HiAGM: hierarchy-aware global model for hierarchical text classification
yuan meng
nv search dsml

- hierarchical: labels represented as taxonomy tree
- multi-label: text may map to multiple paths
hierarchical text classification
as opposed to flat
doordash use case
query-to-taxonomy classification
"chicken"
"Pet Care"
"Meat & Poultry"
"Cats"
"Dogs"
"Cat Food"
"Dry Cat Food"
"Wet Cat Food"
L1
L2
L3
L4
- multi-label: queries can have multiple intents
- hierarchical: products and brands have taxonomy structure
"Poultry"
"Chicken"
"Chicken Breast"
"Chicken Thigh"
what information is missing?
- structural information: e.g., if parent is most likely "News", children are less likely "Books"
- text semantic information: e.g., "book" in input is semantically related to label "Books"
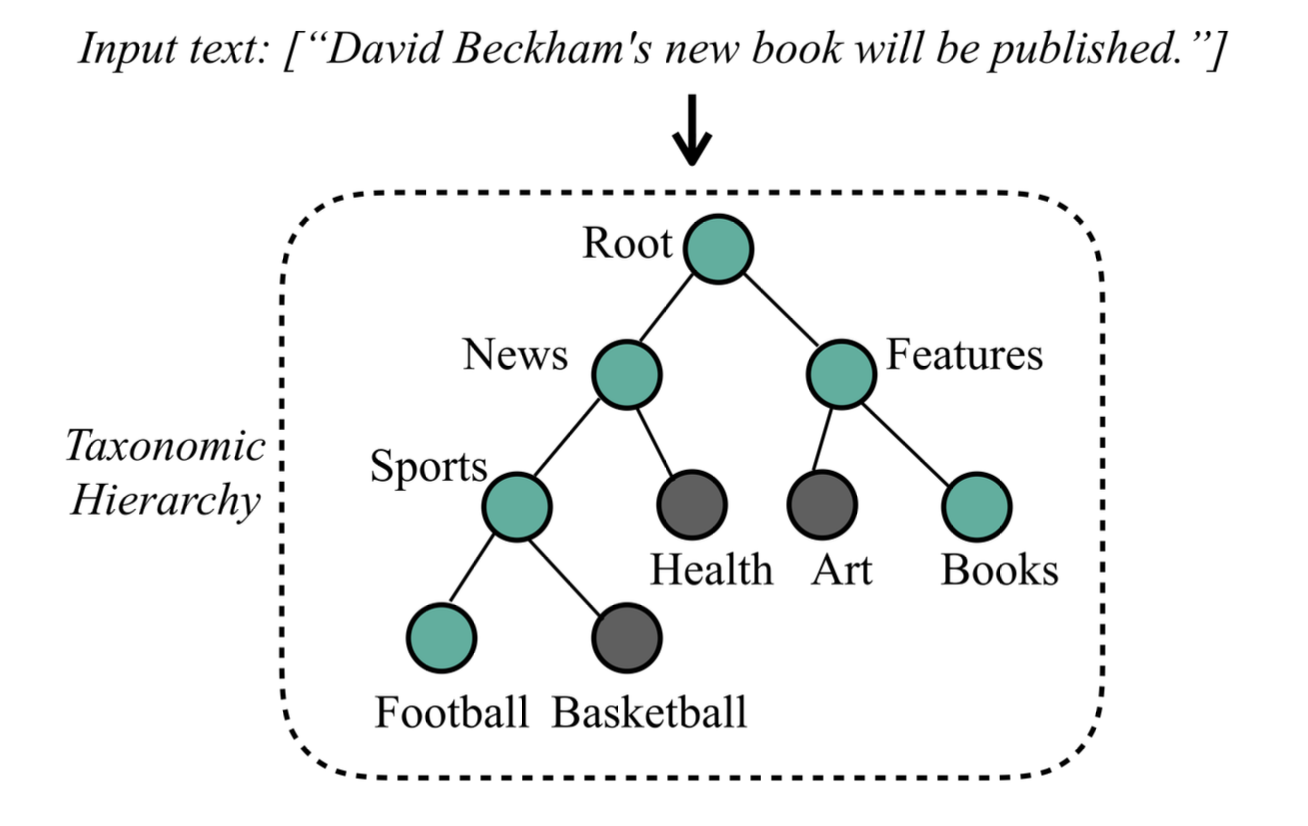
why not? 🤔
traditional: local classifiers
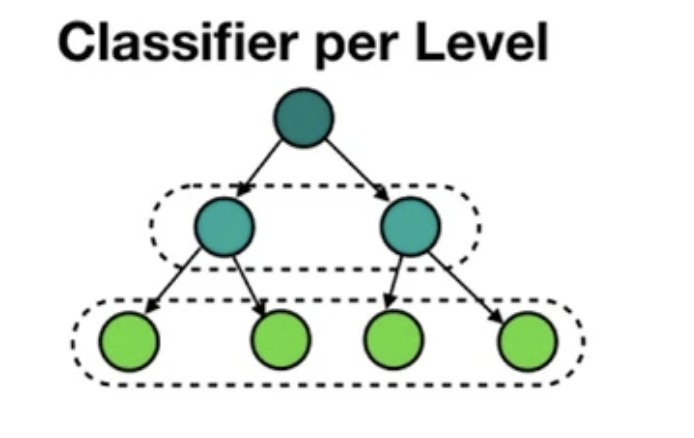
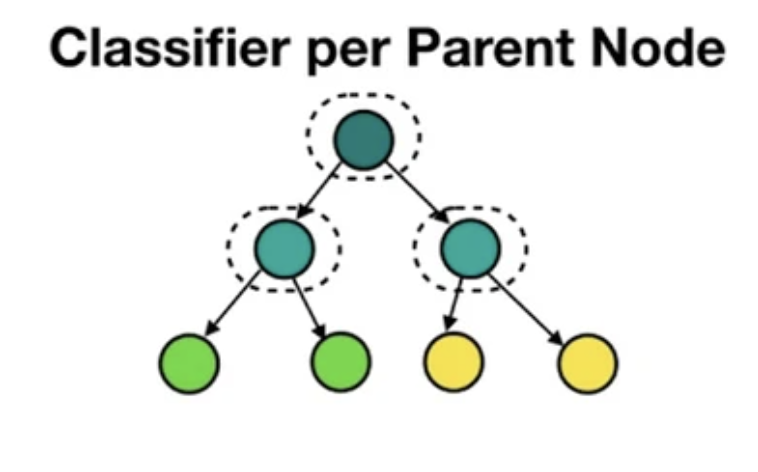
inconsistency: e.g., "Features" >> "Sports"
huge number of classifiers
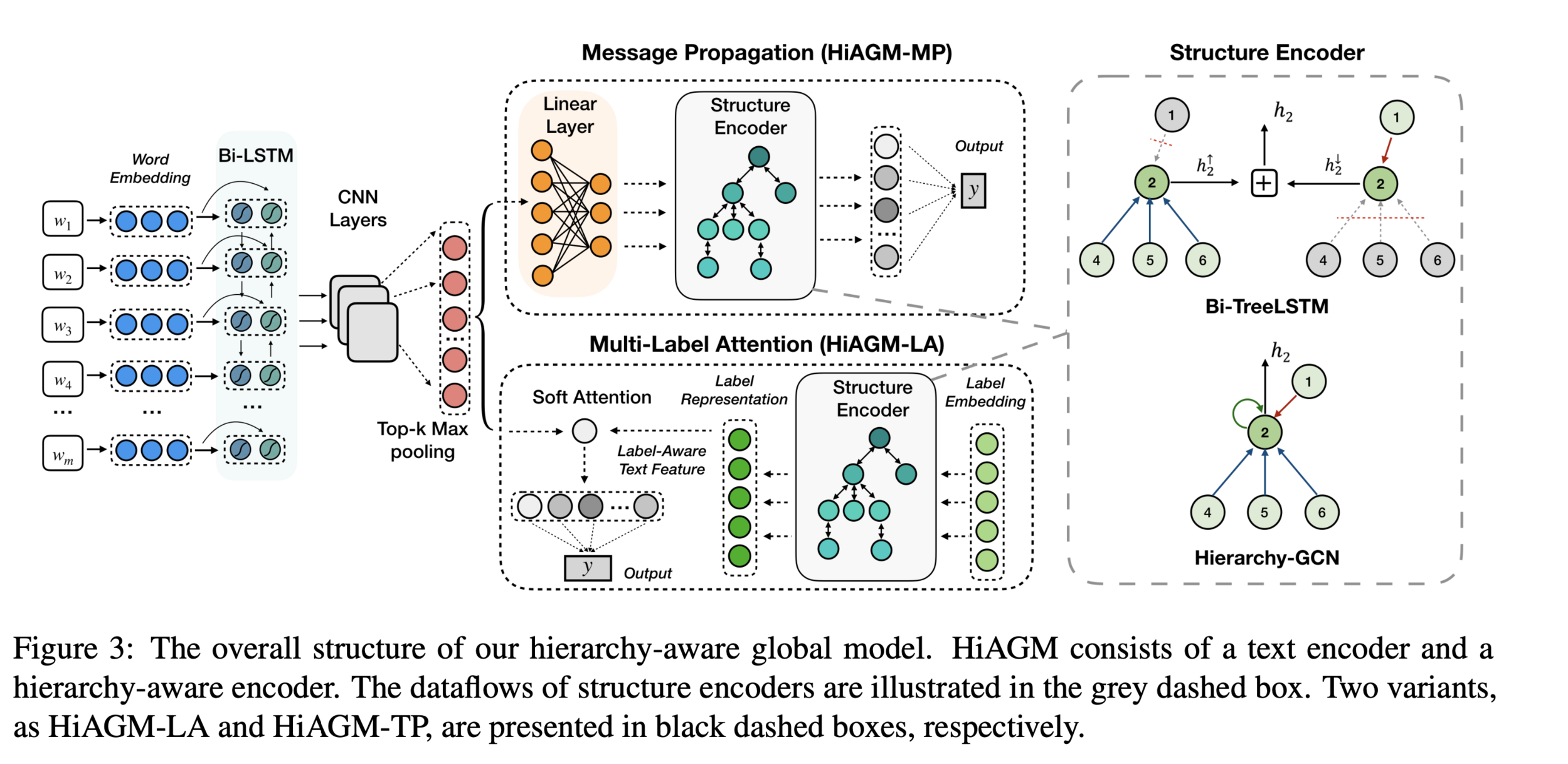
new architecture (zhou et al. 2020)
HiAGM: hierarchy-aware global model for hierarchical text classification
1. textRCNN: encodes text input
2. structure encoder: aggregates label information
inductive fusion
deductive fusion
3. fusion method: combine 1 & 2
dissect each component...
