ModelING Litigation in USPTO patent Claims using Doc2Vec
“The key to artificial intelligence has always been the representation.” —Jeff Hawkins
Zachary D White Feb - 2019
Capstone
How not to do a capstone

Guidelines


Business Application
Applied Natural Language Processing
1
2
3

Valuable to Large Companies
The Conversation

WHat Why How & Who

What is Patent Scope?
§ Legalese Warning
it is used in the general lexicon to refer to the breadth of the patent, or how much intellectual space resides within the metes and bounds of the patent claims.
§ Laymen Terms please
A general definition may well be that the scope of a patent is the boundaries (or limits) of the invention protected by the patent.
§ In practical terms this means what??
This definition manifests in practice as the universe of inventions that infringe on the patent.
“Like other general legal terms—such as negligence or fraud—the practical use of a definition of the scope of a patent comes only in its application to specific cases of infringement."
"INTOLERABLY AMBIGUOUS!"
2 stars
-A friend
Why IS Patent Scope important?

How Do you measure scope?
- Oldest Method - 1990 -2001
- Stanford Method 2015
- USPTO Method - 2016
- Kuhn's Methods - 2017

Problem statement
Problem statement
New Product + Lawsuit = Bad
Search + Patent
WHAT IS PATENT INFRINGEMENT?
Simulations
.jpg)
What is a Patent?

Patent Claim
Terms
ICC - Independent Claim Count is the number of independent claims made by a patent
ICL - Independent Claim Length is the number of words in said claim**.
PC - Primary Claim is the first independent Claim listed in a patent.

My method



Unsupervised Learning
Supervised Learning
New Ideas
UMM Data... HEllo


USPTO Data
df = df = pd.read_csv('claim_2000_2014_v001.csv')
df.head()
pat_no claim_no claim_txt
0 8697278 17 17. Battery comprising an interior of the batt...
1 7385756 81 81. A catadioptric projection objective for im...
2 7387146 1 1. A heavy duty tire comprising a tread portio...
3 7387253 43 43. A system comprising: (a) a optical reader ...
4 7387278 17 17. A parachute ripcord pin for holding a para...DF.INFO()
Number of patents
The claim number for a particular patent
Int64Index: 8216031 entries, 0 to 8216149
Data columns (total 3 columns):
pat_no object
claim_no int64
claim_txt object
dtypes: int64(1), object(2)
memory usage: 250.7+ MBThe text contained in the claim
The Patent ID number of a particular claim
CLEAN DATA &Create FEATURES
pat_no claim_no claim_txt ICL ICC litigation
8697278 17 battery comprising interior battery active ele... 106 2 0
8697278 1 battery cell casing comprising first casing el... 97 2 0
7385756 81 catadioptric projection objective imaging patt... 108 33 0
7385756 94 catadioptric projection objective imaging patt... 116 33 0
7385756 79 catadioptric projection objective imaging patt... 103 33 0-
Text Cleaning
- Removed legal stop words
- Lower cased
- Standard text cleaning
-
Computed
- Independent Claim Length (ICL)
- Independent Claim Count (ICC)
- Merged Patent-wise Litigation Data from Stanford
Closer Look
df['litigation'].value_counts()
0 8185679
1 30352
Name: litigation, dtype: int64
0 = number of non-litigated claims
1 = number of litigated claimsdf['litigation'].value_counts(normalize=True)
Non-Litigated Claims 99.63%
Litigated Claims 0.37%
Name: type, dtype: float64 All Claims
df['litigation'].value_counts()
0 197975
1 7526
Name: litigation, dtype: int64
0 = number of non-litigated claims
1 = number of litigated claimsdf['litigation'].value_counts(normalize=True)
Non-Litigated Claims 96.34%
Litigated Claims 3.66%
Name: type, dtype: float64 Primary Claims only
Descriptive Statistics
All Claims
df.loc[:,['ICL','litigation']].groupby(['litigation']).agg(['count','min','max','mean','std'])
ICL
count min max mean std
litigation
0 8185679 1 18433 104.827044 73.717400
1 30352 1 1509 94.007380 62.130354
#Two Tailed Independent T-Test
statistic pvalue
ICL 30.260286 3.155879e-198Primary Claims Only
df_gbd.loc[:,['ICC','ICL','litigation']].groupby(['litigation']).agg(['count','min','max','mean','std'])
ICC
count min max mean std
litigation
0 2907222 1 276 2.814694 2.326064
1 7526 1 358 4.030162 7.705218
ICL
count min max mean std
litigation
0 2907222 1 18433 106.592626 79.092973
1 7526 2 1509 99.652139 63.708417
# Two Tailed Independent T-Test results
statistic pvalue
ICL 9.432147 5.235061e-21
ICC -13.683259 4.067142e-42Modeling Techniques

