Ambient Diffusion Update
Dec 22, 2025
Adam Wei
Agenda
1. Quick update on experiments
2. How should we write the paper?
Distribution Shifts in Robot Data
- Sim2real gaps
- Noisy/low-quality teleop
- Task-level mismatch
- Changes in low-level controller
- Embodiment gap
- Camera models, poses, etc
- Different environment, objects, etc
robot teleop
simulation


Open-X

Sim &"Real" Cotraining
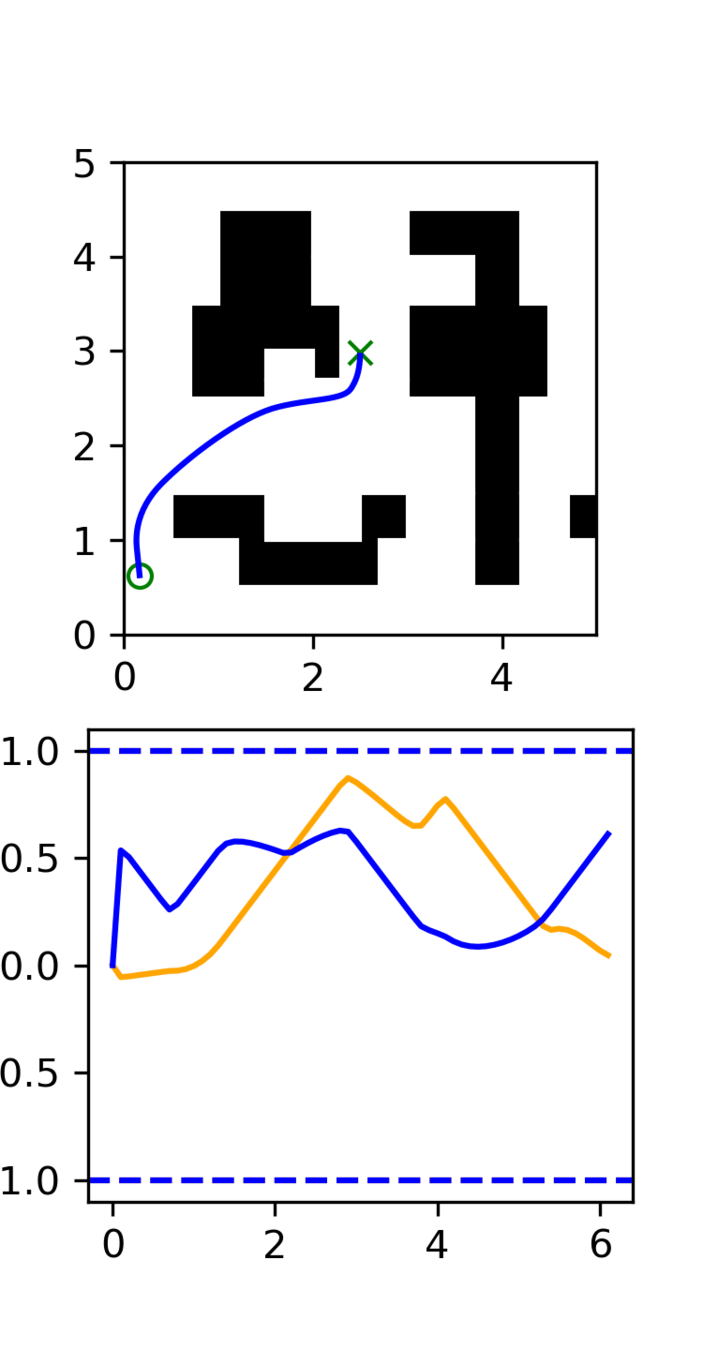
Distribution shift: sim2real gap
In-Distribution:
50 demos in "target" environment
Out-of-Distribution:
2000 demos in sim environment
Sim & Real Cotraining
Real Only
Sim + Real
(reweighted)
Ambient
(\(\sigma_{min}\) per datapoint)
Ambient-Omni
56.5%
84.5%
93.5%
92.0%
Perf
(200 trials)
Bin Sorting
In-Distribution:
50 demos with correct sorting logic
Out-of-Distribution:
200 demos with incorrect sorting
2x
2x
Distribution shift: task level mismatch, motion level correctness
Bin Sorting
Contrived experiment... but it effectively illustrates the effect of \(\sigma_{max}\)
Repeat:
- Sample \(\sigma\) ~ Unif([0,1])
- Sample (O, A, \sigma_{max}\)) ~ \(\mathcal{D}\) s.t. \(\sigma \in [0, \sigma_{max})\)
- Optimize denoising loss
\(\sigma=0\)
\(\sigma=1\)
\(\sigma_{max}\)
\(\sigma>\sigma_{min}\)
\(\sigma_{max}\)
Bin Sorting
Good Data Only
Score
(Task + motion)
Correct logic
(Task level)
Cotrain
(\(\alpha^*=0.9\))
Completed
(Motion level)
Ambient-Omni
(\(\sigma_{max}=0.46\))
61.01%
61.9%
98.6%
Cotrain
(task-conditioned, \(\alpha^*=0.5\))
90.3%
91.5%
98.6%
22.68%
87.2%
26.0%
93.3%
95.0%
98.2%
Bin Sorting