textRCNN: encodes text input
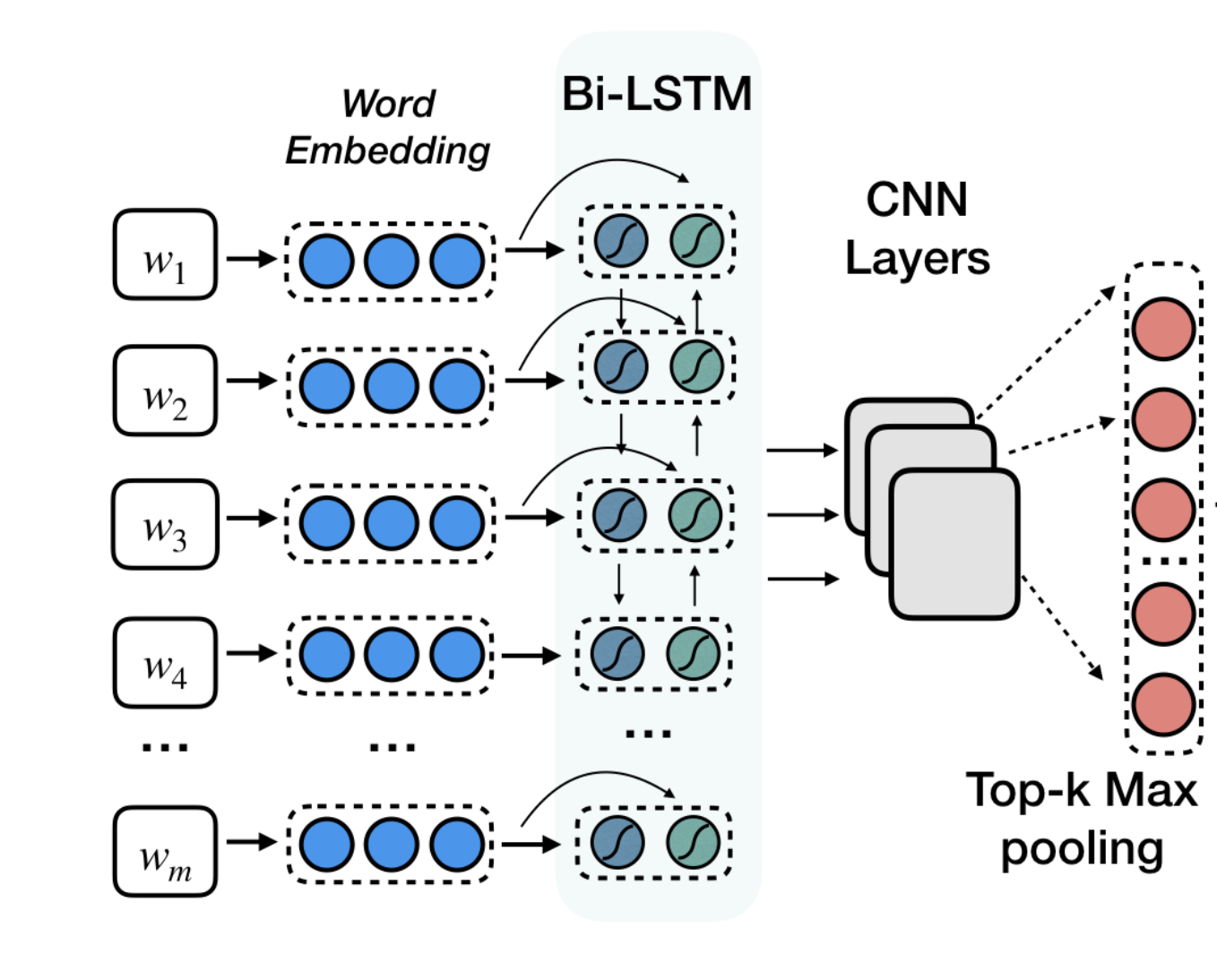

contextual info
n-gram features
key information
def forward(self, inputs, seq_lens):
text_output, _ = self.rnn(inputs, seq_lens)
text_output = self.rnn_dropout(text_output)
text_output = text_output.transpose(1, 2)
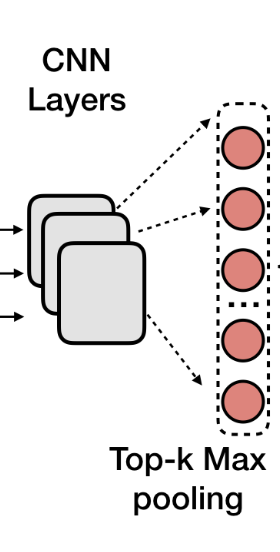
# top k max pooling after CNN
topk_text_outputs = []
for _, conv in enumerate(self.convs):
