Databases for Smart Cities
Me
- Lead engineer of plenar.io at UrbanCCD
- @willengler, willengler@uchicago.edu
- My favorite Chicago Brewery is Off Color
Why I'm Here

How would you deliver terabytes of historical and real-time sensor data from cities around the world?
- Requirements and Constraints
- Design Process
- Next Steps and Lessons Learned
Goals for this talks
You've already had a primer on NoSQL. This is a case study in looking at a problem, evaluating the silly amount of available data stores, and picking the components that you need to solve your problem.
Requirements & Constraints
- Input: What does the data look like, and how much will we be receiving?
- Output: What do our users want to do with the data, and how will they be accessing it?
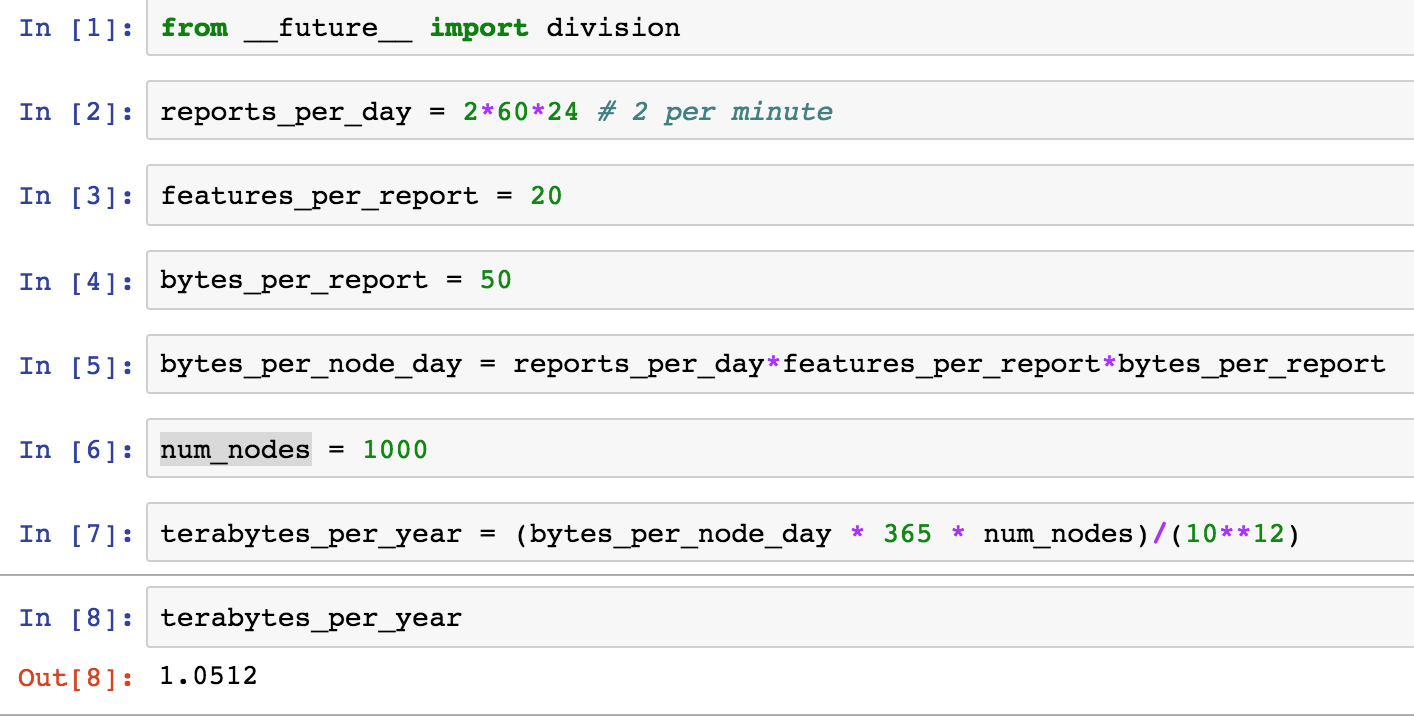
Input: What's Coming from the Nodes?

AoT will essentially serve as a “fitness tracker” for the city, measuring factors that impact livability in Chicago such as climate, air quality and noise.
Is It Big Data?
Is Bigness Even the Most Important Feature?
- Schema flexibility
- Query performance for unconventional access patterns
- Ease of deployment and maintenance
- Don't try to use distributed systems techniques when you don't need them
Output: What Do Our Users Need?
