






















Vedant Puri
PhD student at Carnegie Mellon University
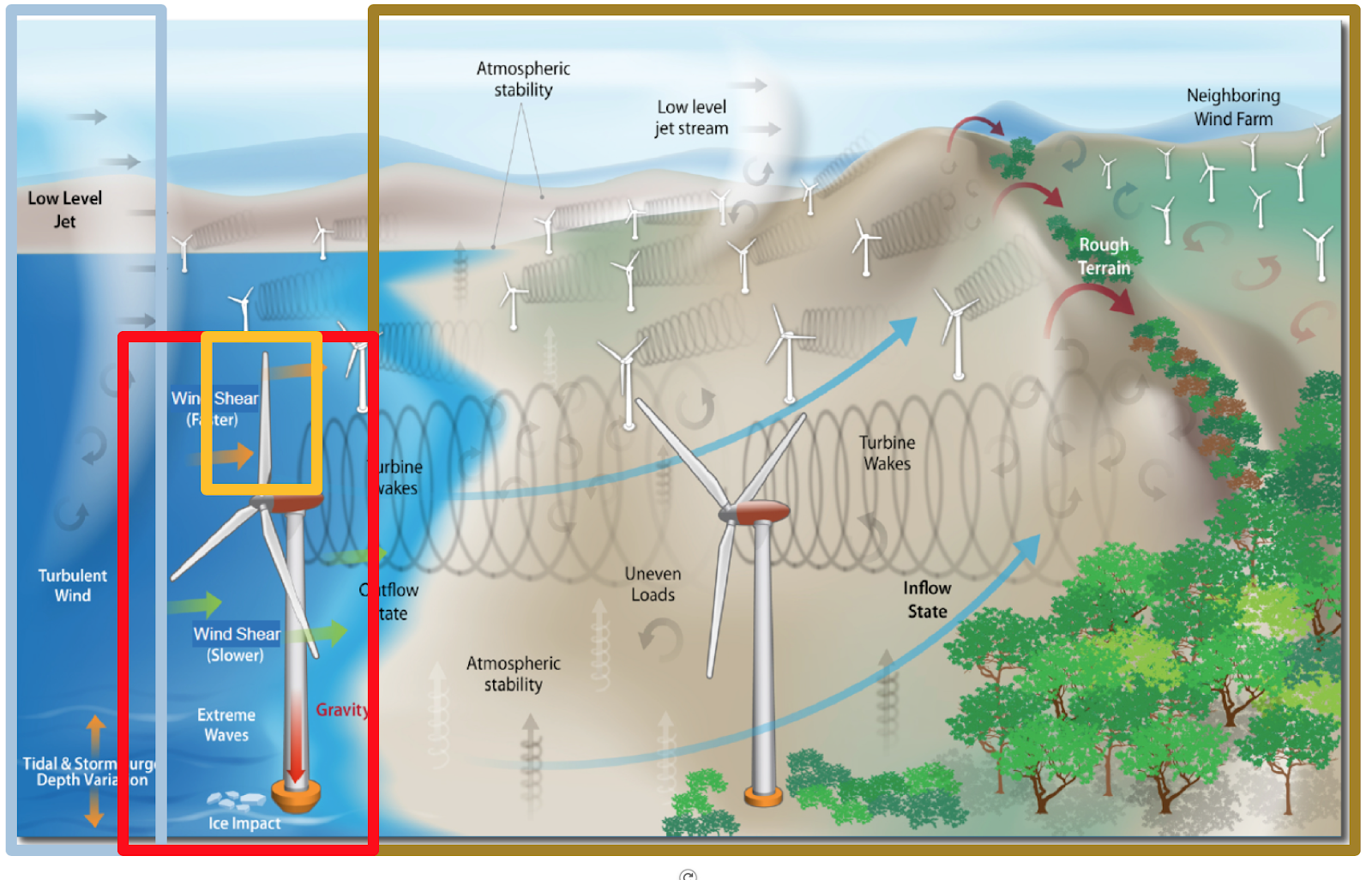
Mesosphere
Wind farm
Turbine
Blade
1
Navier-Stokes Equations
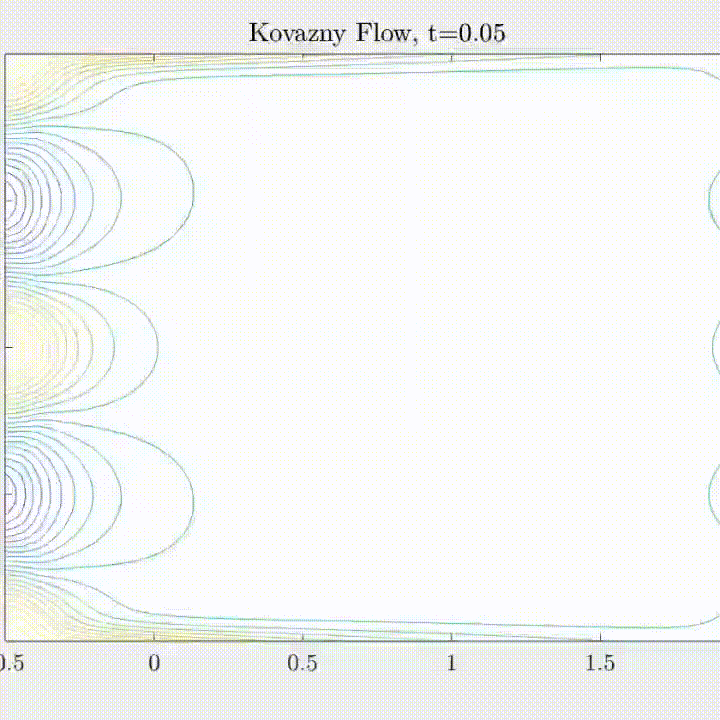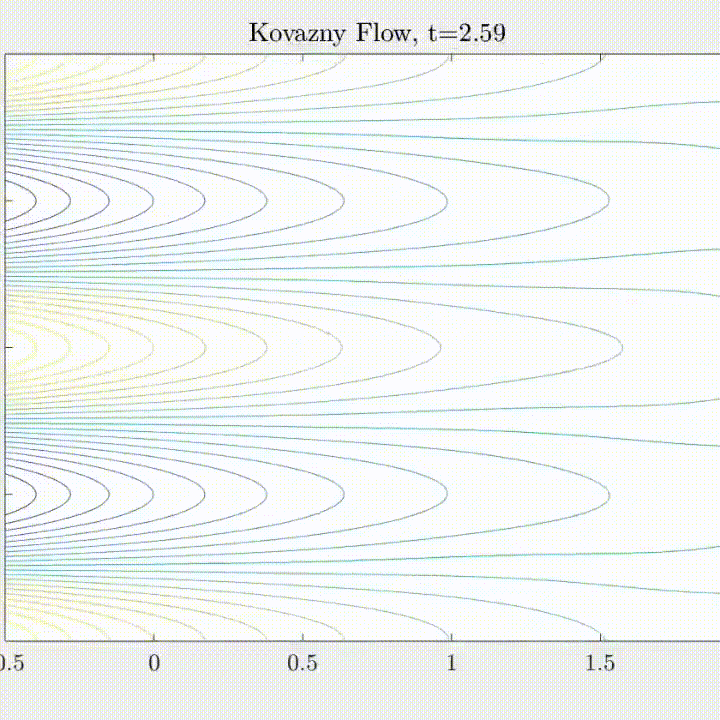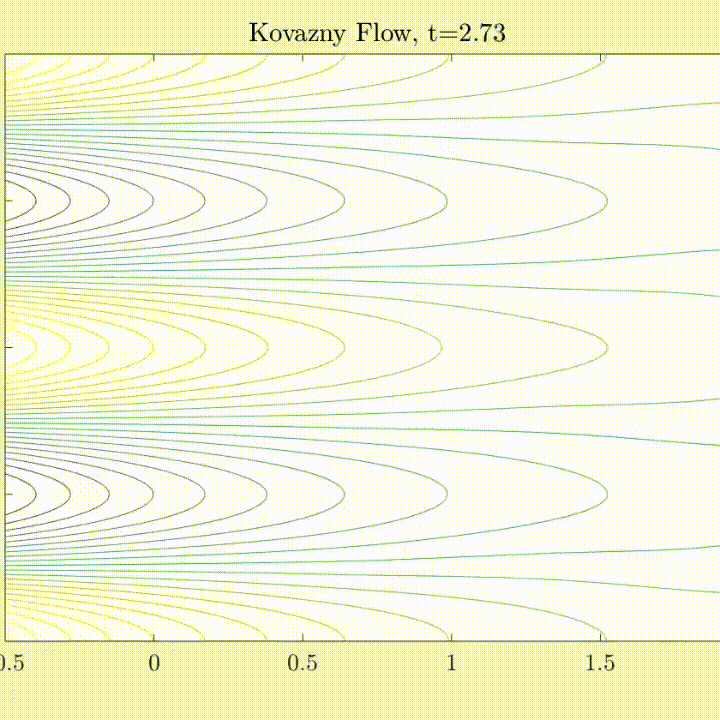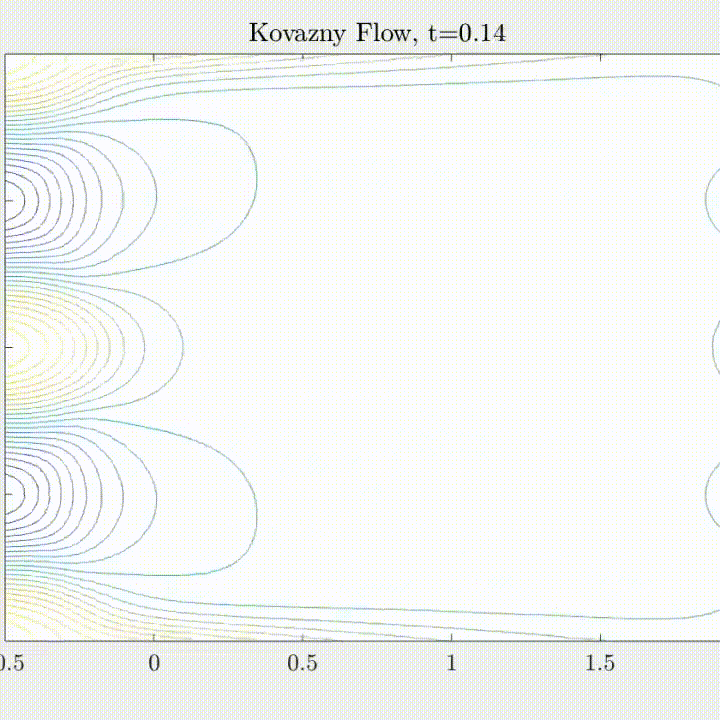
(Flow past bluff body \( Re = 3900 \))
Need high quality function representation over (complex) geometry