Motion Planning*
Task
Planning*
Motion Planning
Distribution shift: Low-quality, noisy trajectories
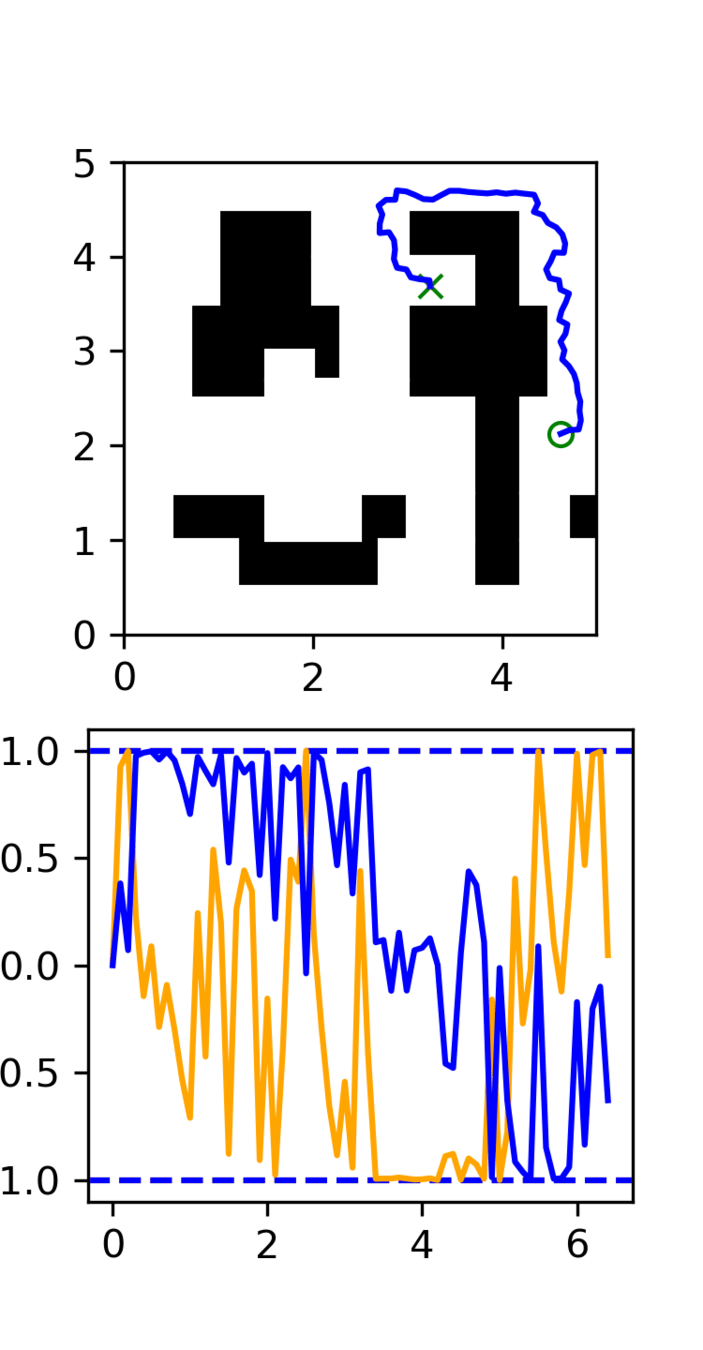
High Quality:
100 GCS trajectories
Low Quality:
5000 RRT trajectories
Motion Planning
Distribution shift: Low-quality, noisy trajectories
High Quality:
100 GCS trajectories
Low Quality:
5000 RRT trajectories
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Motion Planning Results
GCS
Success Rate
(Task-level)
Avg. Jerk^2
(Motion-level)
RRT
GCS+RRT
(Co-train)
GCS+RRT
(Ambient)
50%
Policies evaluated over 100 trials each
100%
7.5k
17k
91%
14.5k
98%
5.5k
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Motion Plannin: 7-DoF Robot Arms


