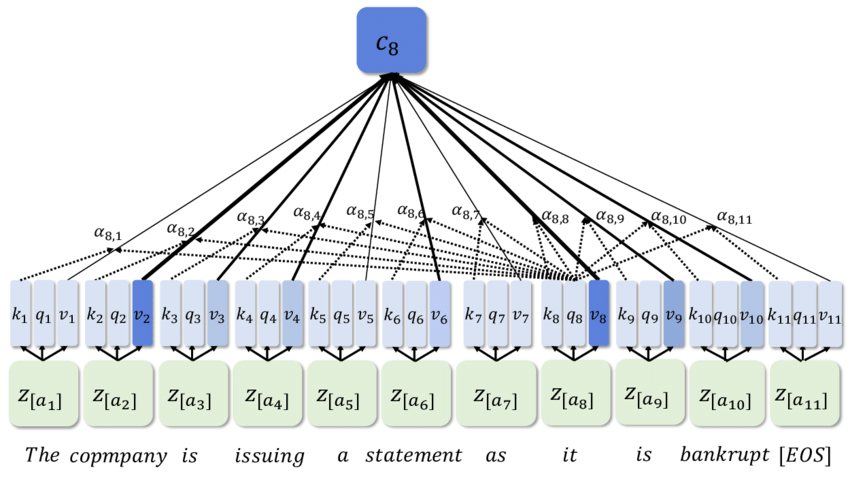
Attention
In Computer Vision




Older approaches
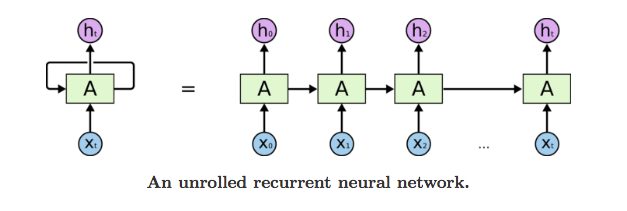
For language models: RNN
One model is running over every word
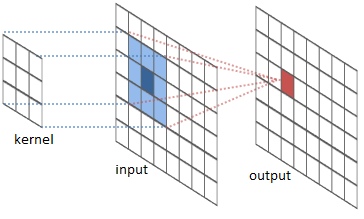
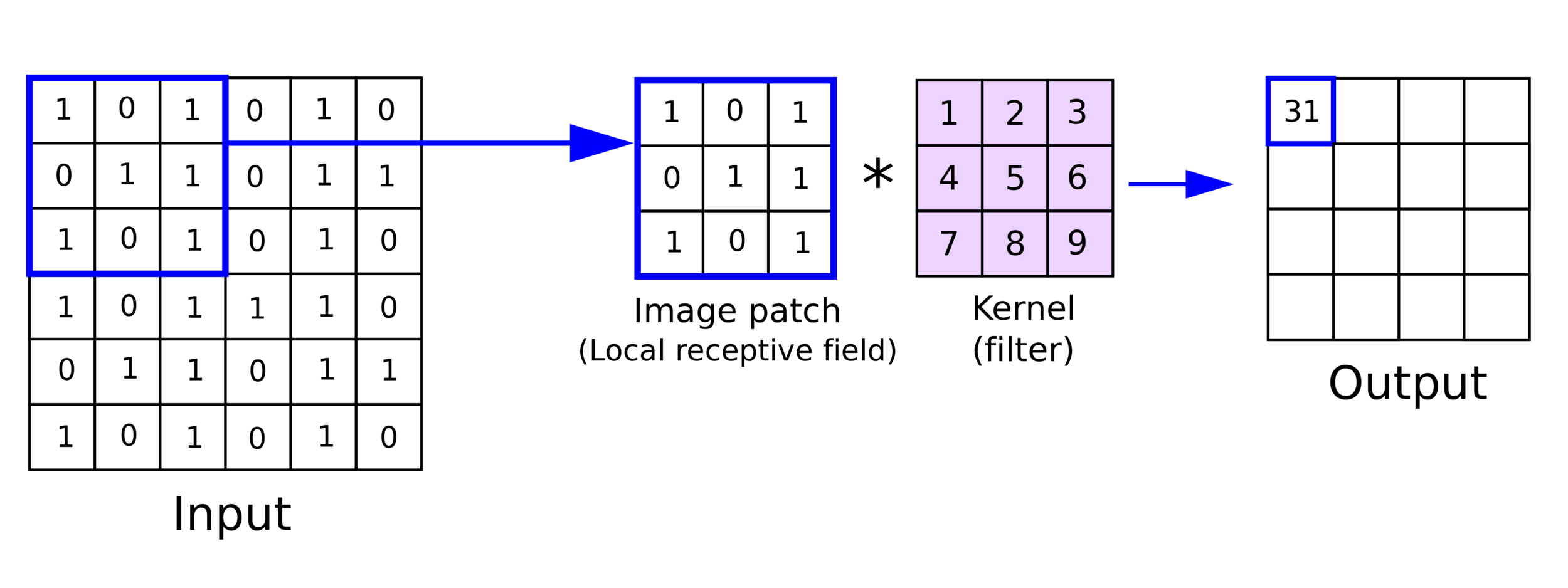
For computer vision: Convolution
Only a small block of pixels processed at a time
Convolutional Layer
Recursive Neural Network
Older approaches
For language models: RNN
One model is running over every word
For computer vision: Convolution
Only a small block of pixels processed at a time
Convolutional Layer
Recursive Neural Network
Older approaches
Ideally we'd process everything at once