Main operations: \(\nabla, \, \int_\Omega\)
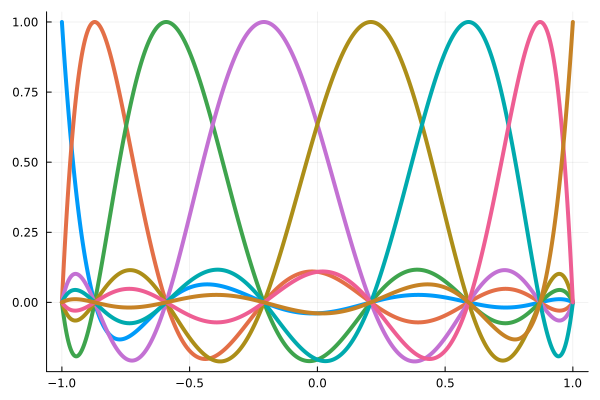
High-order polynomial interpolation is the underlying technology
Differentiation
Interpolation
Integration
Prohibitively expensive
Challenges with meshing
Requires tailoring solution to problem
2
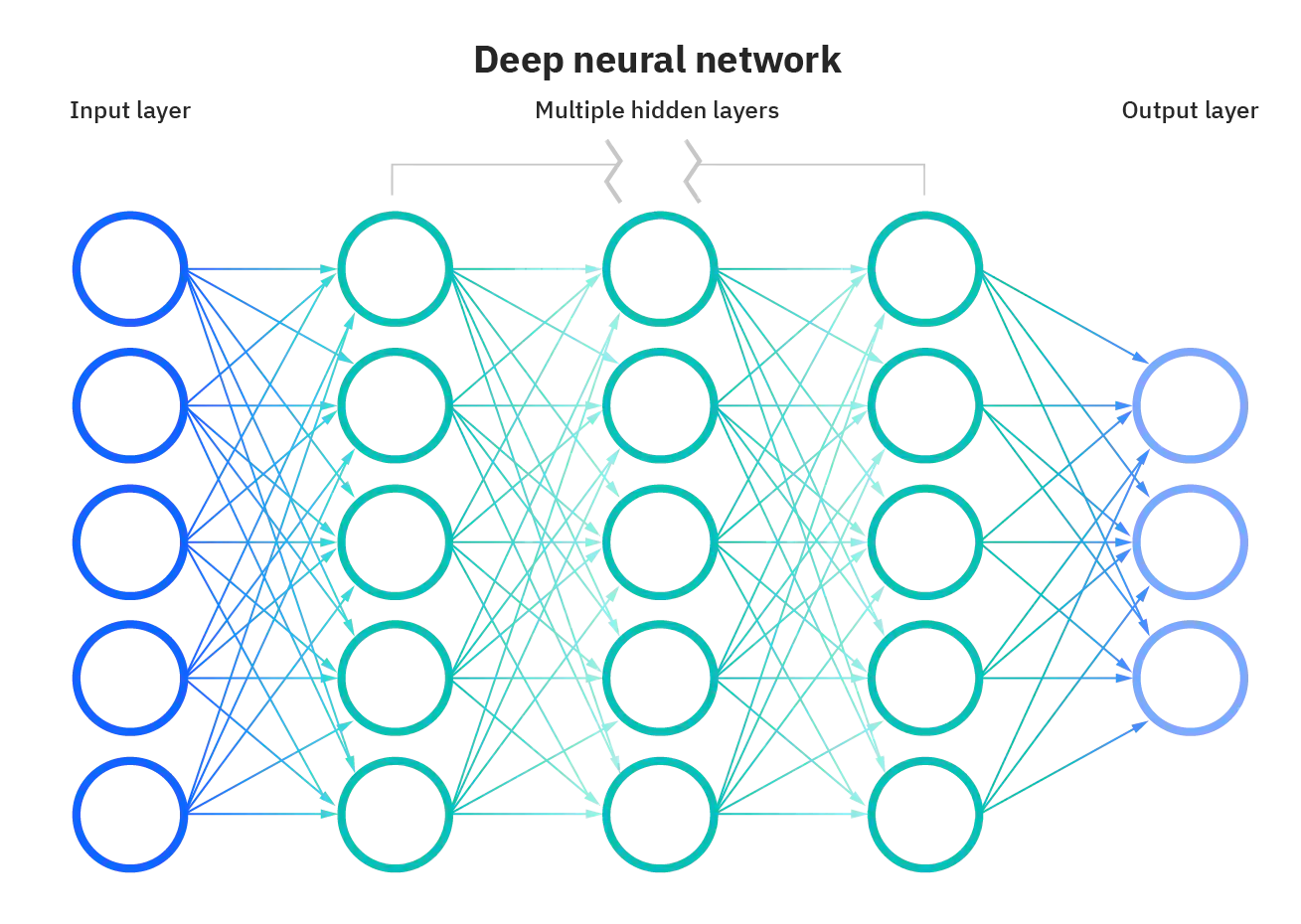
| Orthogonal Functions | Deep Neural Networks |
|---|---|
|
|
|
|
Fast, accurate differentiation |
Fast, accurate differentiatoin |
|
