Herramientas para la recolección de datos web
Yu-Chang (Andy) Ho
May 8th, 2019 in Colombia


About Me
Consultant @ ECLAC, United Nations
M.S. in Computer Science @
University of California, Davis, CA, USA
B.S. in Computer Science @
National Central University, Taiwan
Former Research Assistant @
Academia Sinica, Taiwan
Education
Work Experience
Andy Ho (Yu-Chang Ho)


Outline
- Web-scraping?
- How to Perform Web-scraping?
- What is API?
- What Should be Aware of?
- Technical Skills?
- Our Achievements
- Challenges?

Web-Scraping!
(Crawling??)

1/30
What is
Web-crawling?
Collecting a list of webpage links (Uniform Resource Locator, URL).
We called such a program
"Web Crawler".
Web Crawler
World-wide Web (WWW)

List of Target to Visit
2/30
What is
Web-scraping?
Getting the data from the web!
You will have target.
Wikipedia
Scraping is a form of copying, in which specific data is gathered and copied from the web.
Web Crawler
Content Parsing
Basic Cleaning
World-wide Web (WWW)
Web-scraper


3/30
How to Perform
Web-scraping?
-
Software:
- Listly (https://listly.io/)
- Web Scraper IO (www.webscraper.io)
- Buy the data!:
- Dataprovider.com (www.dataprovider.com)
4/30
Copy & Paste (Human Intelligence)- Programming!!!

What else?
What will you need?
A programmer!



How to Perform
Web-scraping?
5/30
Recall the structure of
A Web-scraper
Web Crawler
Content Parsing
Basic Cleaning
Web-scraper
6/30
Content Parsing??
A webpage is essentially a file of texts.
<html>
<head>
<title>This is an example website</title>
</head>
<body>
<div id='name'><h1>Yu-Chang Ho</h1></div>
<hr height="2px">
<h2>Education</h2>
<div id='edu1'>M.S.in Computer Science, UCD</div>
<div id='edu2'>B.S.in Computer Science, NCU</div>
<h2>Work Experiences</h2>
<div id='work1'>Consultant in ECLAC, UN</div>
</body>
</html>
7/30
Have a deeper look
A HTML Element:
<div id='name'>Yu-Chang Ho</div>is a type of element, a container of any other elements or texts.
Other examples: , , , ......
is an identifier of a specific element.
<div><table><img><p>id='name'8/30
So What Does the Parser Do?
- Read the HTML code (webpage source)
- Libraries like BeautifulSoup or Selenium could help you with this
- Find the target elements
- Collect the values and format them as a table
- Repeat 1. ~ 3. for all the crawled pages
9/30
Essentially......
<html>
<head>
<title>This is an example website</title>
</head>
<body>
<div id='name'><h1>Yu-Chang Ho</h1></div>
<hr height="2px">
<h2>Education</h2>
<div id='edu1'>M.S.in Computer Science, UCD</div>
<div id='edu2'>B.S.in Computer Science, NCU</div>
<h2>Work Experiences</h2>
<div id='work1'>Consultant in ECLAC, UN</div>
</body>
</html>| name | edu1 | edu2 | work1 |
|---|---|---|---|
| Yu-Chang Ho | M.S. in Computer Science, UCD | B.S. in Computer Science, NCU | Consultant in ECLAC, UN |
10/30
Recall the structure of
A Web-scraper
Web Crawler
Content Parsing
Basic Cleaning
Web-scraper
11/30
Data Cleaning
- Format the scraped values
- De-duplication
- Eliminate outliers
12/30
What is an API?
Application Programming Interface (API)??
The API is a service to easily access data!
Data in uniform format like CSV, JSON, or XML.
Not all the website provides this service......
Indicates the willingness of the company/website for sharing their data!

13/30
Comma-separated Values (CSV)
id,name,price (USD),sold,country
'MCR423578486',Parrot Drone Bebop 2 Fpv Wi-fi...,762,4.0,Costa Rica
'MCR423607385',Drone Dji Mavic Air Camera - C...,1150.0,,Costa Rica
'MCR423609599',Drone CuadricÛptero,34,21.0,Costa Rica
'MCR423598615',Minidrone Quadcopter,33,3.0,Costa Rica
'MCR423541901',Parrot Minidrones Rolling...,99.72736445485222,1.0,Costa Rica
'MCR423630621',X8 Pro Dron Cargador De Bateria Nuevo,8.310613704571017,,Costa Rica
'MCR423632316',Drone Sharper Image.con C·mara.,108.03797815942323,,Costa Rica
'MCR423632295',Drone Mini X10. ,36.56670030011248,,Costa Rica14/30
JavaScript Object Notation (JSON)
{
"id": "MSV418788",
"name": "Accesorios Náuticos",
"picture": null,
"permalink": null,
"total_items_in_this_category": 0,
"children_categories": [],
"attribute_types": "none",
"meta_categ_id": null,
"attributable": false
}A set of Key/Value pair.
15/30
Extensible Markup Language (XML)
<?xml version="1.0" encoding="UTF-8"?>
<root>
<row>
<id>'MCR423578486'</id>
<name>Parrot Drone Bebop 2 Fpv ...</name>
<symbol (original)>CRC</symbol (original)>
<price (original)>459000.0</price (original)>
<price (USD)>762.9143380796195</price (USD)>
<sold>4.0</sold>
<country>Costa Rica</country>
</row>
</root>Similar to HTML.
16/30
About API
Always provided with documentations for the usage.