convolution = F.relu(conv(text_output))
topk_text = torch.topk(convolution, self.top_k)[0].view(
text_output.size(0), -1
)
topk_text = topk_text.unsqueeze(1)
topk_text_outputs.append(topk_text)
return topk_text_outputssnippet from TextEncoder class (code)



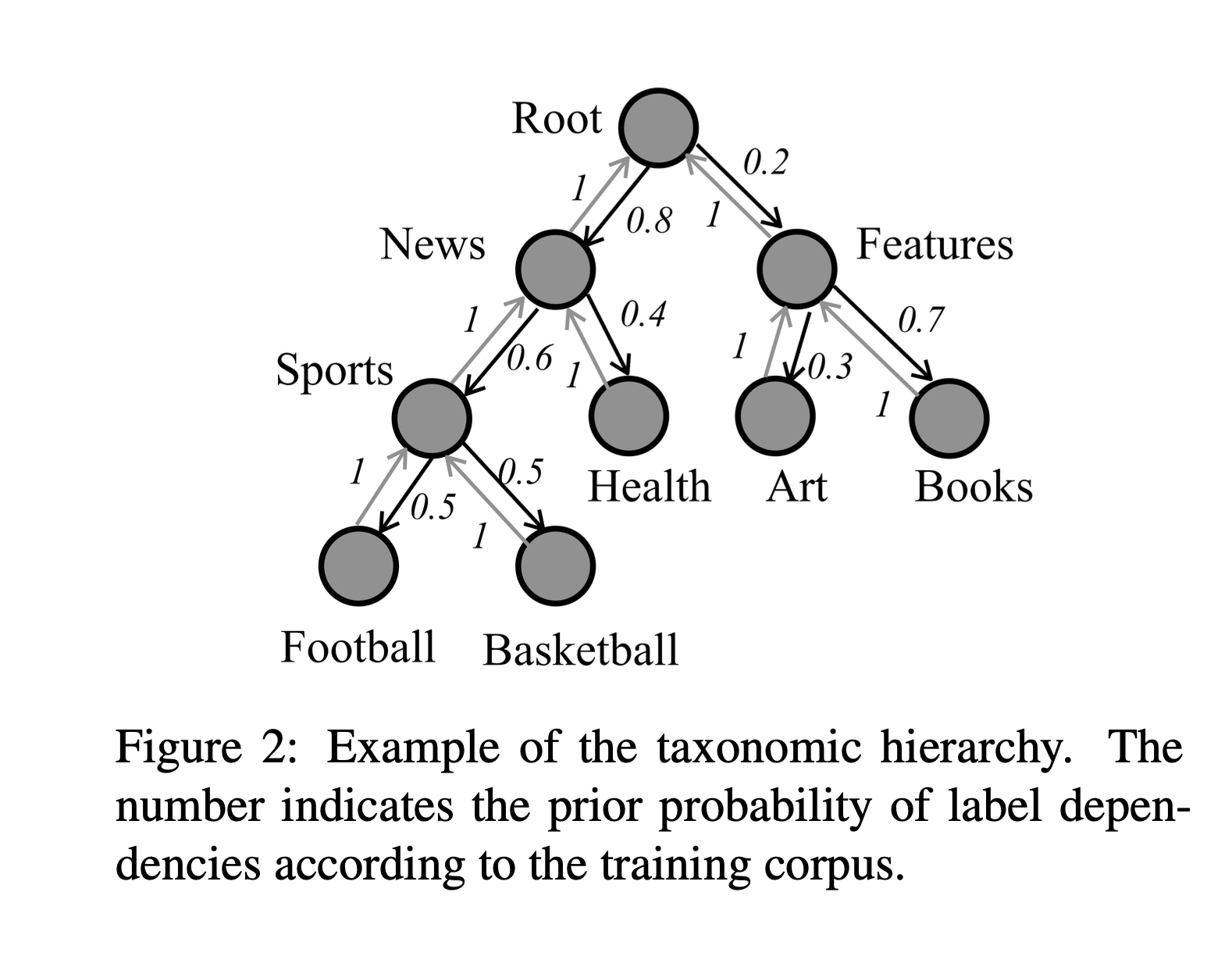
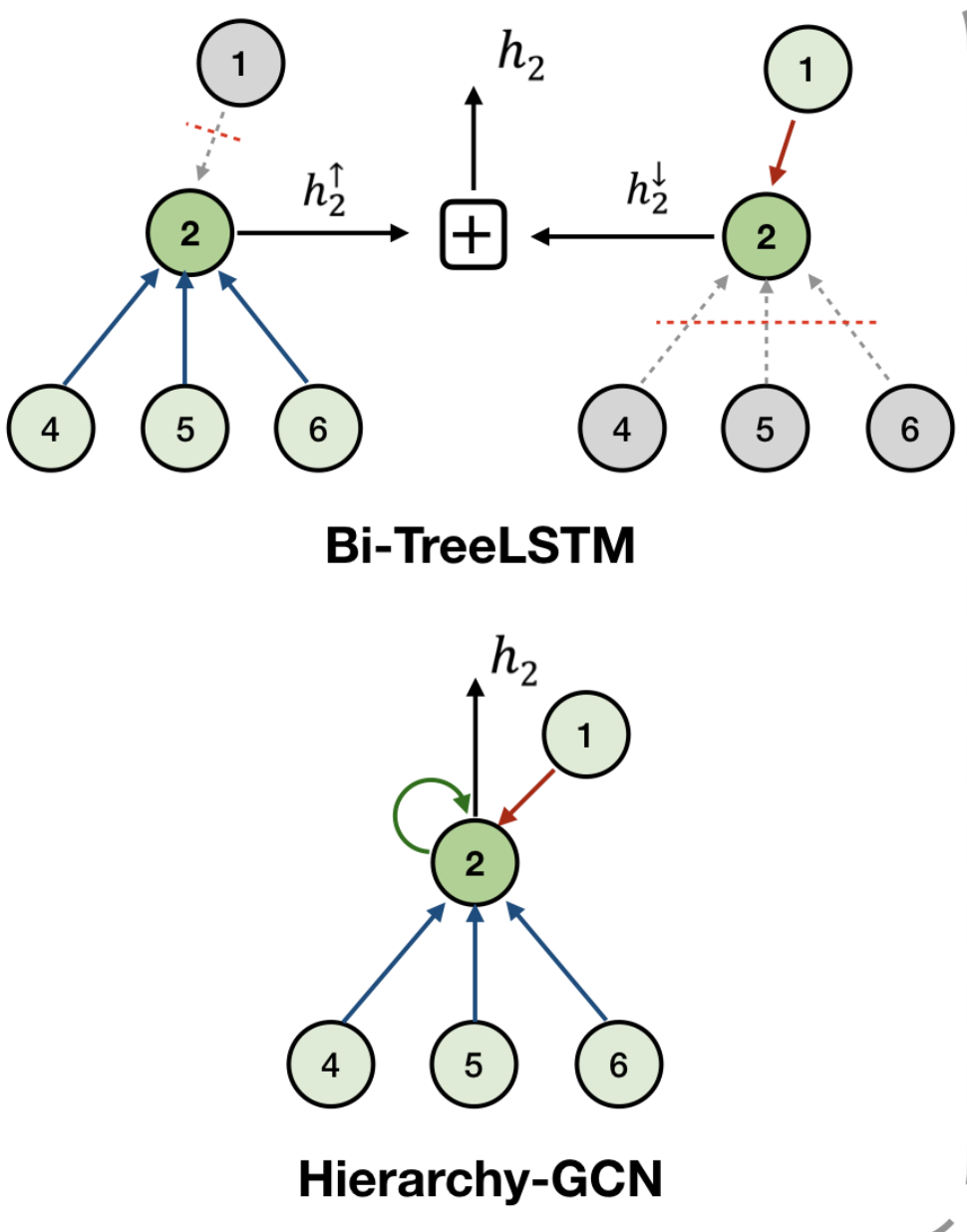
structure encoder: aggregate node information