All words / image pixels being fed to a single layer
Motivation
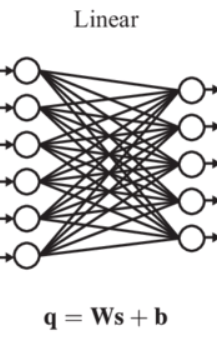
Linear & Convolutional layers rely on an input of fixed size
Motivation
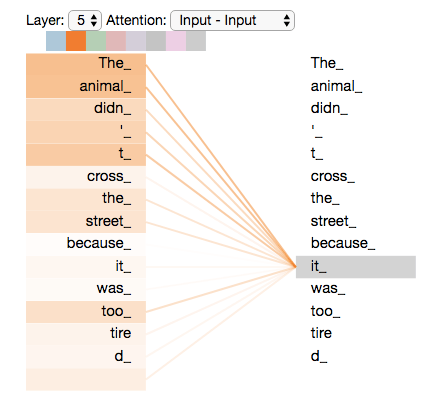
But there's tasks with inputs of arbitrary size

Intuition
Naive idea:
Have the same "Linear Layer", but derive weights on the go
Weights are stored in a matrix
Weights are derived from the two elements
Intuition
Naive idea:
Have the same "Linear Layer", but derive weights on the go
W(i, j) - significance of word i to word j
Intuition
Just use the similarity between words
w_i is a word token (a vector)
W(i, j) = \text{Similarity}(w_i, w_j)\\
w'_j = \sum_i W(i, j)w_i
w
w'
Intuition
