



























Wilmer González
Venezuelan student of Computer Science at UCV. Data Science. Big data. Data Mining. Researching.
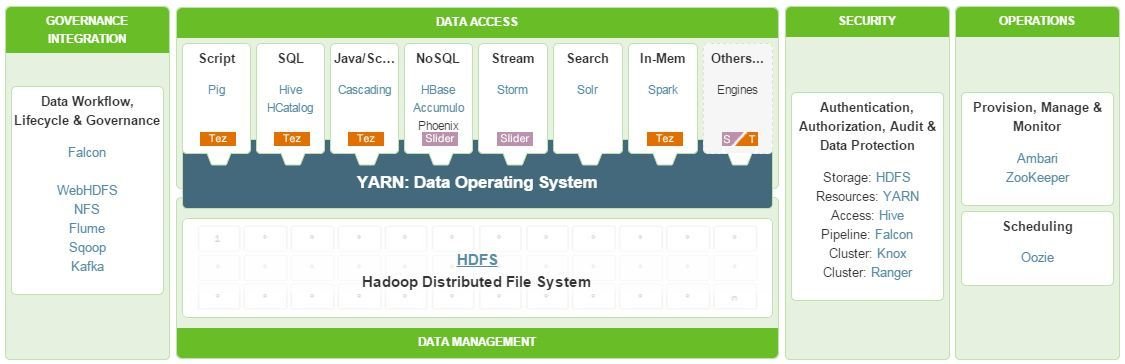
¿Qué es hadoop?
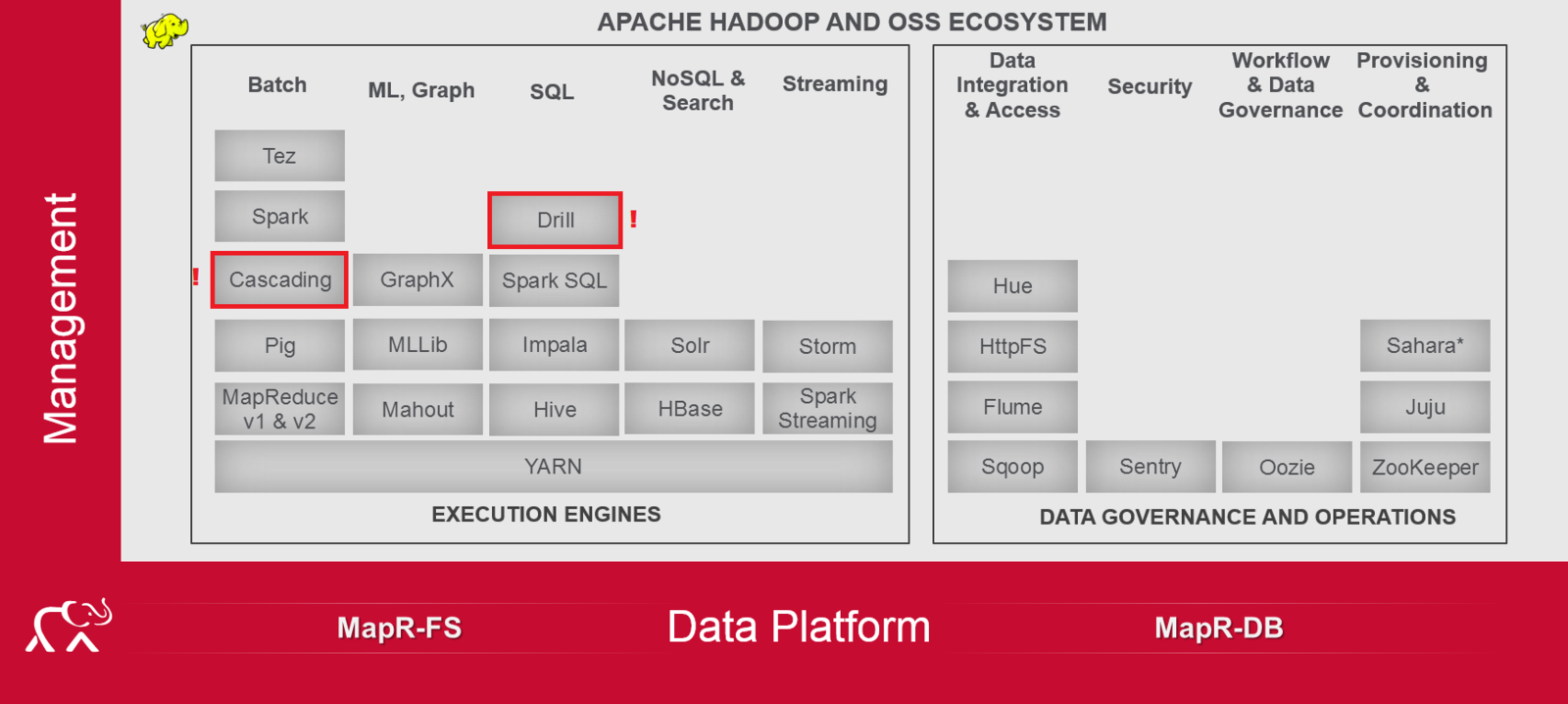
Principales proyectos
Es un proyecto de desarrollo, con código abierto, de computación:
Apache™ Hadoop®
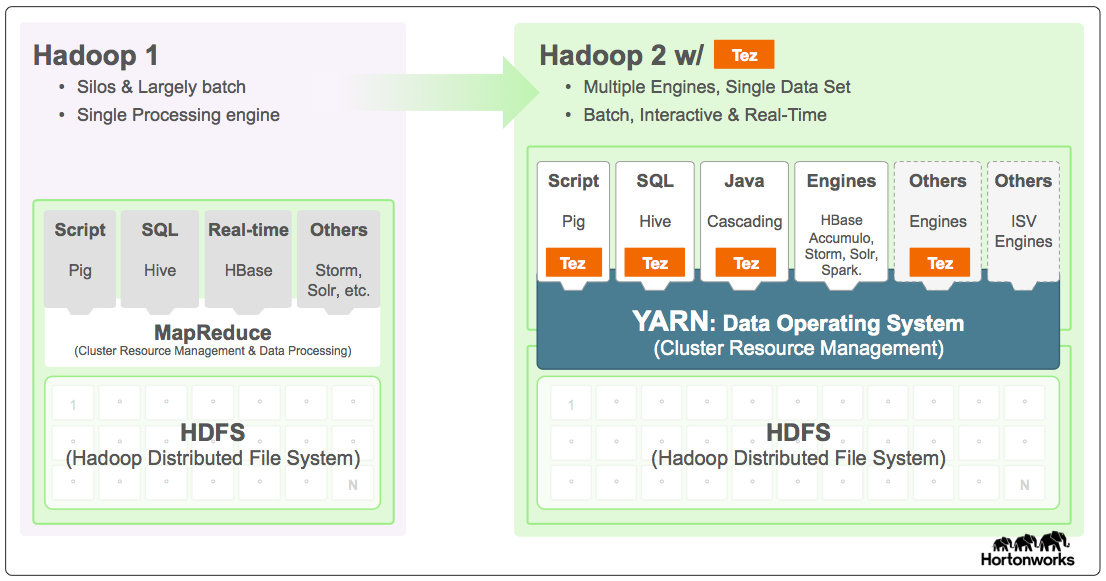