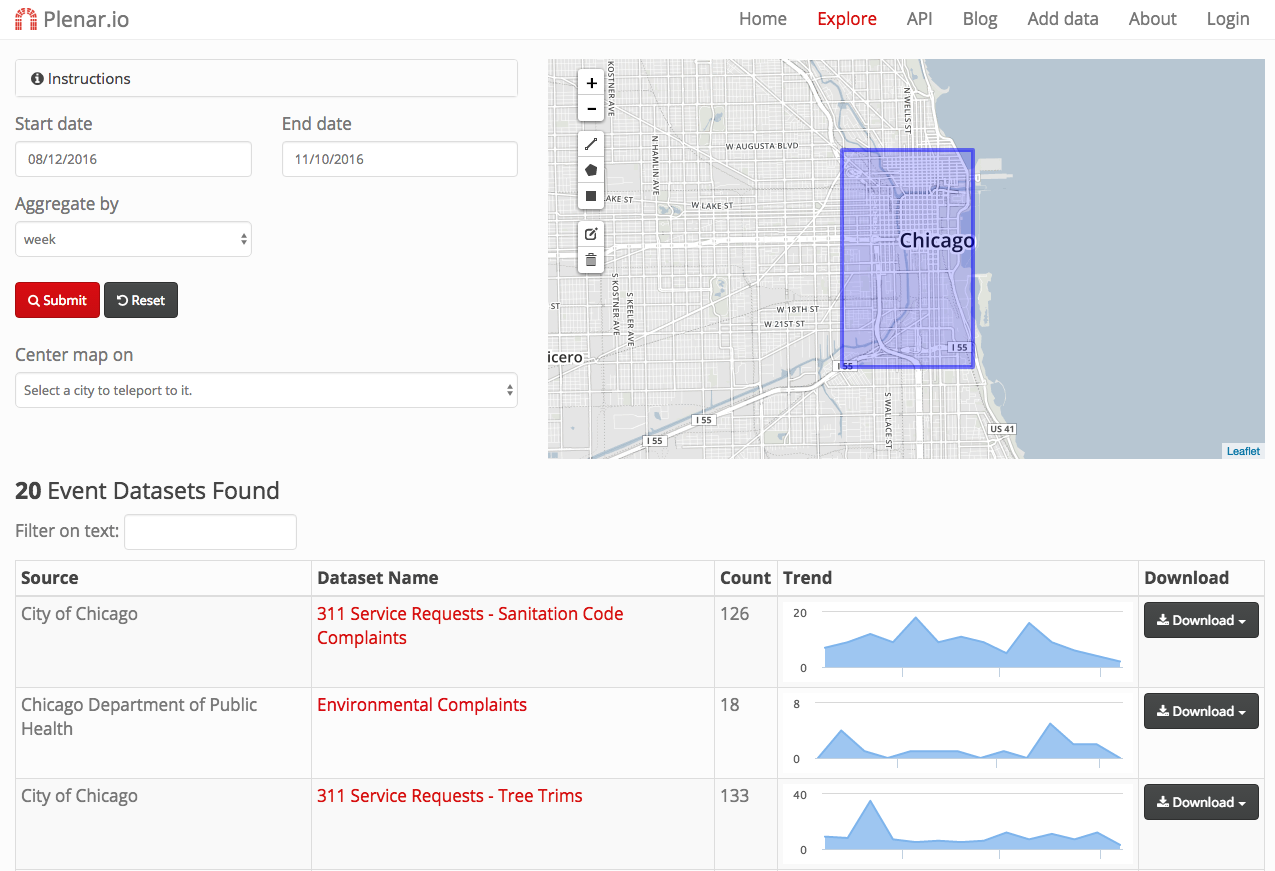
Plenario's Role in Array of Things
- Take on distribution traffic
- Make AoT data discoverable
- Enable real time applications
Aside: Relational vs. Document
- Working on supporting document storage and queries for "entities" like businesses, buildings
- Already supports relational data (events like crimes, shapes like district boundaries)
Distribution
- Make it easy to get big archives
- Make it easy to subscribe to a stream
- Make it easy to do ad hoc and exploratory queries
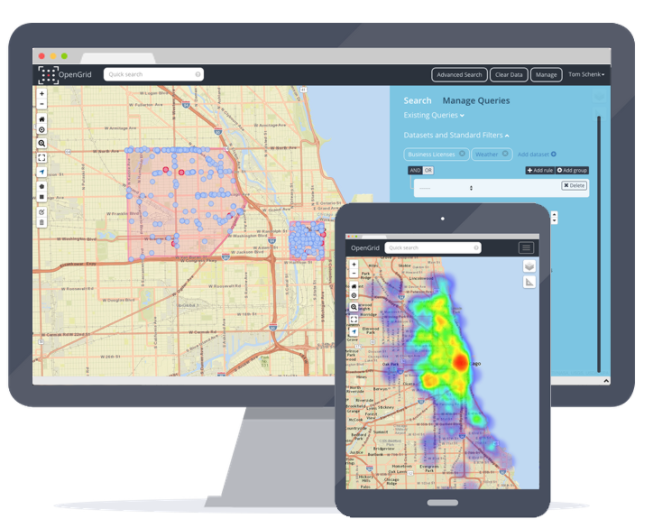
Discoverability
- Nobody cares about node 0x2A1. They care about their neighborhood.
