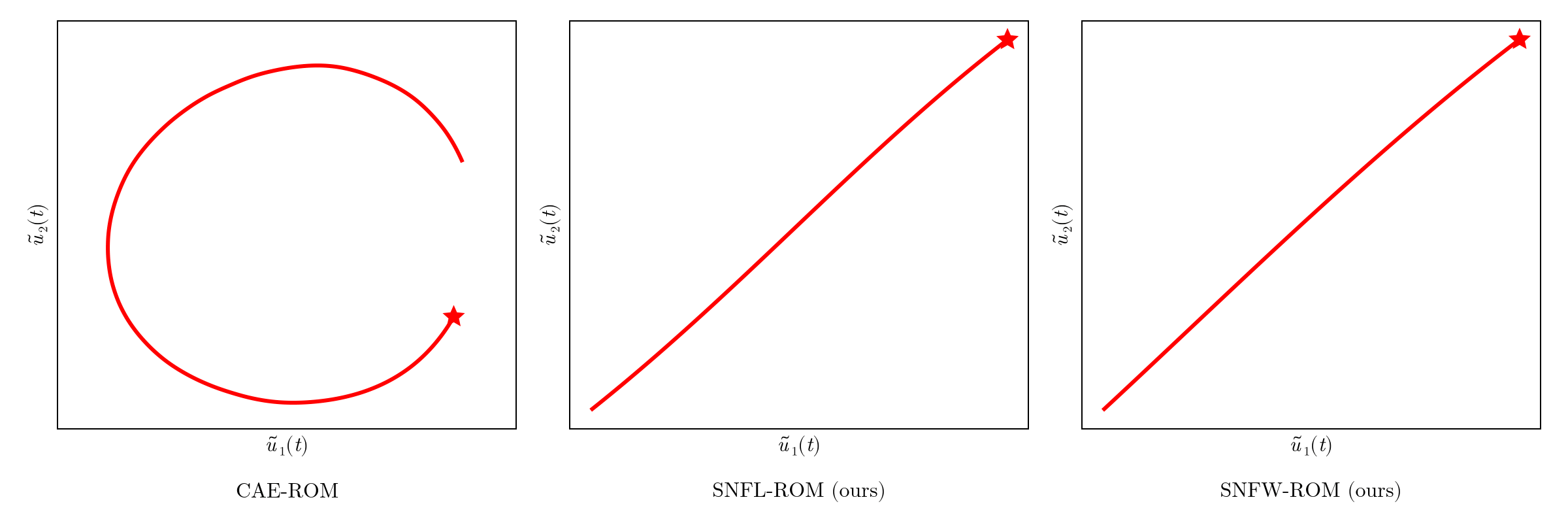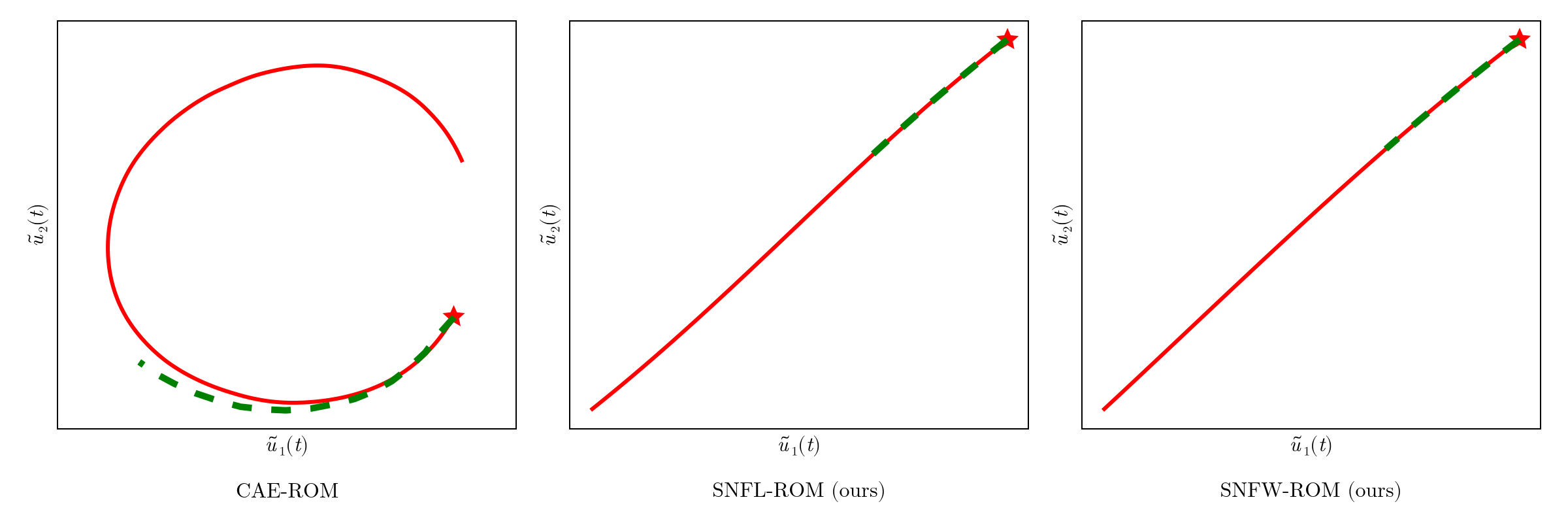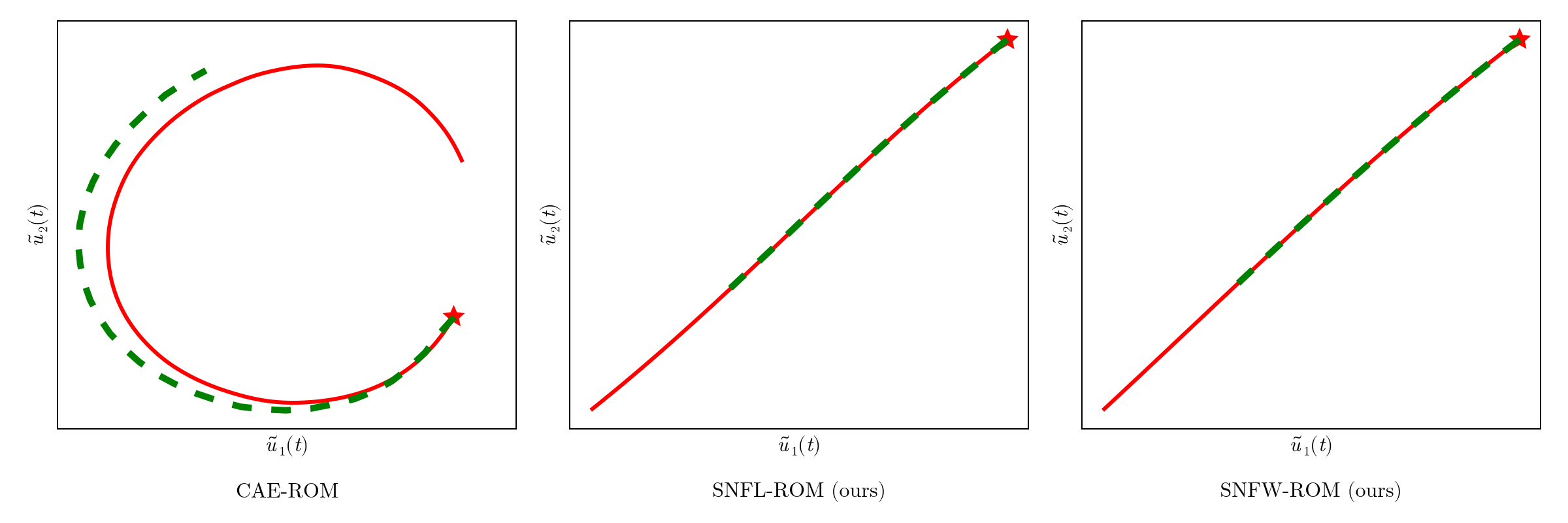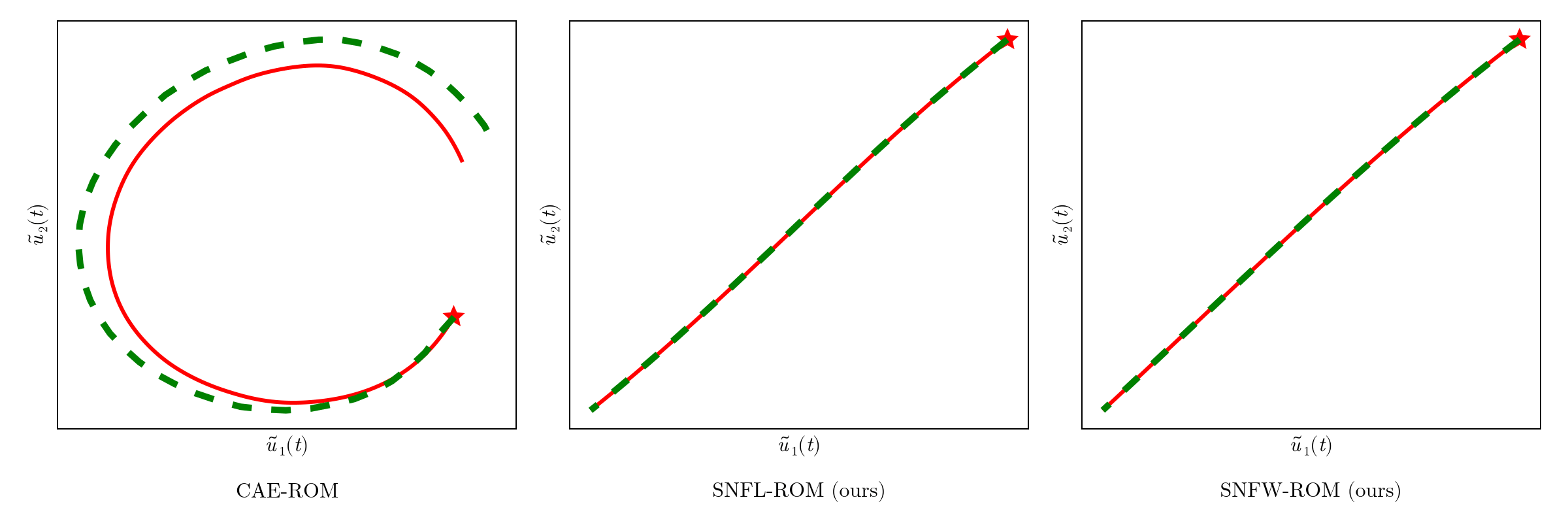
Compression/decompression workflow offers no control over latent trajectories.
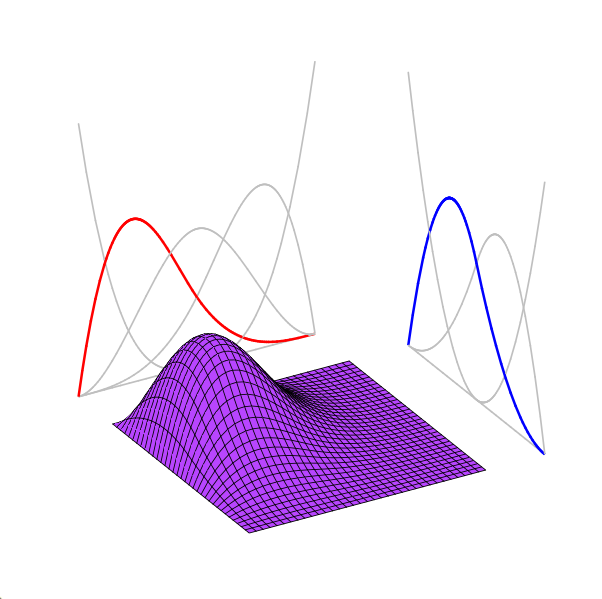
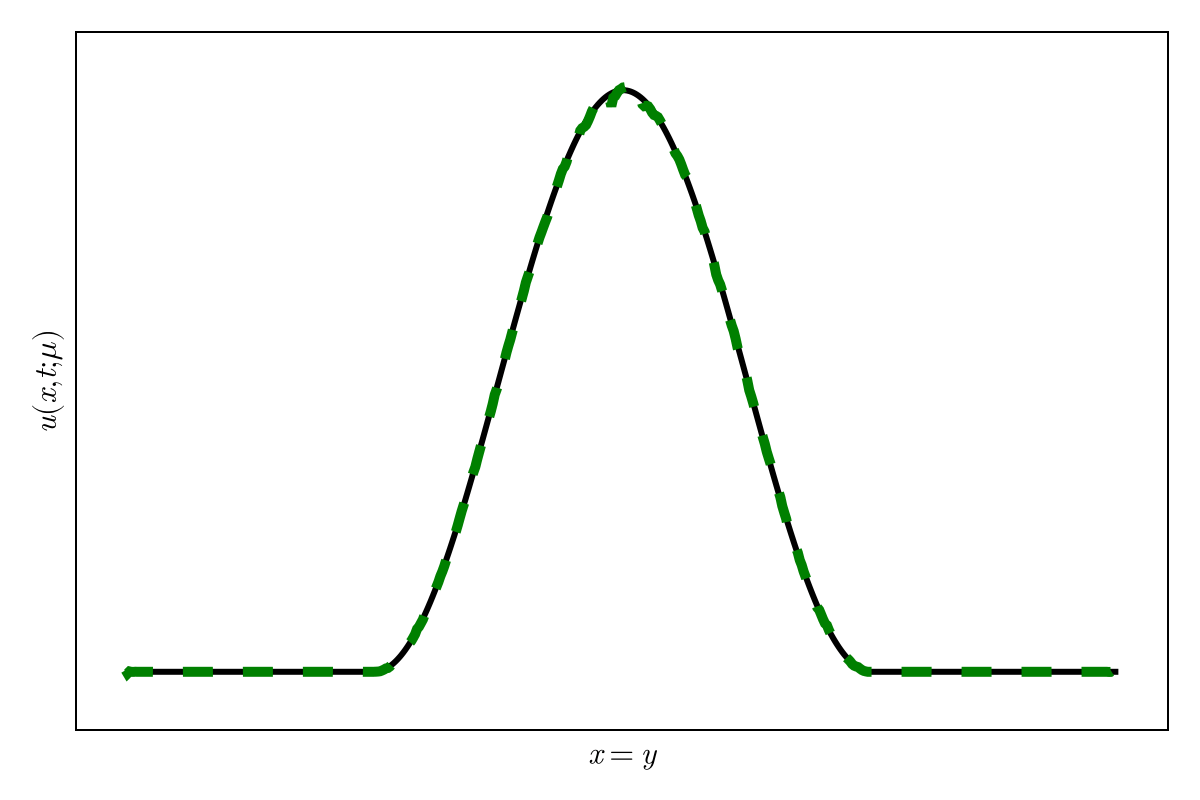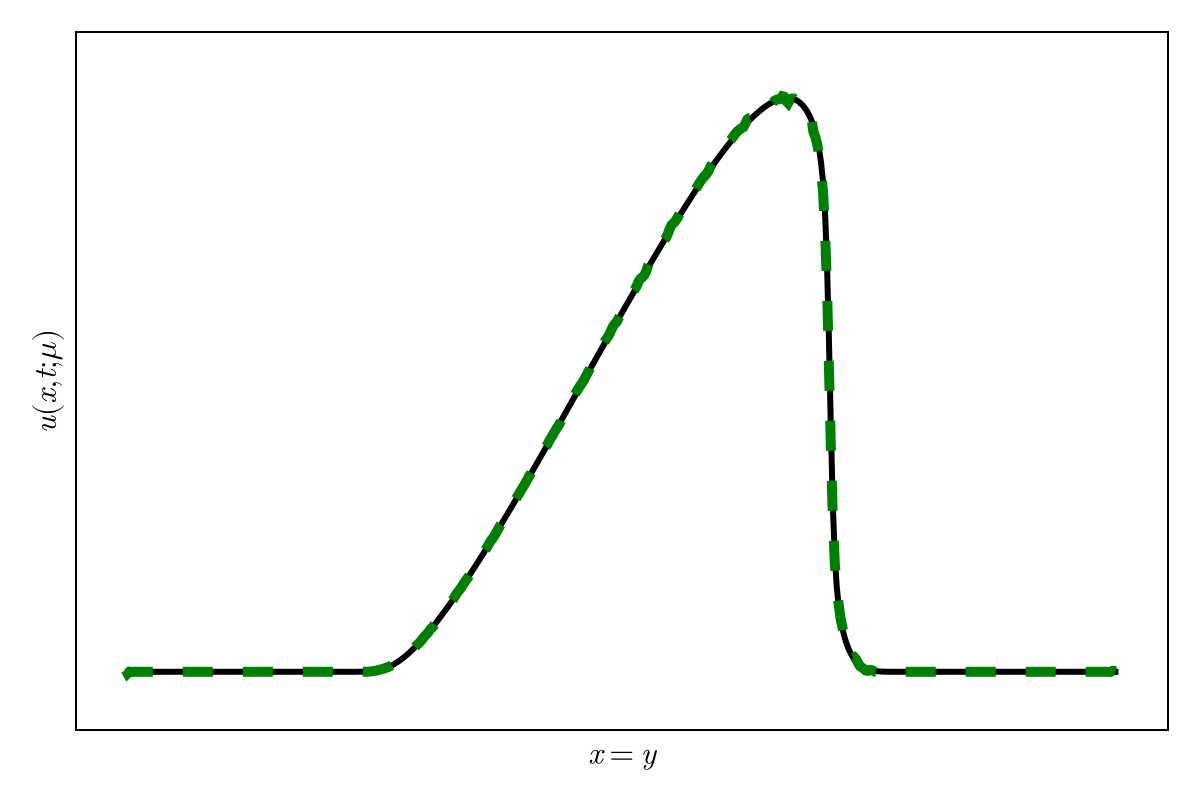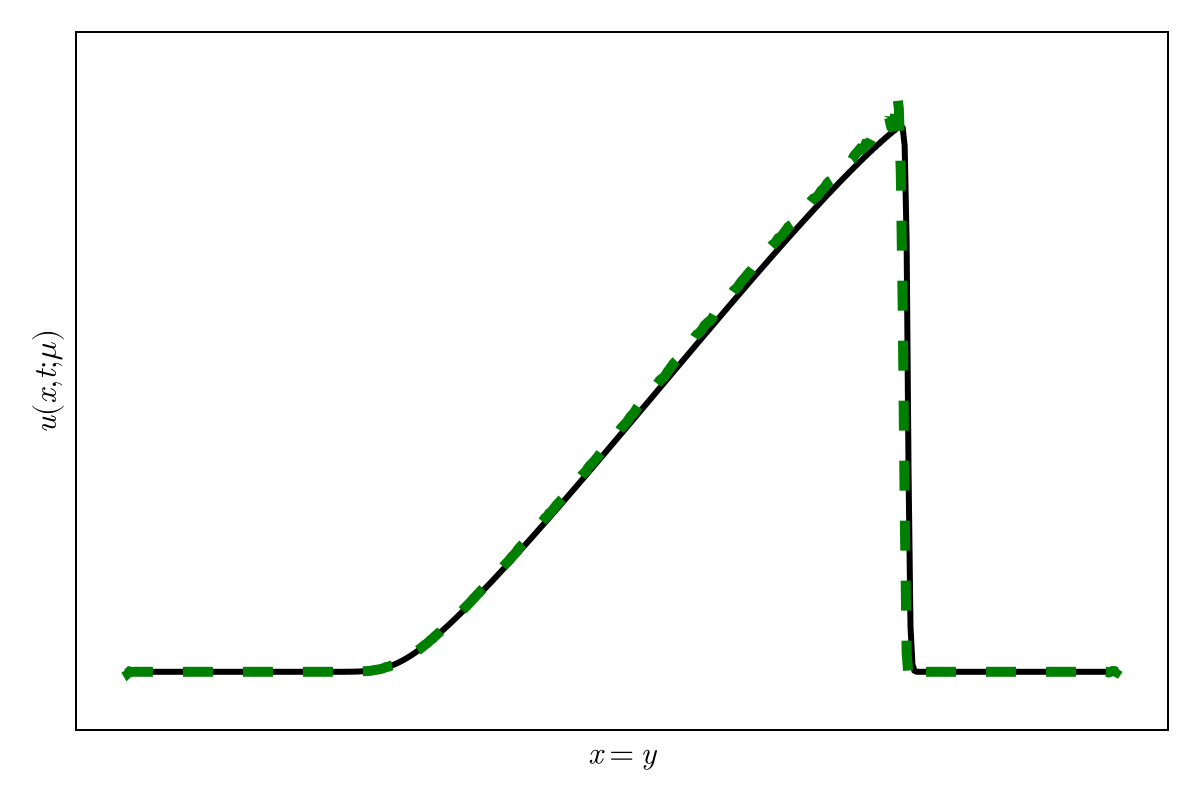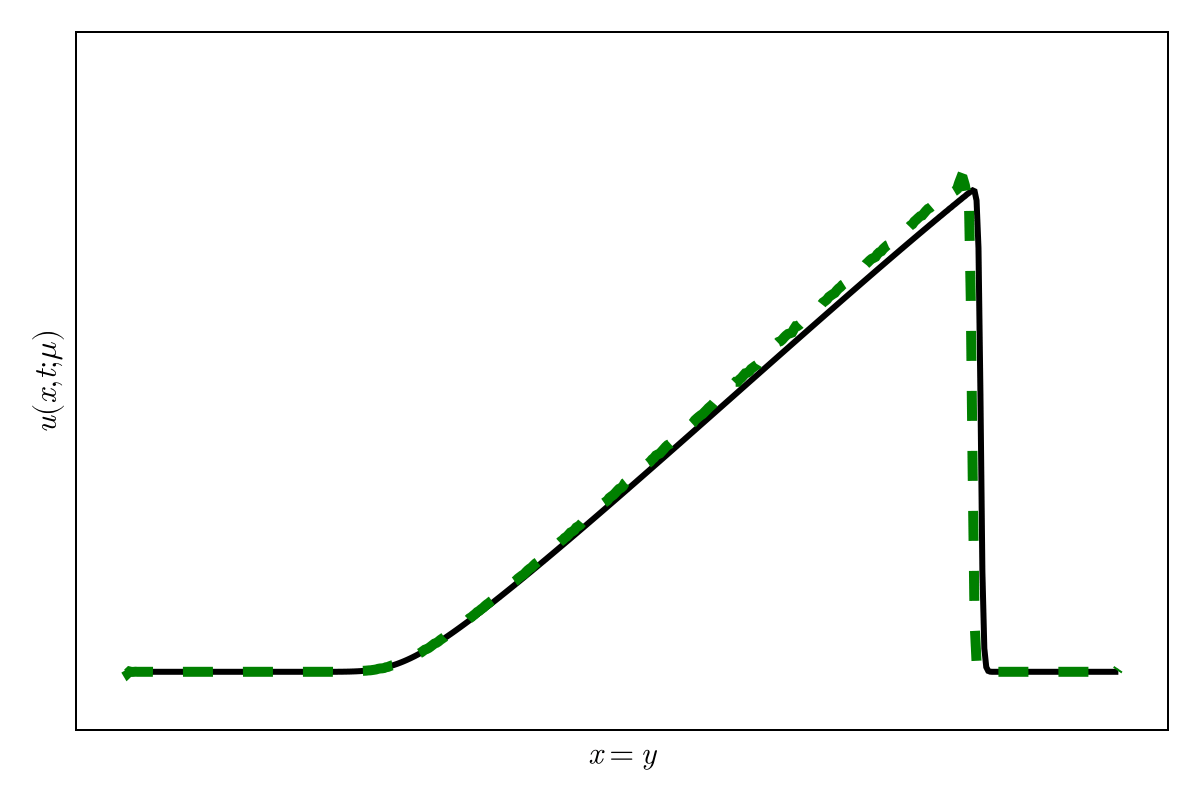
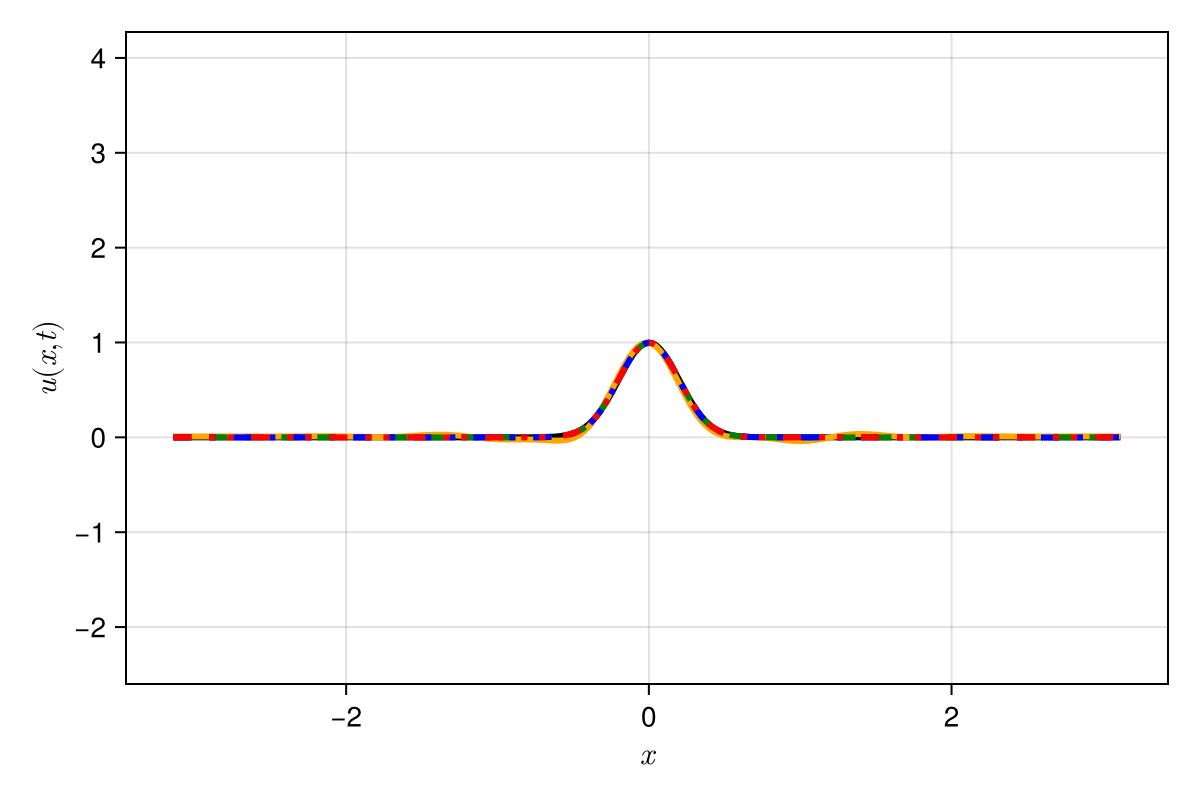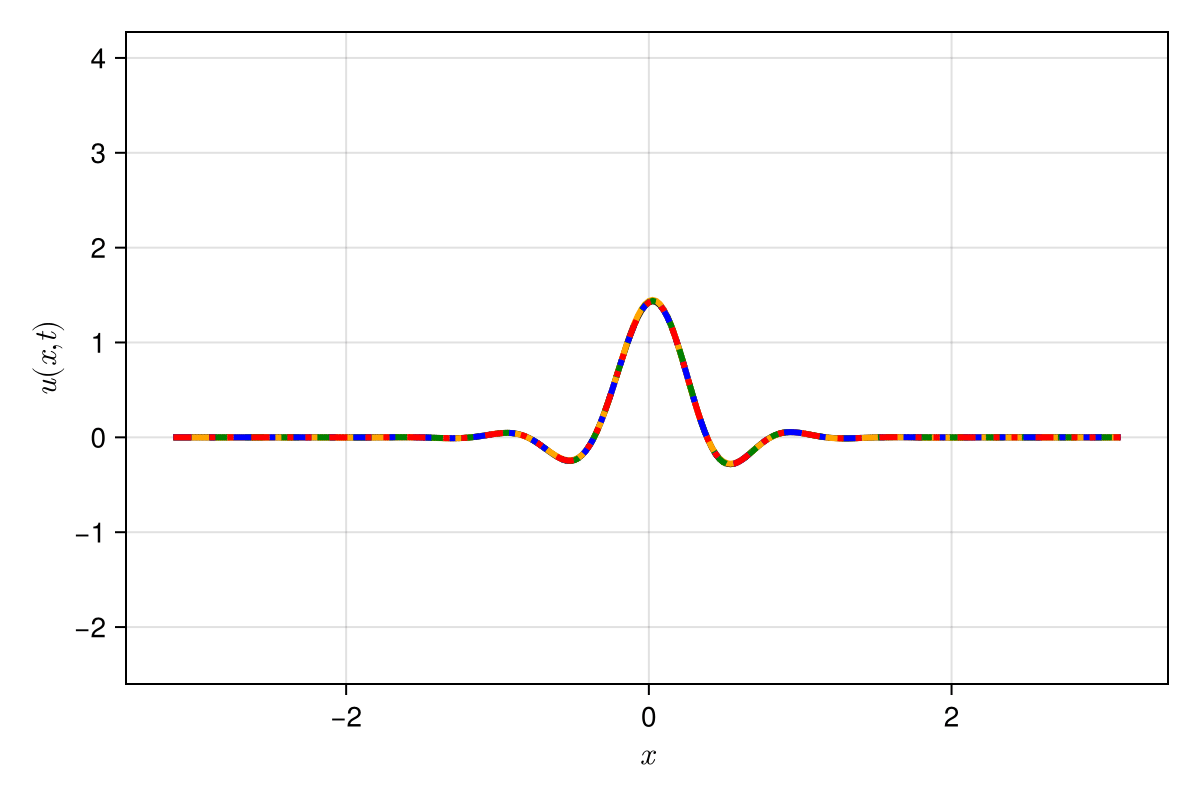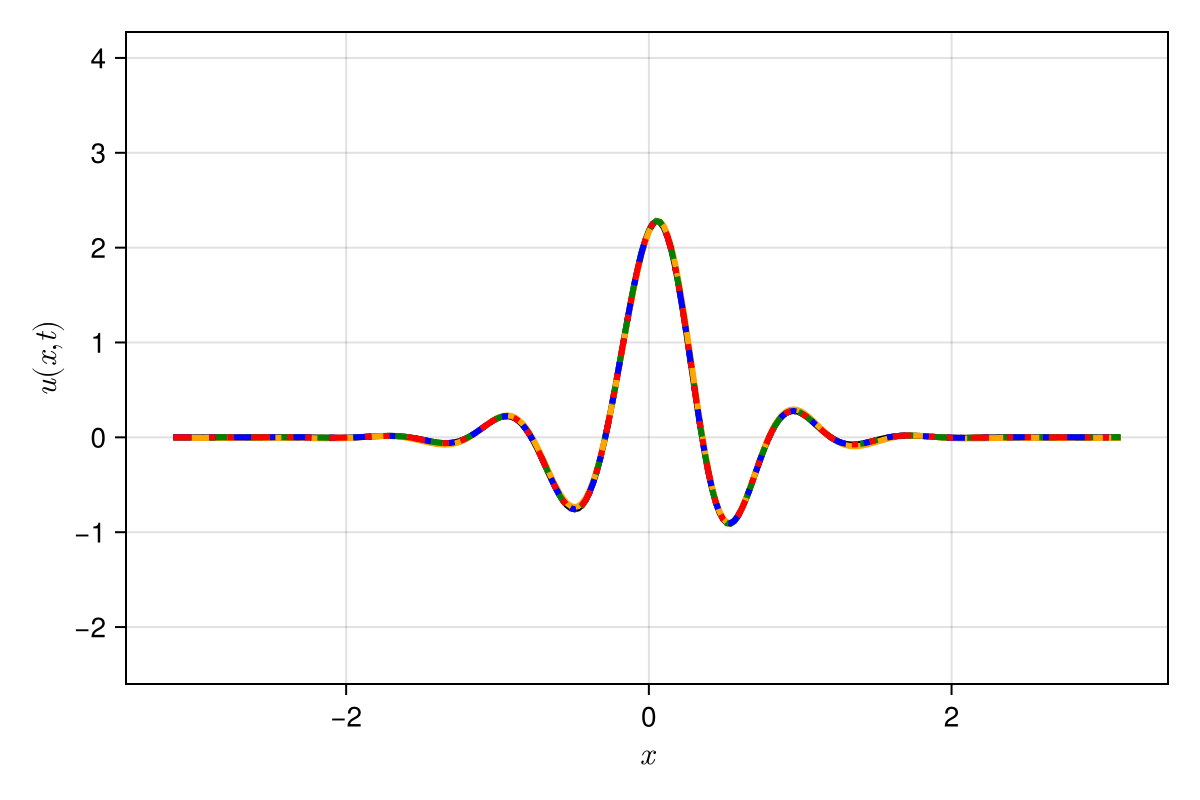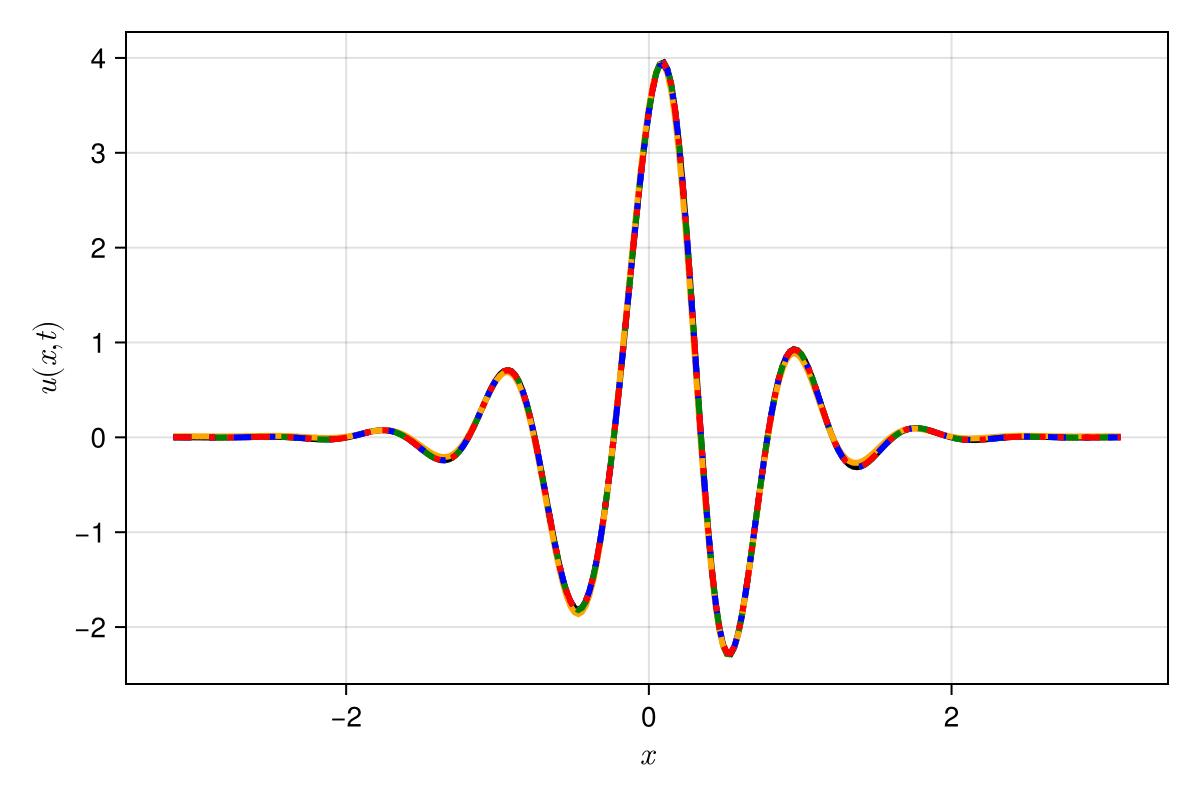
