Чтение по губам для украинского языка
Костров Евгений
Что это?

Что это?
Чтение по губам - процесс использования только визуальной информации о движении губ для преобразования речи в текст
Области применения
- Помощь слабослышащим людям
Области применения
- Помощь слабослышащим людям
- Распознавание речи в шумных пространствах
Области применения
- Помощь слабослышащим людям
- Распознавание речи в шумных пространствах
- Идентификация говорящего
Области применения
- Помощь слабослышащим людям
- Распознавание речи в шумных пространствах
- Идентификация говорящего
- Автоматическая синхронизация аудио и видео
Области применения
- Помощь слабослышащим людям
- Распознавание речи в шумных пространствах
- Идентификация говорящего
- Автоматическая синхронизация аудио и видео
- Беззвучная диктовка текста
Области применения
- Помощь слабослышащим людям
- Распознавание речи в шумных пространствах
- Идентификация говорящего
- Автоматическая синхронизация аудио и видео
- Беззвучная диктовка текста
- Субтитры к немому кино
Области применения
- Помощь слабослышащим людям
- Распознавание речи в шумных пространствах
- Идентификация говорящего
- Автоматическая синхронизация аудио и видео
- Беззвучная диктовка текста
- Субтитры к немому кино
- Субтитры с границами каждого слова
Области применения
- Помощь слабослышащим людям
- Распознавание речи в шумных пространствах
- Идентификация говорящего
- Автоматическая синхронизация аудио и видео
- Беззвучная диктовка текста
- Субтитры к немому кино
- Субтитры с границами каждого слова
- Шпионские истории
Сложности
- Омофемы (homophemes) - слова, которые звучат по разному, но включают в себя идентичные движения губами
Сложности
- Омофемы (homophemes) - слова, которые звучат по разному, но включают в себя идентичные движения губами
- Отсутствие наборов данных
Сложности
- Омофемы (homophemes) - слова, которые звучат по разному, но включают в себя идентичные движения губами
- Отсутствие наборов данных
- Вариации произношения (акценты, скорость речи, бормотание)
Сложности
- Омофемы (homophemes) - слова, которые звучат по разному, но включают в себя идентичные движения губами
- Отсутствие наборов данных
- Вариации произношения (акценты, скорость речи, бормотание)
- Ухудшение картинки (плохое освещение, сильные тени, движение, разрешение, ракурс и т.д.)
Данные
- Собраны с 15 каналов на ютубе
-
До обработки:
- 2300 видео
- ~ 10 дней
-
После обработки:
- 470 видео
- ~ 27 часов

- 4x1060 3Gb
- core i7 3770 @ 3.40GHz × 8
- 32 GB RAM
Работа с данными
Работа с данными

Скачивание

Разрезание

Формат данных

Фильтрация

Фильтрация
-
Чистка текста:
- фильтрация по языку
- текст в скобках
- ударения
- римские цифры в пропись
- спецсимволы
Фильтрация
- Чистка текста:
- фильтрация по языку
- текст в скобках
- ударения
- римские цифры в пропись
- спецсимволы
- Фильтрация по длительности отрезка
Фильтрация
- Чистка текста:
- фильтрация по языку
- текст в скобках
- ударения
- римские цифры в пропись
- спецсимволы
- Фильтрация по длительности отрезка
- Фильтрация по распределению
Фильтрация по распределению