- Nobody cares about sensor HTU21D. They care about how hot it is outside.
Real Time
- Archived data will be useful for climate science, social science
- Real time data has the potential to improve city services, empower citizens
Design Process

Plenario
The Big Picture
Outside-In
- API Design
- Ingestion
- Storage and Retrieval (Databases!!!)
API Design
Make the Problem Easier
- Support streaming to reduce `tail` queries
- Dump common aggregations on S3 to prevent common bulk queries
Ingest Data - Problem
- Need a way for the lab server to push us observations as soon as they're processed
- Need to emit to websocket and insert into database
- Uptime is critical
Ingest Data - Solution
- We chose AWS Kinesis
- A hosted message queue
- Kind of like Apache Kafka
- "pub/sub" model where some services can publish to the queue and others can subscribe
- The lab server publishes observations and new metadata to the queue
- A "mapper" service subscribes to the queue, emits observations through websockets, and inserts observations into the database
Databases
- Depending on how you count, we have two or four databases
- AWS Redshift for sensor observations
- Postgres for sensor metadata
- Redis for transient data
- AWS Kinesis for streaming data
Can We Just Use Postgres?
- Best case scenario is to use just one battle-tested database
- Plenario already used Postgres, so we would have little extra ops effort to make new tables in the same database instance
- Our team already knows and loves it
Why Not Postgres
- Bigness
- We use AWS hosted Postgres, where storage limit is 6TB
- Our existing data, plus new sensor data, plus indexes could bump us over quickly
- Performance
- Postgres is amazingly well-engineered, but maybe we can take better advantage of the shape of our data with a more specialized database
How About DynamoDB?
Hosted NoSQL key-value database

DynamoDB Pros
- Flexible schema: we don't need to know all of the types of observations ahead of time
- Pay for performance (throughput per unit time), not for RAM
- Simplicity of query language
DynamoDB Cons
- Limited indexing
- Can only index two values at once, which would make querying on node, time, and value rough
- If we don't know about feature types ahead of time, no way to index against their values without making a table per feature
- Simplicity of query language
- We would need to perform aggregates in a secondary step
How About AWS Redshift?
- SQL data warehouse (Postgres dialect)
- Column-based storage
- Parallel processing
Redshift Pros
Column-based storage
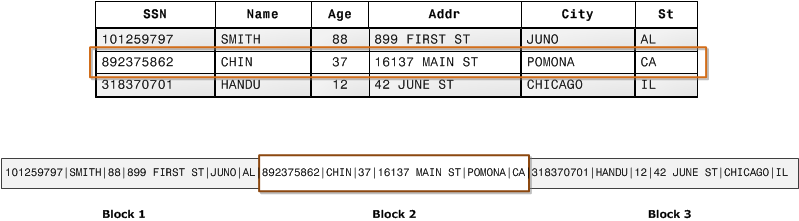
Redshift Cons
- Pricy
- Doesn't have many of the nice Postgres features
- PostGIS
- JSONB
¿Porque no los dos?
- While Redshift was ideal for observations, Postgres won out for metadata
- Flexible Schema
- Postgres is a pretty capable document database (like MongoDB)
- This helped a lot when designing around uncertainty in metadata formatting, and supporting sensor networks other than AoT
- Spatial integration
- If we keep metadata in Postgres, we can do spatial joins with existing datasets
Secret Weapon: Kinesis
- Distributed log store handles our high-velocity problems
- Data bases are being "unbundled"
Lessons Learned & Next Steps
"No Battle Plan Survives Contact With the Enemy"
- Helmuth Van Kohle
"No Application Survives Contact With Production Data"
- Will
Could it be simpler?
Need to Scale Up Streaming Service
More Resources
- Designing Data-Intensive Applications, a wonderful overview of data storage techniques
- Our GitHub
Databases for Smart Cities - Remix
By Will Engler
Databases for Smart Cities - Remix
University of Chicago Guest Lecture - M.S. Databases 2017




