

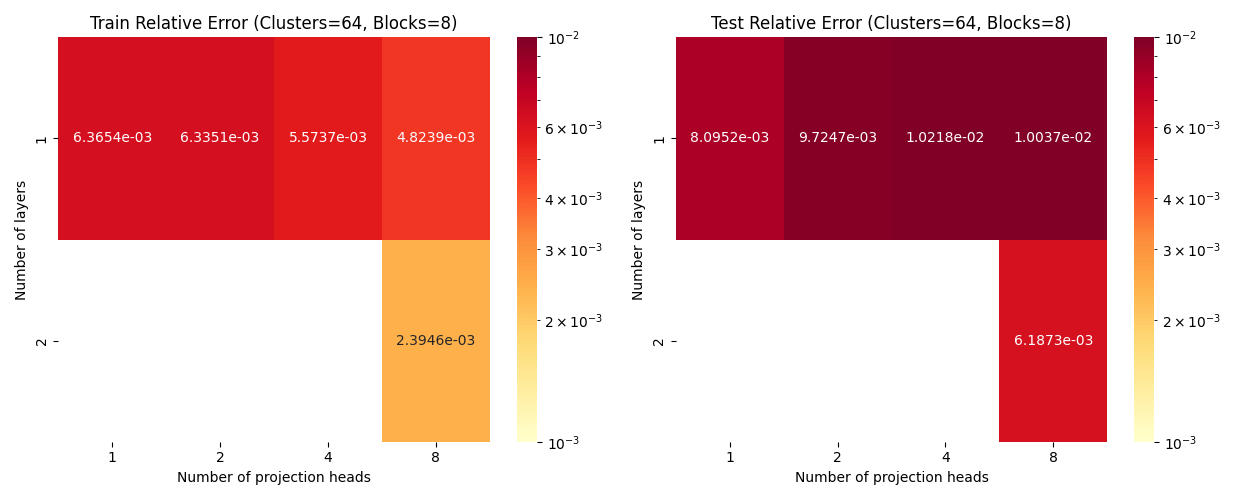




Vedant Puri
PhD student at Carnegie Mellon University
Mechanical Engineering, Carnegie Mellon University
Advisors: Prof. Burak Kara, Prof. Jessica Zhang
Mechanical Engineering, Carnegie Mellon University
Advisors: Prof. Burak Kara, Prof. Jessica Zhang
ML surrogates for biomedical applications
Modeling dynamical deformation in LPBF with neural network surrogates
0.0153
0.0092
| ShapeNet Car |
- | |||||||
|---|---|---|---|---|---|---|---|---|
| LNO | 0.0029 | 0.0049 | 0.0026 | 0.0845 | - | - | ||
| CAT (ours) | 0.00315 | - | - | - | - | 0.00590 | 0.0637 | - |
|
Transolver w/ conv Transolver w/o conv |
/ 0.0064 |
- - |
0.0055 0.0082 |
- - |
- - |
0.00594 0.014313 |
/ 0.0760 |
/ - |
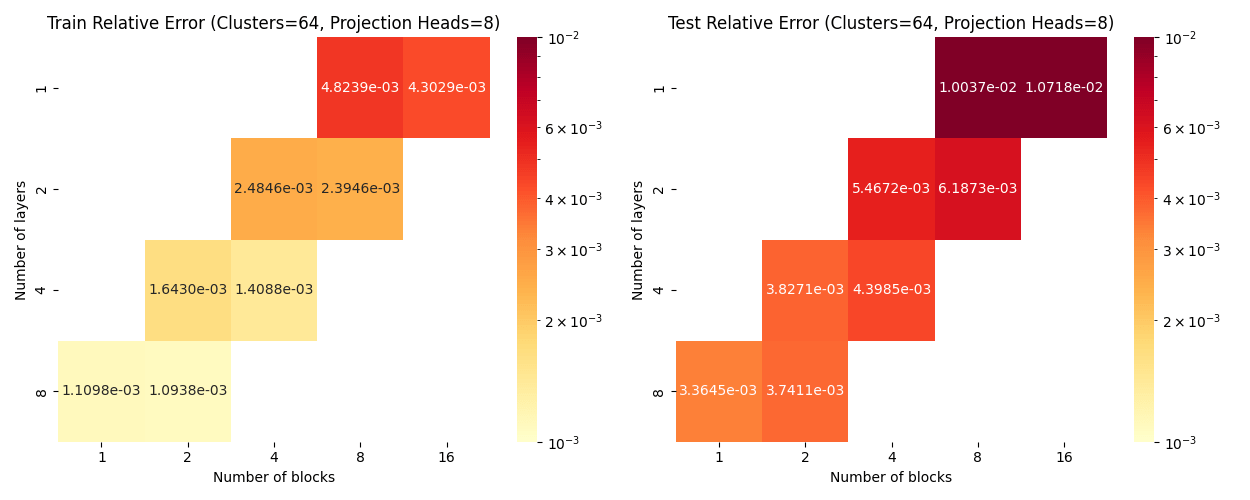