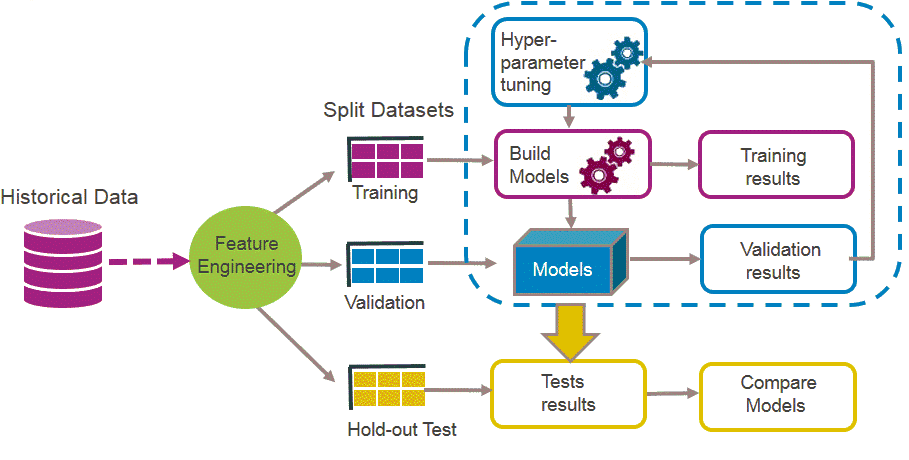
Gensim Doc2Vec Language Model
XGBOOST Logistic Regression
Doc2vec
## Sample of a tagged document
next(corpus_for_doc2vec.__iter__())
>TaggedDocument(words=['battery', 'comprising', 'interior', 'battery', 'active', 'elements', 'battery',
'cell', 'casing', 'said', 'cell', 'casing', 'comprising', 'first', 'casing', 'element', 'first', 'contact',
'surface', 'second', 'casing', 'element', 'second', 'contact', 'surface', 'wherein', 'assembled', 'position',
'first', 'second', 'contact', 'surfaces', 'contact', 'first', 'second', 'casing', 'elements', 'encase',
'active', 'materials', 'battery', 'cell', 'interior', 'space', 'wherein', 'least', 'one', 'gas', 'tight',
'seal', 'layer', 'arranged', 'first', 'second', 'contact', 'surfaces', 'seal', 'interior', 'space',
'characterized', 'one', 'first', 'second', 'contact', 'surfaces', 'comprises', 'electrically', 'insulating',
'void', 'volume', 'layer', 'first', 'second', 'contact', 'surfaces', 'comprises', 'formable', 'material',
'layer', 'fills', 'voids', 'surface', 'void', 'volume', 'layer', 'hermetically', 'assembled', 'position',
'form', 'seal', 'layer'], tags=['8697278-17'])
Build a Language Model
import gensim
from gensim.models.doc2vec import Doc2Vec, TaggedDocument
assert gensim.models.doc2vec.FAST_VERSION > -1 #parallelize doc2vec
from gensim.utils import simple_preprocess
class MyDataframeCorpus(object):
def __init__(self, source_df, text_col, tag_col):
self.source_df = source_df
self.text_col = text_col
self.tag_col = tag_col
def __iter__(self):
for i, row in self.source_df.iterrows():
yield TaggedDocument(words=simple_preprocess(row[self.text_col]),
tags=[row[self.tag_col]])
#Model 1
corpus_for_doc2vec = MyDataframeCorpus(df, 'claim_txt', 'claim_no')
#Model 2
corpus_for_doc2vec = MyDataframeCorpus(df, 'claim_txt', 'litigation')%%time
#Params
model_smple = Doc2Vec(vector_size=100, # 100 should be fine based on the standards
window=8, #number of context words
alpha=.025, #initial learning rate
min_alpha=0.00025, #learning rate drops linearly to this
min_count=2, #ignores all words with total frequency lower than this.
dm =1, #algorith 1=distributed memory , 0=distributed bag of words (PV-DBOW)
epochs=30,
workers=workers)#cores to use
model_smple.build_vocab(corpus_for_doc2vec,progress_per=500000)
## Build vocab from streaming tagged document Show progress every 500k rows
## Should take ~ 30 minutes
# Train Language Model
model_smple.train(corpus_for_doc2vec, total_examples=model_smple.corpus_count, epochs=model_smple.epochs)
>>Wall time: 22h 02min 24sModel In Action
def model_infer_test(df,model):
#grab a random claim from random_claim function
tagged_claim = next(random_claim(df))
#Infer a vector from that claim
inferred_vector = model.infer_vector(tagged_claim.words)
sims = model.docvecs.most_similar([inferred_vector], topn=len(model.docvecs))
#Print top 5 similar claims
print(sims[:5])
# Compare and print the most/median/least similar documents from the train corpus
print('Test Document ({}): «{}»\n'.format(tagged_claim.tags, ' '.join(tagged_claim.words)))
print(u'SIMILAR/DISSIMILAR DOCS PER MODEL %s:\n' % model)
for label, index in [('MOST', 0),('Second', 1) ,('MEDIAN', len(sims)//2), ('LEAST', len(sims) - 1)]:
print(label,index)
#print(u'%s %s: «%s»\n' % (label, sims[index], ' '.join(df[sims[index][0]].words)))
print(u'%s %s: «%s»\n' % (label, sims[index], df.loc[df['claim_no']==sims[index][0],['claim_txt']].values))
# This will let you get random tagged documents
def random_claim(df):
doc_index = np.random.randint(0,len(df))
#row = [df.iloc[doc_index,:]['claim_txt'],df.iloc[doc_index,:]['claim_no']]
yield TaggedDocument(words=simple_preprocess(df.iloc[doc_index,:]['claim_txt']),
tags=df.iloc[doc_index,:]['claim_no'])model_infer_test(df,model_smple)
[('6208475-7', 0.9243185520172119), ('6208475-3', 0.883671224117279), ('6680491-1', 0.6106572151184082),
('8913211-14', 0.5911911725997925), ('8913211-1', 0.5858227610588074)]
Test Document (6208475-7): «optical member inspection apparatus obtaining image data used inspections applying
illumination light optical member one side thereof photographing optical member side comprising holder
