Math Lectures
Comparing Doc2Vec and Tf-idf models to classify text.
Objective:
Proposed Flow
- The Data
- Cleaning the data
- Doc2Vec model
- TF-idf model
- Comparison
- Application
-Project Overview
Scrape The Data
Clean data
Doc2Vec model
TF-idf model
Compare
Clustering
Metrics to Compare
Silhouette Score
Silhouette Score*
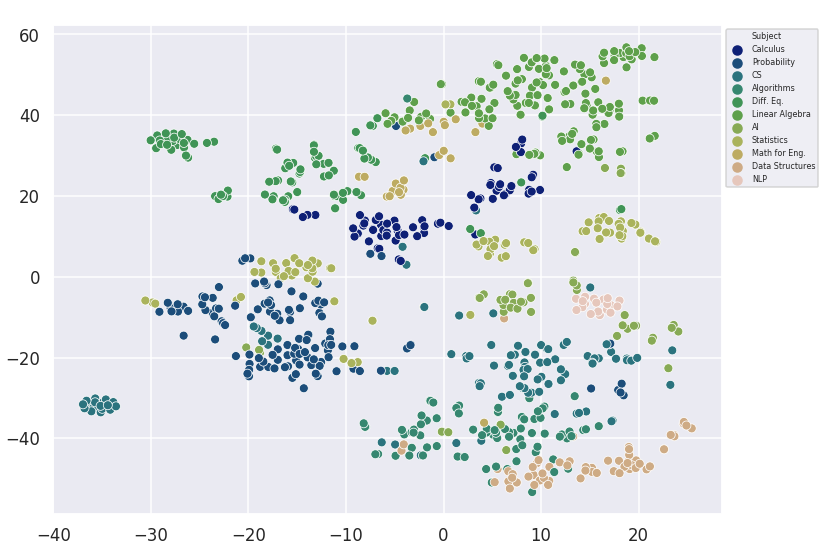
t-SNE Visualization*
t-SNE Visualization
Cosine Similarity
Mean Similarity*
Mean Similarity
f1 score*
Classification
f1 score
Clustering
Silhouette Score*
t-SNE Visualization*
Cosine Similarity
Mean Similarity*
f1 score*
Classification
The Data
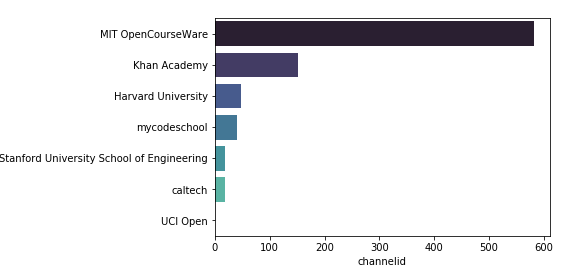
-The data consists of subtitles from 860 maths lectures scraped from youtube videos