Fast, accurate integration |
Approximate integration |
(Weinan, 2020)
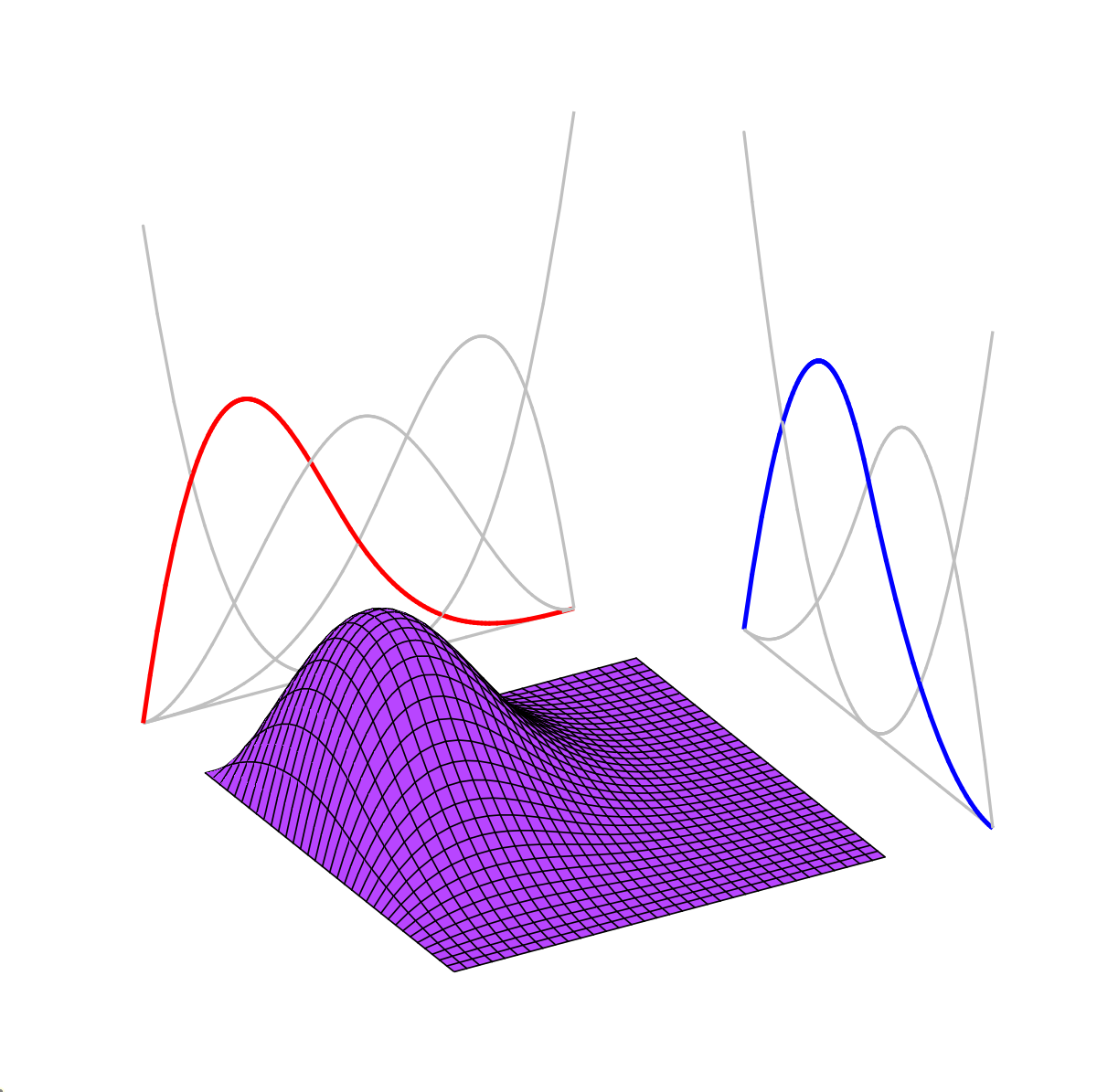
Model size scales with signal complexity
Model size scales exponentially with dimension
3
4
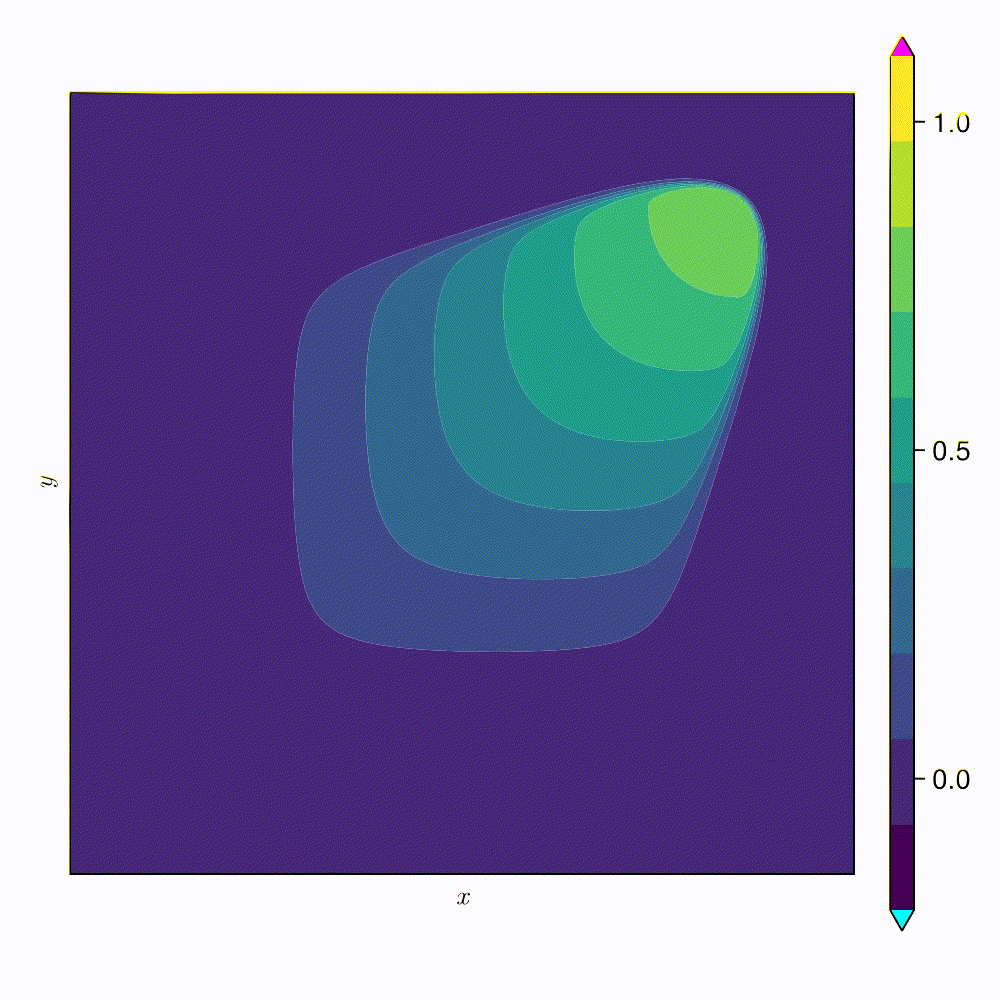
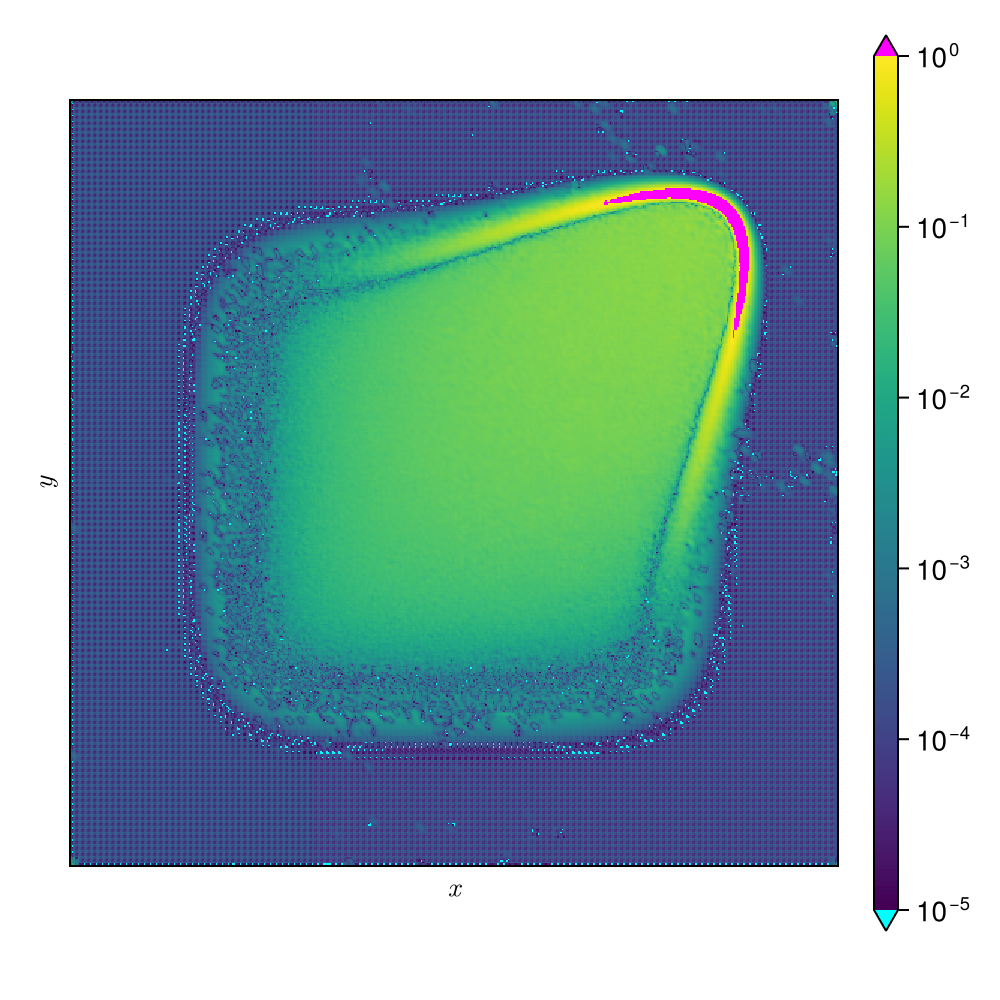
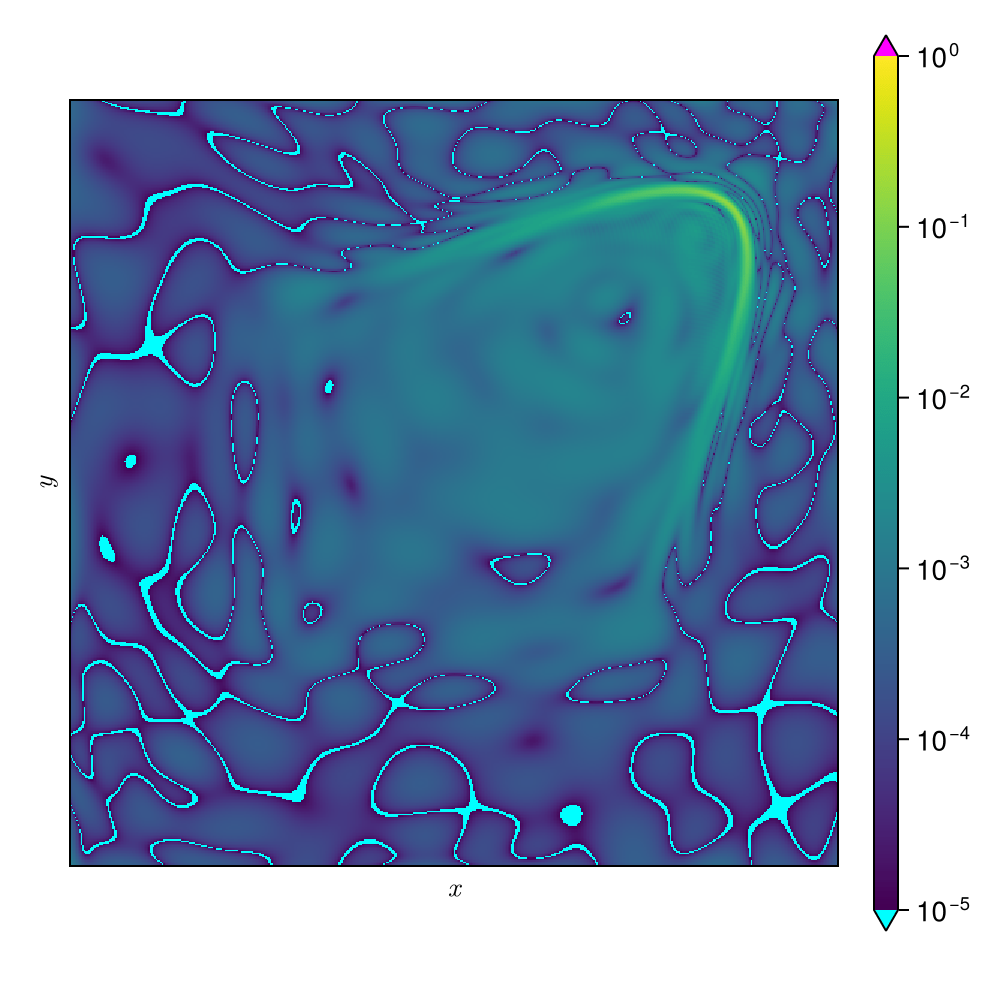
2D Viscous Burgers problem \( (\mathit{Re} = 1\text{k})\)
Reduced order modeling with smooth neural fields
High freq. noise
Non-differentiable!
