Python爬蟲
Introduction
用途:
- 針對目標網站自動擷取資訊
- 將非表格的資料轉換成可結構化的資料
- 追蹤資料變更

例如:
- 社群:流行趨勢、熱門話題
- 股票:追蹤股票趨勢、資料分析
- 線上商店:取得價錢貨比三家
- 網路書店:指定主題的圖書清單



Python set up
Jupyter notebook
pip3 install jupyter
google colab
下載requests 和 beautiful soup套件
pip3 install --user --upgrade requests bs4在命令提示字元打下:
瀏覽網頁的步驟
-
輸入URL網址
-
根據HTTP請求回應至瀏覽器(通常為HTML)
-
剖析網頁內容(DOM) Document Object Document
-
瀏覽器根據DOM產生內容
HTTP通訊協定?
瀏覽器
伺服器
請求
回應
HTTP通訊協定
主從架構(Client-Server Architecture):
Client
Server
HTTP請求
HTTP回應
-
客戶端要求連線伺服端
-
伺服端允許
-
客戶端送出HTTP請求(GET請求/POST表單送回)
-
伺服端以HTTP回應請求
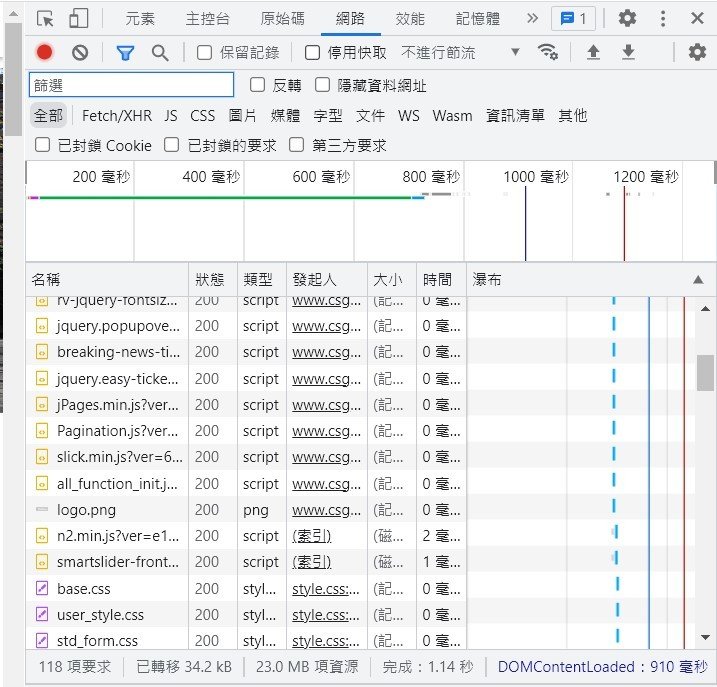
一個網頁要送出幾個請求?
URL網址:
- http和https:前者為HTTP通訊協定,後者為HTTP加密傳輸版本
- 網域名稱(會透過DNS轉換成IP位址)
- 通訊埠號(http為80、https為443)
- 資源路徑
- 參數
- 區塊ID
通訊協定://伺服器位址:埠號/資源路徑?參數#區塊ID標準:
requests
pip install requests開發環境安裝:
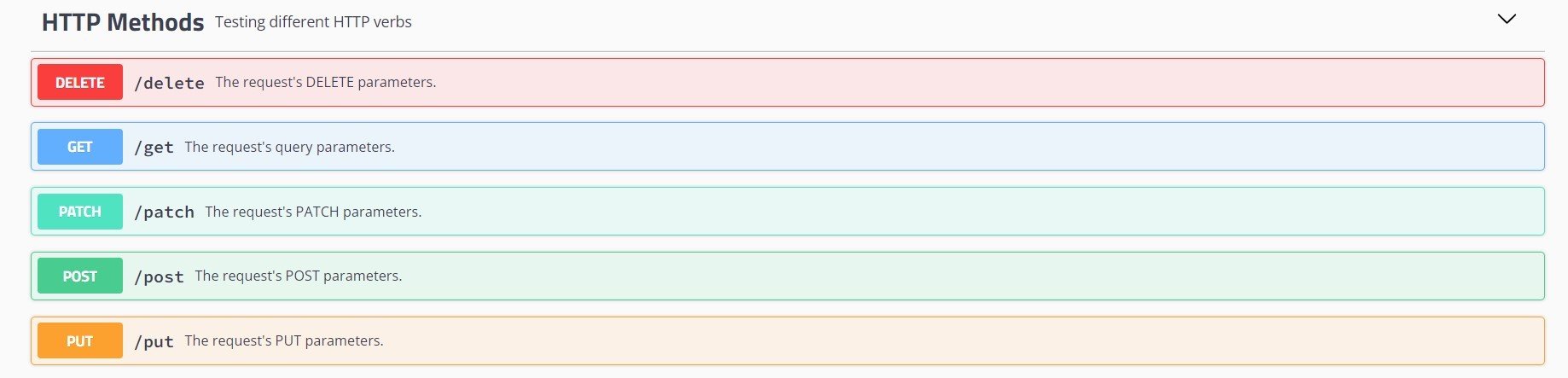
測試網站: http://httpbin.org/
get:
import requests
url="網址"
response=requests.get(url)變數response取得網頁資料的回應
| text | html標籤字串 |
|---|---|
| contents | 非文字類位元組資料(bytes) |
| encoding | html編碼 e.g. UTF-8 or big5等等 |
| status_code |
狀態碼 請求成功:200/requests.codes.ok 請求失敗(不存在):4xx (404) 伺服器錯誤:5xx |
| header | 取得header |
| url | 取得現在的url |
回應後做出指示:
import requests
url="https://www.csghs.tp.edu.tw/"
response=requests.get(url)
if response.status_code==200:
print(response.encoding)
