(Distributed)
observability (in .NET)
🕵
Vedran Mandić, MCSD, MCSA, MCT
@vekzdran / @vmandic
Thank you ATD

Hi, I am Vedran. 👋
- Vedran Mandić freelances, talks (less) and lectures (less) C# / .NET and JavaScript, and this year started golang
- last talk was... 2 years ago!
- 10 years as dev
- I do enterprise mostly
- @vekzdran / @vmandic

What's this presentation about?
Talking about app actions and errors and how to the importance of tracking them efficiently!
...and how to set this up in .NET / C#!
Today's plan?
- Tracking actions and errors in code
- Observability
- Logging how to
- Tracing how to
- Demo
WHAT? (actions)
- a user activity (story), an operation of biz value
- person created, invoice deleted, objects listed, user signed in, access right assigned to user...
- how long did the whole "process" take?
- how long did each "activity" take?
- what is the contextual data related to this activity?
- account ID, user ID, country, role, device...
- easy if its 1 app (if you log it)
- hard(er) if >+1 apps
- the more the merrier right :-)? how to correlate?
WHAT? (errors)
- error or exception? :-) (let's just call it problem)
- OK to trace if we have 1 app
- clear to analyze ("immediately"), hard if not logged
- do we know how to classify (levels, categories!)?
- did we log all the (relevant) contextual data!? 😧
- harder to analyze if more connected apps exist
- it's just cumbersome and takes time
- the action (activity) is distributed (sync / async)
- where (what) is the root error? in which log?
How does this look?
(what happens when services evolve...)

this is super easy, you have a single (non-replica) app... lucky you!

now you gotta know which replica caused the issue...