Cosine Similarity is convenient
k_i = NN(w_i)\\
W(i, j) = \text{CosineSimilarity}(k_i, k_j) = k_i^T k_j\\
w'_j = \sum_i W(i, j)w_i
w
w'
Intuition
Give even more control to the NNs!
q_i = NN_Q(w_i), k_i = NN_K(w_i), v_i = NN_V(w_i)\\
W(i, j) = \text{CosineSimilarity}(q_i, k_j) = q_i^T k_j\\
w'_j = \sum_i W(i, j)v_i
w
w'
Intuition
Where does that formula come from?
sim is the similarity function
\begin{array}{l}
\begin{pmatrix}
\text{sim}( w_{1} ,\ w_{1}) & \text{sim}( w_{1} ,\ w_{2}) & \text{sim}( w_{1} ,\ w_{3})\\
\text{sim}( w_{2} ,\ w_{1}) & \text{sim}( w_{2} ,\ w_{2}) & \text{sim}( w_{3} ,\ w_{3})\\
\text{sim}( w_{2} ,\ w_{1}) & \text{sim}( w_{2} ,\ w_{2}) & \text{sim}( w_{3} ,\ w_{3})
\end{pmatrix} \ =\ \begin{pmatrix}
q_{1}^{T} k_{1} & q_{1}^{T} k_{3} & q_{1}^{T} k_{3}\\
q_{2}^{T} k_{1} & q_{2}^{T} k_{3} & q_{2}^{T} k_{3}\\
q_{3}^{T} k_{1} & q_{3}^{T} k_{3} & q_{3}^{T} k_{3}
\end{pmatrix} \ \\
=\ \begin{pmatrix}
q_{1}^{T}\\
q_{2}^{T}\\
q_{3}^{T}
\end{pmatrix}\begin{pmatrix}
k_{1} & k_{2} & k_{3}
\end{pmatrix} \ =\ Q K^T
\end{array}
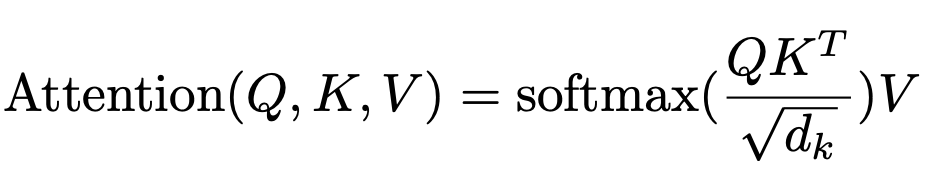
ViT
ViT (Vision Transformer) uses Positional Encoding
To account for the 2D positioning
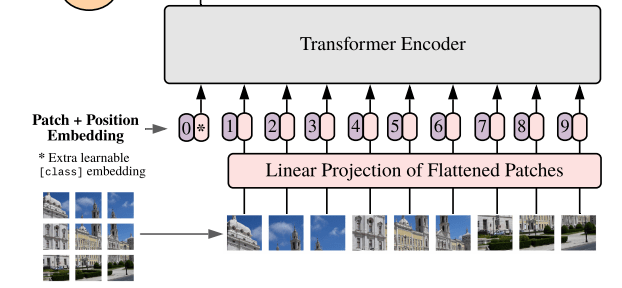
ViT

Segment Anything uses big ViTs

DiNO uses big ViTs
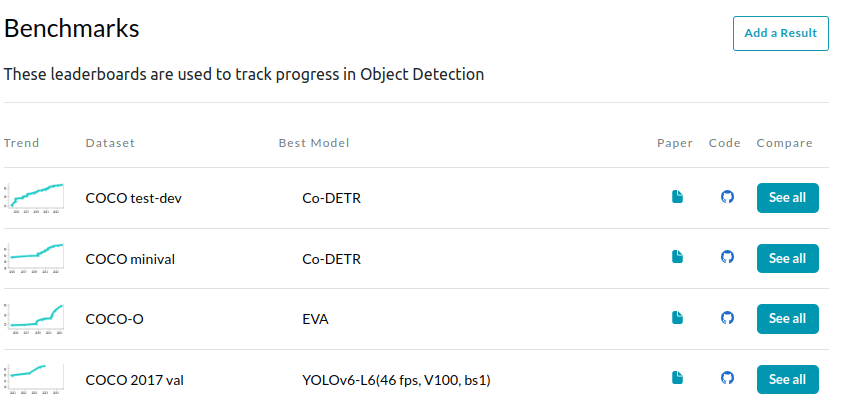
CV benchmarks are mostly overtaken by ViTs
Stable Diffusion