Scraping the data
1. Find playlists on youtube
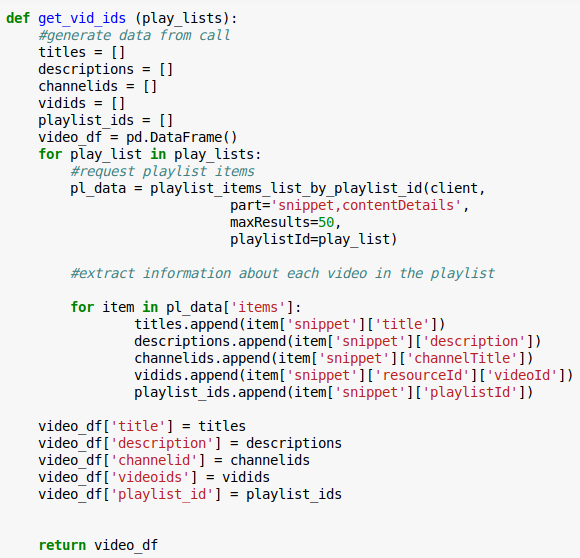
2. Youtube API call for video ids from playlists
3. Store video ids
4. Use video id list with youtube -dl to download the subtitles
Get video ids
Download CCs, extract information
5. Convert files to csv
6. Store text from all csv files in one DataFrame
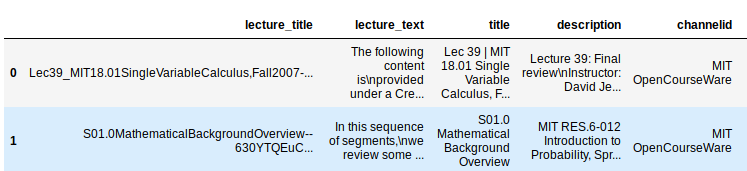
Cleaning the Data


Before
After
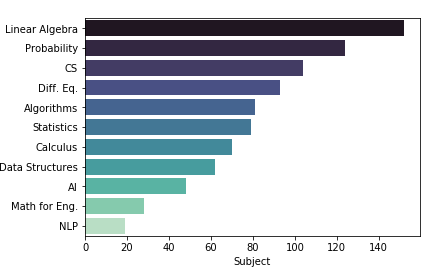
Inspecting the Data
Sources
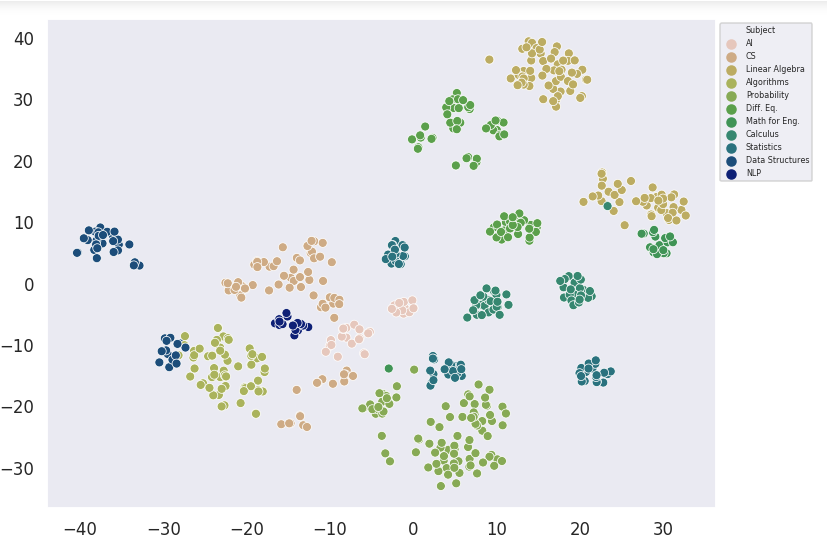
Subjects
Scrape The Data
Clean data
Doc2Vec model
TF-idf model
Compare
Clustering
Metrics to Compare
Silhouette Score
Silhouette Score*