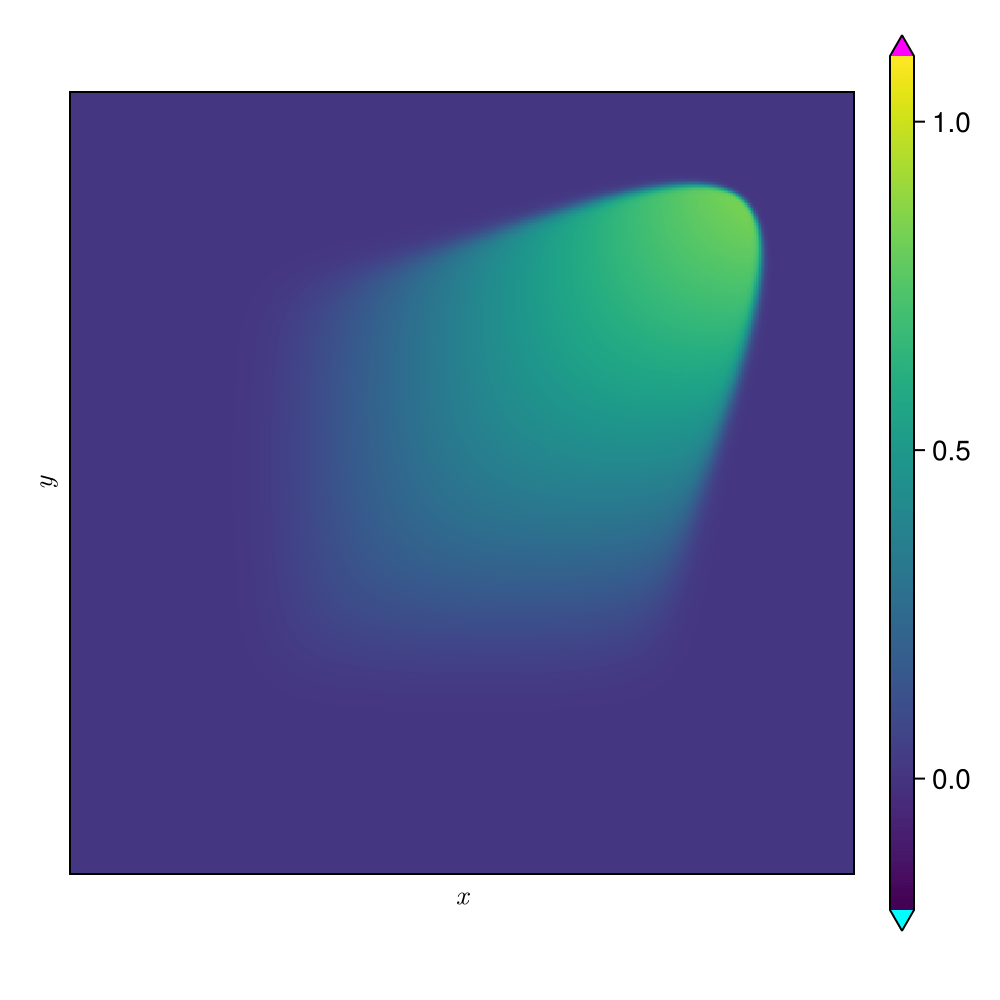
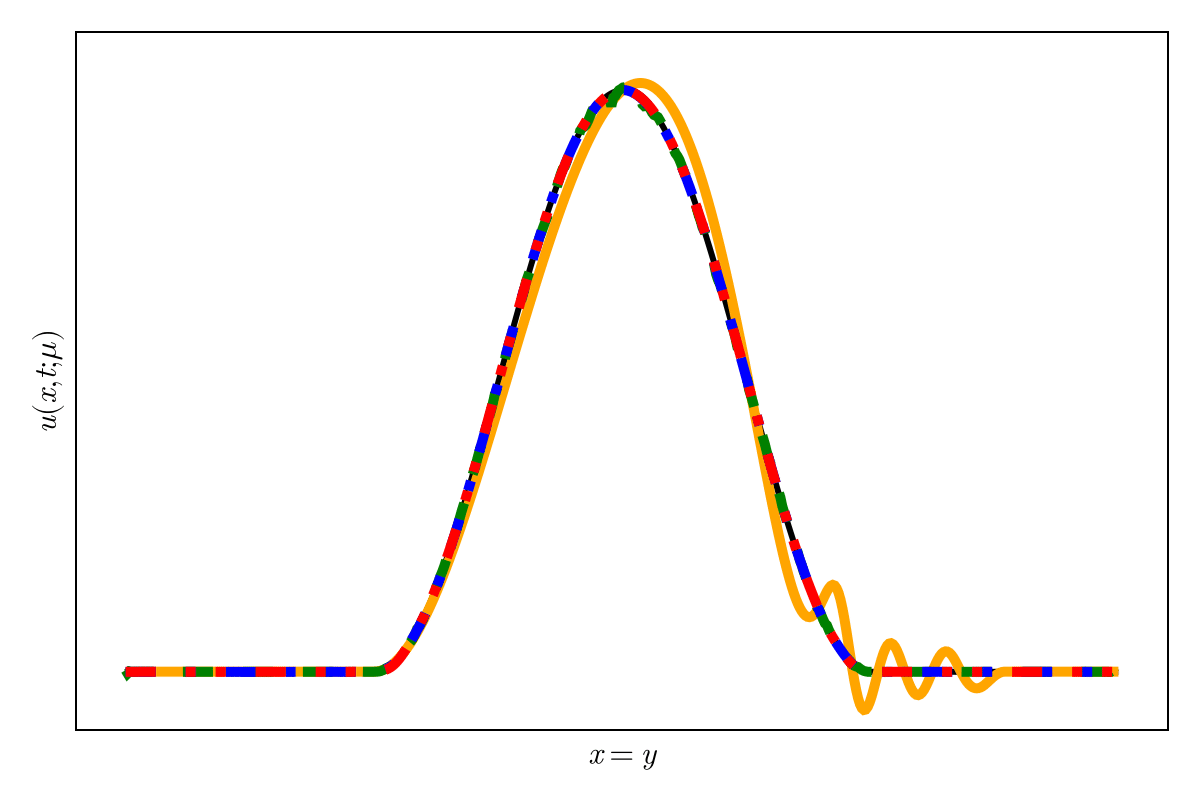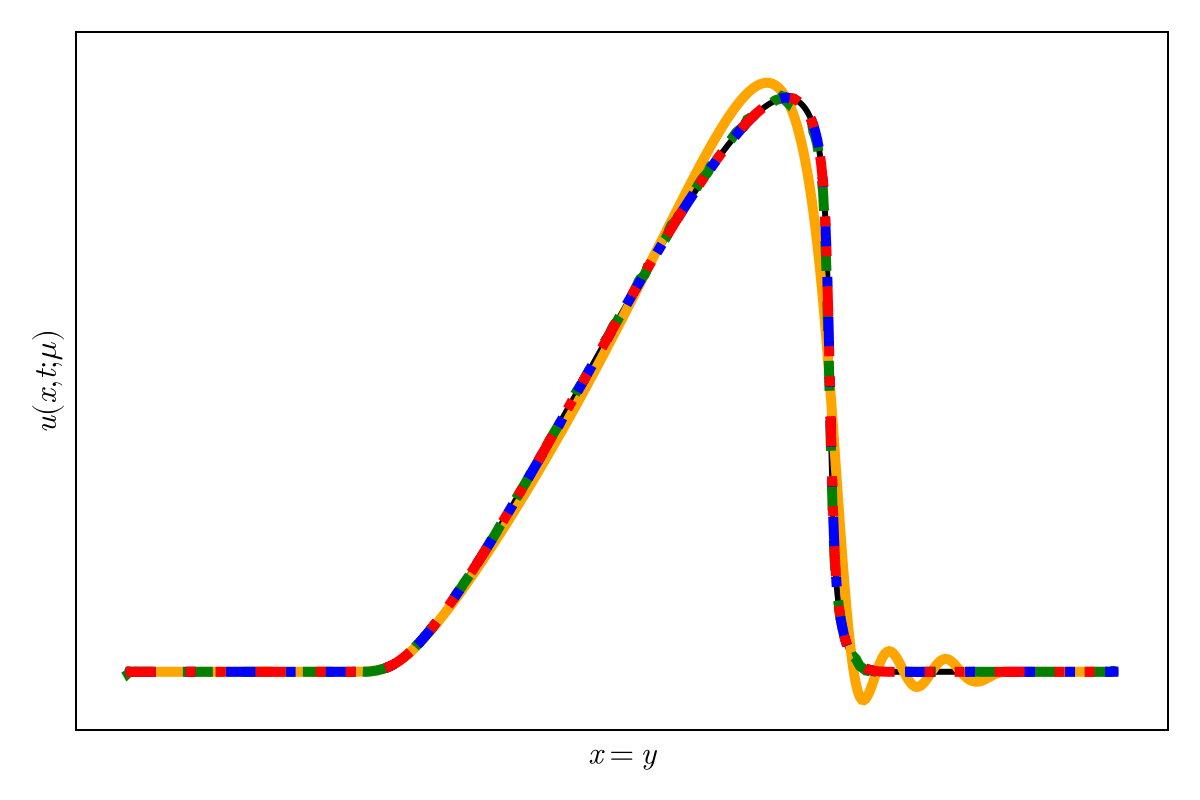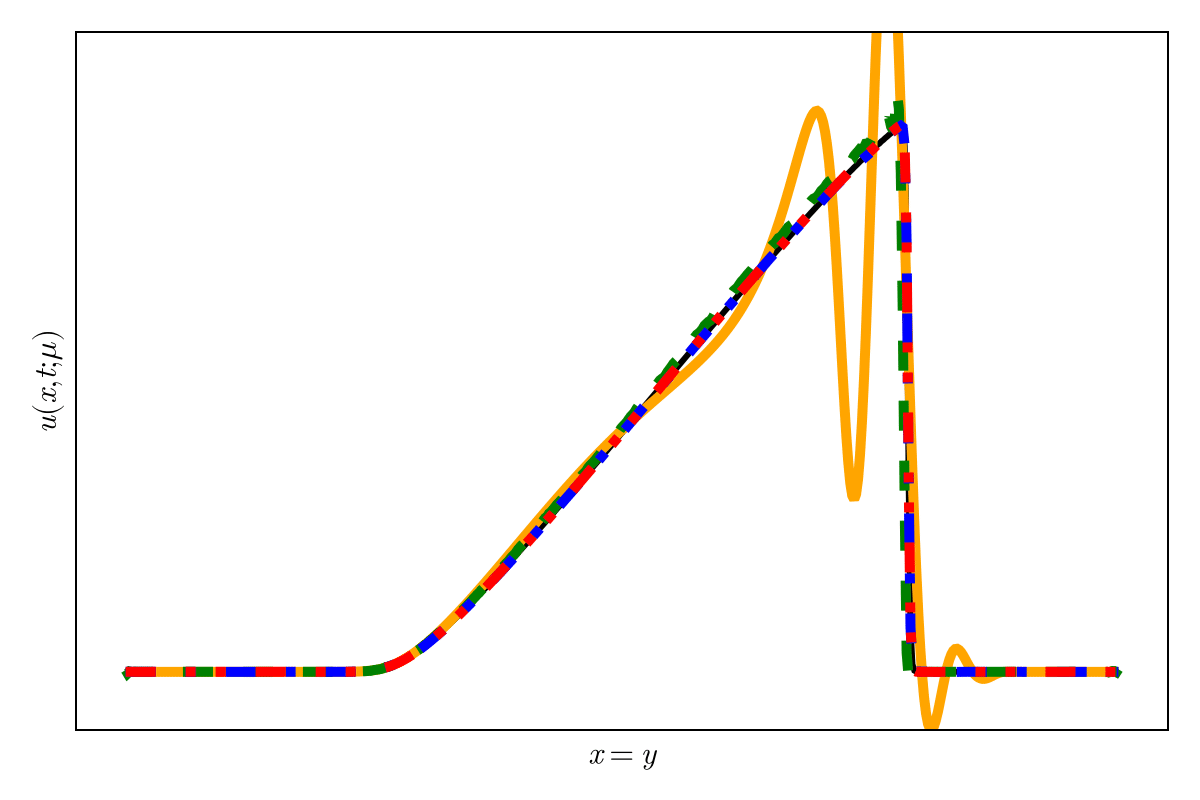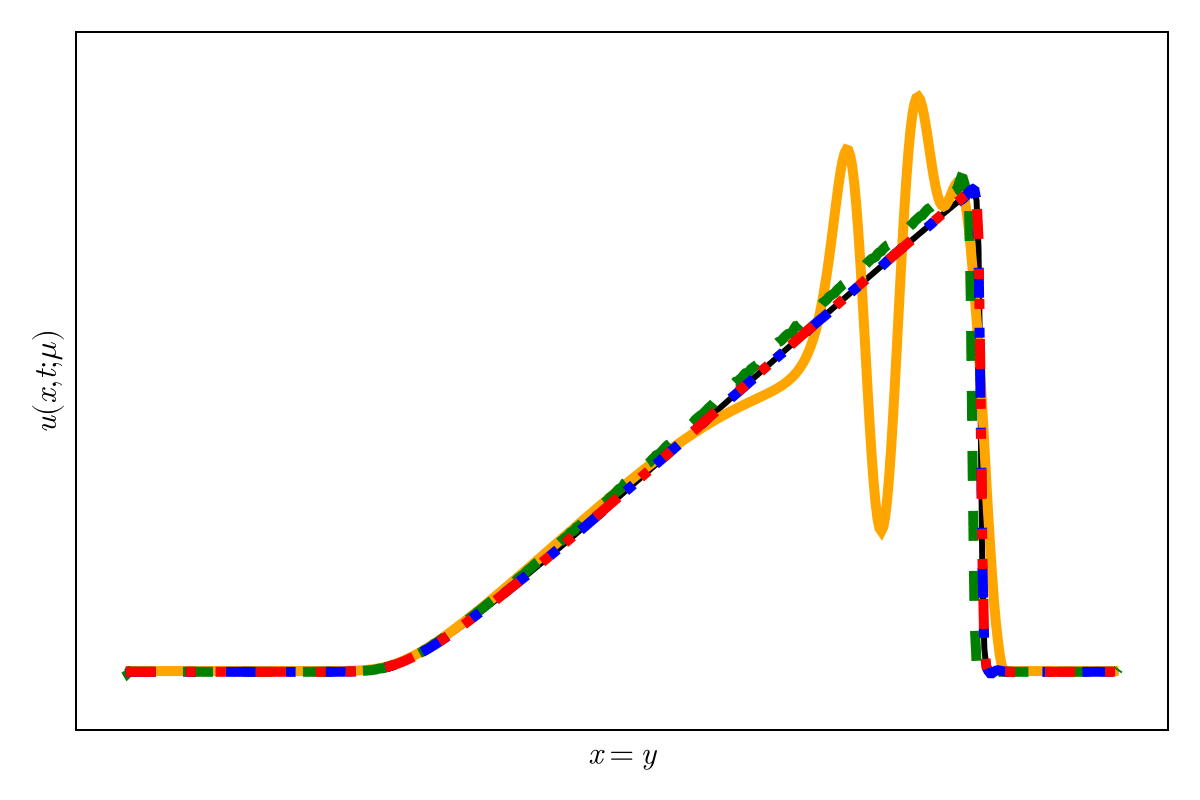
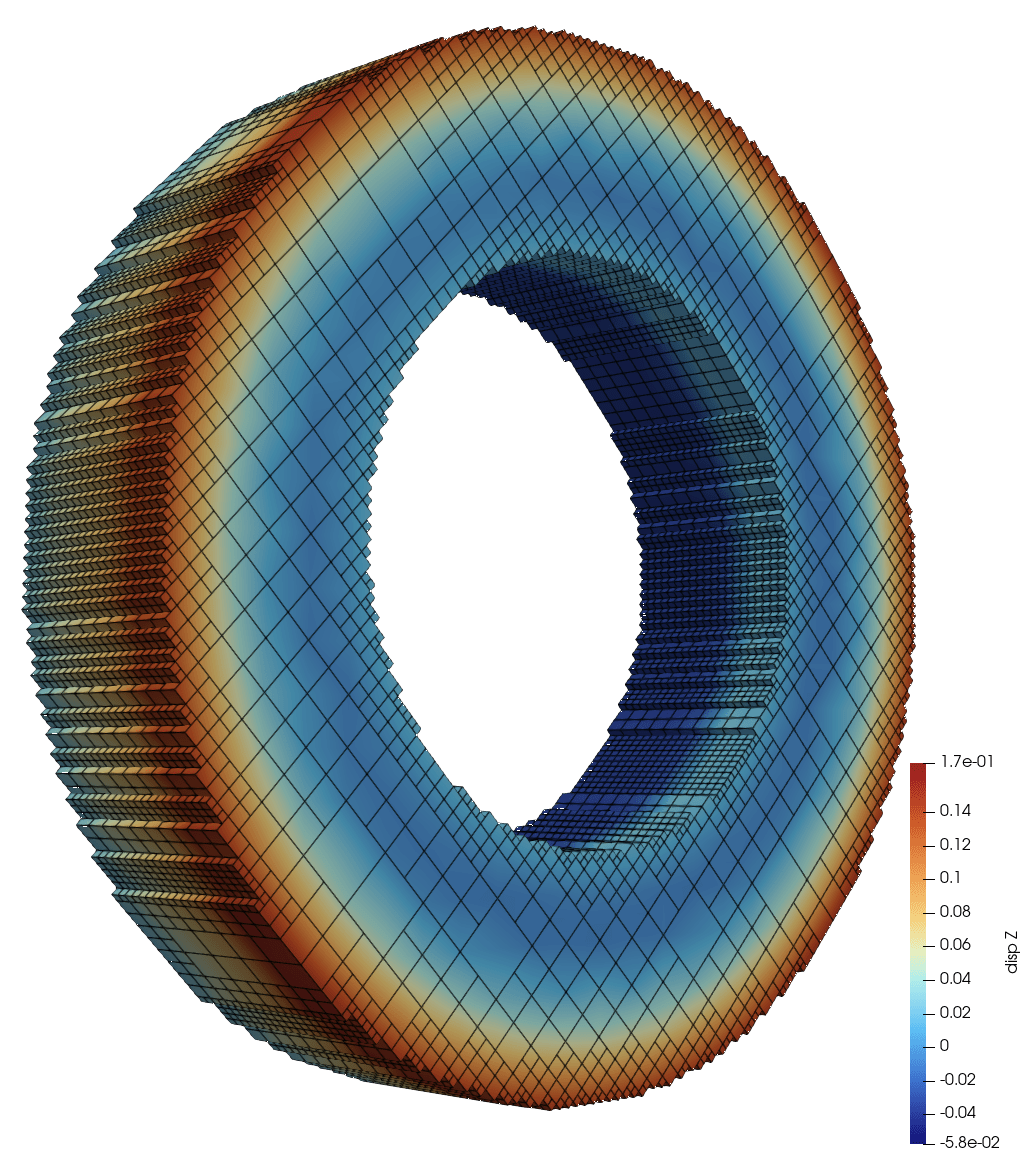
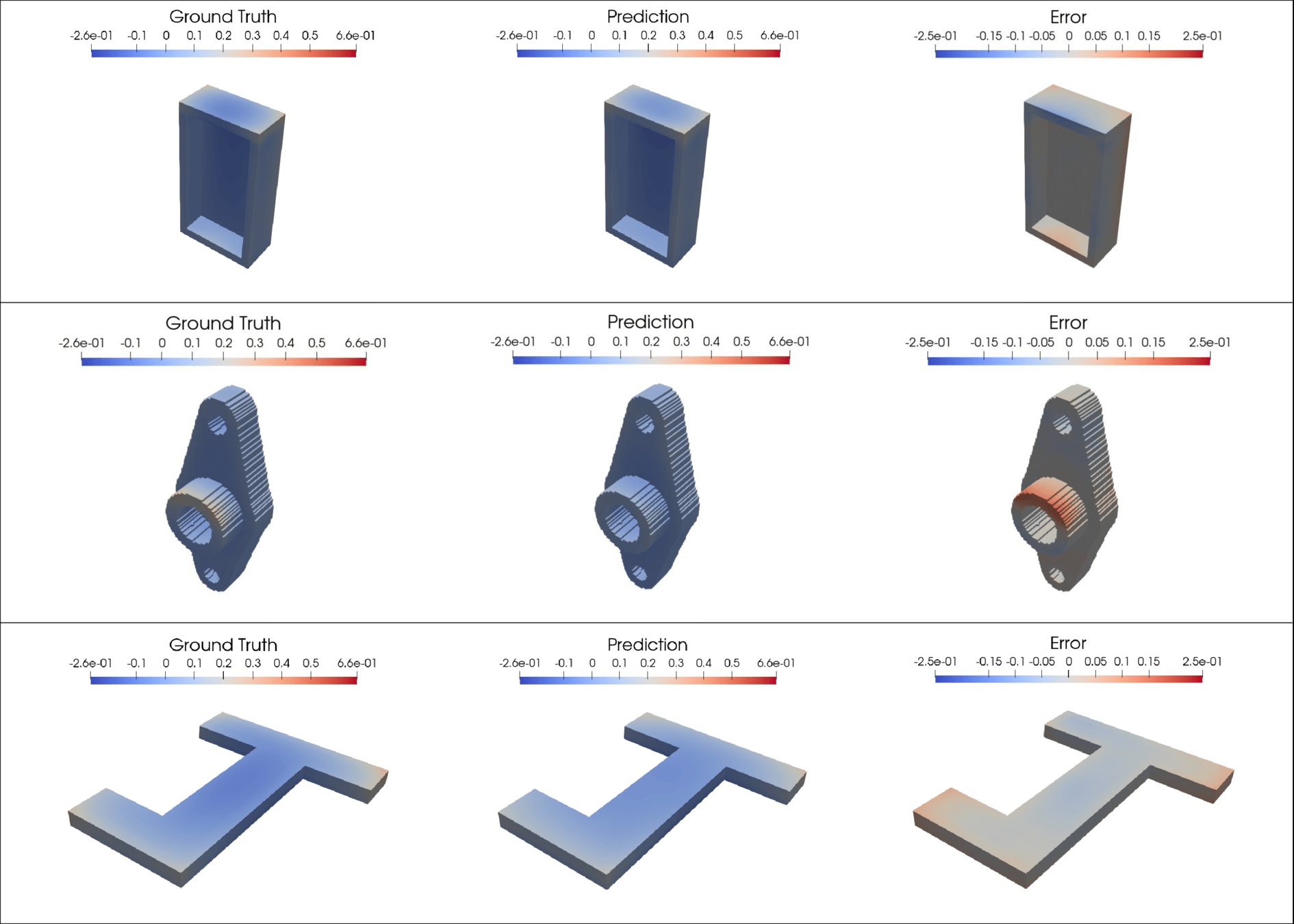
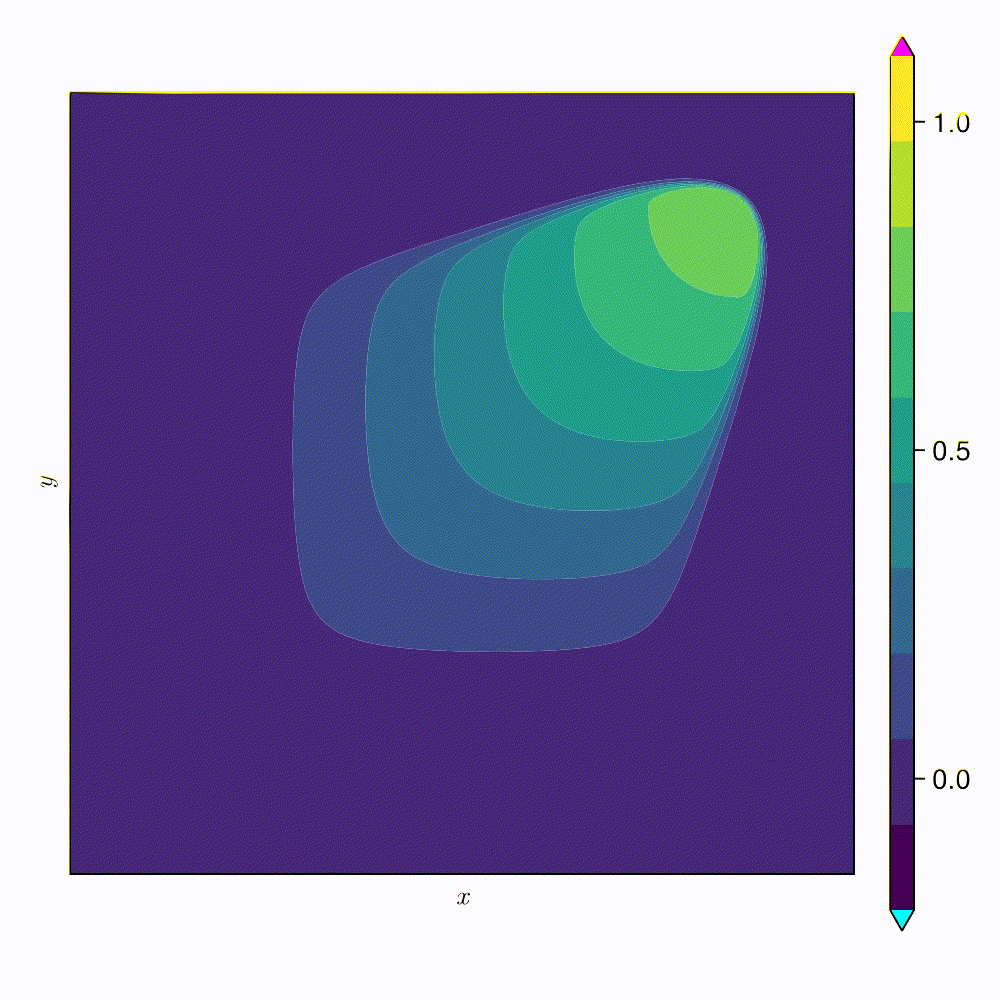
2D Burgers \(\mathit{Re}=1\mathit{k}\)
9
Supervised learning problem jointly learns latent trajectories and data manifold.