your system is now distributed across three apps and 2 DBs

I did not even put a message broker / queue here 😅

boss said "make it more scalable" etc
Observability 🔍
is composed of three essential parts...
...but first read this brilliant piece on MSFT devblog:
https://devblogs.microsoft.com/dotnet/observability-asp-net-core-apps/
-
Logging
-
Tracing
-
Metrics
Observability tries to answer some of the questions like...
- Are we observing more errors than before?
- Were there new error types?
- Did the request duration unexpectedly increase compared to previous versions?
- Has the throughput (req/sec) decreased?
- Has the CPU and/or Memory usage increased?
- Were there changes in our KPIs?
- Is it selling less than before?
- Did our visitor count decrease?
Making logging right...
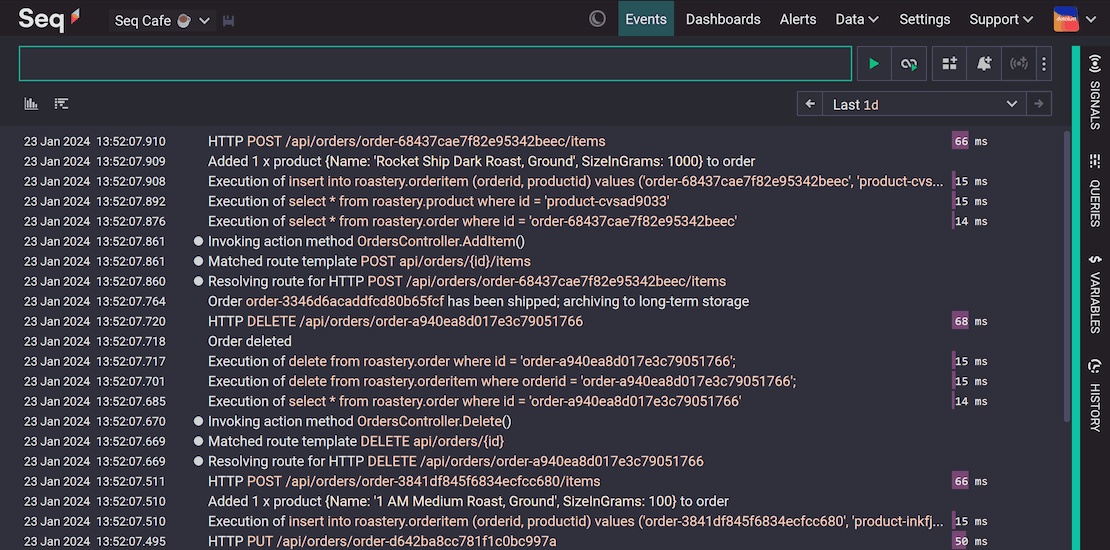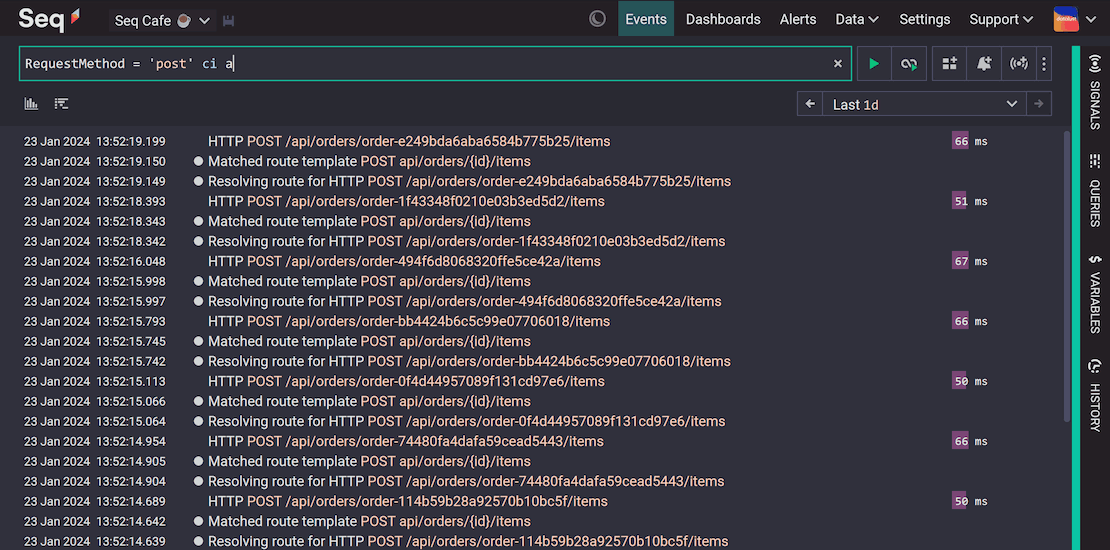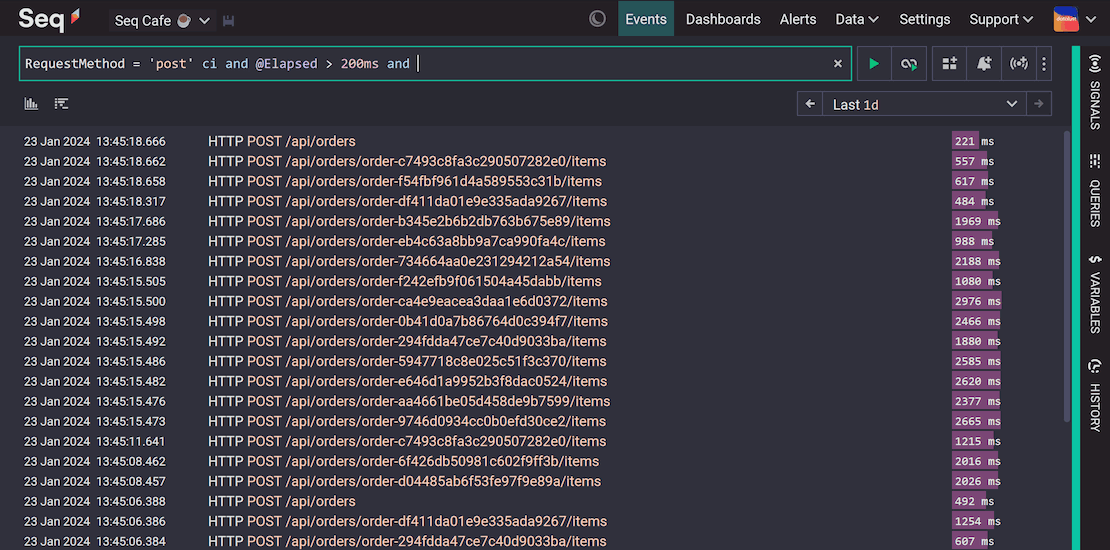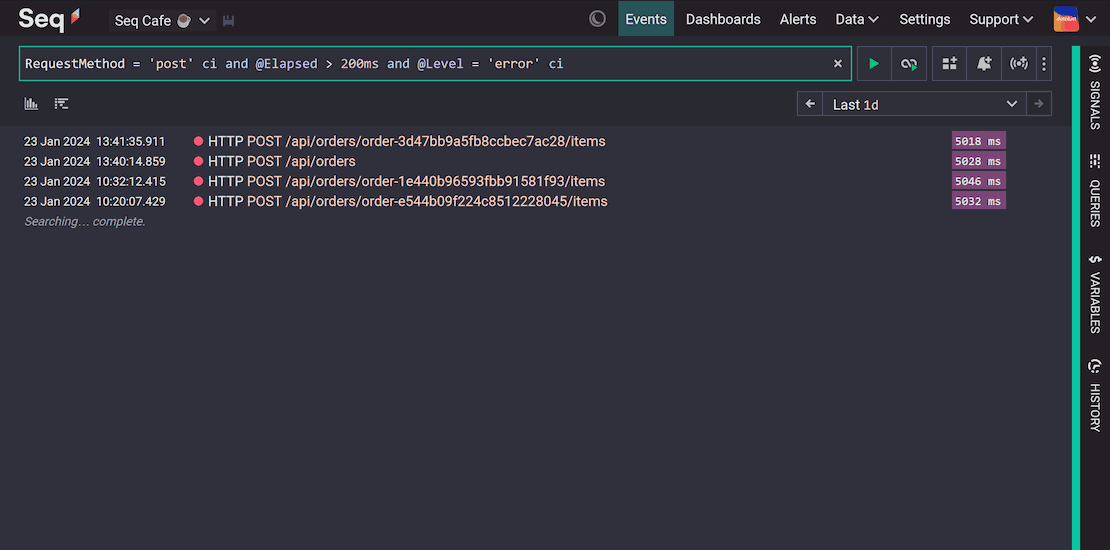
- Centralized: allowing the collection/storage of all system logs in a central location.
- Structured: allows you to add searchable metadata to logs.
- Searchable: allows searching by multiple criteria (app version, date, category, level, text, metadata, etc.)
- Configurable: allows changing verbosity without code changes (based on log level and/or scope).
- Integrated: integrated into tracing, facilitating analysis of traces and logs in the same tool.
Making logging right 1/2
-
standardize
- agree across apps and teams what log levels are used, categories...
- use a proven logging library / system
- log4net, Serilog, NLog, Elmah, Datadog, Logdna, Raygun...
-
maintain / reserve time
- do not just "leave it out there"
- grow team / company "logging culture"
- set up a real-time monitor in dev room / slack channel...
- log in bulks in async (ergo libraries...)
- to any source!
- don't log to console when in prod, cuts your perf...
Making logging right 2/2
Console log slowing you down? How much?