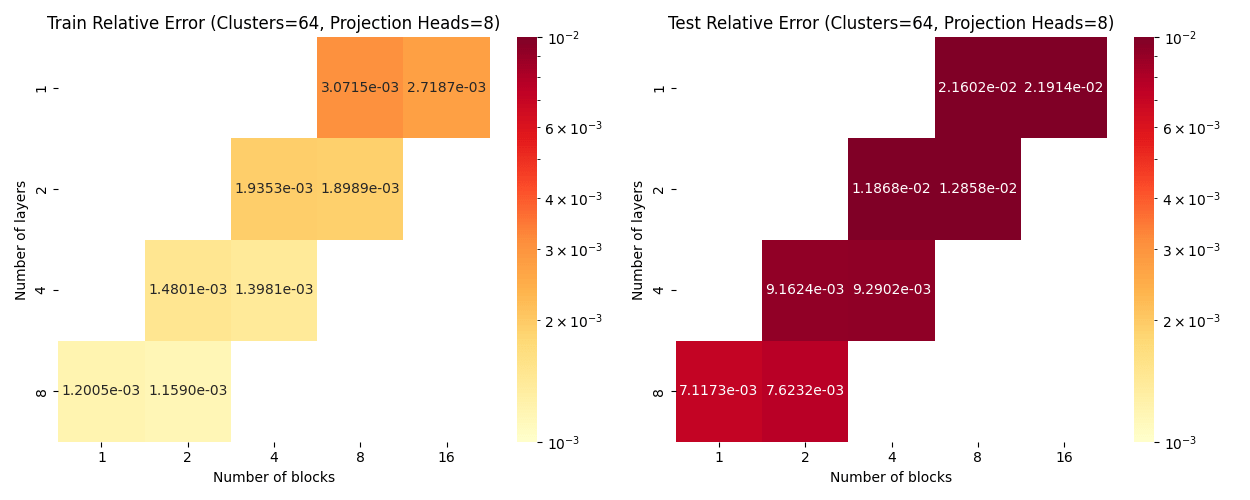
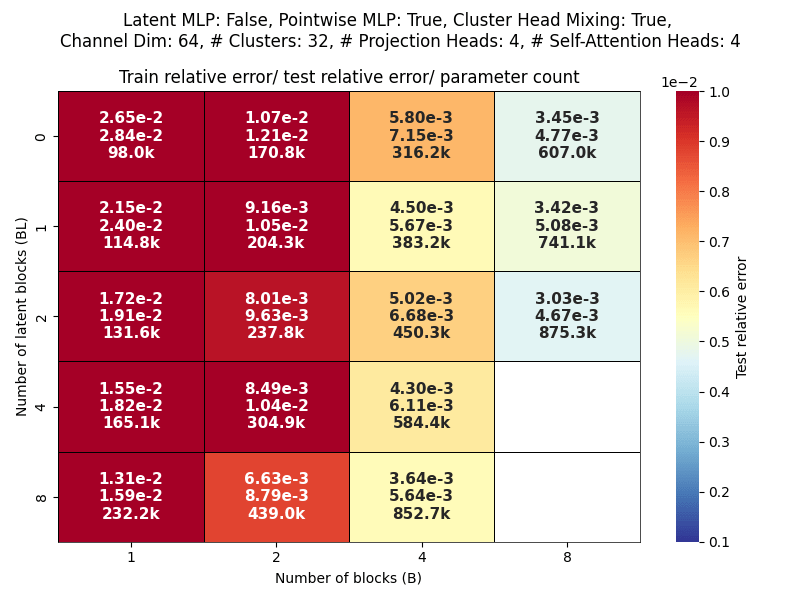
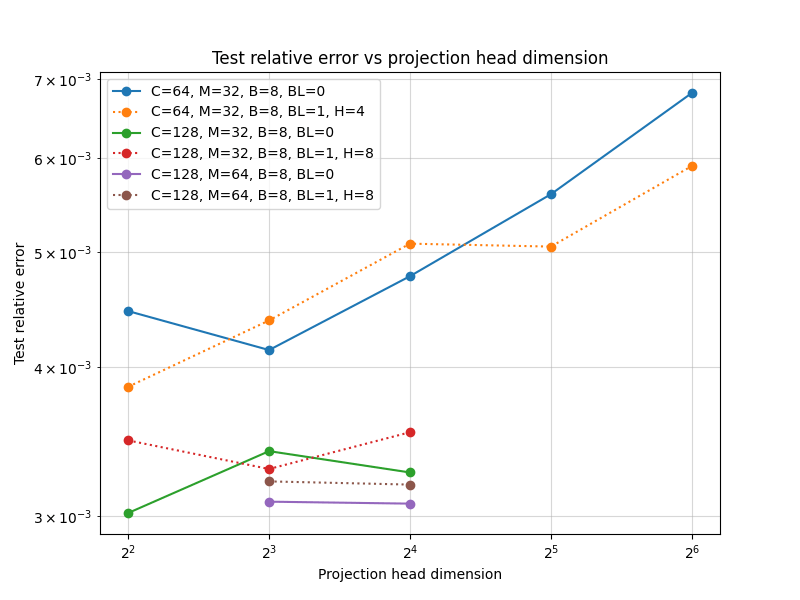
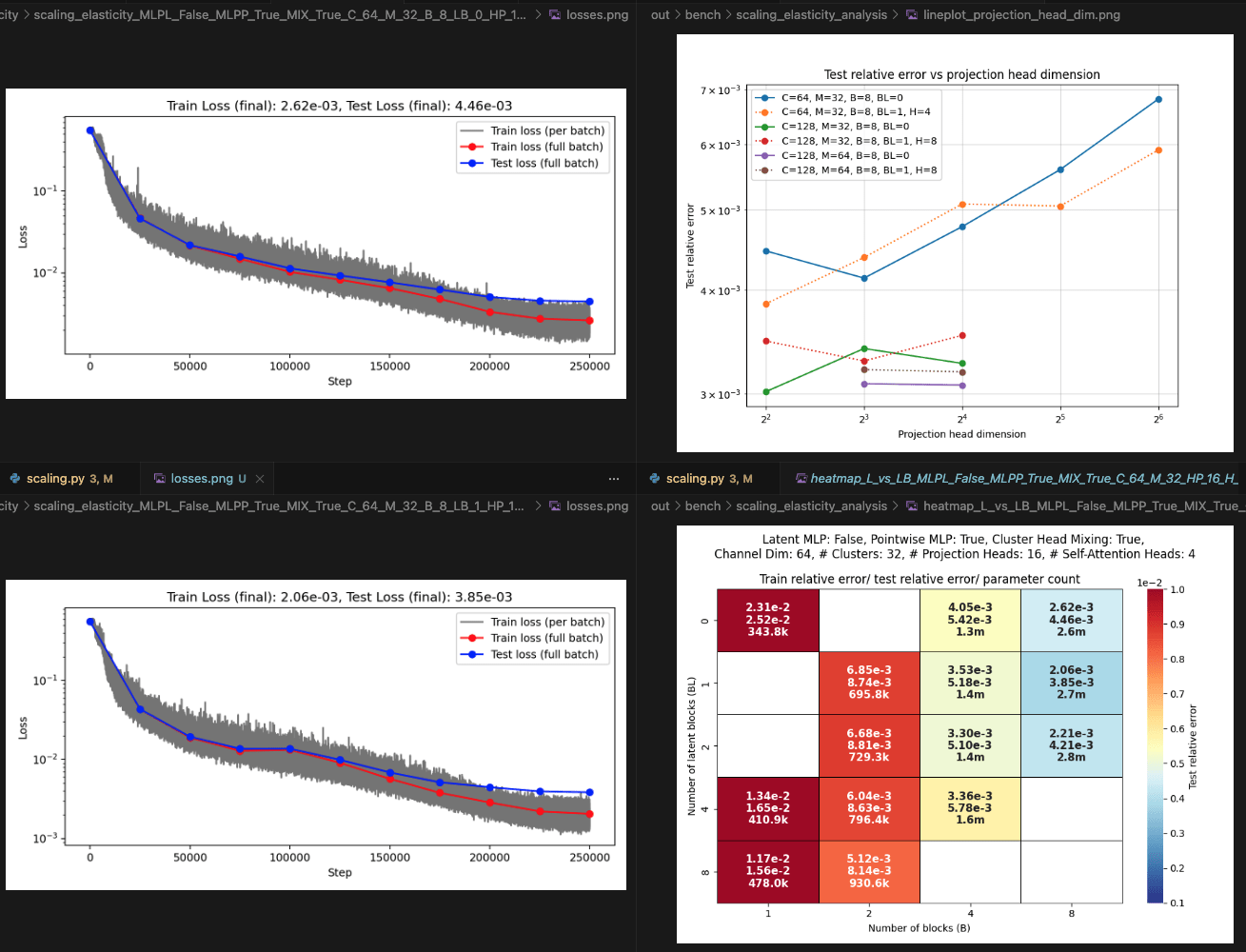
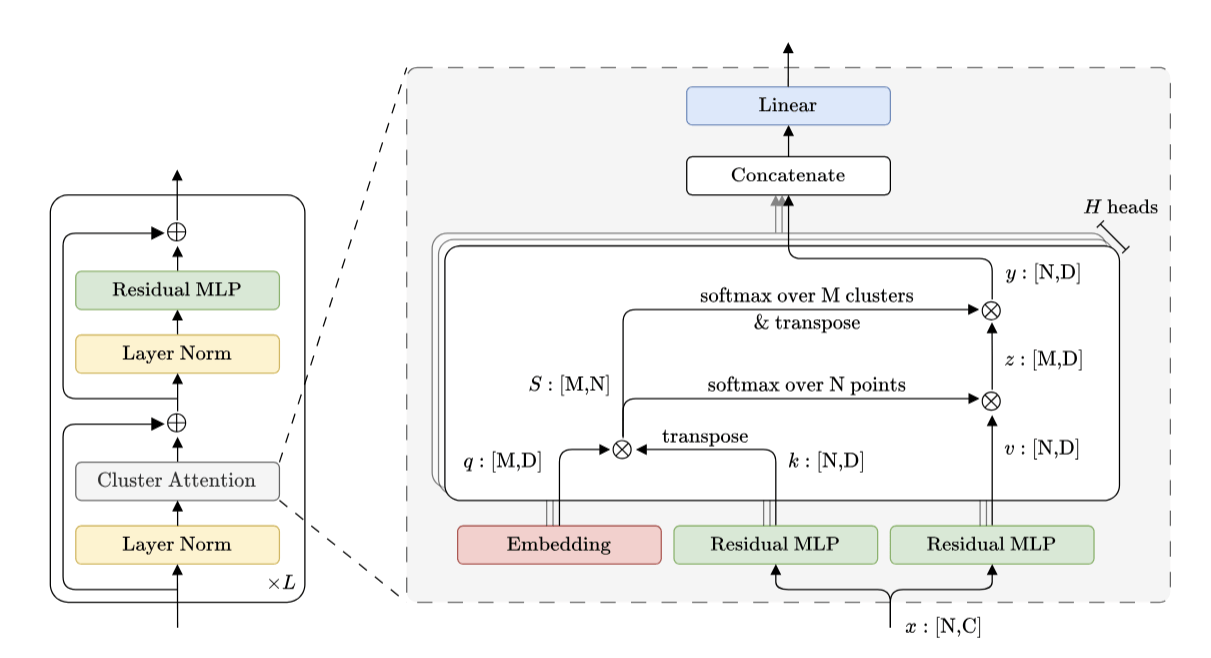
Layers: Number of projections (latent encoding / decoding operations)
Blocks: Number of attention blocks in latent space in each layer.
Layers: Number of projections (latent encoding / decoding operations).
Blocks: Number of attention blocks in latent space in each layer.
Projection heads: Number of latent encoding/ decoding projections happening in parallel in each layer.
Clusters: Projection dimension
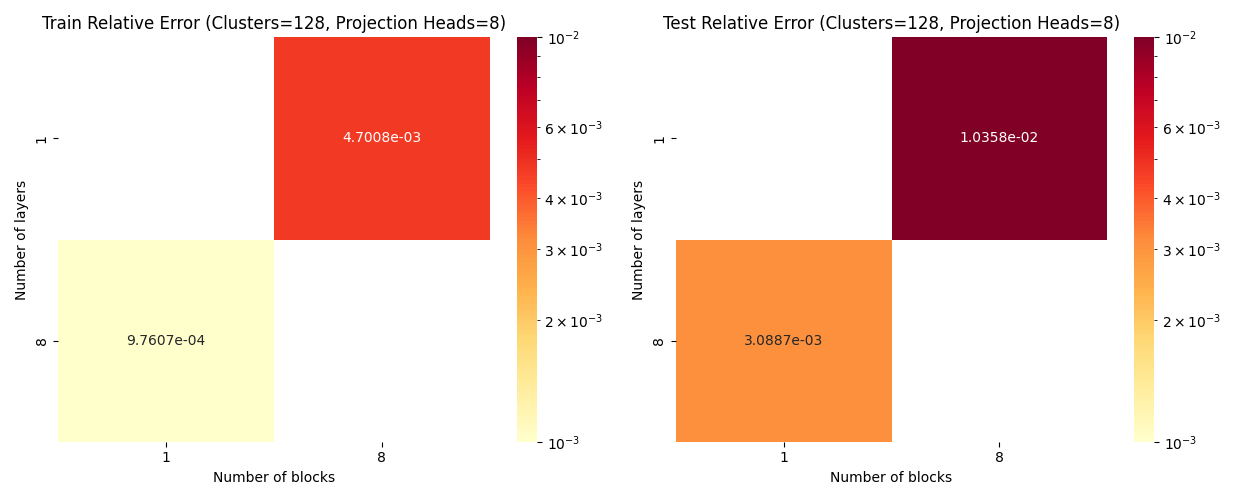
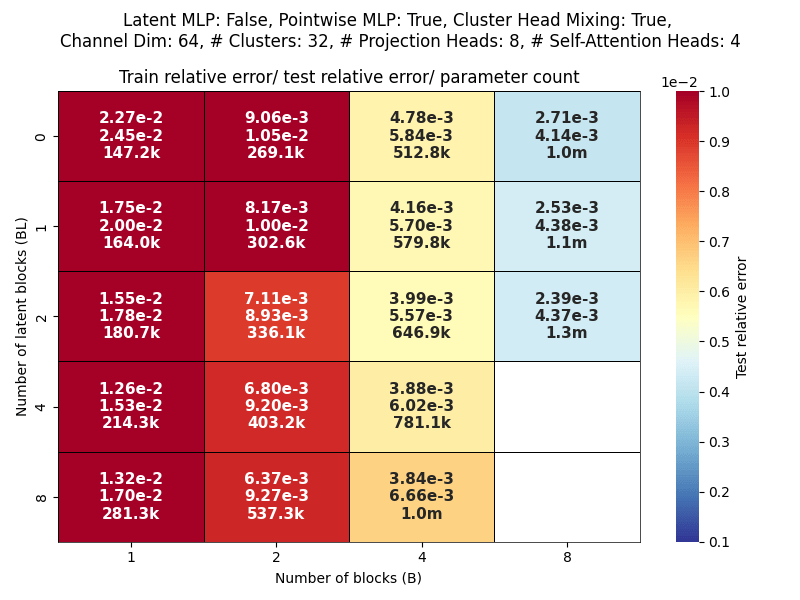
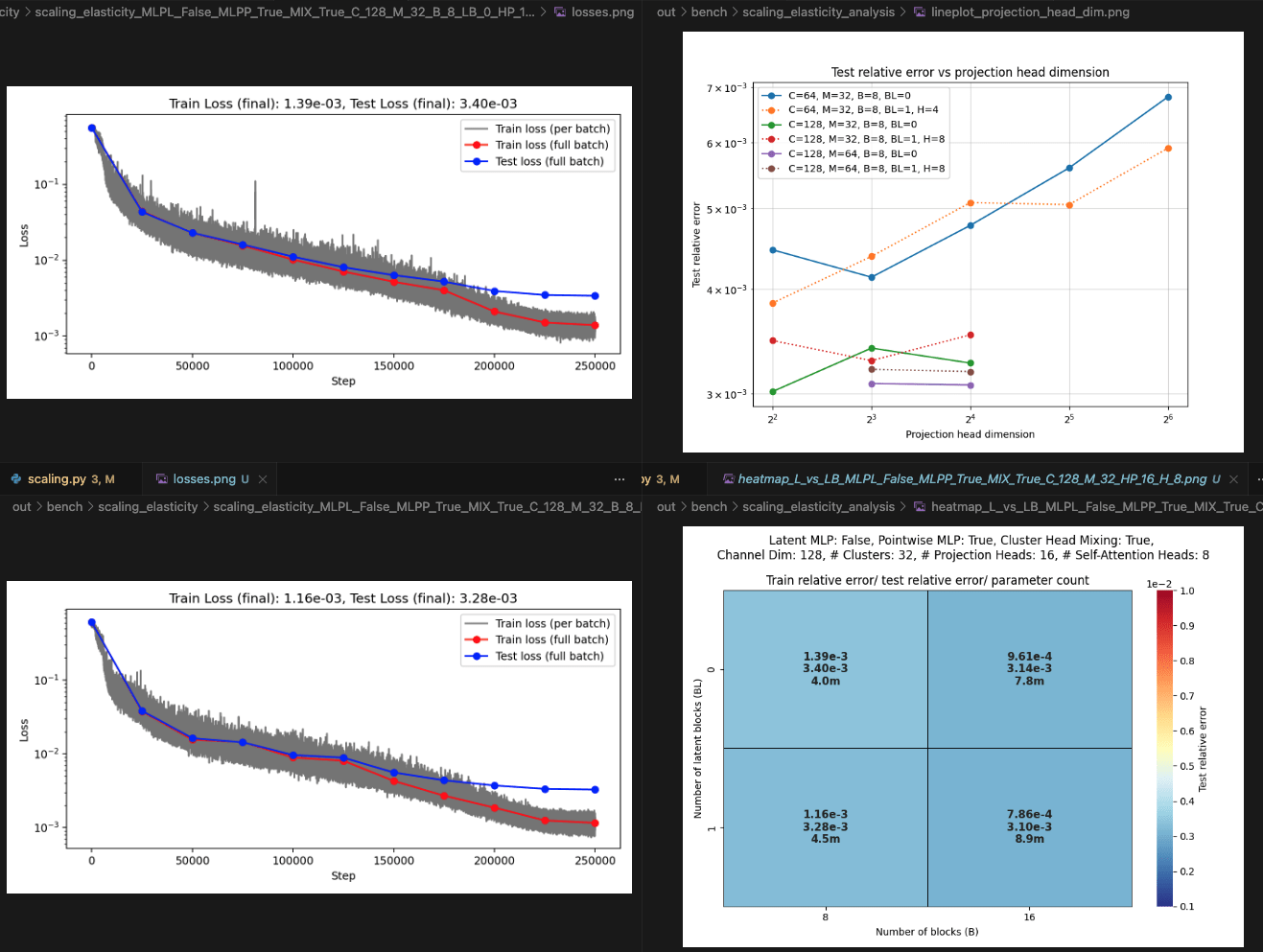
Layers: Number of projections (latent encoding / decoding operations).