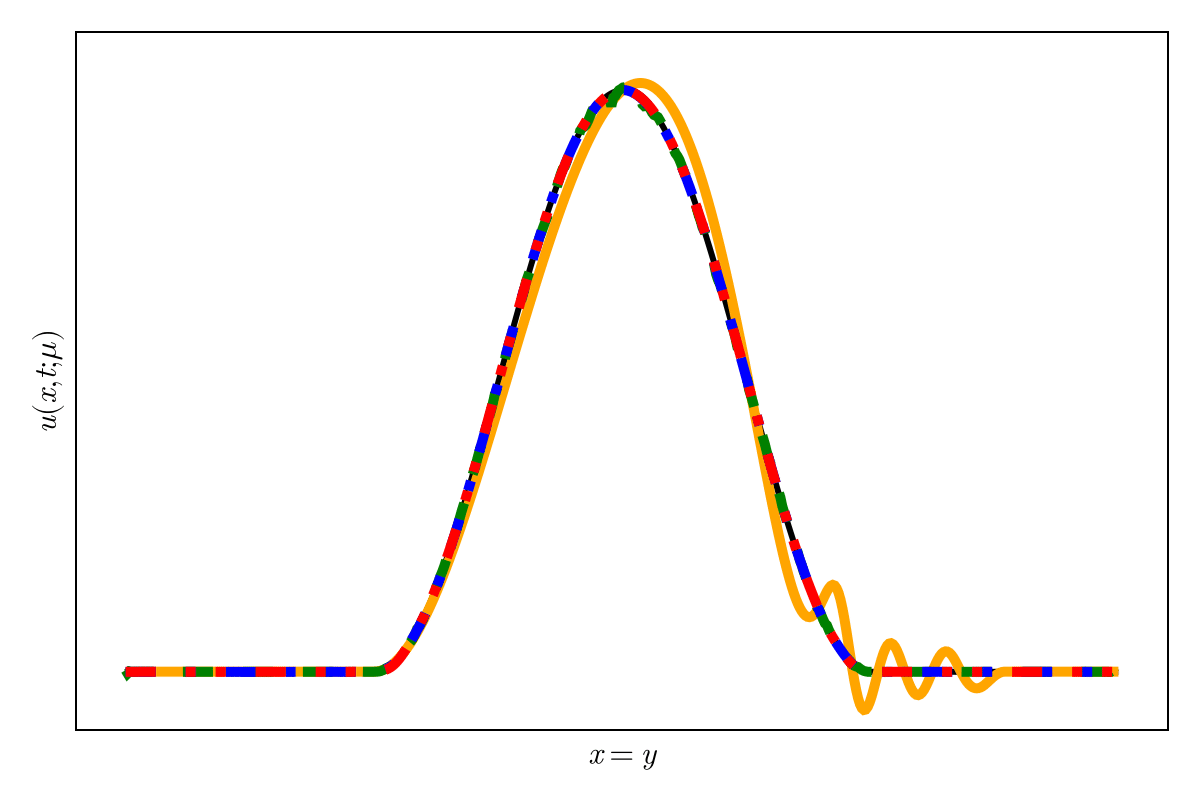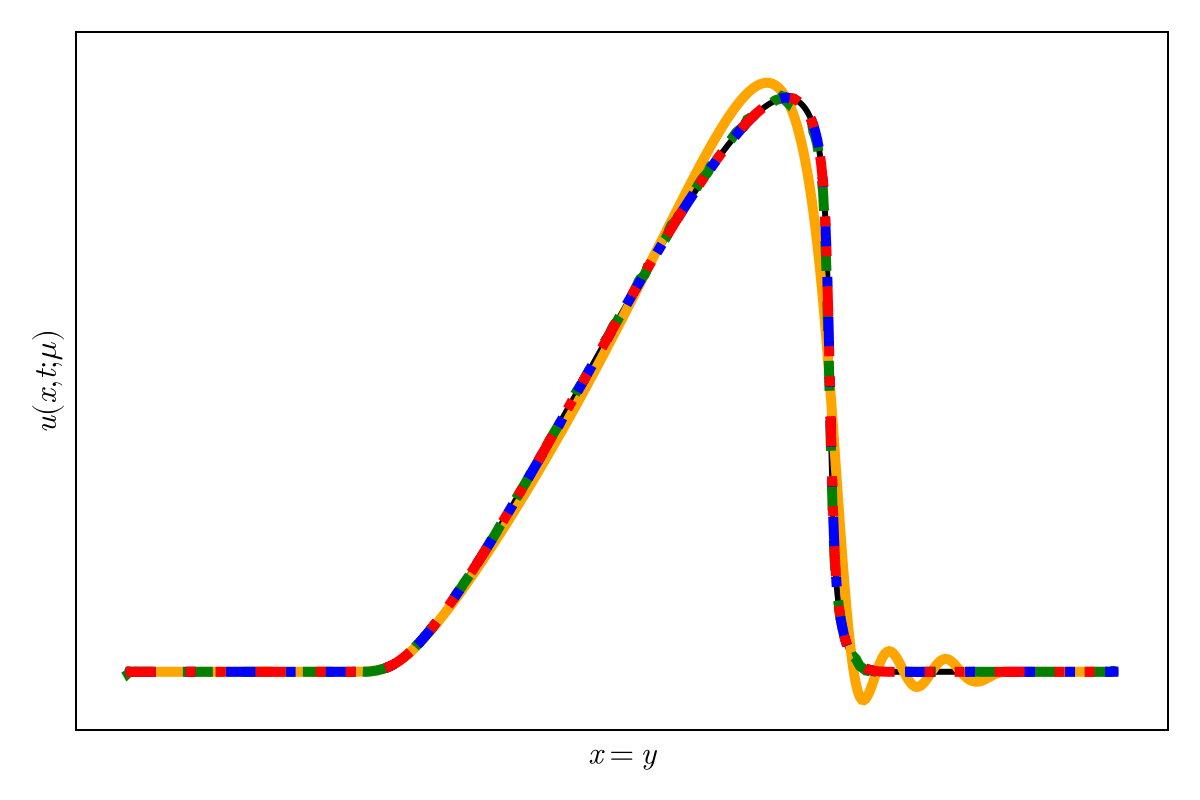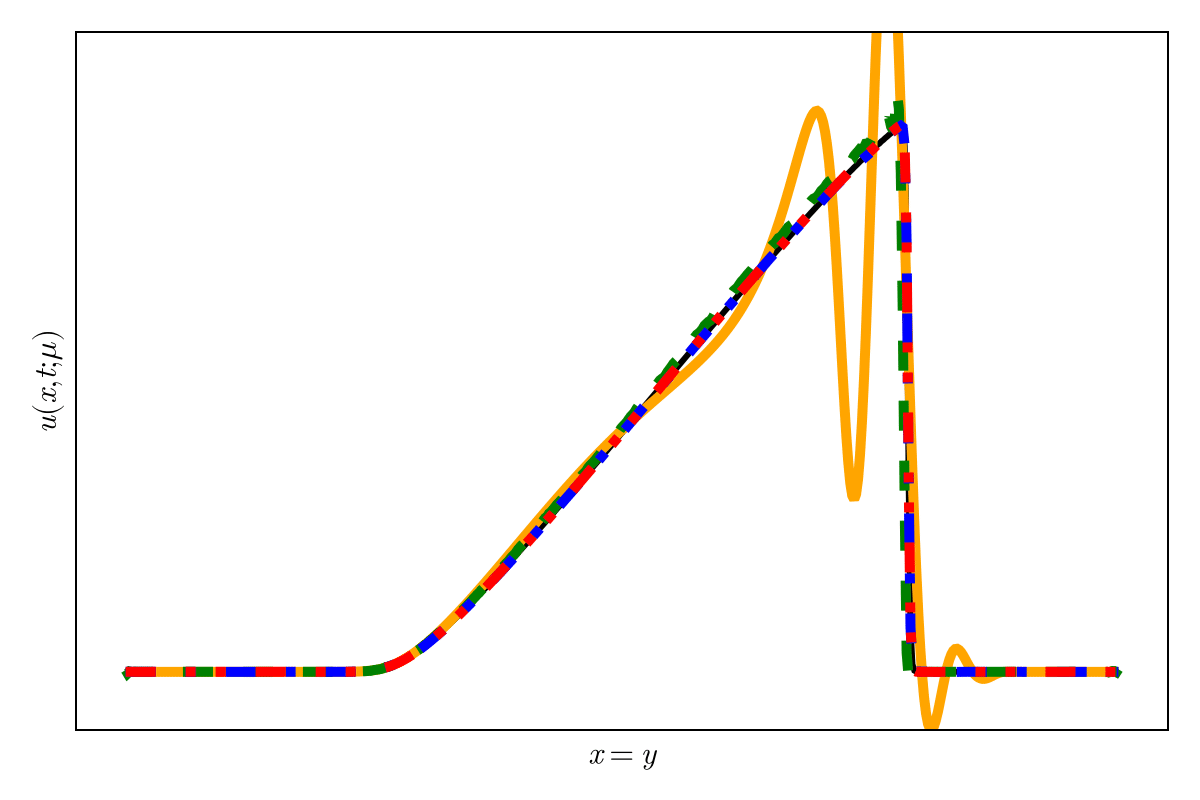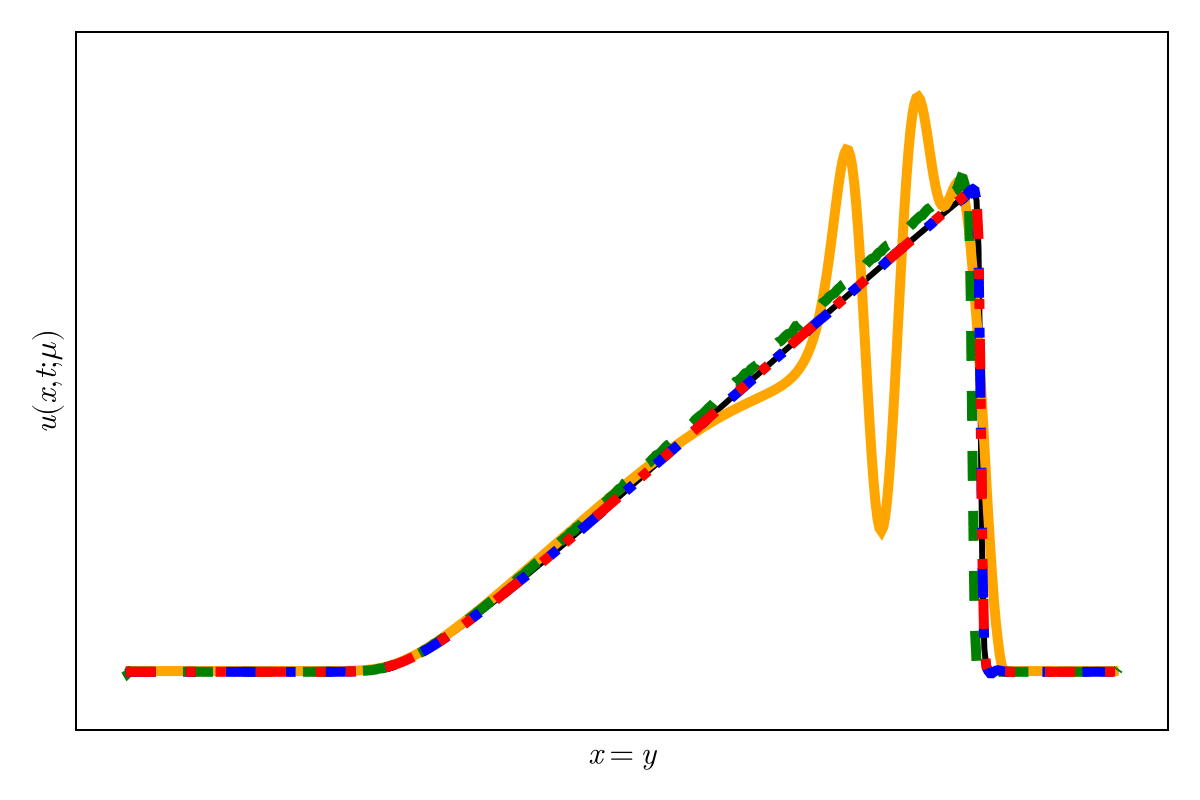
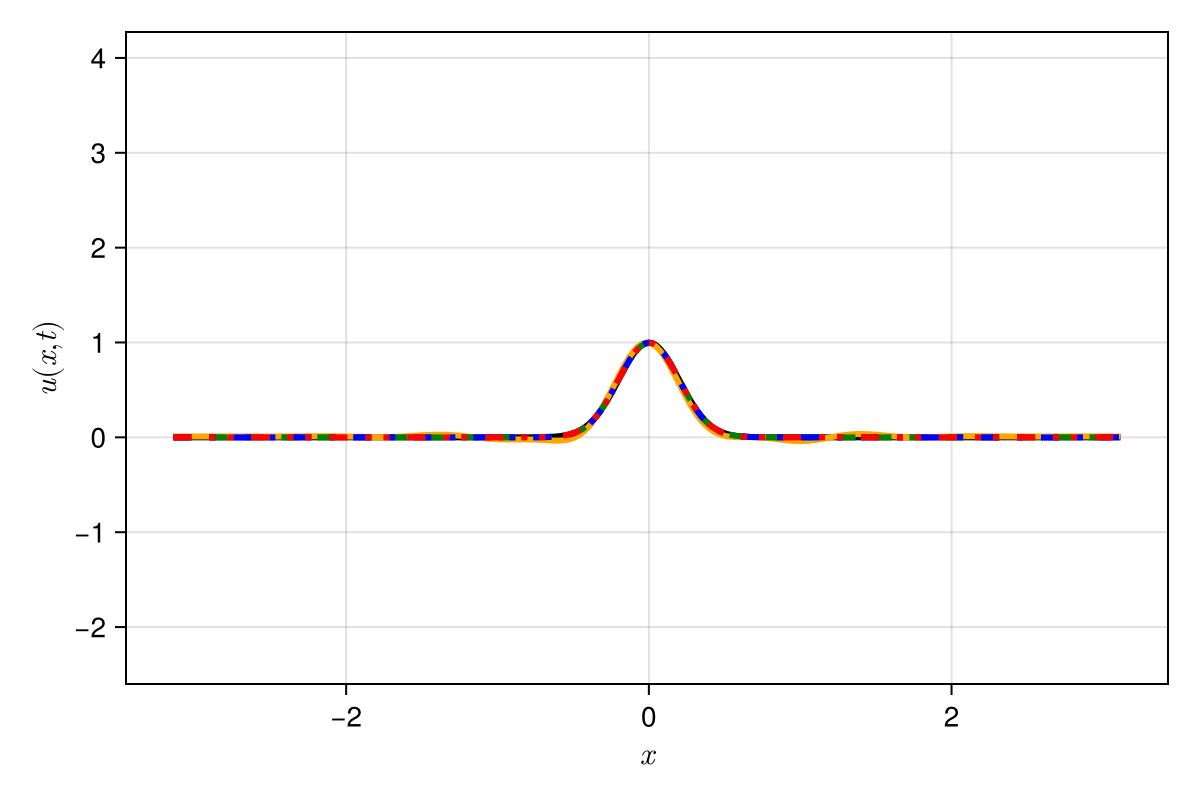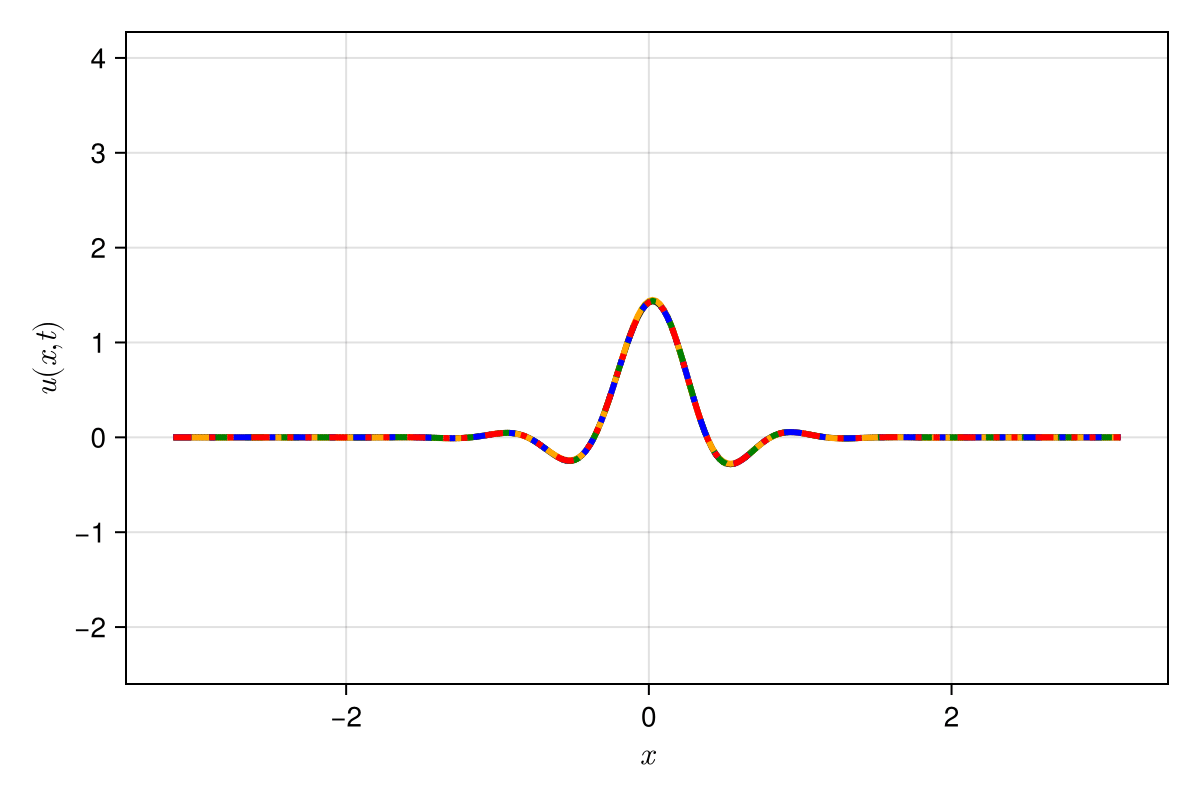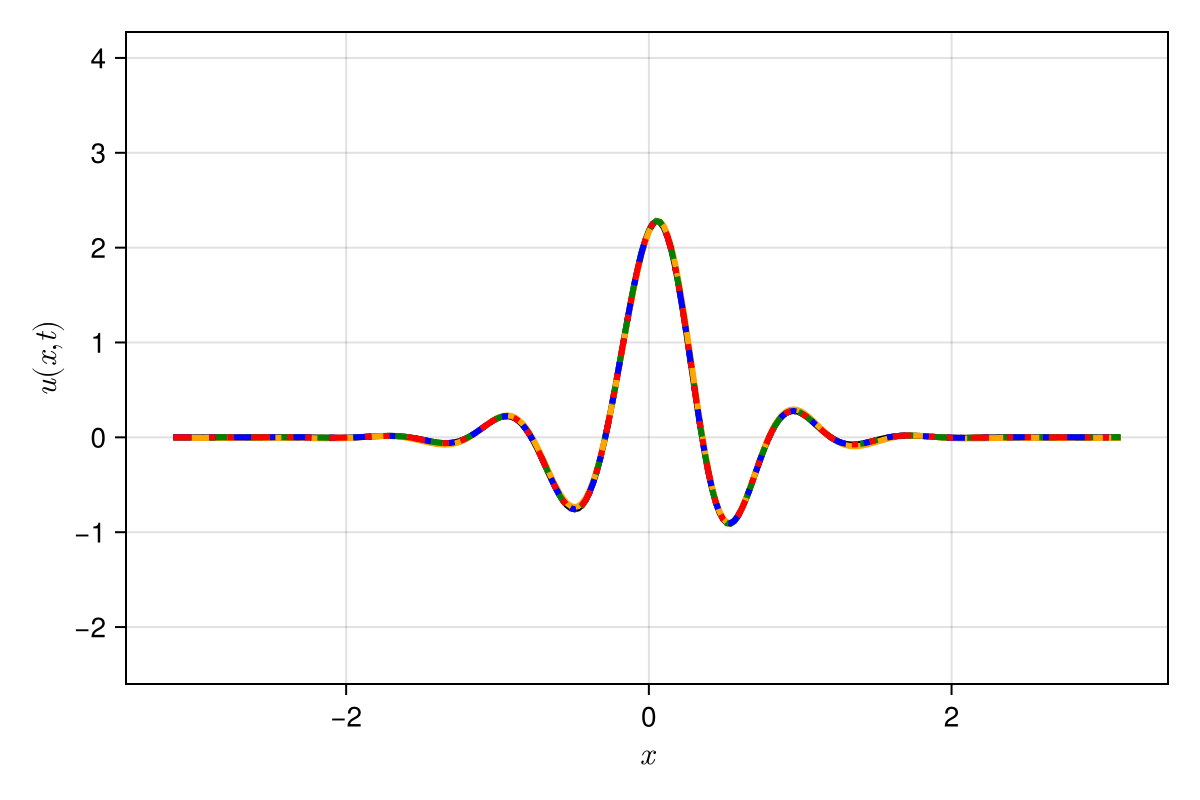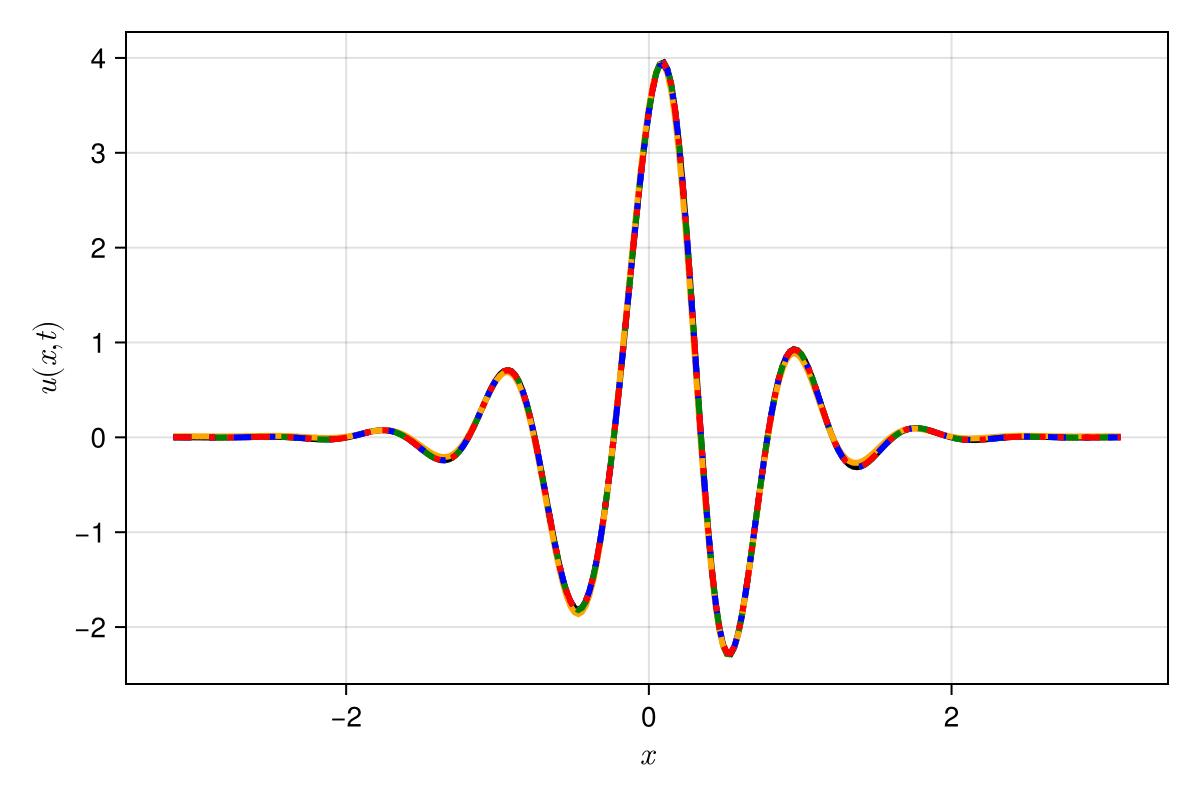
Accurately capture of dynamics with smooth neural fields
Accurate capture of dynamics
Baseline method
Our approaches
5
Full order model (FOM)
Linear POD-ROM
Nonlinear ROM
Learn low-order spatial representations
Time-evolution of reduced representation with Galerkin projection
4
\(\tilde{u}(t; \boldsymbol{\mu})\)
\(\Xi_\varrho\)
Q. What prior to place on the latent space to ensure smooth/accurate traversal?
