УПРАВЛІННЯ
ТЕХНОЛОГІЧНИХ ПРОЦЕСІВ
Василь СКИБА

3
лекція
Теоретичні основи статистичного
управління процесами
Робочі потоки
Теоретичні основи статистичного
управління процесами
Статистичне управління процесами
це прийняття рішень на основі фактів. Статистичні методи дозволяють кількісно оцінити мінливість процесів. Це дозволяє планувати діяльність по стабілізації виробничих процесів.
Статистичне управління процесами дозволяє також визначити не очевидні взаємозв'язки між параметрами процесів і показниками якості.
При цьому статистика в ряді випадків є єдиною прийнятною методикою виявлення необхідних для управління залежностей між входами й виходами процесів. Використання інших методів вимагає, як правило, значних матеріальних, часових і людських ресурсів.
Теоретичні основи статистичного управління процесами включають:
- принципи формування раціональних підгруп даних.
- класифікація контрольних карт;
- критерії ефективності контрольних карт;
- інтерпретація контрольних карт.
Управління процесами здійснюється на підставі їх кількісних характеристик, які необхідно виміряти.
Тож врахування реальних спостережених дійсних фактів і їх кількісна оцінка є підставою для прийняття рішення.
Основою управління є:
- вимірювання характеристик (параметрів, показників);
- вибіркова оцінка на підставі статистичних характеристик.
Методологія статистичного управління процесами
була запропонована Вальтером А. Шугартом (Шухарт, Шевхарт, Shewhart) – всі процеси мають варіацію.
Передбачувана – “випадкова”;
непередбачувана – неконтрольована варіація.
Методологія статистичного управління процесами
була запропонована Вальтером А. Шугартом (Шухарт, Шевхарт, Shewhart) – всі процеси мають варіацію.
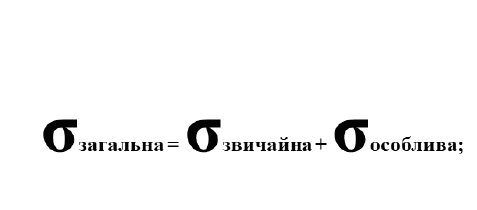
Концепція варіації

де ВМР – верхня межа регулювання (UCL);
НМР – нижня межа регулювання (LCL);
μ – унормоване значення показника;
σ – середньоквадратичне відхилення.

Сутність статистичного управління -
передбачення, – не точних значень, але у певних межах.
За умови стабільного процесу розподіл
досліджуваної ознаки буде:
Світовий досвід застосовності статистичних методик в системах управління якістю узагальнено в технічному звіті ISO/TR 10017:2003 “Статистичні методи. Настанови щодо застосування статистичних методів згідно з ISO 9001:2000”.
ISO/TR 10017:2003 рекомендує до застосування наступні статистичні методи або сімейства методів:
- описова статистика;
- планування експериментів;
- перевірка гіпотез;
- вимірювальний аналіз;
- аналіз можливостей процесу;
ISO/TR 10017:2003 рекомендує до застосування наступні статистичні методи або сімейства методів:
- регресійний аналіз;
- аналіз надійності;
- вибірковий контроль;
- моделювання;
- карти статистичного контролю процесу (карти СКП);
ISO/TR 10017:2003 рекомендує до застосування наступні статистичні методи або сімейства методів:
- статистичне призначення допуску;
- аналіз часових рядів.
В стандарті надається короткий опис кожного методу за схемою:
- сутність методу;
- область застосування;
- переваги;
- обмеження і застереження;
приклади застосування.
Контрольна карта Шугарта
Контрольна карта Шугарта
графік зміни параметрів вибірки, зазвичай середнього значення, розмаху або стандартного відхилу.
Контрольна карта Шугарта передбачає такі етапи:
- спостереження;
- вибірка за часом отримання;
- вимірювання величини параметра;
- нанесення на карту;
- прийняття рішення щодо отриманих результатів.
Головні припущення, які дають право застосовувати карти Шугарта:
- спостереження, які отримано у часі, є незалежними один від одного;
- досліджувана ознака має нормальний розподіл.
