Node Core #4
File system
Plan
- "fs" overview
- "path" overview
- Promisified "fs"
- Buffers
- streams
"fs" overview
The fs module provides a lot of very useful functionality to access and interact with the file system.
const fs = require('fs')
-
fs.access(): check if the file exists and Node.js can access it with its permissions -
fs.appendFile(): append data to a file. If the file does not exist, it's created -
fs.chmod(): change the permissions of a file specified by the filename passed. Related:fs.lchmod(),fs.fchmod() -
fs.chown(): change the owner and group of a file specified by the filename passed. Related:fs.fchown(),fs.lchown() -
fs.close(): close a file descriptor -
fs.copyFile(): copies a file -
fs.createReadStream(): create a readable file stream -
fs.createWriteStream(): create a writable file stream -
fs.link(): create a new hard link to a file -
fs.mkdir(): create a new folder -
fs.mkdtemp(): create a temporary directory -
fs.open(): set the file mode -
fs.readdir(): read the contents of a directory -
fs.readFile(): read the content of a file. Related:fs.read() -
fs.readlink(): read the value of a symbolic link -
fs.realpath(): resolve relative file path pointers (.,..) to the full path -
fs.rename(): rename a file or folder -
fs.rmdir(): remove a folder -
fs.stat(): returns the status of the file identified by the filename passed. Related:fs.fstat(),fs.lstat() -
fs.symlink(): create a new symbolic link to a file -
fs.truncate(): truncate to the specified length the file identified by the filename passed. Related:fs.ftruncate() -
fs.unlink(): remove a file or a symbolic link -
fs.unwatchFile(): stop watching for changes on a file -
fs.utimes(): change the timestamp of the file identified by the filename passed. Related:fs.futimes() -
fs.watchFile(): start watching for changes on a file. Related:fs.watch() -
fs.writeFile(): write data to a file. Related:fs.write()
const express = require("express");
const fs = require("fs");
const app = express();
app.get("/file", (req, res) => {
let file = fs.readFileSync("package.json", "utf8");
res.setHeader('Content-Length', file.length);
res.setHeader('Content-disposition', 'attachment; filename=test.txt');
res.setHeader('Content-type', 'text/html');
res.write(file, 'binary');
res.end();
})Let's find an issue here
readFileSync also blocks any other code from execution
Sync & Async
This makes a huge difference in your application flow.
const fs = require('fs')
fs.rename()
fs.renameSync()
fs.write()
fs.writeSync()
try {
fs.renameSync('before.json', 'after.json')
//done
} catch (err) {
console.error(err)
}const express = require("express");
const fs = require("fs");
const app = express();
app.get("/file", (req, res) => {
fs.readFile("package.json", "utf8", (error, data) => {
res.setHeader('Content-Length', data.length);
res.setHeader('Content-disposition', 'attachment; filename=test.txt');
res.setHeader('Content-type', 'text/html');
res.write(data, 'binary');
res.end();
});
})Is that solved an issue?
Well partially...
fs.readfile loads the whole file into the memory you pointed out, the fs.createReadStream, on the other hand, reads the entire file in chunks of sizes that you specified
fs.readdir
fs.readdir(path.resolve(), (err, list) => {
console.log('Files:', list);
})
/*
Files: [
'asd.js',
'evens.js',
'fp.js',
'index.js',
'monitor.js',
'node_modules',
'package-lock.json',
'package.json',
'test.ts',
'Untitled-1.mongodb'
]
*/"path" overview
The path module provides a lot of very useful functionality to access and interact with the file system.

const path = require('path');
console.log(path.basename('/test/something/file.txt')); // file.txt
console.log(path.dirname('/test/something/file.txt')); // /test/something
console.log(path.extname('/test/something/file.txt')); // .txt
console.log(path.parse('/test/something/file.txt'));
/*
{
root: '/',
dir: '/test/something',
base: 'file.txt',
ext: '.txt',
name: 'file'
}
*/
console.log(path.normalize('/users/joe/..//test.txt')); // /users/test.txt
console.log(path.join('/', 'users', 'joe', 'notes.txt')) //'/users/joe/notes.txt'
console.log(path.resolve('asd.js')) // /Users/joe/tmp/asd.js;The Node.js path module
Promisified "fs"
util.promisify(original)
const util = require('util');
const fs = require('fs');
const stat = util.promisify(fs.stat);
async function callStat() {
const stats = await stat('.');
console.log(`This directory is owned by ${stats.uid}`);
}An alternative set of asynchronous file system methods that return Promise objects rather than using callbacks. The API is accessible via require('fs').promises.
const fs = require('fs/promises');
const path = require('path');
fs.readdir(pref, { withFileTypes: true })
.then(list => {
console.log('files', list)
});The fs.promises API
Buffers
Fixed-size chunk of memory (can't be resized) allocated outside of the V8 JavaScript engine.
