

















Viktor Petukhov
PhD student at the University of Copenhagen
Student: Viktor Petukhov
PI: Peter Kharchenko
2011-2015: South Ural State University
Applied Mathematics and Informatics
2015-2017: St. Petersburg Polytechnic University
Applied Mathematics and Informatics:
Bioinformatics
Summer 2016: Harvard Medical School
Human Science and Technology
summer institute
*http://thescienceexplorer.com/brain-and-body/fat-tissue-shields-cancer-cells-chemo-study-finds
**https://support.10xgenomics.com/single-cell-gene-expression/instrument/doc/user-guide-chromium-single-cell-controller-readiness-test
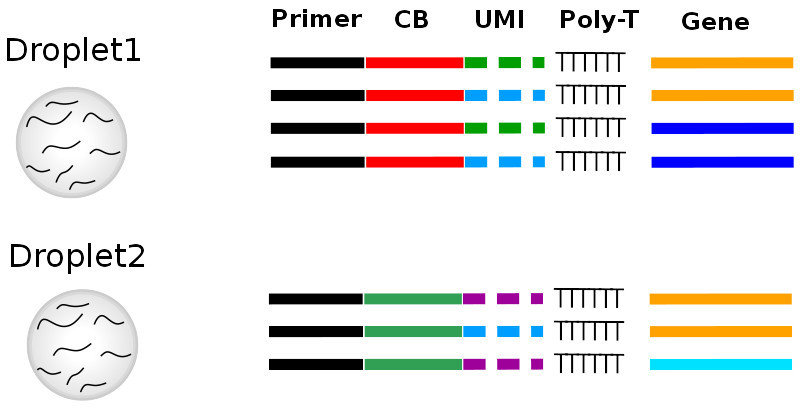
Fastq files
with
barcoded
reads
(CB + UMI)
**
Single cells
Sequencing
*
- Differential expression analysis
- Cell-to-cell interactions
- Cell type annotation
- Pseudotime ordering
- Gene correlation networks
*http://thescienceexplorer.com/brain-and-body/fat-tissue-shields-cancer-cells-chemo-study-finds
**https://support.10xgenomics.com/single-cell-gene-expression/instrument/doc/user-guide-chromium-single-cell-controller-readiness-test
Fastq files
with
barcoded
reads
(CB + UMI)
**
Single cells
Sequencing
*
10x fastq
inDrop fastq
Drop-seq fastq
10x CellRanger
inDrop scripts
Drop-seq tools
Fastq files
Tools
Gene count matrix
UMI collisions
UMI barcode errors
Cell barcode errors
Background cells
+
10x fastq
inDrop fastq
Drop-seq fastq
???
dropEst
pipeline
(C++)
Protocols
Gene count matrix
UMI N
...
UMI 6
UMI 5
UMI 4
UMI 3
UMI 2
UMI 1
UMI 4
UMI 7
UMI 1
Gene 1
UMI pool:
UMI 5
Gene 1
UMI 4
UMI 7
UMI 1
: x10
: x3
: x15
28 reads; 3 UMIs
Expression level: 3
UMI 4
UMI 7
UMI 1
UMI 3
UMI 9
UMI 9
: x1
: x2
: x8
28 reads; 3 UMIs
Expression level: 3
UMI 2
: x4
UMI 2
Gene 1
UMI 3
UMI 9
: x1
: x10
: x4
Cell 1
Cell 2
Cell 2
Estimate total number of UMIs given number of different UMIs:
k - #observed UMIs
n - #UMIs
m - pool size
Assume uniform distribution:
*Fu, G.K., et al., Counting individual DNA molecules by the stochastic attachment
of diverse labels. Proc Natl Acad Sci U S A, 2011. 108(22): p. 9026-31.