Blocks: Number of attention blocks in latent space in each layer.
Projection heads: Number of latent encoding/ decoding projections happening in parallel in each layer.
Clusters: Projection dimension
Layers: Number of projections (latent encoding / decoding operations)
Blocks: Number of attention blocks in latent space in each layer.
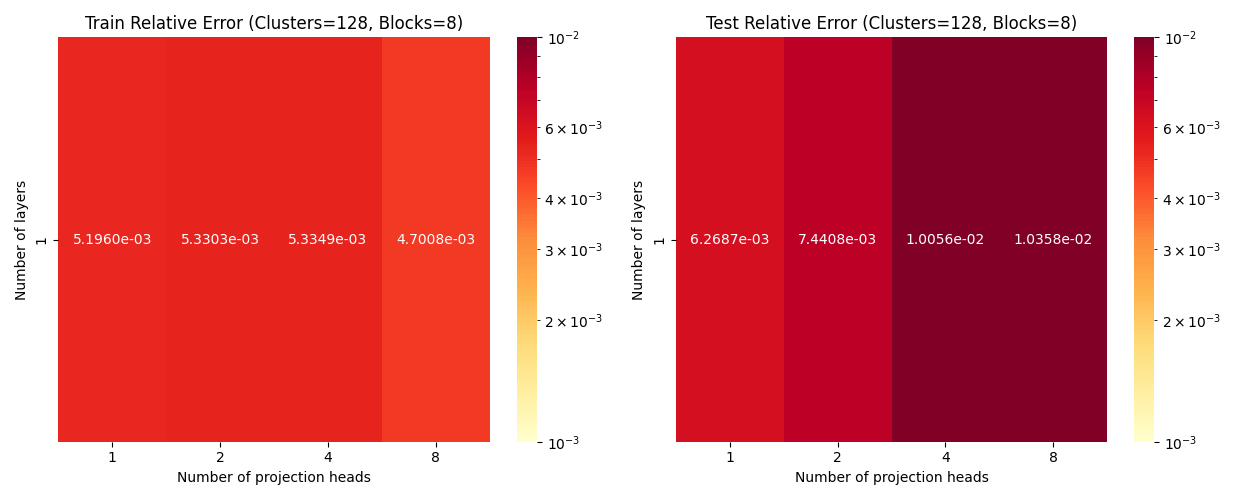
Layers: Number of projections (latent encoding / decoding operations).
Blocks: Number of attention blocks in latent space in each layer.
Projection heads: Number of latent encoding/ decoding projections happening in parallel in each layer.
Clusters: Projection dimension
MLP block in latent and pointwise space
