放學社課-深度學習2
張嘉崴
1. 學期簡介
講師簡介
- 225 張嘉崴
- 資訊社教學
- FB:張嘉崴
1. 學期簡介
1. 學期簡介
課程簡介
每週三 18:00-19:00,遇段考停課
理論為主,實作為輔
Pytorch

1.學期簡介
課程簡介
RNN
CNN
NN
Reinforcement Learning
LSTM
Transformer
課表
1.1 學期簡介
| 時間 | 課程內容 |
|---|---|
| 1-2 | 課程簡介&神經網路&梯度下降&反向傳播 |
| 3-4 | RNN & Transformer |
| 5 | Unsupervised Learning |
| 6-7 | Reinforcement Learning |
| 8 | 傳承 |
能力需求
- Python
- 加法
- 乘法

SoloLearn

1. 學期簡介
能力奢求
- 簡單線性代數
- 微分鏈鎖率
- 認識神經網路

3Blue1Brown
1. 學期簡介
什麼是機器學習?
機器
有用的機器
資料
機器學習
支持向量機
迴歸模型
神經網路
氣溫、濕度
風速、雨量
預測明天股價
1. 學期簡介
什麼是深度學習?
if model.name[-2:] == '網路':
print('深度學習')
else:
print('機器學習')1. 學期簡介
1. 學期簡介
Google colab
1. 學期簡介
來玩吧
2. 乘法&神經網路
2.2 乘法
乘法
我來機器學習,
你給我上乘法??
乘法 \(\rightarrow\) 相似程度
2.2 乘法
怎麼說?
1\times1 = 1
-1\times-1 = 1
1\times-1 = -1
-1\times1 = -1
2.2 乘法
相似程度
\(A=[-2,-1,1,1,1]\)
\(B=[-1,-2,1,1,1]\)
\(C=[2,1,-1,1,-1]\)
\(A \cdot B = 7\)
\(A \cdot C = -6\)
2.2 乘法
圖片相似程度

2.2 乘法
圖片相似程度
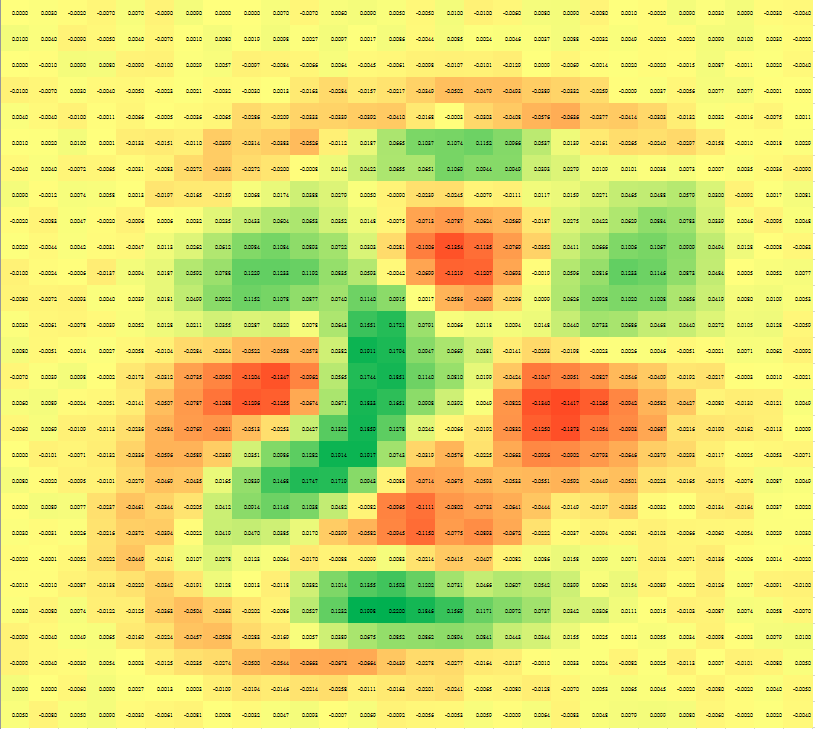
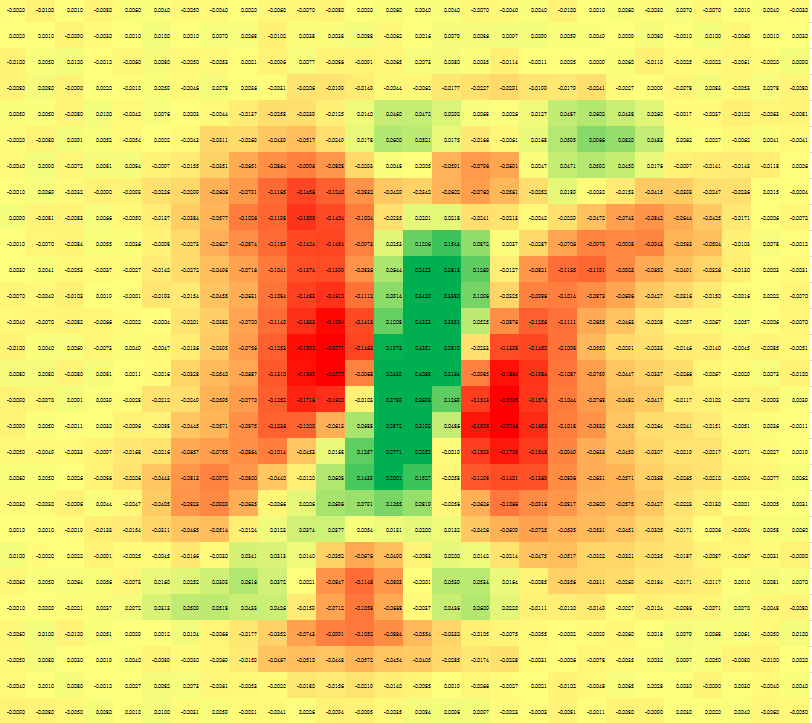

2.2 乘法
圖片相似程度
0.1
1.7
-0.4
-0.5
0.1
-0.2
-0.7
0.9
-1.1
0.3
0.0
0.1
0.4
-0.8
1.9
-0.4
-0.3
-0.1
0.1
1.4
2.2 乘法
1
2
3
4
5
6
7
8
9
\rightarrow
1
2
3
4
5
6
7
8
9
類別0
類別9
類別1
類別5
...
...
2.2 乘法
1
2
3
4
5
6
7
8
9
類別0
類別9
類別1
類別5
...
...