Фильтрация по распределению

Фильтрация по распределению

Извлечение лиц

Извлечение лиц
- Нормализация фреймрейта
Извлечение лиц
- Нормализация фреймрейта
- Определение лица на каждом фрейме
Детекция лиц
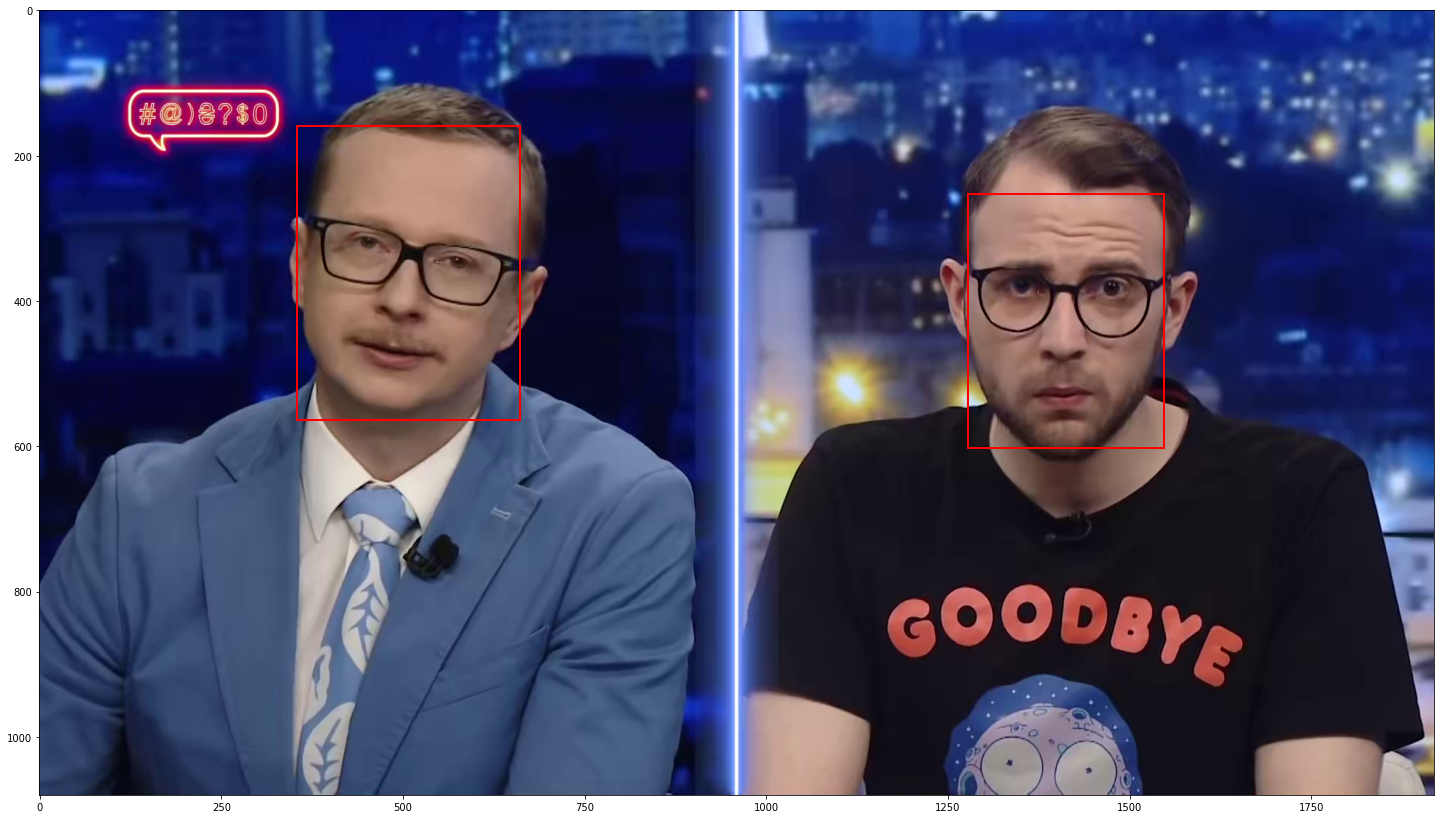
*Multi-task Cascaded Convolutional Networks
Извлечение лиц
- Нормализация фреймрейта
- Определение лица на каждом фрейме
- фильтрация, если лиц больше одного
Извлечение лиц
- Нормализация фреймрейта
- Определение лица на каждом фрейме
- фильтрация, если лиц больше одного
- Вырезание области лица
Вырезание лиц

Извлечение лиц
- Нормализация фреймрейта
- Определение лица на каждом фрейме
- фильтрация, если лиц больше одного
- Вырезание области лица
- Масштабирование до 112х112
Извлечение лиц
- Нормализация фреймрейта
- Определение лица на каждом фрейме
- фильтрация, если лиц больше одного
- Вырезание области лица
- Масштабирование до 112х112
- Нахождение ключевых точек
Ключевые точки

*The Face Alignment Network (FAN)
Ключевые точки

Извлечение лиц
- Нормализация фреймрейта
- Определение лица на каждом фрейме
- фильтрация, если лиц больше одного
- Вырезание области лица
- Масштабирование до 112х112
- Нахождение ключевых точек
- Определение активности
Определение активности

