Scalable Data Collection For Imitation Learning
Adam Wei
Oct 6, 2023
Motivation






Diffusion policies have achieved really impressive results!
... but they rely on human demonstrations.
Research Questions
1. Can we use model-based planning and simulation to generate data for imitation learning at scale?
- SBMP (RRT, RRT*)
- Stochastic policies, RL
\}
Hope to explore later...
2. How can we leverage a small amount of human data to improve performance and reduce the sim2real gap?
- Classifier Free Guidance?
3. What are the scaling laws for diffusion? Is diffusion the right framework for multi-skill composition and LBMs?
- GCS!
Today's Focus...
1. Can we use model-based planning and simulation generate data for imitation learning at scale?
- SBMP (RRT, RRT*)
- Stochastic policies, RL
- GCS!
\}
Hope to explore later...
2. How can we leverage a small amount of human data to improve performance and reduce the sim2real gap
- Classifier Free Guidance?
Data Collection Via GCS
For each shelf...
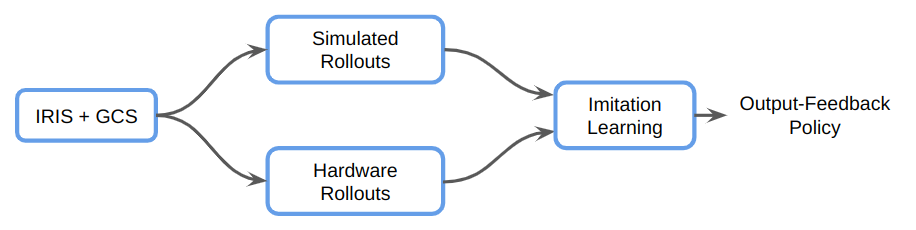
Connection to GCS as a policy...
\mathcal{D}\{(o_i,a_i)\}
\pi_\theta(a | o)
Trajectories
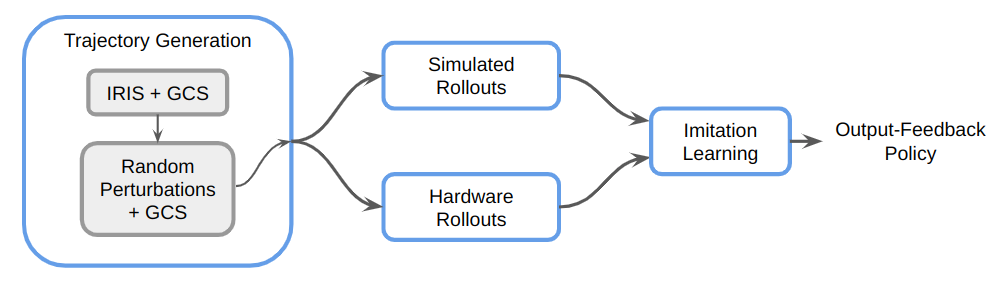
Data Collection Via GCS
For each shelf...
1. GCS trajectories leave no margins around obstacles
2. GCS is a deterministic planner; the resulting dataset could lack diversity, coverage, recovery demonstrations or other desirable characteristics from human data
3. GCS for contact?
Potential Problems
\mathcal{D}\{(o_i,a_i)\}
\pi_\theta(a | o)
Trajectories
Data Collection Via GCS
For each shelf...
1. Sample trajectories from unexplored regions of the state space
2. Does our planning objective change if the trajectories will be used for imitation learning?
3. Do we need to use a different planner? Ex. something stochastic, sampling-based, less "optimal"?
Other Approaches
\mathcal{D}\{(o_i,a_i)\}
\pi_\theta(a | o)
End Goals + Contact?
There are more interesting problems in manipulation than just motion planning...
- Ex. contact-rich manipulation, manipulation of deformable, dexterous in-hand manipulation
Good toy examples? Ex. 2D maze, reaching into shelves, etc
Benchmarks?
Human Demos
Human demonstrations still have a lot to offer
- Diversity, recovery actions, ability to demonstrate harder tasks
- sim2real
How can we leverage a small amount of human data to improve performance and reduce the sim2real gap?
Classifier Free Guidance
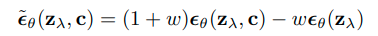
Ho & Salimans, 2022
Conditional Score Estimate
Unconditional Score Estimate
Guided Denoising Step


Increasing 'Guidance Strength'
Classifier Free Guidance
Idea: Train a diffusion policy to learn both the human data distribution and the synthetic data distribution. At runtime, bias the diffusion toward 'human-like' trajectories
Potential Advantages
1. Provides control over the influence of human data without the need for more human data
2. Can rely on synthetic data to perform the bulk of the training
3. Score function similarity is a proxy for distribution similarity?
deck
By weiadam