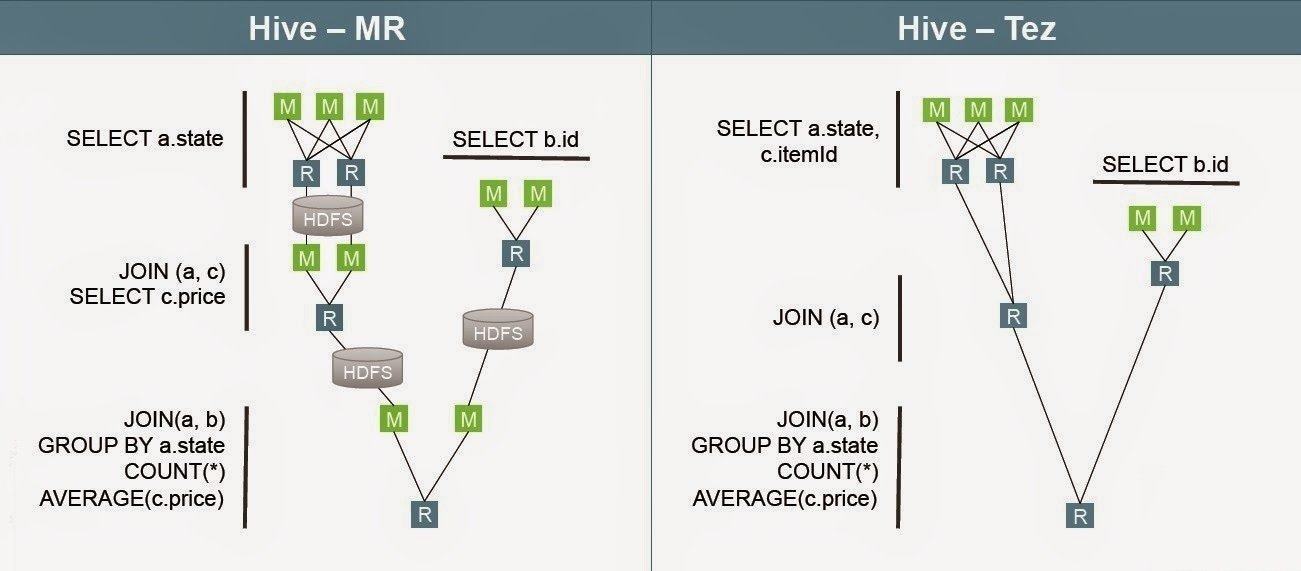
Framework para la construcción de aplicaciones de procesamiento de datos batch e interactivas de alto rendimiento. Tez mejora el paradigma MapReduce.
Generaliza el paradigma MapReduce para ejecutar un DAG de tareas.
Dataflow definition API. Permite modelar (construir) el plan de ejecución en forma de grafo.
Vértices: Entrada - Procesamiento - Salida
Aristas: Movimiento de los datos