print(response.text)
else:
print("HTTP請求失敗")參數:
get_params={
"key":"value"
}
url="目標網址"
response=requests.get(url,params=get_params)
import requests
url="http://httpbin.org/get"
params_get={"name":"Phoebe","year":"17"}
response=requests.get(url,params=params_get)
print(response.text)import requests
url="https://www.csghs.tp.edu.tw/"
params_get={
"s":"行事曆"
}
response=requests.get(url,params=params_get)
print(response.text)
post:
http://httpbin.org/post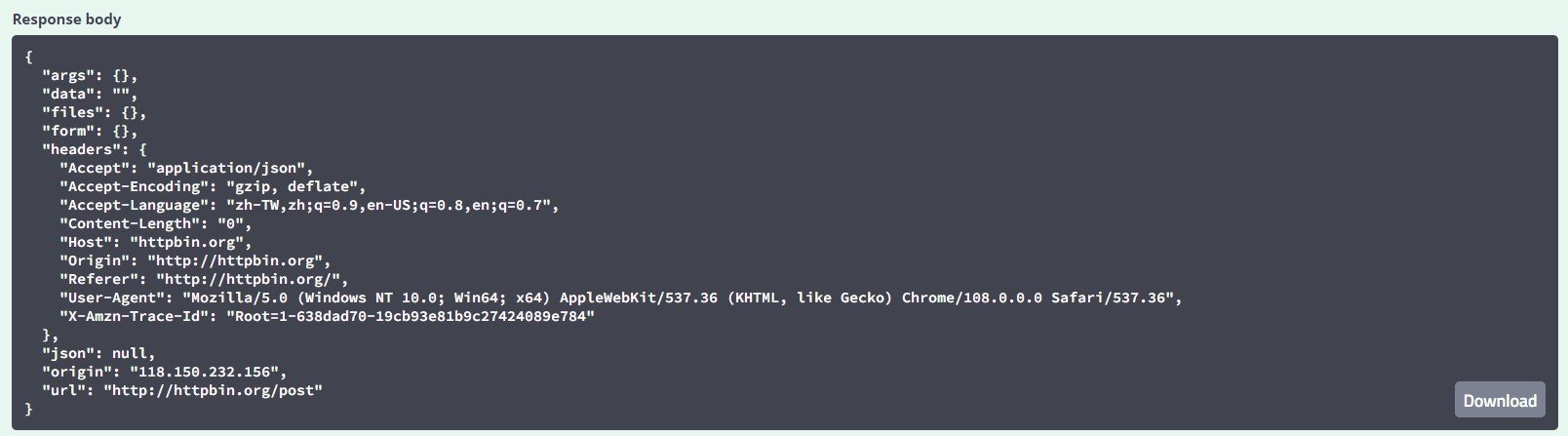
參數:
post_data={
"key":"value"
}
url="目標網址"
response=requests.post(url,data=post_data)import requests
url="http://httpbin.org/post"
post_data={"name":"Phoebe","year":"17"}
response=requests.post(url,data=post_data)
print(response.text)
headers:
- 過量請求會導致網頁過載
- 避免被偵測為爬蟲
- 設定請求使用者代理
header={
"User-Agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36"
}瀏覽網頁時送出的請求,讓我們看起來不是爬蟲
(其實完整的長這樣)
header={
"Accept": "application/json",
"Accept-Encoding": "gzip, deflate",
"Accept-Language": "zh-TW,zh;q=0.9,en-US;q=0.8,en;q=0.7",
"Host": "httpbin.org",
"Referer": "http://httpbin.org/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/108.0.0.0 Safari/537.36",
"X-Amzn-Trace-Id": "Root=1-639b115a-5c22c80d7c1dc204593dbcd6"
}
url="目標網址"
response=requests.get(url,headers=header)Beautiful soup