comprising frame shaped base portion plurality spaced optical member holding portions provided base portion
enclose space supporting optical member formed base portion said optical member holding portions receiving
face outer margin optical member mounted restriction wall restrict movement optical member mounted receiving
face contacting outer margin optical member said receiving face contacting outer margin face optical member
light passes operation optical member said restricting wall located said moving face»
SIMILAR/DISSIMILAR DOCS PER MODEL Doc2Vec(dm/m,d100,n5,w5,mc2,s0.001,t16):
MOST 0
MOST ('6208475-7', 0.9243185520172119): «[['optical-member inspection apparatus obtaining image data used
inspections applying illumination light optical member one side thereof photographing optical member side,
comprising:a holder comprising frame shaped base portion plurality spaced optical-member holding portions
provided base portion enclose space supporting optical member formed base portion, said optical-member
holding portions receiving face outer margin optical member mounted restriction wall restrict movement
optical member mounted receiving face contacting outer margin optical member, said receiving face contacting
outer margin face optical member light passes operation optical member, said restricting wall located said
moving face.']]»
Second 1
Second ('6208475-3', 0.883671224117279): «[['holder holding outer margin optical member, comprising:a frame
shaped base portion; anda plurality spaced optical-member holding portions provided base portion enclose
space supporting optical member formed base portion, said optical-member holding portions receiving face
outer margin optical member mounted restriction wall restrict movement optical member mounted receiving face
contacting outer margin optical member, said receiving face contacting outer margin face optical member
light passes operation optical member, said restricting wall located said receiving face.']]»
MEDIAN 4108015
MEDIAN ('6592902-1', 0.08781707286834717): «[['pharmaceutical composition comprising (a) particulate
eplerenone d90 particle size 25 400 microns, amount 10 mg 1000 mg, (b) one pharmaceutically acceptable
carrier materials; said composition controlled release oral dosage form wherein 50% said eplerenone
dissolved vitro least 1.5 hours 1% sodium dodecyl sulfate solution 37� c.']]»
LEAST 8216030
LEAST ('6823942-1', -0.3702787756919861): «[['tree saver apparatus preventing excess pressure christmas tree
well, wherein christmas tree comprises tubing, master valve, top valve, second master valve, wing valve,
wherein apparatus comprises:a. hydraulic system comprising: i. piston connected piston rod; ii. cylinder
connected piston; iii. upper plunger connected piston; iv. hand wheel connected upper plunger; b. connection
least 3 outlets connected cylinder; c. frac wing valve connected connection least 3 outlets; d. frac valve
first port second port, wherein first port connected connection least 3 outlets; e. mandrel first end
second end, wherein first end connected piston rod; f. landing bowl connected top valve.']]»Data transformation
ICL ICC litigation 0 1 2 3 4 5 6 ... 90 91 92 93 94 95 96 97 98 99
claim_no
8697278-17 106 2 0 -0.021915 0.124170 -0.467477 1.725972 1.353391 -0.197958 1.234415 ... -1.201108 -0.272672 0.649778 -1.023098 0.146432 0.122571 0.215042 -1.076661 -0.508896 -1.690101
8697278-1 97 2 0 -0.271349 0.260269 -0.315466 1.746054 0.874254 -0.225060 0.971804 ... -1.190130 -0.417508 0.587534 -1.157797 0.314950 0.189521 0.474607 -1.119020 -0.376173 -1.699343
7385756-81 108 33 0 1.429105 0.936555 -0.296551 -1.073354 -0.421059 -0.114407 -0.881726 ... 0.885844 0.934247 0.678008 -0.752642 -0.121980 -0.623260 -2.384536 0.471751 0.874406 1.251178
7385756-94 116 33 0 1.027478 0.484034 -0.535233 -1.124252 -0.382812 -0.101879 -0.348340 ... 0.772912 0.951951 0.901475 -0.721144 -0.304449 -0.278908 -2.655865 0.323664 0.943390 0.687369
7385756-79 103 33 0 1.396978 0.419591 -0.072397 -0.642861 -0.482944 0.496666 -1.178749 ... 0.074441 1.187986 0.909484 0.278953 -0.483475 -0.028059 -2.268470 0.986993 0.039141 0.374451Modeling Techniques
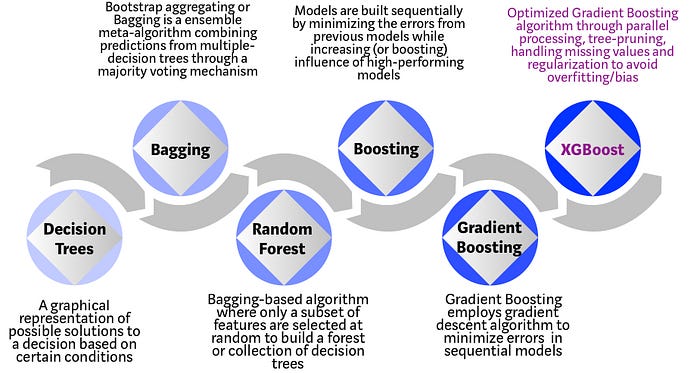
Gensim Doc2Vec Language Model
XGBOOST Logistic Regression
XGBOOST