t-SNE Visualization*
t-SNE Visualization
Cosine Similarity
Mean Similarity*
Mean Similarity
f1 score*
Classification
f1 score
Clustering
Silhouette Score*
t-SNE Visualization*
Cosine Similarity
Mean Similarity*
f1 score*
Classification
Train a Doc2Vec Model
Clustering the Doc2Vec Vectors
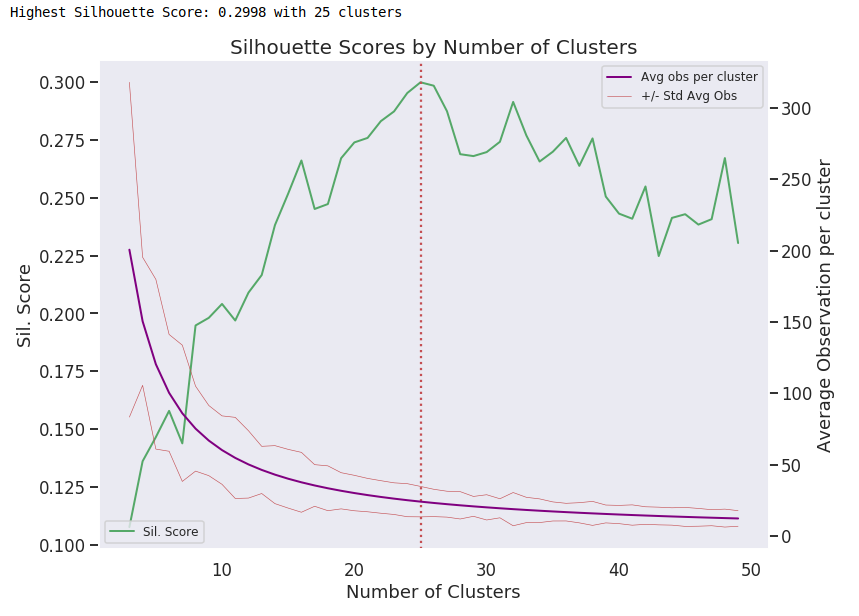
KMeans
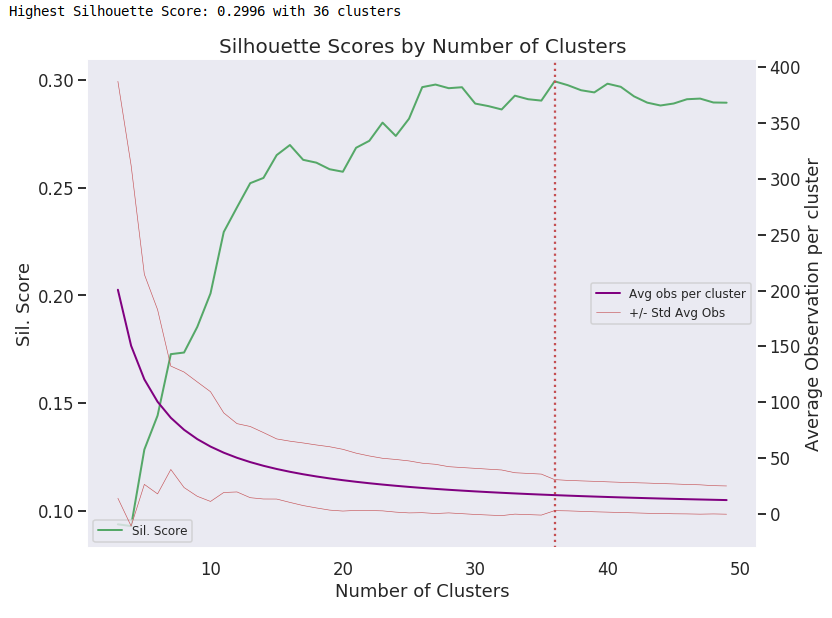
Agglomerative
Highest Silhouette Score: .2998
Number of Clusters: 25
Highest Silhouette Score: .2996
Number of Clusters: 36
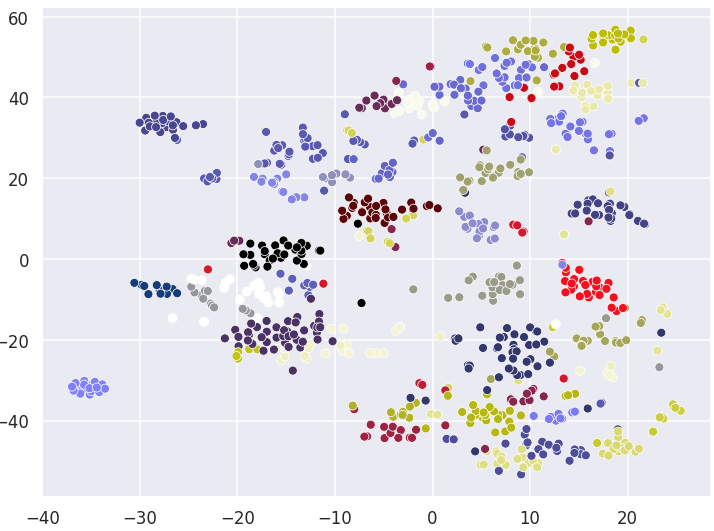
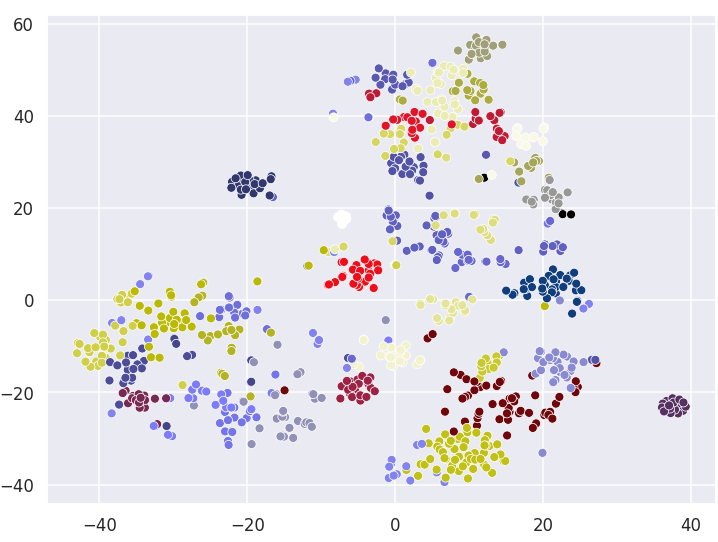
Visualizing Clusters with t-SNE decomposition
K Means
Agglomerative Clustering
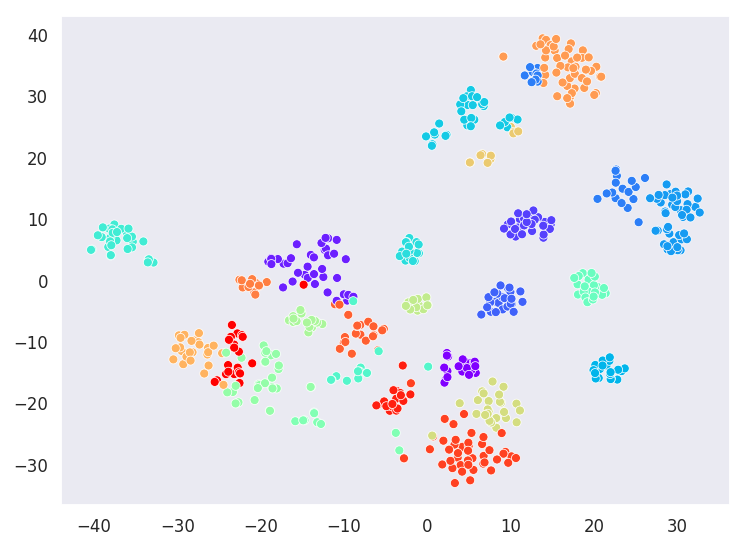

