Supercharge ML experiments with Pytorch Lightning
Machine Learning Singapore
23 Feb 2023
Vivek Kalyan
hello@vivekkalyan.com
@vivekkalyansk
About Me
AI Research @ Handshakes
- Knowledge Graphs
- Entity Recognition, Entity Linking, Relationship Extraction
- Document Understanding
- Classification, Summarization
- Clustering, Trends, Events, Recommendation
- Information Extraction
- PDFs, Tables
Agenda
- Why Pytorch-Lightning?
- Convert Pytorch to Pytorch-Lightning
- Features
- Experiment Management
- Dev Features
- Memory Features
- Optimizer Features
- Deployment
- .. and more!
Why Pytorch Lightning?
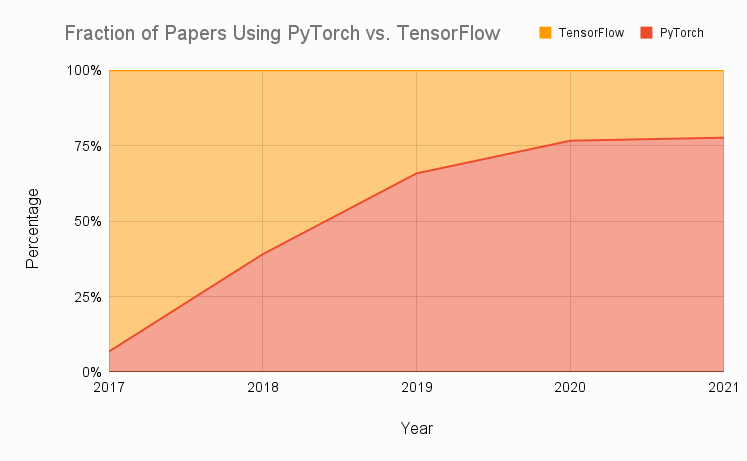
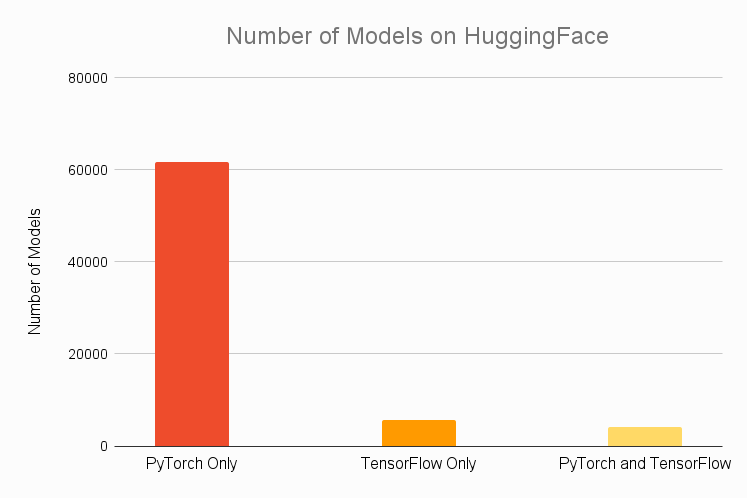
Why Pytorch?
- Most popular framework for research
- Stable APIs
- Pytorch 2.0 release is exciting!
- Intuitive and explicit ...
Easy to make mistakes in Pytorch
- "Boilerplate code"
- call
.zero_grad() - call
.train()/.eval()/.no_grad() - call
.to(device)
- call

Pytorch Lightning Decouples Engineering & Research Code

- Research code
-
Model
-
Data
-
Loss + Optimizer
-
-
Engineering Code
-
Train/Val/Test Loops
-
Everything else ...