Model Set up TTS
### Test Train Split
y = df['litigation']
X = df.drop(['litigation','claim_no'],axis=1)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.30,random_state=42)
#free up memory
del df,y,X
#Class balance test and train
y_test.value_counts(normalize=True)
0 0.996355
1 0.003645
Name: litigation, dtype: float64
y_train.value_counts(normalize=True)
0 0.996285
1 0.003715
Name: litigation, dtype: float64
# Convert input data from numpy to XGBoost format
dtrain = xgb.DMatrix(X_train, label=y_train)
dtest = xgb.DMatrix(X_test, label=y_test)
#again to conserve memory
del X_train, X_test, y_train, y_testfrom sklearn.model_selection import train_test_split
import xgboost as xgb
## Testing Features against language vectors
# Model ICL_100F
df= pd.read_csv('claims_vectors_litigation.csv',
usecols=lambda x : x not in ['claim_txt','ICC'])
# Model ICC_100F
df= pd.read_csv('claims_vectors_litigation.csv',
usecols=lambda x : x not in ['claim_txt','ICL'])
# Model ICL_ICC
df= pd.read_csv('claims_vectors_litigation.csv',
usecols=['claim_no','ICL','ICC','litigation'])
#Model ICL_ICF_100F
df= pd.read_csv('claims_vectors_litigation.csv',
usecols=lambda x : x not in ['claim_txt'])
# Model 100F
df= pd.read_csv('claims_vectors_litigation.csv',
usecols=lambda x : x not in ['ICL','ICC','claim_txt'])
Training the Model
# Specify sufficient boosting iterations to reach a minimum
num_round = 5000
param = {'objective' : 'binary:logistic', # Specify binary classification
'eta' : .5,
'max_depth' : 8,
'predictor' : 'gpu_predictor',
#'verbosity' : 3,
'tree_method' : 'gpu_hist', # Use GPU accelerated algorithm
'random_state': 42
}
gpu_res = {} # Store accuracy result
tmp = time.time()
# Train model
tst_model = xgb.train(param, dtrain, num_round, evals=[(dtest, 'test')], evals_result=gpu_res)
print("GPU Training Time: %s seconds" % (str(time.time() - tmp)))INITIAL Results
Turning water into wine
model % non-lit claims % lit claims RMSE % predicted #predicted
ICC_100F 99.6355 0.3645 0.003138 0.0507 15
ICL_ICC_100F 99.6355 0.3645 0.003142 0.0503 15
ICL_100F 99.6355 0.3645 0.003267 0.0378 11
100F 99.6355 0.3645 0.003283 0.0362 11
ICL_ICC 99.6355 0.3645 0.003490 0.0155 5What do our results mean?
Text