\(\text{Loss } (L)\)
\(\text{Backpropagation}\)
\(\nabla_\theta L\)
\(\nabla_\varrho L\)
\(\nabla_\theta L\)
\(\text{PDE Problem}\)
\((\boldsymbol{x}, t, \boldsymbol{\mu})\)
\(\text{ Parameters}\)
\( \text{and time}\)
\(\text{ Intrinsic ROM manifold}\)
\(\text{Coordinates}\)
\(\text{Smooth neural field MLP }(g_\theta)\)
\(\tilde{u}\)
\(\boldsymbol{x}\)
\(\boldsymbol{u}\left( \boldsymbol{x}, t; \boldsymbol{\mu} \right)\)
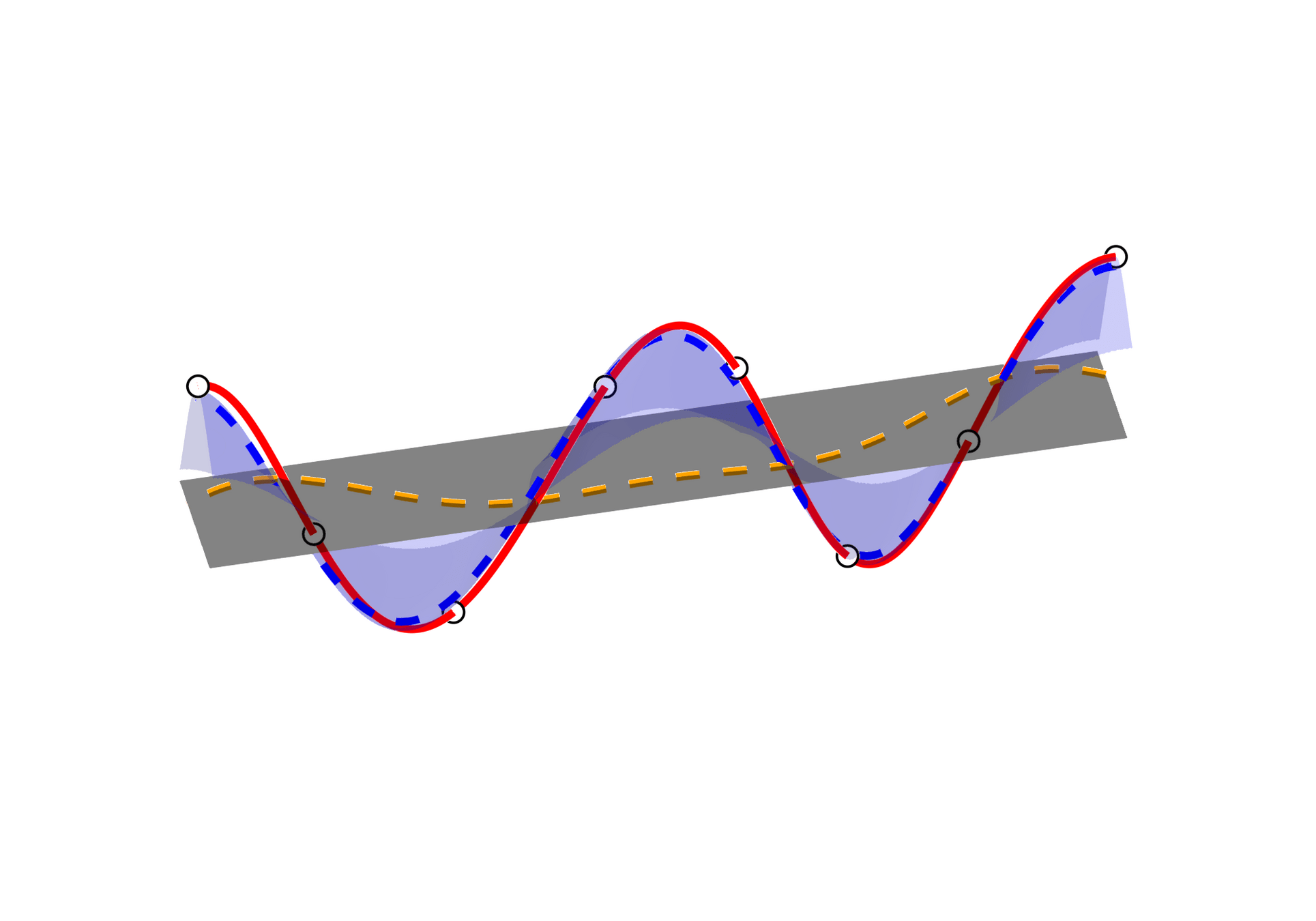
Force \( t \mapsto \tilde{u}(t) \) to be simple, e.g., shallow MLP.
Coordinate MLPs with sinusoidal activations offers grid-independence.
Replace autoencoder with a direct prediction workflow.
10
SNF-ROM with Lipschitz regularization (SNFL-ROM)
\(\text{Penalize the \textcolor{blue}{Lipschitz constant} of the MLP [arXiv:2202.08345]}\)
\(\text{[enwiki:1230354413]}\)
SNF-ROM with Weight regularization (SNFW-ROM)
\(\text{Directly penalize \textcolor{red}{high-frequency components} in }\dfrac{\text{d}}{\text{d} x}\text{NN}_\theta(x)\)
We present two approaches to learn inherently smooth and accurately differentiable neural field MLPs.
\({x}\)
\({u(x)}\)
High freq. noise
11
\(\text{CAE-ROM}\) [1]
\(\text{SNFL-ROM (ours)}\)
\(\text{SNFW-ROM (ours)}\)
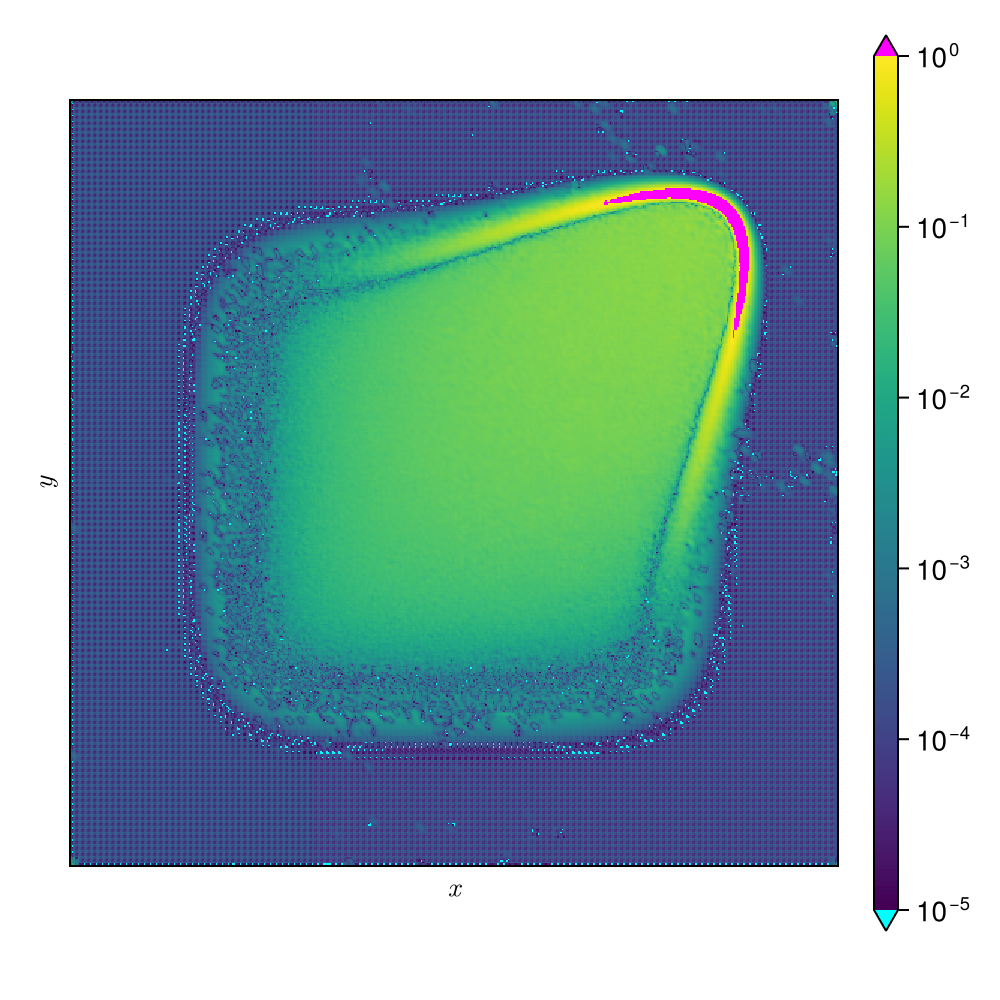
Online dynamics solve matches learned trajectories