Control the complexity of latent trajectories.
Supervised learning problem: \((\boldsymbol{x}, t; \boldsymbol{\mu}) \to \boldsymbol{u}(\boldsymbol{x}, t; \boldsymbol{\mu})\).
\(\text{Loss } (L)\)
\(\text{Backpropagation}\)
\(\nabla_\theta L\)
\(\nabla_\varrho L\)
\(\nabla_\theta L\)
\(\text{PDE Problem}\)
\((\boldsymbol{x}, t, \boldsymbol{\mu})\)
\(\text{ Parameters}\)
\( \text{and time}\)
\(\text{ Intrinsic ROM manifold}\)
\(\text{Coordinates}\)
\(\text{Smooth neural field MLP }(g_\theta)\)
\(\tilde{u}\)
\(\boldsymbol{x}\)
\(\boldsymbol{u}\left( \boldsymbol{x}, t; \boldsymbol{\mu} \right)\)
Learn \((t; \boldsymbol{\mu}) \to \tilde{u}(t; \boldsymbol{\mu})\) directly
6
Derivative calculation is carried out with automatic differentiation making the dynamics evaluation non-intrusive.
SNF-ROM with Lipschitz regularization (SNFL-ROM)
\(\text{Penalize the \textcolor{blue}{Lipschitz constant} of the MLP [arXiv:2202.08345]}\)
\(\text{[enwiki:1230354413]}\)
SNF-ROM with Weight regularization (SNFW-ROM)
\(\text{Directly penalize \textcolor{red}{high-frequency components} in }\dfrac{\text{d}}{\text{d} x}\text{NN}_\theta(x)\)
We present two approaches to learn inherently smooth and accurately differentiable neural field MLPs.
\({x}\)
\({u(x)}\)
Neural field MLPs are
non-differentiable
High freq. noise
8
Both Lipschitz regularization (SNFL) and weight regularization (SNFW) capture the 4-th order derivative accurately.