Раціональна підгрупа даних:
- вибірка або підгрупа виробів;
- між вибірками або в середині вибірки можуть бути відхилення;
- стандартне відхилення в середині підгрупи, встановлене із вибірки підгрупи чи відоме з минулого досвіду, є основною мірою випадкової варіації.
Типи контрольних карт:
- Шугарта – кількісних змінних та альтернативних ознак, коли стандартні значення задано і не задано;
- приймального контролю – середніх значень та розмахів або часток невідповідної продукції, а також кількості дефектів;
- адаптивні – використання моделей різного ступеня складності, що дозволяє передбачити, де буде процес, якщо його залишити у цьому (певному) стані.
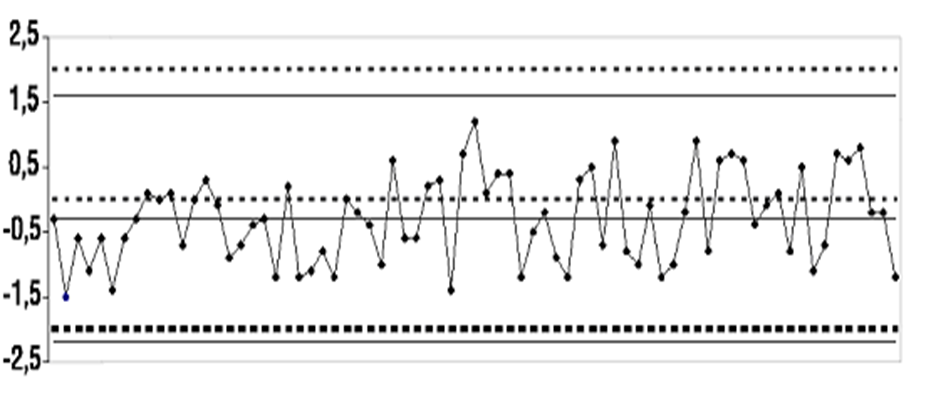
Приклад контрольної карти розмахів для стабільного процесу
Контрольна карта індивідуальних спостережень
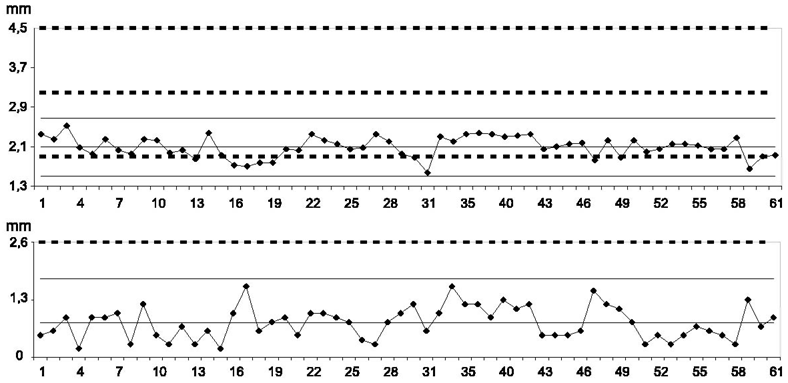
Ефективність карт:
- сигналізує про зміни, причина яких різноманітна;
- характеристика процесу на підставі середнього вибіркового розмаху є короткочасною характеристикою процесу, оскільки враховує варіацію між послідовними спостереженнями;
- на підставі середньоквадратичного відхилення – є довготерміновою оцінкою варіації, оскільки бере до уваги всі спостереження.
Регресійний аналіз
Класичний підхід до визначення емпіричних залежностей ґрунтується на поданні досліджуваного процесу, що піддається впливу декількох факторів, у вигляді «чорної скриньки».
Процес
Невимірювані фактори
Некеровані фактори
Вхід
Вихід
Така модель процесу є найпоширенішою, тому що дозволяє абстрагуватися від складності внутрішньої структури досліджуваного об'єкту.
Хоча теоретично ідея «чорної скриньки» представляється привабливою, але вона нерідко приводить до дуже тривалих і дорогих процедур, тому що зневажає частиною наявної інформації.