The address to access
Something you could customize
(sorting, filtering, ......)
The format of response
17/30
About API
Has limitations for Accessing:
- Authentication (Access Token, Valid User Account)
- Limited Number of Requests.

token = '72b17b7e17b58e9de79c83678737d418'18/30
API or Web-scraping?
| API | Web-scraping |
|---|---|
| Granted to use the data | Not grant to use the data |
| No need to make a parser | Need to design the parser for the webpage source |
| No need to clean the data | Need to make sure the data obtained is correct |
|
Easy to use (as a programmer perspective), but not always provided |
Some companies can prevent the data from being scraped |
| Have rules to follow, so not a security issue for the website | A kind of attack to their service! |
19/30
API will always be the recommended way!
Of Course, if provided......
20/30
What Should be Aware of When Collecting Data?
- Terms & Conditions provided by the website.
- The ability of the server of the website. (How much requests at the same time?)
- Random wait time.
- The network status of your machine.
- Your computer could crash!!! (Heavy loading......)

21/30
Technical Skills for
Web-scraping
- Software Development
- Knowledge of Databases (Relational, NoSQL)
- Server Management (Linux, Windows)



22/30
What We Achieved
| Target | Data Points through Scraping | Data Points through API |
|---|---|---|
| MercadoLibre (Items) | 192092 (192K) | 53423091 (53.4M) |
| MercadoLibre (Sellers) | 25679 (25K) | 2474157 (2.4M) |
| Kiva | N/A | 1684119 (1.6M) |
| N/A | 104724059 (104M) | |
| Freelancer.com | N/A | 191424 (191K) |
| WORKANA | 20456 (20K) | N/A |
Over 150 Million Data Points!
23/30
Our Infrastructure
24/30
Architecture
Database
Multi-threaded Crawler
Content Parser
Basic Data Cleaning
Normalization
Data File Output

Visualization!
Web-scraper
Error Handling & Retry
De-dupe
Aggregation
25/30
Challenges?
-
Infrastructure😝 - Been blocked by the target site for doing the scraping
- Coffee Shop or Public WiFi
- Program errors handling
- Observing the behavior of the website
- Data cleaning
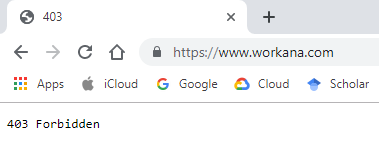
26/30
Time-consuming!!!
Did I Mention Observing the Behavior of the website?
Magic happens in background!
Open a webpage is essentially downloading files from the server.


Google's
Web Server
1. Open www.google.com
Your Browser
2. Send the webpage source & the browser will run it
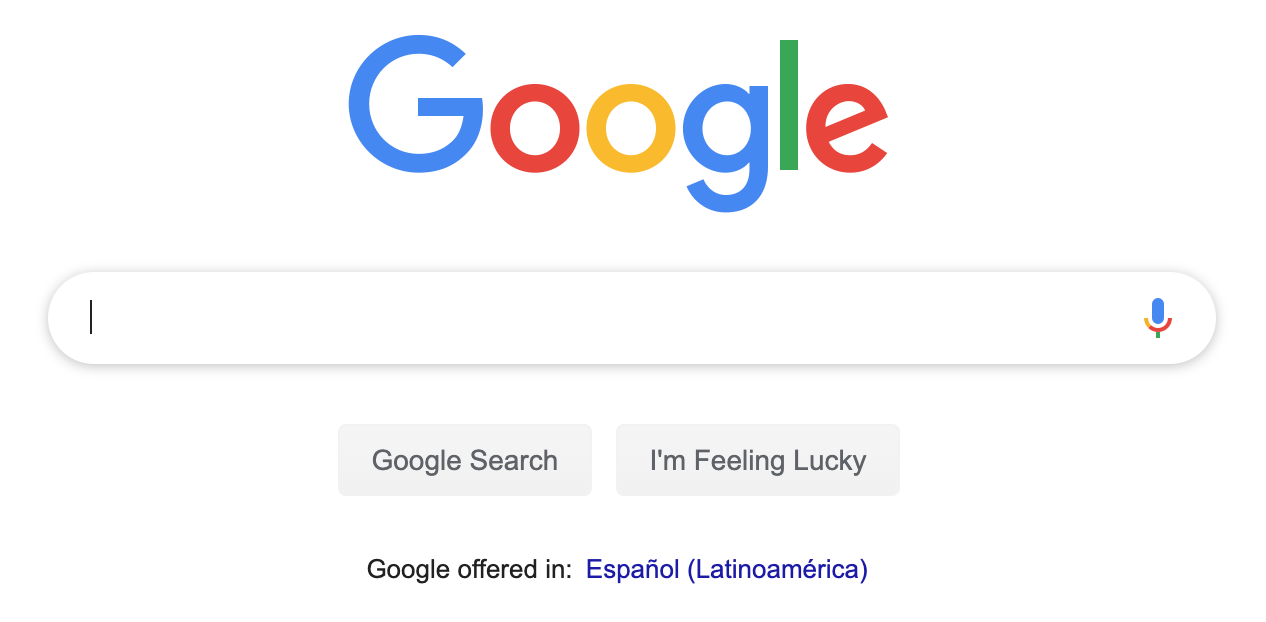
3. The Result
27/30
Live Demo!
Sample Website:
28/30
References
29/30
Thank you! Questions?

My Teammates (from Left to Right):
Matthew Reese, Karla Rascon-Garcia, Me, Veronika Vilgis, Xin Jin
30/30
Program Error Handling
Parsing Algorithm
Record URL to log
Continue to next URL
Failure!
Write Data
Record Data to log
Input
Failure!
Finished?
Log Files are your best friend!
Yes!
No
27/30
What is Web-scraping?
By Yu-Chang Ho
What is Web-scraping?
Presentation for Big Data Workshop held by ECLAC, United Nations about Web-scraping. Workshop held on May 8th, 2019 in Colombia.