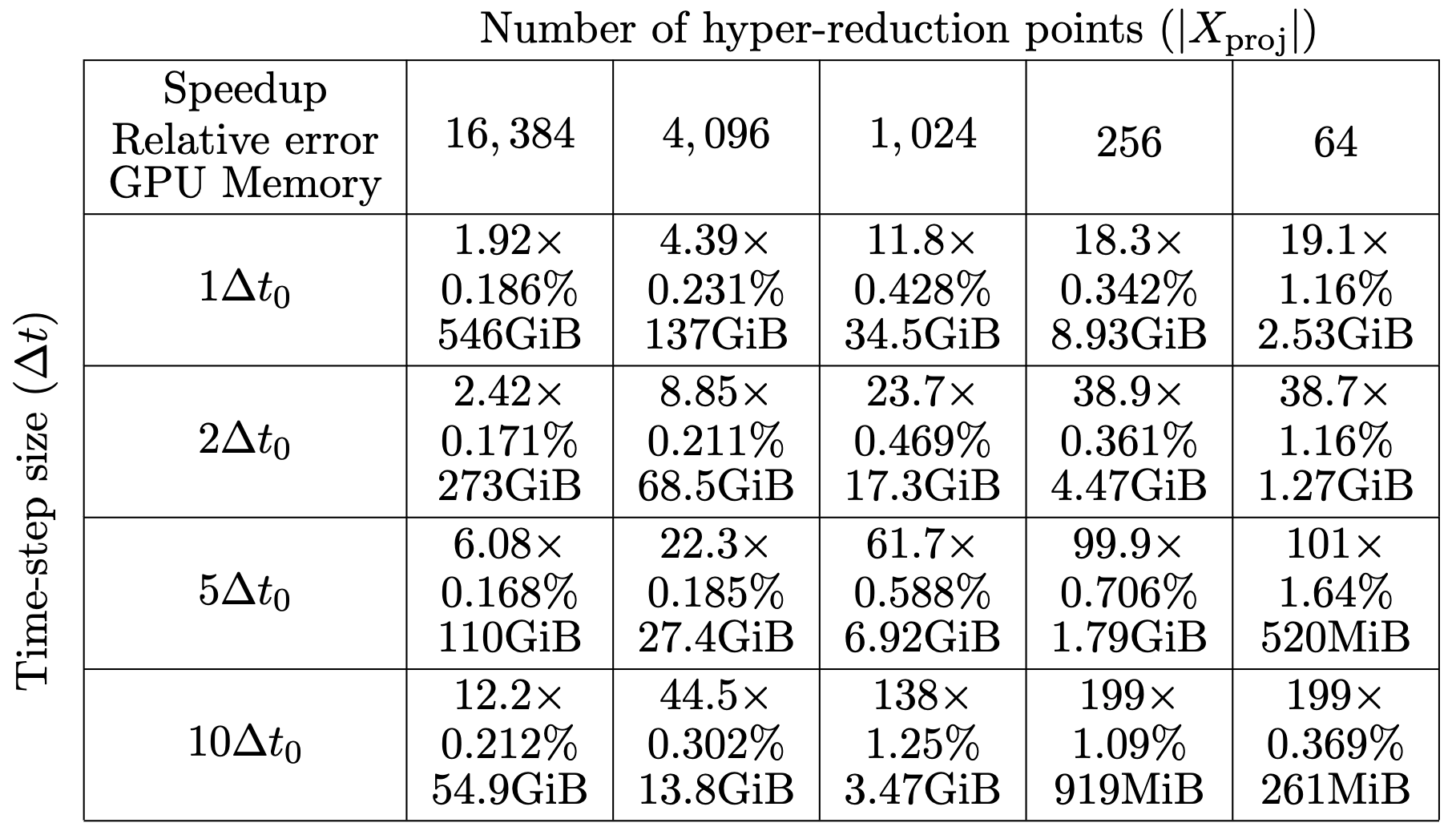
\(\text{Relative error } (\Delta t = \Delta t_0)\)
\(\text{Relative error } (\Delta t = 10\Delta t_0)\)
Oscillations due to variation in projection error
Highly diffusive; even POD with 2 modes
6
\(\text{CAE-ROM}\)
\(\text{SNFL-ROM}\)
\(\text{SNFW-ROM}\)
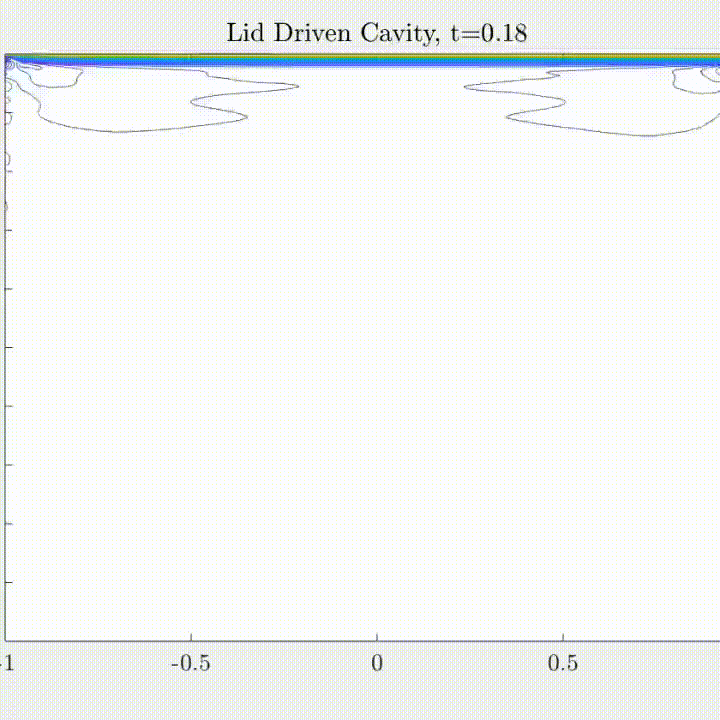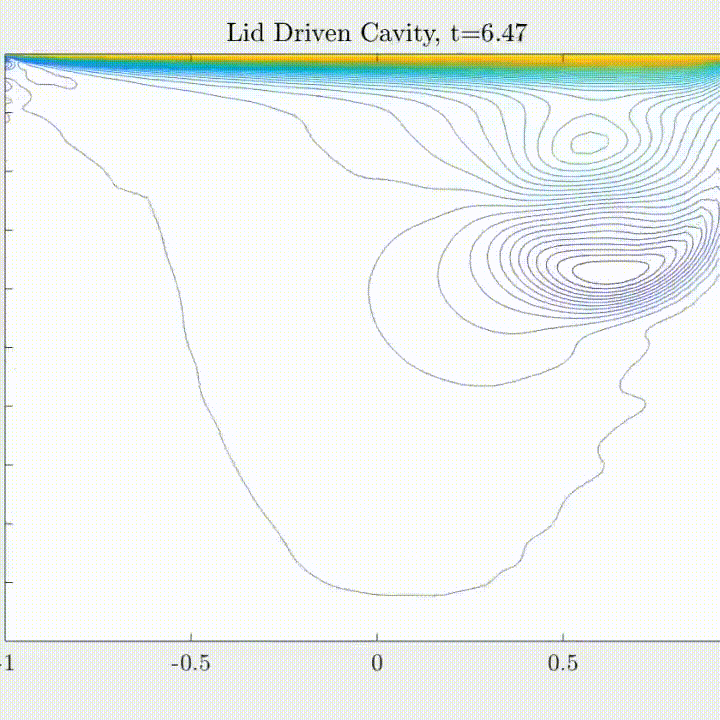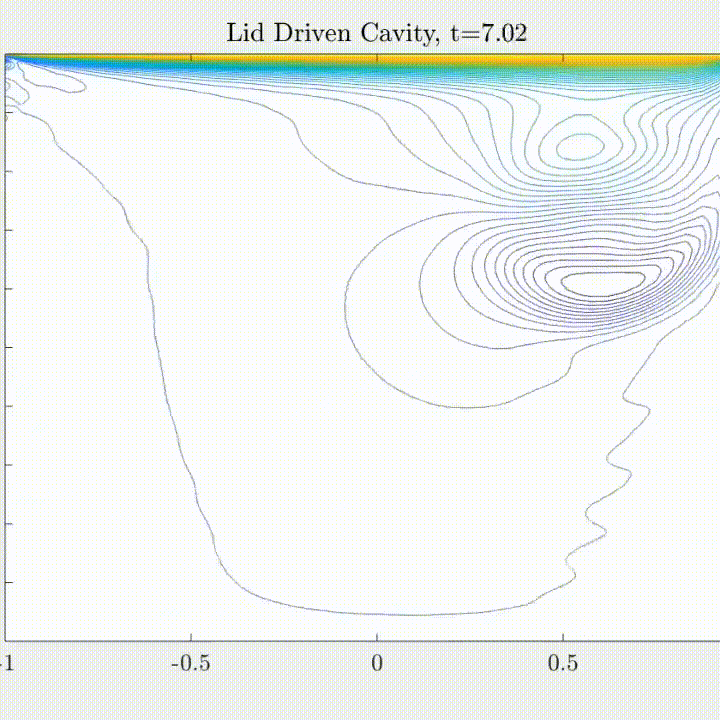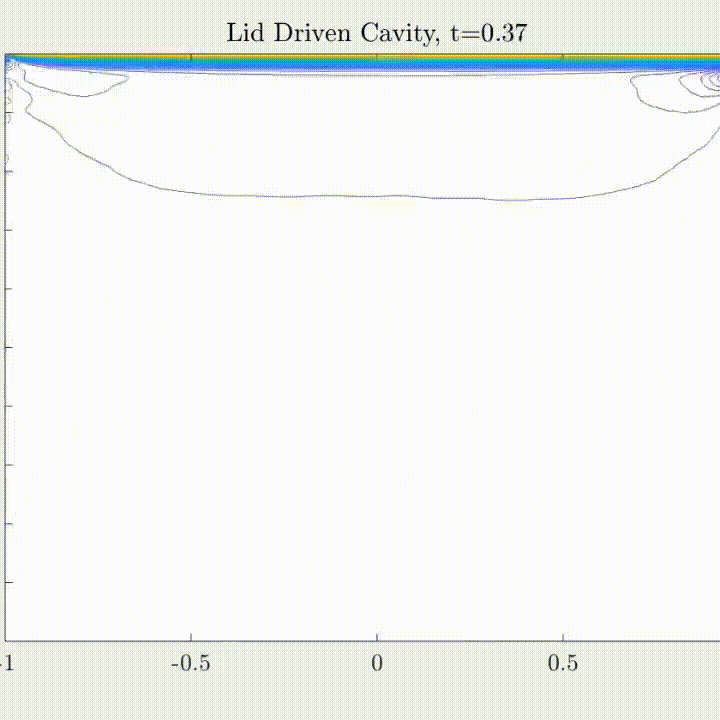