-
Convert Pytorch to
Pytorch Lightning
class Net(LightningModule):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
def train_dataloader(self):
mnist_train = MNIST(os.getcwd(), train=True,
download=True, transform=transforms.ToTensor())
return DataLoader(mnist_train, batch_size=64)
def configure_optimizers(self):
optimizer = Adam(self.parameters(), lr=1e-3)
return optimizer
def training_step(self, batch, batch_idx):
data, target = batch
output = self.forward(data)
loss = F.nll_loss(output, target)
return {"loss": loss}
if __name__ == "__main__":
net = Net()
trainer = Trainer(accelerator="gpu", max_epochs=10)
trainer.fit(net)class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
mnist_train = MNIST(os.getcwd(), train=True, download=True,
transform=transforms.ToTensor())
train_loader = DataLoader(mnist_train, batch_size=64)
net = Net().to(device)
optimizer = Adam(net.parameters(), lr=1e-3)
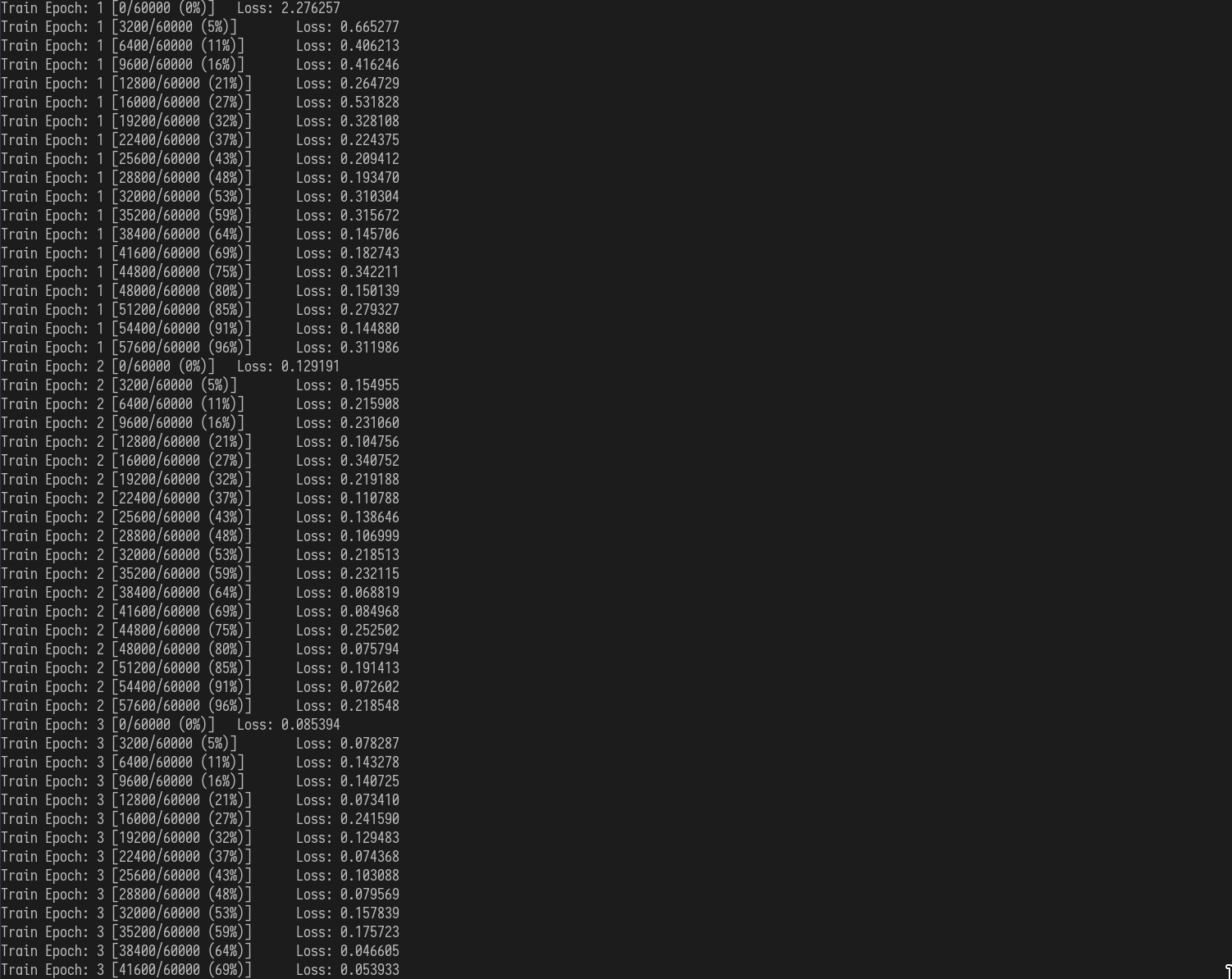
for epoch in range(1, 11):
net.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = net(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % 50 == 0:
print("Train Epoch: {} [{}/{} ({:.0f}%)]\t
Loss: {:.6f}".format(epoch,
batch_idx * len(data),
len(train_loader.dataset),
100 * batch_idx / len(train_loader),
loss.item()))
Pytorch
Pytorch Lightning
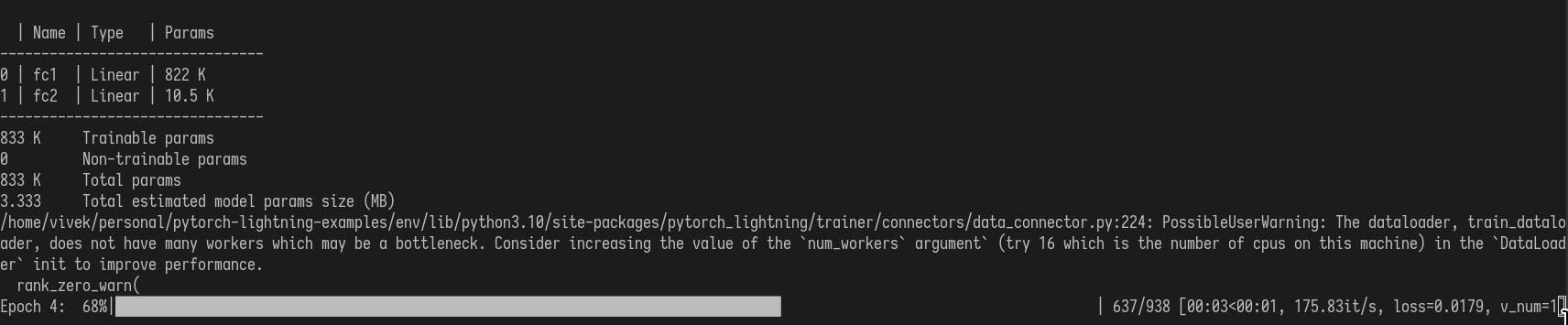
Features
Experiments Management
- keeping track of multiple experiments
Logging
- Automatically creates a folder for each run
- Saves any values logged with
self.log- Automatically decides if should log at current step or accumulate and log at end of epoch
- Choose from different loggers
- Tensorboard
- Comet
- MLFlow
- Neptune
- Weights and Biases
class Net(LightningModule):