Определение активности

Извлечение лиц
- Нормализация фреймрейта
- Определение лица на каждом фрейме
- фильтрация, если лиц больше одного
- Вырезание области лица
- Масштабирование до 112х112
- Нахождение ключевых точек
- Определение активности
- Преобразование в оттенки серого
Упаковка в TFRecord

Чтение TFRecord
Случайные аугментации:
- Отражение по горизонтали
- Изменение яркости
- Изменение контраста
- Изменение качества JPEG
- Поворот
- Cutout
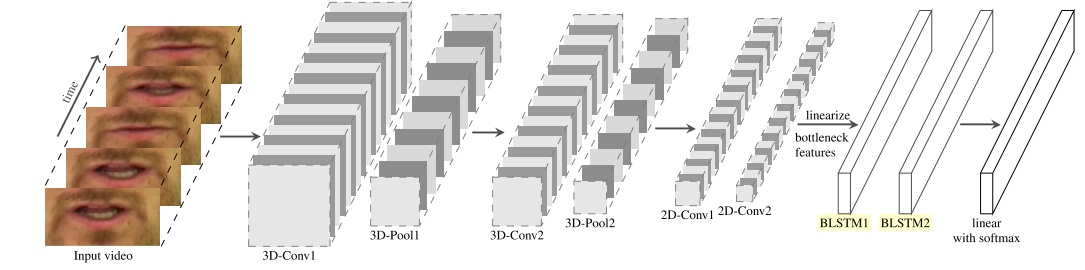
Модель
3D-2D-CNN BLSTM with character CTC
LipReading with 3D-2D-CNN BLSTM-HMM and word-CTC model - https://arxiv.org/abs/1906.12170
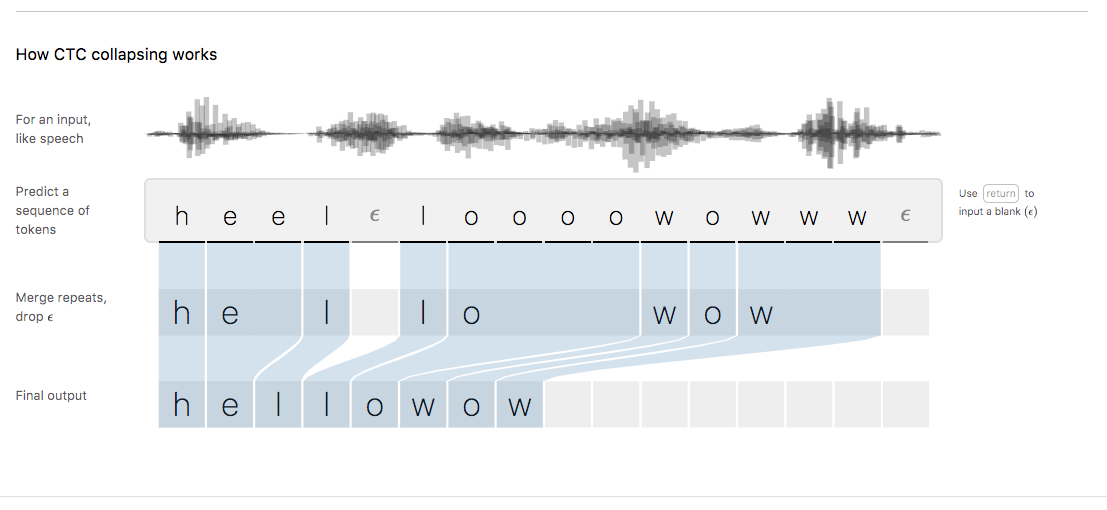
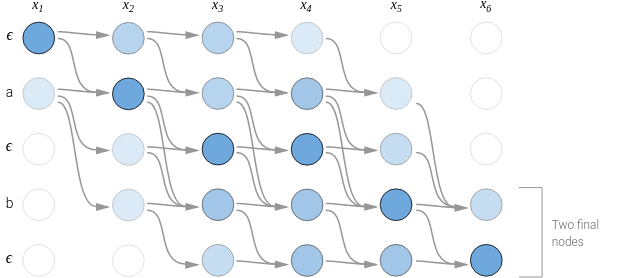
CTC Loss
*Connectionist Temporal Classification: Labelling Unsegmented Sequence Data with Recurrent Neural Networks
CTC Loss
Метрика
Character Error Rate:
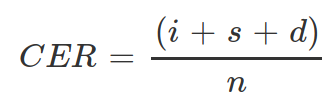
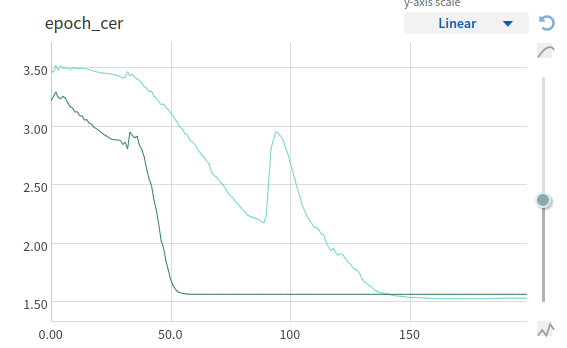
LSTM vs Conv1d (TC)
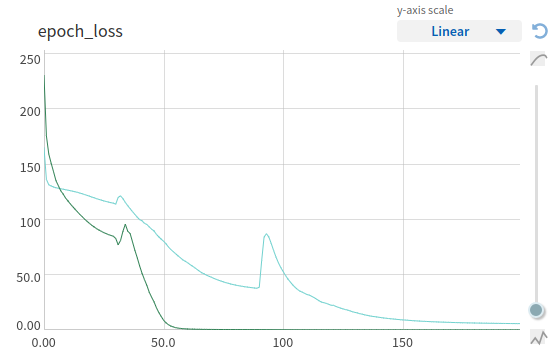
LSTM vs Conv1d (TC)
Архитектура
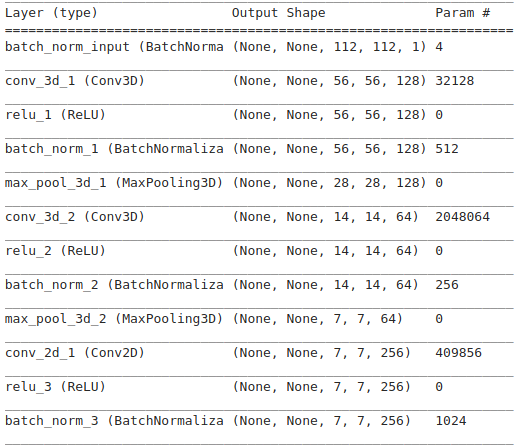