The actual denoising diffusion U-Net is a ViT
The text is integrated there
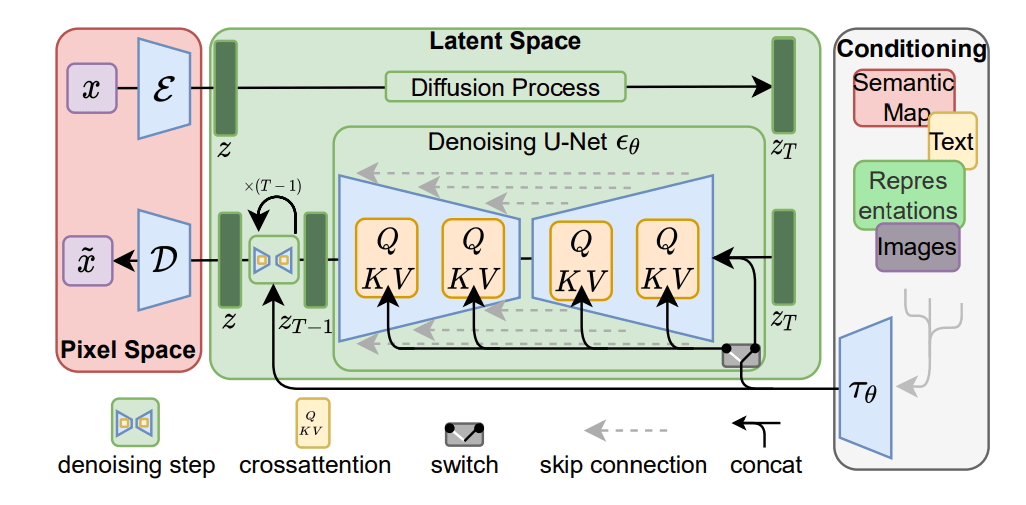
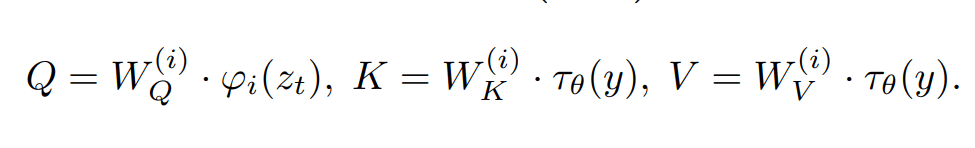
Image editing tricks
During diffusion, intermediate activations from generating original image
Are injected during generation of the new image
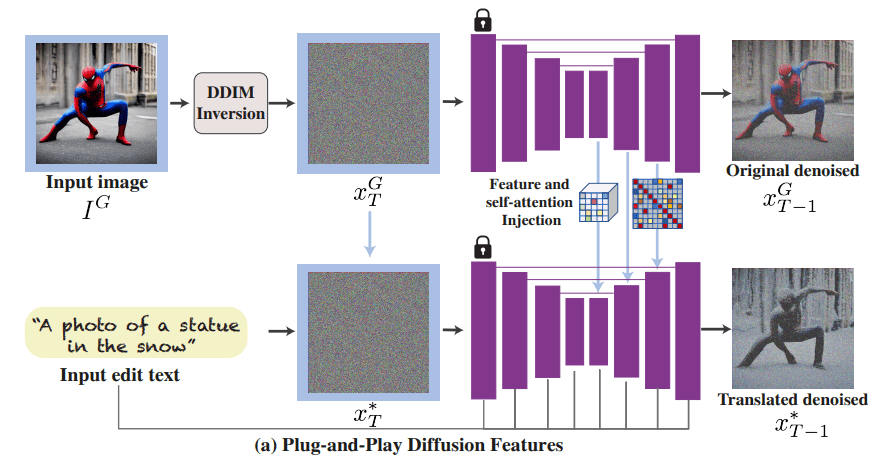
Video editing tricks
Similar thing for video, but we deform the features using Optical Flow
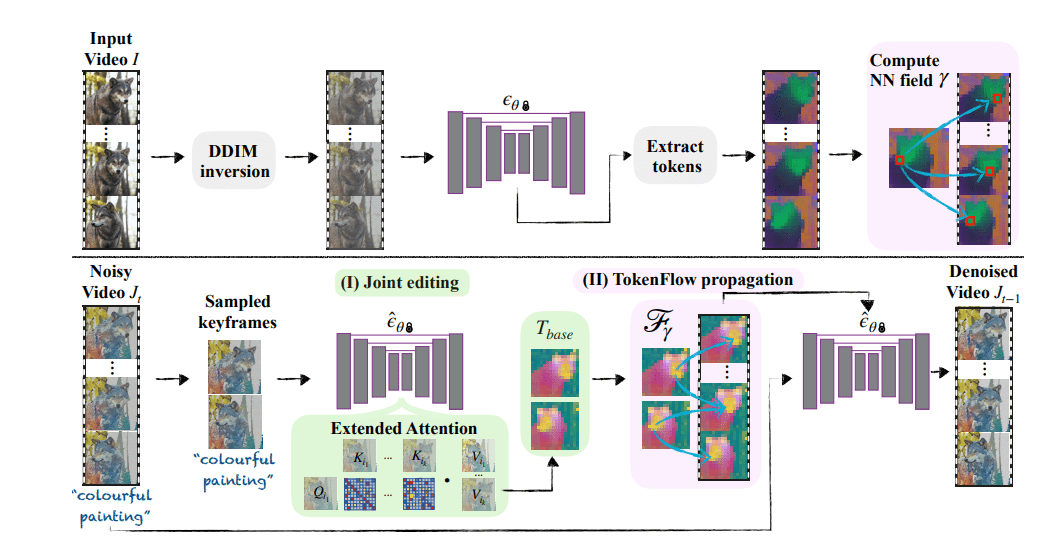
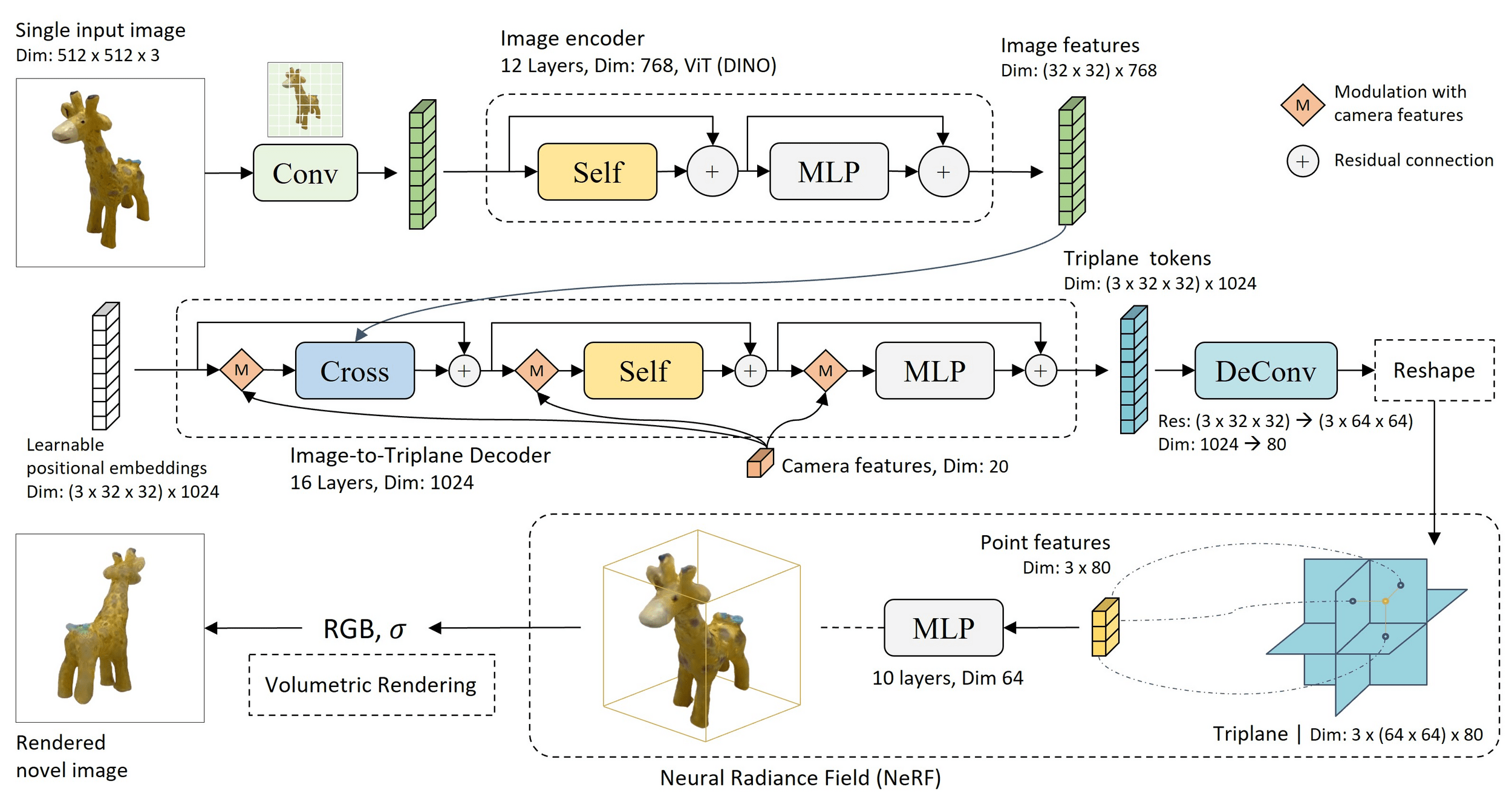
Text-to-3D
Attention is applied cross-images
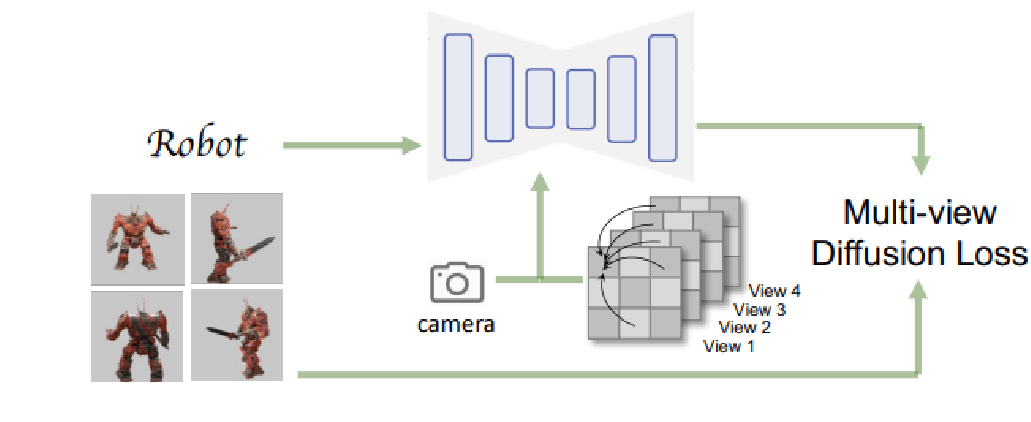
Text-to-3D
Attention is used to inject image features into a 3D structure
Attention in CV
By xallt