Politely laugh at the image below
Why Recall?
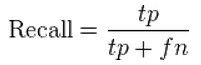
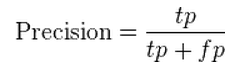
Test model on Less data!
.. A LOT LESS DATA
<class 'pandas.core.frame.DataFrame'>
Int64Index: 19895884 entries, 0 to 3432364
Data columns (total 12 columns):
step int64
action object
amount float64
nameOrig object
oldBalanceOrig float64
newBalanceOrig float64
nameDest object
oldBalanceDest float64
newBalanceDest float64
isFraud int64
isFlaggedFraud int64
isUnauthorizedOverdraft int64
dtypes: float64(5), int64(4), object(3)
memory usage: 1.9+ GBAccuracy by admission status
col_0 0 1 All
isFraud
0 19887444 54 19887498
1 3763 4623 8386
All 19891207 4677 19895884
Percentage accuracy
0.9998081512739017
Percentage Fraud caught
0.5512759360839494Train a new model
def split_search_pred(df):
# must change this to check if data is already in correct format.
# change / reshape data
df.drop(['isFlaggedFraud','isUnauthorizedOverdraft'],1,inplace=True)
df.rename(columns={'action':'type','oldBalanceOrig':'oldbalanceOrg','newBalanceOrig':'newbalanceOrig','oldBalanceDest':'oldbalanceDest','newBalanceDest':'newbalanceDest'},inplace=True)
#encode type
le.fit(df['type'])
df['type']=le.transform(df['type'])
#split into dependant and independant variable(s)
# T T S assign
X = df.drop(['isFraud','nameOrig','nameDest'],1)
Y = df['isFraud']
X_train, X_test, y_train, y_test = train_test_split(X,Y, test_size=0.25, stratify=Y, random_state=7351)
params = {'loss': ['deviance','exponential'],
'learning_rate' : [ .01, 0.1],
'n_estimators': [800],
'subsample': [.8],
'min_samples_split':[2],
'min_weight_fraction_leaf': [0,.1],
'max_depth': [2],
'tol':[0.00001],
'random_state':[7351]
}
xgb_model = xgb.XGBClassifier()
skf = StratifiedKFold(n_splits=10)
xgb_grid = GridSearchCV(xgb_model, params, cv=skf,scoring='recall',verbose=10)
start_time = time.time()
#Fit the Data
xgb_grid.fit(X_train, y_train)
print("--- %s seconds ---" % (time.time() - start_time))
return gridTest and evaluate
df1 = pd.read_csv('Run2.csv')