Online evaluation deviates!
Distribution of reduced states \((\tilde{u})\)
[1] Lee & Carlberg — Nonlinear manifold ROM via CNN autoencoders (JCP 2020)
12
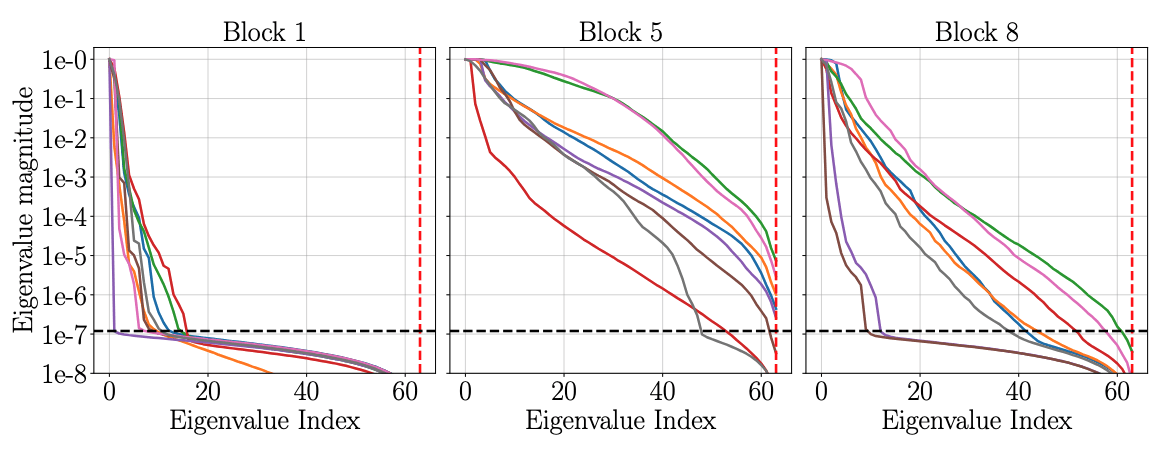
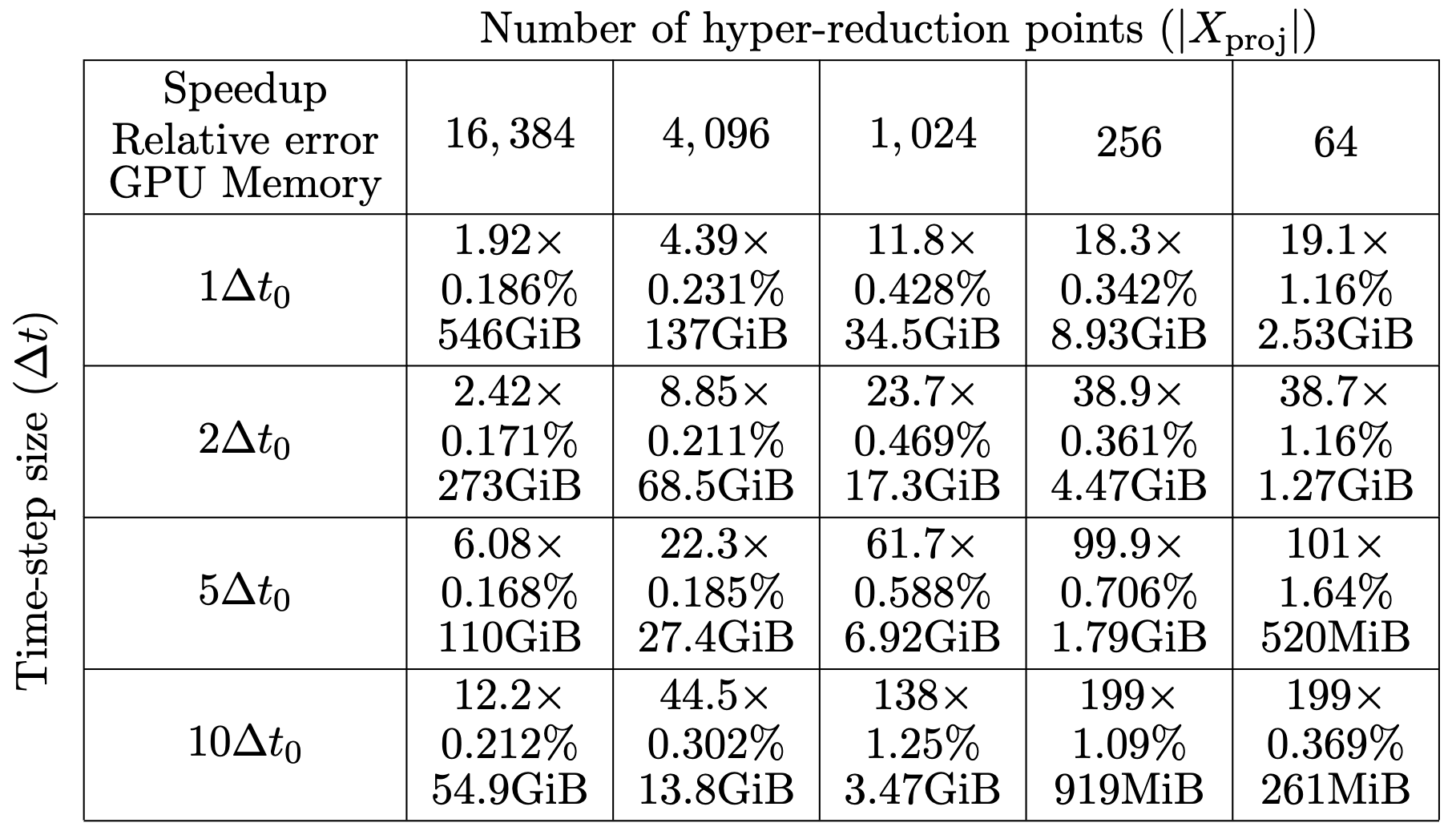
SNF-ROM maintains high accuracy even with larger time-steps.
\(\text{Relative error vs time } (\Delta t = \Delta t_0)\)
\(\text{Relative error vs time } (\Delta t = 10\Delta t_0)\)
[1] Lee & Carlberg — Nonlinear manifold ROM via CNN autoencoders (JCP 2020)
13
\(\text{CAE-ROM}\) [1]
\(\text{SNFL-ROM (ours)}\)
\(\text{SNFW-ROM (ours)}\)
Relative error
[1] Lee & Carlberg — Nonlinear manifold ROM via CNN autoencoders (JCP 2020)
\([1]\)
\(0.4\%\) relative error
\(\text{DoFs: }524~k \to 2\)
\(\text{Time }(t)\)
\(\text{Relative Error}(t)\)
\(199\times\) speed-up
14
Accurate derivate evaluation for neural representations.
Fast and accurate latent space traversal in neural ROMs
Won poster award at World Conf. Comp. Mech. 2024
Published in Journal of Comp. Phys.
15
Large training cost is amortized over several evaluations
Model learns to predict \(\boldsymbol{u}\) over a distribution of \(\boldsymbol{\mu}\)
16
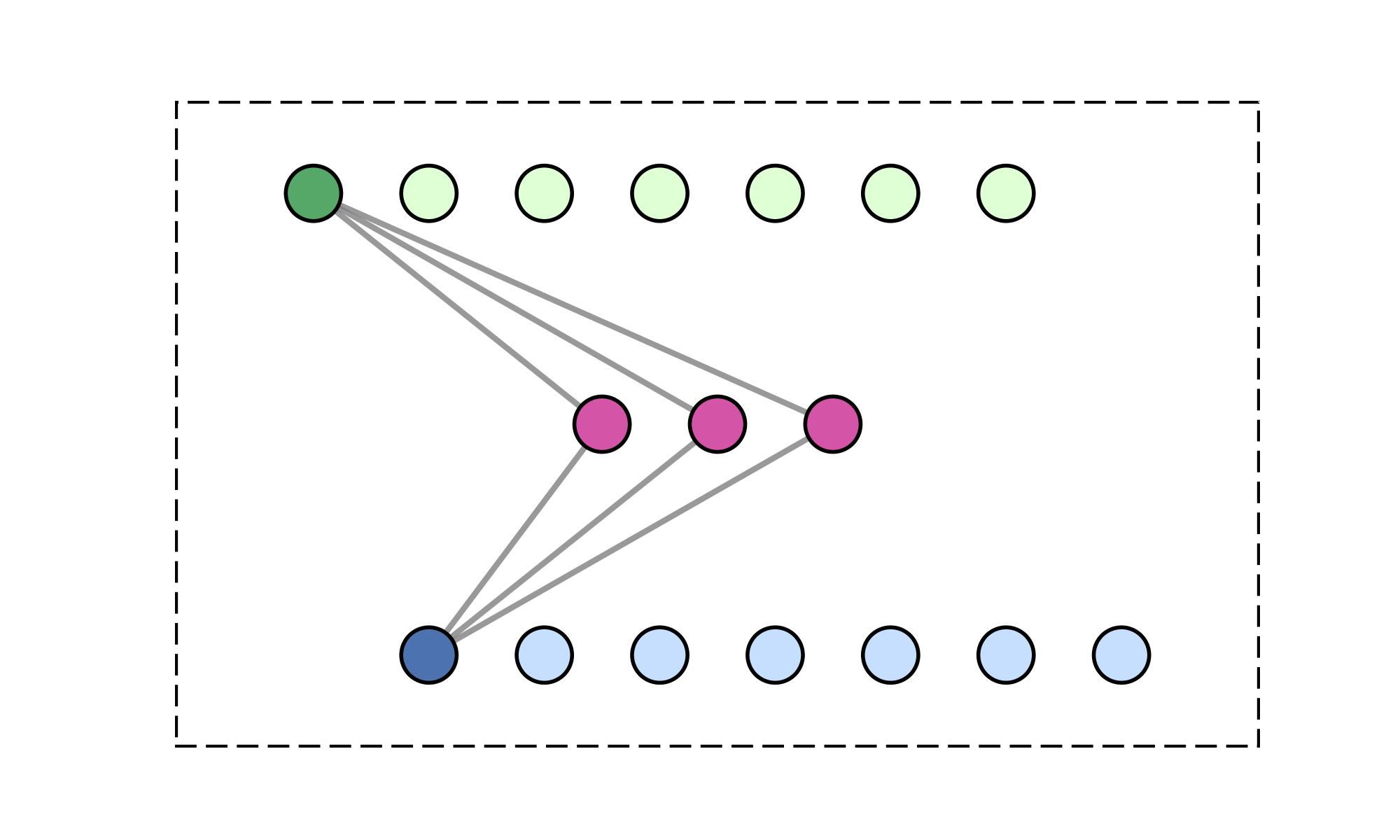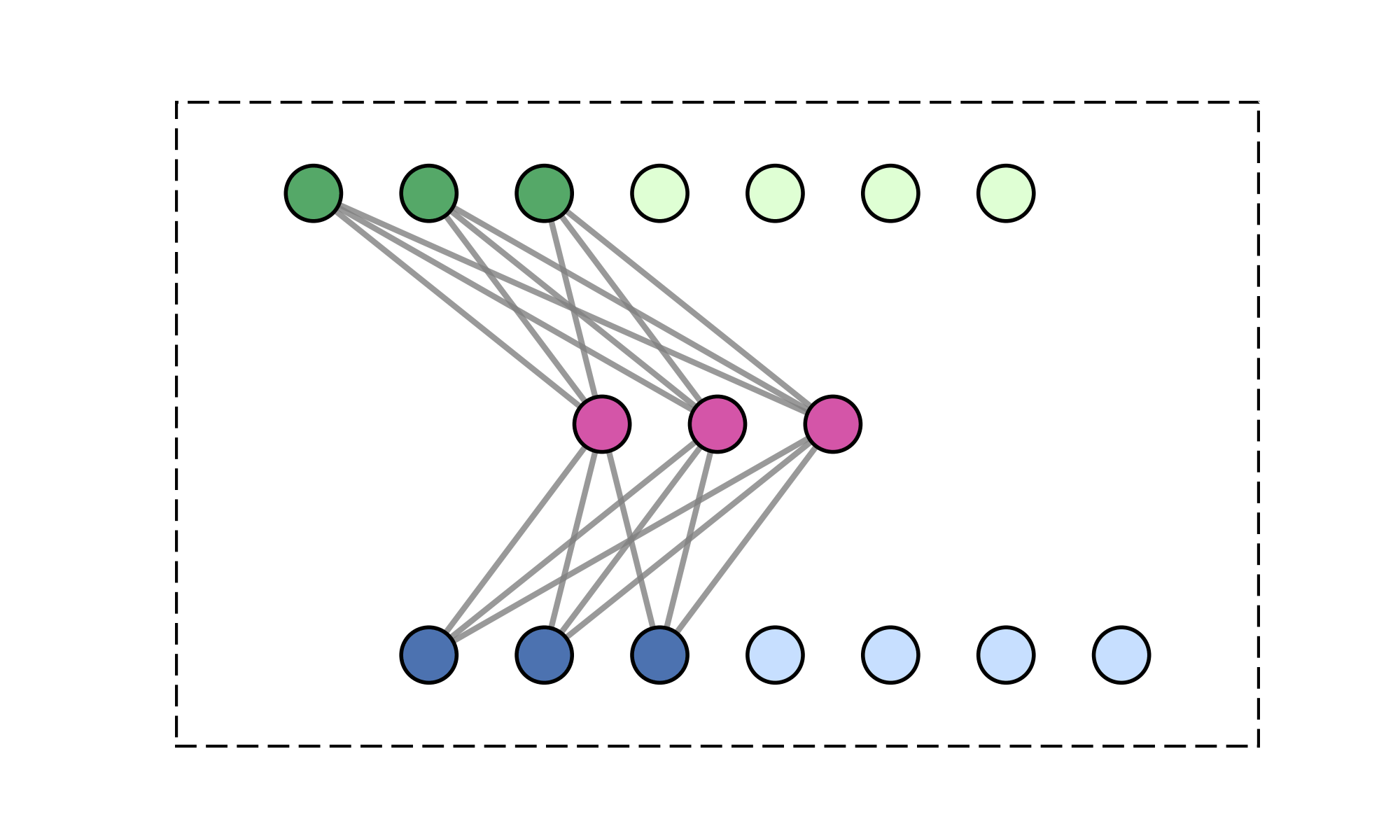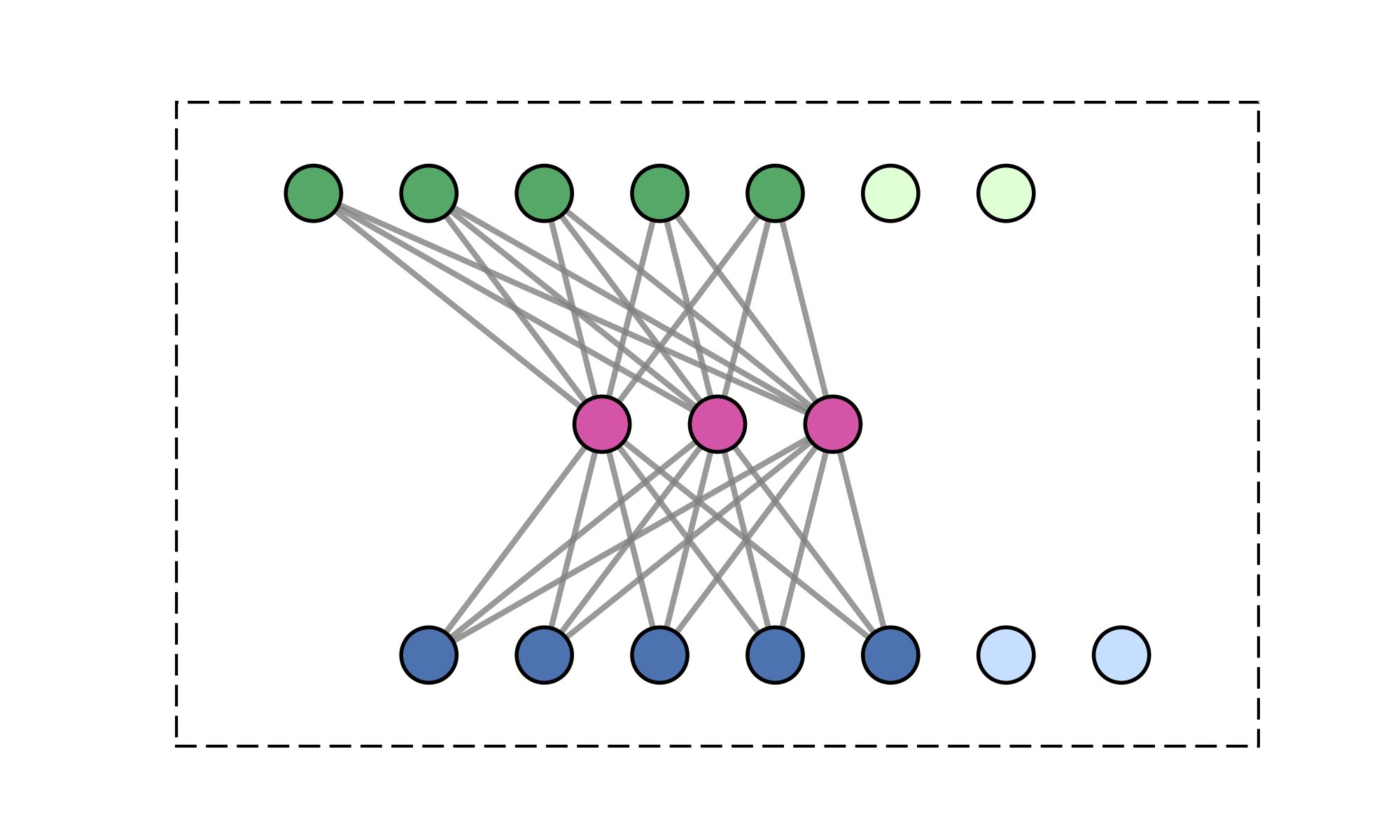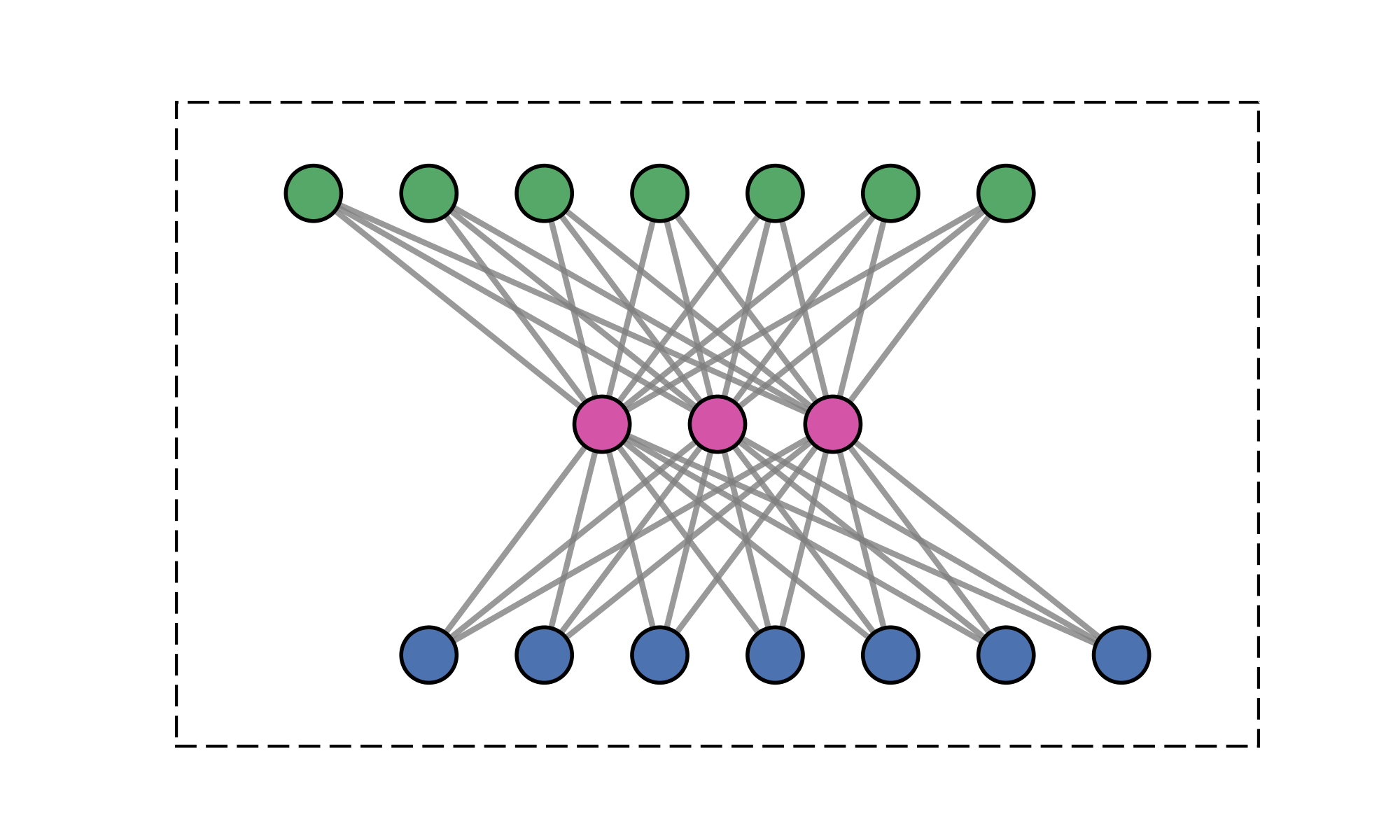