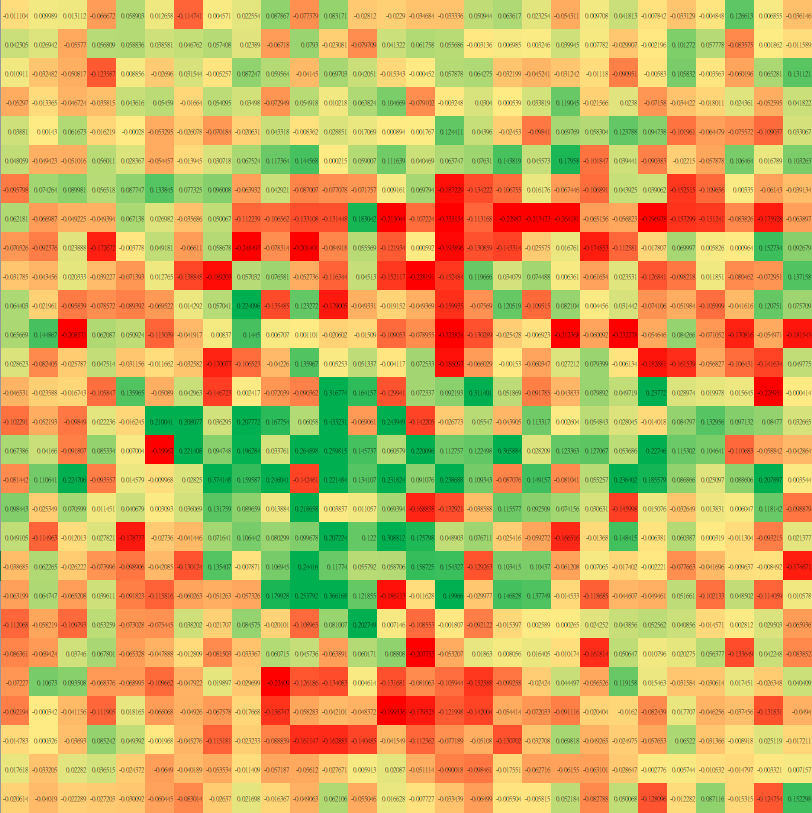
輸入 input
權重 weight
輸出 output
a^{(1)} = W a^{(0)}
2.3 神經網路
幾乎是神經網路
a^{(1)} = W a^{(0)} + b
bias偏值
0.5
0.314
-0.271
-0.8
0.2
-0.1
0.47
-0.6
0.9
0.6
-0.3
-0.3
0.57
0.44
0.38
0.01
0.03
-0.02
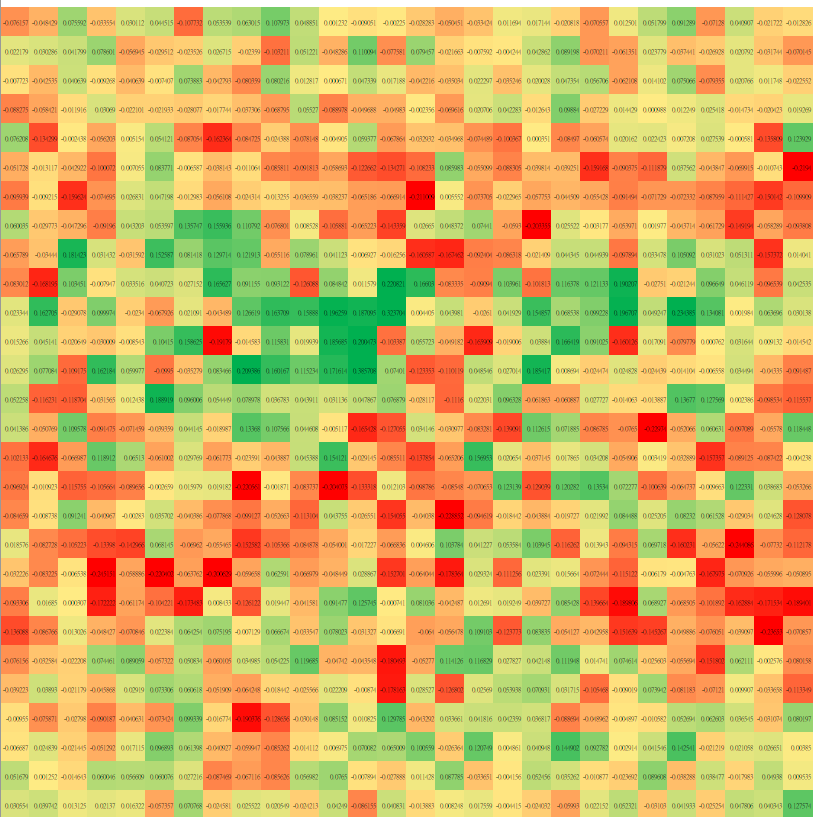
2.3 神經網路
神經網路
a^{(1)} =\sigma ( W a^{(0)} + b)
0.5
0.314
-0.271
-0.8
0.2
-0.1
0.47
-0.6
0.9
0.6
-0.3
-0.3
0.57
0.44
0.38
0.01
0.03
-0.02
\sigma(0.57)
\sigma(0.44)
\sigma(0.38)
2.3 神經網路
\(\sigma\)函數
\sigma(100)\approx1
\sigma(-100)\approx 0