cost_df1 = model_data(df1,xgb_grid_opt)
def model_data(df,model):
# must change this to check if data is already in correct format.
# change / reshape data
df=df
df.drop(['isFlaggedFraud','isUnauthorizedOverdraft'],1,inplace=True)
df.rename(columns={'action':'type','oldBalanceOrig':'oldbalanceOrg','newBalanceOrig':'newbalanceOrig','oldBalanceDest':'oldbalanceDest','newBalanceDest':'newbalanceDest'},inplace=True)
#encode type
le = pp.LabelEncoder()
le.fit(df['type'])
df['type']=le.transform(df['type'])
#split into dependant and independant variable(s)
X = df.drop(['isFraud','nameOrig','nameDest'],1)
Y = df['isFraud']
print('Starting prediction')
#use model to predit
cost = model_evaluate(model,X,Y)
cost['nameOrig'] = df['nameOrig']
cost['nameDest'] = df['nameDest']
return costTest set accuracy:
Percent Type I errors: 0.0002624220326785749
Percent Type II errors: 1.8851297672463193e-05
Accuracy by admission status
col_0 0 1 All
isFraud
0 3339648 877 3340525
1 63 1357 1420
All 3339711 2234 3341945
Evaluation Contd
What do our results mean
Test set accuracy:
Percent Type I errors: 0.0002624220326785749
Percent Type II errors: 1.8851297672463193e-05
Accuracy by admission status
col_0 0 1 All
isFraud
0 3339648 877 3340525
1 63 1357 1420
All 3339711 2234 3341945
Type 1 and Type 2 Error represents waste
Represents the justification for keeping your job
Projected fraud department "case-load"
What do we do now?
cost_df1['isRefund'] = 0 #comment this out later, just to reset the refund column inbetween runs
cheat = cost_df1[((cost_df1['type']==1) | (cost_df1['type']==4)) & (cost_df1['fraud']==1)]
cheat.reset_index(inplace=True)
cheat.head(12)
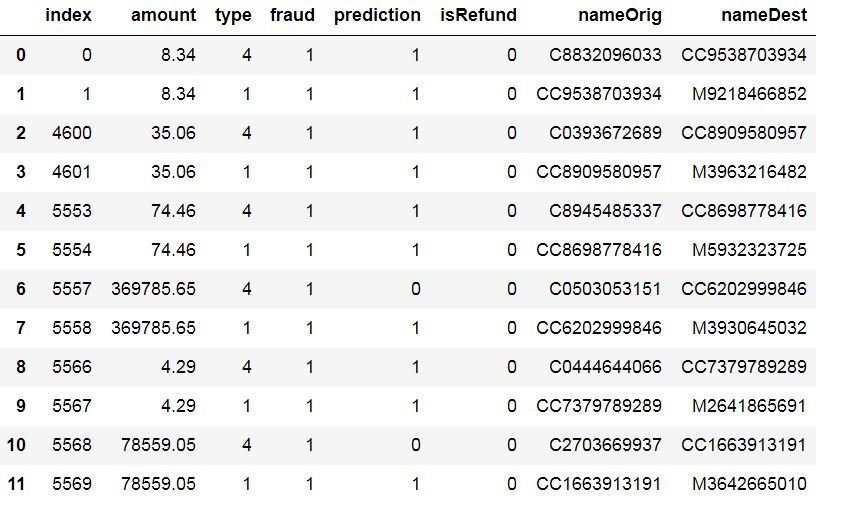
cALCULATING THE rEFUND
def adj_confmat(df):
for i in range(len(df.index)):
if i+1==(len(df.index)):
break
row = df.iloc[i,:]
# look for transfer transactions correctly predicted as fraud
if (row['type']==4) and (row['fraud']==1) and (row['prediction']==1):
# flag the transfer as being refunded
df.at[i,'isRefund']=1