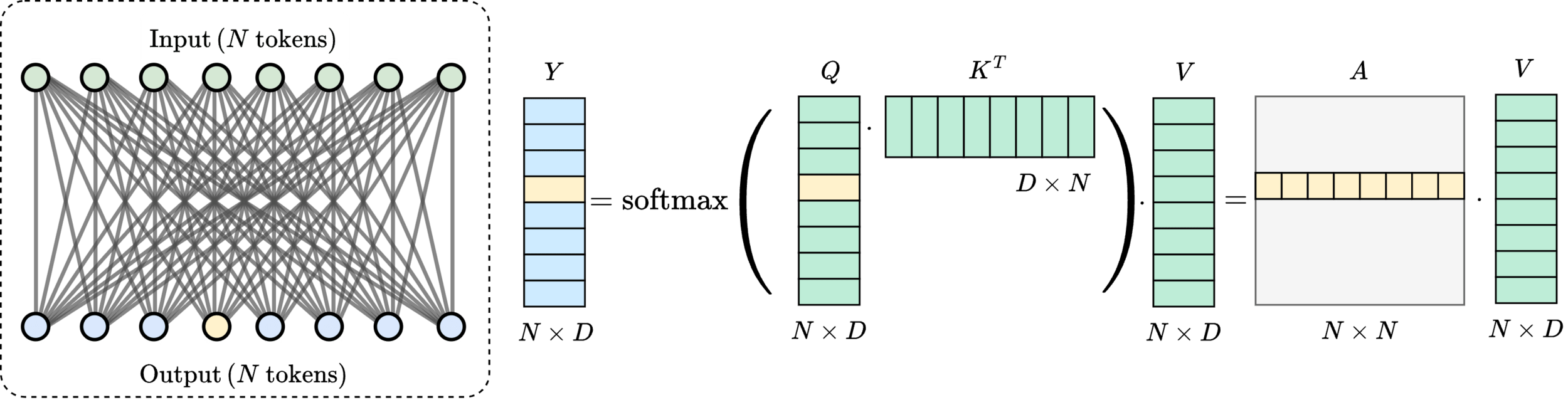
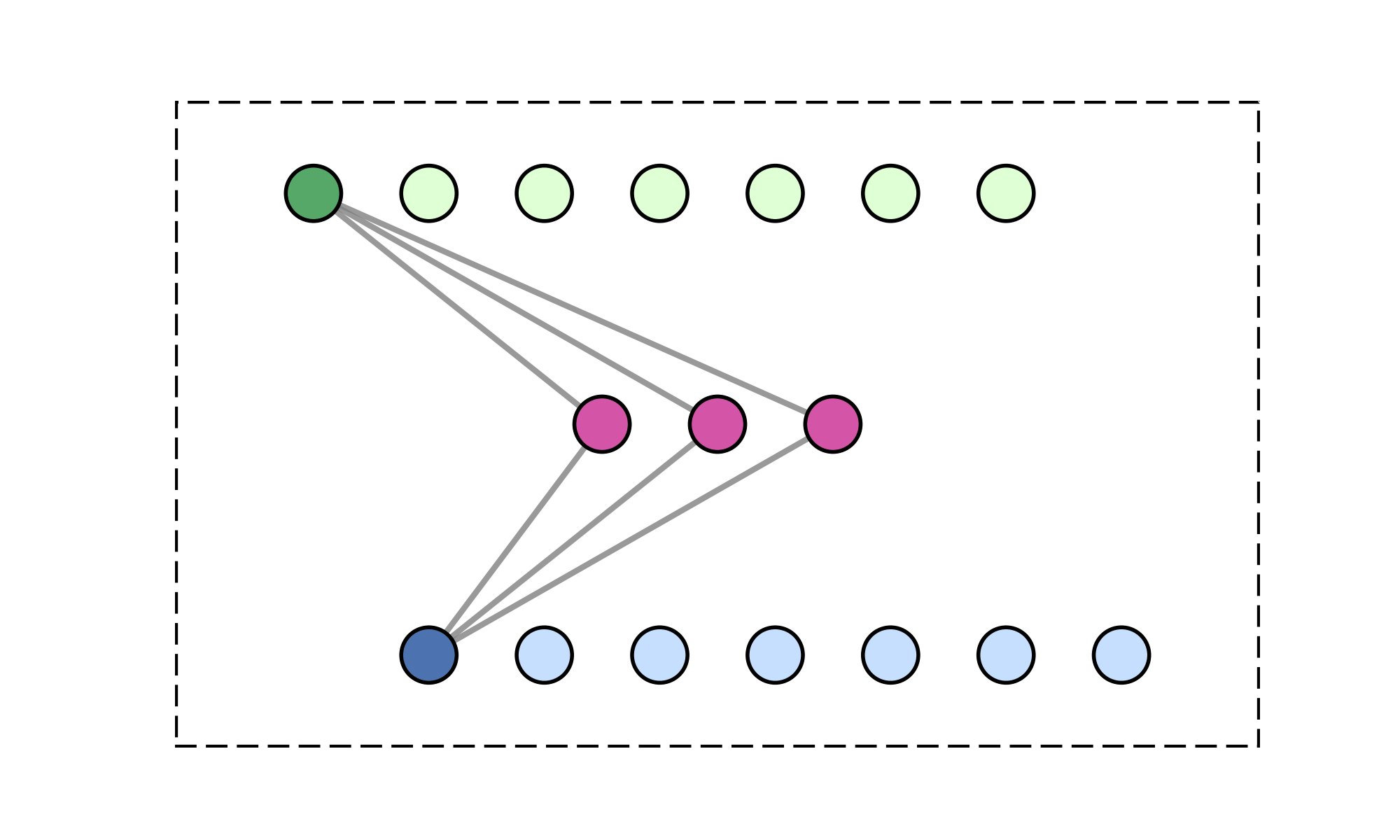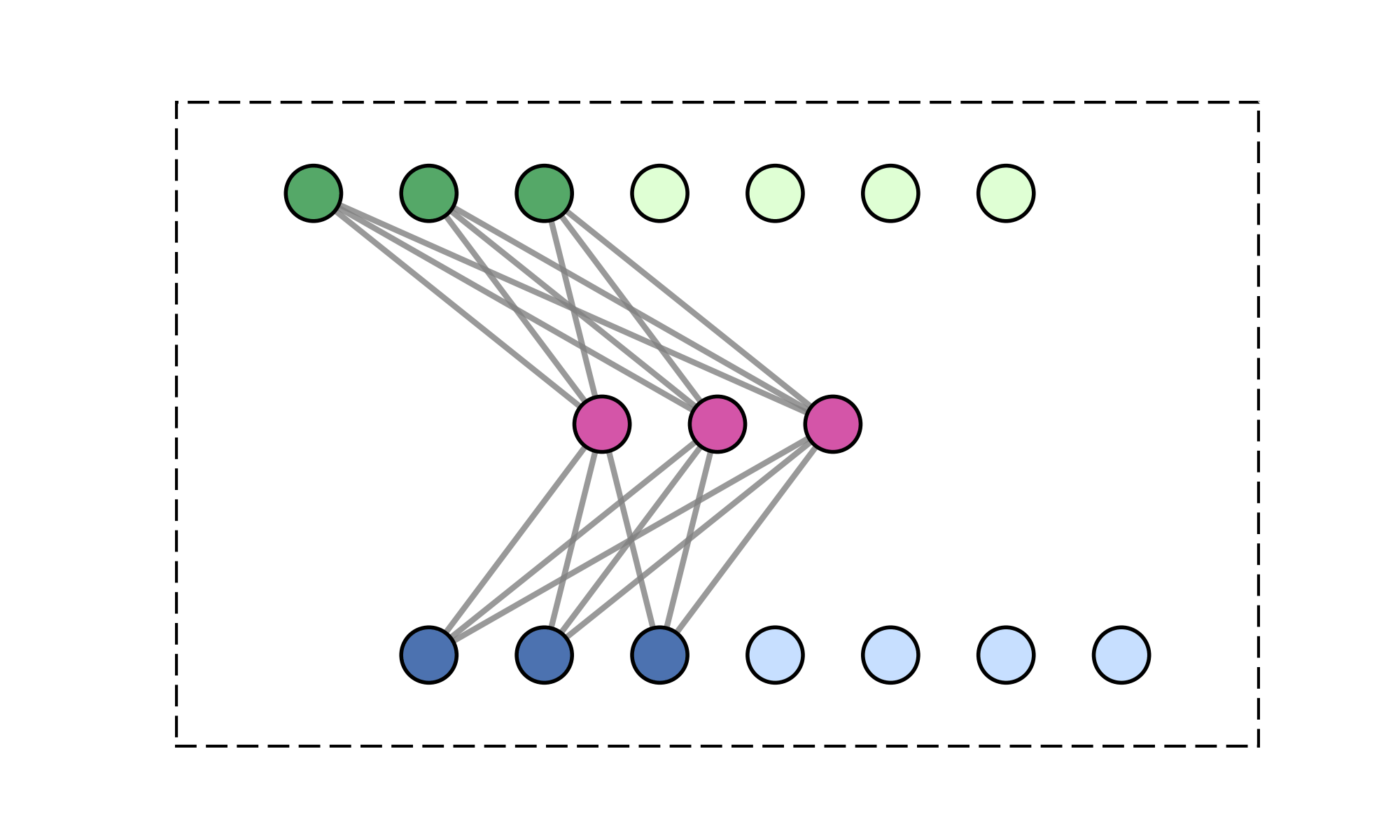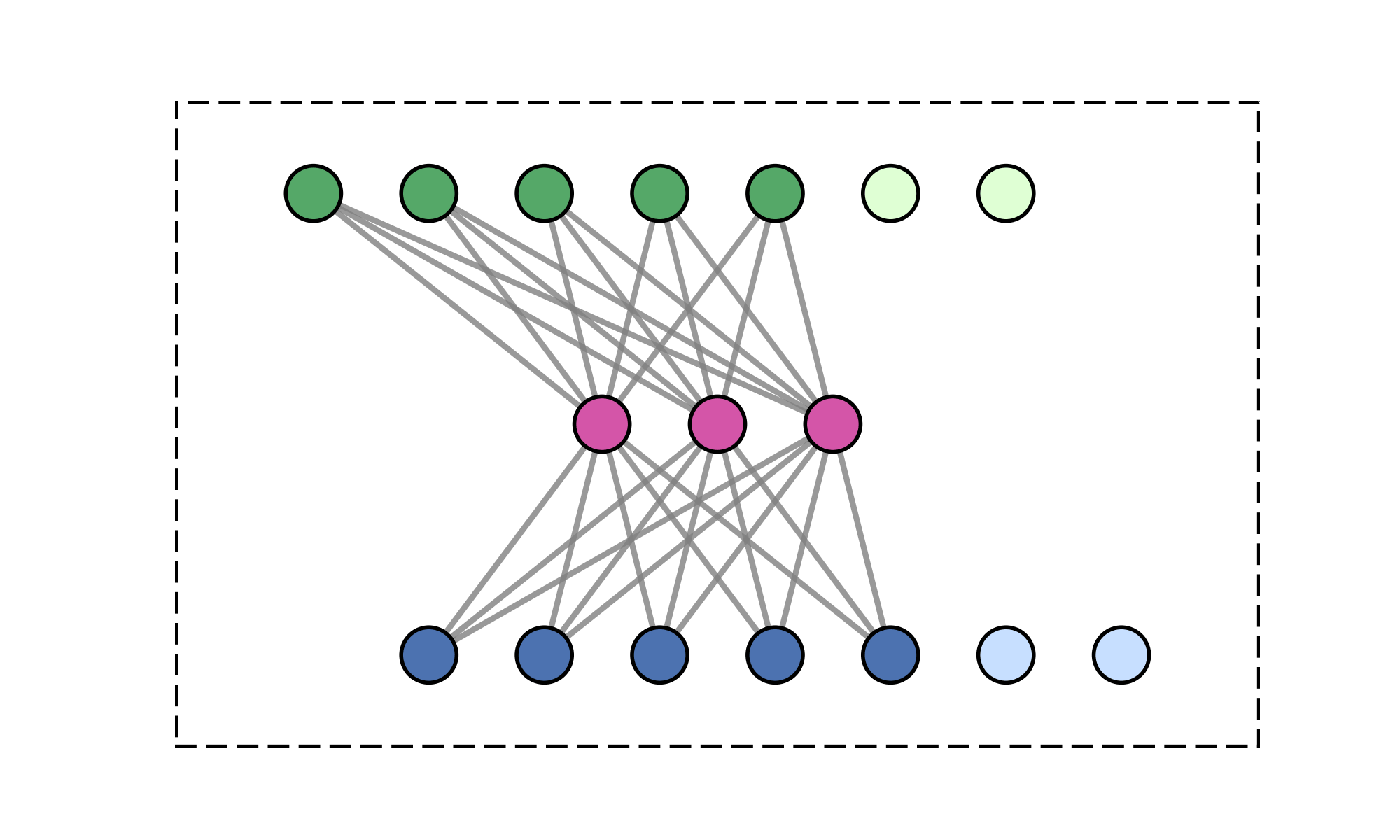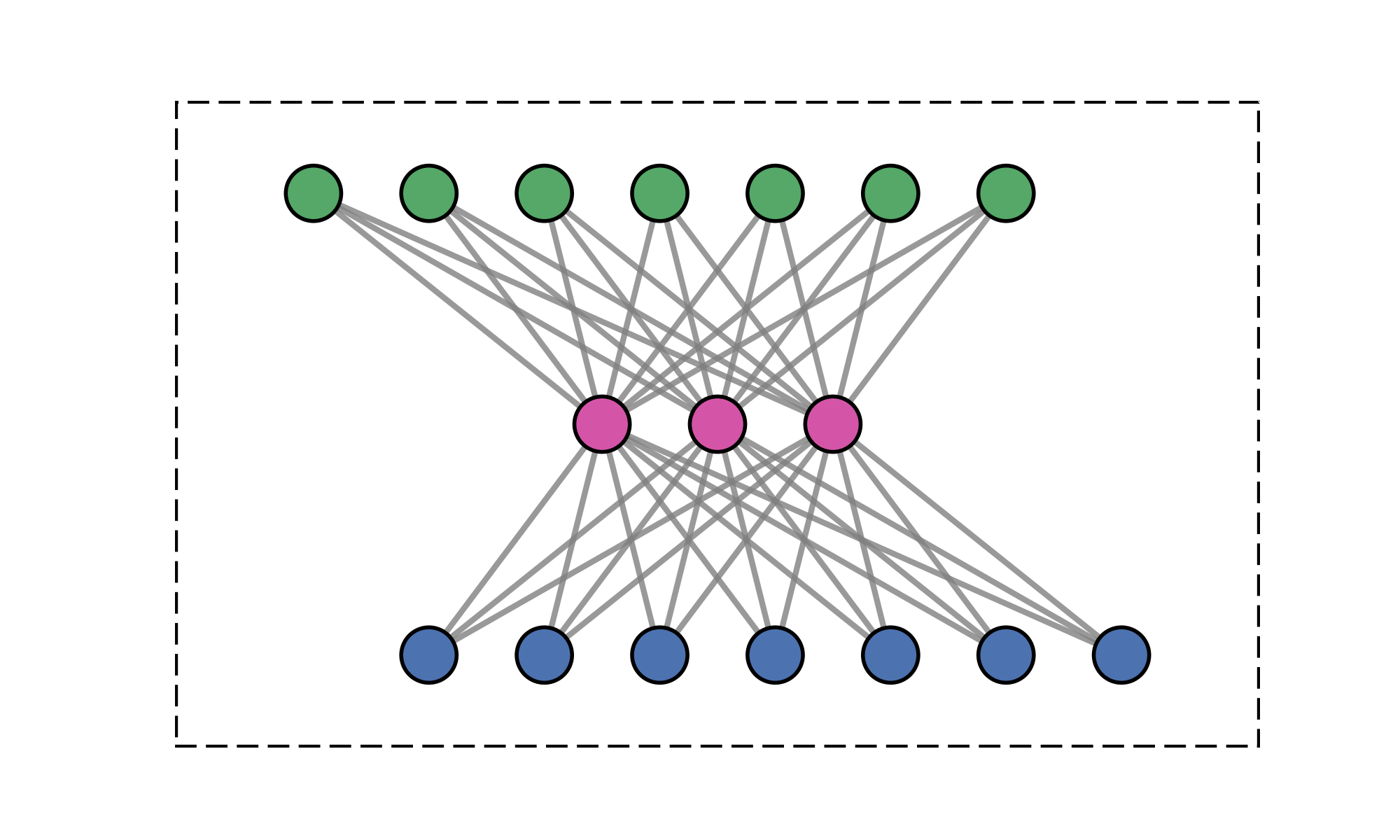
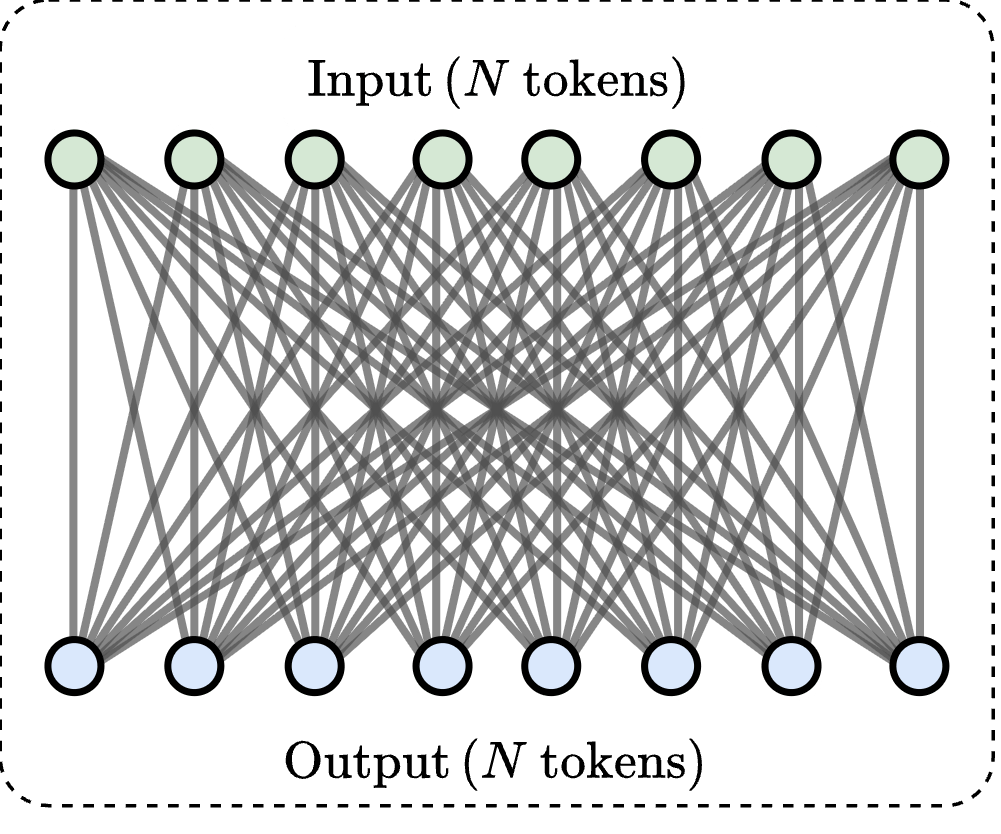
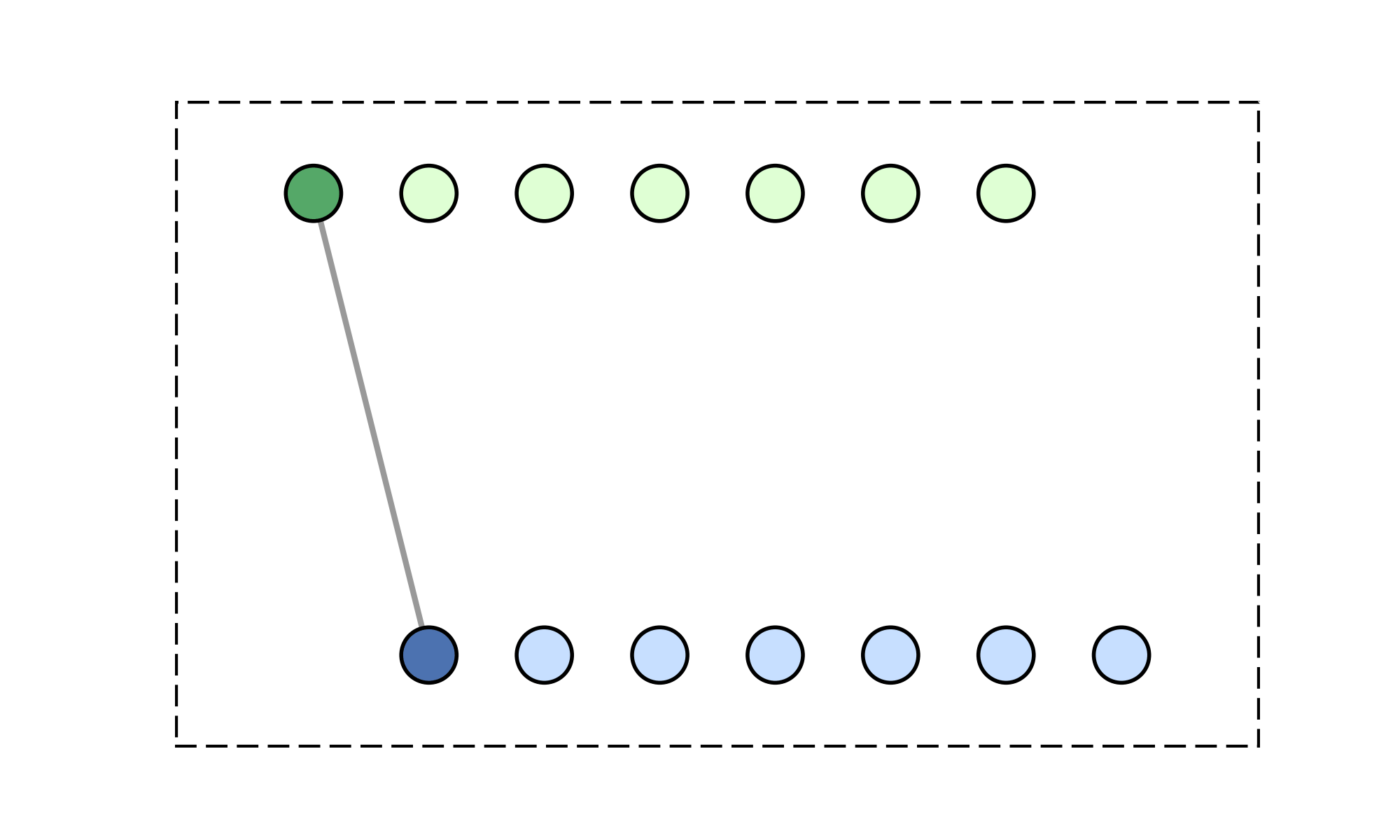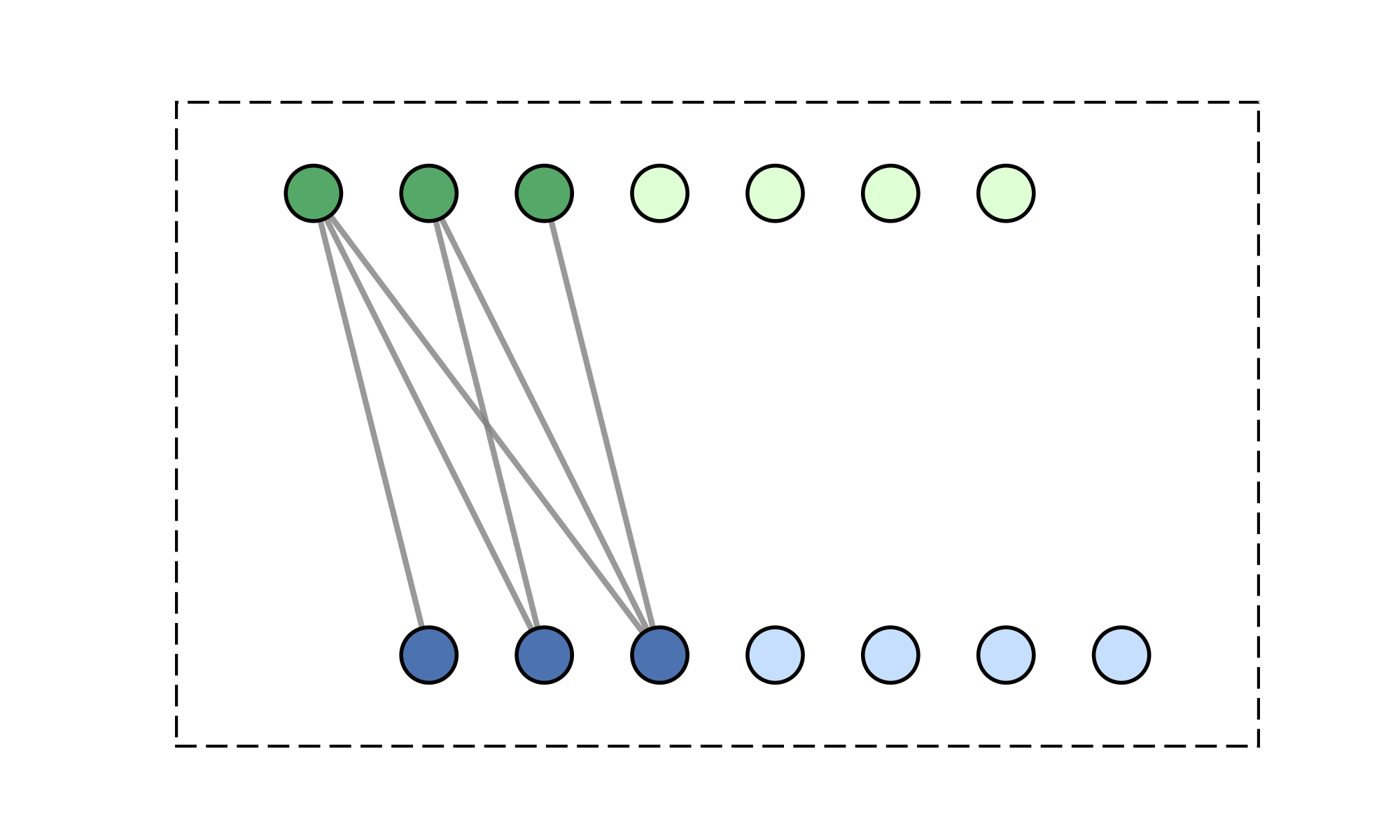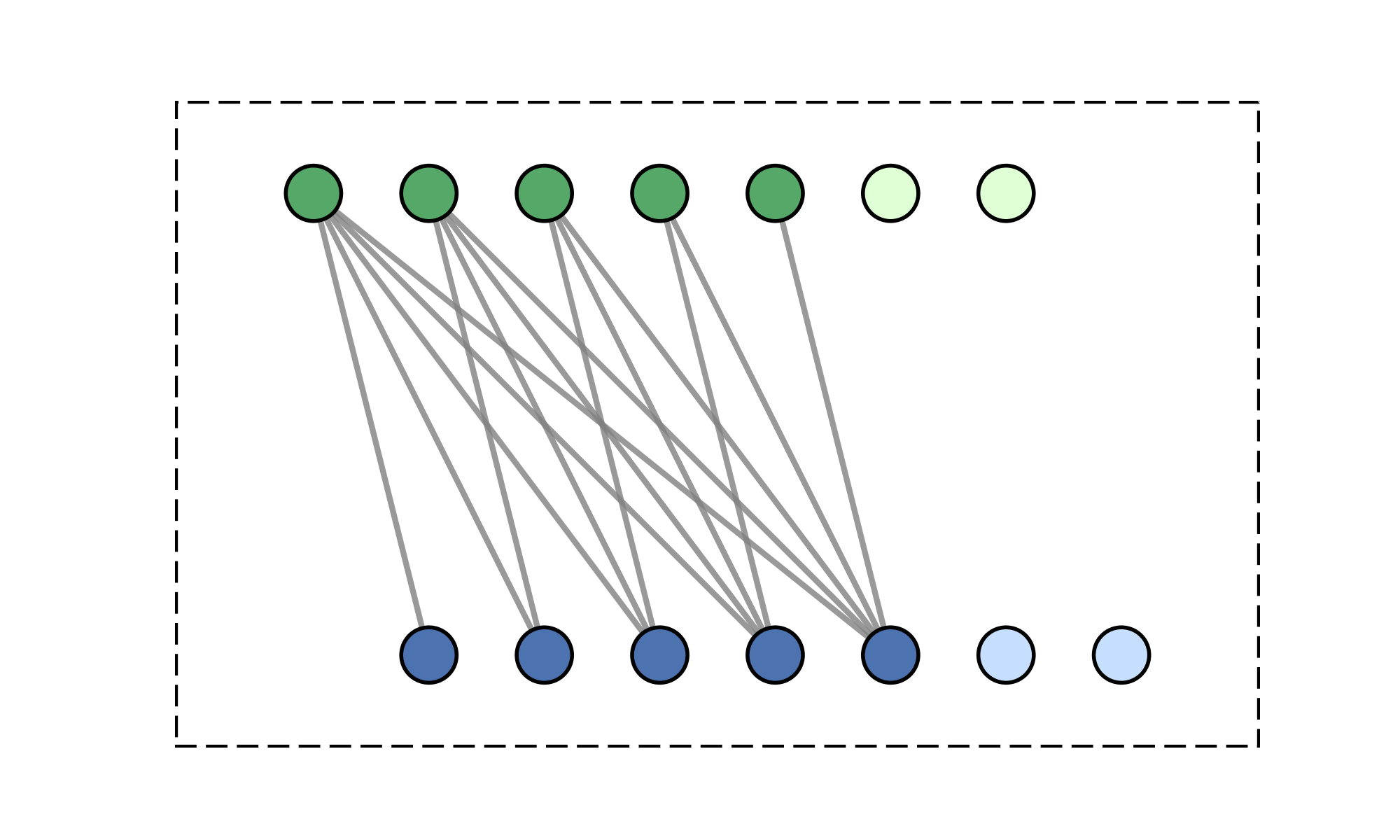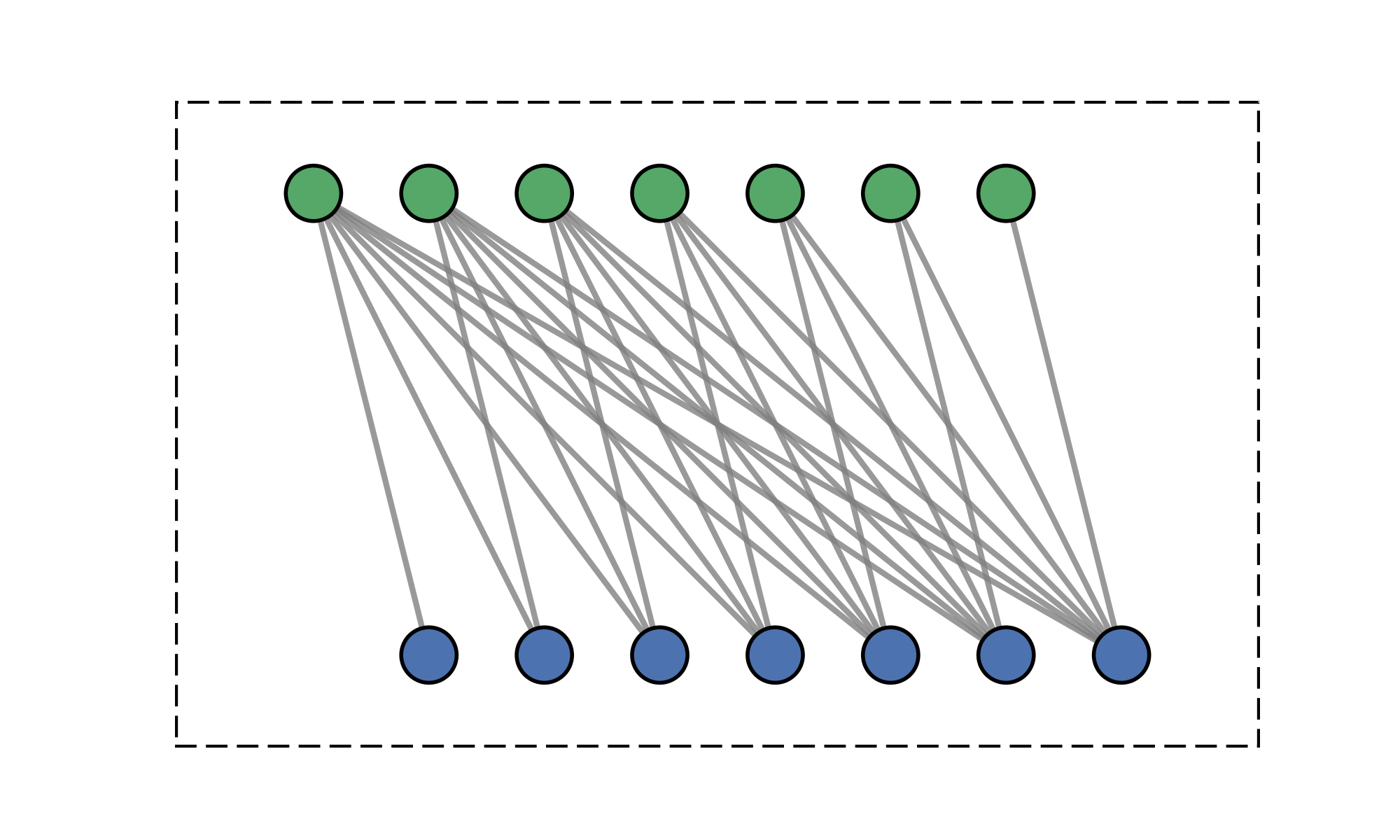
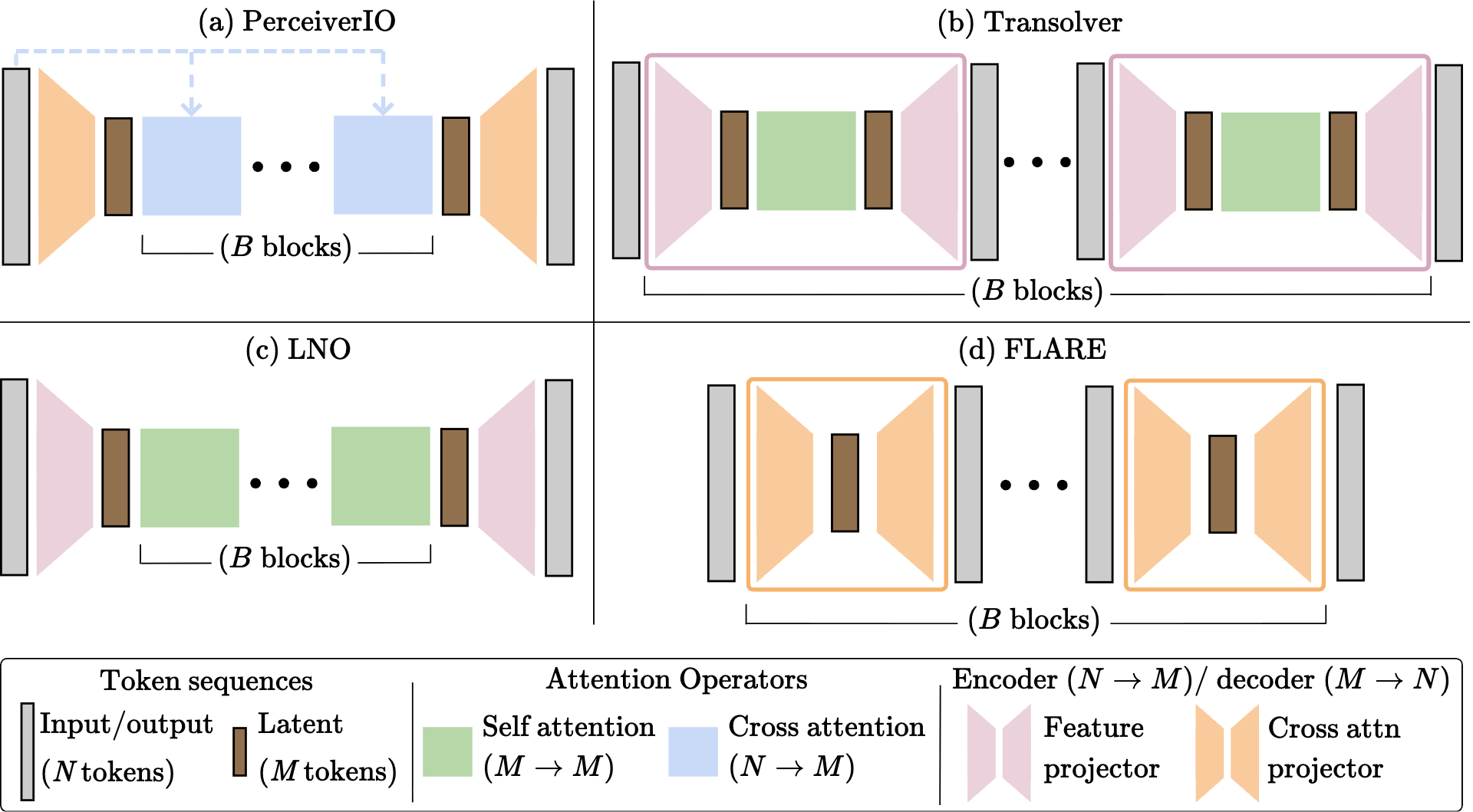
Message-passing on a dynamic all-to-all graph.
[1] Vaswani et al. — “Attention Is All You Need”, NeurIPS 2017
Quadratic (\(\mathcal{O}(N^2)\)) cost limits scalability
17
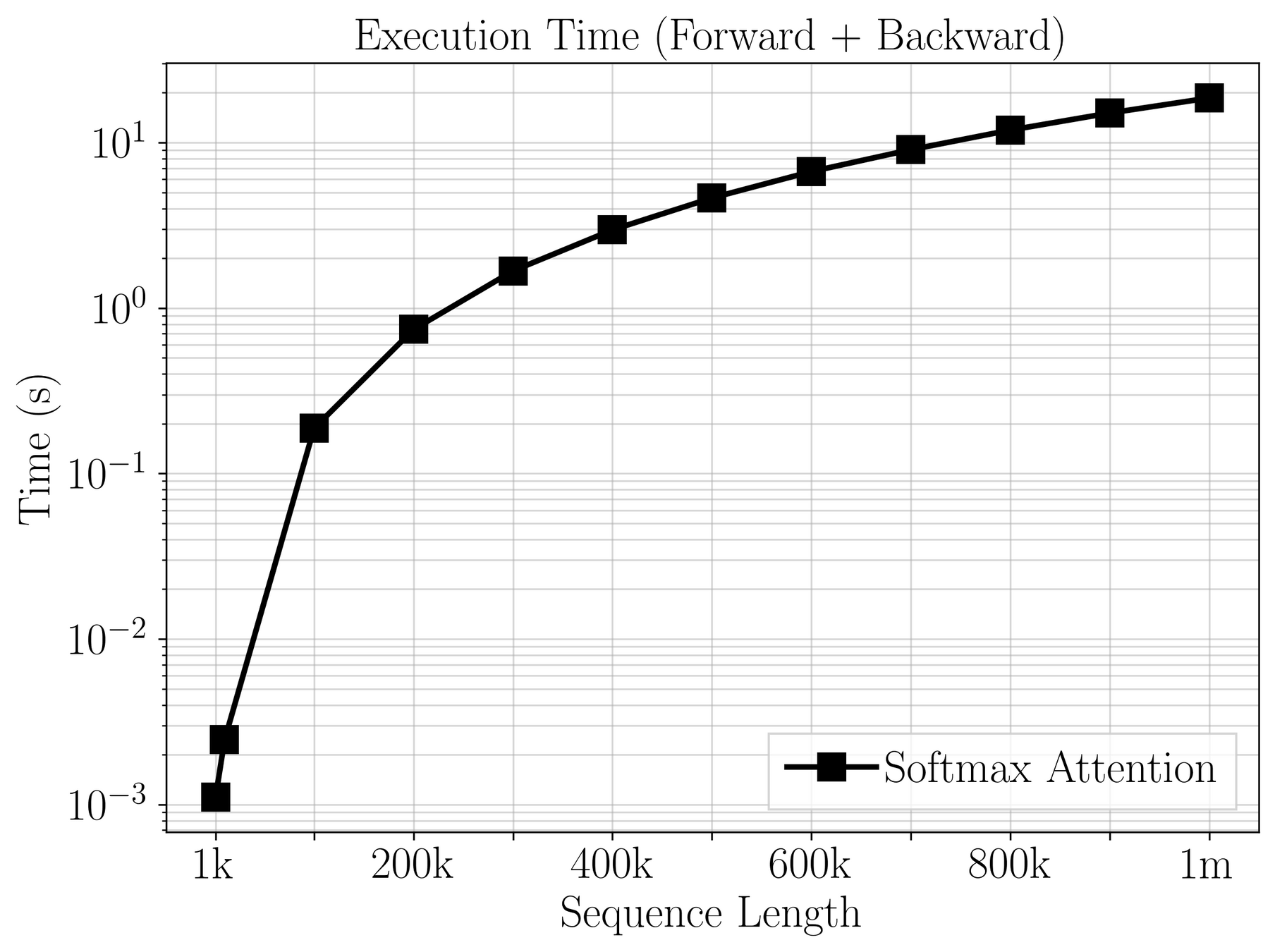
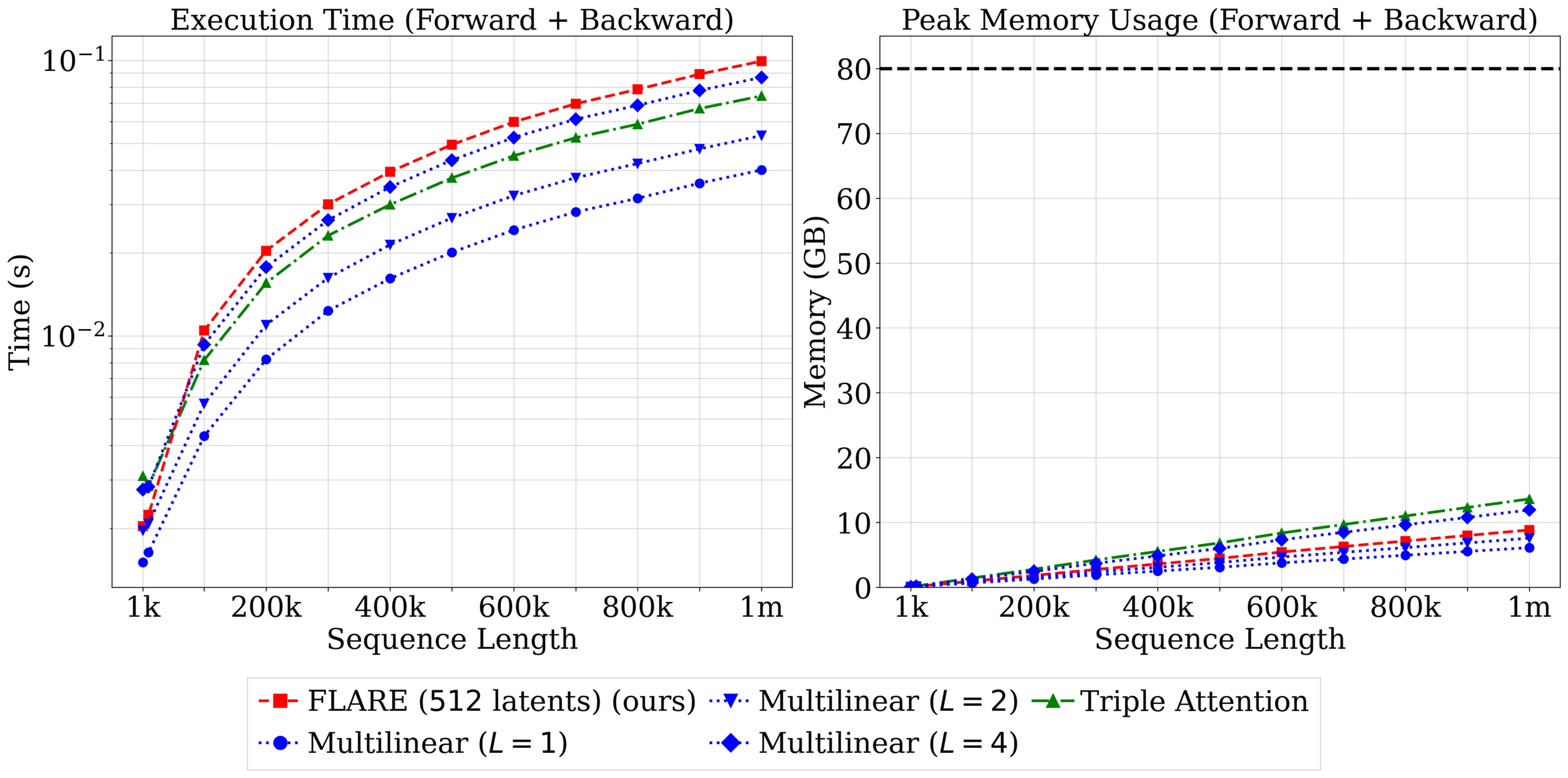
Over \(20~\text{s}\) per gradient step on a mesh of 1m poins!
Goal: enable transformer models on large meshes.
[1] Vaswani et al. — “Attention Is All You Need”, NeurIPS 2017
\([1]\)
18
Solution operator requires global communication.
Forward operator is implemented with sparse, structured communication.
Need principled strategy for reducing communication cost.
Detour: finite elements
[1] ParticleInCell.com — “Finite Element Experiments in MATLAB” (2012)
[1]
19
Smoothness implies redundancy in communication.
19
Smoothness implies redundancy in communication.
Method: club matching points to one cluster and communicate together.