MLP block in latent space only
MLP block in pointwise space only
Projection Heads=4
Projection Heads=1
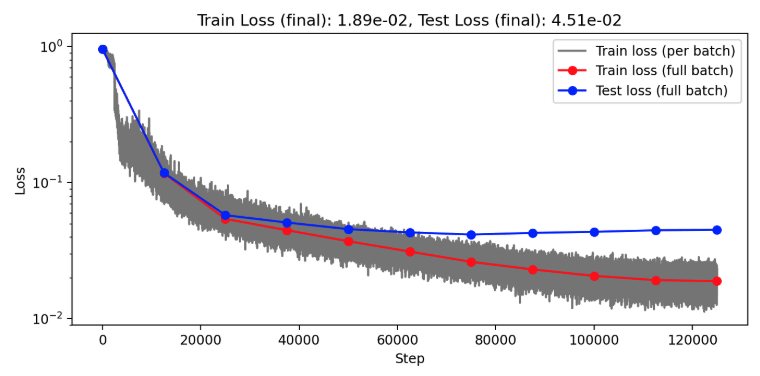
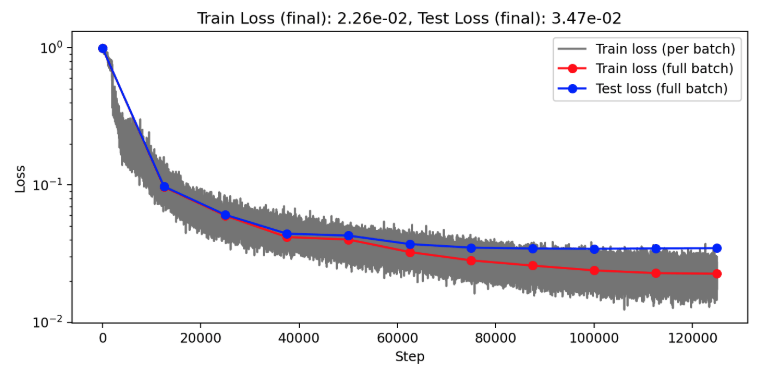
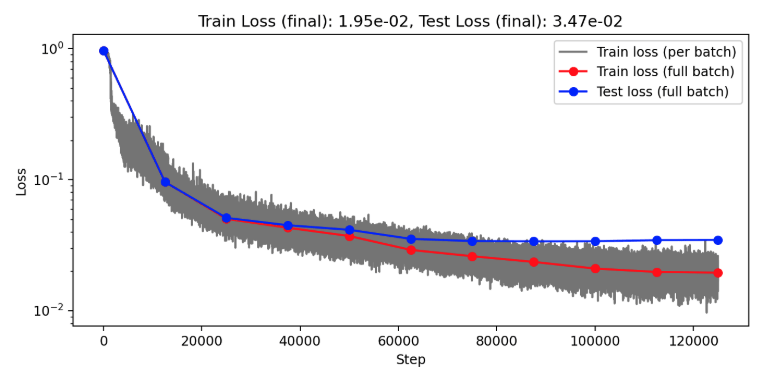
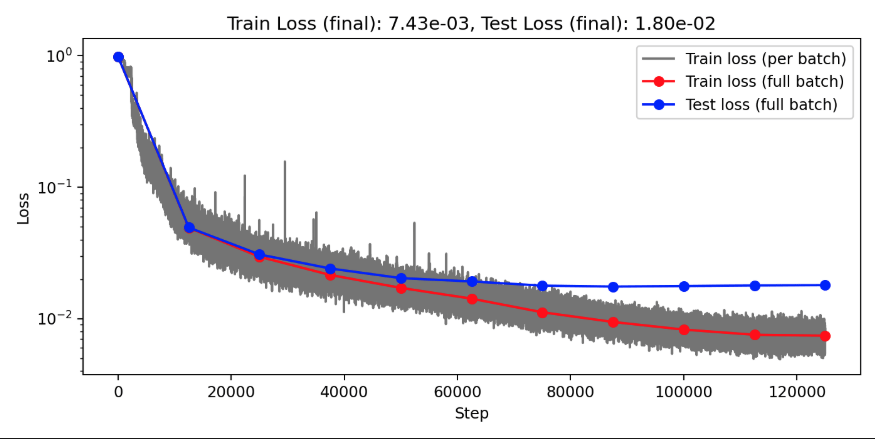
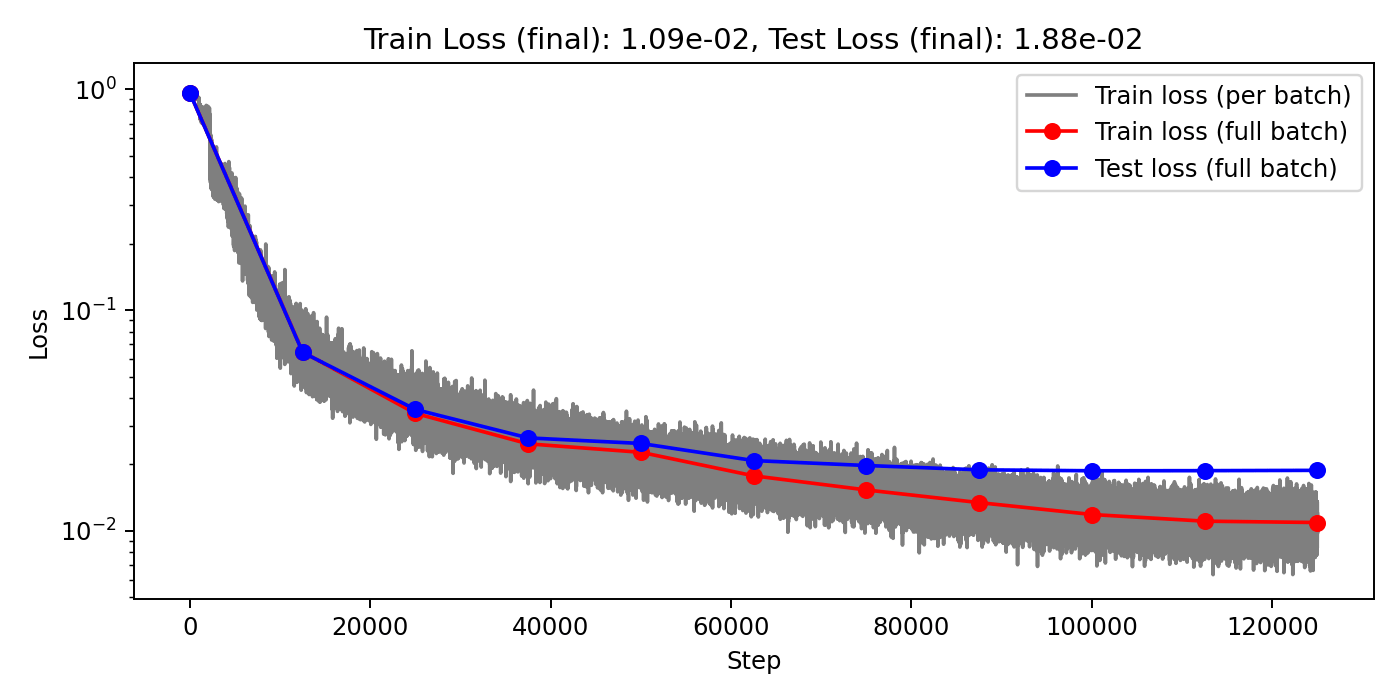
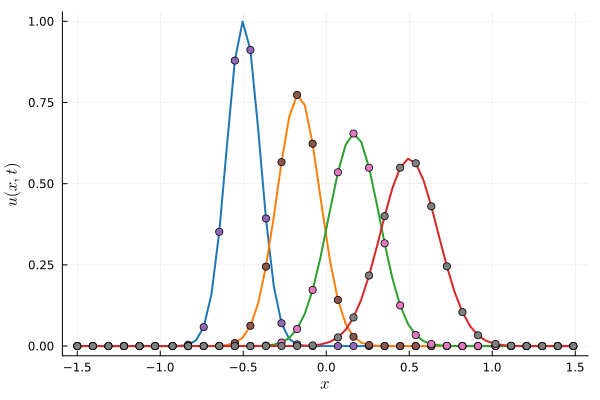
(Train/test) rel error: 5.765e-3 / 2.027e-2
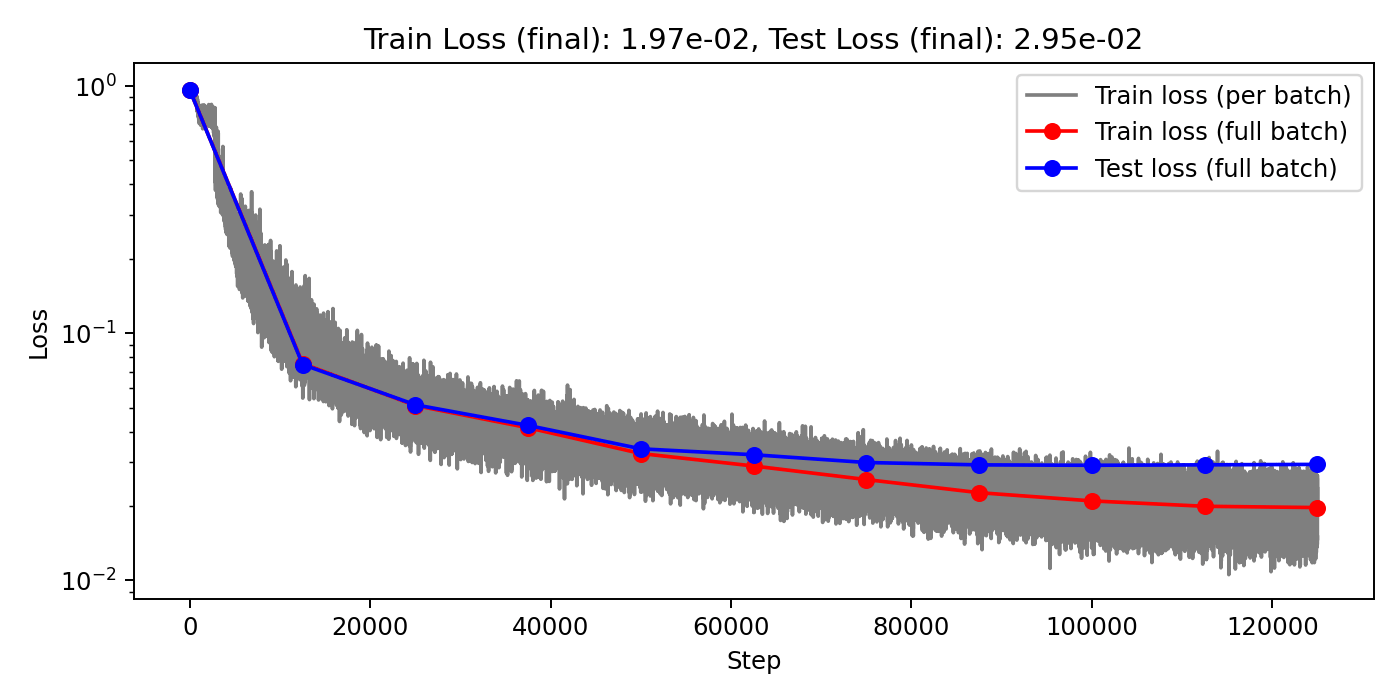
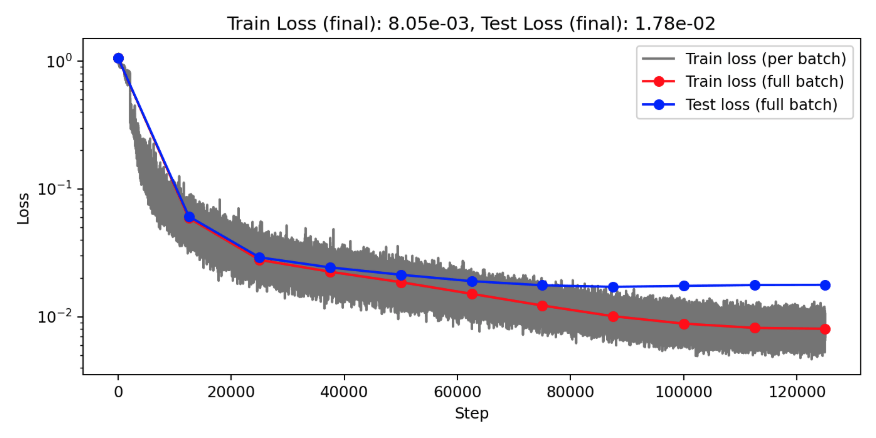
(Train/test) rel error: 5.999e-3 / 1.440e-2
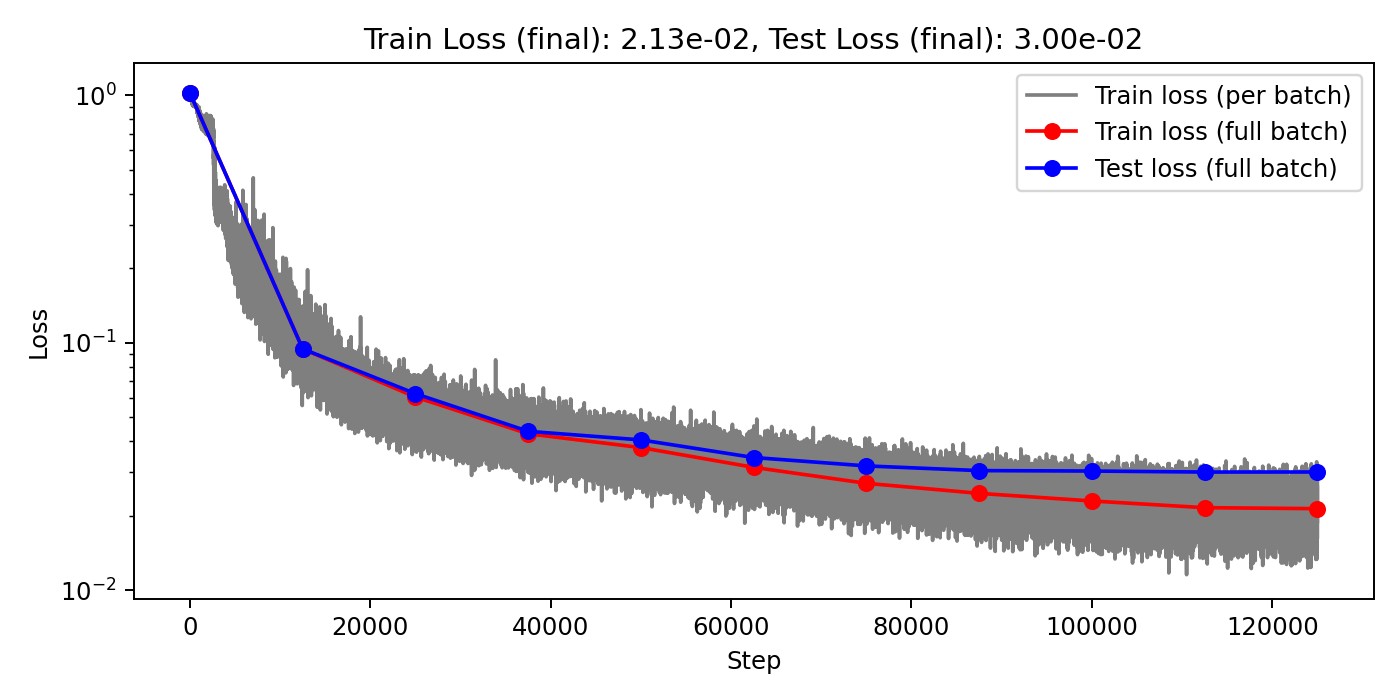
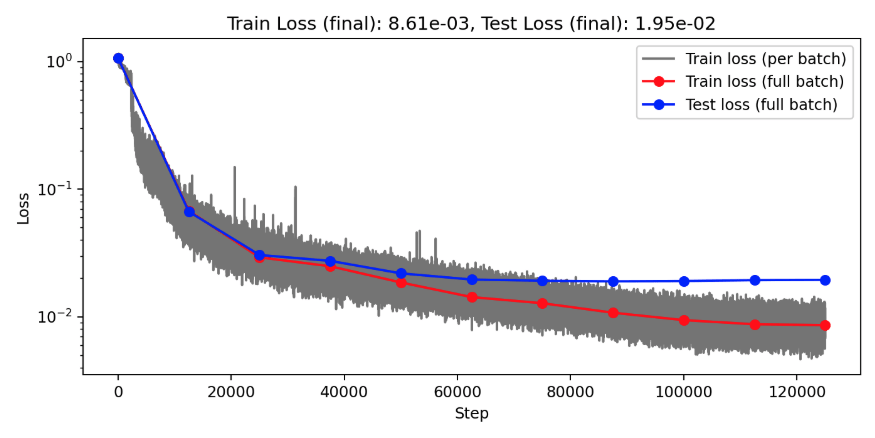
(Train/test) rel error: 7.363e-3 / 1.465e-2
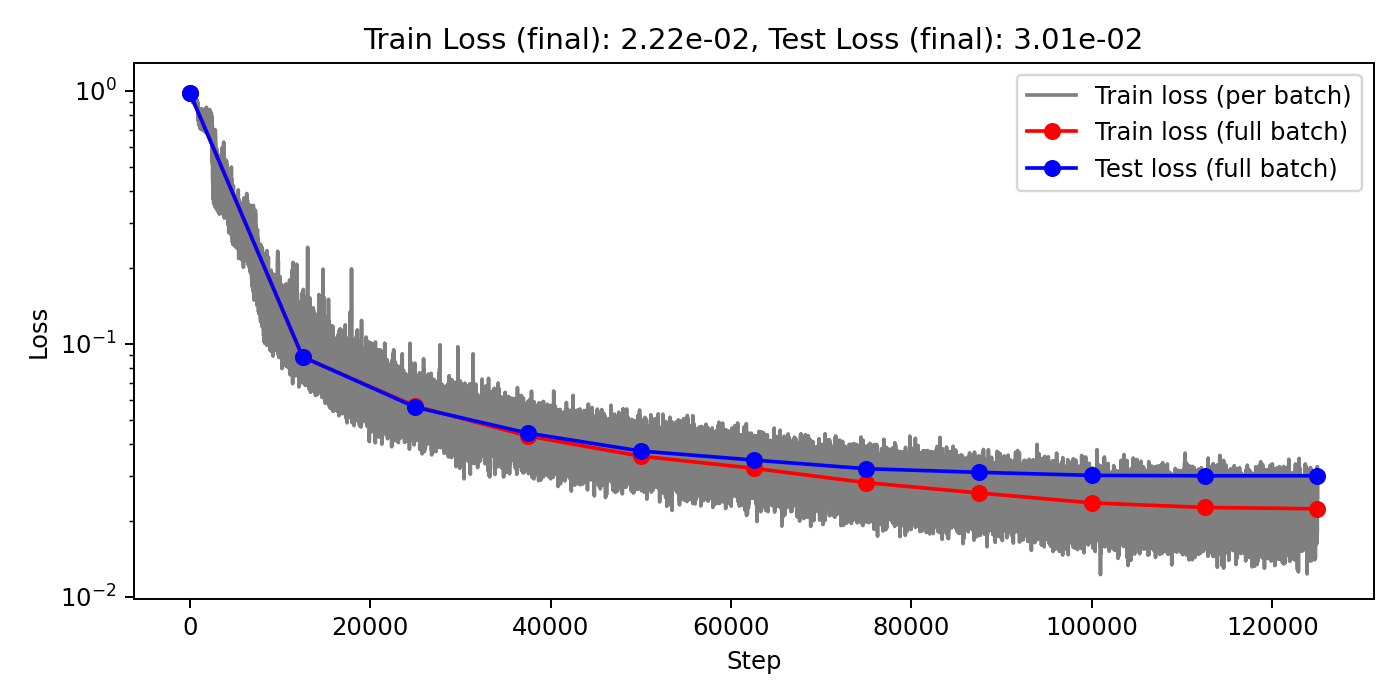