\mathrm{P(child}_j | \mathrm{parent}_i) = \frac{\mathrm{occurence}_j}{\mathrm{occurence}_i}
\mathrm{P(parent}_i | \mathrm{child}_j) = 1
before learning: assign priors
learning of a node informs its parent + children


fusion method #1: multi-label attention (HiAGM-LA)
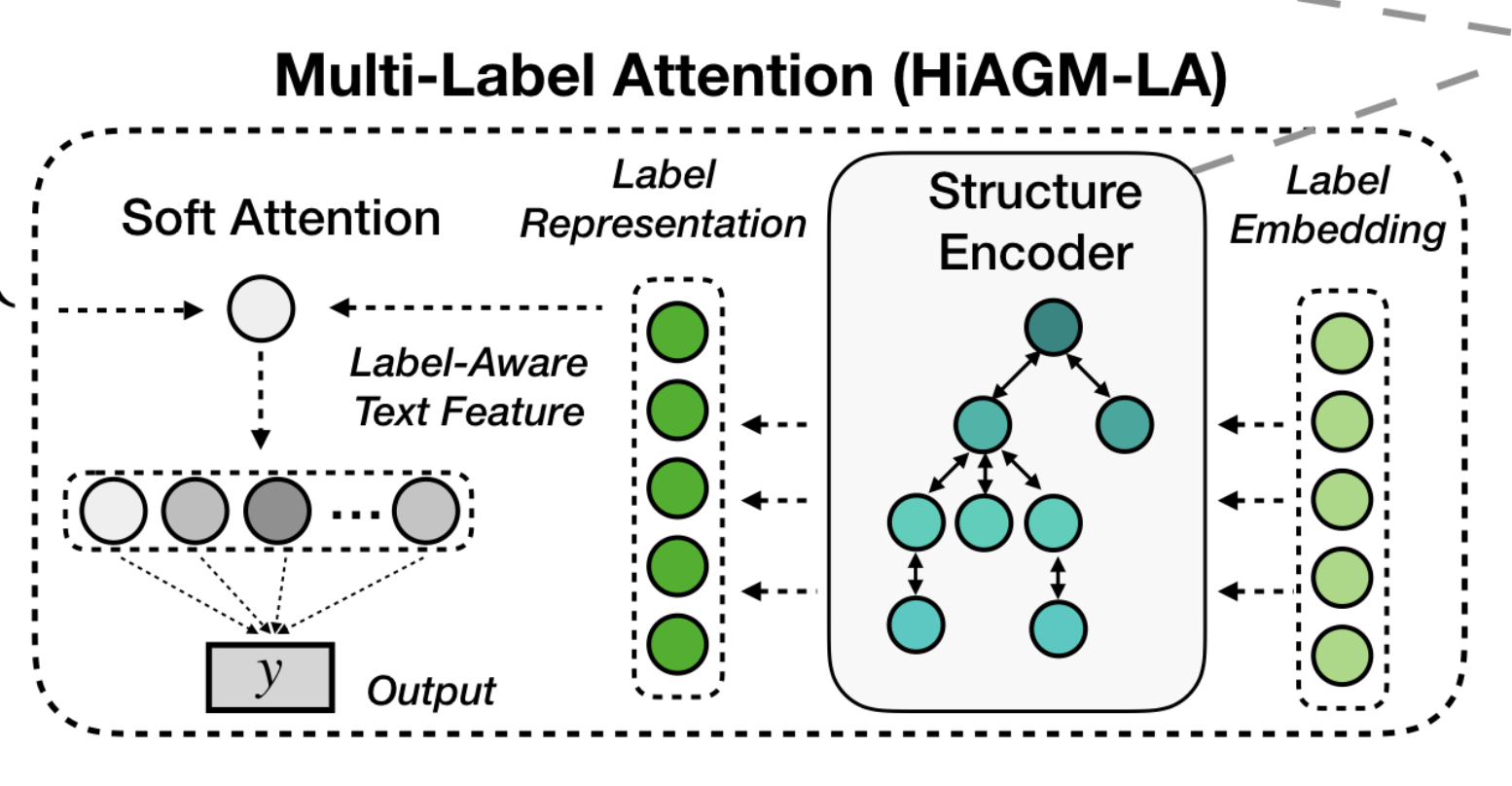
- label embeddings: from pretrained model
- structure encoder: aggregates label embeddings 👉 final label representation
