Виконав студент групи КП-52м:
Зайка Владислав Андрійович
Науковий керівник:
к.т.н., доцент Заболотня Тетяна Миколаївна
Підвищення релевантності
пошукових систем методом
розбиття на рубрики
Мета дослідження
1. Дослідити існуючі алгоритми аналізу великих об'ємів даних
2. Запропонувати власні вдосконалення існуючих рішень
Об'єкт та предмет
Об'єкт дослідження - процес збирання, узагальнення та кластеризації масивів даних.
Предмет дослідження - оптимізований алгоритм для класифікації та кластеризації масивів даних.
Проблема
Регулярна обробка великого масиву даних.
Мільйони пошукових запитів.
Визначення тематичних рубрик
Вирішення
Розподілити обробку пошукових даних на комп'ютерний кластер
Використати генетичні алгоритми для виділення рубрик(застосовується розфарбування графів).
Завдання
1. Обрати підходящі python бібліотеки
2. Виконати тестування на одній машині
3. Конфігурувати кластер машин
4. Розподілити обчисленя на кластер
5. Порівняти бібліотеки
6. Запропоновати вдосконалення
Inspyred
FW для розподілених паралельних обчислень
Працює разом з PP модулем
Inspyred
Створений для локальних мереж
Швидкий старт
Планувальник! --
on the nodes: node-1> ./ppserver.py -a node-2> ./ppserver.py -a
final_pop = ea.evolve(generator=generate, evaluator=inspyred.ec.evaluators.parallel_evaluation_pp,
pp_evaluator=evaluate,
pp_servers=("*",),
pp_dependencies=(my_squaring_function,),
pp_modules=("math",),
pop_size=8,
bounder=inspyred.ec.Bounder(-5.12, 5.12),
maximize=False,
max_evaluations=256,
num_inputs=3)
DEAP
FW спеціально створений для розподілених обчислень
Використовує SCOOP для розпаралелювання
Проект університету Laval, Quebec
DEAP
Підключення до будь-якої машини
Без налаштування нод
Складність конфігурування
Ручне налаштування хостів
from scoop import futures
toolbox.register("map", futures.map)
python -m scoop --hostfile hosts program.py
hostname_or_ip 4
other_hostname
third_hostname 2
Кластер
Inspyred:
- швидкий старт
- мінімум коду
- авто конфігурація
- один кластер
- планувальник
DEAP:
- без коду на нодах
- масштабування
- активна розробка
- ручна конфігурація
- складність налаштування
PP vs SCOOP
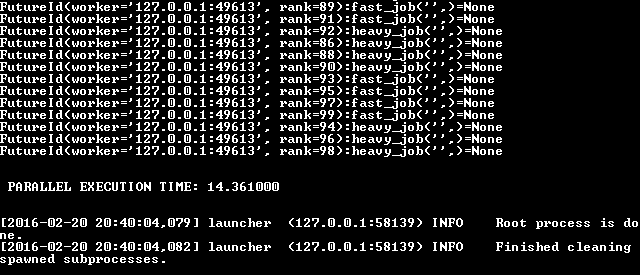
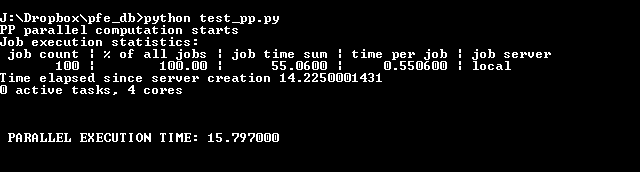
PP
SCOOP
Планувальник
Планувальник PP модуля назначає всі роботи на початку
Планувальник SCOOP чекає поки існуючі роботи будуть виконані
SCOOP + Inspyred
Розробка паралелізму scoop для inspyred
final_pop = my_ec.evolve(generator=generate,
evaluator=parallel_evaluator_scoop,
scoop_evaluator=evaluate,
pop_size=1,
maximize=True,
max_generations=5,
num_elites=_NumberOfElite,
seeds=None,
dimension_bits=_NumberOfBits
)
def parallel_evaluator_scoop(candidates, args):
evaluator = args['scoop_evaluator']
results = list(futures.map(evaluator, candidates, args))
return results
Бенчмарки
- максимальний час роботи на ноді
- середній час роботи на ноді
- перевірити закон Amdahl"а:
T(p)=Ts+Tp/p
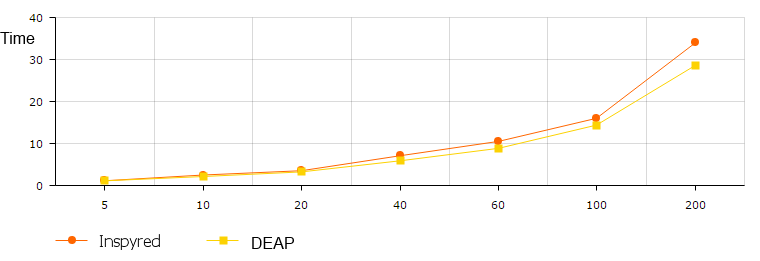
Наступні кроки
- Тестування SCOOP + Inspyred
- Завантажити дані до кластеру
- Налаштувати обробку даних
- Аналізувати результати
OAR
OAR - менеджер робіт на кластері
jdoe@idpot:~$ oarsub -I -l /nodes=3/core=1
jdoe@idpot5:~$ cat $OAR_NODEFILE
idpot5.grenoble.grid5000.fr
idpot8.grenoble.grid5000.fr
idpot9.grenoble.grid5000.fr
#!/bin/bash
python3 insp_script.py
Висновки
- Тестування Inpyred vs DEAP
- конфігурування OAR
- Визначення слабких сторін
- зв'язка SCOOP + Inspyred
- Бенчмарки
Дякую за увагу
Публікації
Наукова доповідь: "Prediction of miRNA-disease associations with vector space model."
Магістр презентація
By Vladyslav Zaika
Магістр презентація
Parallelization of a Bioinformatics program in Python.