Виходи моделі
змінні, що характеризують досліджуваний процес або, інакше, його стан. Виходів у процесу, як правило, багато, але в регресійному аналізі розглядається ситуація, коли модель має лише один вихід.
Для іншого виходу з того ж самого процесу розробляється окрема модель.
Входи моделі
незалежні змінні, котрими можна керувати, тобто встановлювати будь яке значення вхідної дії з множини можливих.
Ця множина визначається фізичними особливостями процесу. В регресійному аналізі входи називають факторами або регресорами.
Дослідження процесу може бути проведено як в активному (активний експеримент), так і в пасивному режимі (пасивний експеримент).
Активний експеримент
проводиться за заздалегідь складеним планом, відповідно до якого ставиться завдання не тільки визначення оптимальних умов проведення експерименту, а й спрощення обробки його результатів.
При активному експерименті проводиться за заздалегідь складеним планом, відповідно до якого ставиться завдання не тільки визначення оптимальних умов проведення експерименту, а й спрощення обробки його результатів.
При пасивному експерименті значення факторів лише реєструються. Задати їх не можливо.
Некеровані фактори
незалежні фактори, які можна виміряти, але керувати якими немає можливості через фізичні, економічні або етичні чинники.
Не вимірювані фактори впливають на процес, але ними не можна керувати і їх неможливо виміряти через фізичні або економічні чинники.
Такі фактори присутні завжди при проведенні експериментів і визначають стохастичний характер отриманих результатів.
В ході проведення експериментів здійснюють зміну керованих m факторів, кожен у визначеному діапазоні.
Проводять фіксацію вихідної величини для кожного експерименту. Звісно, для отримання достовірних результатів необхідно провести експерименти з усіма можливими комбінаціями факторів.
Узагальнення результатів експериментів є математичне співвідношення, що називають рівнянням регресії або просто регресією
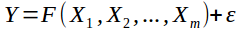
Приклад рівняння регресії
де Y - залежна змінна,
X1, X2, ..., Xm – незалежні змінні (фактори),
ε - випадкова помилка.
Вид рівняння регресії в принципі може бути будь який і обирається дослідником.
Коефіцієнти, які містить рівняння регресії, обираються так, щоб мінімізувати помилку між розрахунковим результатами і експериментальними даним відповідно до обраного критерію близькості.