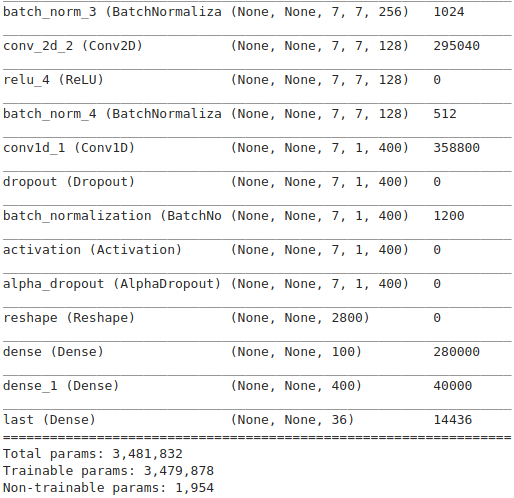
Архитектура
model.add(Input(shape=(None, 112, 112, 1), name="input"))
model.add(BatchNormalization(name="batch_norm_input"))
model.add(Conv3D(128, (10, 5, 5), strides=(1, 2, 2), padding="same", name="conv_3d_1", kernel_initializer=he_normal(seed=SEED)))
model.add(ReLU(name="relu_1"))
model.add(BatchNormalization(name="batch_norm_1"))
model.add(MaxPooling3D(pool_size=(1, 2, 2), strides=(1, 2, 2), padding="valid", name="max_pool_3d_1"))
model.add(Conv3D(64, (10, 5, 5), strides=(1, 2, 2), padding="same", name="conv_3d_2", kernel_initializer=he_normal(seed=SEED)))
model.add(ReLU(name="relu_2"))
model.add(BatchNormalization(name="batch_norm_2"))
model.add(MaxPooling3D(pool_size=(1, 2, 2), strides=(1, 2, 2), padding="valid", name="max_pool_3d_2"))
model.add(Conv2D(256, (5, 5), strides=(1, 1), padding="same", name="conv_2d_1", kernel_initializer=he_normal(seed=SEED)))
model.add(ReLU(name="relu_3"))
model.add(BatchNormalization(name="batch_norm_3"))
model.add(Conv2D(128, (3, 3), strides=(1, 1), padding="same", name="conv_2d_2", kernel_initializer=he_normal(seed=SEED)))