import requests
from bs4 import BeautifulSoup
url = "https://www.csghs.tp.edu.tw/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
#"lxml"較快 "html.parser"為預設
print(soup.prettify()) #排版parasing將HTML網頁建立成HTML標籤物件的階層結構,以便快速定位和取出所需要的標籤
- tag
- select_one(),select()
- find(),find_all()
| 方法 | 說明 |
|---|---|
| select_one() | 參數CSS搜尋HTML標籤,回傳第一個符合的 |
| select() | 參數CSS搜尋HTML標籤,回傳所有符合的 |
| find() | 搜尋HTML標籤,回傳第一個符合的 |
| find_all() | 搜尋HTML標籤,回傳所有符合的 |
tag
import requests
from bs4 import BeautifulSoup
url = "https://www.csghs.tp.edu.tw/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
tags=soup("a")
for tag in tags:
print(tag.get("href",None))import requests
from bs4 import BeautifulSoup
url = "https://www.csghs.tp.edu.tw/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
print(soup.title.text)
直接點
| 屬性or方法 | 說明 |
|---|---|
| tag.text | 取得html標籤內容 |
| tag.attrs | 取得標籤所有屬性的字典 |
| tag.get("href",None) | 取得第一個參數href,若沒有輸出None |
| tag.string | 取得內容 |
import requests
from bs4 import BeautifulSoup
url = "https://www.csghs.tp.edu.tw/"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
tags=soup("a")
tag=tags[12]
print("URL:",tag.get("href",None))
print("標籤內容:",tag.text)
print("屬性:",tag.attrs)
範例:
select_one()
import requests
from bs4 import BeautifulSoup
