David Lu
Software Developer
Yung-Sheng Lu
Apr 11, 2017
@NCKU-CSIE
Problem Setting
Challenges
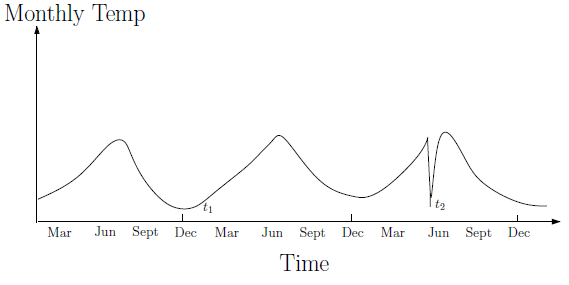
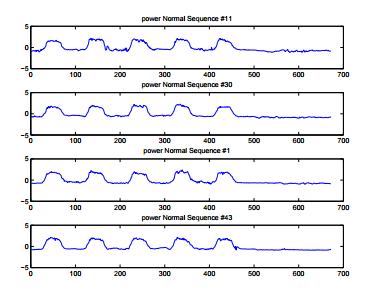
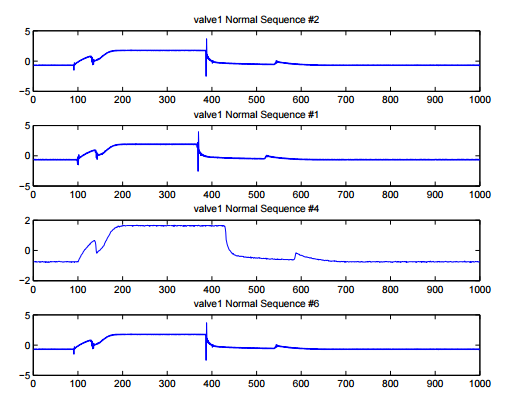
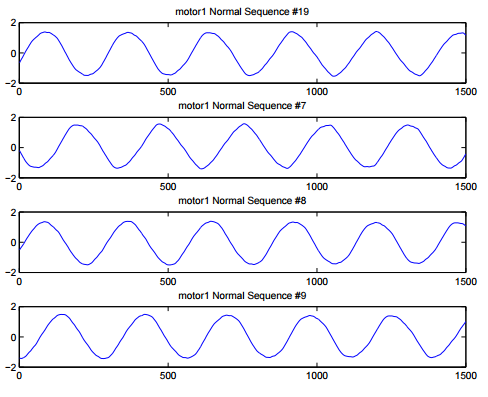
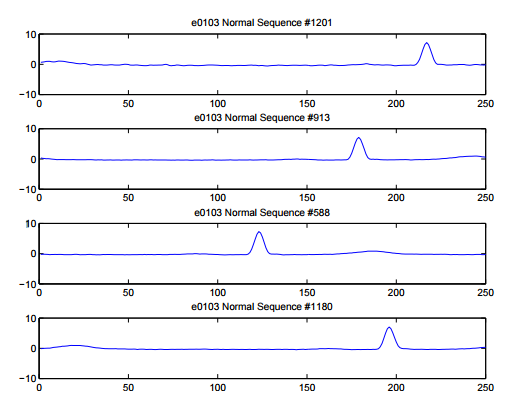
Types of Time Series
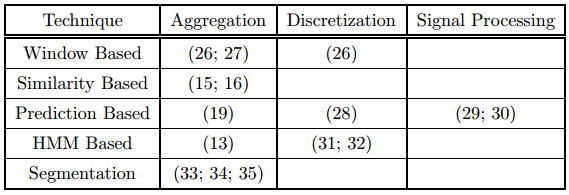
Existing Techniques
Transformation of Data
Detection Techniques
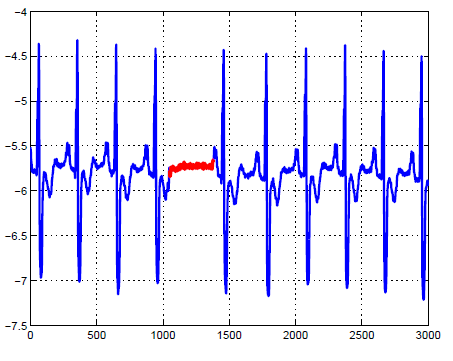
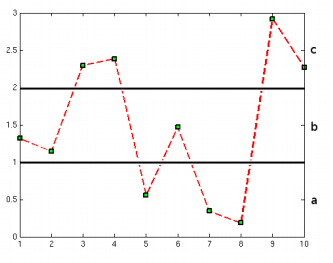
Discord Detection
discords
By David Lu
Anomaly Detection for Time Series