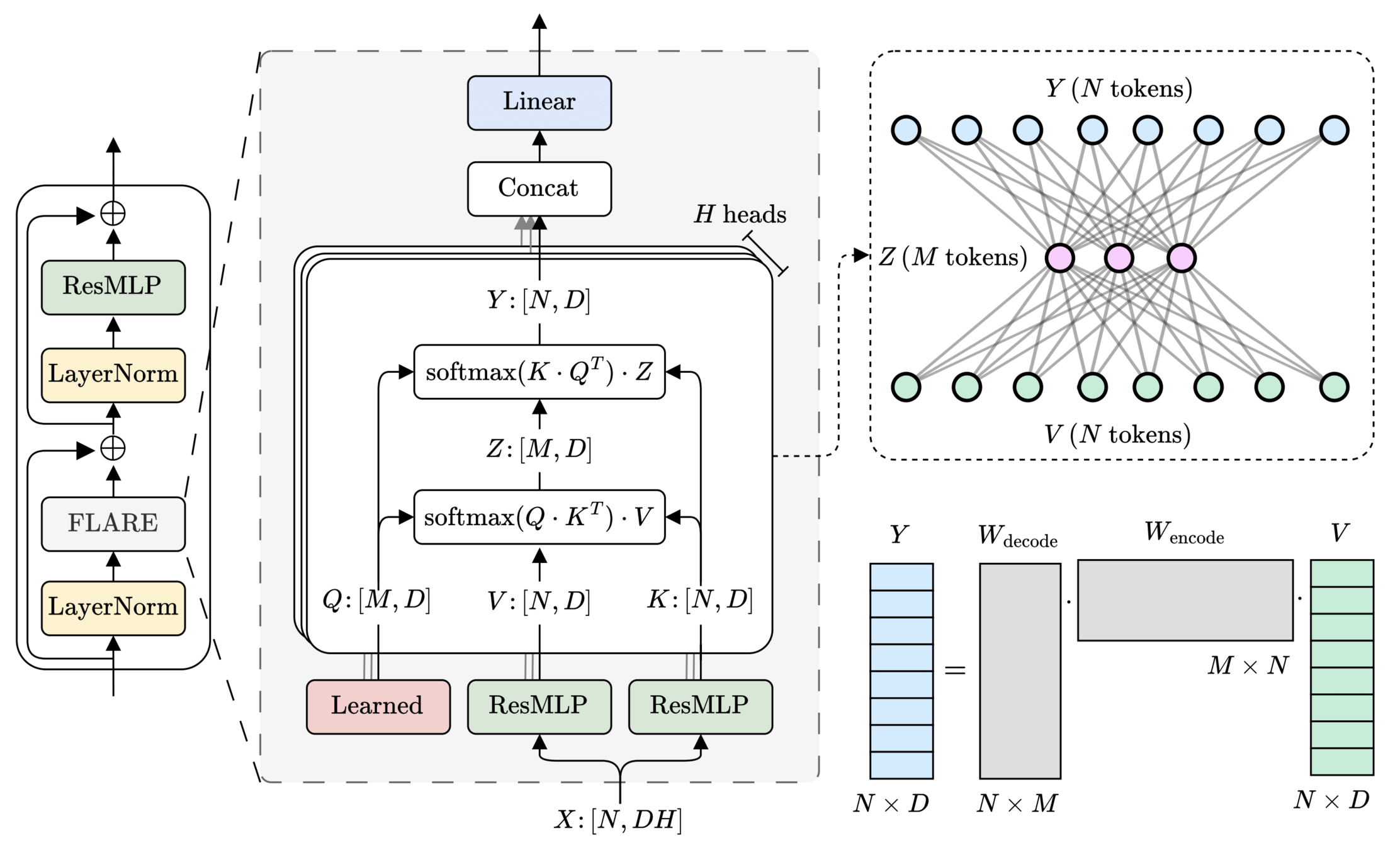
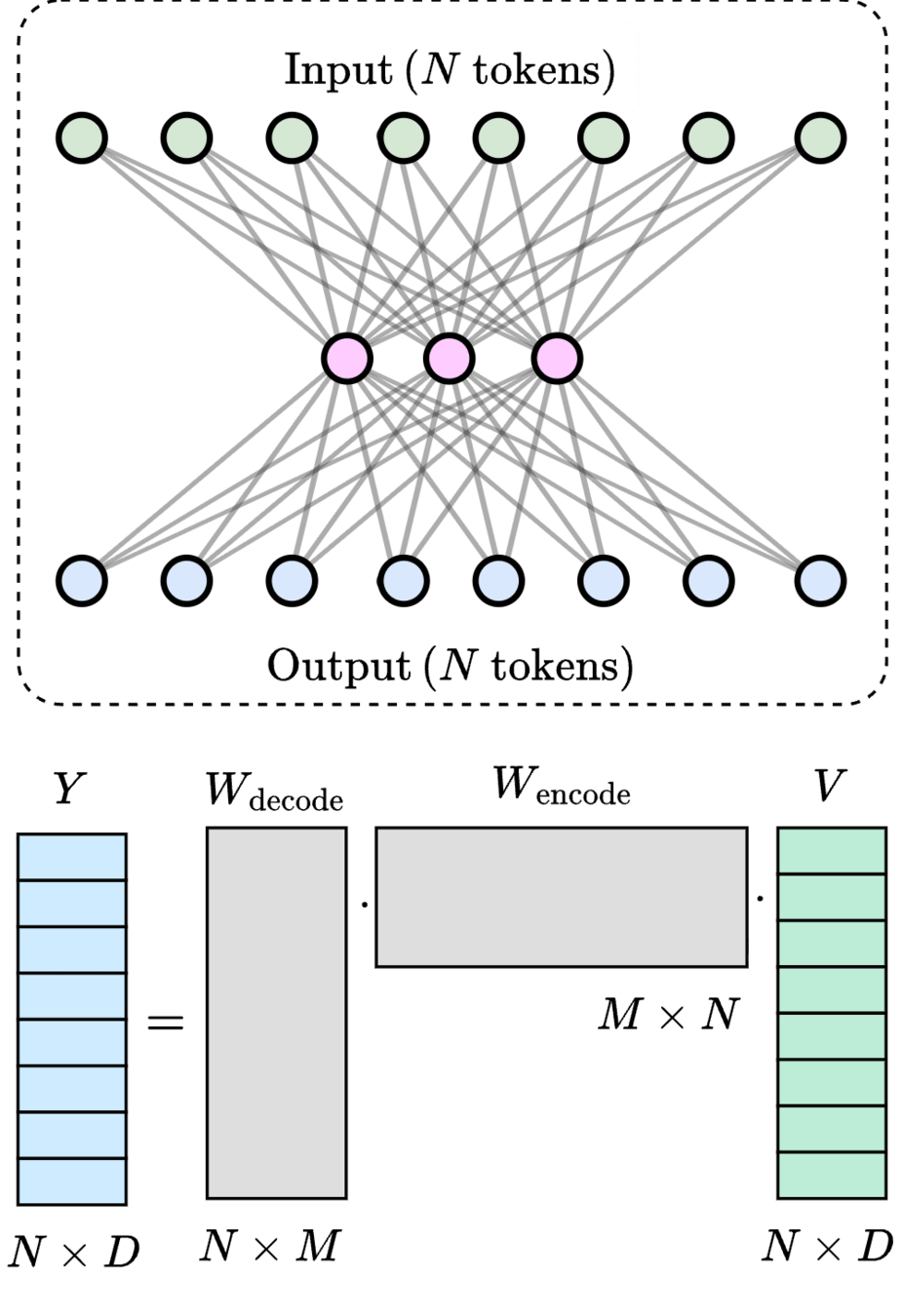
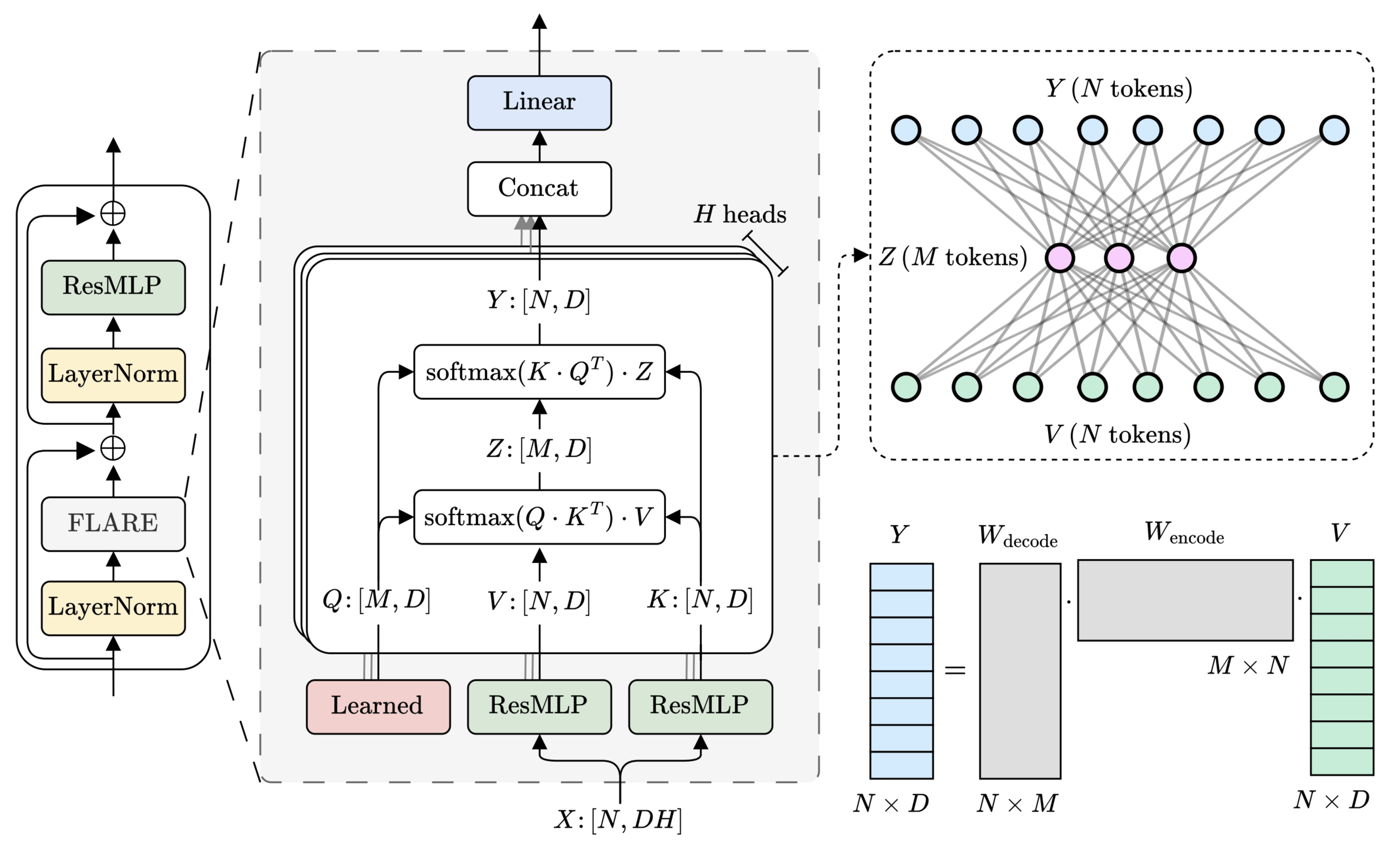
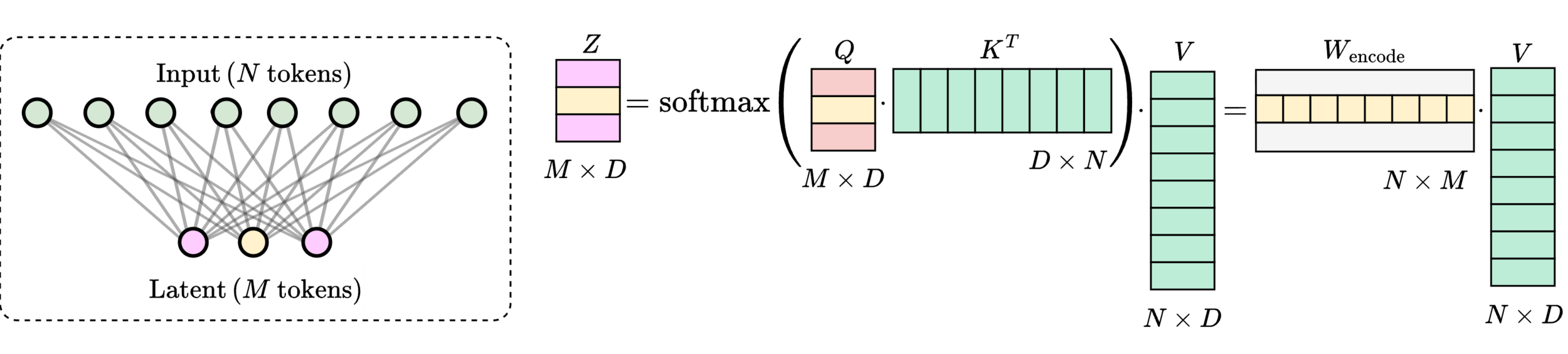
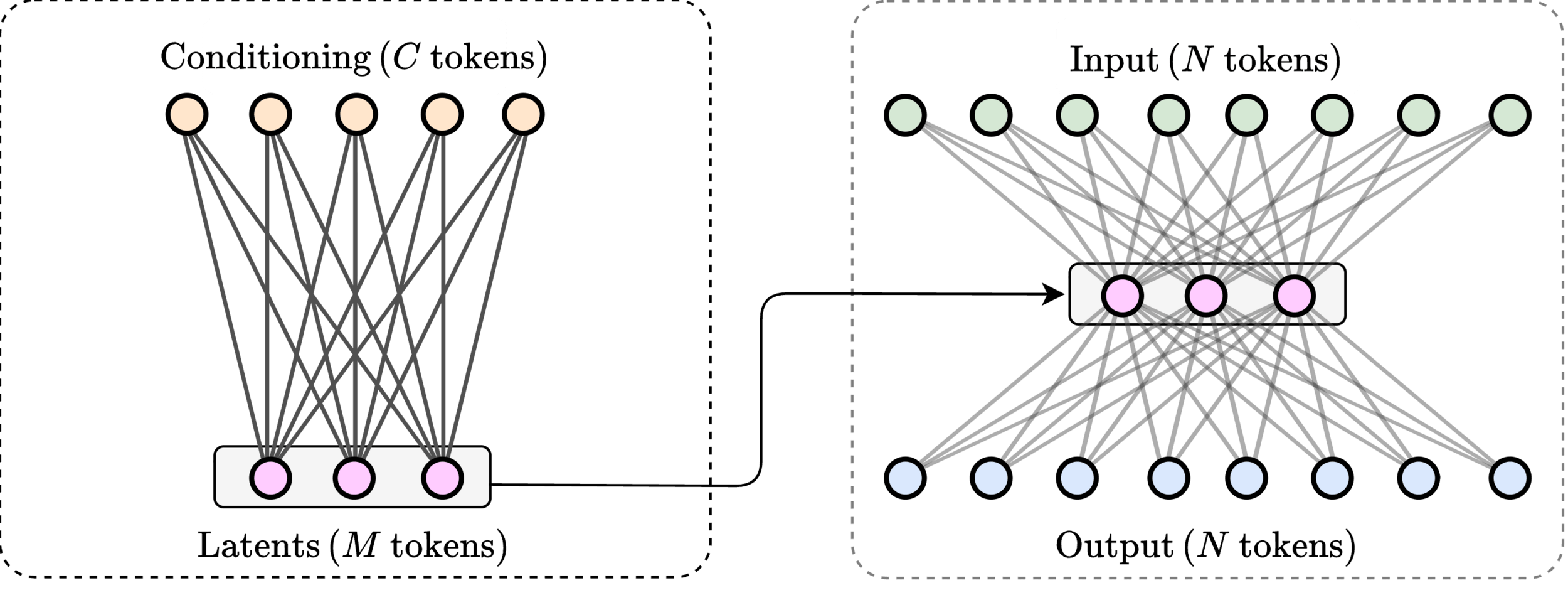
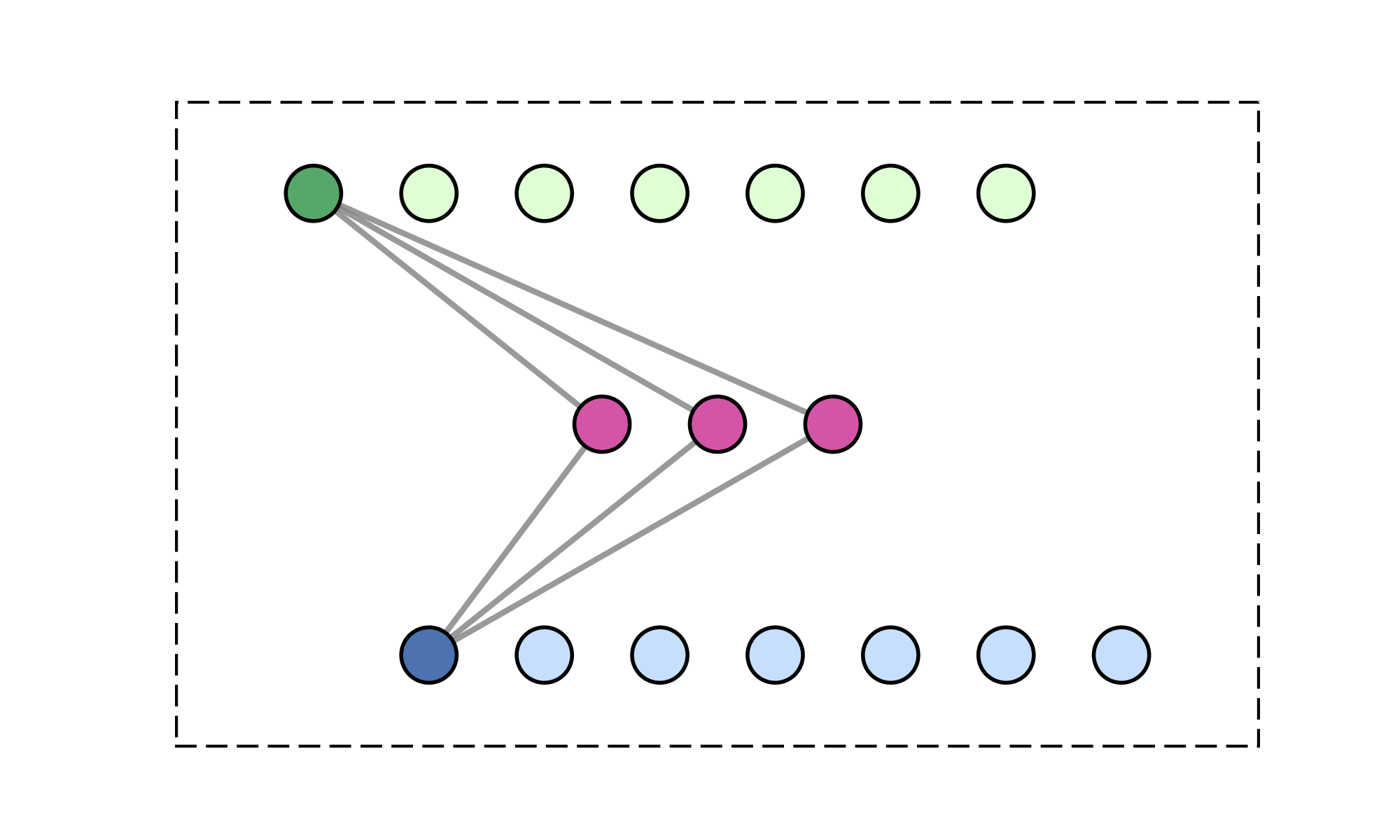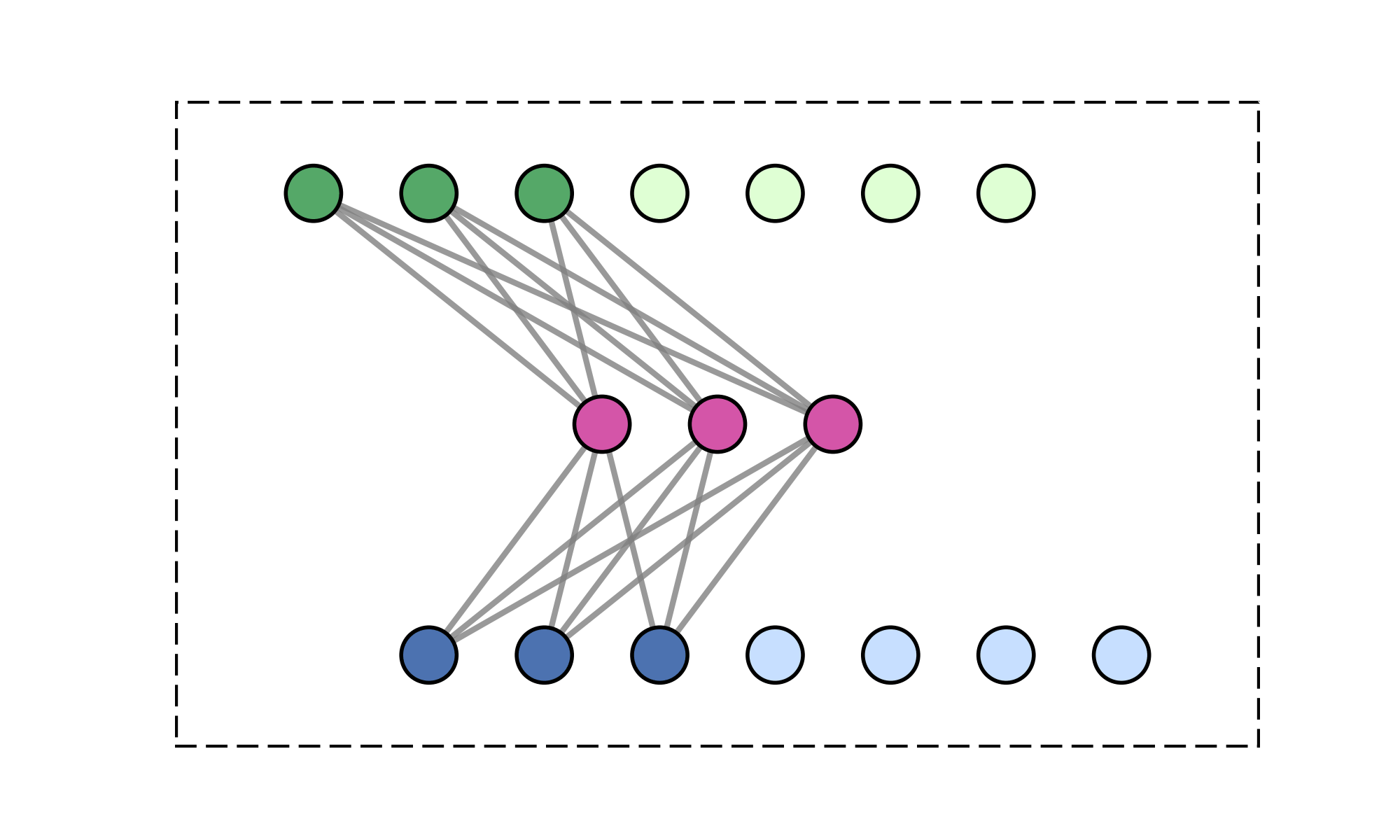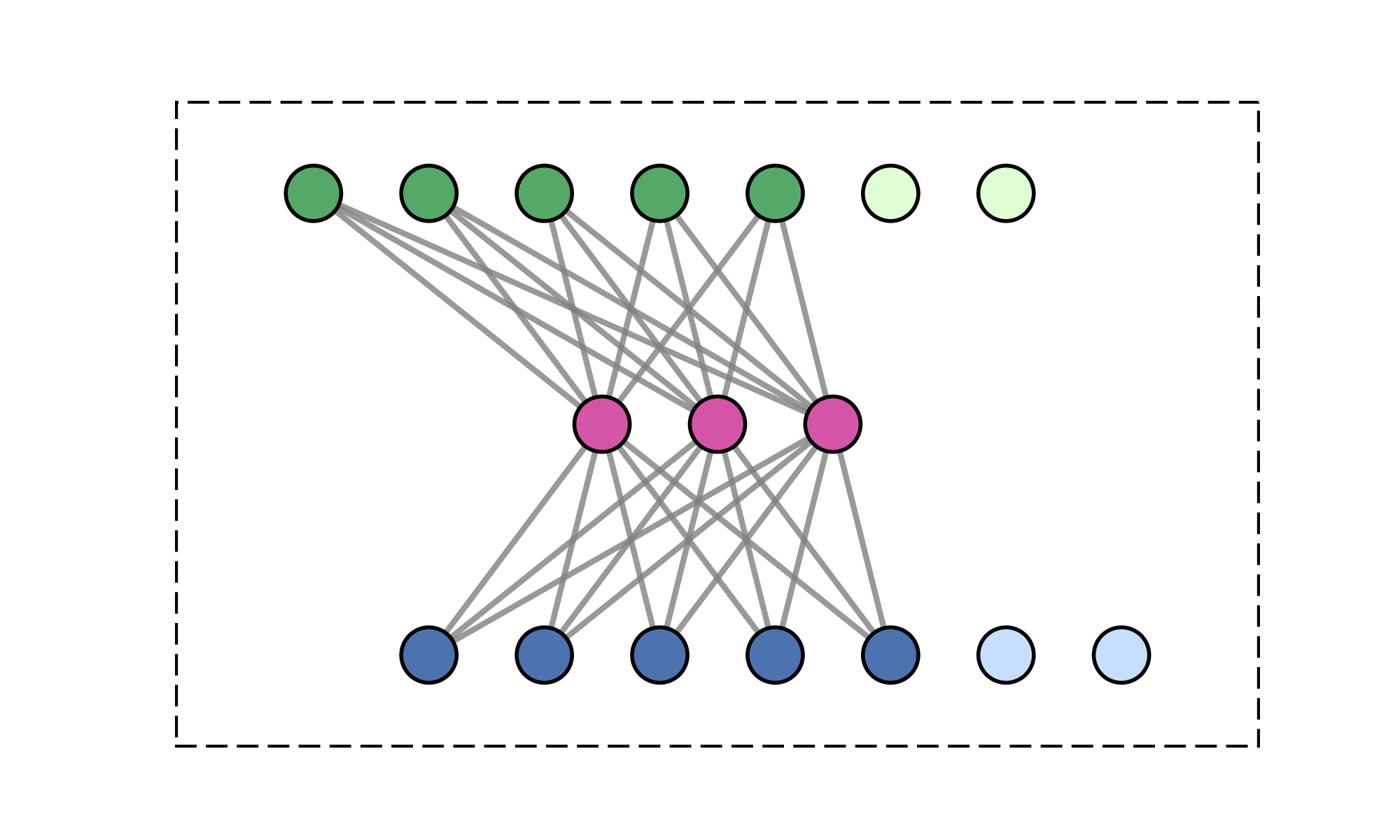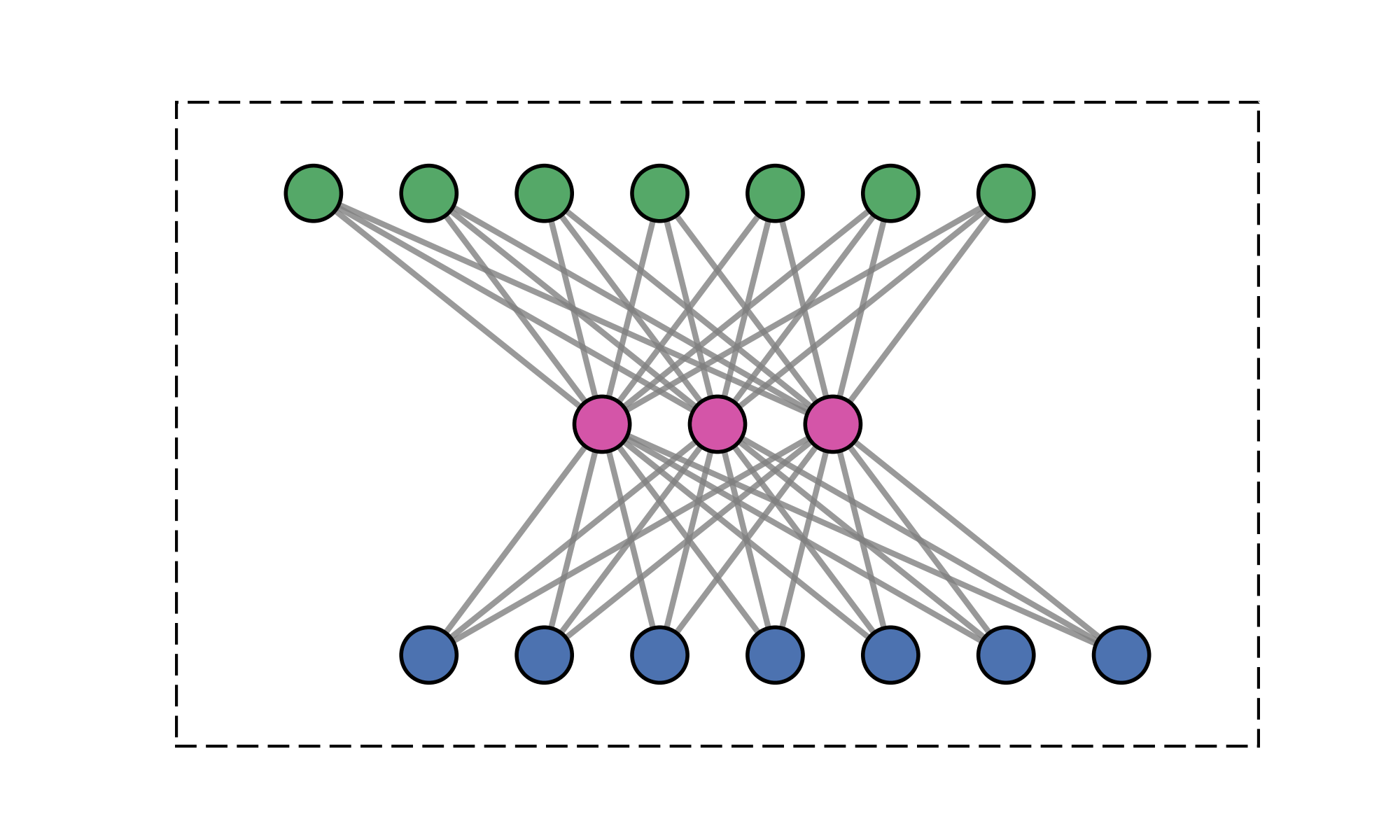
20
\(M\) learned queries
21
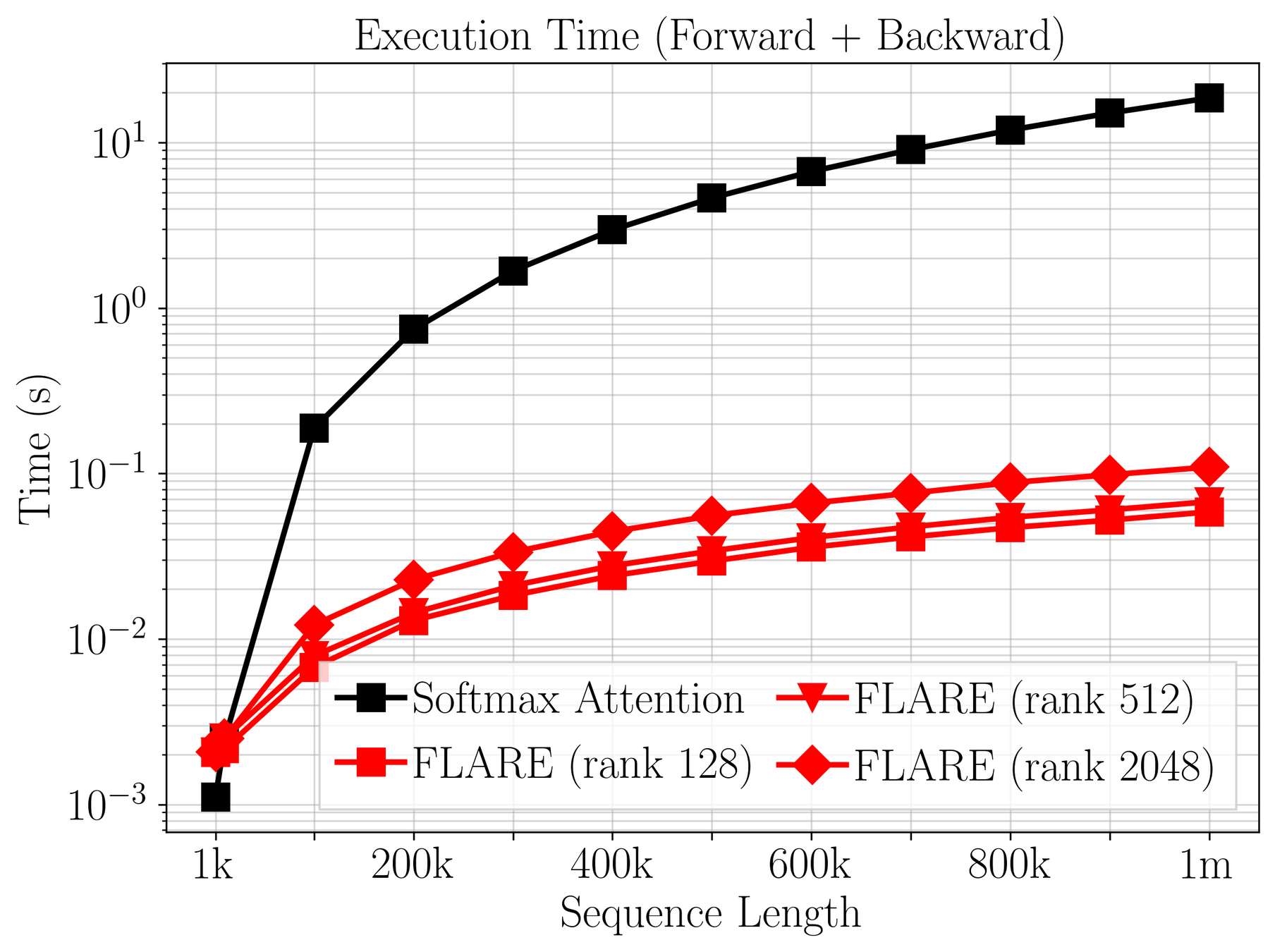
\(\mathcal{O}(2MN) \ll \mathcal{O}(N^2)\)
\(\text{rank}(W_\text{encode}\cdot W_\text{decode}) \leq M\)
\(>200\times\) speedup
\(\text{(} M \text{ tokens)}\)
\(\text{Latent}\)
[1] Vaswani et al. — “Attention Is All You Need”, NeurIPS 2017
\([1]\)
22
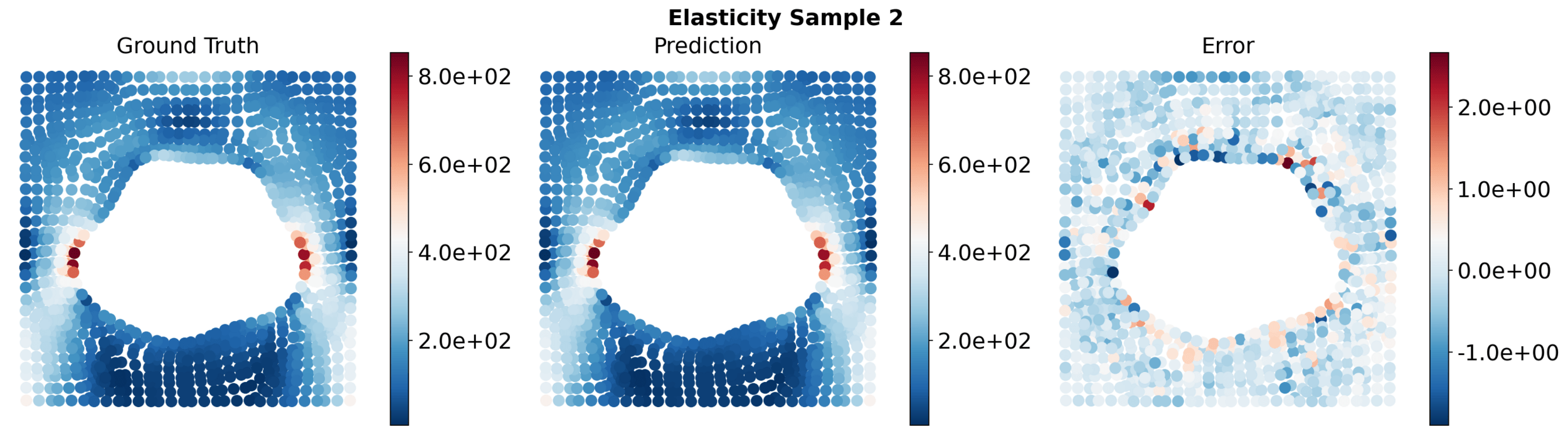
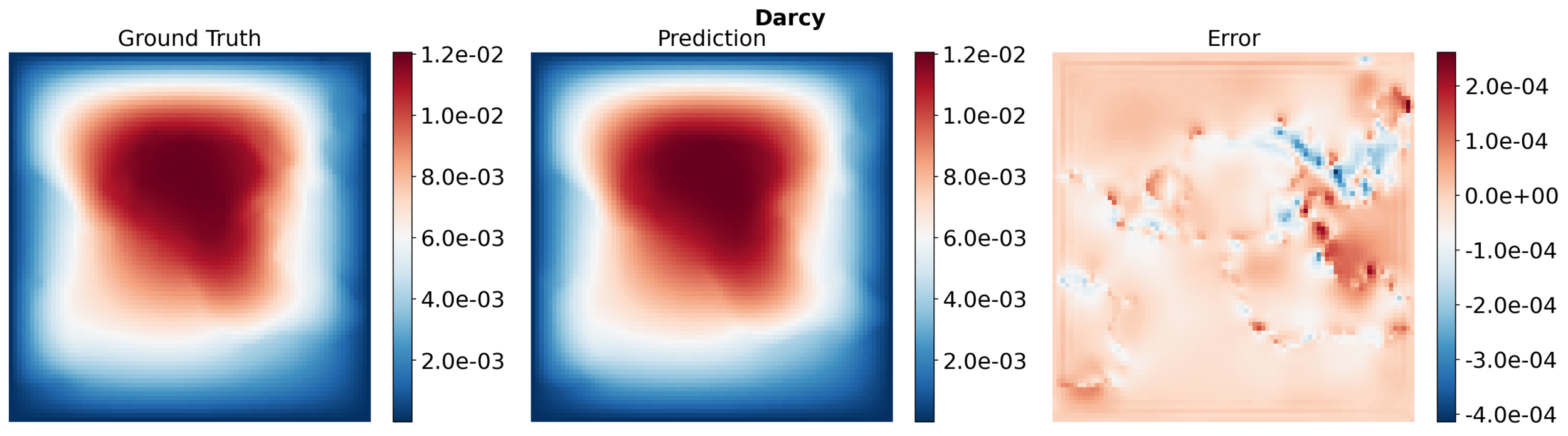
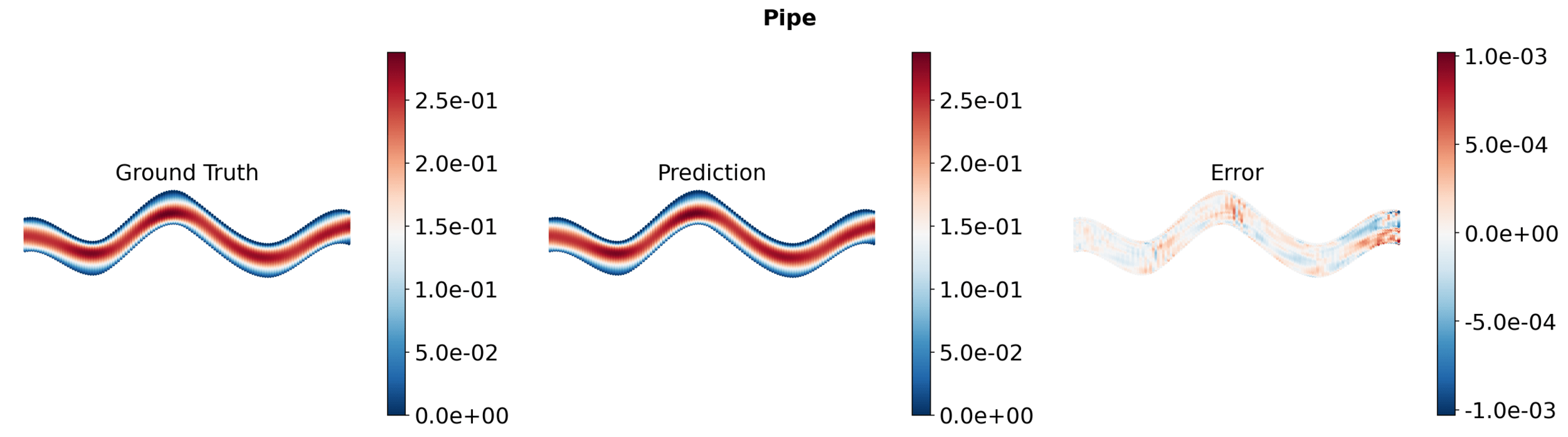
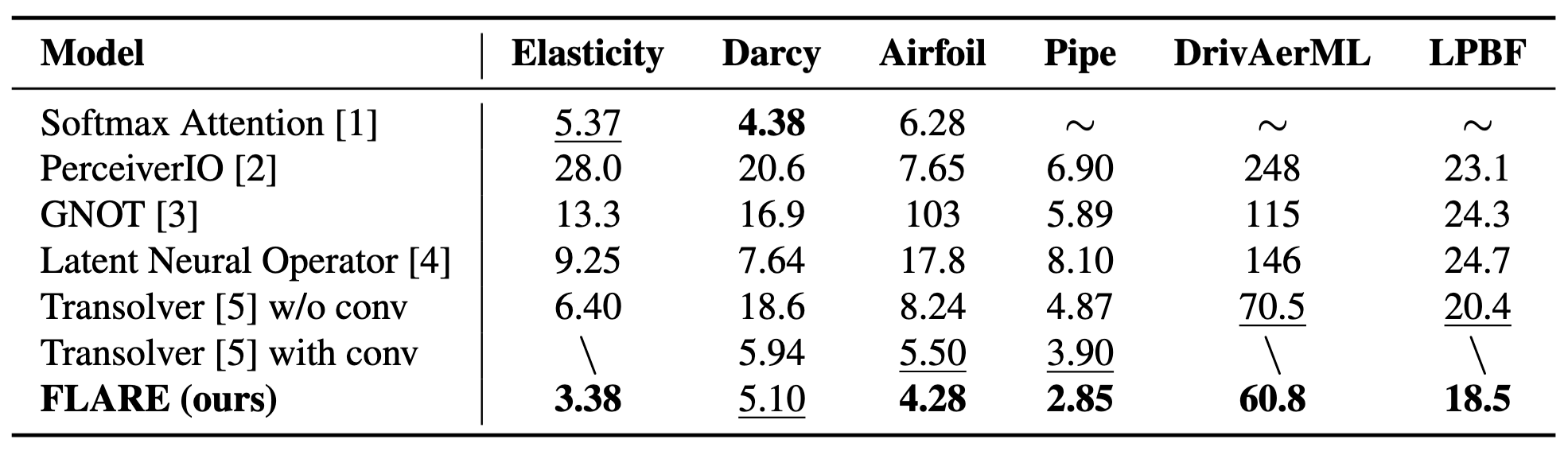
Pipe
Darcy
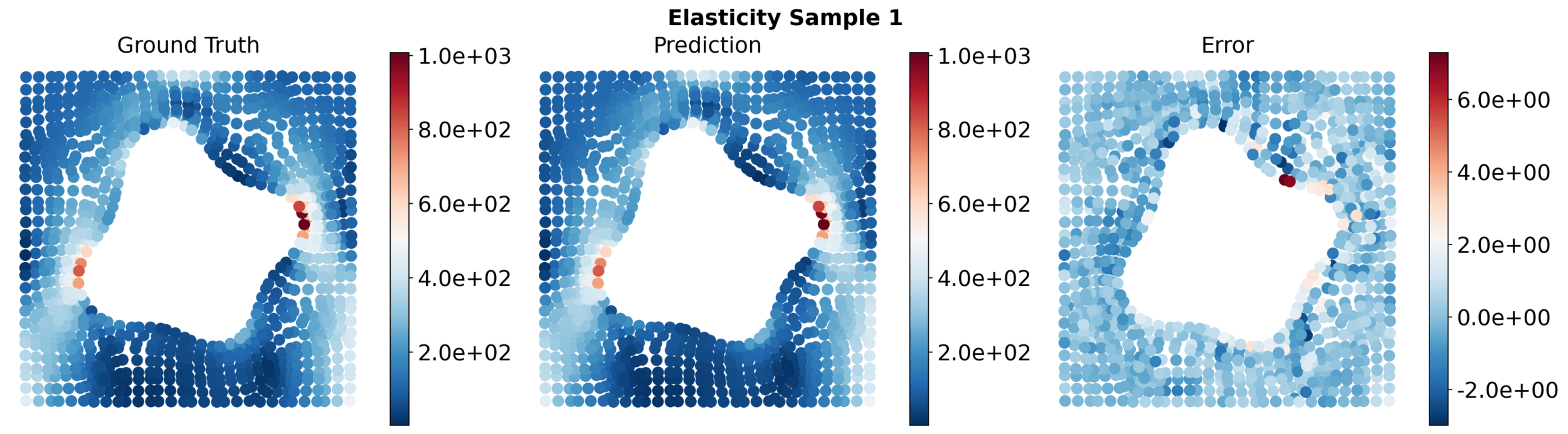
Elasticity
LPBF
DrivAerML
[1] Vaswani et al. — “Attention Is All You Need”, NeurIPS 2017
[2] Jaegle et al. — "PercieverIO: A General Architecture for Structured Inputs & Outputs", ICLR 2022
[3] Hao et al., — "GNOT: A General Neural Operator Transformer for Operator Learning", PMLR 2023
[4] Wang et al. —"Latent Neural Operator", NeurIPS 2024
[5] We et al. — "Transolver: A Fast Transformer Solver for PDEs on General Geometries", ICML 2024
23
24
25
Largest experiment on a single GPU!