\sigma(0) = 0.5
\sigma(x)=\frac{1}{1+e^{-x}}
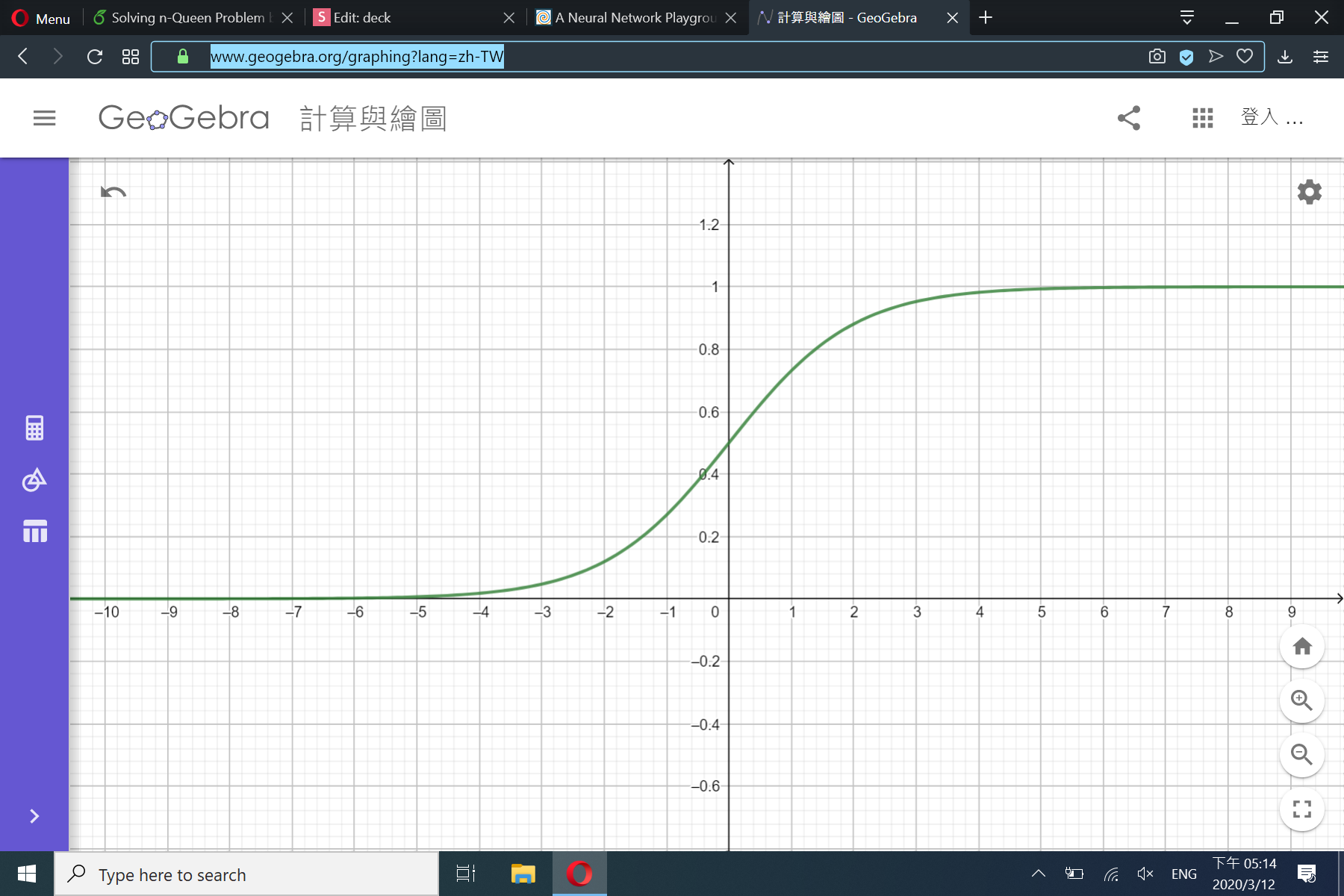
e\approx 2.718
2.3 神經網路
神經網路
- 把圖片變數字
- 做乘法
- 加入偏值
- 放入\(\sigma\)函數
a^{(1)} =\sigma ( W a^{(0)} + b)
2.4 實作
Numpy
import numpy as np
a = np.array([0.1,0.2,0.3])
w = np.array([[0.1,0.2,0.3],[0.4,0.5,0.6],[0.7,0.8,0.9]])
b = np.array([0,0,-1])
print(w@a)
a2 = w@a+b
print(a2)
def sigmoid(x):
return 1 / (1+np.exp(-x))
print(sigmoid(a2))2.5 深度神經網路
深度神經網路
為何要多層?
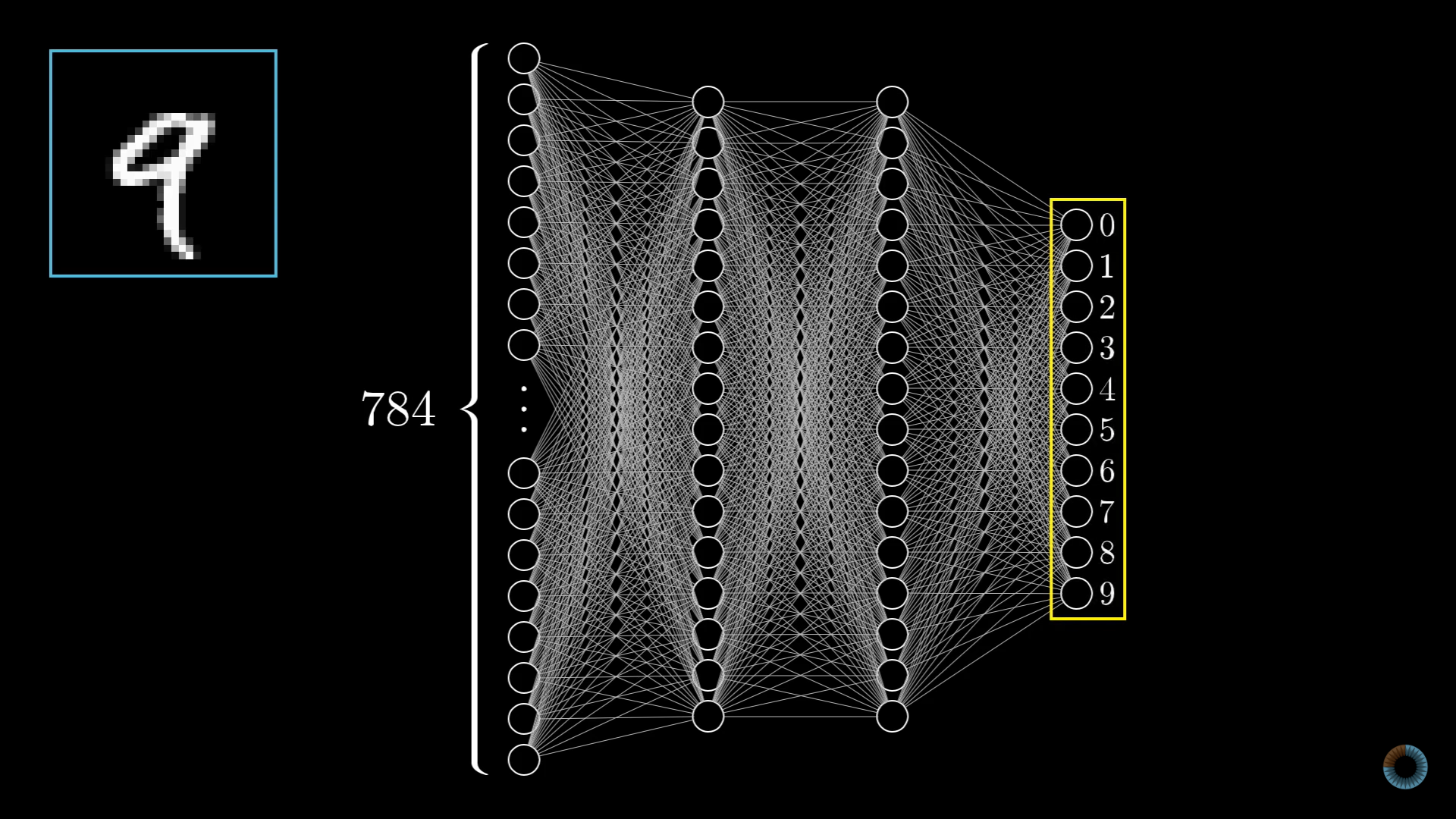
2.5 深度神經網路
為何要多層?