url = "https://fchart.github.io/Elements.html"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
tags=soup.select_one("h2")
print("h2:",tags.text)import requests
from bs4 import BeautifulSoup
url = "https://fchart.github.io/Elements.html"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
tags=soup.select_one("#q2")
tag2=tags.select_one("b")
print("b:",tag2.text)
the 混
id屬性需在前面加上'#'import requests
from bs4 import BeautifulSoup
url = "https://fchart.github.io/Elements.html"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
tags=soup.select("b")
print("b0",tags[0].text)
print("b1",tags[1].text)
print("b2",tags[2].text)select()
import requests
from bs4 import BeautifulSoup
url = "https://fchart.github.io/Elements.html"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
tags=soup.select(".response")
print("li:",tags[0].text)
print("li:",tags[1].text)class屬性可套用於多個標籤,因此需使用select一次讀取import requests
from bs4 import BeautifulSoup
url = "https://fchart.github.io/Elements.html"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
tags=soup.find("h2")
print("h2:",tags.text)find()
find_all()
import requests
from bs4 import BeautifulSoup
url = "https://fchart.github.io/Elements.html"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
tags=soup.find_all("b")
print("b0:",tags[0].text)
import requests
from bs4 import BeautifulSoup
url = "https://fchart.github.io/Elements.html"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
tags=soup.find("li",{"id":"q2"})
tag_q=tags.find("b")
print("Q:",tag_q.text)
tag_a=tags.find_all("li",{"class":"response"})
for tag in tag_a:
print("A:",tag.text)
class_()
import requests
from bs4 import BeautifulSoup
url = "https://fchart.github.io/Elements.html"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
tags=soup.find("li",{"id":"q2"})
tag_q=tags.find("b")
print("Q:",tag_q.text)
tag_a=tags.find_all("li",class_="response")
for tag in tag_a:
print("A:",tag.text)limit()
import requests
from bs4 import BeautifulSoup
url = "https://fchart.github.io/Elements.html"
response = requests.get(url)
soup = BeautifulSoup(response.text, "lxml")
tag_a=soup.find_all("li",class_="response",limit=3)
for tag in tag_a:
print("A:",tag.text)
爬蟲實作
以PTT為例
去PTT挑一個自己喜歡的版面
import requests
url = 'https://www.ptt.cc/bbs/PokeMon/index.html'
response = requests.get(url)
抓起來
從標題下手->
til=soup.find_all("div",class_="title")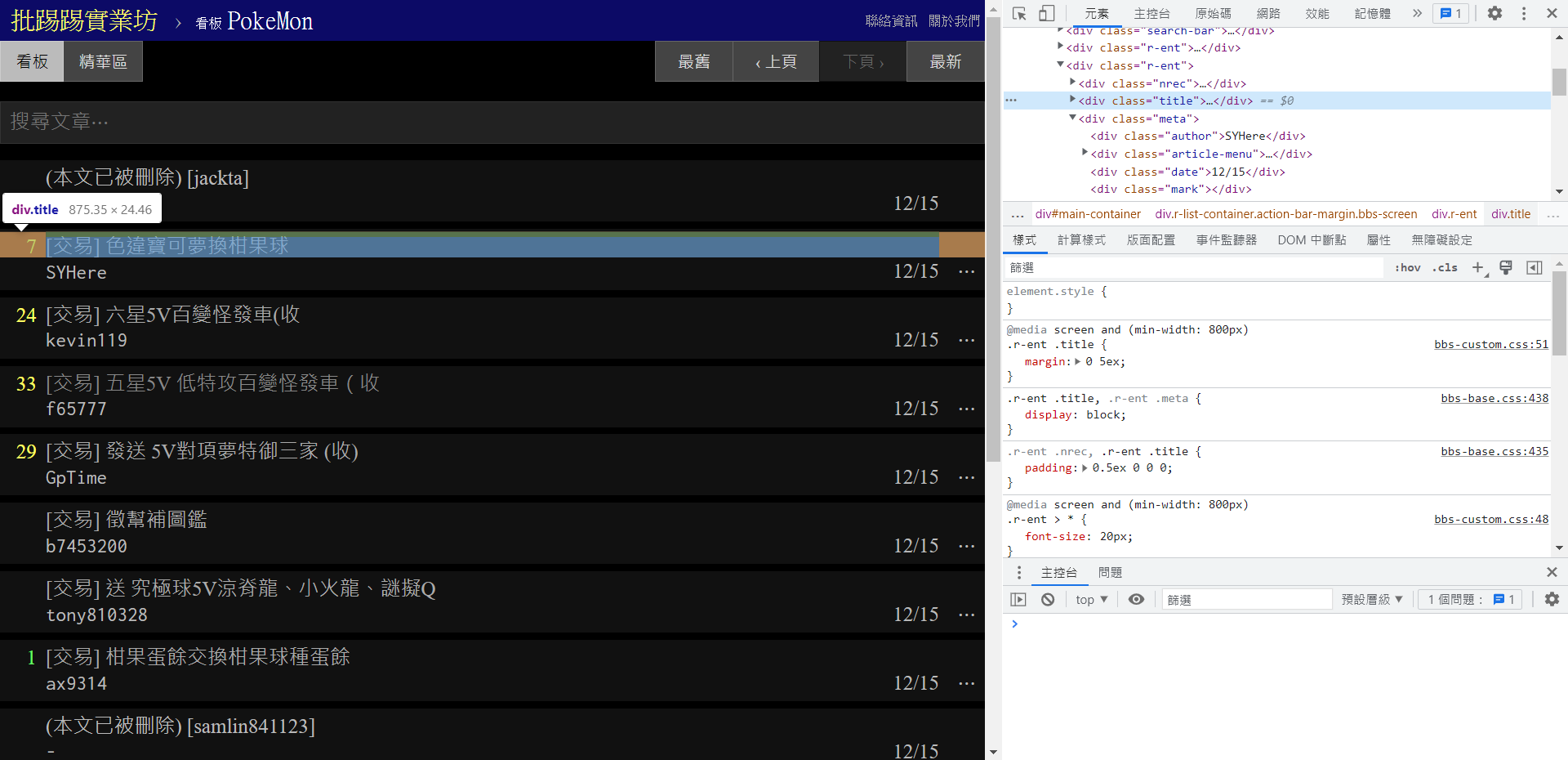
印出所有標題->
til[0],til[1],til[2]...
->使用迴圈取出for t in til:
if t.a!=None:
print(t.a.text)稍作改良
import requests
from bs4 import BeautifulSoup
url = 'https://www.ptt.cc/bbs/PokeMon/index.html'