26
[1]
[1] Ashton et al. — “DrivAerML: High-Fidelity CFD Dataset for Road-Car Aerodynamics” (arXiv:2408.11969, 2024)
27
Pathfinder
Listops
Image classification
Text sentiment analysis
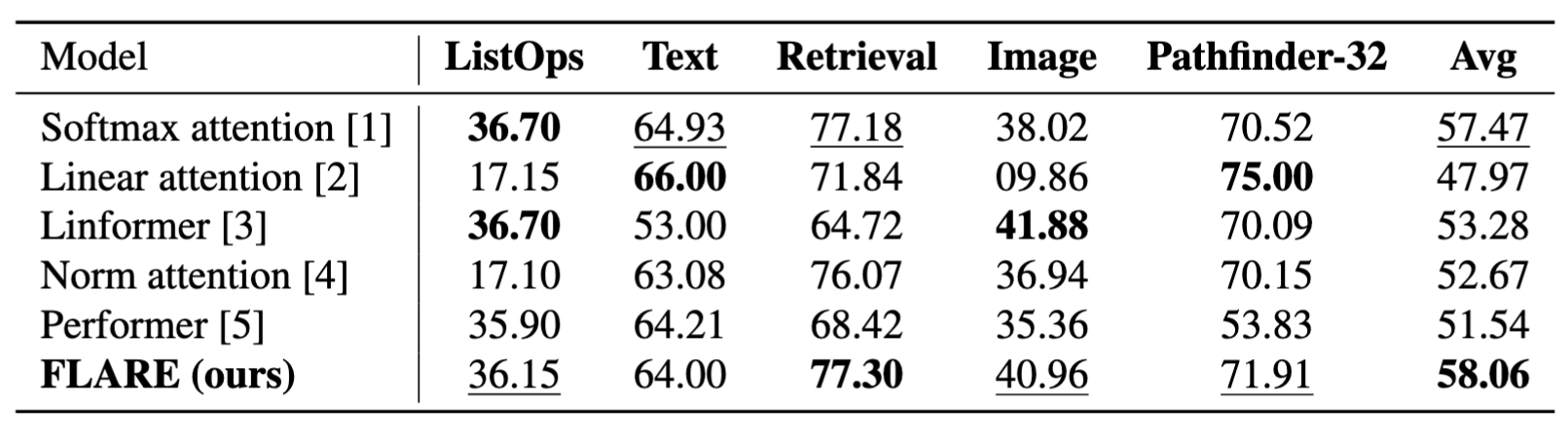
[7]
[8]
[1]
[5]Choromanski et al. — "Rethinking Attention with Performers", ICLR 2021
[6] Tay, Y. et al. — “Long Range Arena: A Benchmark for Efficient Transformers” (arXiv 2020)
[7] Centric Consulting — “Sentiment Analysis: Way Beyond Polarity” (blog)
[8] Krizhevsky — CIFAR dataset homepage
[6]
Accuracy \((\%)\) (higher is better)
[1] Vaswani et al. — “Attention Is All You Need”, NeurIPS 2017
[2] Katharopoulos et al. — "Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention", ICML 2020
[3] Wang et al. — "Linformer: Self-attention with linear complexity", arXiv:2006.04768 2020
[4] Qin et al. — "The devil in linear transformer", arXiv:2210.10340 2022
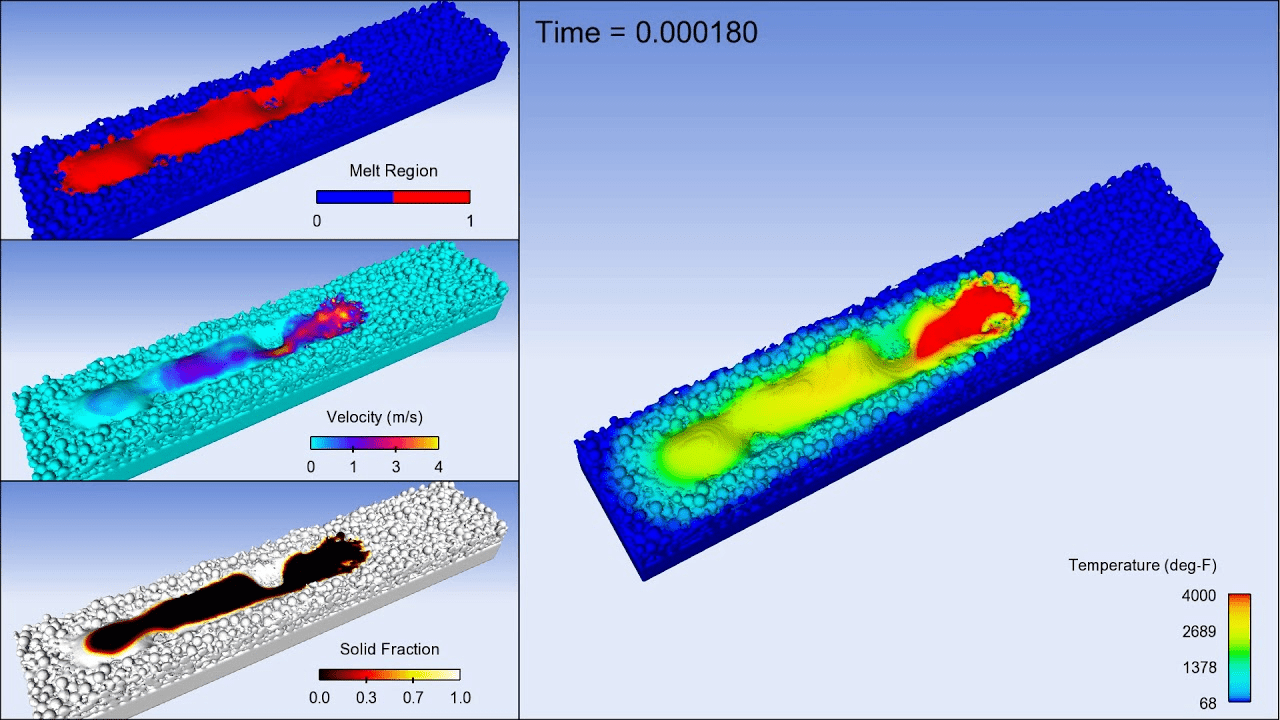
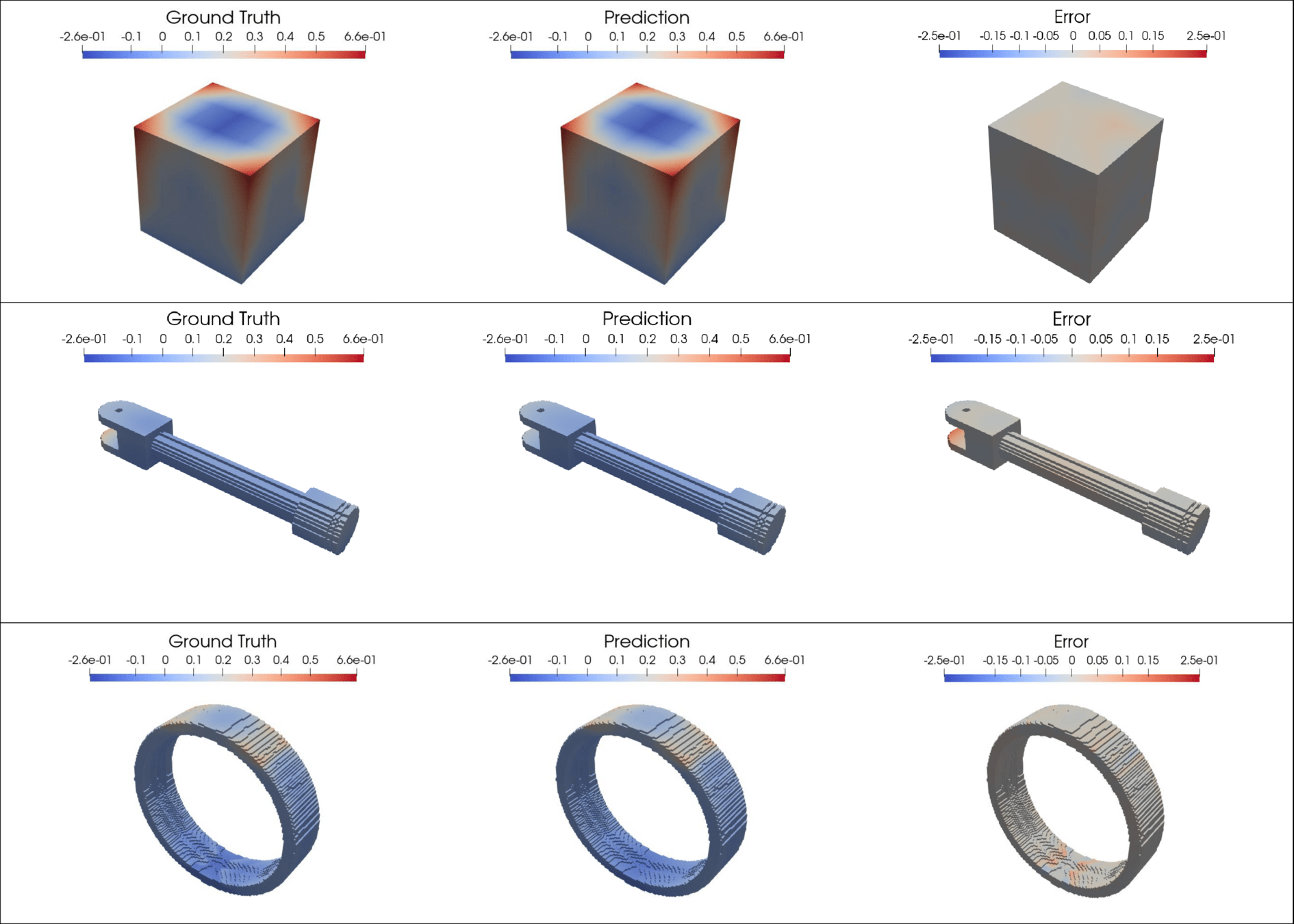
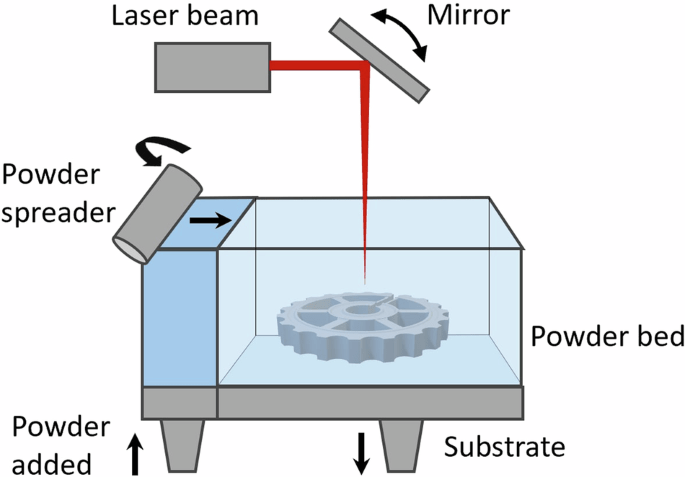
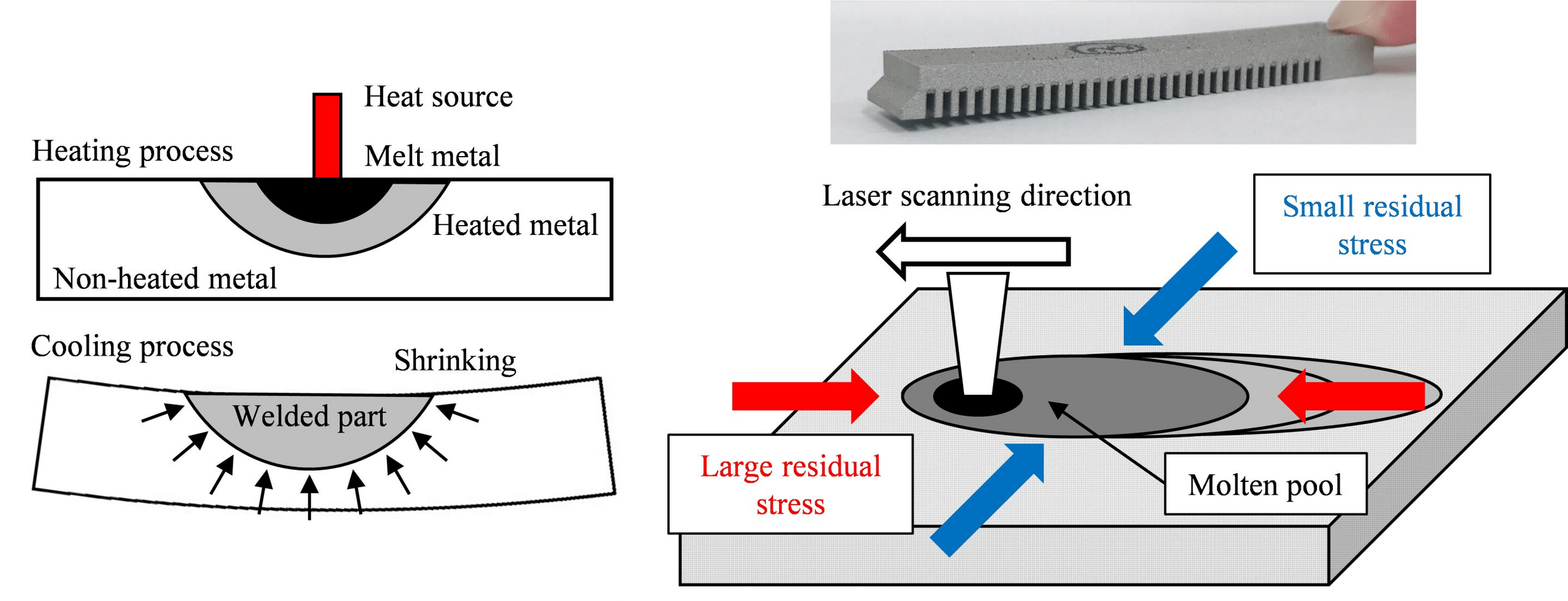
Laser Powder Bed Fusion (LPBF)
Dataset of 20k LPBF calculations
Goal: develop fast surrogate model to predict warpage during build
Governing equations
End results could be deployed as a valuable design tool for metal AM.
28
[1]
[2]
[1] Nature Scientific Data — High-resolution dataset (2025)
[2] TechXplore — “Synergetic optimization reduces residual warpage in LPBF” (2022)
29
30
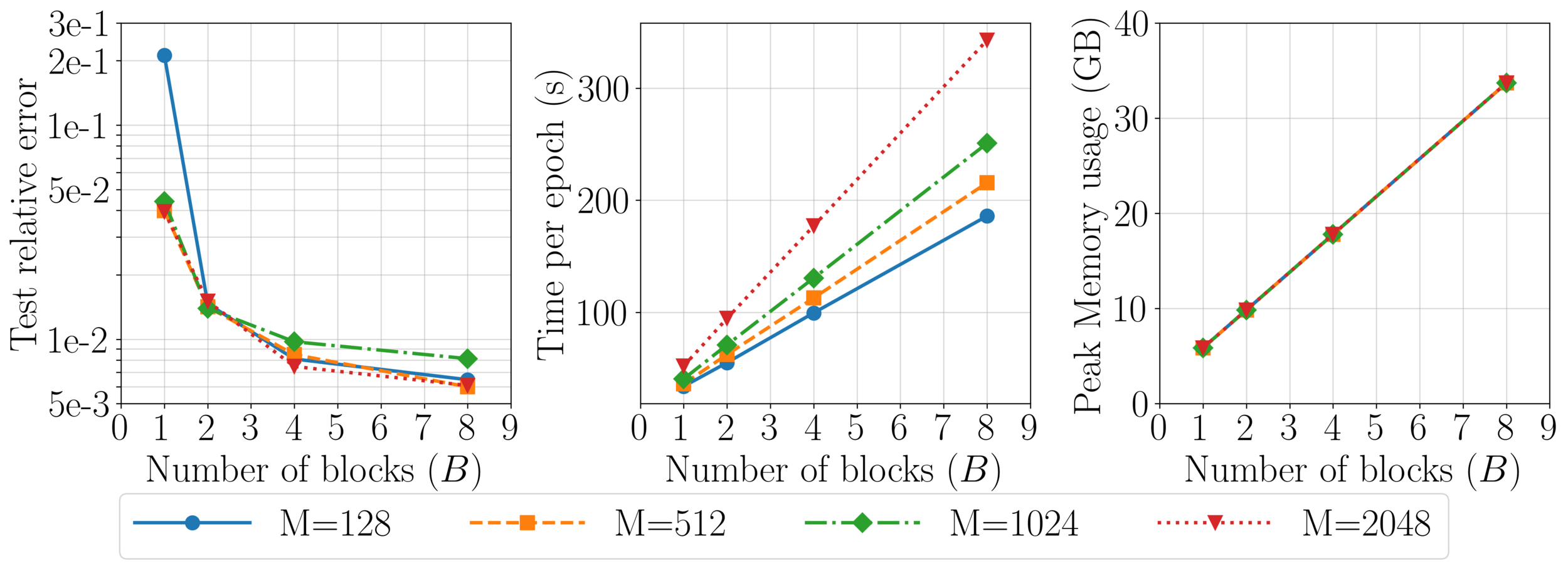
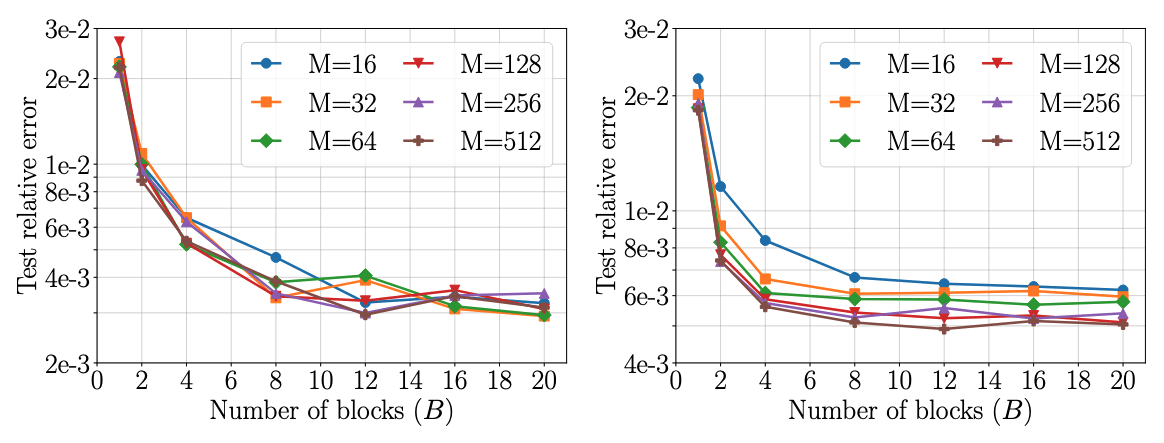
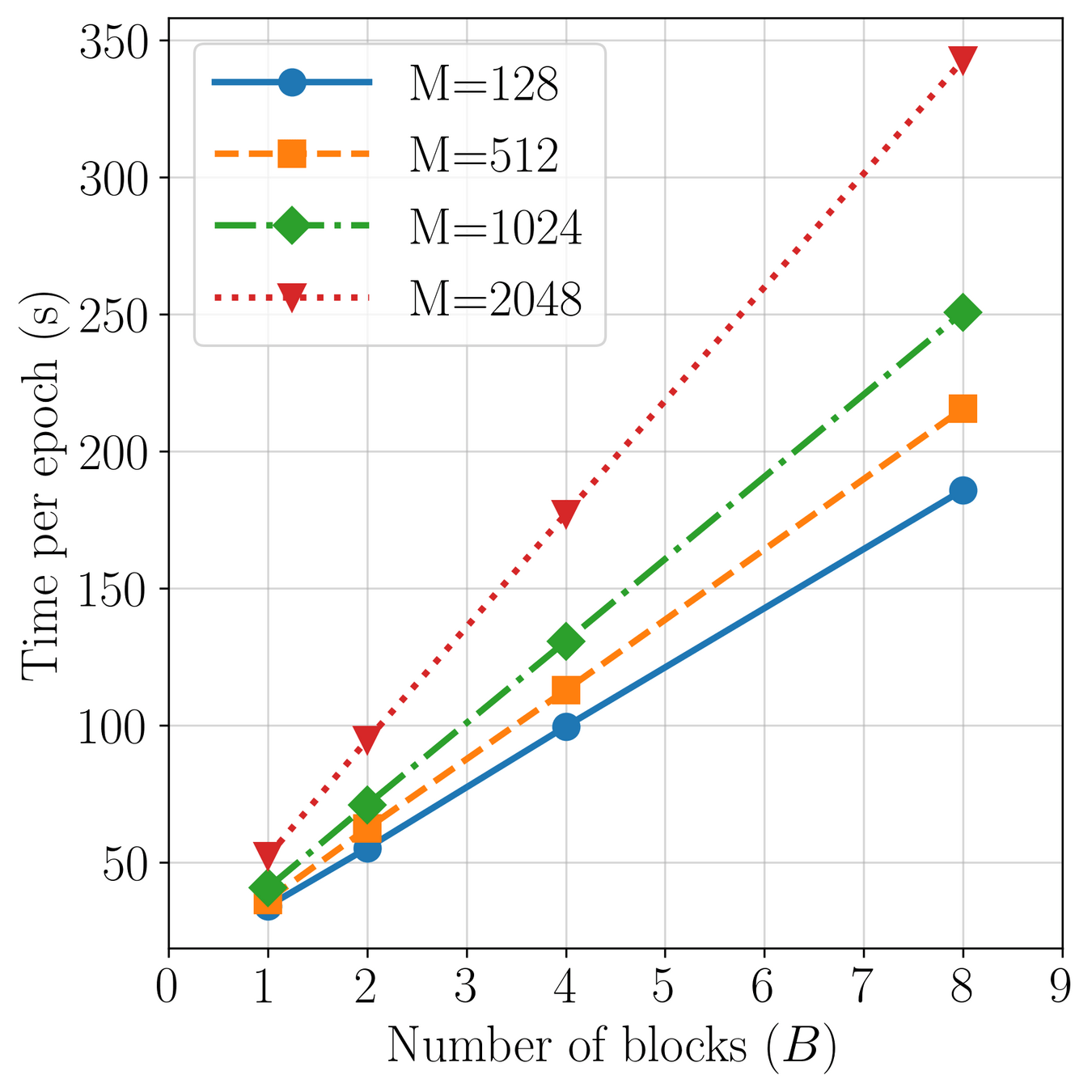
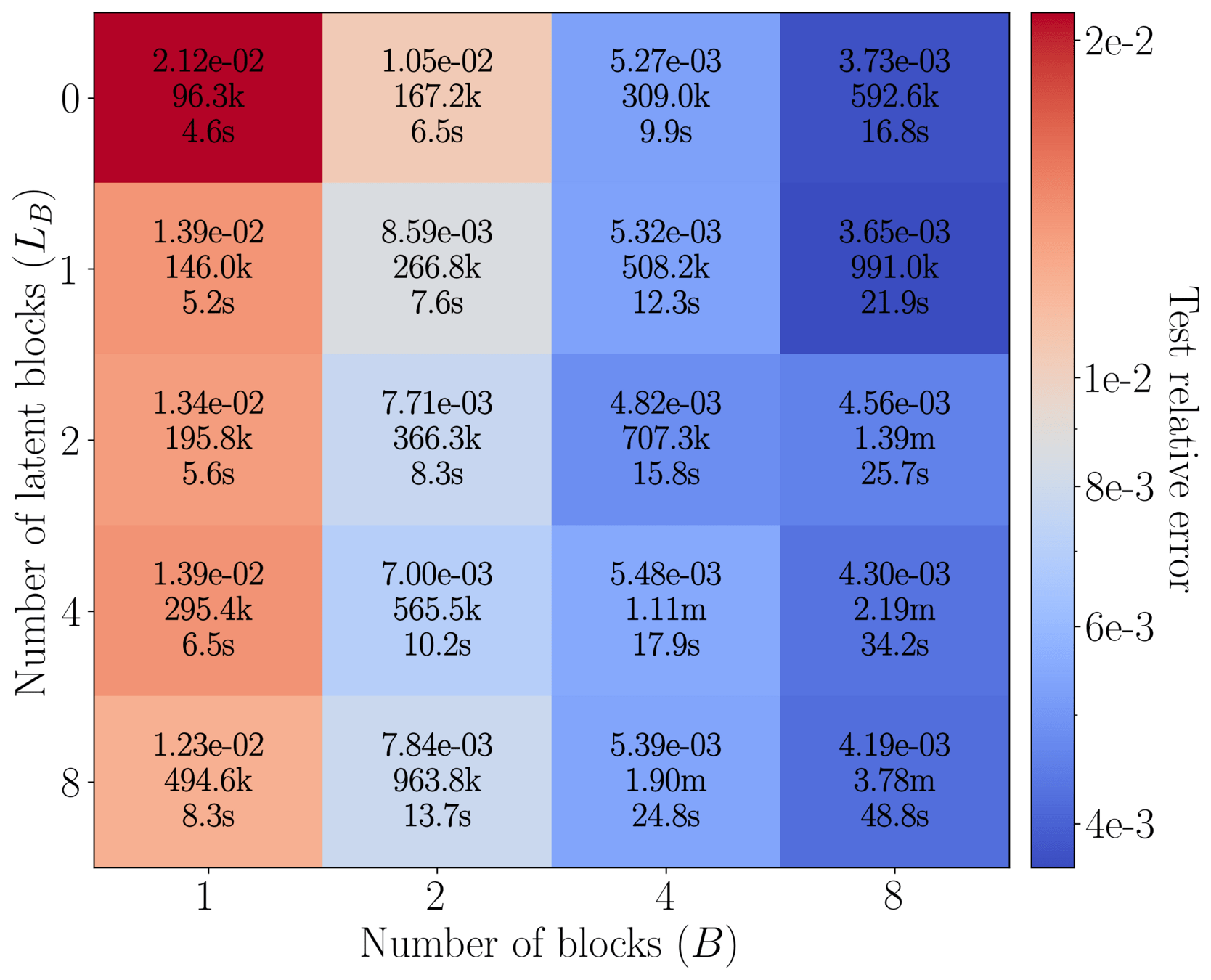
Complexity scales with latents (\(M\)): \(\mathcal{O}(2MN)\)
Accuracy increases with \(M\)
Method: progressively increase latents (\(M\)) through training.