Таким критерієм є, зазвичай, мінімум суми квадратів помилок між експериментальними значенням Yi для X1i, X2i, ..., Xmi і обчисленими значеннями F(X1i, X2i, ... Xmi).
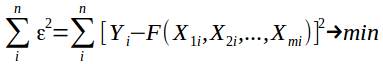
де n - кількість проведених експериментів.
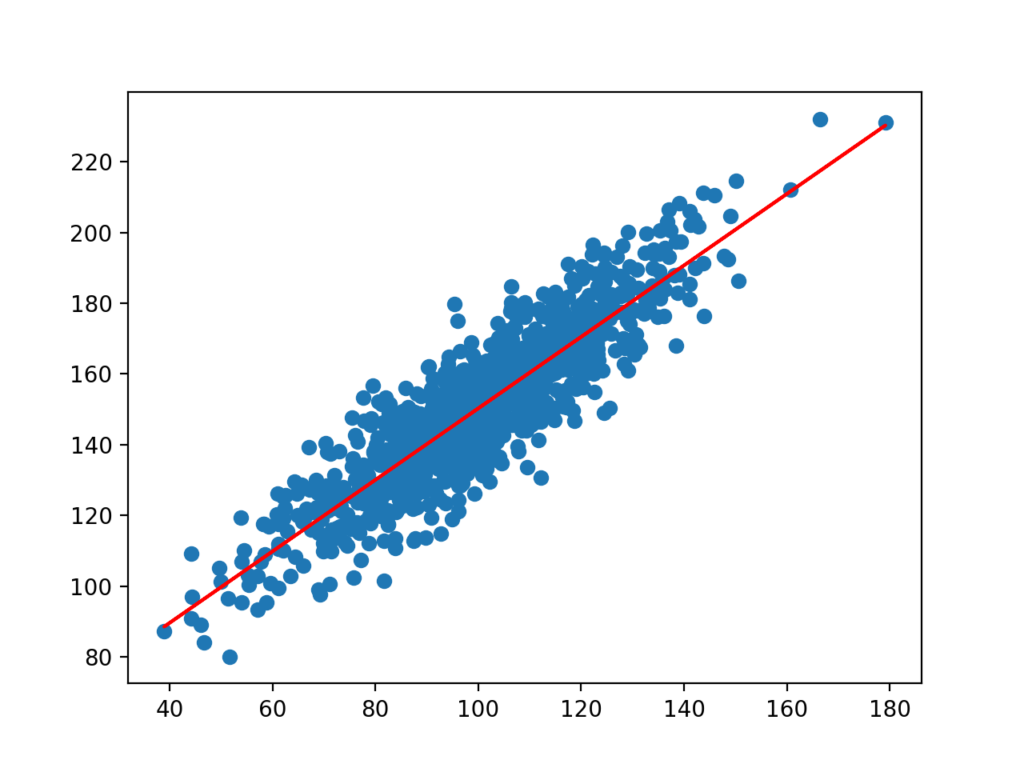
Приклад однофакторного експерименту при якому було отримано масив даних Y та X. Для наочності масив доцільно представити у вигляді графіку. Данні групуються біля прямої лінії, котра описується лінійним рівнянням виду Y=b1X+b0.
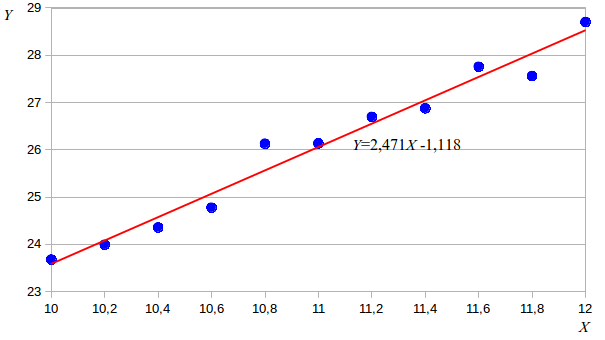
Саме через простоту аналітичного обчислення коефіцієнтів методики лінійного регресійного аналізу найпоширеніші і найбільш розроблені.
Останній фактор є одним з найбільш важливих при виборі статистичних інструментів для статистичного керування процесами.
У ряді випадків нелінійні функції за допомогою операцій лінеаризації можуть бути приведені до виду лінійної регресії.
У класичному регресійному аналізі для одержання оцінок коефіцієнтів моделі й можливості аналізу їхніх властивостей необхідне виконання ряду допущень і передумов, що випливають із теореми Гаусса-Маркова:
- в кожному досліді математичне сподівання випадкової помилки дорівнює нулю;
- у всіх дослідах дисперсія постійна й однакова;
- помилки в будь-яких двох дослідах незалежні.

Здійснення цих передумов
вимагає низки управлінських
рішень, спрямованих на забез-печення стабільності всіх пара-
метрів при проведенні про-
мислового експерименту.
Незалежні змінні (фактори) повинні відповідати наступним вимогам, що враховують також і при проведенні ранжування процесів методом експертних оцінок:
- змінні повинні мати фізичний сенс;
- бути відтворюваними;
- бути однозначними - кожному значенню незалежних змінних повинне відповідати одне значення вихідних змінних;
- мати вимірювані значення у всій області обраних вхідних параметрів (факторів).
Залежні змінні повинні відповідати наступним вимогам:
- бути керованими;
- бути незалежні від інших вхідних величин;
- повинні допускати будь-які сполучення один з одним;
- бути детермінованими;
- мати достатній інтервал змін.
Незалежні змінні повинні бути однозначними.
Вибір факторів повинен бути повним, тобто достатнім для пояснення поводження залежних змінних.
Вибір інформативних факторів має бути обмеженим на рівні, що не перевищує одного-двох десятків.