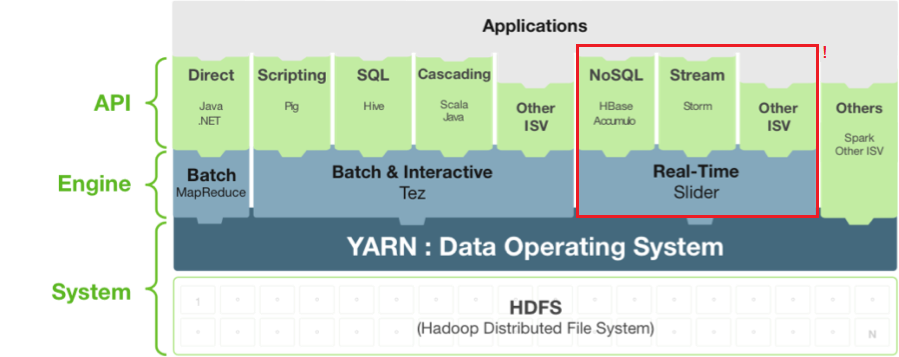
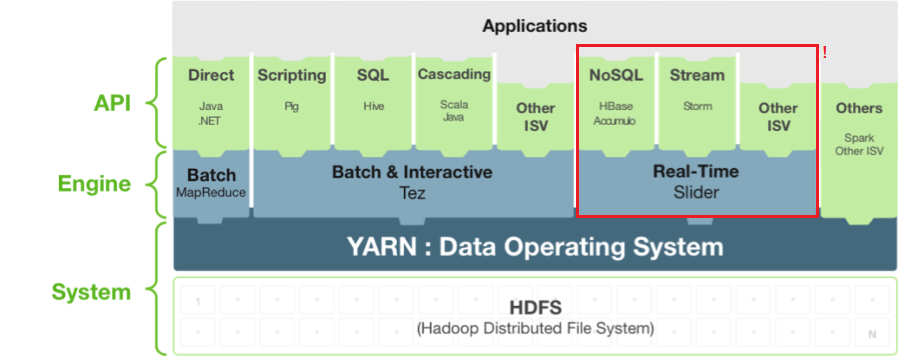
Framework para la gestión y despliegue de aplicaciones de acceso a los datos 'long-running'. [Aplicaciones YARN Dinámicas].
"Complementa a Apache Tez permitiendo que aplicaciones long-running y servicios en tiempo real se integren fácilmente al ecosistema Hadoop"
Agregar aplicaciones bajo demanda en un cluster YARN.