response = requests.get(url)
soup = BeautifulSoup(response.text, "html.parser")
til=soup.select("div.title a")
for t in til:
print(t.text)
Cookie處理
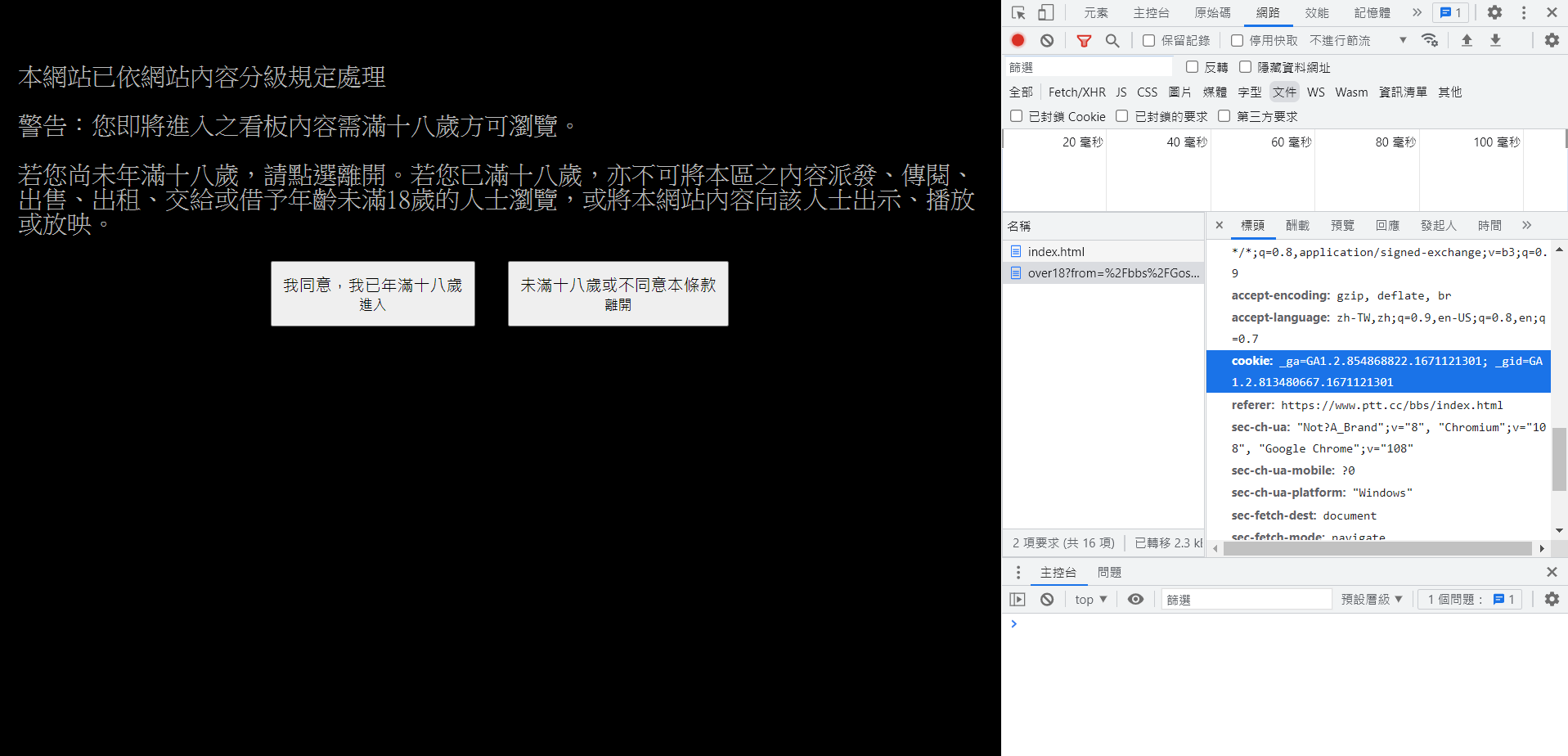
會遭到阻擋
_ga=GA1.2.854868822.1671121301; _gid=GA1.2.813480667.1671121301; over18=1header={
"cookie":"over18=1"
}cookie={
"over18":"1"
}response = requests.post(url,headers=header)
response = requests.get(url,cookies=cookie)import requests
from bs4 import BeautifulSoup
header={
"cookie":"over18=1"
}
url = 'https://www.ptt.cc/bbs/Gossiping/index.html'
response = requests.post(url,headers=header)
soup=BeautifulSoup(response.text,"lxml")
til=soup.select("div.title a")
for t in til:
print(t.text)最終版本:
爬圖
import requests
from bs4 import BeautifulSoup
url = "目標網址"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')起手
往上找id -> 為id=main-container中 div的img
photo=soup.select_one("#main-container img")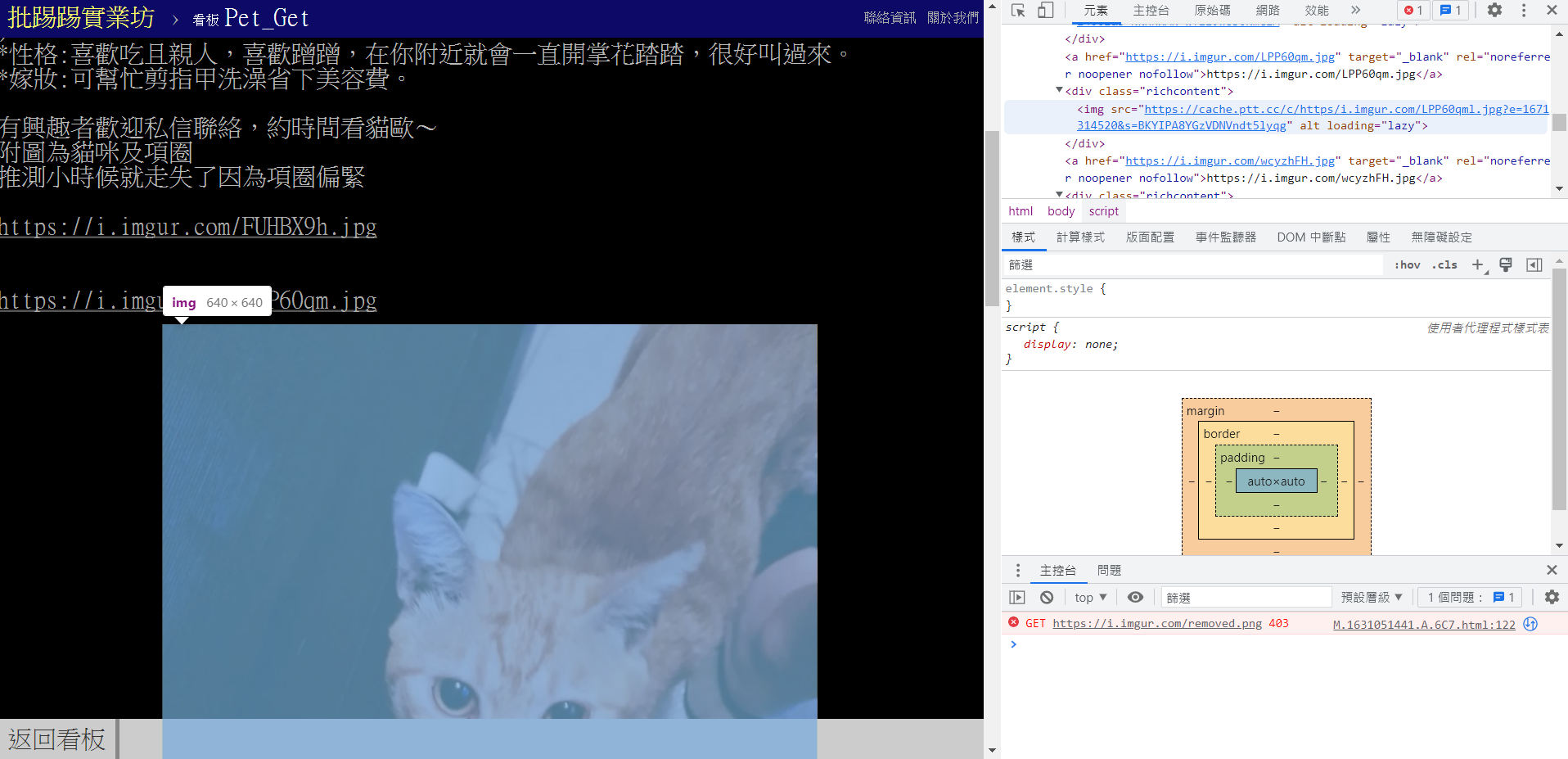
獲取網址:
phurl = "https:" + photo.get("src")import requests
from bs4 import BeautifulSoup
url = "https://www.ptt.cc/bbs/Pet_Get/M.1631051441.A.6C7.html"
response = requests.get(url)
soup = BeautifulSoup(response.text, 'html.parser')
photo=soup.select_one("#main-container img")
phurl = "https:" + photo.get("src")
print(phurl)印出來確認:

創建資料夾:
import os