def __init__(self):
super(Net, self).__init__()
self.save_hyperparameters()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
# ... forward
def train_dataloader(self):
# ... train_dataloader
def configure_optimizers(self):
# ... configure_optimizers
def training_step(self, batch, batch_idx):
data, target = batch
output = self.forward(data)
loss = F.nll_loss(output, target)
self.log("loss", loss)
return {"loss": loss}
if __name__ == "__main__":
net = Net()
logger = TensorBoardLogger()
trainer = Trainer(accelerator="gpu", max_epochs=10, logger=logger)
trainer.fit(net)Tensorboard
Tensorboard
$ tensorboard --logdir lightning_logs --port 8888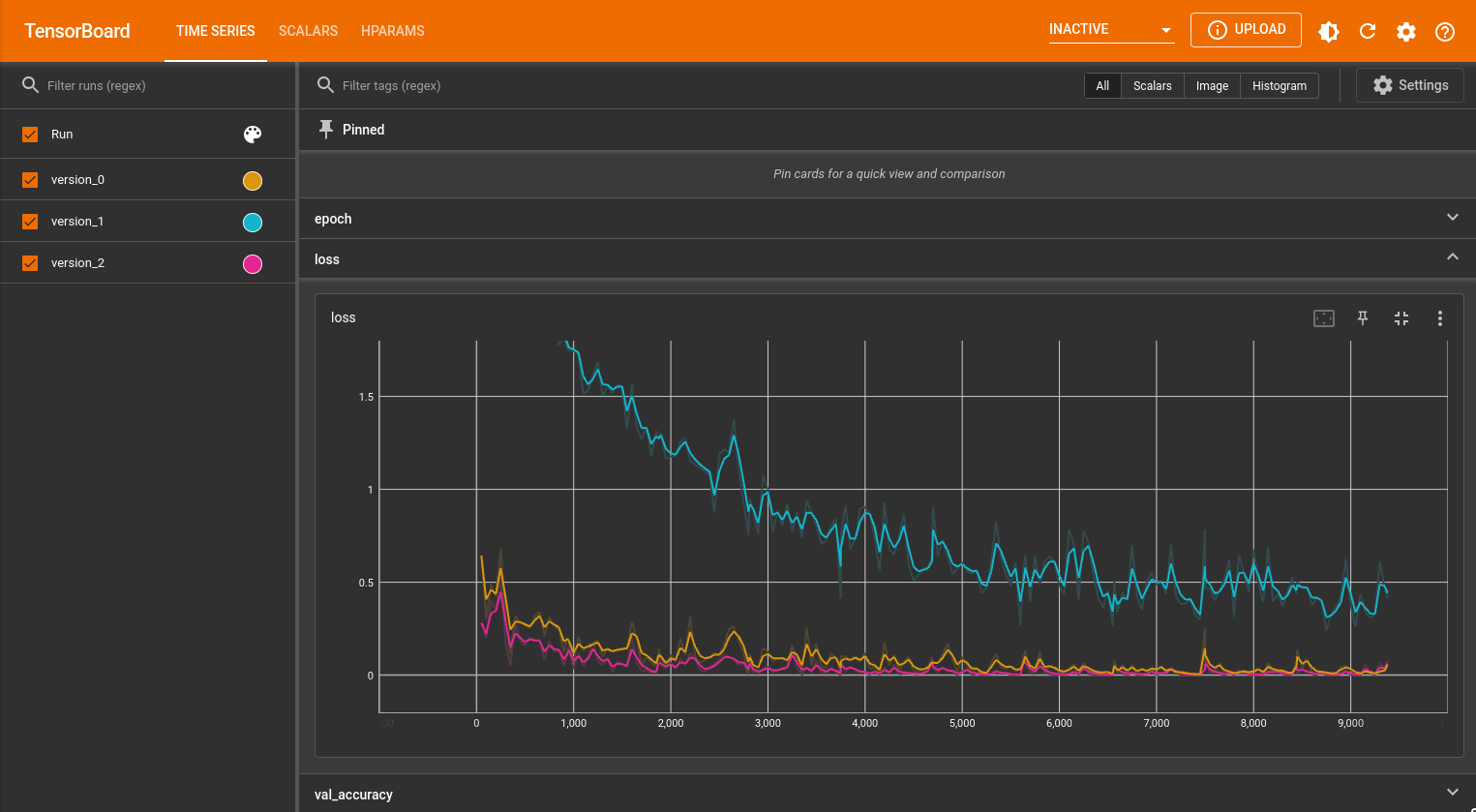
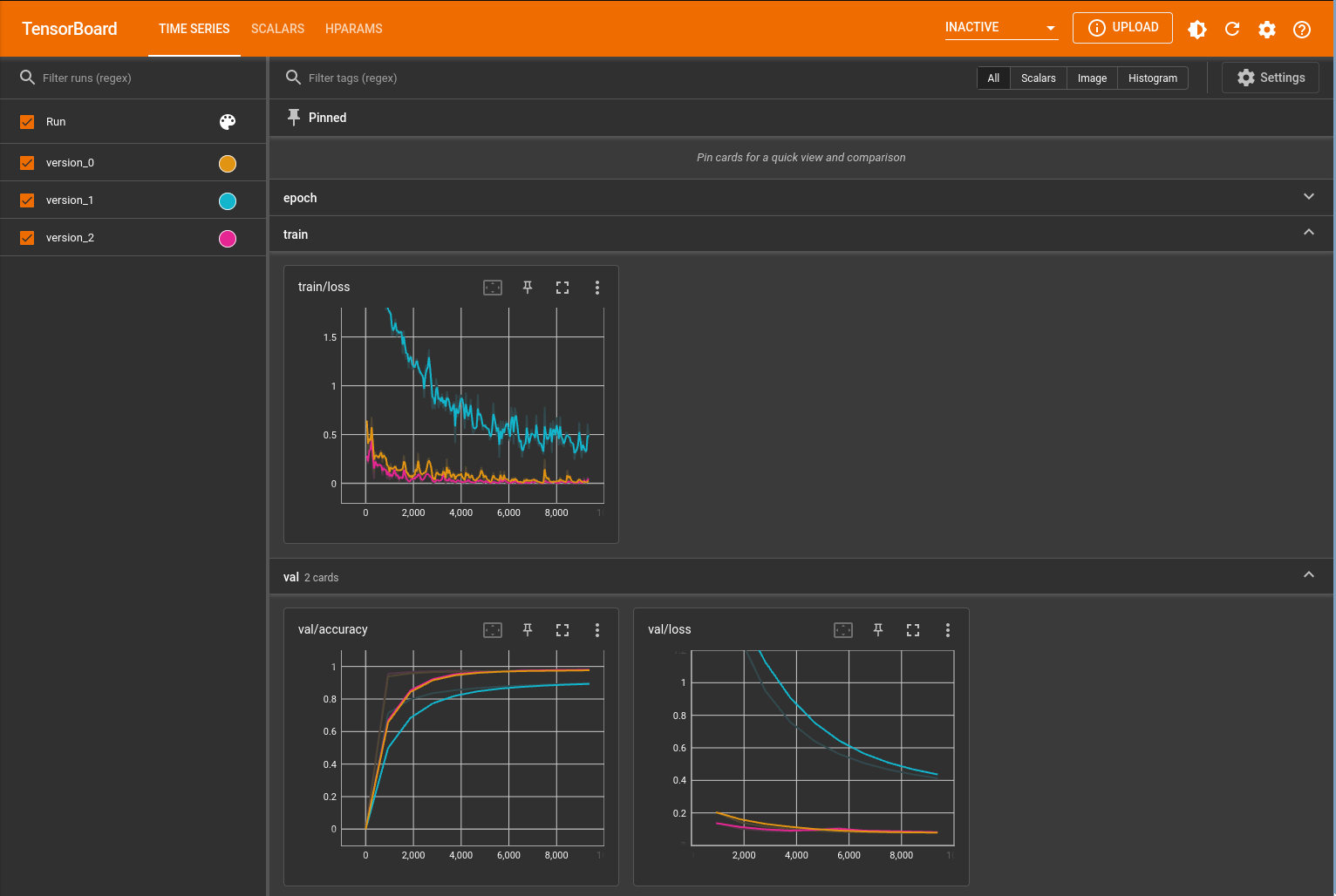
Validation/Test Dataset
class Net(LightningModule):
def __init__(self):
# ... init
def forward(self, x):
# ... forward
def train_dataloader(self):
# ... train_dataloader
def val_dataloader(self):
mnist_train = MNIST(os.getcwd(), train=False, download=True,
transform=transforms.ToTensor())
return DataLoader(mnist_train, batch_size=self.batch_size)
def configure_optimizers(self):
# ... configure_optimizers
def training_step(self, batch, batch_idx):
# ... training_step
def validation_step(self, batch, batch_idx):
data, target = batch
output = self.forward(data)
loss = F.nll_loss(output, target)
pred = output.argmax(dim=1, keepdim=True)
correct = pred.squeeze(1).eq(target).sum().item()
self.log("val/loss", loss)
return {"loss": loss, "correct": correct, "total": len(target)}
def validation_epoch_end(self, outs):
num_correct = sum(map(lambda x: x[f"correct"], outs), 0)
num_total = sum(map(lambda x: x[f"total"], outs), 0)
self.log("val/accuracy", num_correct / num_total)
if __name__ == "__main__":