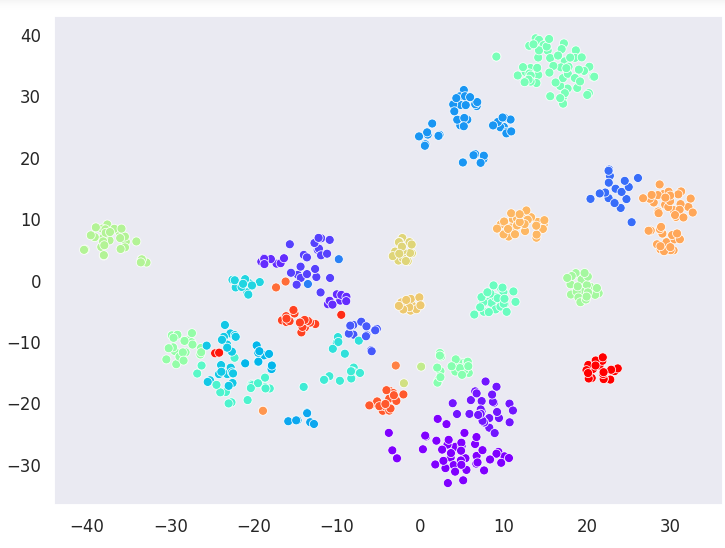

True Labels
Scrape The Data
Clean data
Doc2Vec model
TF-idf model
Compare
Clustering
Metrics to Compare
Silhouette Score
Silhouette Score*
t-SNE Visualization*
t-SNE Visualization
Cosine Similarity
Mean Similarity*
Mean Similarity
f1 score*
Classification
f1 score
Clustering
Silhouette Score*
t-SNE Visualization*
Cosine Similarity
Mean Similarity*
f1 score*
Classification
KMeans
.2998
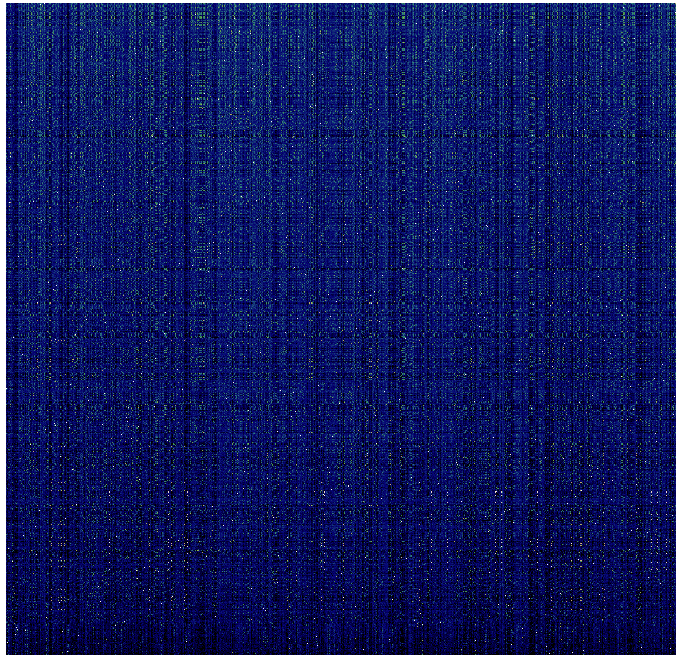
Cosine Similarity Matrix

Lecture 1
Lecture 2
Lecture 3
Lecture m
x1
x2
x3
x100
Lecture 1
Lecture 1
Lecture 2
Lecture 3
Lecture 3
Lecture 2
1
1
1


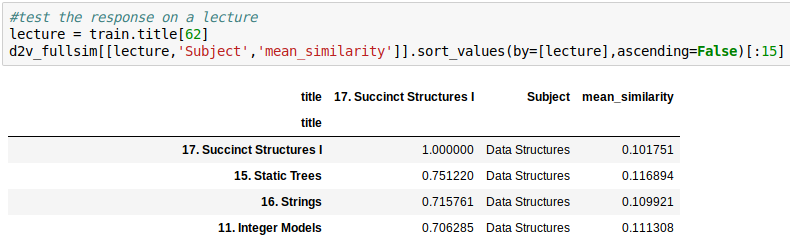
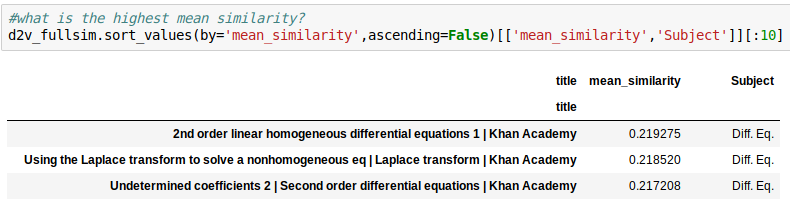