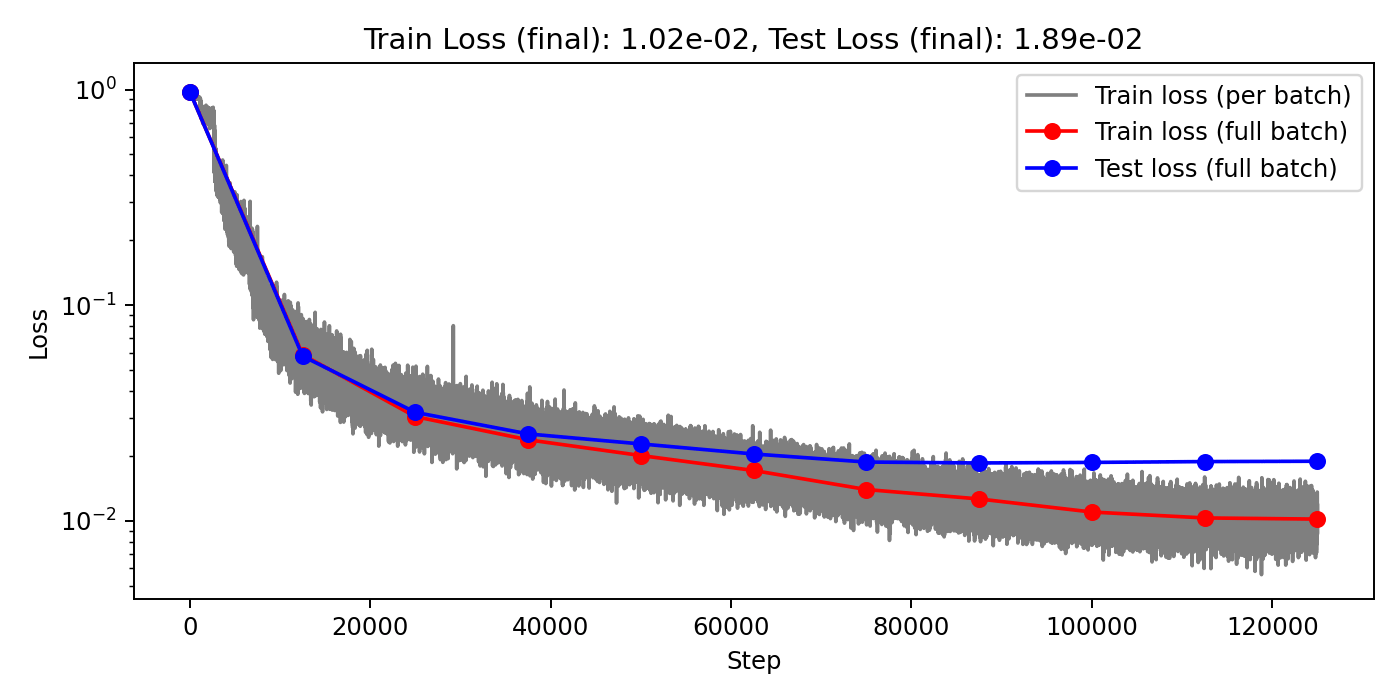
(Train/test) rel error: 6.076e-3 / 1.144e-2
(Train/test) rel error: 6.776e-3 / 1.182e-2
(Train/test) rel error: 7.234-3 / 1.176e-2
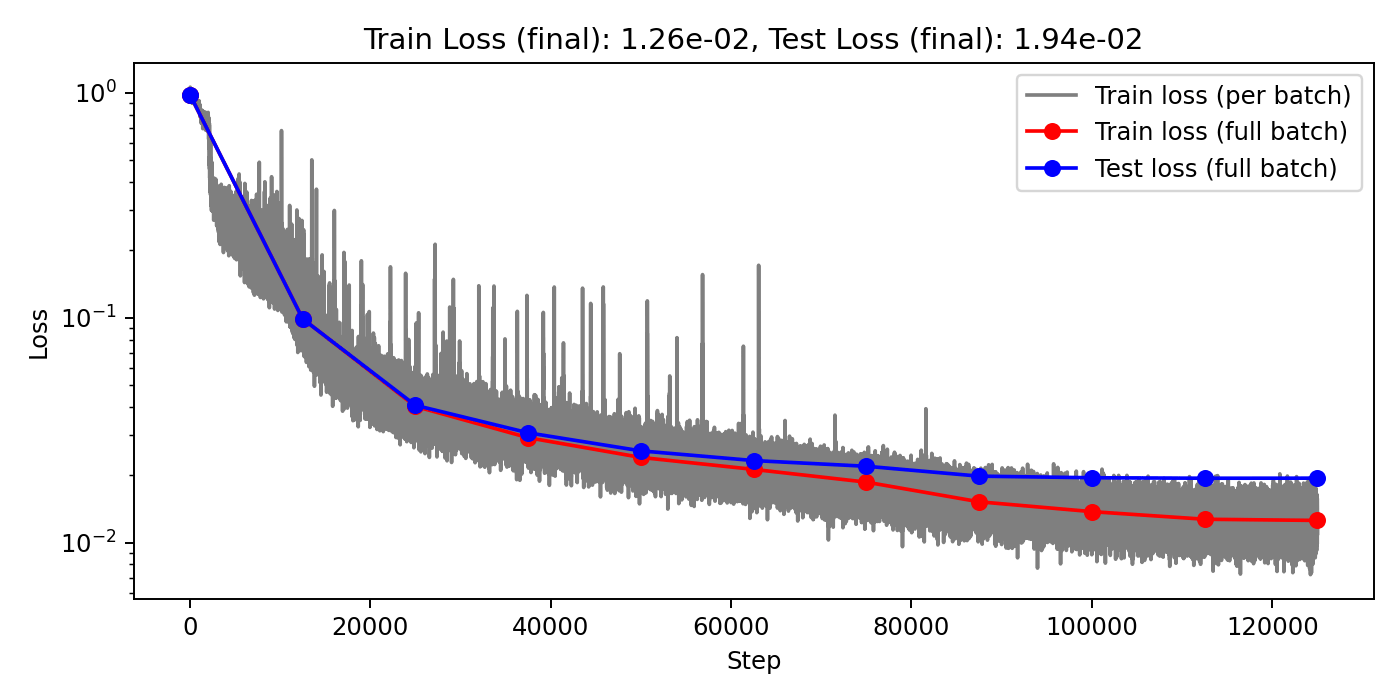
Projection Heads=4
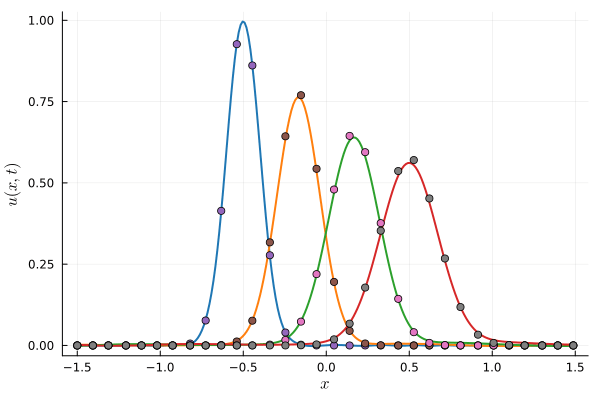
(Train/test) rel error: 1.915e-3 / 6.935e-3
(Train/test) rel error: 2.243e-3 / 7.581e-3
(Train/test) rel error: 2.078e-3 / 7.101e-3
Projection Heads=1
(Train/test) rel error: 2.780e-3 / 6.956e-3
(Train/test) rel error: 2.999e-3 / 6.918e-3
MLP block in latent and pointwise space
MLP block in latent space only
MLP block in pointwise space only
(Train/test) rel error: 3.526e-3 / 7.109e-3
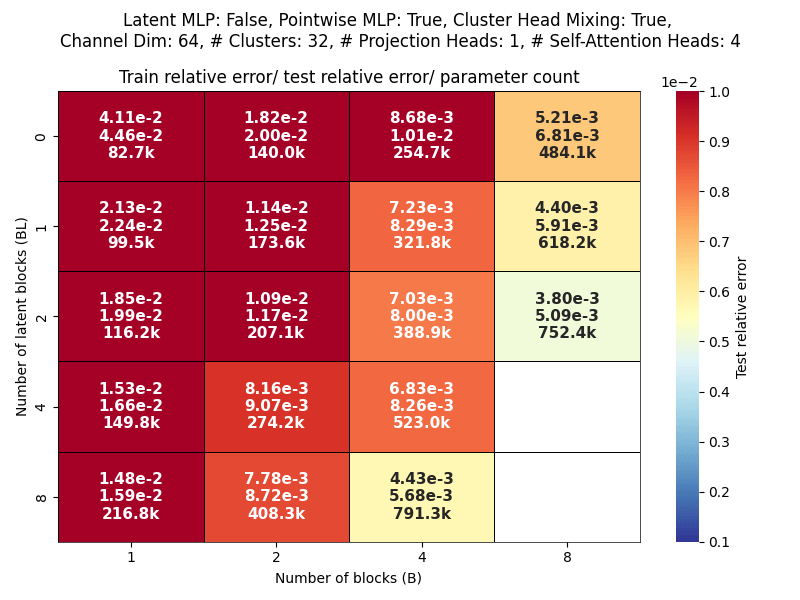