# ...
Metrics
- Define metrics to be tracked
class Net(LightningModule):
def __init__(self):
# ... init
def forward(self, x):
# ... forward
def train_dataloader(self):
# ... train_dataloader
def val_dataloader(self):
# ... val_dataloader
def configure_optimizers(self):
# ... configure_optimizers
def on_train_start(self):
self.logger.log_hyperparams(self.hparams, {"val/accuracy": 0})
def training_step(self, batch, batch_idx):
# ... training_step
def validation_step(self, batch, batch_idx):
# ... validation_step
def validation_epoch_end(self, outs):
num_correct = sum(map(lambda x: x[f"correct"], outs), 0)
num_total = sum(map(lambda x: x[f"total"], outs), 0)
self.log("val/accuracy", num_correct / num_total)
if __name__ == "__main__":
# ...
Metrics
Custom checkpointing
- Configure checkpoint saving to save best model based on logged metric
class Net(LightningModule):
# ... net
if __name__ == "__main__":
net = Net()
logger = TensorBoardLogger()
checkpoint_callback = ModelCheckpoint(monitor='val/accuracy', mode='max', verbose=True)
trainer = Trainer(callbacks = [checkpoint_callback], accelerator="gpu", max_epochs=10, logger=logger)
trainer.fit(net)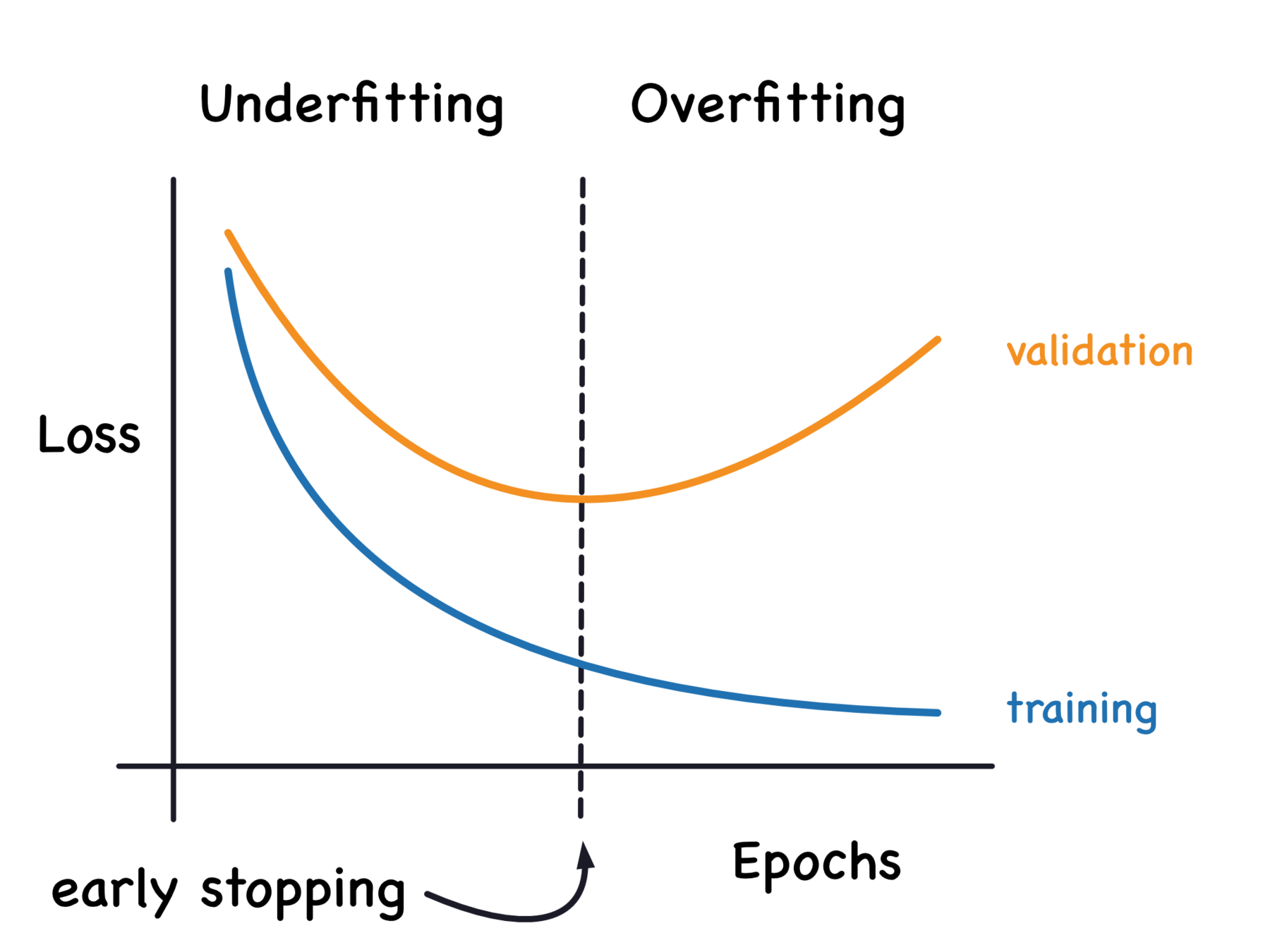
Early Stopping
-
Rules for early stopping
- Maximise or minimize metric
- Patience ...
class Net(LightningModule):
# ... net
if __name__ == "__main__":
net = Net()
logger = TensorBoardLogger()
checkpoint_callback = ModelCheckpoint(monitor='val/accuracy', mode='max', verbose=True)
early_stopping_callback = EarlyStopping(monitor='val/accuracy', mode='max', patience=2)
trainer = Trainer(callbacks = [early_stopping_callback, checkpoint_callback],
accelerator="gpu", max_epochs=10, logger=logger)
trainer.fit(net)Dev Features
- make development easier