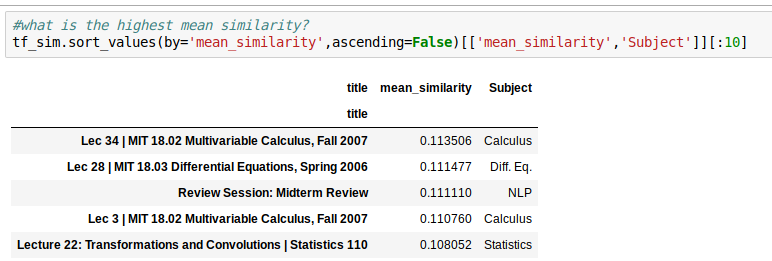
Calculate Mean Similarity
Look up the most similar
Look at the *most* similar

Average Mean Similarity: .1445
Scrape The Data
Clean data
Doc2Vec model
TF-idf model
Compare
Clustering
Metrics to Compare
Silhouette Score
Silhouette Score*
t-SNE Visualization*
t-SNE Visualization
Cosine Similarity
Mean Similarity*
Mean Similarity
f1 score*
Classification
f1 score
Clustering
Silhouette Score*
t-SNE Visualization*
Cosine Similarity
Mean Similarity*
f1 score*
Classification
KMeans
.2998
.1445
Document Classification with Doc2Vec
Creating testing data from the model

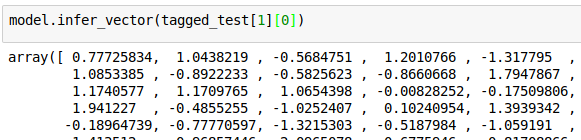
Use 'infer_vector' to generate test set vectors.