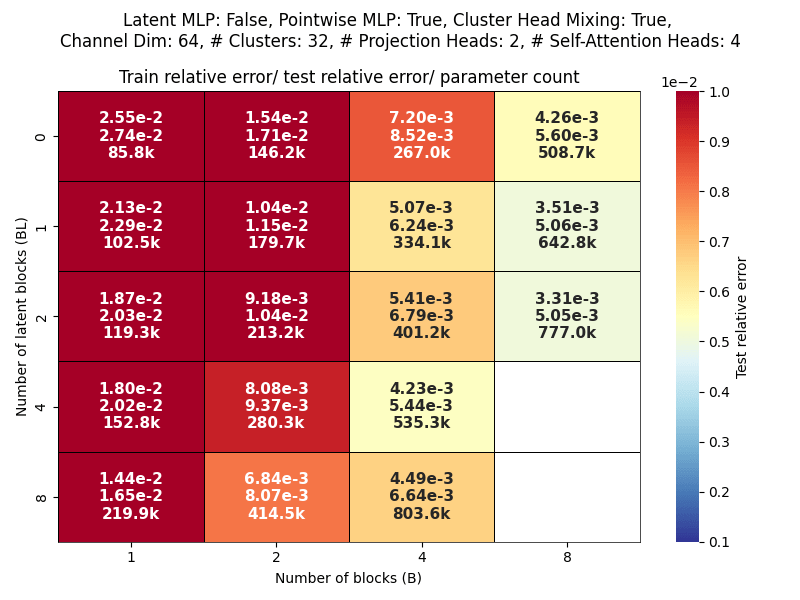
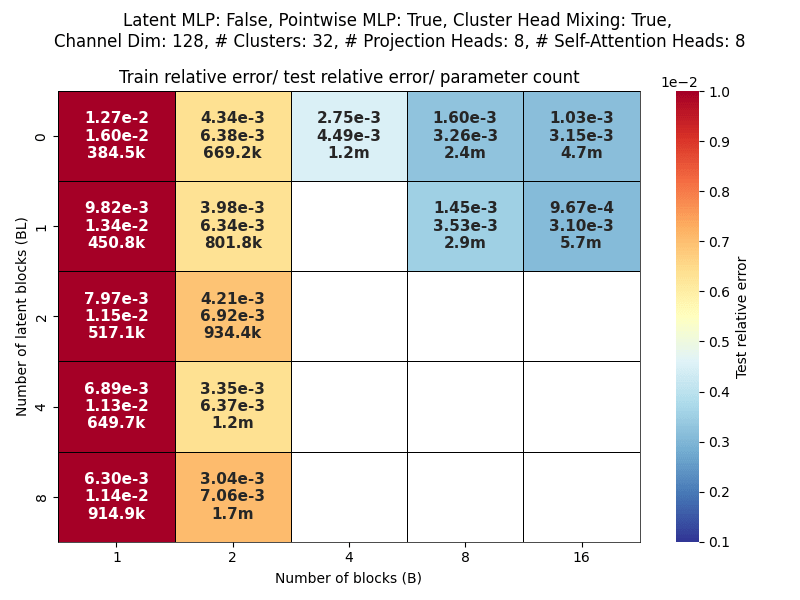
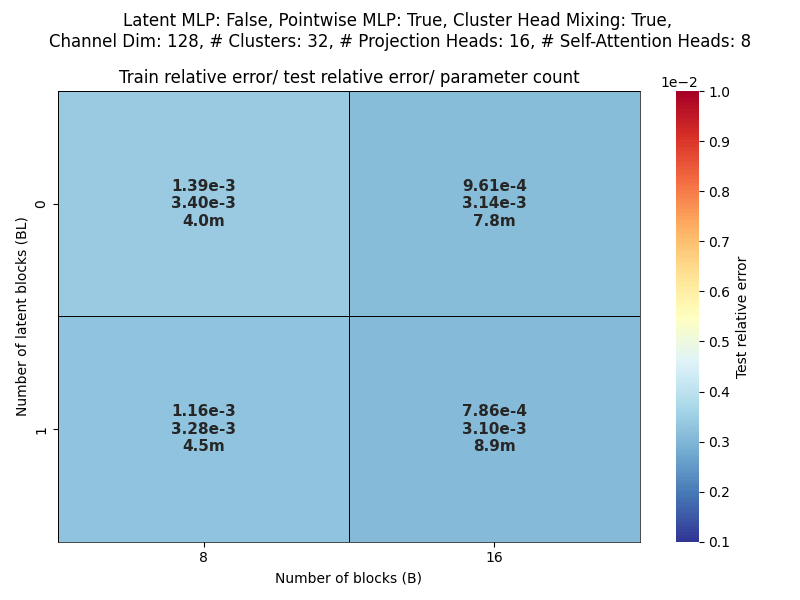
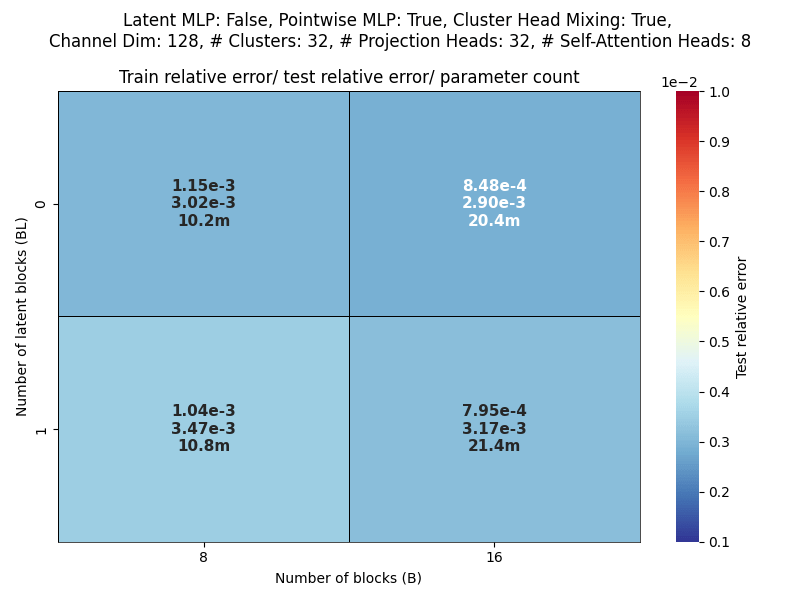
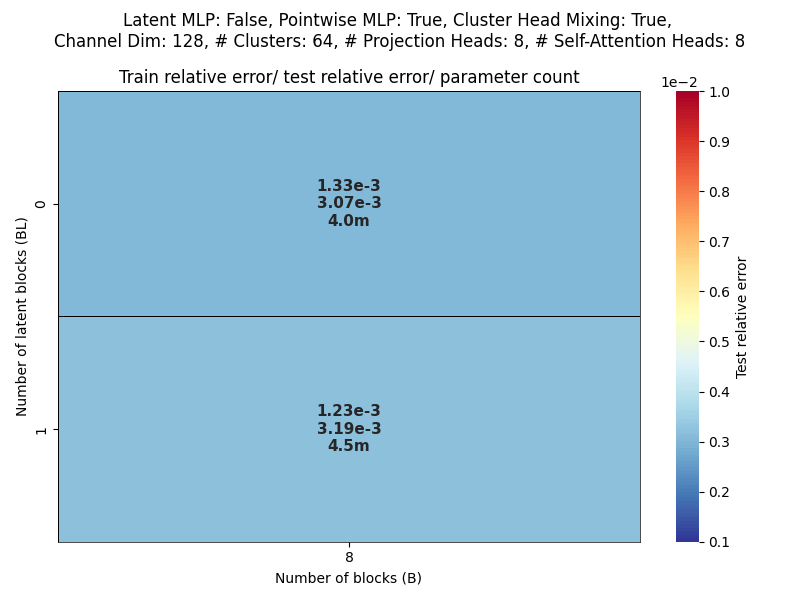
Channel dim: Model working dimension.
Blocks: Number of CAT projection blocks (latent encoding / decoding operations).
Latent Blocks: Number of self-attention blocks in latent space in each CAT block.
Projection heads: Number of latent encoding/ decoding projections happening in parallel in each layer.
Clusters: Projection dimension
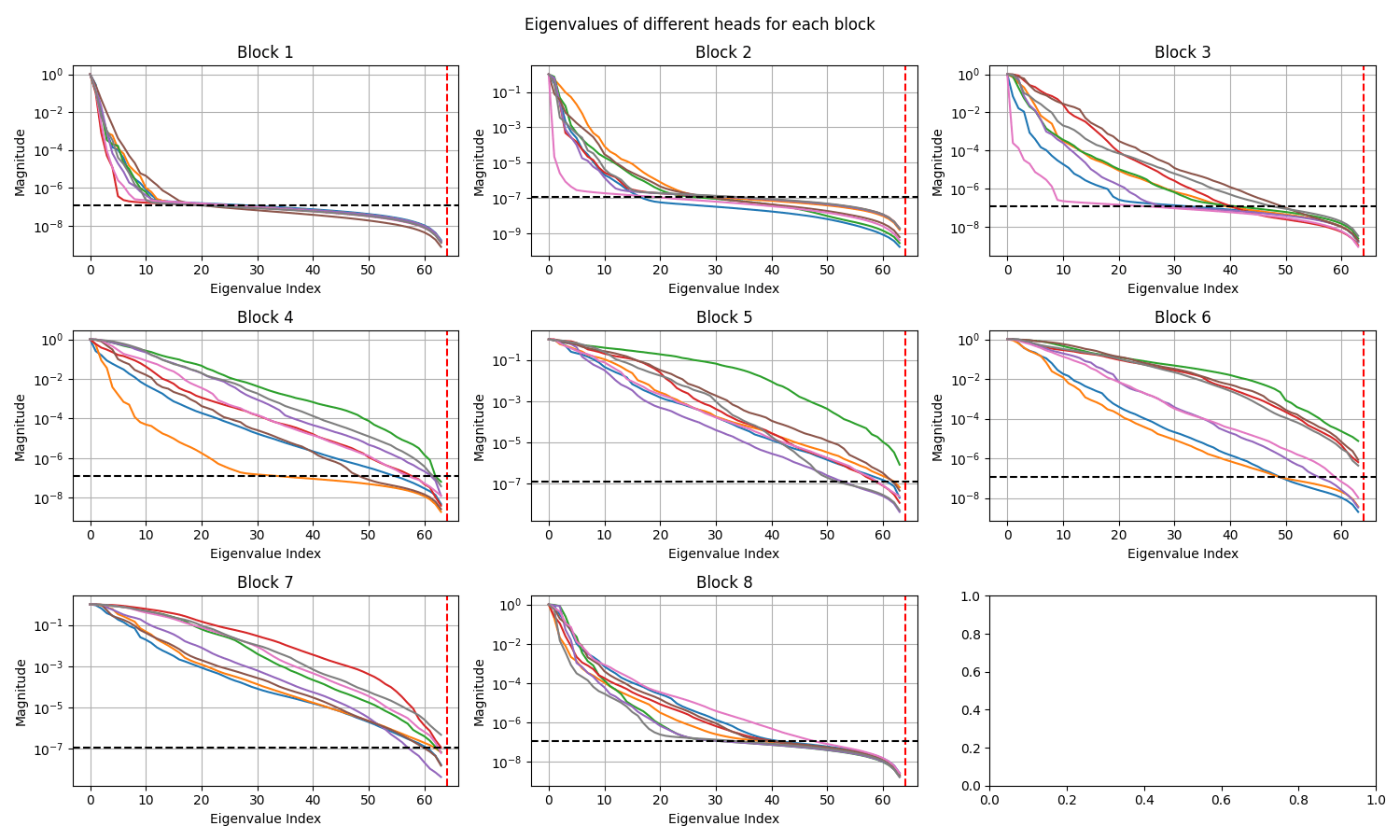
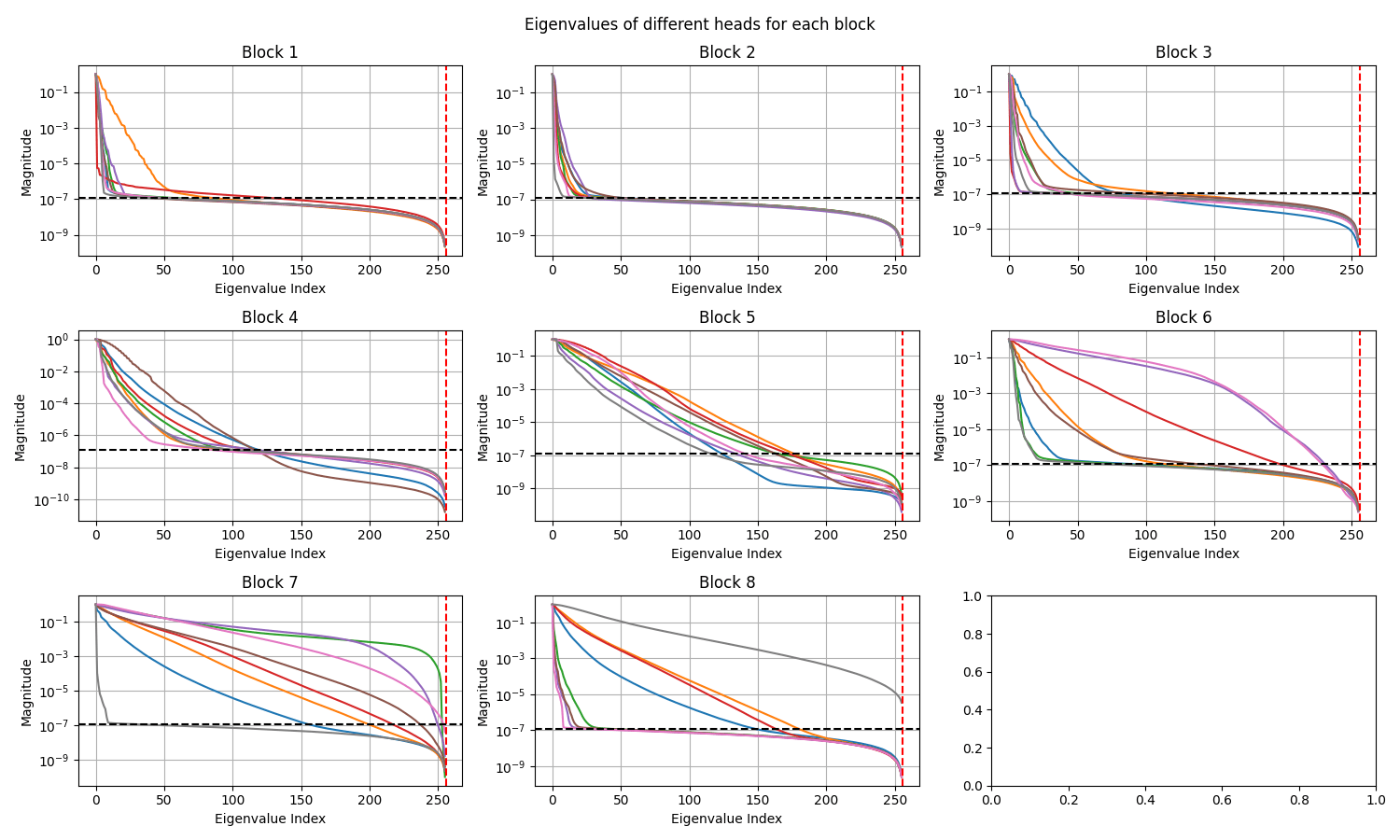
OBSERVATIONS:
OBSERVATIONS:
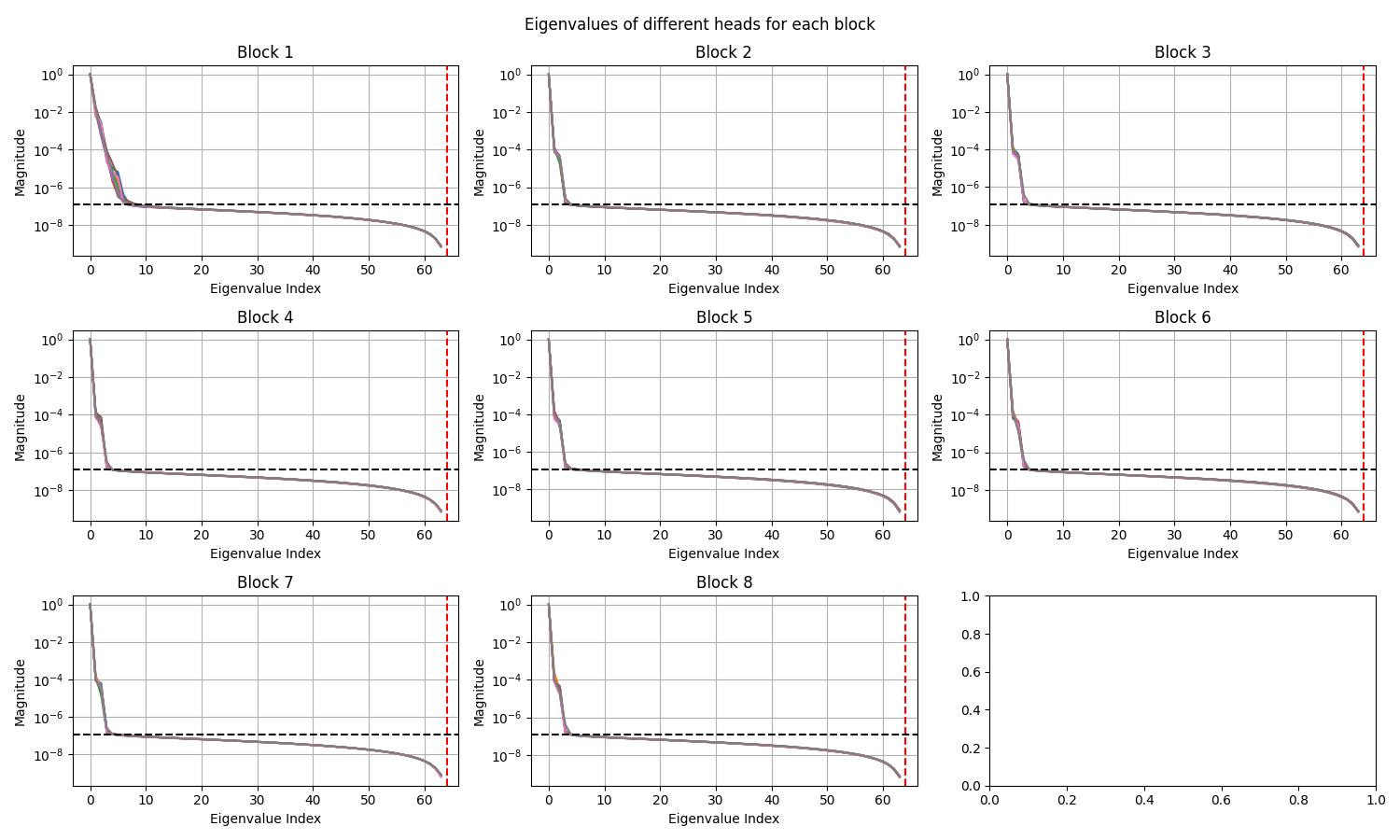