Command line arguments
- Control model hyper-parameters via CLI
- Lightning Trainer provides function to expose configuring it through CLI as well
class Net(LightningModule):
def __init__(self, batch_size, hidden_size, learning_rate, **kwargs):
# ... init
def add_model_specific_args(parent_parser):
parser = parent_parser.add_argument_group("Net")
parser.add_argument("--batch_size", type=int, default=64)
parser.add_argument("--hidden_size", type=int, default=128)
parser.add_argument("--learning_rate", type=float, default=1e-3)
return parent_parser
def forward(self, x):
# ... forward
if __name__ == "__main__":
# ...
parser = ArgumentParser()
parser = Net.add_model_specific_args(parser)
parser = Trainer.add_argparse_args(parser)
args = parser.parse_args()
net = Net(**vars(args))
trainer = Trainer.from_argparse_args(args)
trainer.fit(net)Fast Dev Run
- Run one batch of train/val/test
- Useful to verify pipeline works before starting long run
$ python train.py --fast_dev_runOverfit batch
- Overfits training against small % of dataset
- Sanity check to verify that loss is decreasing ~ model is learning
$ python train.py --overfit_batches 0.01Learning Rate Finder
class Net(LightningModule):
# ... net
if __name__ == "__main__":
net = Net()
trainer = Trainer(accelerator="gpu", max_epochs=10)
# Run learning rate finder
lr_finder = trainer.tuner.lr_find(model)
# Plot with
fig = lr_finder.plot(suggest=True)
fig.show()
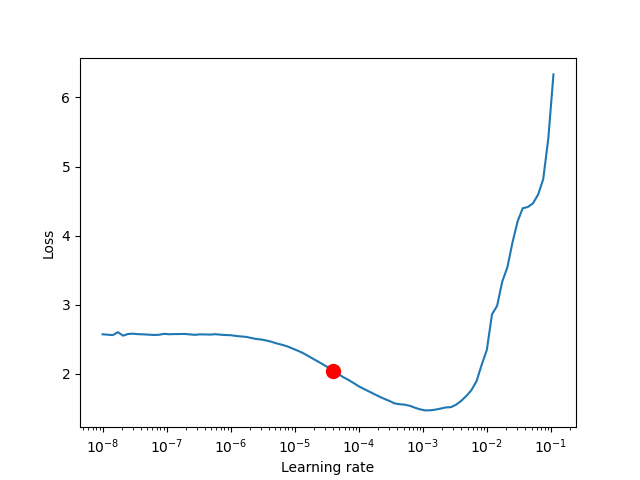
- Increase learning rate is for each batch and corresponding loss is logged
- Plot learning rate vs loss
- Suggest learning rate at highest rate of loss decrease
Memory Features
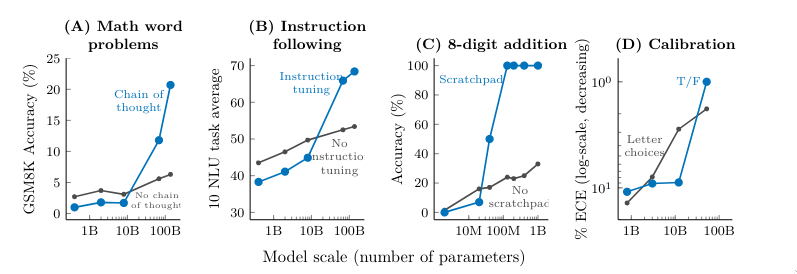
Emergent Abilities of Large Language Models (Wei et al., 2022)
Precision 16