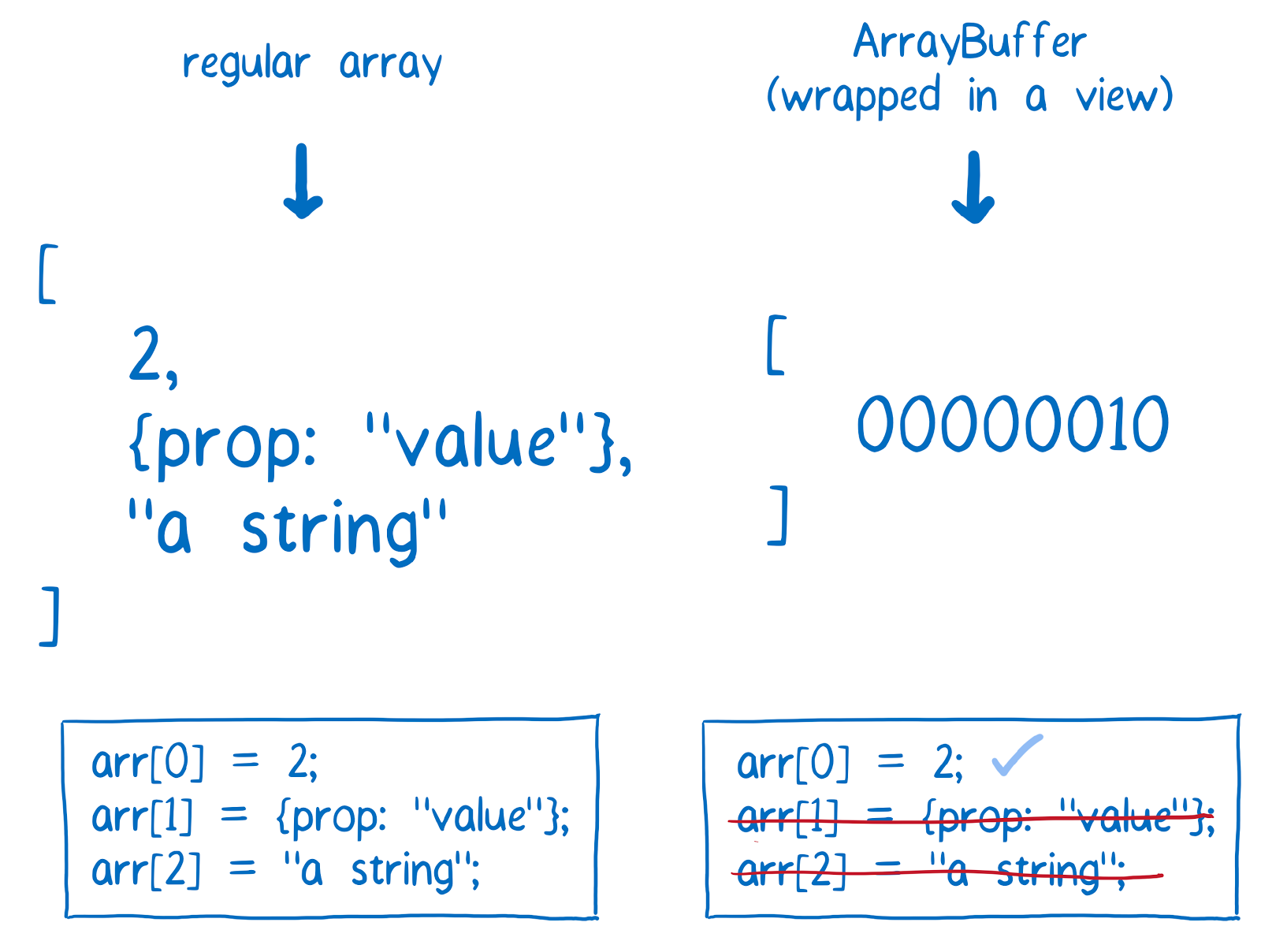
Why do we need a buffer?
Buffers were introduced to help developers deal with binary data, in an ecosystem that traditionally only dealt with strings rather than binaries.
Buffers in Node.js are not related to the concept of buffering data. That is what happens when a stream processor receives data faster than it can digest.
const buf = Buffer.from('Hey!');
console.log(buf[0]) //72
console.log(buf[1]) //101
console.log(buf[2]) //121
buf[1] = 111 //o in UTF-8
console.log(buf.toString()) // utf by default
const buf = Buffer.alloc(1024);
const buf = Buffer.from('Hey?')
let bufcopy = Buffer.from('Moo!')
bufcopy.set(buf.subarray(1, 3), 1)
bufcopy.toString() //'Mey!'