CAT with Latent Blocks = 0
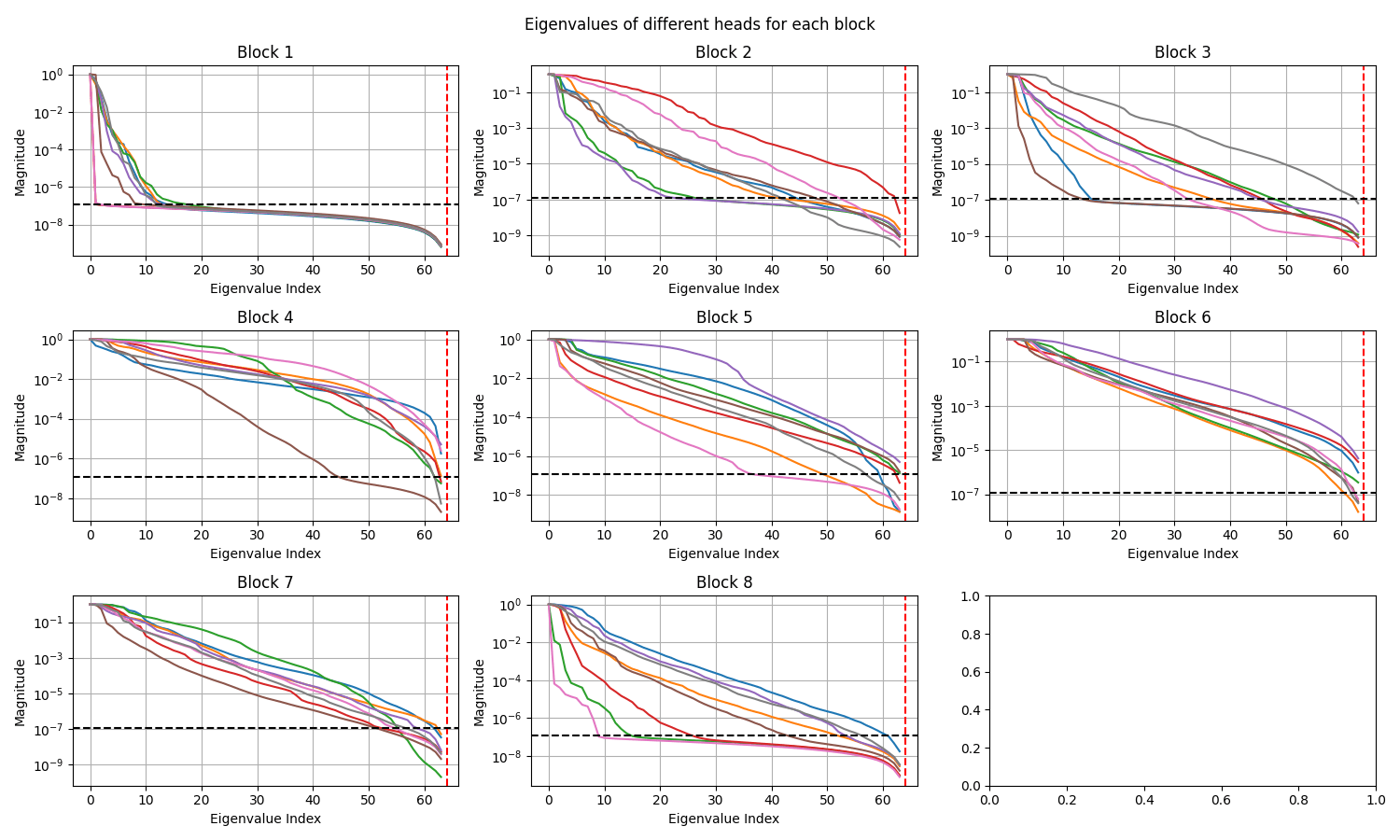
Transolver
OBSERVATIONS:
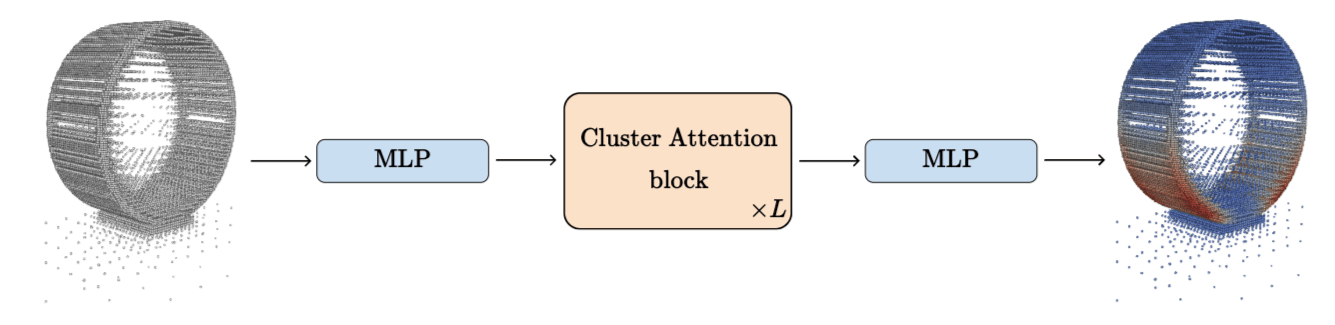
Expressive transformer architecture
TASKS
APPLICATIONS
FUTURE WORK
PROPOSAL
NEXT PAPER - ICML (Int'l conference of Machine Learning)
WINTER BREAK PLAN - visit India Dec 11 - Jan 10
PROGRESS
NEXT STEPS
PROPOSAL
NEXT PAPER - ICML (Int'l conference of Machine Learning)
PROGRESS
NEXT STEPS
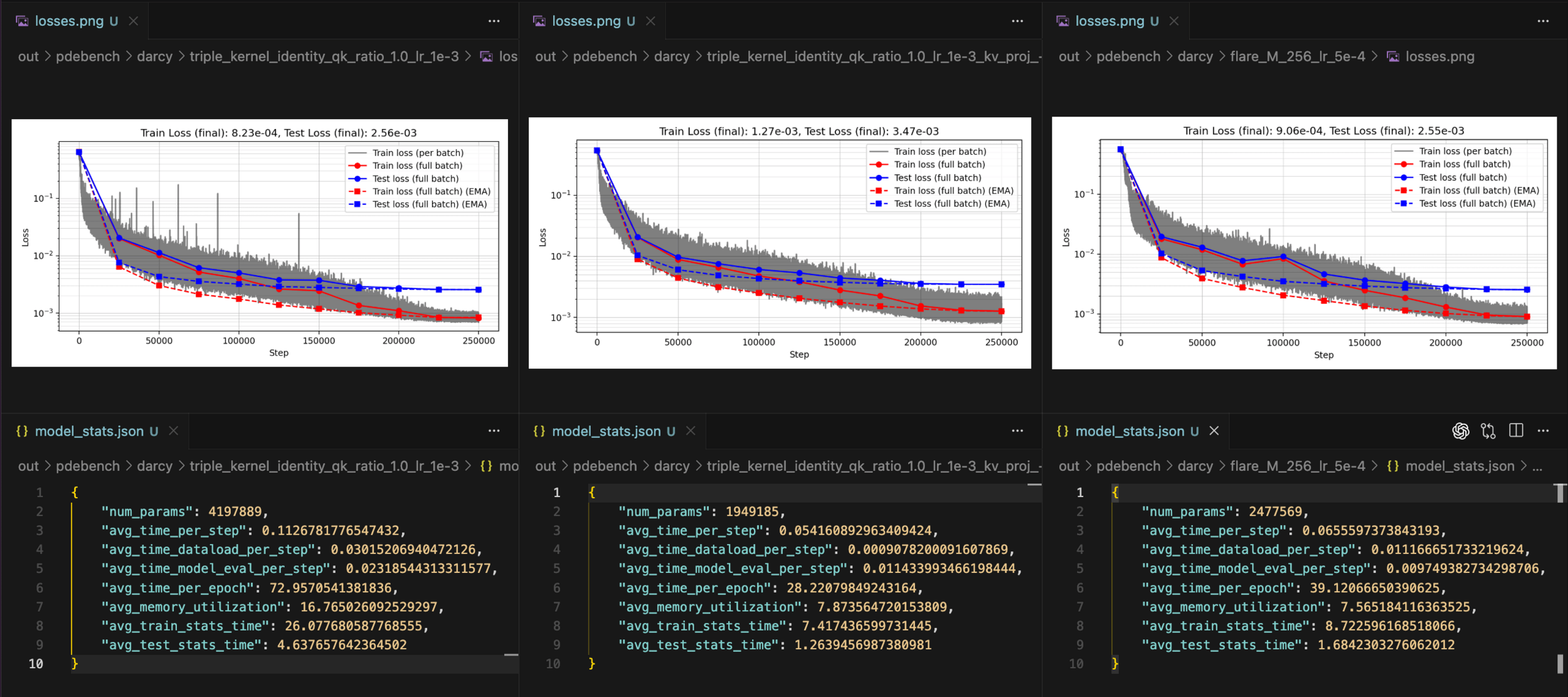
Triple v1 (4.2m)
Triple v2 (1.9m)
FLARE (2.4m)
Different depths of ResidualMLPs
Nonlinear kernel parameterizations for Neural Galerkin
Status and plan
Potential new contributions and timeline
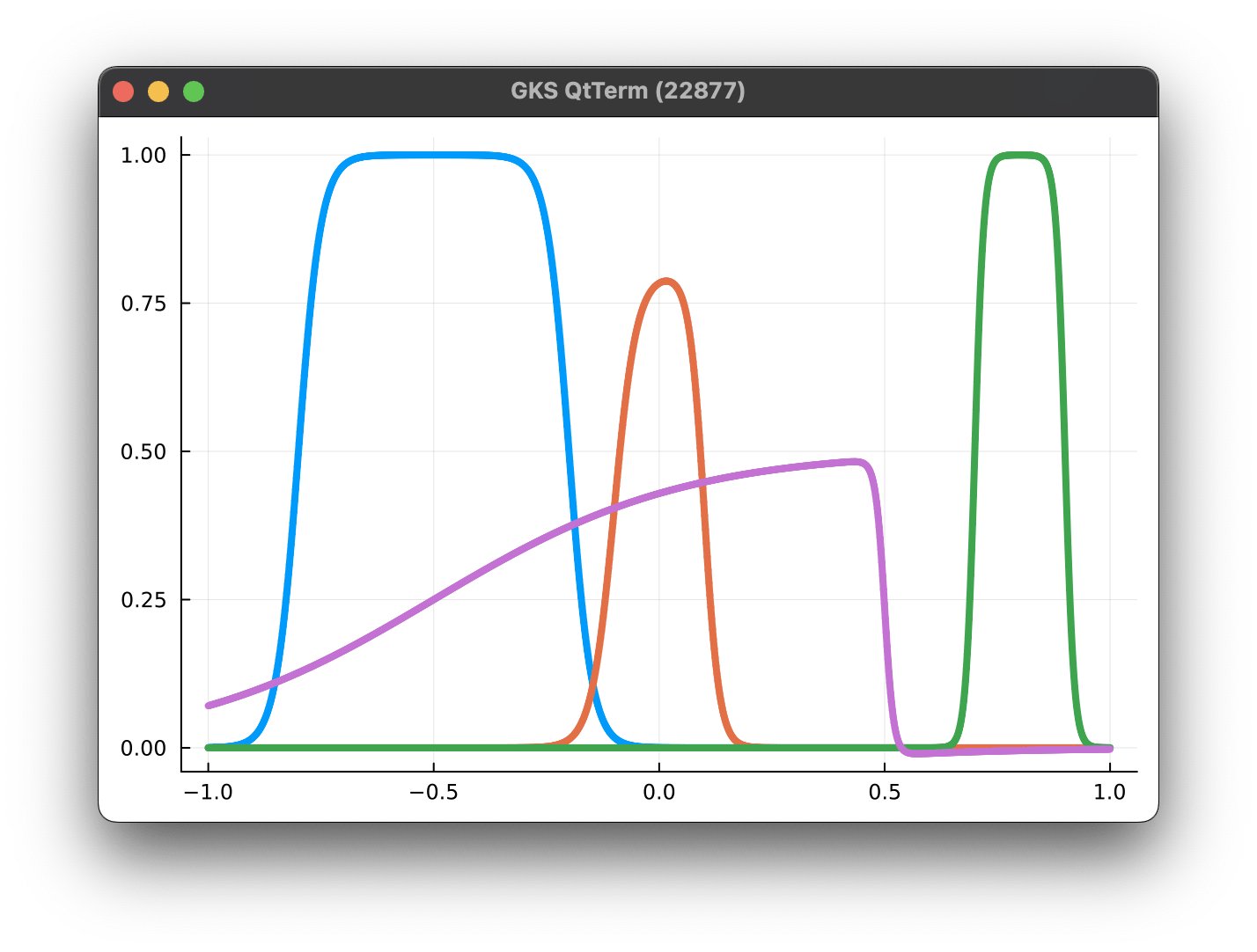