- Using fp16 instead of fp32 for parameters
- fit larger models/batches on GPU for ~ free
- increases training speed for ~ free
$ python train.py --precision 16Acculumate Gradients
- Calculate gradients for N batches before updating parameters
- Effective batch size = batch_size * N
$ python train.py --accumulate_grad_batches 4Optimizer Features
Gradient Clipping
- Clip gradients above set value.
- Helps to prevent exploding gradients
$ python train.py --gradient_clip_val 1Stochastic Weight Averaging
- Helps prevent loss being stuck in local minimum
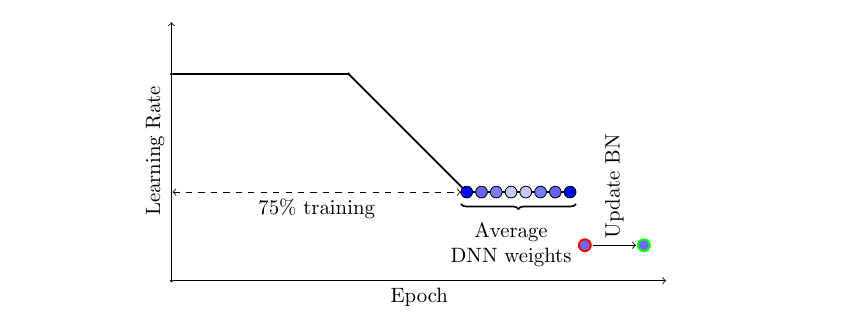
class Net(LightningModule):
# ... net
if __name__ == "__main__":
net = Net()
logger = TensorBoardLogger()
swa_callback = StochasticWeightAveraging(swa_lrs=1e-2)
trainer = Trainer(callbacks = [swa_callback],
accelerator="gpu", max_epochs=10, logger=logger)
trainer.fit(net)Quantization Aware Training (beta)
- Models quantization errors in both the forward and backward passes using fake-quantization modules.
- After training, model is converted to lower precision
Deployment
- export to multiple formats
Predict with Pure Pytorch
- Swap
pl.LightningModule->nn.Module - No Lightning dependency for prediction
- access to entire ecosystem of Pytorch deployment
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28 * 28, 128)
self.fc2 = nn.Linear(128, 10)
def forward(self, x):
x = x.view(x.size(0), -1)
x = self.fc1(x)
x = F.relu(x)
x = self.fc2(x)
output = F.log_softmax(x, dim=1)
return output
model = Net()
checkpoint = torch.load("path/to/lightning/checkpoint.ckpt")
model.load_state_dict(checkpoint["state_dict"])
model.eval()
... and more!
- Profilers
- Quantization/Pruning
- (Distributed) GPU optimizations
- ...
Thank you!
pytorch-lightning
By vivekkalyan