Using a buffer
A buffer, being an array of bytes, can be accessed like an array
fs.readFile(path.resolve('evens.js'))
.then((data) => {
console.log(Buffer.from(data).toString())
})
http.get(url.parse('http://myserver.com:9999/package'), function(res) {
var data = [];
res.on('data', function(chunk) {
data.push(chunk);
}).on('end', function() {
//at this point data is an array of Buffers
//so Buffer.concat() can make us a new Buffer
//of all of them together
var buffer = Buffer.concat(data);
console.log(buffer.toString('base64'));
});
});Using a buffer
Streams
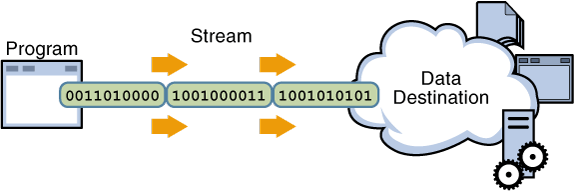
They are a way to handle reading/writing files, network communications, or any kind of end-to-end information exchange in an efficient way.

Using streams you read a file piece by piece
Streams basically provide two major advantages over using other data handling methods:
-
Memory efficiency: you don't need to load large amounts of data in memory before you are able to process it
- Time efficiency: it takes way less time to start processing data, since you can start processing as soon as you have it, rather than waiting till the whole data payload is available
An example of a stream
const http = require('http')
const fs = require('fs')
const server = http.createServer(function(req, res) {
fs.readFile(__dirname + '/data.txt', (err, data) => {
res.end(data)
})
})
server.listen(3000)If the file is big, the operation will take quite a bit of time. Here is the same thing written using streams
An example of a stream
const http = require('http')
const fs = require('fs')
const server = http.createServer((req, res) => {
const stream = fs.createReadStream(__dirname + '/data.txt')
stream.pipe(res)
})
server.listen(3000)Instead of waiting until the file is fully read, we start streaming it to the HTTP client as soon as we have a chunk of data ready to be sent.
pipe()
src.pipe(dest1).pipe(dest2);
// same as
src.pipe(dest1)
dest1.pipe(dest2)It takes the source, and pipes it into a destination.
Streams-powered Node.js APIs
Due to their advantages, many Node.js core modules provide native stream handling capabilities, most notably:
- process.stdin returns a stream connected to stdin
- process.stdout returns a stream connected to stdout
- process.stderr returns a stream connected to stderr
- fs.createReadStream() creates a readable stream to a file
- fs.createWriteStream() creates a writable stream to a file
- net.connect() initiates a stream-based connection
- http.request() returns an instance of the http.ClientRequest class, which is a writable stream
- zlib.createGzip() compress data using gzip (a compression algorithm) into a stream
- zlib.createGunzip() decompress a gzip stream.
- zlib.createDeflate() compress data using deflate (a compression algorithm) into a stream
- zlib.createInflate() decompress a deflate stream
There are four classes of streams:
- Readable: a stream you can pipe from, but not pipe into (you can receive data, but not send data to it). When you push data into a readable stream, it is buffered, until a consumer starts to read the data.
- Writable: a stream you can pipe into, but not pipe from (you can send data, but not receive from it)
- Duplex: a stream you can both pipe into and pipe from, basically a combination of a Readable and Writable stream
- Transform: a Transform stream is similar to a Duplex, but the output is a transform of its input
const Stream = require('stream')
const readableStream = new Stream.Readable({
read() {}
})
const writableStream = new Stream.Writable()
writableStream._write = (chunk, encoding, next) => {
console.log(chunk.toString())
next()
}
readableStream.pipe(writableStream)
readableStream.push('hi!')
readableStream.push('ho!')'use strict';
const fs = require('fs');
const zlib = require('zlib');
const http = require('http');
const rs = fs.createReadStream('index.html');
const gs = zlib.createGzip();
const buffers = [];
let buffer = null;
gs.on('data', buffer => {
buffers.push(buffer);
});
gs.on('end', () => {
buffer = Buffer.concat(buffers);
});
rs.pipe(gs);
const server = http.createServer((request, response) => {
console.log(request.url);
response.writeHead(200, { 'Content-Encoding': 'gzip' });
response.end(buffer);
});
server.listen(8000);Thank you!
Node Core #4
By Vladimir Vyshko
Node Core #4
FS