if not os.path.exists("Pet"): #創資料夾
os.mkdir("Pet")
for chunk in response.iter_content(100000):
FGOFile.write(chunk)
FGOFile.close #關閉資料夾迭代圖片中的區塊:
100000/次
import requests
from bs4 import BeautifulSoup
import os
url = "https://www.ptt.cc/bbs/Pet_Get/M.1631051441.A.6C7.html"
response = requests.get(url)
if not os.path.exists("Pet"): #創資料夾
os.mkdir("Pet")
soup = BeautifulSoup(response.text, 'html.parser')
photo=soup.select_one("img")
phurl = "https:" + photo.get("src")
print(phurl)
PetFile = open(os.path.join('Pet', os.path.basename(phurl)), 'wb')
for chunk in response.iter_content(100000):
PetFile.write(chunk)
PetFile.close 爬所有的圖:
import requests
import os
import bs4
url="https://www.ptt.cc/bbs/Pet_Get/M.1631051441.A.6C7.html"
request = requests.get(url)
data = bs4.BeautifulSoup(request.text, "html.parser")
imageData = data.find_all('img')
path=r"C:\Users\Phoebe Wu\Pet"
if (os.path.exists(path) == False):
os.makedirs(path)
imgList = []
lenth = len(imageData)
for x in range(lenth):
imgList.insert(x,imageData[x].attrs["src"])
for i in range(lenth):
getImage = requests.get(imgList[i])
image = getImage.content
imageSave = open(path+"\img"+str(i)+".jpg","wb")
imageSave.write(image)
imageSave.close()
print("img"+str(i)+".jpg"+"下載成功")
print("下載完成") PythonWebScratch
By Wu Phoebe