*
Real distribution:
Gene 1
Gene 1
UMI 3: x15
UMI 2: x1
UMI 1: x3
UMI 3: x9
UMI 1: x5
GTTA: x15
GGAC: x1
AATT: x3
UMI 4: x3
UMI 5: x1
GTTA: x9
AATT: x5
AGAG: x3
GTAA: x1
GTAA: x1
Cell 1
Cell 2
Expression
level: 3
Expression
level: 4
Real expression
level: 3
Real expression
level: 3
GTTA: x13
TGAC: x1
AATT: x3
GGAC: x1
GGTA: x8
GTCA: x4
GCCA: x2
GTTT: x15
Total number of molecules: 8
GTTA: x13
TGAC: x1
AATT: x3
GGAC: x1
GGTA: x8
GTCA: x4
GCCA: x2
GTTT: x15
Total number of molecules: 3
GTTA: x13
TGAC: x1
AATT: x3
GGAC: x1
GGTA: x8
GTCA: x4
GCCA: x2
GTTT: x15
Total number of molecules: 8
GTTA: x13
TGAC: x1
AATT: x3
GGAC: x1
GGTA: x8
GTCA: x4
GCCA: x2
GTTT: x15
Total number of molecules: 6
GTTA: x13
TGAC: x1
AATT: x3
GGAC: x1
GGTA: x8
GTCA: x4
GCCA: x2
GTTT: x15
CTTA: x3
UMI sequence
Num. of reads
Quality
#Smaller/larger adjacent UMIs
#UMIs per gene
Probability to have such #adjacent UMIs given #adjacent UMIs with larger number of reads, #UMIs per gene and UMI probability