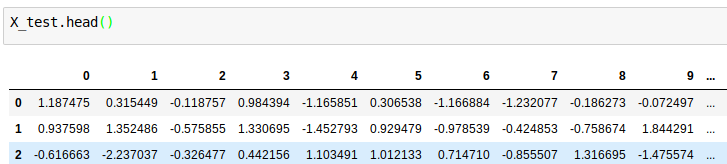
Test set vectors
Classification with Doc2Vec
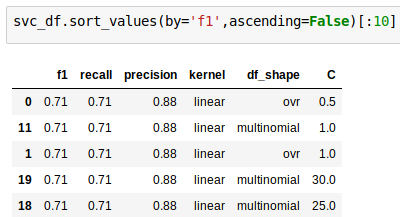
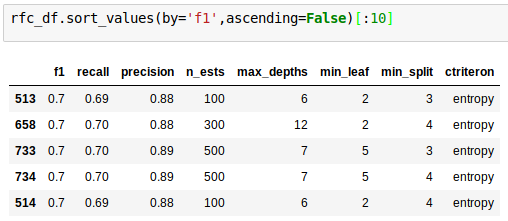
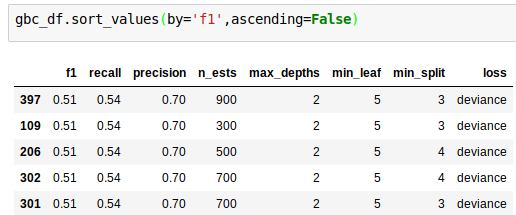
SVC = .71
Random Forest = .7
Gradient Boosting = .51
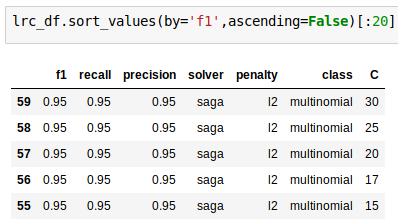
Logistic Regression = .95
Classification with Doc2Vec
Logistic Regression
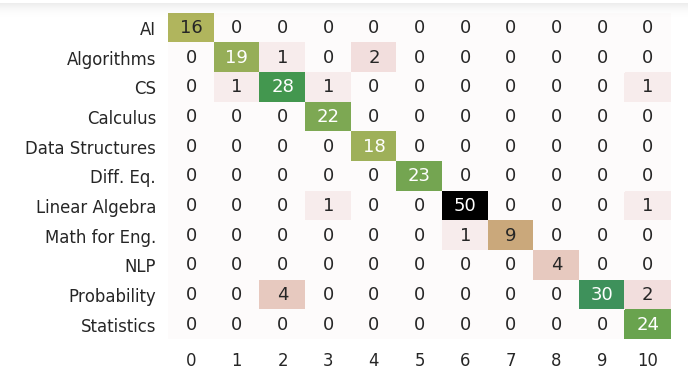
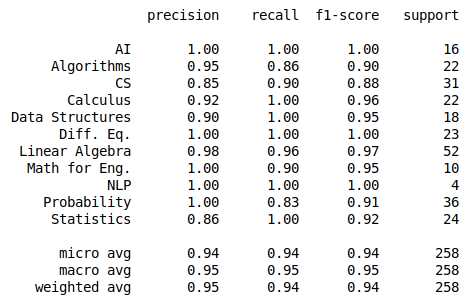
Highest f1 score: .94
Scrape The Data
Clean data
Doc2Vec model
TF-idf model
Compare
Clustering
Metrics to Compare
Silhouette Score
Silhouette Score*
t-SNE Visualization*
t-SNE Visualization
Cosine Similarity
Mean Similarity*
Mean Similarity
f1 score*
Classification
f1 score
Clustering
Silhouette Score*
t-SNE Visualization*
Cosine Similarity
Mean Similarity*
f1 score*
Classification
KMeans
.2998
.1445
.94
Tf-idf and Clustering
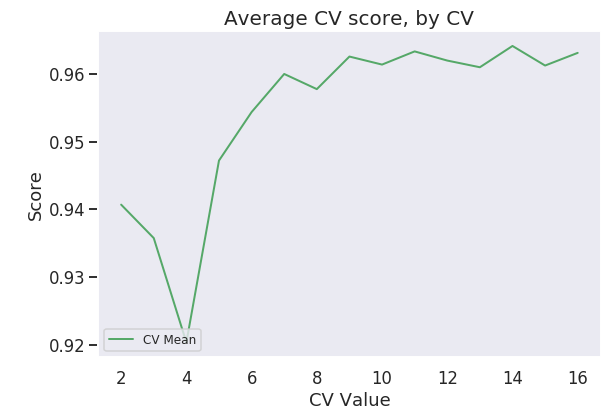
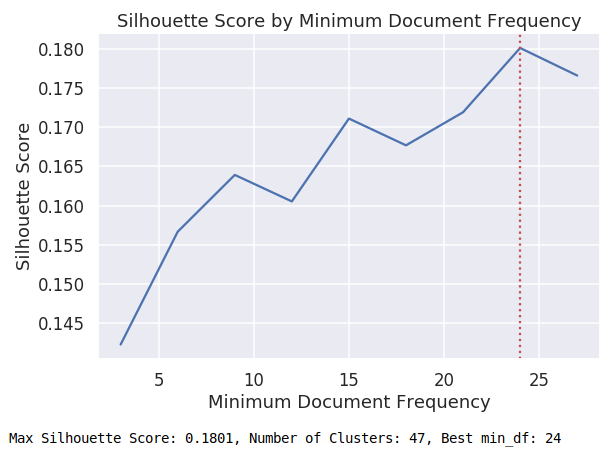
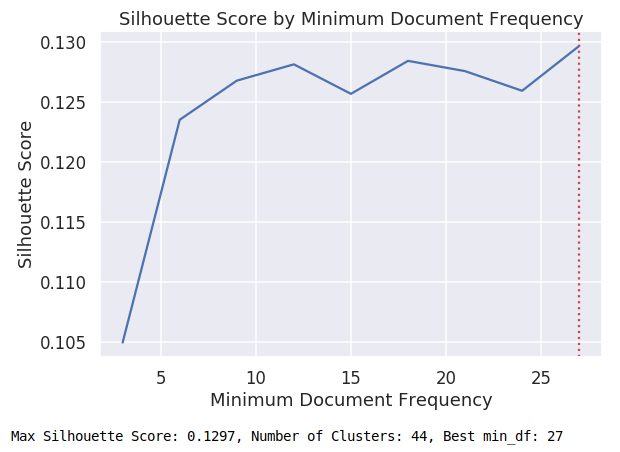
Try different values for min_df
for each tf-idf iteration, cluster vectors from 8-50 clusters
K Means
Agglomerative
Highest Silhouette Score: .1801
Highest Silhouette Score: .1297
Actual Labels
Cosine Similarity


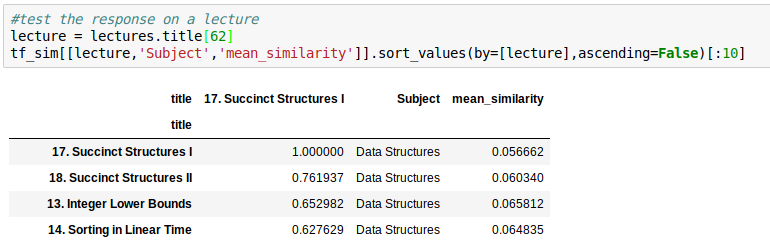
Look up related items
Look at *most* similar