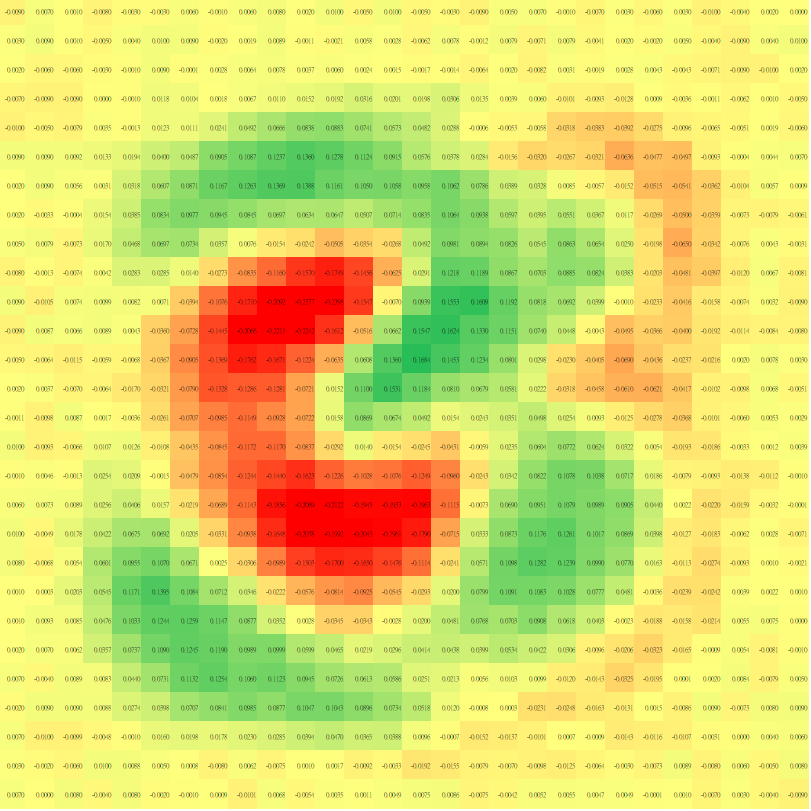
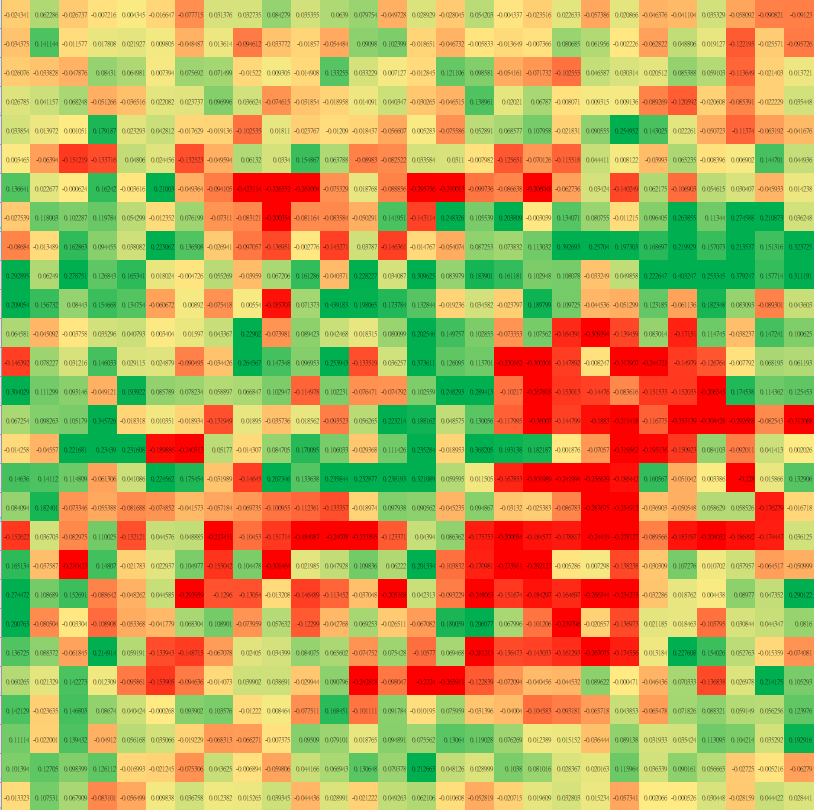
2.5 深度神經網路
為何要多層?
2.5 深度神經網路
為何要多層?
輸入(像素)\(\rightarrow\)簡單特徵(小線段)\(\rightarrow\)複雜特徵(圓圈、直線)\(\rightarrow\)類別
輸入(像素)\(\rightarrow\)類別
2.5 深度神經網路
深度神經網路的數學
2.5 深度神經網路
深度神經網路的數學
a^{(1)}=\sigma(z^{(1)})
z^{(1)} =W^{(1)} a^{(0)} + b^{(1)}
a^{(0)}
a^{(1)}
a^{(2)}
a^{(3)}
a^{(2)}=\sigma(z^{(2)})
z^{(2)} =W^{(2)} a^{(1)} + b^{(2)}
a^{(3)}=\sigma(z^{(3)})
z^{(3)} =W^{(3)} a^{(2)} + b^{(3)}
2.5 深度神經網路
總結
2.6 收尾
深度神經網路
輸入:圖片(像素值)
輸出:類別
參數:權重和偏值們
Numpy Code
2.6 收尾
3. 畢氏定理&Loss
3.1 畢氏定理
一維的情況
\(A(x_0)\,\,B(x_1)\)
\(d(A,B)^2=|x_1-x_0|^2\)
=(x_1-x_0)^2
3.1 畢氏定理
二維的情況
\(A(x_0,y_0)\,\,B(x_1,y_1)\)
\(d(A,B)^2=(x_1-x_0)^2+(y_1-y_0)^2 \)
3.1 畢氏定理
三維的情況
\(A(x_0,y_0,z_0)\,\,B(x_1,y_1,z_1)\)
\(d(A,B)^2=\)
\((x_1-x_0)^2+(y_1-y_0)^2+(z_1-z_0)^2\)
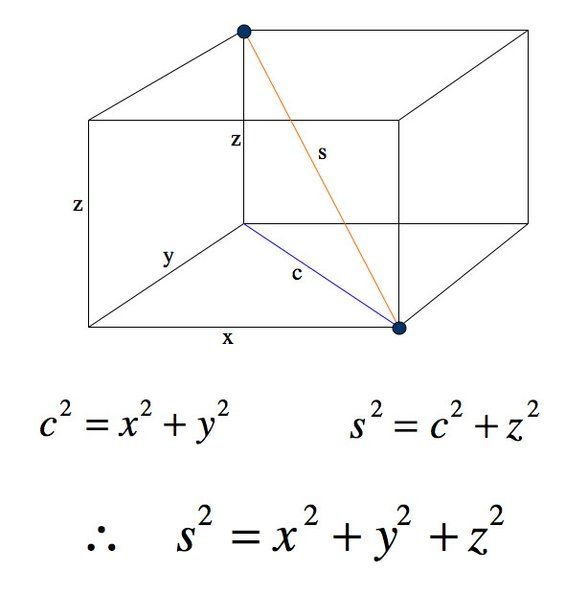
3.1 畢氏定理
\(n\)維的情況
\(A(x_0,y_0,z_0...)\,\,B(x_1,y_1,z_1...)\)
\(d(A,B)^2=\)
\((x_1-x_0)^2+(y_1-y_0)^2+(z_1-z_0)^2+...\)
\(\sum{x^2}\)
3.2 損失函數
問題
3.2 損失函數
損失函數
評估神經網路表現如何
3.2 損失函數
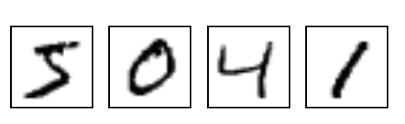
0.0
0.1
0.4
0.8
0.5
0.4
0.3
0.1
0.1
0.9
亞洲父母法
錯!