Sequence:
#Reads:
Quality:
Probability to make an error in a read
Probability to have observed number of erroneous reads
Probability to have observed quality in the reads depends if are real or erroneous
| Probability of error | ||
|---|---|---|
| 0 | - | |
| 3 | ||
| 4 | ||
| 8 |
Maximum likelihood separation on real and erroneous reads
1'st UMI is erroneous
1'st and 3'rd UMIs are erroneous
All adjacent UMIs are erroneous
All adjacent UMIs are real
Probability to observe adjacent UMI depends on total #UMIs and sequencing depth:
Problem: How to know the real answer?
Problem: How to know the real answer?
Idea: Let's trim UMIs and correct them.
GTTAAATTAG: x9
AATTTGCCTA: x5
GTTAAACCGT: x3
Original
AATTTG: x14
GTTAAA: x3
Trimmed
GTTAAATTAG: x9
AATTTGCCTA: x5
GTTAAACCGT: x3
Merged
("real" answer)
GATAAACCGT: x1
GATAAACCGT: x1
GATAAA: x1
Original
GTTAAATTAG: x9
AATTTGCCTA: x5
GTTAAACCGT: x3
GATAAACCGT: x1
GTTAAATTAG: x9
AATTTGCCTA: x5
GTTAAACCGT: x4
Correction