def _soft_attention(text_f, label_f):
att = torch.matmul(text_f, label_f.transpose(0, 1))
weight_label = functional.softmax(att.transpose(1, 2), dim=-1)
label_align = torch.matmul(weight_label, text_f)
return label_align- soft attention: computes label-wise attention
- classification: one-layer mlp with sigmoid
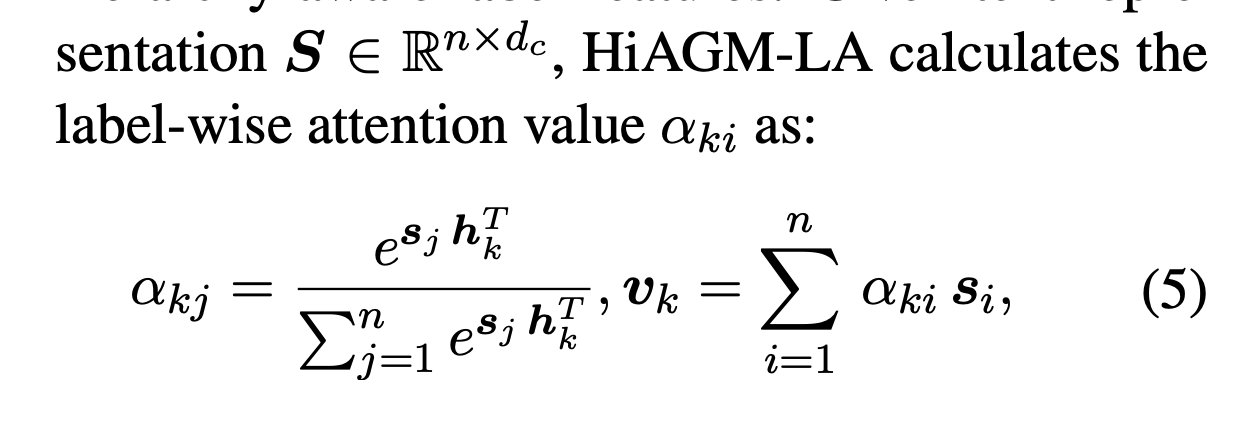
fusion method #2: text feature propagation (HiAGM-TP)
