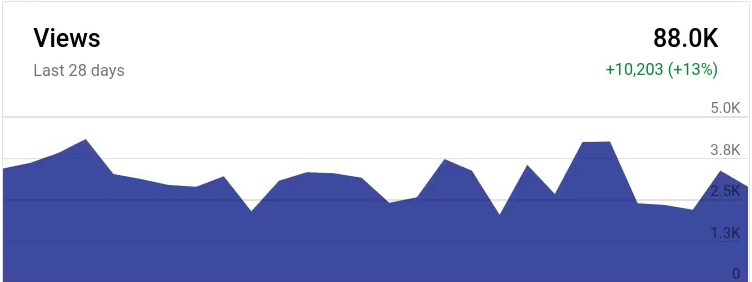
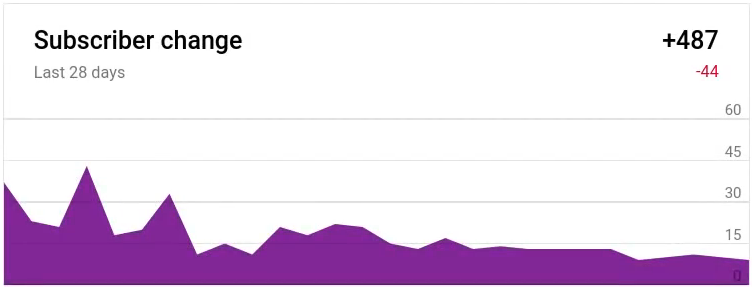









Viktor Petukhov
PhD student at the University of Copenhagen
Виктор Петухов, Сергей Журихин
Машинное обучение и статистика для поддержки принятия решений от уровня государств до отдельных индивидов;
Использование научного метода для лучшего управления государством и бизнесом;
Проблемы человеческого сознания, мешающие корректному принятию решений. Как данные помогают с ними бороться;
Какие проблемы человеческого сознания унаследовал искусственный интеллект. Введение в область Fairness in AI для автоматизации принятия решений;
Разбор конкретных проектов, направленных на реализацию «открытых правительств»;
Идеи:
Начать с того, чтобы ввести сам концепт эксперимента, а потом уточнить о том, как можно собирать различные данные для понимания процесса
Дизайн систем для уменьшения последствий индивидуальных искажений
Примеры с судьями
Упомянуть Ought и EA Geneva (gspi.ch)
Мини-введение в mechanism design?
Это можно рассказать вместе с пунктом про идеальную систему для принятия решений. По сути, пункт 2 - это просто один из элементов дизайна
В этой лекции я сфокусируюсь на пункте 2 и немного расскажу про пункт 3
Сделать голосование, чтобы понять что интересно?
YouTube
История про бегуна, который доминировал все олимпийские игры?
В этой лекции я сфокусируюсь на пункте 2 и немного расскажу про пункт 3
Опрос граждан в Канзасе
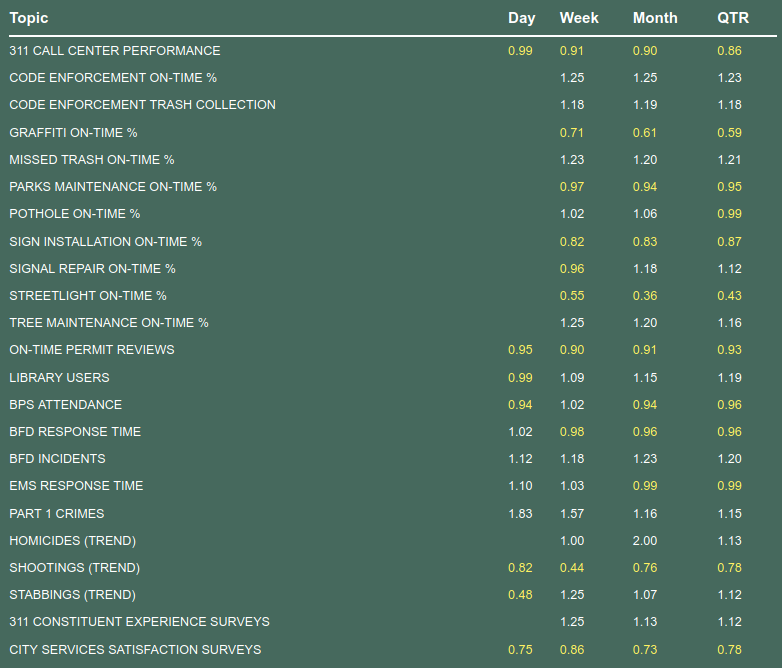
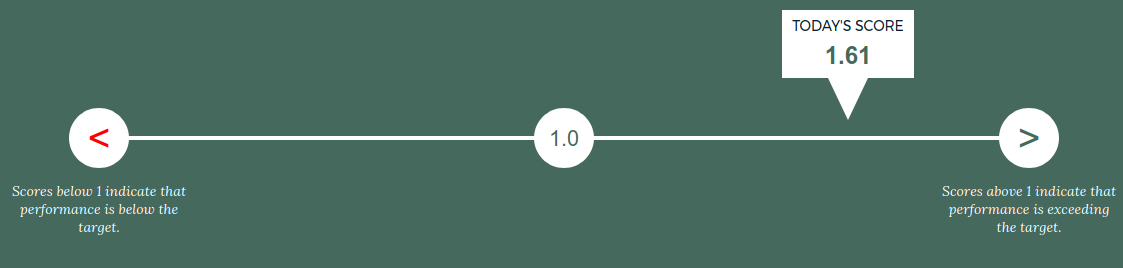
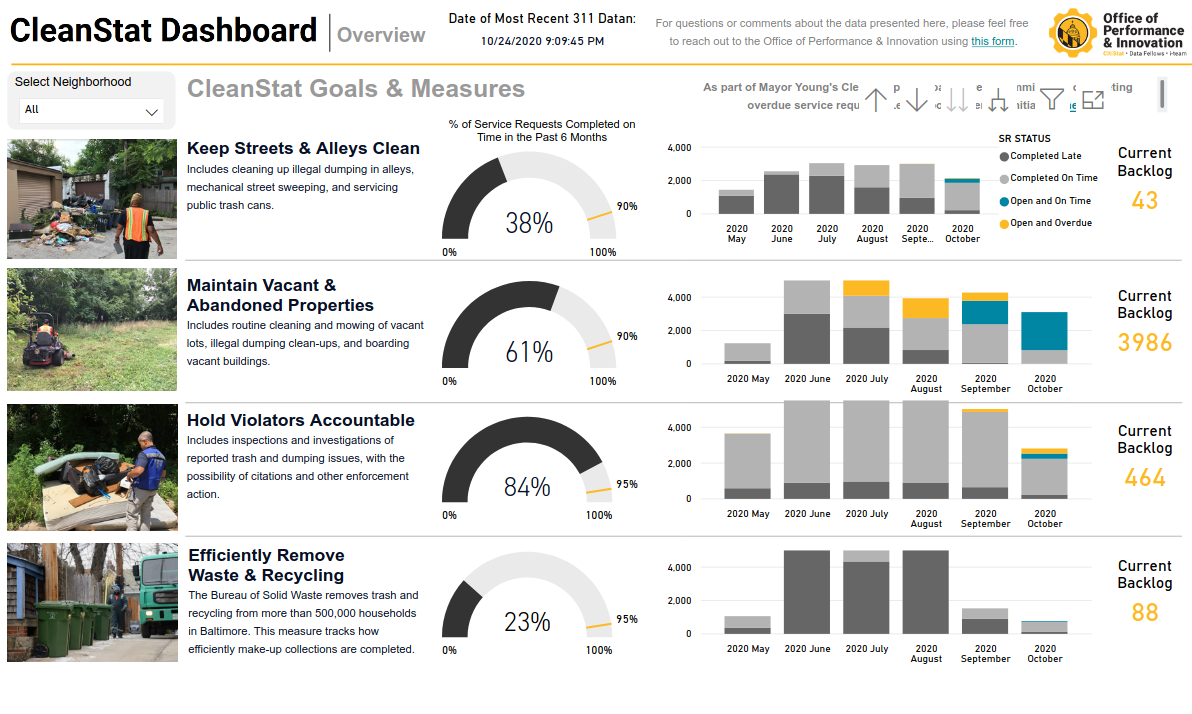