Problem: How to know the real answer?
Idea: Let's trim UMIs and correct them.
Gene 1
Gene 2
Gene 3
UMI 3: x15
UMI 2: x1
UMI 1: x3
UMI 4: x2
UMI 4: x1
UMI 5: x3
AAAATTTGGG
Gene 1
Gene 2
Gene 3
UMI 3: x5
UMI 1: x1
UMI 5: x1
AAAACTTGGG
Gene 1
Gene 2
Gene 3
UMI 3: x10
UMI 2: x1
UMI 1: x2
UMI 4: x2
UMI 4: x1
UMI 5: x2
AAAATTTGGG
Gene 1
Gene 2
Gene 3
UMI 3: x5
UMI 1: x1
UMI 5: x1
AAAACTTGGG
Gene 1
Gene 2
Gene 3
UMI 3: x10
UMI 2: x1
UMI 1: x2
UMI 4: x2
UMI 4: x1
UMI 5: x2
AAAATTTGGG
3 UMIs
5 UMIs
4 UMIs
| Merge type |
#Merges |
Fraction of mixed merges | Similarity to merge with barcodes |
|---|---|---|---|
| Poisson | 8999 |
0.58% | 99.74% |
| Known barcodes | 8985 |
0.62% |
100% |
| Merge all adjacent |
21827 |
32.96% | 20.67% |
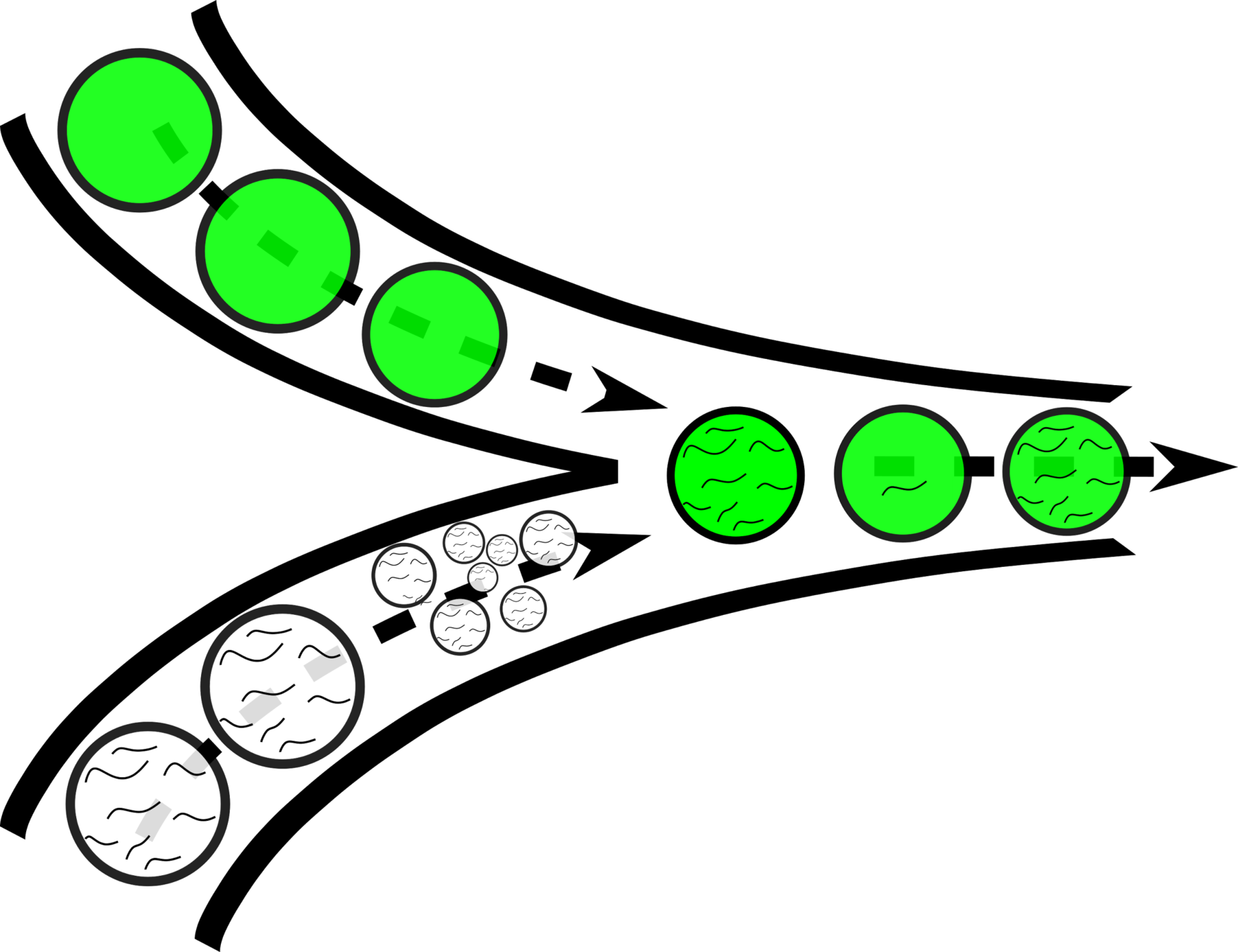
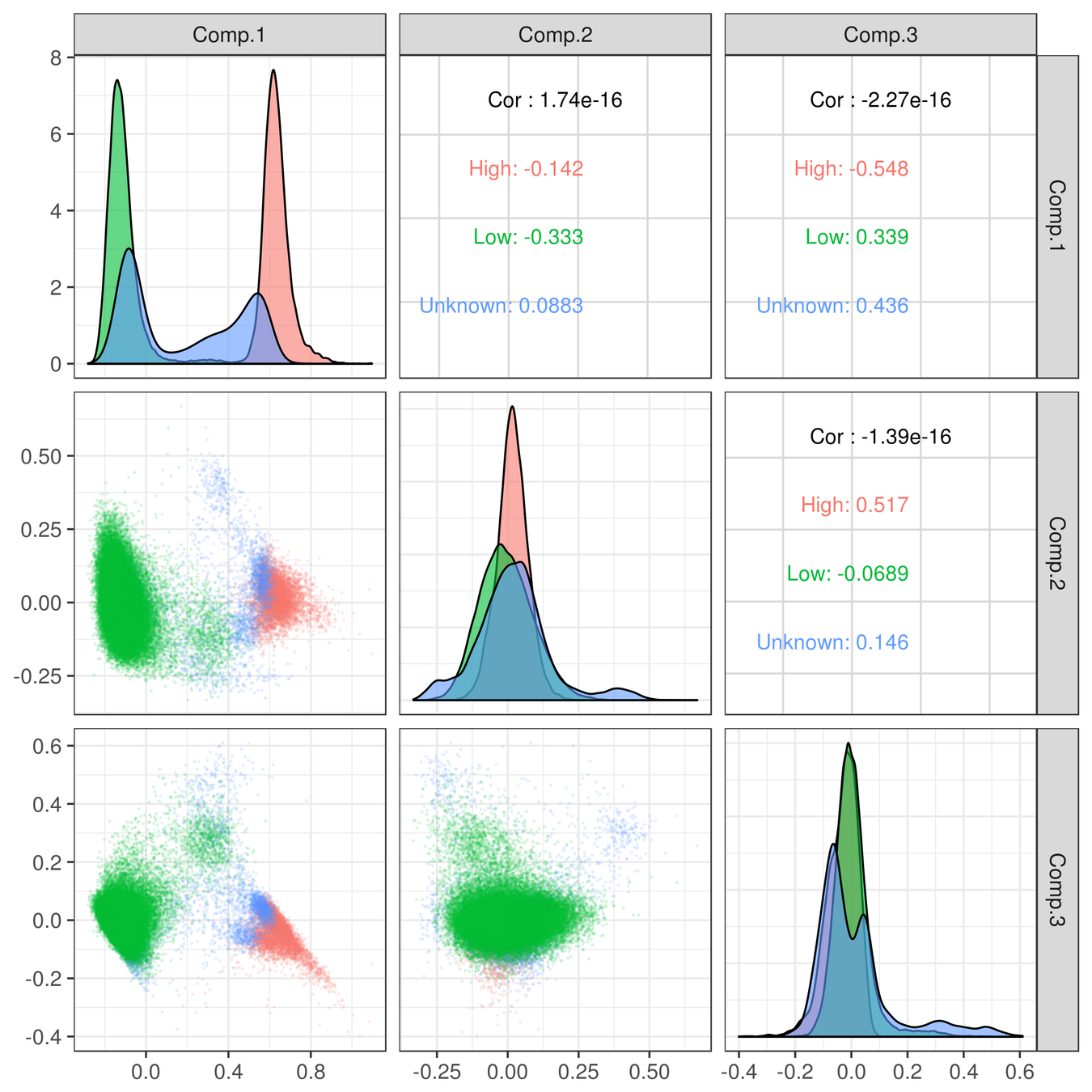
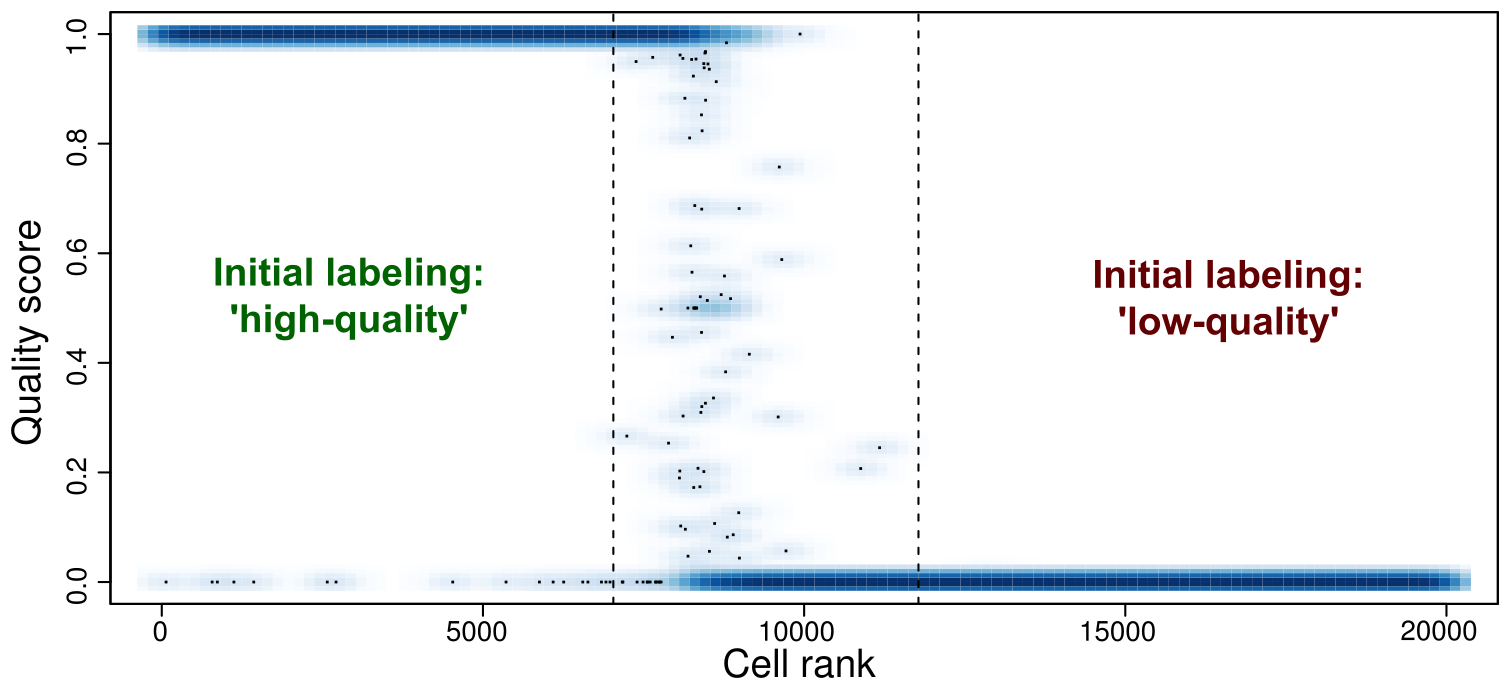
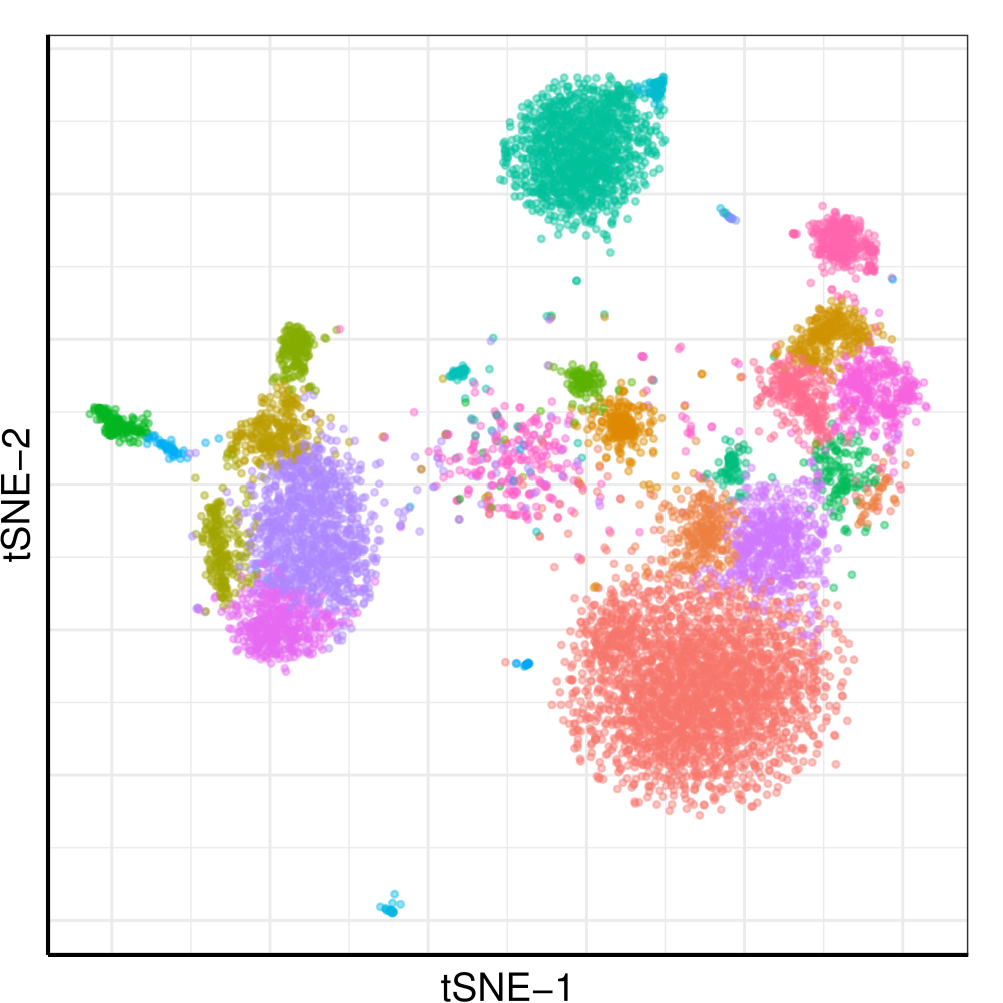
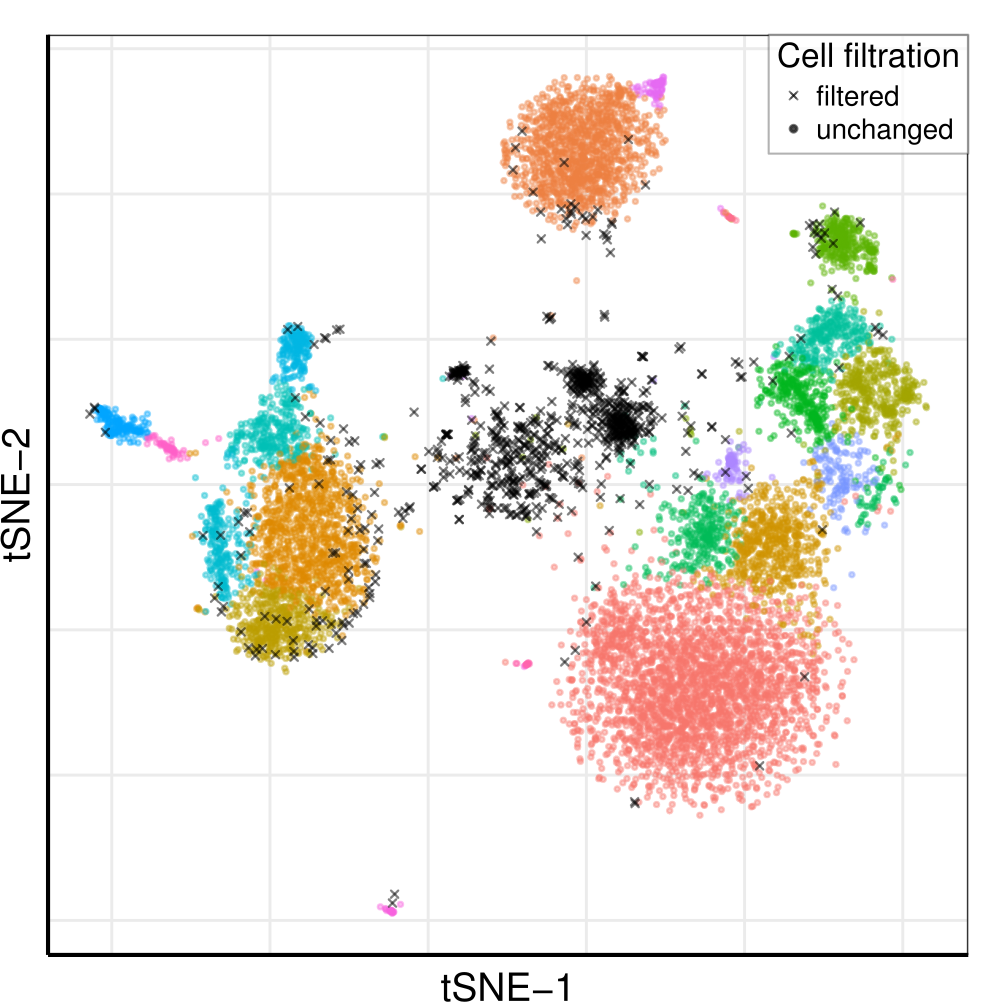
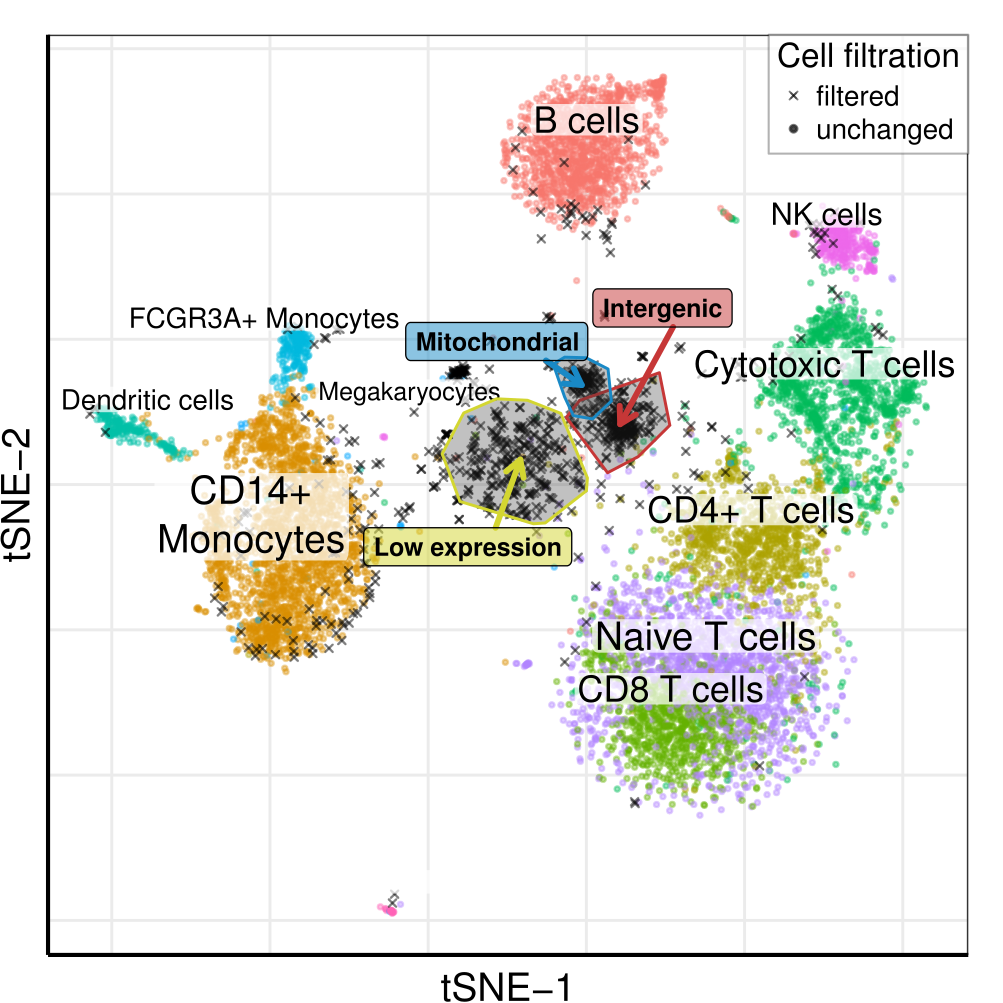