0.0
0.9
0.1
0.0
0.0
0.2
0.1
0.91
0.1
0.2
錯!
3.2 損失函數
0.0
0.1
0.4
0.8
0.5
0.4
0.3
0.1
0.1
0.9
十維畢氏定理
0.0
0.9
0.1
0.0
0.0
0.2
0.1
0.91
0.1
0.2
0.0
1.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
1.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
距離平方2.14
距離平方0.95
3.2 損失函數
0.0
0.1
0.4
0.8
0.5
0.4
0.3
0.1
0.1
0.9
損失函數
0.0
1.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
0.0
距離平方2.14
\(\sum{(\hat y-y)^2}\)
3.2 損失函數
損失函數應用
[0,...,1,0,0]
[1,...,0,0,0]
[0,...,1,0,0]
[0,...,0,1,0]
...
[0.6,...,0.9,0.1,0.5]
[0.6,...,0.2,0.7,0.3]
[0.1,...,0.2,0.1,0.9]
[0.6,...,0.9,0.1,0.5]
分類手寫數字
找損失函數的最小值
3.2 損失函數
抽象一點
L(\theta)
損失函數:L
輸入:神經網路的所有參數 \(\theta\)
輸出:一個數字(Loss值)
參數:圖片資料庫
3.2 損失函數
函數比較
損失函數
輸入:神經網路的所有參數 \(\theta\)