Challenge: Minimize loss spikes, training instabilities.
Token mixing [1] (\(\mathcal{O}(N^2)\))
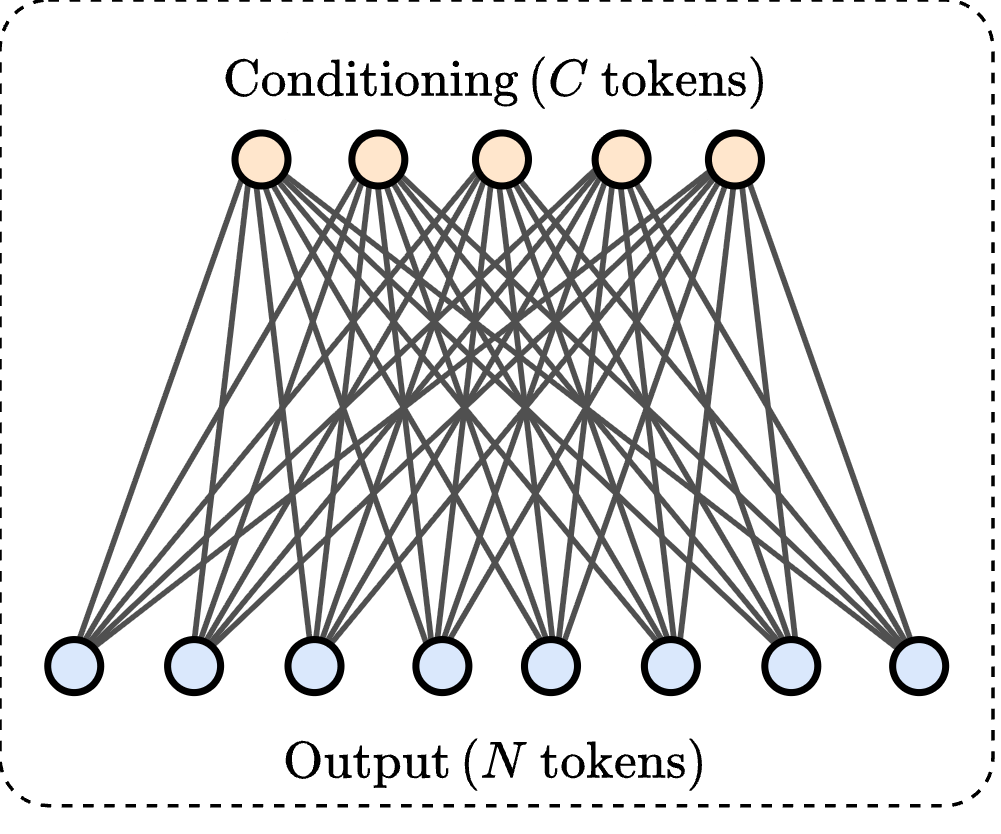
Conditioning [1] (\(\mathcal{O}(N\cdot C)\))
Token mixing
Token mixing
Conditioning
31
[1] Vaswani et al. — “Attention Is All You Need”, NeurIPS 2017
Key idea: Modulate token-mixing with conditioning tokens
Cross FLARE
32
\(\mathcal{O}(2MN + MC) \) complexity
All previous key/value \(\{k_\tau, v_\tau \}_{\tau \leq t}\) must be cached on the GPU.
Major memory and latency bottleneck!
33
[1] Vaswani et al. — “Attention Is All You Need”, NeurIPS 2017
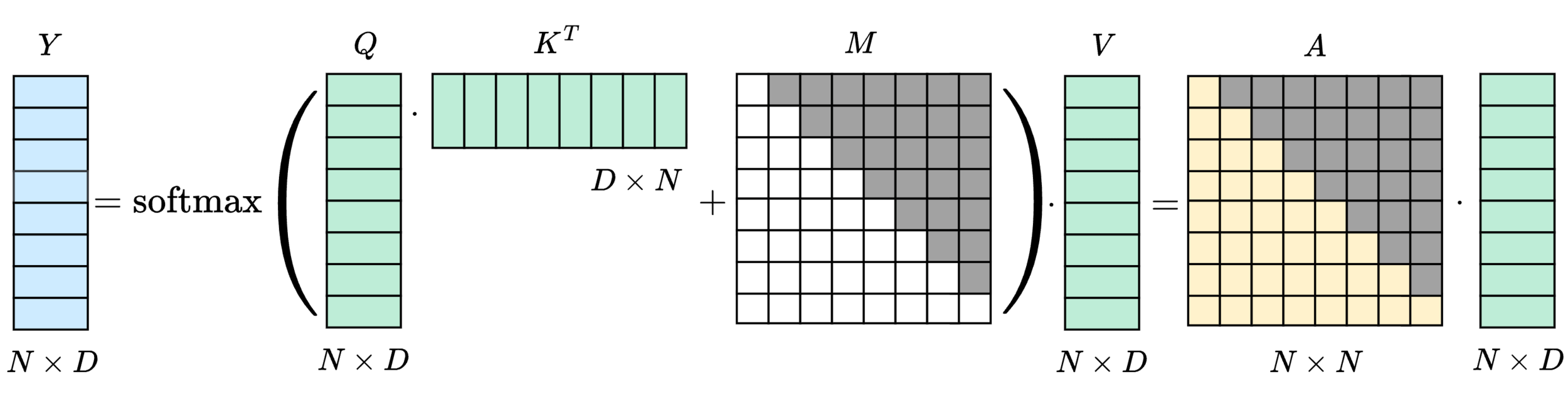
Training algorithm (causal masking)
Inference algorithm (recurrence relation)
Dot-products need to be recomputed for every \(q_t\).
\(\mathcal{O}(N^2)\) complexity.
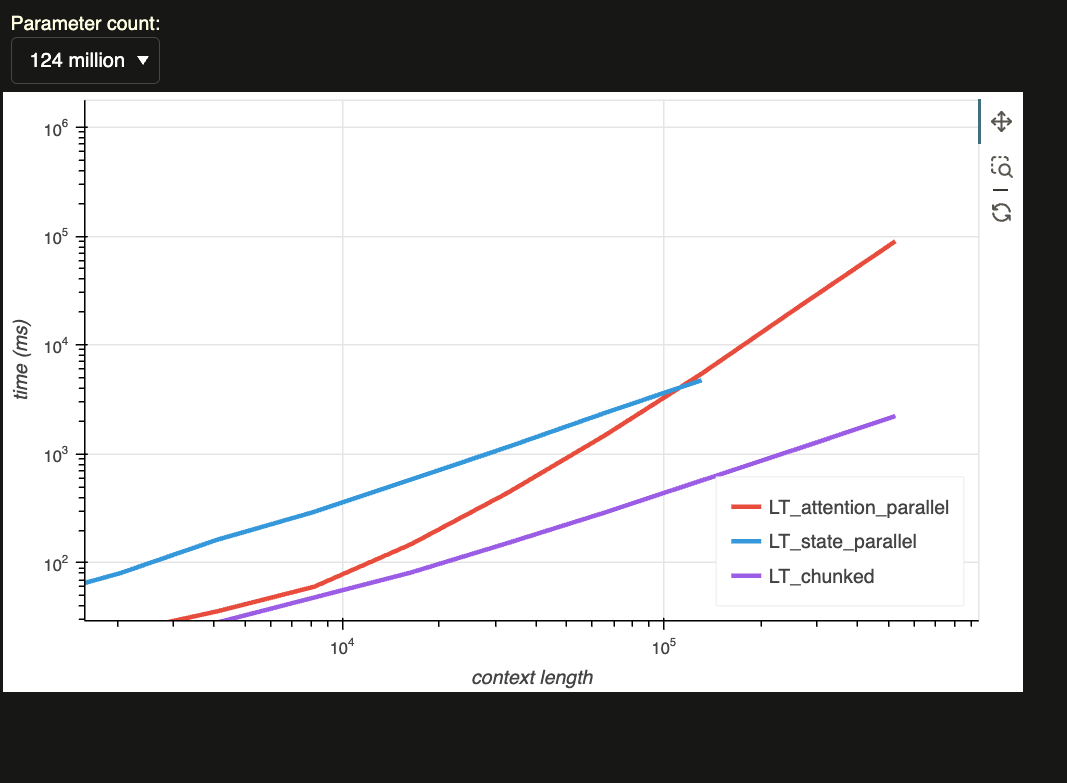
Linear time auto-regressive attention.
Fixed memory footprint (only store \(\mathcal{O}(M)\) cache).
Flexible latent capacity.
Advantages
Required components
Fused GPU kernels for training and inference.
Bespoke training algorithm for causal FLARE.
Extensive benchmarking and evaluation.
34
Inference algorithm (recurrence rule)
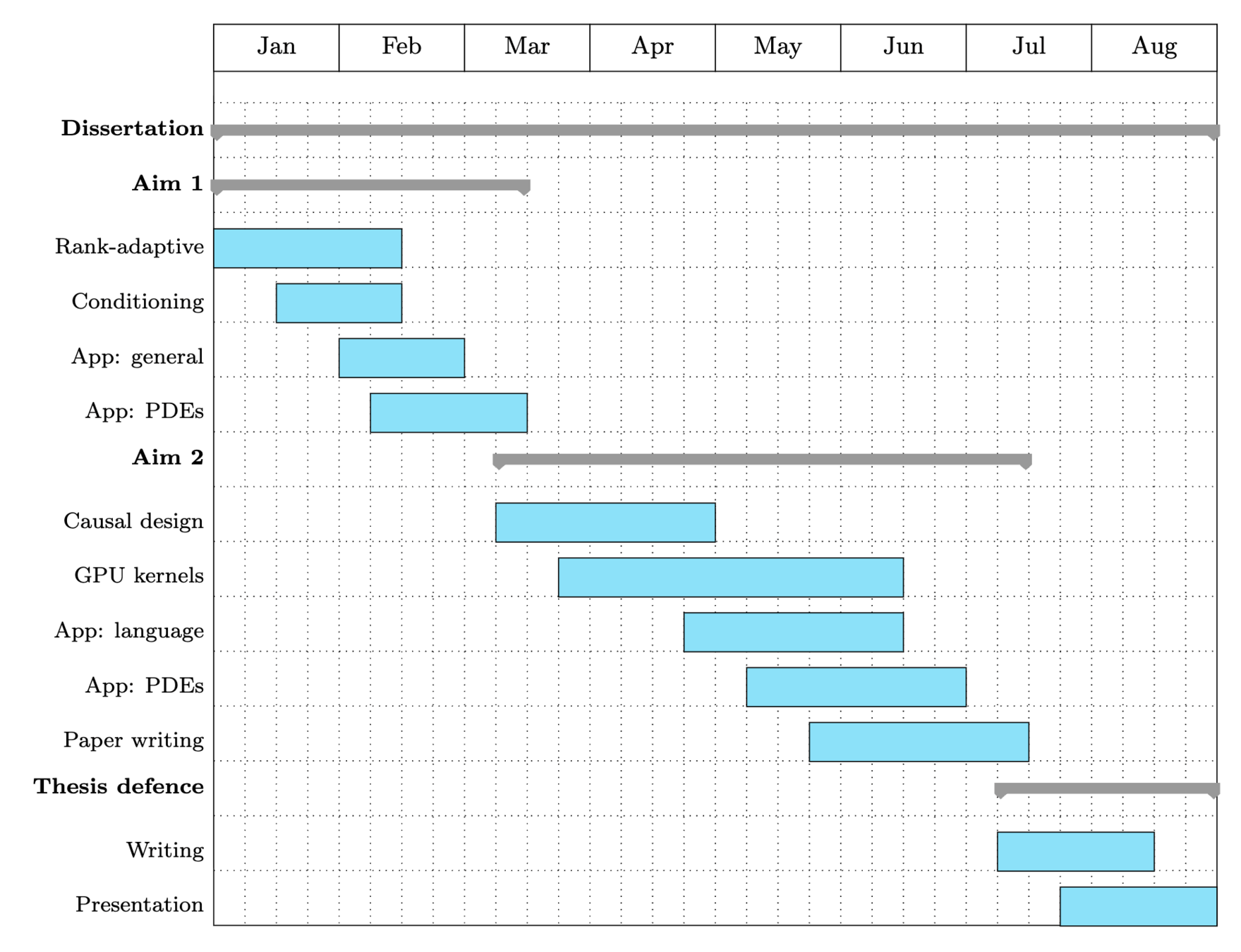
Expected graduation: Summer 2026
35
Fast and accurate latent space traversal in neural ROMs
Scalable and accurate self attention mechanism
Flexible and scalable cross-attention mechanism
Efficient and flexible decoder model.
36
Puri, Vedant, Aviral Prakash, Levent Burak Kara, and Yongjie Jessica Zhang. "SNF-ROM: Projection-based nonlinear reduced order modeling with smooth neural fields." Journal of Computational Physics 532 (2025): 113957.
Puri, Vedant, Aditya Joglekar, Kevin Ferguson, Yu-hsuan Chen, Yongjie Jessica Zhang, and Levent Burak Kara. "FLARE: Fast Low-rank Attention Routing Engine." arXiv preprint arXiv:2508.12594 (2025).
(In preparation)
37
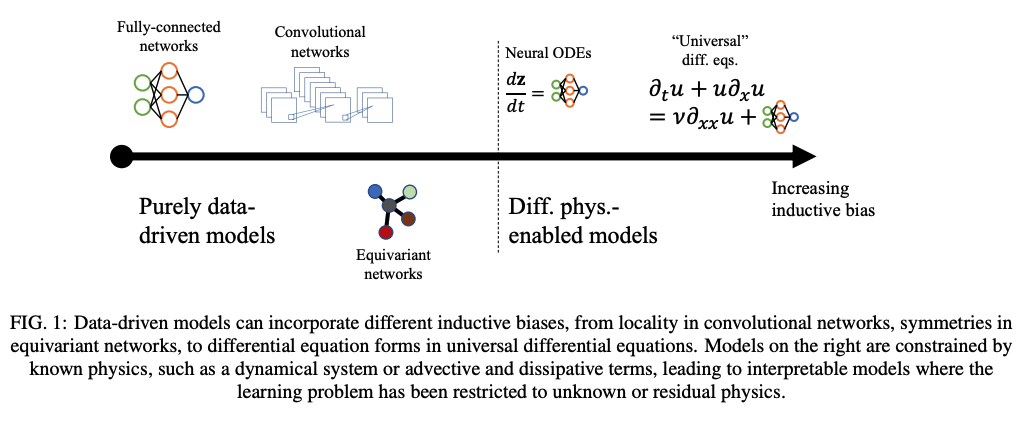
Landscape of ML for PDEs
Mesh ansatz
PDE-Based
Neural Ansatz
Data-driven
FEM, FVM, IGA, Spectral
Fourier Neural Operator
Neural Field
DeepONet
Physics Informed NNs
Convolution NNs
Graph NNs
Adapted from Núñez, CEMRACS 2023
Neural ODEs
Universal Diff Eq
Reduced Order Modeling
| Orthogonal Functions | Deep Neural Networks |
|---|---|
|
|
|
|
|
|
|
|
\( N \) parameters, \(M\) points
\( h \sim 1 / N \) (for shallow networks)
\( N \) points
\( \dfrac{d}{dx} \tilde{f}\sim \mathcal{O}(N^2) \) (exact)
\( \dfrac{d}{dx} \tilde{f} \sim \mathcal{O}(N) \) (exact, AD)
\( \int_\Omega \tilde{f} dx \sim \mathcal{O}(N) \) (exact)
(Weinan, 2020)
\( \int_\Omega \tilde{f} dx \sim \mathcal{O}(M) \) (approx)
Model size scales with signal complexity
Model size scales exponentially with dimension
\( N \sim h^{-d/c} \)
FEATURES
DEMONSTRATIONS
Challenge: Learn PDE surrogate on 5-10 m points on multiGPU cluster
Linear transformers replace the softmax kernel with a feature map \(\phi(\cdot)\) such that
This factorization allows causal attention to be computed recurrently:
https://manifestai.com/articles/linear-transformers-are-faster/
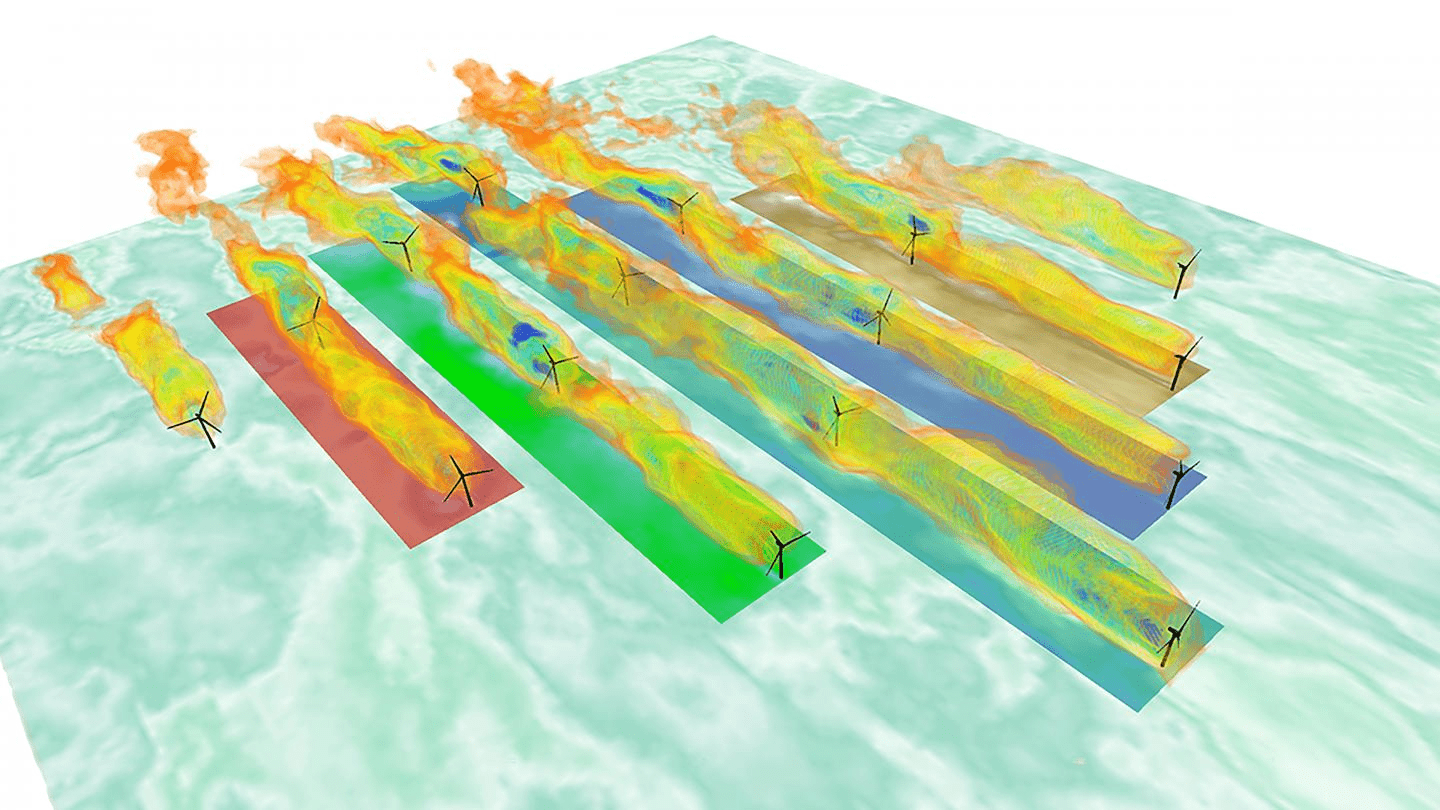
Mesosphere
Wind farm
Turbine
Blade
1
Modern engineering is reliant on computer simulations
Design space exploration
Predictive maintenance
[1]
[2]
Under review at Int'l Conf. Learning Representations
Scalable and accurate self attention mechanism
Model must capture spatial structure and temporal evolution.
Increases training data by an order of magnitude.
Time-stepping logic may cause drift from ground truth.
24
Message-passing is fundamentally low-rank
25
8
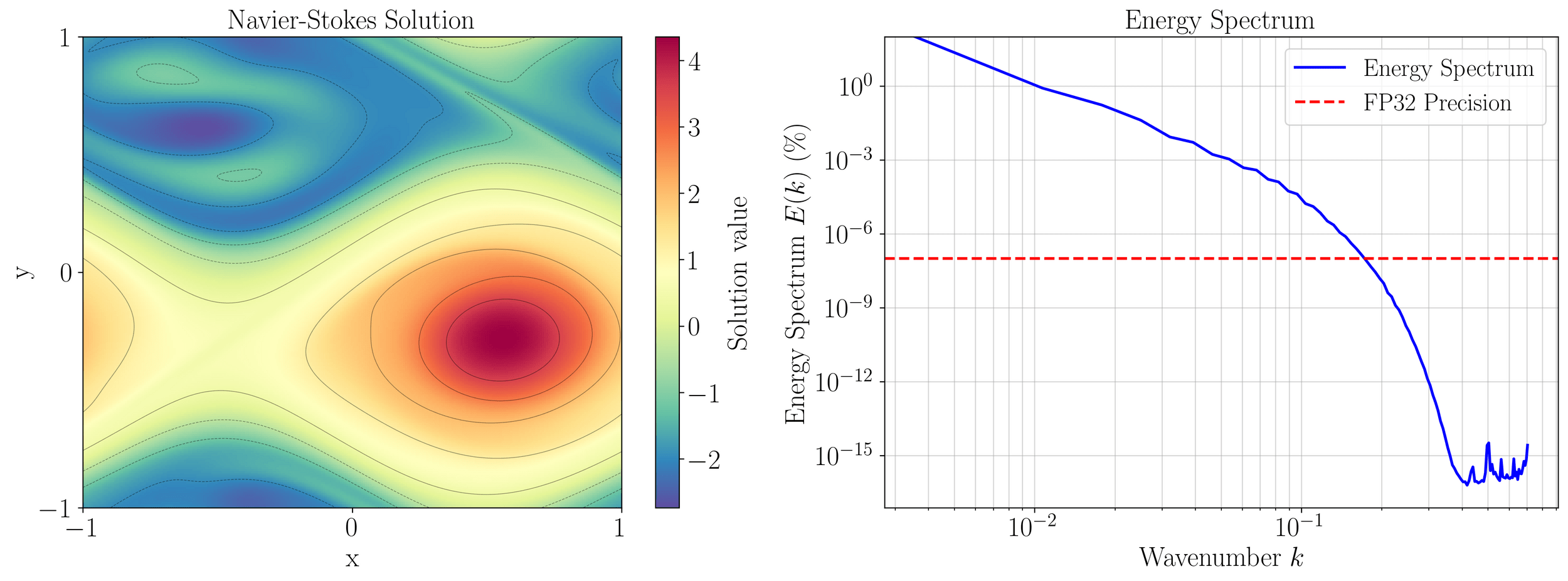
2D Viscous Burgers problem \( (\mathit{Re} = 1\text{k})\)
\(199\times\) speed-up
High freq. noise
Non-differentiable!
Accurately capture of dynamics with smooth neural fields
Large deviations!
Learning smooth latent space trajectories
\(\text{Autoencoder ROM}\)
\(\text{SNF-ROM (ours)}\)
Evolution of ROM states
No deviation
Accurate capture of dynamics
\(\text{DoFs: }524~k \to 2\)
2
Full order model (FOM)
Linear POD-ROM
Nonlinear ROM
Learn low-order spatial representations
Time-evolution of reduced representation with Galerkin projection
13
\(\text{CAE-ROM}\) [1]
\(\text{SNFL-ROM (ours)}\)
\(\text{SNFW-ROM (ours)}\)
\(\text{Relative error }\)
[1] Lee & Carlberg — Nonlinear manifold ROM via CNN autoencoders (JCP 2020)
\([1]\)
By Vedant Puri
Vedant Puri's thesis proposal at Carnegie Mellon University