Average Mean Similarity: .065
Scrape The Data
Clean data
Doc2Vec model
TF-idf model
Compare
Clustering
Metrics to Compare
Silhouette Score
Silhouette Score*
t-SNE Visualization*
t-SNE Visualization
Cosine Similarity
Mean Similarity*
Mean Similarity
f1 score*
Classification
f1 score
Clustering
Silhouette Score*
t-SNE Visualization*
Cosine Similarity
Mean Similarity*
f1 score*
Classification
KMeans
.2998
.1445
.94
KMeans
.1800
.065
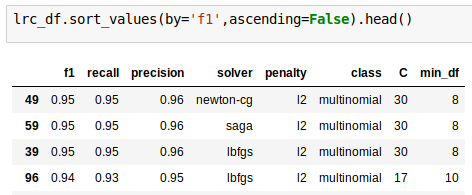
Classification modeling with tf-idf
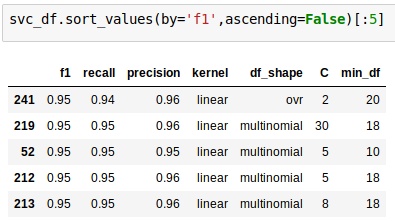
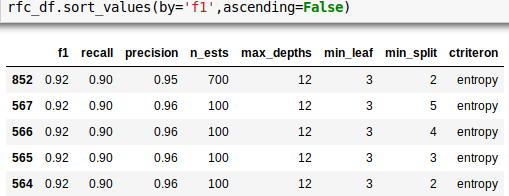
Random Forest = .92
SVC = .95
Logistic Regression: .95
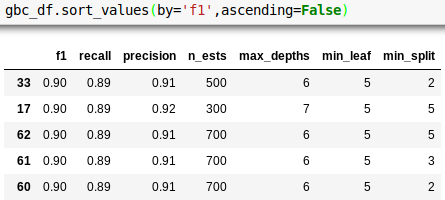
Gradient Boosting = .90
Classification with Tf-idf Vectors
Logistic Regression
Highest f1 score: .95
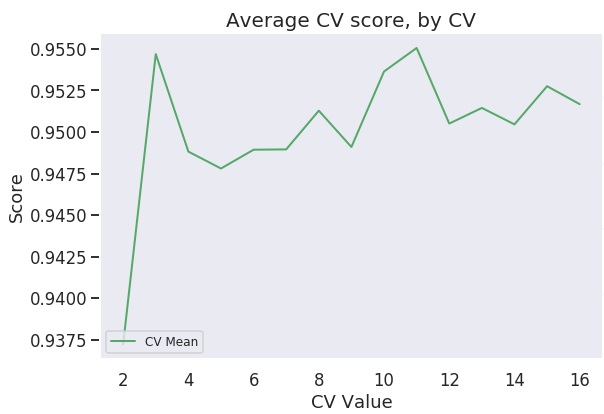
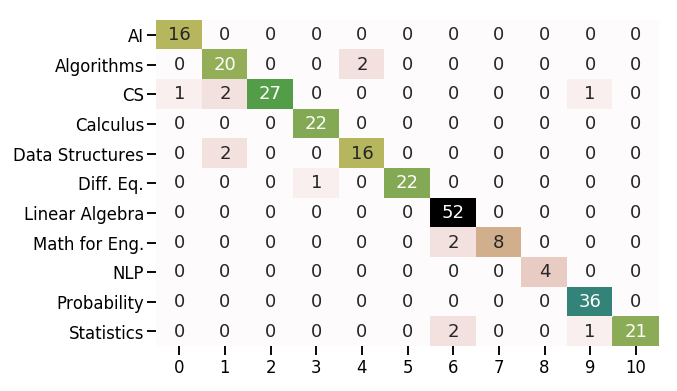
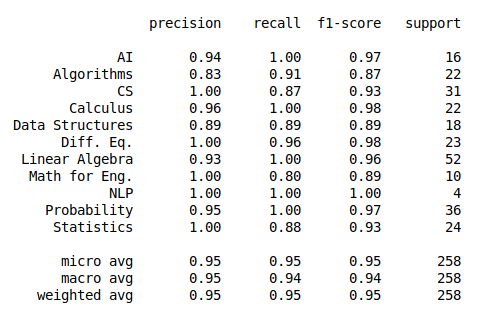
Scrape The Data
Clean data
Doc2Vec model
TF-idf model
Compare
Clustering
Metrics to Compare
Silhouette Score
Silhouette Score*
t-SNE Visualization*
t-SNE Visualization
Cosine Similarity
Mean Similarity*
Mean Similarity
f1 score*
Classification
f1 score
Clustering
Silhouette Score*
t-SNE Visualization*
Cosine Similarity
Mean Similarity*
f1 score*
Classification
KMeans
.2998
.1445
.94
KMeans
.1800
.065
.95
Clustering
Doc2Vec
Tf-idf
Cosine Similarity
.2998
.1801
.065
.1445
Mean Similarity
Mean Similarity
Classification
.94
.95
Compare
Silhouette Score
Avg f1
Mean Similarity
Use Cases
Cosine Similarity is useful for identifying items are similar to each other.
Clustering can be used on unlabeled data. This can be useful for determining resource allocation for new tasks.
Example:
"We have thousands of unsorted emails in our info@ourco.com inbox. We want to see how we can most efficiently categorize these emails"
Example:
"We want to deliver a premium experience for our users; we want a way to suggest additional products/items that our users are likely to consume."
Text Classification is useful subject identification and document routing.
Example:
"We want a way to efficiently assign helpdesk tickets to the person who is best fit to answer"
Conclusions
-Doc2Vec is better for clustering and establishing similarity
-Overall the tf-idf model outperformed the Doc2Vec model in the classification task.
Next Steps
-Collect more data
-Use a pre-trained word embedding as part of a deeper neural network to classify the texts
-Use LDA, NMF and other advanced NLP techniques to improve scores.
Text Classification
By will-m
Text Classification
An overview of multi class text classification using Doc2Vec and Tf-Idf



