












Viktor Petukhov
PhD student at the University of Copenhagen
Выборка
Гипотезы
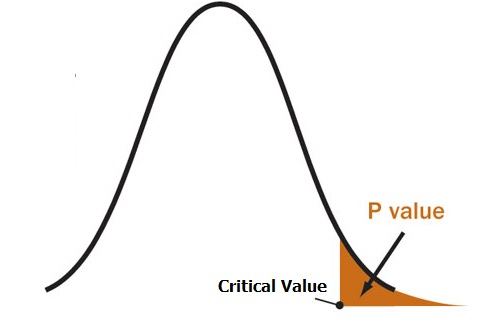
Критерий проверки
Статистика критерия
P-value
Ответ
Уровень значимости
Для одной гипотезы:
Для k гипотез:
Частный случай (для 20 гипотез):
В следствие ошибки ни одна мартышка не пострадала!
Выборка 1
...
Гипотеза 1
Выборка 2
Гипотеза 2
Выборка k
Гипотеза k
...
...
Хотим:
Вероятность хотя бы одной ошибки 1-го рода
Выборка 1
...
Гипотеза 1
Выборка 2
Выборка k
Пример гипотезы:
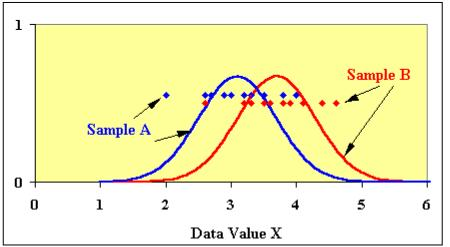
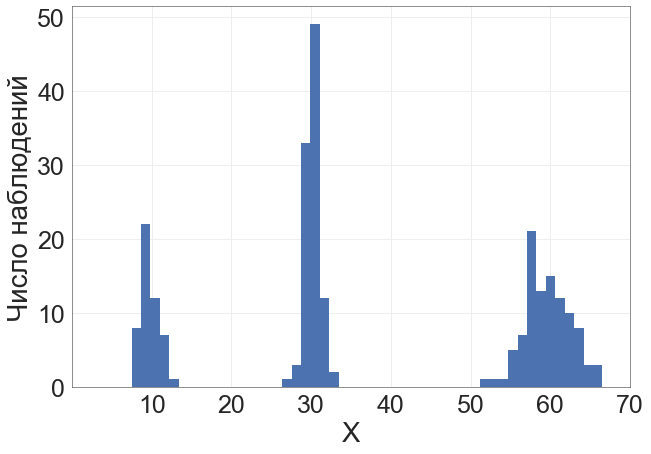
Все средние всех выборок равны.
Хотя бы одно из средних отличается от остальных
Выборка 1
...
Гипотеза 1
Выборка 2
Гипотеза 2
Выборка 3
Гипотеза 3
Выборка k
Гипотеза k
...
...
...
Хотим:
Вероятность хотя бы одной ошибки 1-го рода
Хотим:
Доля ошибок 1-го рода
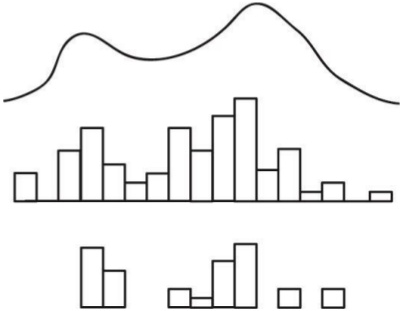
Исходная выборка:
Подвыборка:
Распределения:
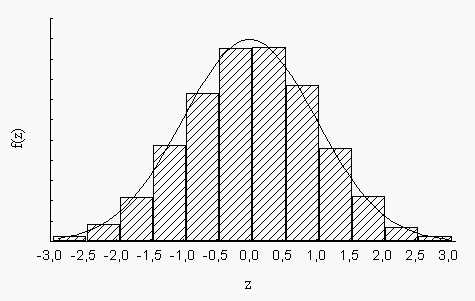
Требует нормальности!
| Кантри | Рок-н-рол | Джаз | Всего | |
|---|---|---|---|---|
| Город | 15 | 30 | 5 | 50 |
| Село | 25 | 20 | 5 | 50 |
| Всего | 40 | 50 | 10 | 100 |
By Viktor Petukhov