model.add(ReLU(name="relu_4"))
model.add(BatchNormalization(name="batch_norm_4"))
channels = 7
model.add(Conv1D(filters=400, kernel_size=7, strides=1, name="conv1d_1", kernel_initializer='lecun_normal'))
model.add(Dropout(0.2, noise_shape=(channels, 1, 400)))
model.add(BatchNormalization(scale=False))
model.add(Activation('selu'))
model.add(AlphaDropout(0.1))
model.add(Reshape((-1, model.output_shape[2]*model.output_shape[3]*model.output_shape[4]), name="reshape"))
model.add(Dense(100, activation='relu', use_bias=False, kernel_initializer='he_normal'))
model.add(Dense(400, activation='sigmoid', use_bias=False, kernel_initializer='he_normal'))
model.add(Dense(36, name="last"))Оптимизатор
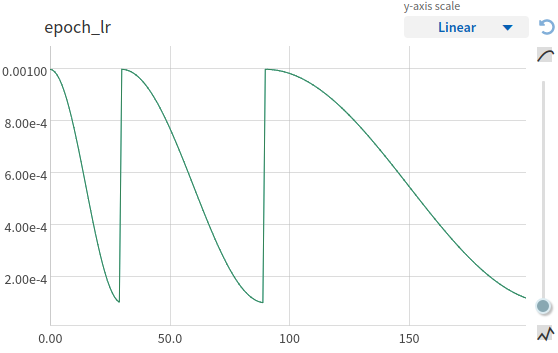
Adam, lr=1e3
Предтренировка
Curriculum Learning подход
- 10 эпох сортированных данных
- 5 эпох сортированных батчей в окне
- батчи в случайном порядке
Результаты, но не те
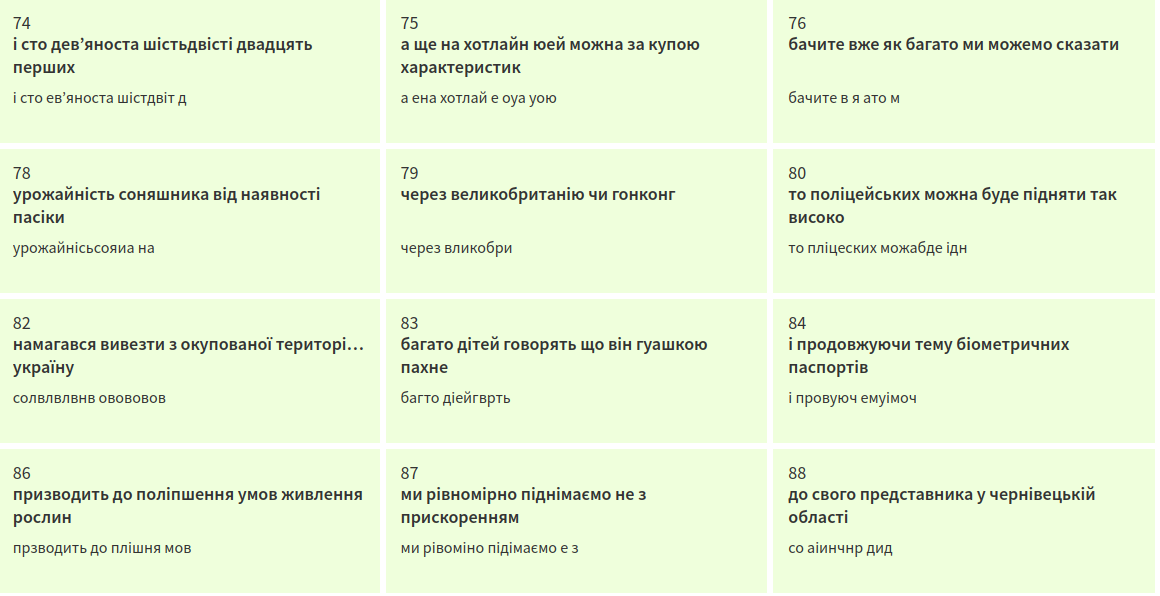
Результаты на данный момент

Ukrainian lip reading
By __