Parameterized Tanh kernels
Nonlinear kernel parameterizations for Neural Galerkin
Status and plan
Potential new contributions and timeline
Parameterized Tanh kernels
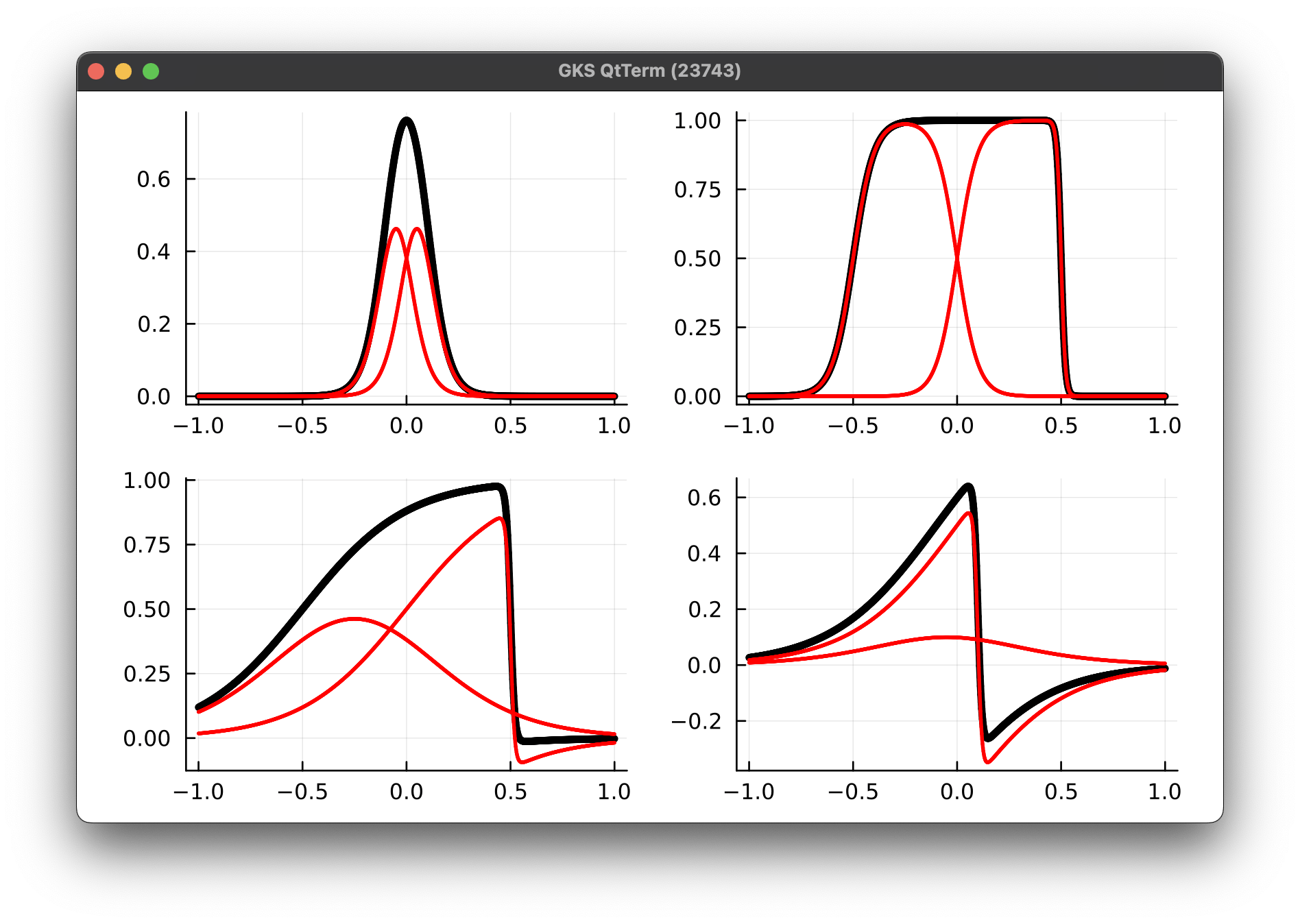
Parameterized Gaussian (OURS)
3 parameters
8 collocation points
Deep Neural Network (BASELINE)
~150 parameters
256 collocation points
Multiplicative filter network (MFN)
~210 parameters
256 collocation points
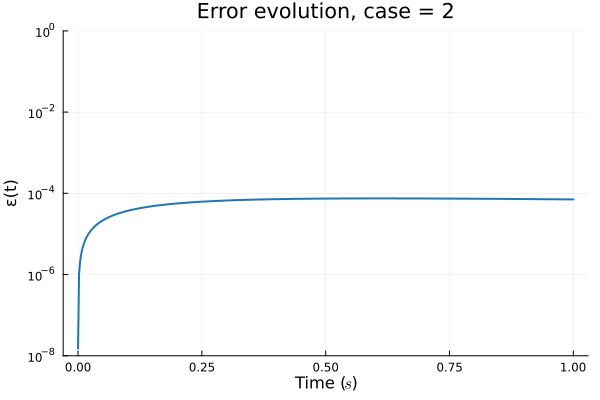
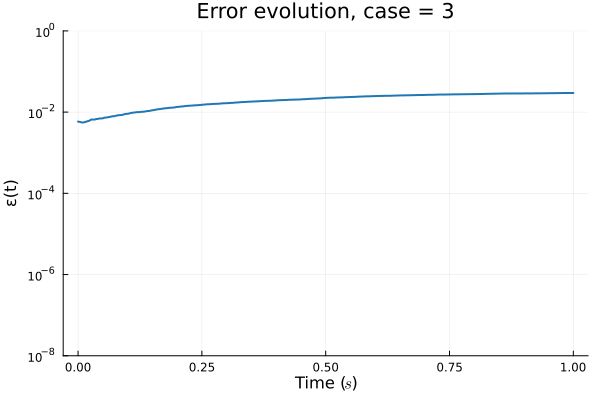
Error due to limited expressivity of this simple model
FAILED TO CONVERGE
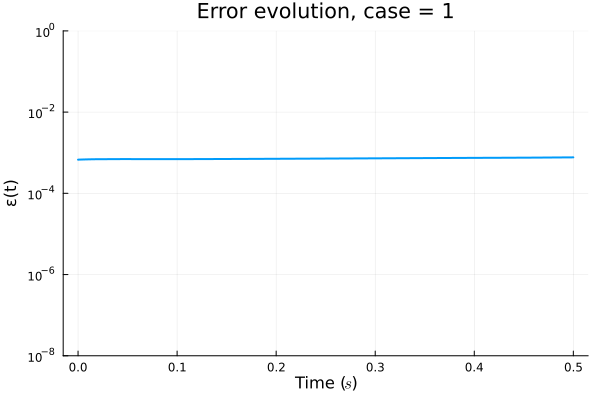
1 Kernel (6 params)
4 Kernel (21 params)
By Vedant Puri
Biweekly co-advisor meeting