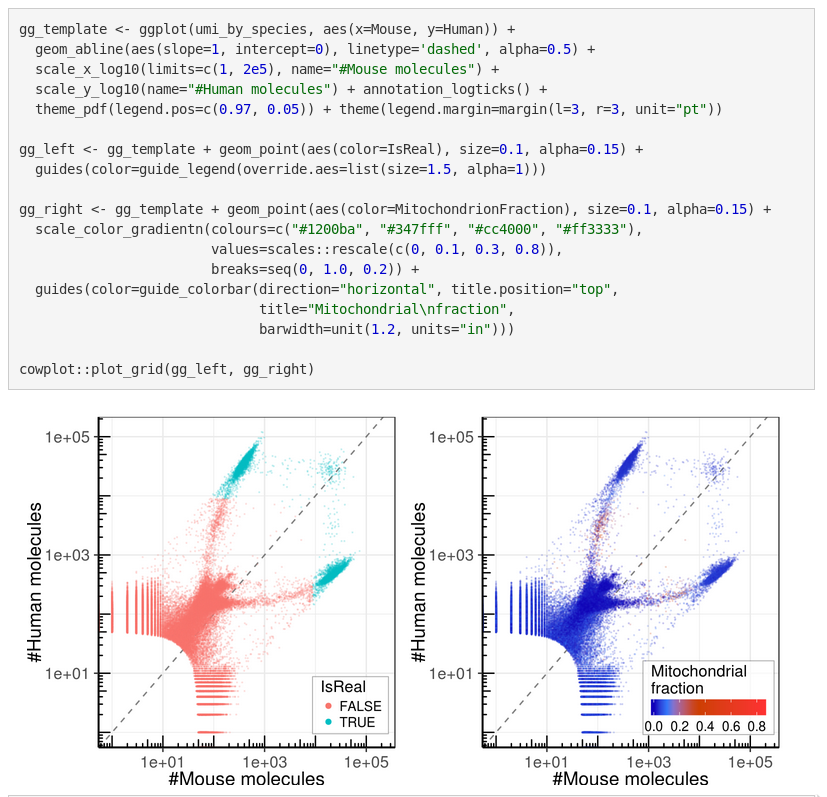
10x 8k Human PBMCs dataset
Droplets
Cells
Barcoded cells, isolated within droplets
10x 8k Human PBMCs dataset
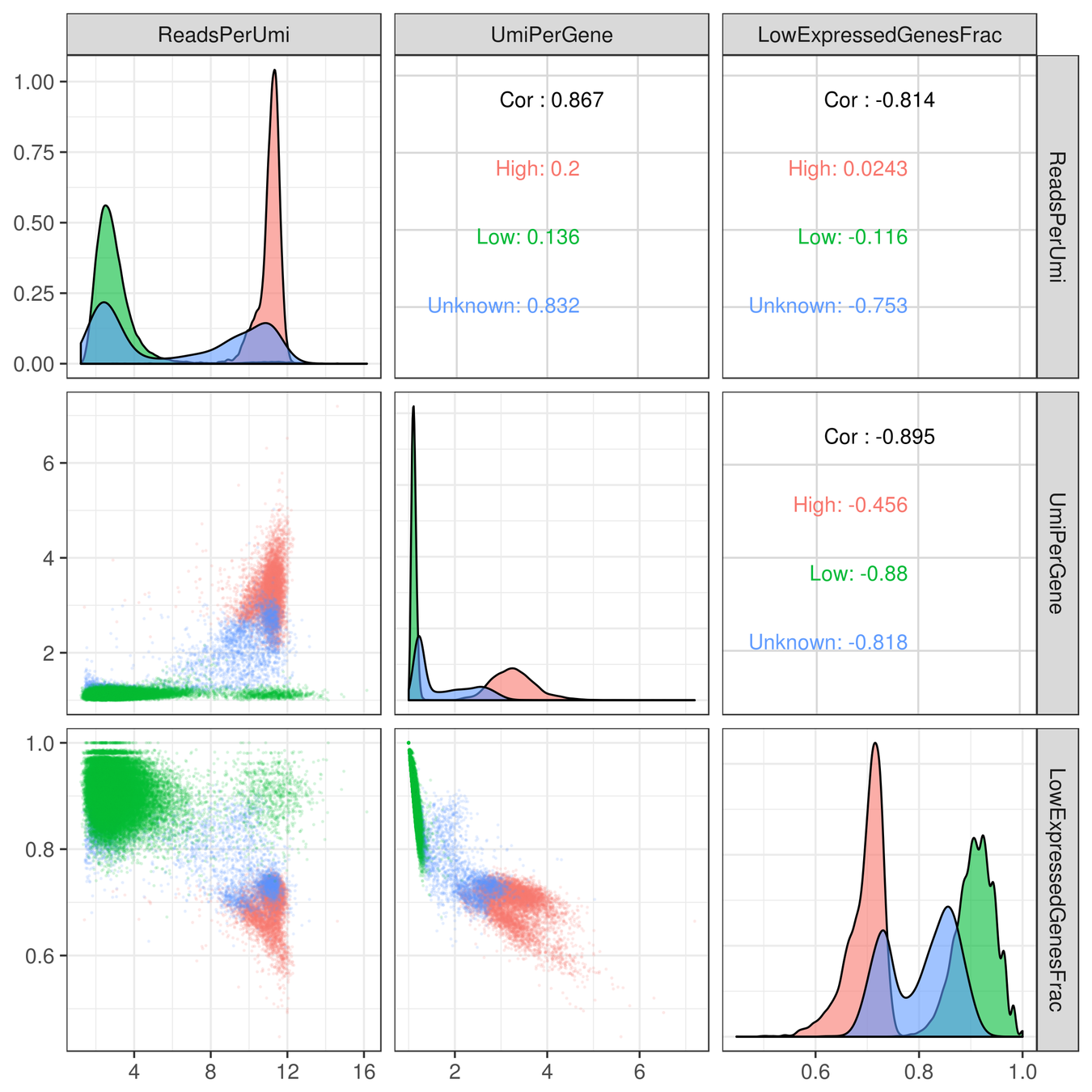
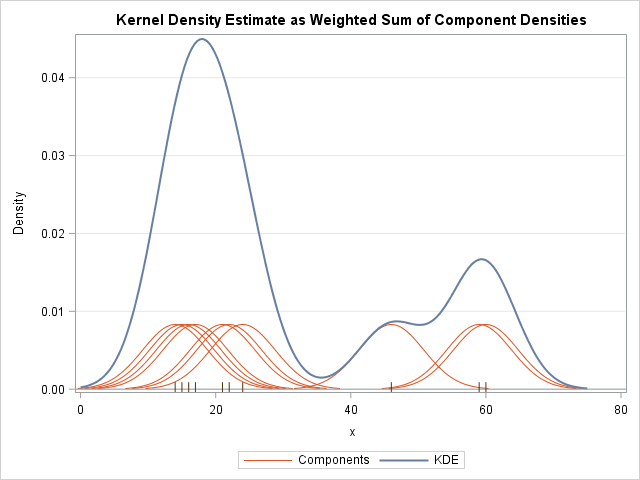
- Probabilistic interpretation
- Has single parameter (bandwidth)
Correction of
UMI and cell
barcodes
Adjustment of
UMI collisions
Filtration of background cells
10x
inDrop
Drop-seq
dropEst
pipeline
(C++)
dropestr
R package
(Rcpp)
Analysis
By Viktor Petukhov