輸出:一個數字(Loss值)
參數:圖片資料庫
深度神經網路
輸入:圖片資料庫
輸出:類別
參數:神經網路的所有參數\(\theta\)
3.3 實作
實作
def loss_function(output,label):
loss = np.sum((output-label)**2,axis = -1)
all_loss = np.mean(loss)
return all_loss3.4 搜尋空間
簡單一點
y = wx+b
兩個參數、三個維度
3.4 搜尋空間
7850+1維的空間
784個輸入
10個輸出
784X10個權重
10個偏值
3.5 課後
Matplotlib


4. 梯度下降
想像一下

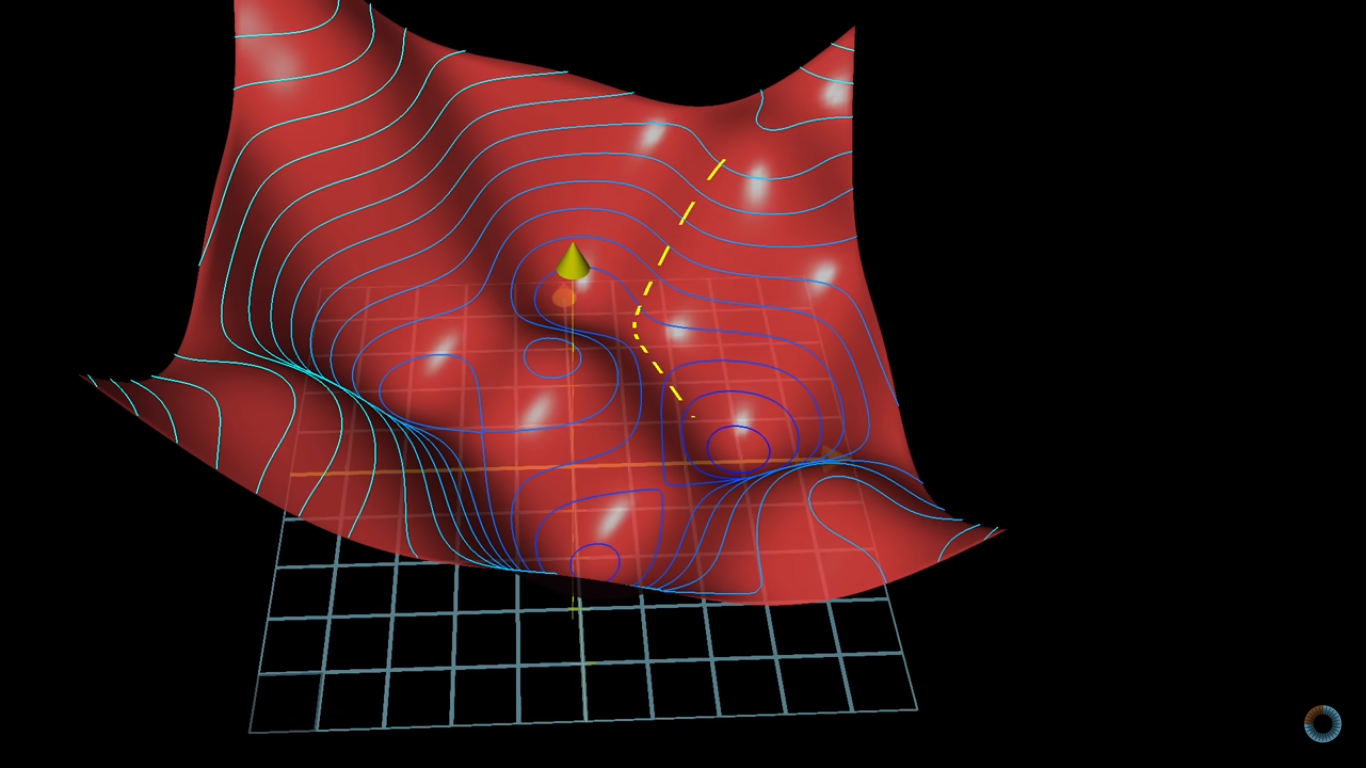
4.1 宏觀的梯度
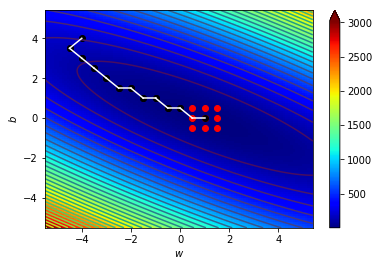

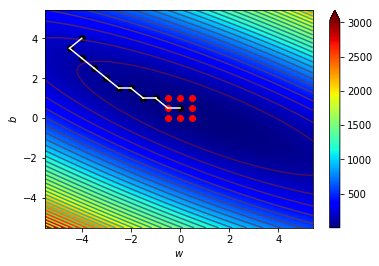
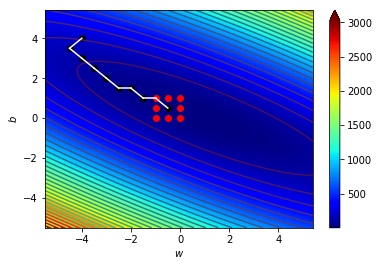
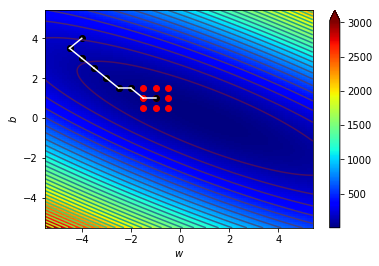
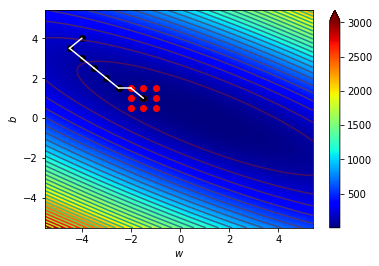
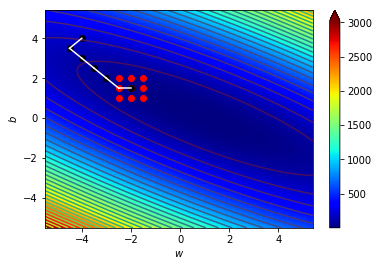
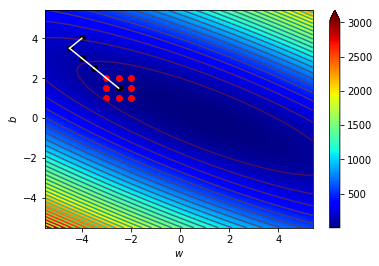
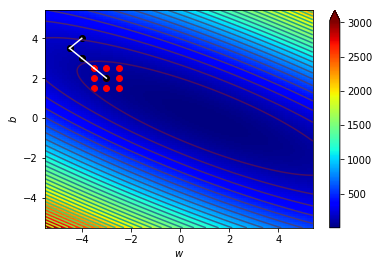
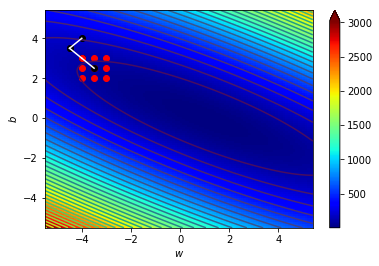