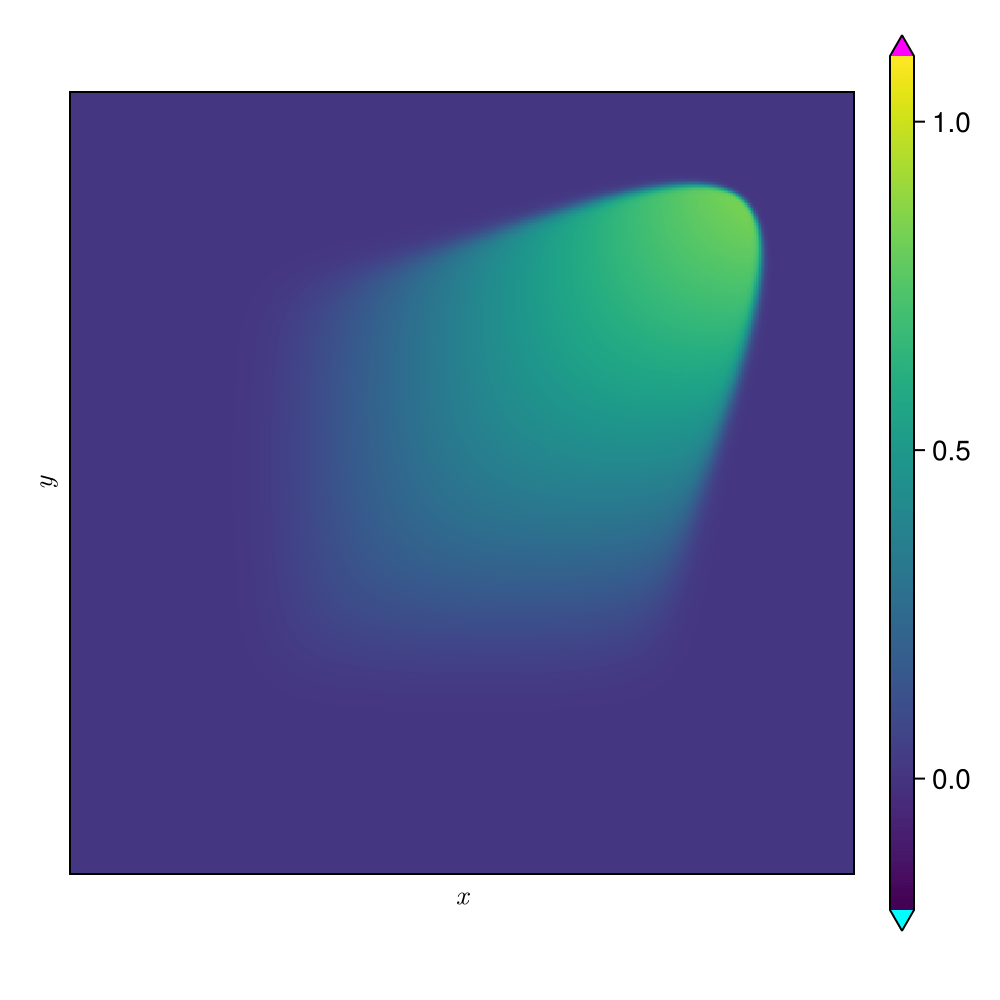
SNFL-ROM, SNFW-ROM effectively capture the traveling shock.
1
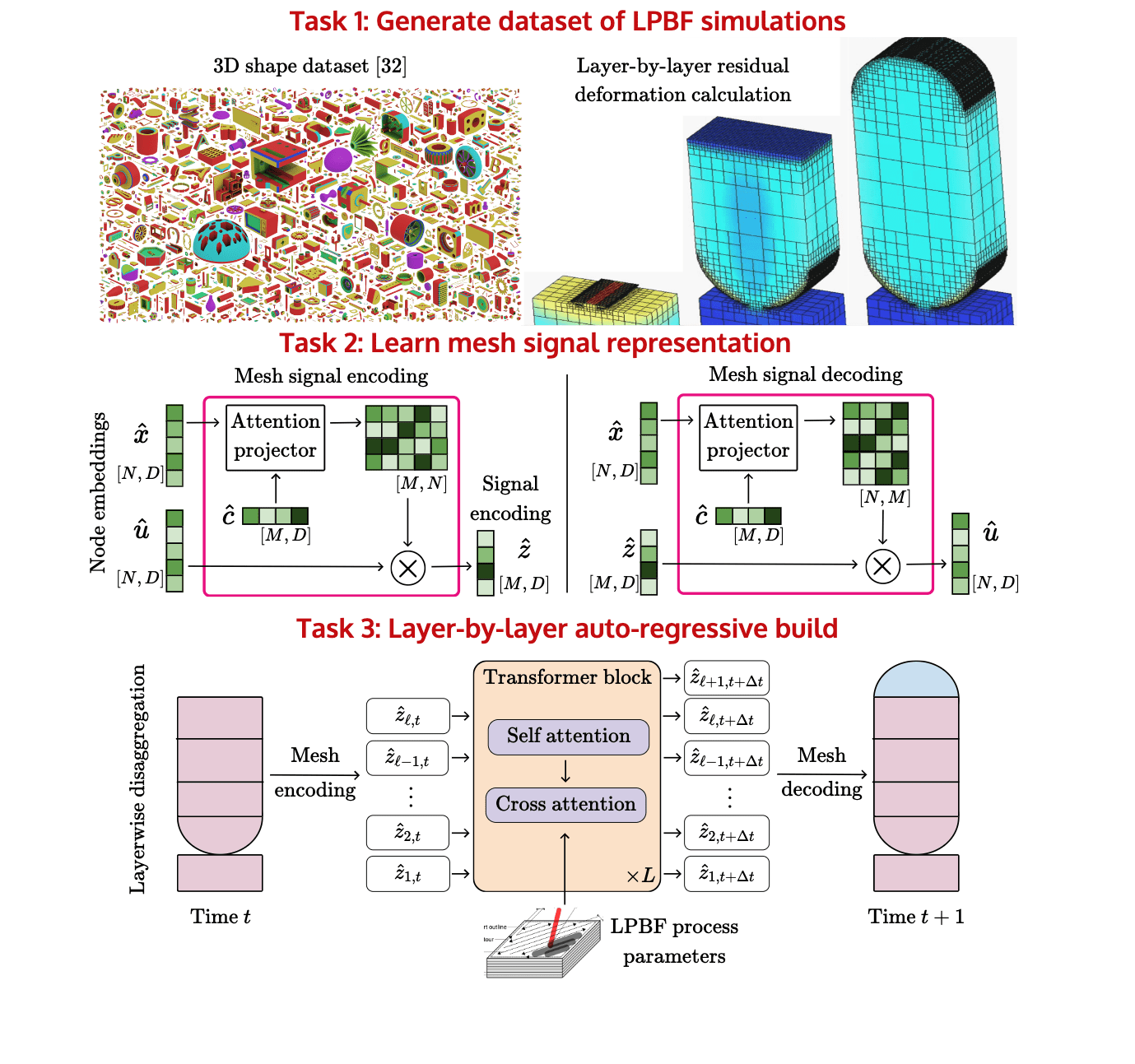
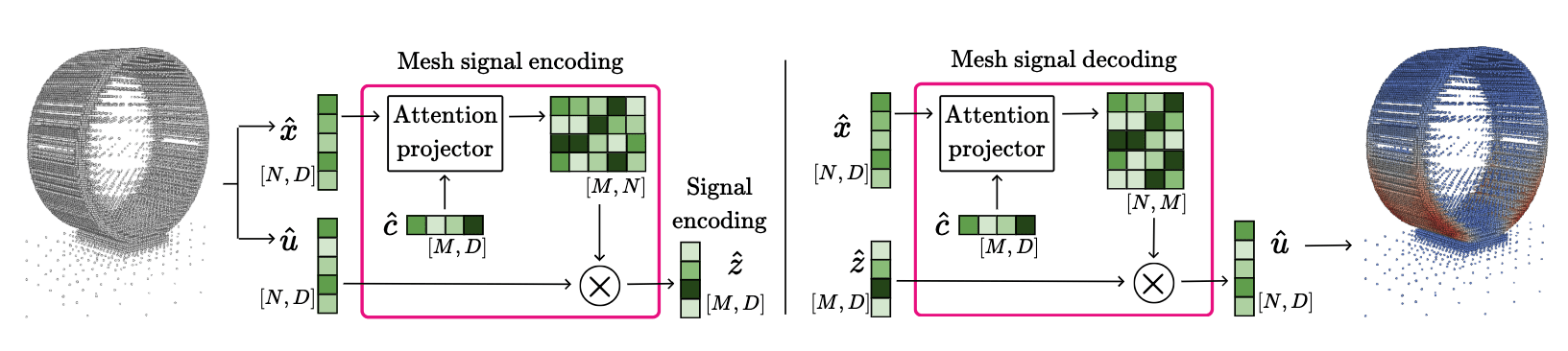
The challenge is geometry tokenization!
1
We learn an attention-based encoding scheme for tokenizing unstructured data that can be deployed on arbitrary point clouds
By Vedant Puri
Summary deck