Ejecutar diferentes versiones de una aplicación.
Ejecutar diferentes instancias de una aplicación.
Detener, suspender y reanudar instancias de aplicación.
Ampliar / reducir instancias de aplicación, según sea necesario.
Permite:
Skin SQL para HBase. Utiliza las API's estándar de JDBC en lugar de las de HBase para crear tablas, insertar y consultar datos.
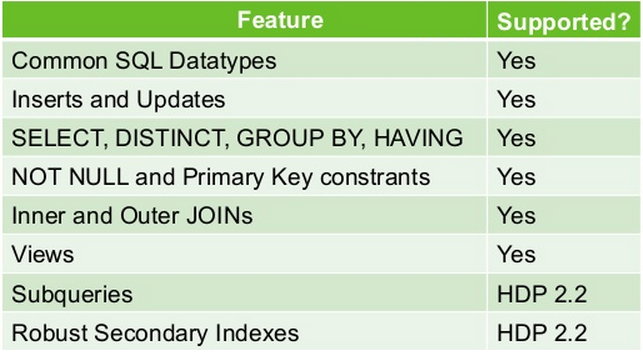
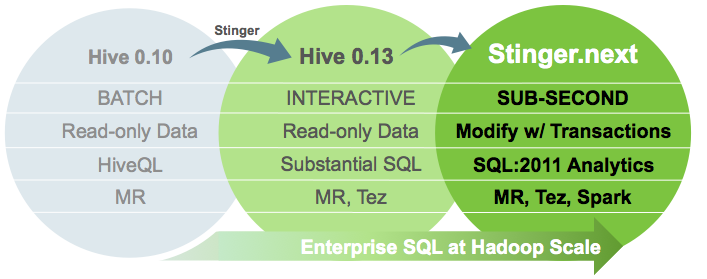
Hive es el estándar de facto para SQL en hadoop. Stinger.next es una iniciativa para evolucionar Hive y proveer SQL empresarial en escala hadoop.
Es un motor de consultas distribuida de baja latencia para conjuntos de datos a gran escala, incluyendo datos estructurados y semi-estructurados / anidados. Se caracteriza por:
Impala
Impala
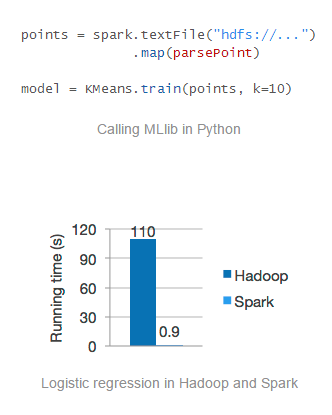
Es un motor rápido y general para el procesamiento de datos a gran escala, usando:
Admite SQL con programas Spark
Admite consultas a diversas fuentes de datos (Hive tables, JSON, etc)
Compatible con HiveQL
Estándar de compatibilidad ODBC
Streaming, batch and interactive.
Tolerancia a fallos de estado y operadores sin código adicional.
Soporta Scala, Python y Java.
Visualización de datos en gráficos o colecciones
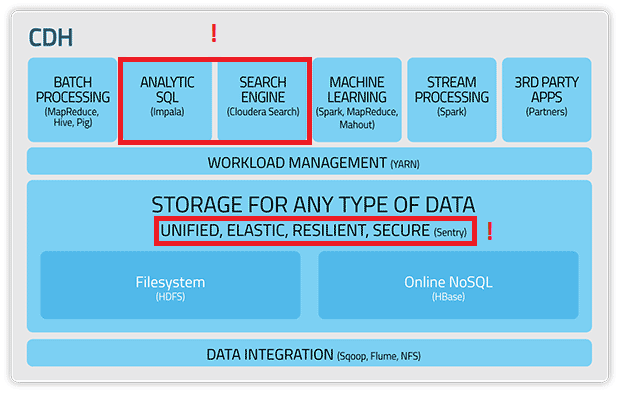
Es un conjunto de aplicaciones web que interactúan con CDH (Cloudera Data Hub):
Es un módulo de seguridad que gestiona el acceso a la mayoría de herramientas SQL y de BI, posee las siguientes características:
Es una herramienta de gestión de datos integrada de manera nativa con hadoop, posee las siguientes características:
www.hortonworks.com www.mapr.com www.cloudera.com
By Wilmer González