Rick Strahl "WestWind" (.NET Core 2.2):
That's 40x slower with Console [INFO] VS [WARN] on!

.NET6?
Make traceability right..

- learn OpenTelemetry.io set of tools and "standards"
- use the W3C standard (2020.)
- use an activity SDK (.NET has one) supporting W3C
- define (W3C's) SpanId, TraceId and ParentId
- log baggage (additional properties) ie. form TraceContext
- be consistent (apply activity tracking in all your services)
- make it centralized, searchable, alterable
- use a CFN dedicated service to store and visualize
- AppInsights, Zipkin, Jaeger, Prometheus, Splunk...
Making traceability right
Terminology recap for traceability
- Trace - a collection of spans that share the same trace ID
- First span is root one - represent the E2E of an operation
- Each span carries metrics and baggage

Thanks for holding thight...

...also ST folks know their observability :-)
demo time!
more sort of a code-review than coding :-)
The end! 📸 Questions?

VEDRAN MANDIĆ
mandic.vedran@gmail.com
@vekzdran @vmandic
SRC: https://github.com/vmandic/distributed-observability-dotnet-presentation
https://bit.ly/vmandic-distributed-obs-dotnet

Distributed observability in .NET
By Vedran Mandić
Distributed observability in .NET
A presentation on the WHAT, HOW and WHY of logging and tracing in modern .NET applications with focus on the HTTP channel.