Generate good (expensive) and bad (cheap) motion planning data in 20,000 environments
Evalute in new scences. Goal is to generate good trajectories
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Cross Embodied Data
Loss Function
Loss Function (for \(x_0\sim q_0\))
Denoising Loss vs Ambient Loss
Choosing \(\sigma_{min}\)
Cross Embodied Data

Immediate Next Direction
- Sim2real gaps
- Noisy/low-quality teleop
- Task-level mismatch
- Changes in low-level controller
- Embodiment gap
- Camera models, poses, etc
- Different environment, objects, etc
Open-X
Immediate Next Direction
Open-X
Variant of Ambient Omni
Cool Task!!
Cool Demo!!
Open-X Embodiment
Open-X
Magic Soup++: 27 Datasets
Custom OXE: 48 Datasets
- 1.4M episodes
- 55M "datagrams"
Open-X Embodiment
Table Cleaning
Ambient policy on OOD objects. (2x speed)
Table Cleaning: Evaluation


Task completion =
0.1 x [opened drawer]
+ 0.8 x [# obj. cleaned / # obj.]
+ 0.1 x [closed drawer]
Question: How to compute error bars?
Research Goals/Questions
- Does ambient help?
- Does ambient-omni help?
- Reweighting is critical in cotraining, is it also needed for ambient?
Ex. Reweights vs Unweighted


Reweighted
(sample clean 50%)
Unweighted
(sample clean 0.06%)
Results
Cotrain
Ambient
Ambient-Omni
Magic Soup++
Custom OXE
Clean only (50 demos): 63.3%
68.8% / bad!
74.2% / bad!
80.3% / 68.7%
72.8%* / 75.8%
?
?
* Need to retrain
Baseline Results: Reweighted
Baseline Results: Reweighted
Clean Only
Magic Soup Cotrain
Custom OXE Cotrain
Opening
Closing
Cleaning
Task Completion
20/20
20/20
20/20
34/60
37/60
41/60
16/20
19/20
16/20
19/20
0.633
0.688
0.742
Ambient
Even the best policy right now is mediocre...
Next Steps
- Finish \(\sigma_{max}\) experiments
- Policies are poor:
- Collect more data (50 demos -> 150 demos)
- Explore DiT + stronger vision encoder
- Some small fixes ;)
- Second hardware task using best practises
How To Structure Paper
Option 1:
- We use ambient diffusion in robotics
- The results are good, the method is general
Option 2:
- Co-training is important in robotics; we are doing it wrong.
- Ambient is one approach that works well and illustrates this problem
Costis/Russ 12/22/25
By weiadam