Це пов'язане з різким зростанням потреб у ресурсах з ростом кількості вхідних факторів і, що на сьогодні значно більш важливо, з погіршенням надійності отриманих результатів.
Оскільки регресійний аналіз вимагає варіювання незалежних факторів у межах, що перевищує значення технологічних допусків, то відповідні дослідження повинні проводитися в рамках промислового експерименту.
Експеримент припускає неминуче одержання невідповідної продукції, і отже повинен оформлятися наказом по підприємству. Для зменшення кількості невідповідної продукції варто використати методики планування експериментів, адекватні поставленому завданню.
Незважаючи на те, що математичний апарат для рішення цього класу завдань добре розроблений, регресійний аналіз для виробничих процесів застосовують рідко.
Причиною цього є необхідність проведення дорогих промислових експериментів.
При цьому вхідні змінні (параметри процесів) в обов'язковому порядку повинні виходити за межі допусків.
У противному випадку отримані рівняння дають абсолютно неправдоподібні результати.
При зміні обсягу аналізованої вибірки коефіцієнти будуть істотно мінятися.
Оцінкою інформативності регресійної моделі є величина коефіцієнта кореляції R між експериментальним значенням вихідної величини Y
і її оцінкою Ŷ, обрахованою за моделлю.
Часто використовують значення R2, що має назву коефіцієнта детермінації.
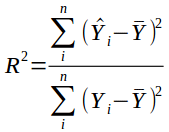
Y - середнє значення вихідної величини у всіх проведених експериментах. Для активного експерименту значення R2 має бути не меншим за 0,8.
Коефіцієнт детермінації
Перевірка гіпотез

Перевірка гіпотез являє собою статистичну процедуру визначення, із заданим рівнем ризику, сумісності сукупності даних (у типовому випадку з вибірки) з конкретною гіпотезою.
Гіпотеза може ставитися до припущення про специфічний статистичний розподіл або модель,
або ж вона може ставитися до значення деякого параметра розподілу
(такого, як його середнє значення).
Нехай (X,Θ) – закон розподілу випадкової величини X з деяким параметром Θ.
У якості основної (або, як прийнято її називати в математичній статистиці, нульової) гіпотези приймемо ствердження, що параметр Θ приймає значення Θ0.
H0 - Θ= Θ0
Тоді альтернативна або конкуруюча гіпотеза укладається в тім, що цей же параметр приймає деяке інше значення Θ1
H1 - Θ= Θ1
Кожна з гіпотез може бути як вірною, так і помилковою. У математичній статистиці прийнято класифікувати помилки.
Так випадок, коли правильна гіпотеза H0 помилково відкидається, прийнято називати помилкою першого роду.
Помилкою другого роду називають випадок прийняття гіпотези H0 у якості вірної, у той час, коли вірної є гіпотеза H1.
Імовірність помилки першого роду або рівень значимості нульової гіпотези позначають як α.
Імовірність правильного прийняття нульової гіпотези називається довірчою ймовірністю й дорівнює 1-α.
Імовірність помилки другого роду позначають як β,
а величину 1-β називають потужністю критерію.
Різні процедури перевірки гіпотез використаються для визначення правильності прийняття рішень на основі статистичних методів.
Прикладом такого використання є ухвалення рішення про середнє значення деякого фактору в генеральній сукупності на основі середнього значення, обчисленого за вибіркою.
Щоб гарантувати справедливість висновків, отриманих при перевірці гіпотез, істотно, щоб були задоволені статистичні припущення, які лежать в їхній основі.
Особливо це стосується незалежності та випадковості формування вибірки.
Більше того, довірчий інтервал, на підставі якого може бути зроблений висновок визначається обсягом вибірки.

Довірчий інтервал
Довірчий інтервал
в математичній статистиці є типом інтервальної оцінки, яка обчислюється за даними спостереження, і покриває невідомий статистичний параметр із заданою надійністю.
Це інтервал, у межах якого з заданою довірчою імовірністю можна чекати значення оцінюваної (шуканої) випадкової величини.