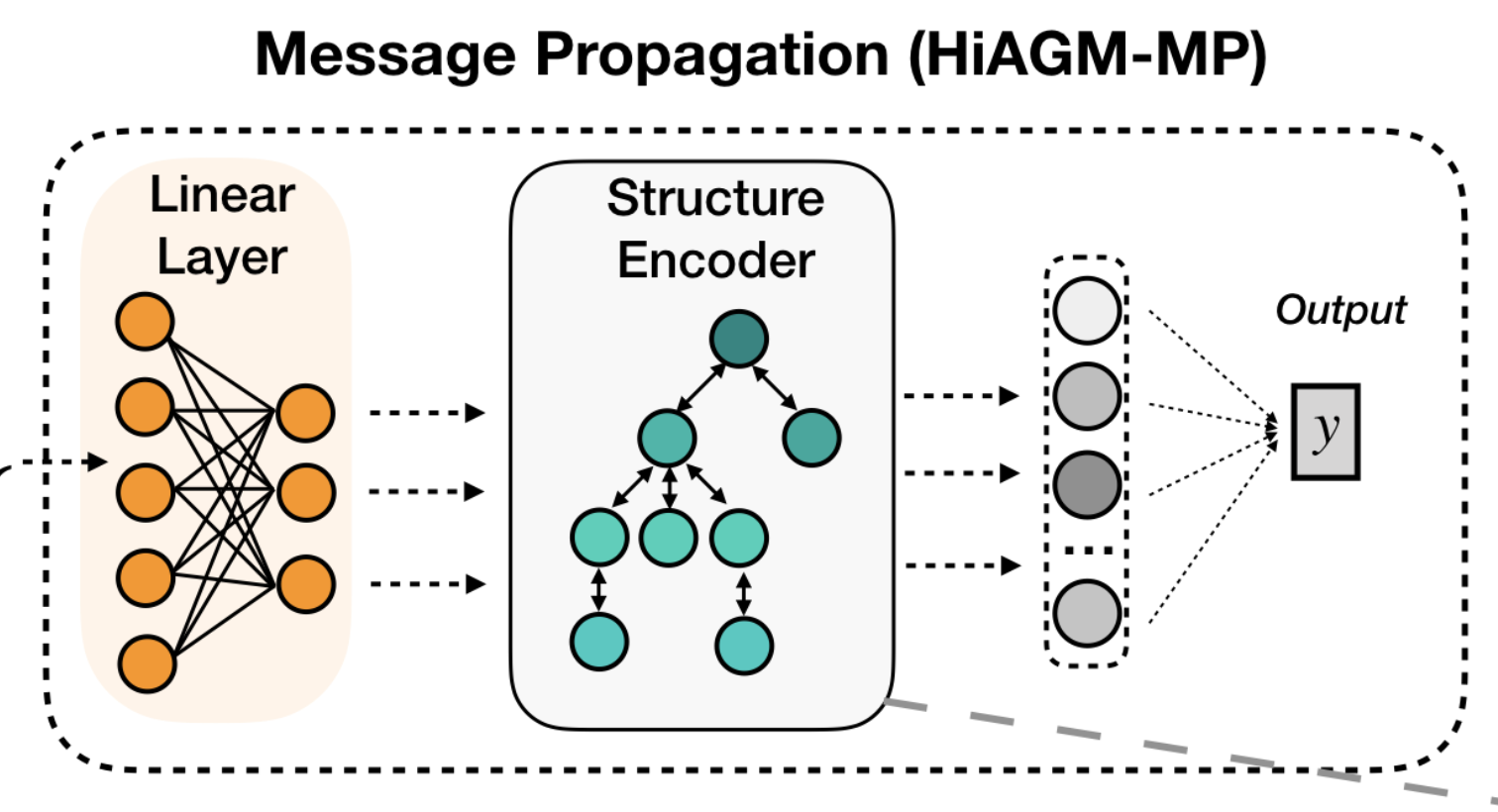
- text feature aggregation: input observed with a label 👉 pass feature values to other nodes via taxonomy
- classification: one-layer mlp with sigmoid
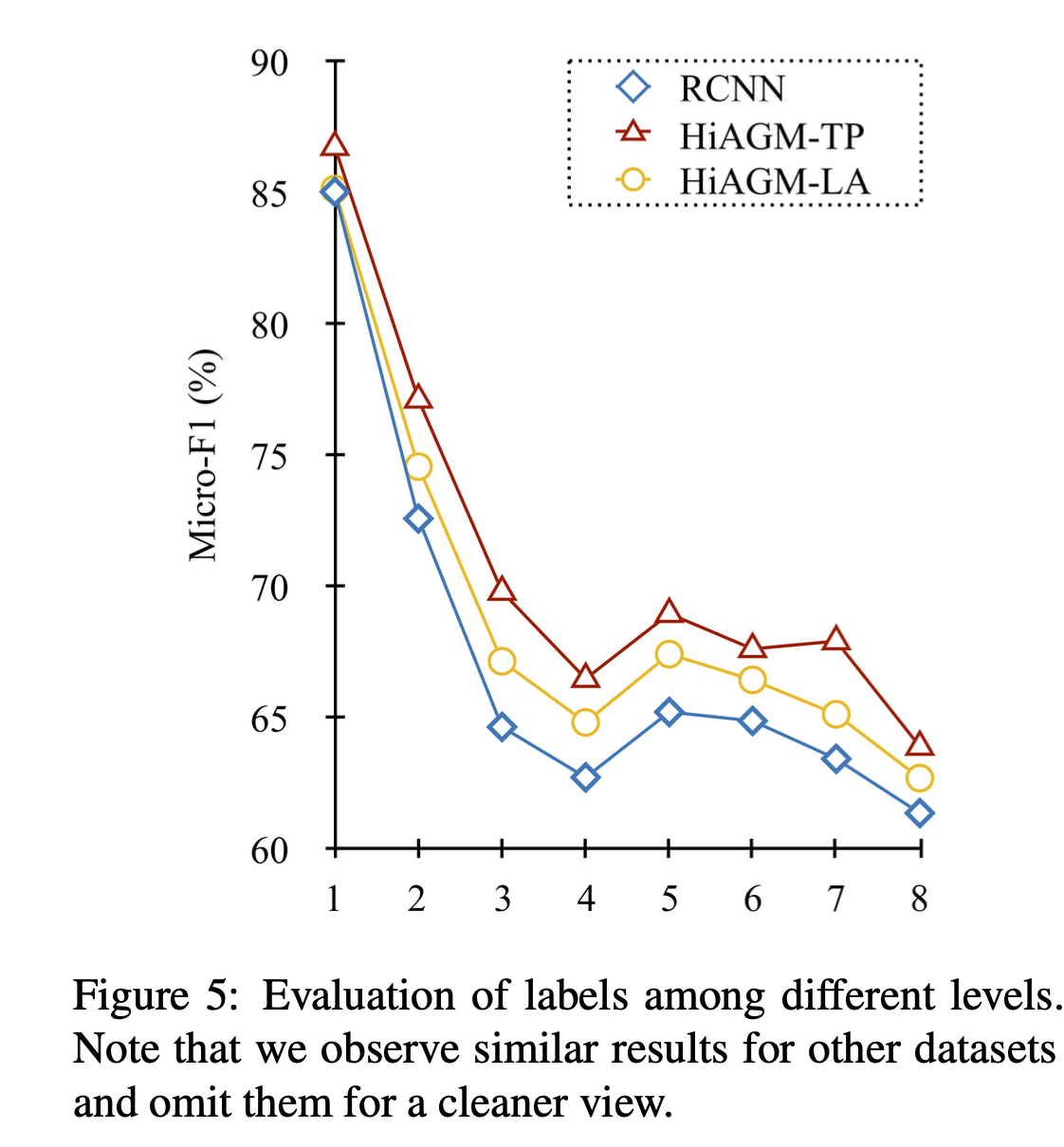
model performance
- eval metrics: good ol' micro and macro f1 (positive: ≥ 0.5)
- benchmarks: news (RCV1-V2, NYT) + research (WOS)
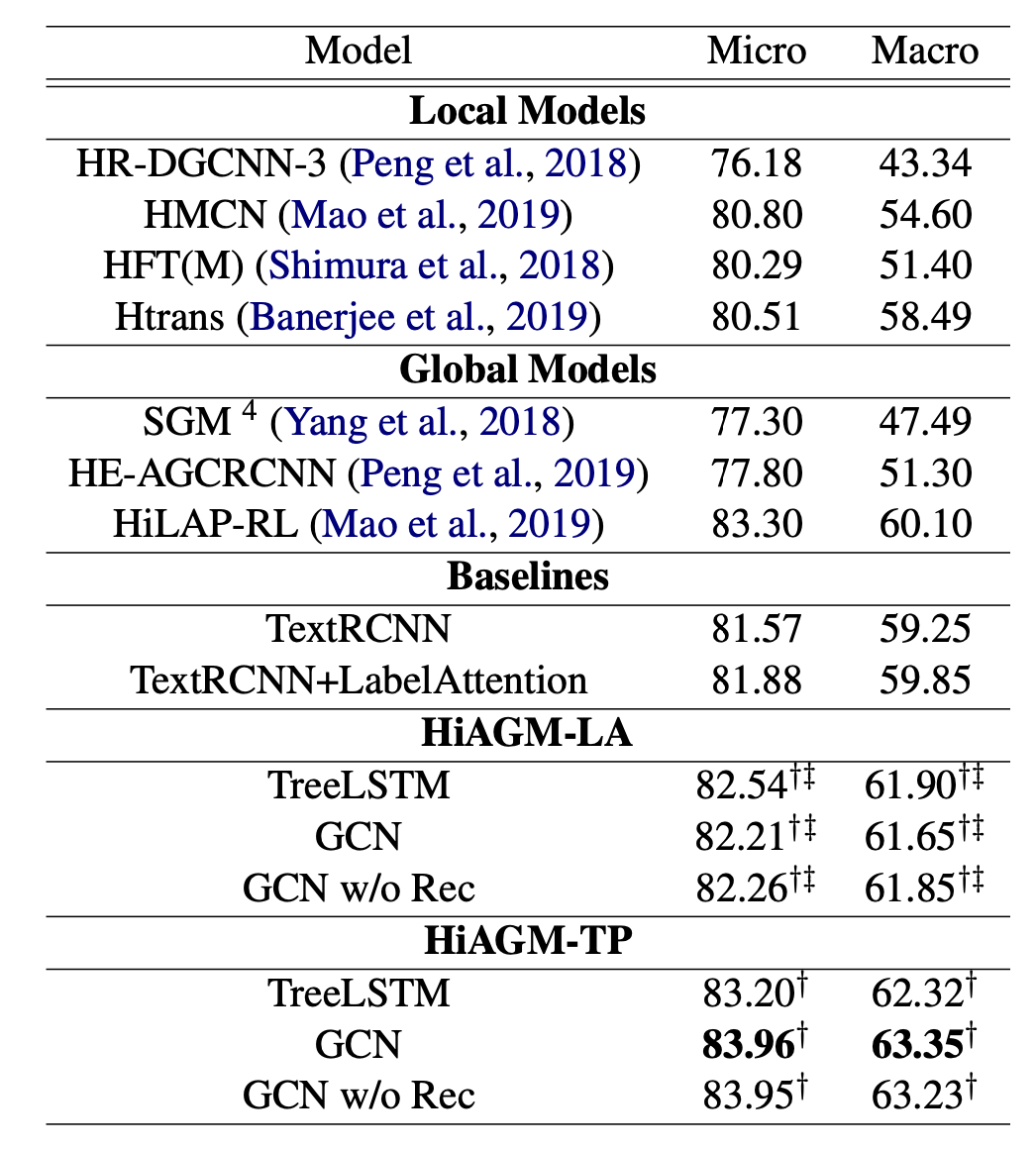
main results
model performance