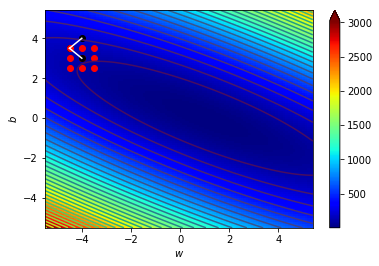
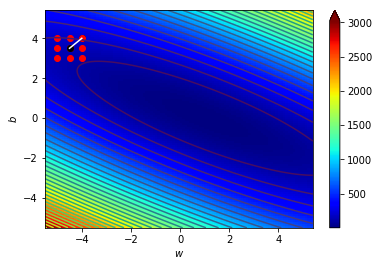
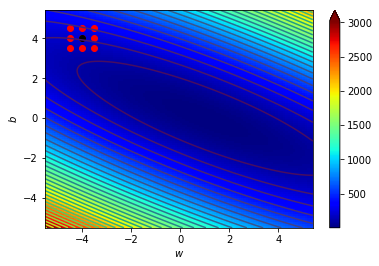
4.1 宏觀的梯度
海拔很高
看不到路
只能感覺腳下坡度
朝最斜的地方走去
神經網路Loss很高
不知道其他地方的Loss
算出梯度
背對該方向走去
4.1 宏觀的梯度
4.2 梯度
梯度
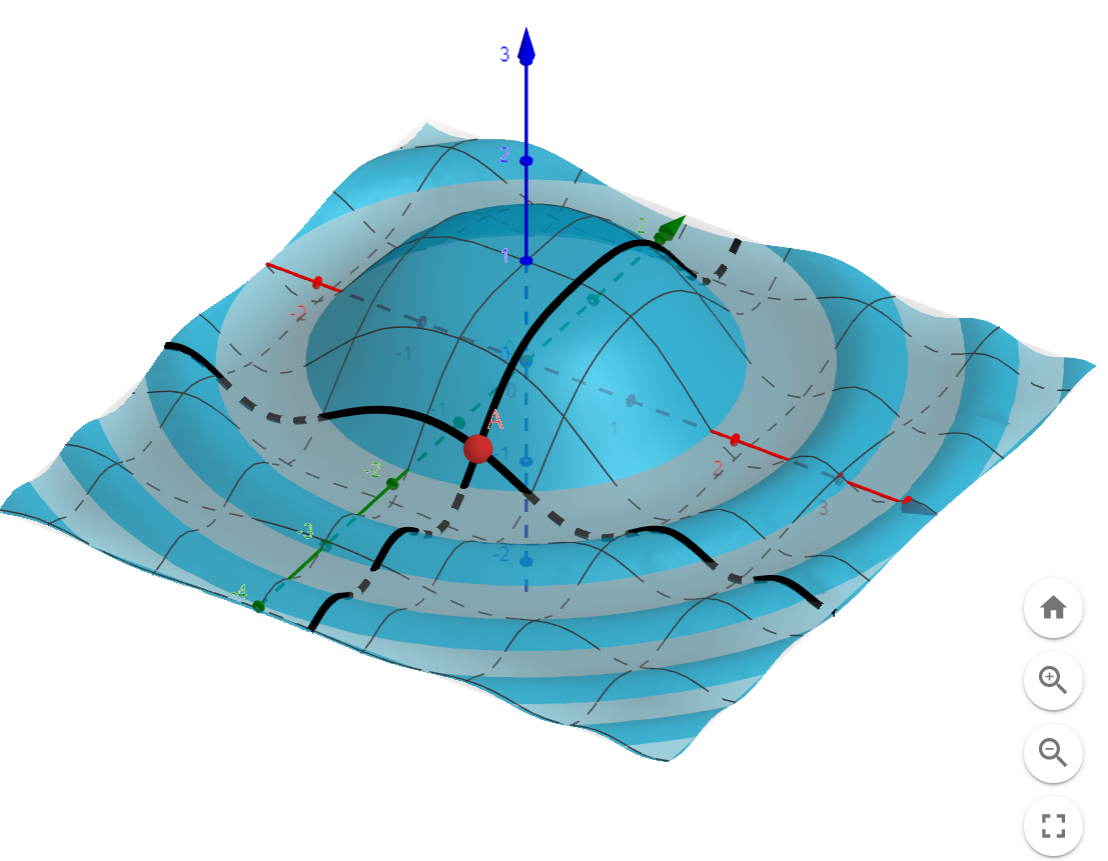
點A的x方向斜率為-0.416
點A的y方向斜率為1.248
\nabla_{f(x,y)} = \langle-0.416,1.248\rangle
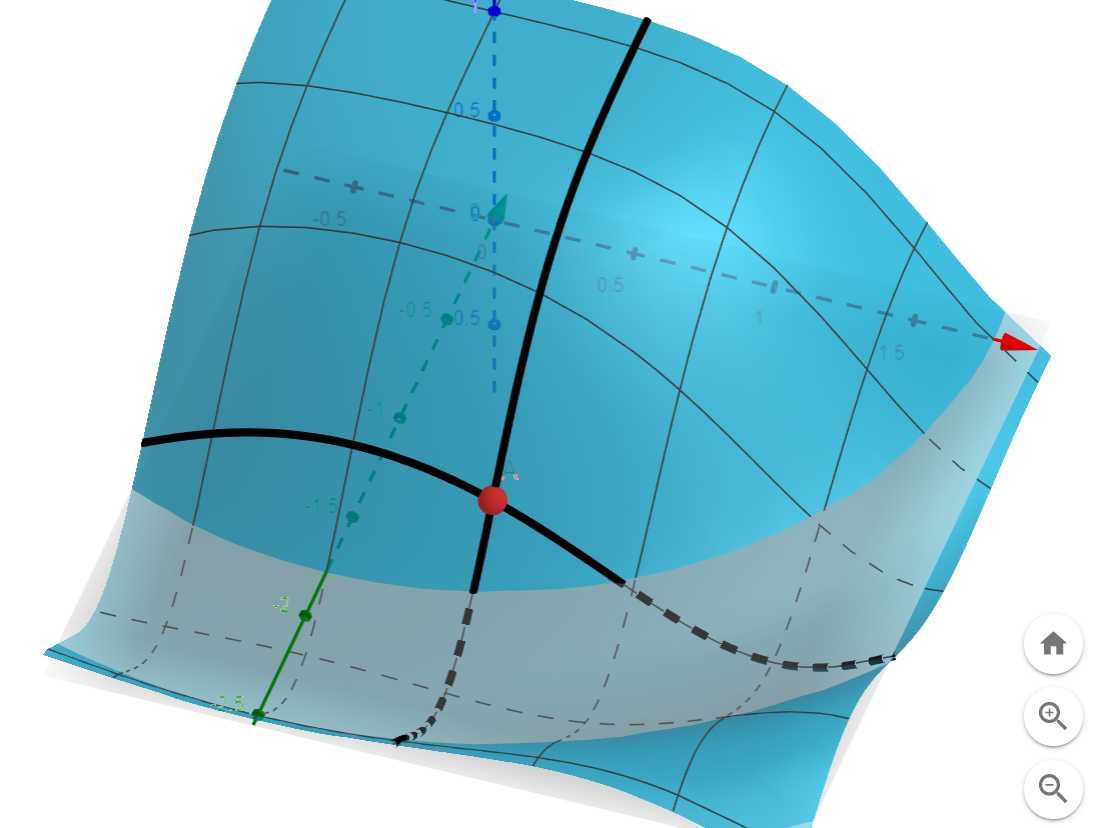
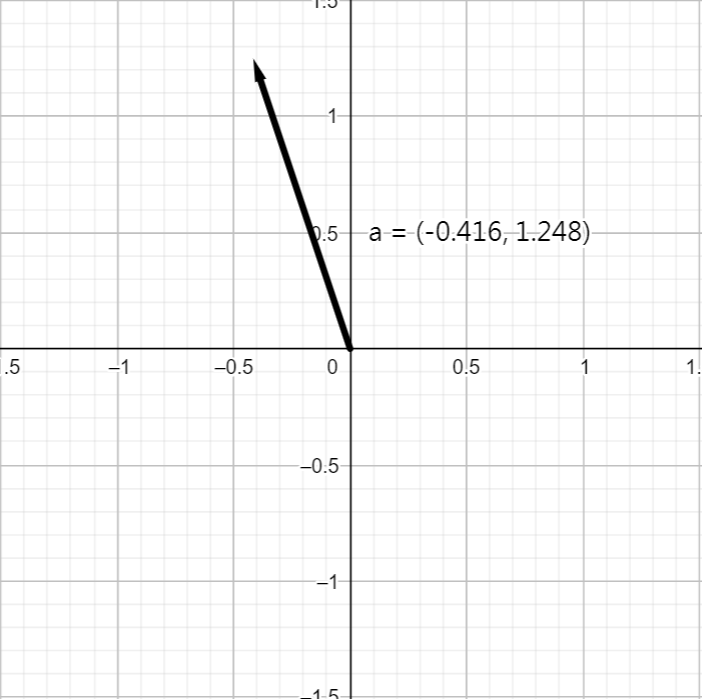
f(x,y)
\langle \frac{\partial f}{\partial x},\frac{\partial f}{\partial y}\rangle
4.2 梯度
梯度
往梯度方向走,上升最快
往負梯度方向走,下降最快
x \leftarrow x - \frac{\partial}{\partial x}
y \leftarrow y - \frac{\partial}{\partial y}
x \leftarrow x - \mu\frac{\partial}{\partial x}
y \leftarrow y - \mu\frac{\partial}{\partial y}
4.2 梯度
神經網路的梯度
7000多維的山?
