
ICLR 2026(8664)
Background
- Recently, several studies have applied Reinforcement Learning with Verifiable Rewards (RLVR) to the multimodal domain in order to enhance the reasoning abilities of vlms.
- However, these works largely overlook the enhancement of multimodal perception capabilities in vlms, which serve as a core prerequisite and foundational component of complex multimodal reasoning.
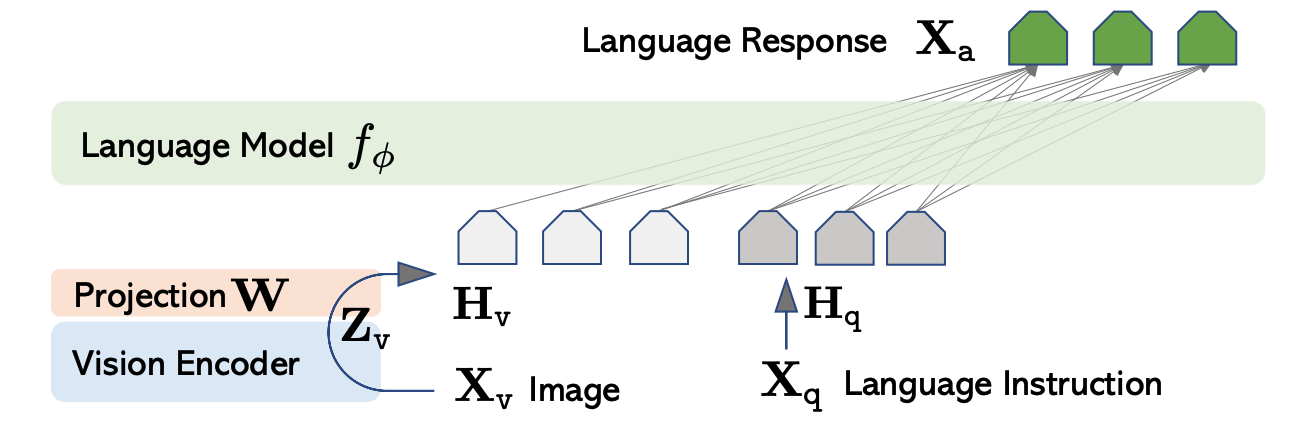
Problem Formulation
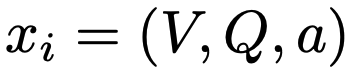
comprises visual input V (e.g., image), a textual query Q, and the corresponding ground-truth answer a.
Given a data sample xi ∈ D as input, the vlm is required to generate a textual token sequence y that aims to reach the ground-truth answer a.
RLVR
Reward Functions:
The reward functions consist of two components:
(1). Format Reward encourages MLLMs to generate in a structured “think-then-answer” format, with the reasoning process enclosed in tags and the answer enclosed in tags.
(2). Accuracy Reward drives the reasoning optimization in RLVR training by evaluating the correctness of predicted answer.
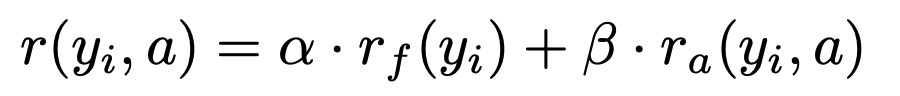
Method: PERCEPTION-R1
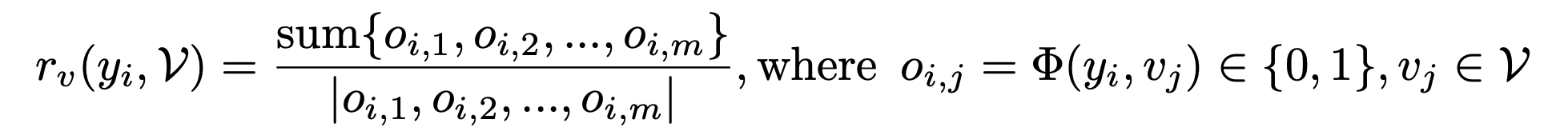
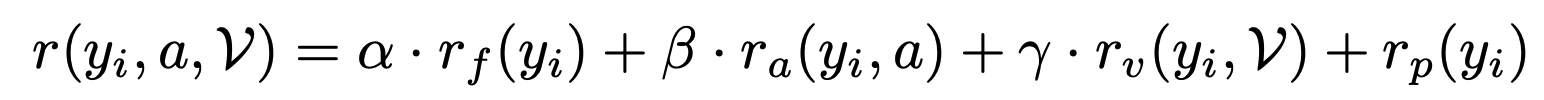
Final reward
r_p is the repetition penalty reward that discourage repetitive behavior during MLLMs’ generation.
How Visual Perception Score Is Computed
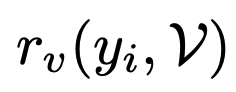
Given image and query, they first prompt frontier LLMs (Gemini2.5 pro to generate reference visual perceptions.