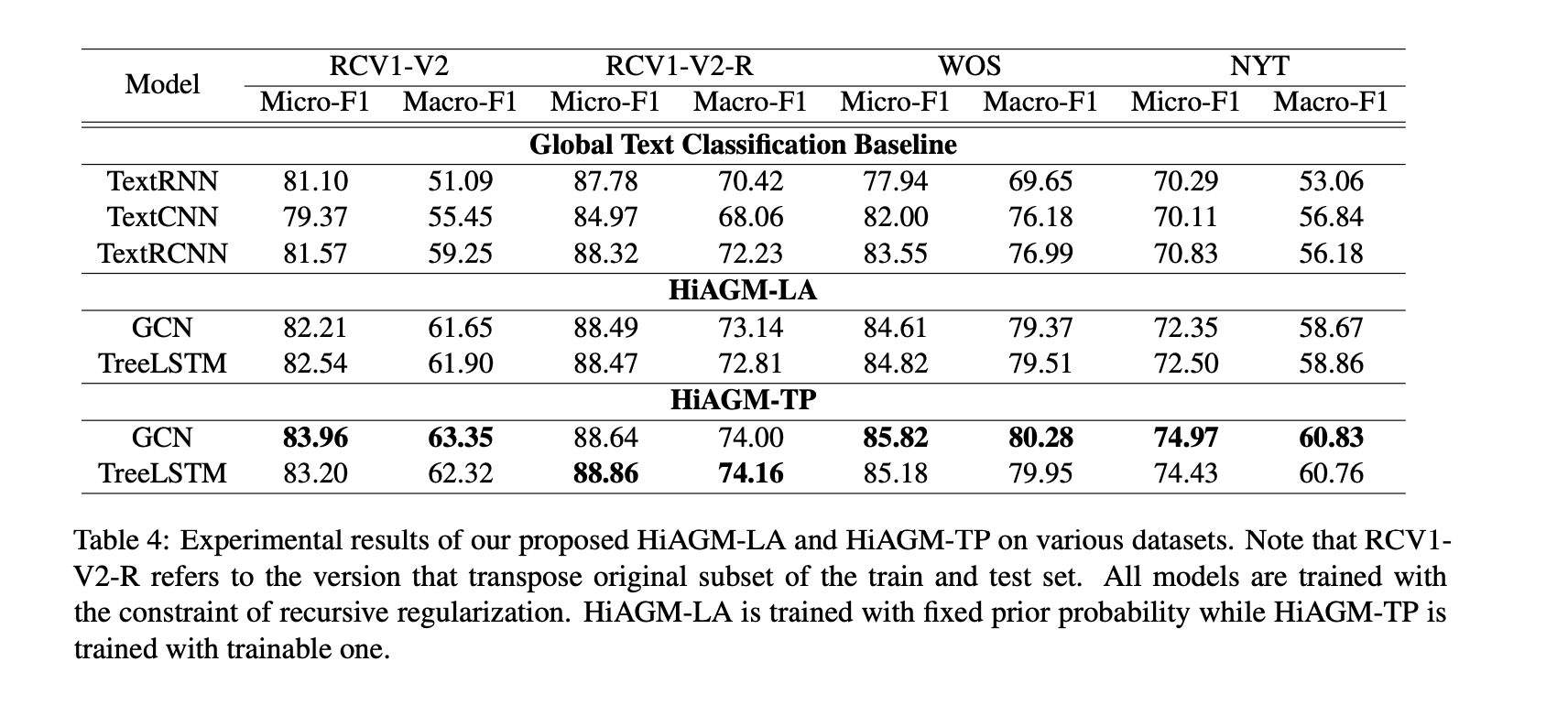
compare different component choices
winner
model performance
depth of gcn
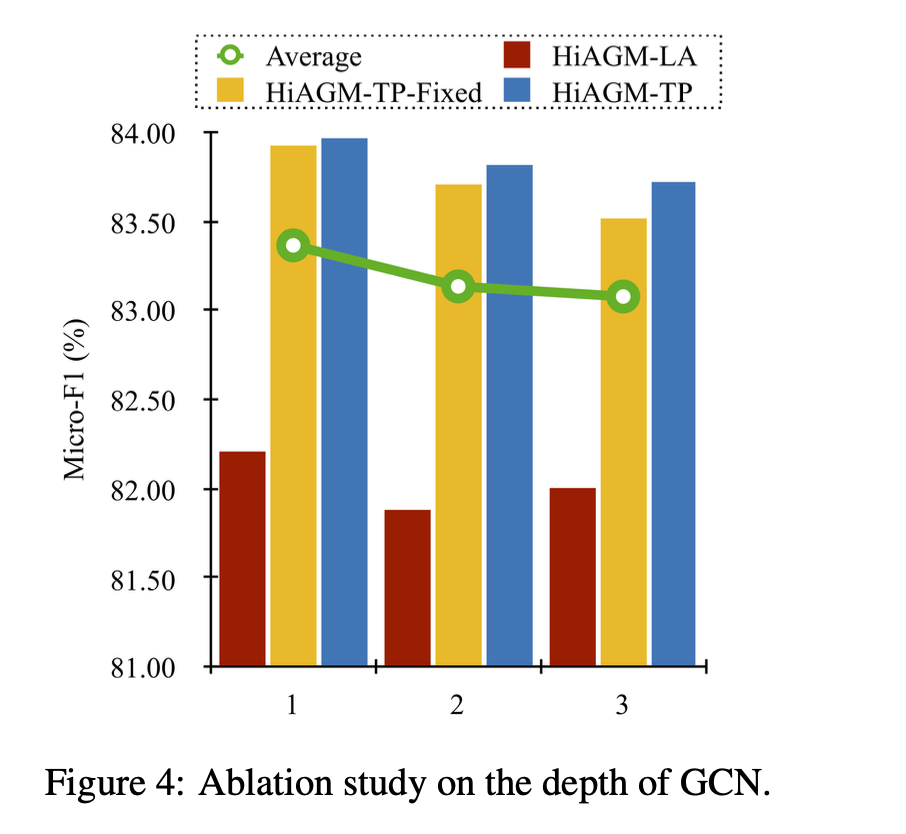
depth of taxonomy
summary
- nodes are flatten to leaf level for eventual classification 👉 "prework": dependencies between nodes are preserved via structure encoder
- 2 directions of aggregation: from text inputs (winner) vs. from labels
HiAGM
By Yuan Meng