Городской рейтинг в Бостоне (CityScore)
Городская статистика в Балтиморе (cityStat)
Планирование военных операций
Управление цепями поставок
Распределение работников по сменам
Распределение нагрузок в больницах
ещё десятки применений...
*см. полный список на wiki:
Operations research - Problems addressed
Исследование операций
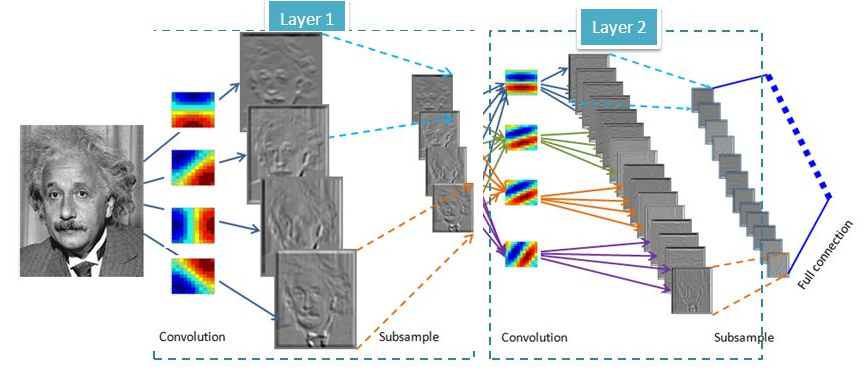
Большие данные
Глубокие нейронные сети
Анализ текстов, речи, изображений и видео:
Генерация кратких конспектов
Есть модели для извлечения информации из сложных данных
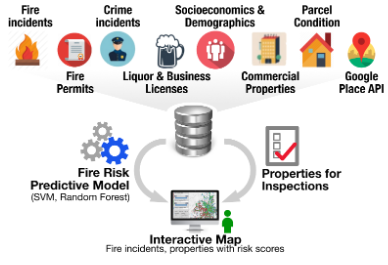
Есть мат. модели основных процессов. Есть много успешных случаев внедрения моделей исследования операций.
Нет настроенных потоков данных для решения гос. проблем. Также нет практик использования данных.
Есть рабочие методы машинного обучения
Генеративные модели ещё не готовы для широкого использования
Defense Advanced Research Projects Agency
Цели проекта:
Критерии оценки проектов:
Вынесенные уроки
Модель ARIMA
Gold Coast Hospital improved its waiting time performance by 20% using the tool, while one estimate put the financial returns for the state of Queensland as high as $80 million USD per year. This comprises $77.5 million from improved patient outcomes, while hospitals benefit from $2.5 million worth of efficiency savings.
Сложные методы нужны для извлечения информации из текста, изображений или видео. Когда информация есть - сложные методы не нужны.
Group vs individual fairness
TODO: remove this part?
By Viktor Petukhov