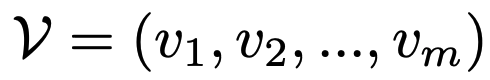
During training, they we use LLM-as-Judge to determine if visual perception above presented in the sampled trajectories y_i.
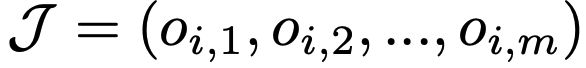
where o_i,j ∈ {0, 1} indicates whether v_j is accurately reflected in y_i or not.
Experiments
Training Dataset: Geometry3K
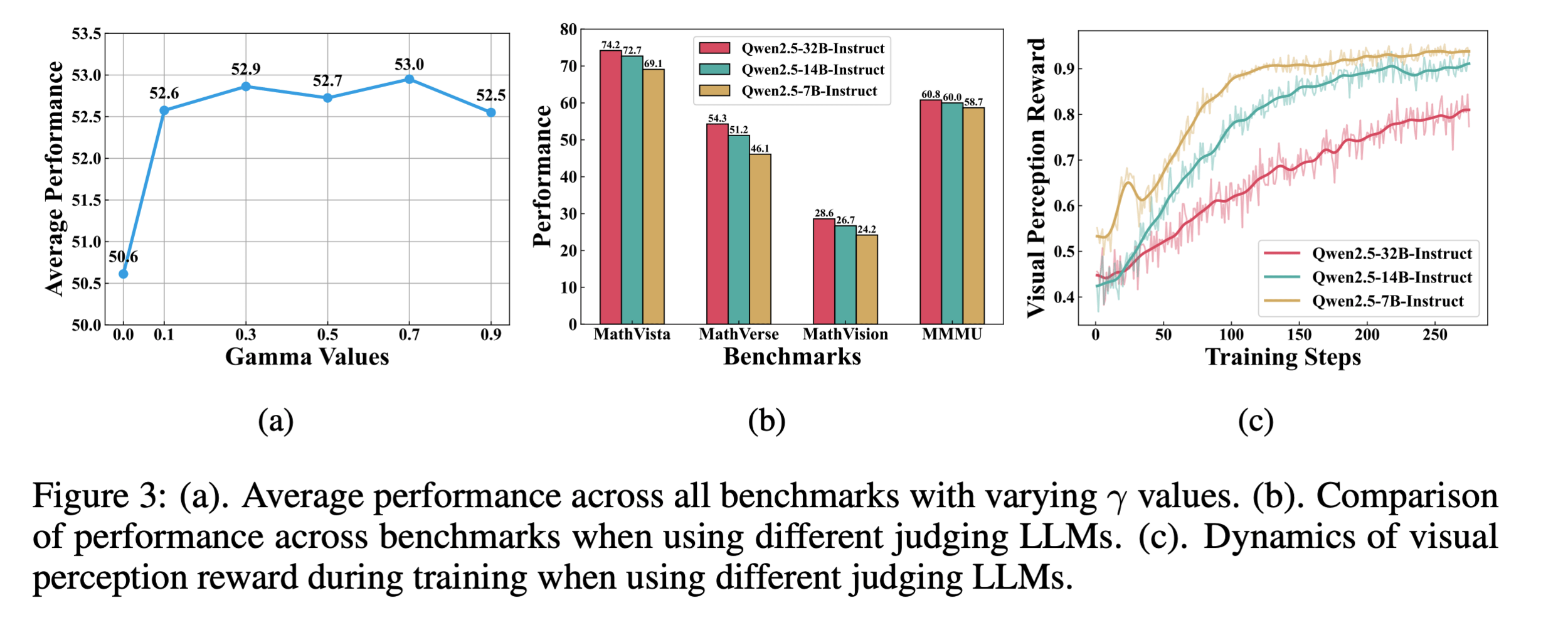
LLM-as-judge model: Qwen2.5-32B-IT
Benchmarks and Evalution Settings: MathVista,
MathVerse, WeMath and more
Training Model: Qwen2-VL-7B-IT
Results
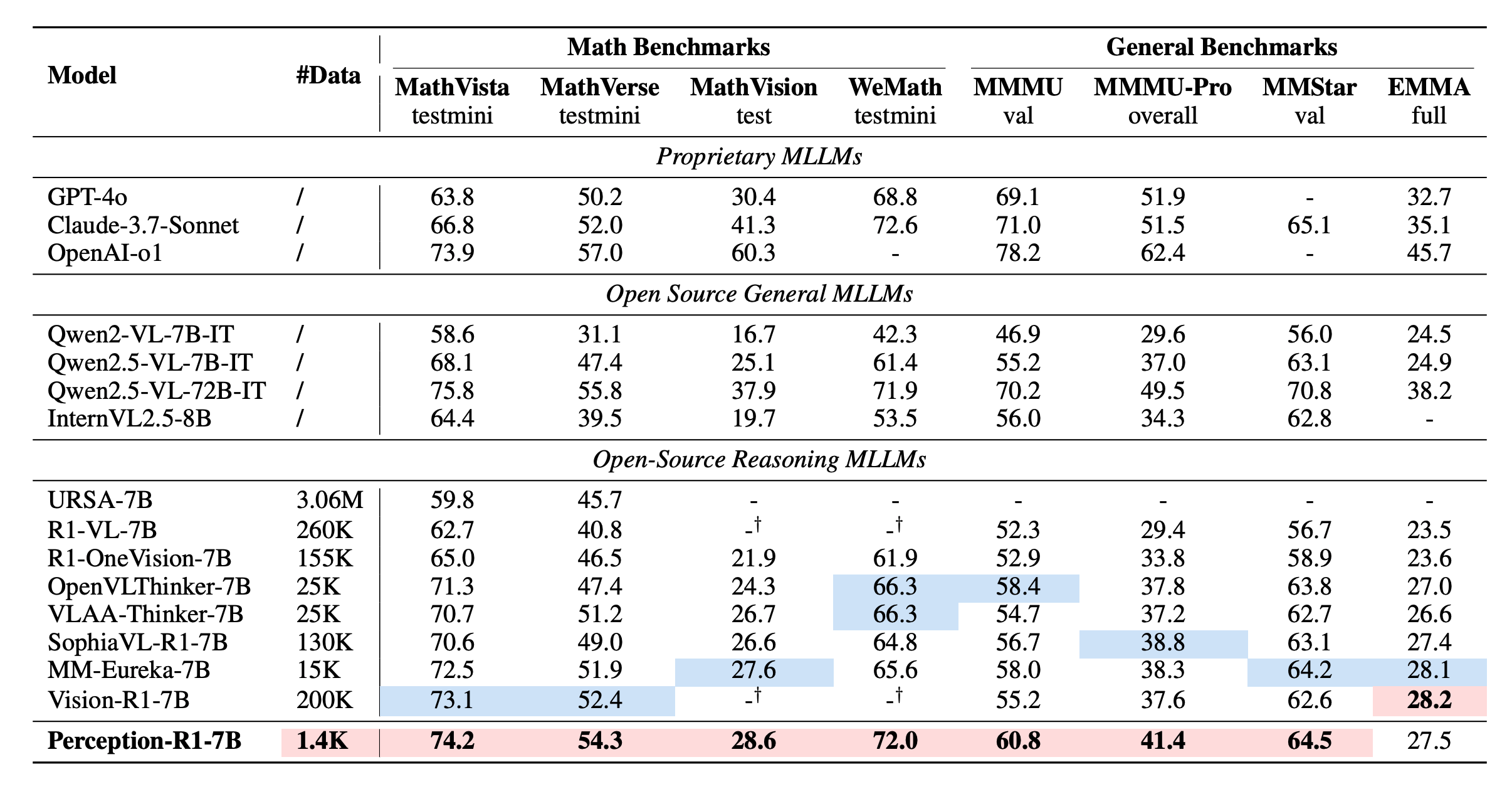
Results
Ablation
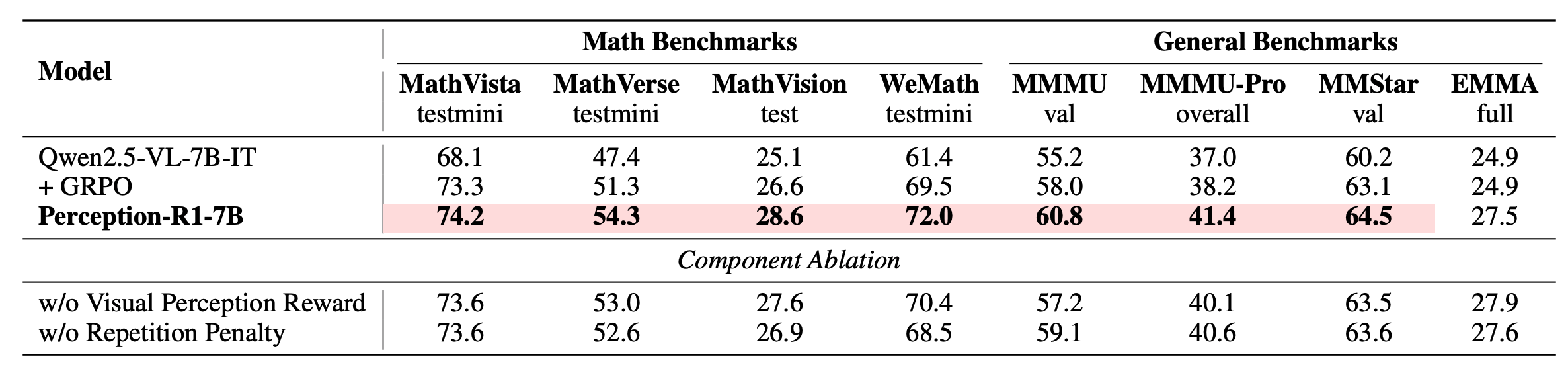
More Ablations
Thx
deck
By Yao