y = \sigma(wa+b)
2個參數 \(\rightarrow\) 3維的山
(w,b,L)
4.3 微觀的梯度
7000多維的山
把每個變數想成一個滑桿
4.3 微觀的梯度
神經網路的梯度
把梯度想成敏感度
4.4 梯度計算
Warning

4.4 梯度計算
神經網路計算樹
a^{(2)}
w^{(2)}
b^{(2)}
a^{(1)}
w^{(1)}
a^{(0)}
b^{(1)}
L
y
a^{(3)}
b^{(3)}
w^{(3)}
神經網路計算樹
a^{(2)}
L
y
a^{(3)}
b^{(3)}
w^{(3)}
4.4 梯度計算
a^{(2)}
L
y
a^{(3)}
b^{(3)}
w^{(3)}
z^{(3)}
神經網路計算樹
4.4 梯度計算
a^{(2)}
L
y
a^{(3)}
b^{(3)}
w^{(3)}
z^{(3)}
求\(w^{(3)}\)對\(L\)的靈敏度
\(w^{(3)}\) 對\(z^{(3)}\)的靈敏度
\(z^{(3)}\) 對\(a^{(3)}\)的靈敏度
\(a^{(3)}\) 對\(L\)的靈敏度
\times
\times
\frac{\partial L}{\partial w^{(3)}}
\frac{\partial z^{(3)}}{\partial w^{(3)}}
\frac{\partial a^{(3)}}{\partial z^{(3)}}
\frac{\partial L}{\partial a^{(3)}}
鏈鎖率
4.4 梯度計算
a^{(2)}
L
y
a^{(3)}
b^{(3)}
w^{(3)}
z^{(3)}
\frac{\partial L}{\partial w^{(3)}}
\frac{\partial z^{(3)}}{\partial w^{(3)}}
\frac{\partial a^{(3)}}{\partial z^{(3)}}
\frac{\partial L}{\partial a^{(3)}}
=
\frac{\partial L}{\partial b^{(3)}}
\frac{\partial z^{(3)}}{\partial b^{(3)}}
\frac{\partial a^{(3)}}{\partial z^{(3)}}
\frac{\partial L}{\partial a^{(3)}}
=
\frac{\partial L}{\partial a^{(2)}}
\frac{\partial z^{(3)}}{\partial a^{(2)}}
\frac{\partial a^{(3)}}{\partial z^{(3)}}
\frac{\partial L}{\partial a^{(3)}}
=
鏈鎖率
4.4 梯度計算
\frac{\partial L}{\partial a^{(2)}}
\frac{\partial z^{(3)}}{\partial a^{(2)}}
\frac{\partial a^{(3)}}{\partial z^{(3)}}
\frac{\partial L}{\partial a^{(3)}}
=
a^{(2)}
w^{(2)}
b^{(2)}
a^{(1)}
w^{(1)}
a^{(0)}
b^{(1)}
L
y
a^{(3)}
b^{(3)}
w^{(3)}
\frac{\partial L}{\partial w^{(2)}}
\frac{\partial z^{(2)}}{\partial w^{(2)}}
\frac{\partial a^{(2)}}{\partial z^{(2)}}
\frac{\partial L}{\partial a^{(2)}}
=
\frac{\partial L}{\partial a^{(1)}}
\frac{\partial z^{(2)}}{\partial a^{(1)}}
\frac{\partial a^{(2)}}{\partial z^{(2)}}
\frac{\partial L}{\partial a^{(2)}}
=
4.4 梯度計算
多神經元的梯度
\frac{\partial L}{\partial a_0^{(1)}}
\frac{\partial L}{\partial a_2^{(1)}}
\frac{\partial L}{\partial a_1^{(1)}}
a_0^{(0)}
a_1^{(0)}
a_2^{(0)}
a_3^{(0)}
w_{ij}^{(1)}
i
j
\frac{\partial L}{\partial w_{12}^{(1)}}
=
\frac{\partial L}{\partial a_0^{(1)}}
\frac{\partial a_0^{(1)}}{\partial w_{12}^{(1)}}
\frac{\partial L}{\partial b_{1}^{(1)}}
=
\frac{\partial L}{\partial a_0^{(1)}}
\frac{\partial a_0^{(1)}}{\partial b_{1}^{(1)}}
\frac{\partial L}{\partial a_{1}^{(0)}}
=
?
4.4 梯度計算
多神經元的梯度
\frac{\partial L}{\partial a_0^{(1)}}
\frac{\partial L}{\partial a_2^{(1)}}
\frac{\partial L}{\partial a_1^{(1)}}
a_0^{(0)}
a_1^{(0)}
a_2^{(0)}
a_3^{(0)}
w_{ij}^{(1)}
i
j
\frac{\partial L}{\partial a_0^{(1)}}
\frac{\partial a_0^{(1)}}{\partial a_{1}^{(0)}}
\frac{\partial L}{\partial a_{1}^{(0)}}
=
\frac{\partial L}{\partial a_1^{(1)}}
\frac{\partial a_1^{(1)}}{\partial a_{1}^{(0)}}
\frac{\partial L}{\partial a_2^{(1)}}
\frac{\partial a_2^{(1)}}{\partial a_{1}^{(0)}}
深度學習精隨
4.5 梯度下降
w^{(3)}\leftarrow w^{(3)} - \mu \frac{\partial L}{\partial w^{(3)}}
\theta \leftarrow \theta - \mu \nabla L(\theta)
4.5 梯度下降
3Blue1Brown
4.6 課後
Pytorch -tensor
4.6 課後
Pytorch
def loss_func(out,lbl):
loss = torch.sum((out-lbl)**2,axis = -1)
all_loss = torch.mean(loss,axis = -1)
return all_loss
learning_rate = 0.1
out = torch.tensor([[0.1,0.1,0.1],[0.1,1.0,0.1]],requires_grad = True)
lbl = torch.tensor([[1.0,0.0,0.0],[0.0,1.0,0.0]],requires_grad = True)
L = loss_func(out,lbl)
print(L)
L.backward()
out = out - learning_rate * out.grad
out.grad = None
lbl.grad = None
L = loss_func(out,lbl)
print(L)5. 遞迴神經網路
5.1 任務
名字語源
Suzuki
Chang
Rahmaninov
Wolfeschlegelsteinhausenbergerdorff ???
Chinese
Japanese
Russian
5.1 任務
加法
"1+1"
"12+345"
"2"
"357"
"314159265358979323+2718281828459045"???
"1+999999999999999999999999"???
5.2 遞迴神經網路
遞迴神經網路RNN
RNN
記憶、輸入
記憶
輸出
5.2 遞迴神經網路
遞迴神經網路RNN
RNN
RNN
RNN
5.2 遞迴神經網路
遞迴神經網路RNN
Chinese
h
C
g
n
a
RNN
Chang
5.2 遞迴神經網路
輸入
a:[1,0,0...,0]
\\
b:[0,1,0...,0]
\\
...
\\
z:[0,0,0...,1]
全連接層
5.2 遞迴神經網路
RNN內部架構
h_0
x
h_1
W
h_1
W'
y
h_1 = f_0( W \begin{bmatrix}h_0\\x\end{bmatrix} )
y = f_1(W'h_1)
\(f_0,f_1\)為激勵函數
5.2 遞迴神經網路
名字語源
國小加法
5.3 Seq2seq
Seq2seq
Encoder
'+'
'8'
'9'
記憶
Encoder
Encoder
5.3 Seq2seq
Seq2seq
Decoder
'1'
'<sos>'
'7'
Decoder
Decoder
記憶
Start Of Sequence
'1'
'7'
'<eos>'
End Of Sequence
5.3 seq2seq
名字語源
國小加法
5.4 RNN的問題
梯度消失&梯度爆炸
h_0
x
h_1
W
h_1
W'
y
h_1 = f_0( W \begin{bmatrix}h_0\\x\end{bmatrix} )
\frac{\partial h_1}{\partial h_0} = W(...)
\frac{\partial h_2}{\partial h_0} = W^2(...)
\frac{\partial h_{10}}{\partial h_0} = W^{10}(...)
5.4 RNN的問題
解決方法
- Gradient Clipping
- Long Short Term Memory(LSTM)
- Transformer
5.5 實作
RNN NAME
6. Transformer
7. value based rl
8. Policy based rl
Copy of 放課 深度學習 2
By yennnn