Наприклад, можна стверджувати:
результати дослідження показали, що новий інтерфейс сайту є більш зручним для 40 % користувачів.
Проте математично правильніше сказати:
з імовірністю 90 % кількість користувачів, що вважають новий інтерфейс більш зручним згідно з опитуваннями лежить в інтервалі 40±3 %.
Тут довірчим інтервалом є ±3 %.
Уявимо собі ситуацію, коли необхідно оцінити можливі зміни функціоналу мобільного додатку із 100 тис. аудиторією.
При цьому опитати кожного ми не можемо ні по одинці (занадто довго), ні всі відразу (занадто багато данних).
Єдиний спосіб у цьому випадку - провести оцінку на підставі вибірки.
Природно, вибірка повинна бути абсолютно випадковою.
Однак, які б ми вибірки не використали, середні вибіркові значення будуть відрізнятися один від одного, хоча і будуть знаходиться в деякому діапазоні значень.
Таким чином, ми змушені будемо перейти від точкової оцінки випадкової величини до інтервальної оцінки. Необхідно тільки встановити, якому інтервалу можна довіряти.
Метод визначення довірчого інтервалу для середнього значення (математичного очікування) залежить від розміру вибірки.
Для малих вибірок (n<30) використаємо
формулу <%7-%-6%>
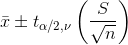
Величина x є середнім вибірковим значенням,
S – стандартним відхиленням, що розраховується за вибіркою.
Значення ν=n-1 називають кількістю ступенів свободи.
Поняття ступенів свободи використовується в математичній статистиці для вираження того факту, що існують природні обмеження на кількість факторів, що аналізуються.
Так кількість спостережень у вибірці не може бути меншою за одиницю.
Тому існує можливість (свобода) додати тільки n-1 значень до обсягу вибірки.
При малій вибірці вважається, що помилка визначення середнього значення по вибірці підкоряється розподілу Стьюдента для заданого довірчого рівня й числа ступенів свободи.
Значення визначають за відомими таблицями або розраховують за допомогою будь-якого програмного пакета, що здійснює статистичний аналіз.
Робочі потоки

Робочий потік (Workflow)
повна чи часткова автоматизація виробничого процесу, при якій документи, завдання та інша інформація одним і тим
самим методом передаються у вигляді команд, завдань, звітів від одного ділянки виробництва
до іншого.
Робочий потік вимагає спеціальної системи підтримки, в основі якої закладено інформаційно-організаційна система (Workflow-Management).
Workflow-Management
це сукупність апаратно-програмного забезпечення загального доступу, що розроблено для керування робочим потоком.
До Workflow-Management відносять процеси моделювання потоку, керування та його контроль, за допомогою програмного забезпечення вказують та визначають послідовність технологічних операцій.
Дуже важливим є узгодження форматів та необхідність роботи в єдиному форматі.
Система керування робочим потоком для поліграфічних виробництв базується на форматах PDF, JDF (JDF-Workflow), що запропонований консорціумом фірм:
Heidelberger Druckmaschinen, Manroland, Agfa и Adobe.
Основною метою інтеграції робочого потоку — це автоматизація процесів поліграфічного виробництва
впровадження різноманітних ПЗ та систем, що забезпечують збір актуальних даних про стан процесів та їх передача на різноманітні ділянки виробництва з метою керування.
Така система називається Computer Integrated Manufacturing (CIM) - комп'ютерні технології, що інтегровані у виробництво.
Формат PPF в поліграфічній індустрії, також відомий як CIP3-Format здійснює передачу технічних даних з відділу додрукарської підготовки в друкований цех, або з відділу додрукарської підготовки до відділу післядрукарської підготовки.
Також існує можливість попереднього перегляду майбутнього відбитка (Preview), паралельно формуючи завдання RIP на виготовлення
друкованої форми.
Попереднє зображення відбитка містить
інформацію про параметри кольору, яка потім передається на друкарську машину.
Організація виробництва із застосуванням PPF - Workflow має такі переваги:
- технічні дані, що містять параметри для роботи обладнання, можуть передаватися з одного підрозділу в інший;
- дані в одному і тому ж форматі можуть передаються на різні пристрої (наприклад, як на пристрої друку, так і на пристрої післядрукарської обробки);
- зменшує кількість операцій.
В даний час скорочуються обсяги тиражів, при збільшенні кількості найменувань, а вимоги замовників, навпаки, посилюються.
Тому скорочення термінів проходження замовлень при підвищених вимогах до їх якості вимагає оптимізацію виробничих процесів, яку може забезпечити JDF-робочий потік.
Формат JDF (Job Definition Format) здатен створювати робочі потоки, передавати налаштування роботи обладнання і вести протоколи повного виробничого процесу.
JDF здійснює підтримку в разі передачі даних про замовлення; передачі даних про параметри налаштування обладнання; обліку виробництва і обліку роботи устаткування; диспозиції; контролю виконання замовлення.
При JDF-робочому потоці здійснюється:
- інформаційна підтримка при взаємодії програм калькуляції замовлення (MIS - інформаційно-керуюча система) з виробництвом. Інформаційний файл містить повністю всю інформацію, яка потрібна абсолютно на всіх ділянках виробництва;
- збір даних про роботу обладнання і інших виробничих відомостей (Job Tracking), контроль виконання замовлення, звітна калькуляція;
При JDF-робочому потоці здійснюється:
- облік продуктивності праці і ведення протоколу;
- інформаційна підтримка в режимі «он-лайн» при спілкуванні замовника і виконавця;
- дію розділів «Асортимент», «Пропозиції», «Підтвердження замовлення» та інше;
- формування вимог і налаштувань до інтеграції програмного забезпечення (Plug-and-play) на основі форматів JDF / JMF на відповідній ділянці виробництва;
При JDF-робочому потоці здійснюється:
- протоколювання всіх виробничих процесів.
Однак дана схема далеко не завжди здатна забезпечувати ефективність управління робочим потоком, оскільки дані необхідно збирати із різних ділянок виробництва, які не завжди можуть бути послідовними.
Їй на зміну прийшла більш прогресивна система на основі робочої картки завдання (Job-tickets), яка вже базується на серверних рішеннях.
За такого підходу можлива електронна комунікація підрозділів в межах виробництва та із замовником.
Наприклад, передача даних для розрахунку і налаштування зон друкарської секції з відділу додрукарської підготовки в друкарський цех тощо.
Метадані за допомогою локальної мережі передаються на пульти керування різних машин і агрегатів, і через неї здійснюється і зворотний зв'язок.
За такого підходу можлива електронна комунікація підрозділів в межах виробництва та із замовником.
Наприклад, передача даних для розрахунку і налаштування зон друкарської секції з відділу додрукарської підготовки в друкарський цех тощо.
Метадані за допомогою локальної мережі передаються на пульти керування різних машин і агрегатів, і через неї здійснюється і зворотний зв'язок.
Література:
1. Меняев М. Ф. Цифровые системы управления техническими процессами в полиграфии: Учебное пособие / М: МГУП, 2006. - 126 с.
2. Депцова Т. Ю. Управление информационными потоками в издательском деле: учеб. пособ. / Т. Ю. Депцова, Е. В. Ермакова. - Самарский у-тет, 2018. - 76 с.
3. Шахова И. И. Рабочий поток репродуцирования цветного оригинала: учеб. пособие / И.И. Шахова ; Моск. гос. ун-т печати имени Ивана Федорова. - М. : МГУП имени Ивана Федорова, 2014. - 89 с.
4. Коваленко А.Г. Управление рабочими потоками: Учебное пособие. – М.: Изд-во МГУП, 2004.
5. Ковалева В.В. Автоматизированные системы управления технологическими процессами в полиграфии: Учебн. пособие. – М.: Изд-во МГУП, 2010.
6. Кипхан Гельмут. Энциклопедия по печатным средствам информации / Гельмут Кипхан. – М. : Изд-во МГУП, 2003. – 1280 с.
Дякую за увагу!
Copy of Управ. тех. проц. Л3
By wassky