#look at subsequent cash_out if it was "not caught" assume that it was because the transfer was caught
#ensure that the amounts are the same "not a realistic assumption insitu"
if (df.iloc[i+1,:]['type']==1) and (df.iloc[i+1,:]['fraud']==1) and (df.iloc[i+1,:]['prediction']==0) and (row['amount']==df.iloc[i+1,:]['amount']):
df.iat[i+1,'prediction']==1
# look for Cash_outs that were predicted, but the previous transfer was not caught
if (row['type']==1) and (row['fraud']==1) and (row['prediction']==1):
#look at previous transfer and set prediction to 1 as the
if (df.iloc[i-1,:]['type']==4) and (df.iloc[i-1,:]['fraud']==1) and (df.iloc[i-1,:]['prediction']==0) and (row['amount']==df.iloc[i-1,:]['amount']):
df.at[i-1,'prediction']=1
#print(df.iloc[i-1,:])
df.at[i,'isRefund']=1
#print("we found 1")
return df
test = adj_cheat(cheat)
Accuracy by admission status
col_0 0 1 All
isFraud
0 3339648 877 3340525
1 18 1402 1420
All 3339666 2279 3341945
test[test['isRefund']==1]['amount'].sum()
Dollars Refunded to Customers
2,851,462,501.44$
Percentage of Fraud Caught
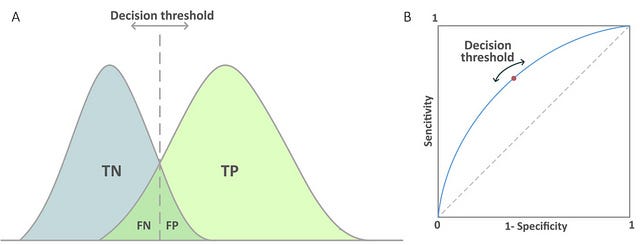
98.73%Decision Threshold
ARE WE DONE NOW? Is the answer ever yes?
df1_adj_eval = adj_conf(df1_fraud)
Accuracy by admission status
col_0 0 1 All
isFraud
0 3339648 877 3340525
1 18 1402 1420
All 3339666 2279 3341945
df1_adj_eval[df1_adj_eval['isRefund']==1]['amount'].sum()
Dollars Refunded to Customers
2,851,462,501.44$
Percentage of Fraud Caught
98.73%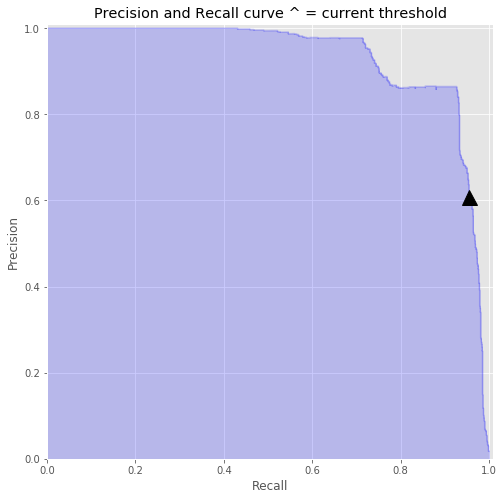
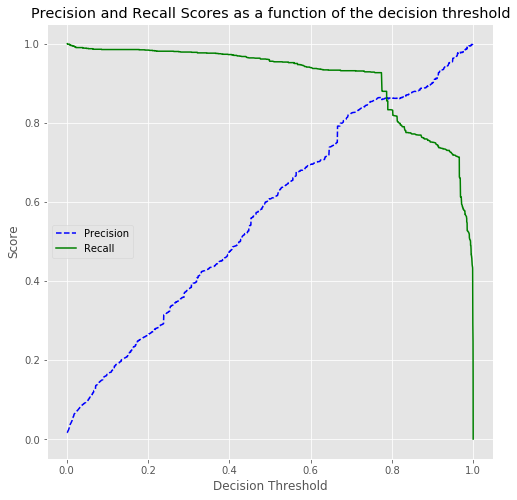
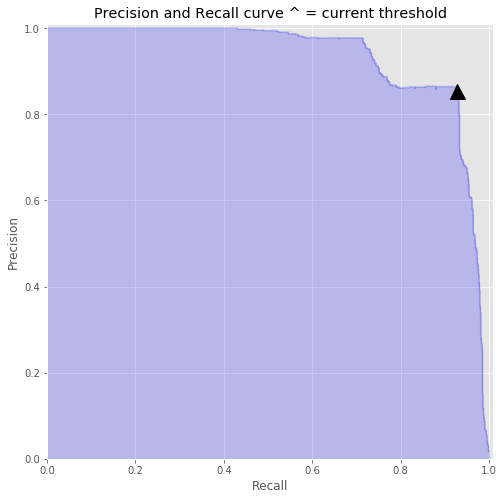
pred_pos pred_neg
pos 3340300 225
neg 102 1318
Adjusted for refunded transactions
Accuracy by admission status
col_0 0 1 All
isFraud
0 3340300 225 3340525
1 24 1396 1420
All 3340324 1621 3341945
# Dollars Refunded
$2,849,545,091.61
#Cost Difference between
#Decision Thresh = .75 and .5
$1,917,409.83
# Predicted Case Load difference
~ 610 Fewer casesDecision Threshold
With Refund
Final words
Lessons learned
pip install joblib
from joblib import dump, load
xgb_grid_opt = load('grid_opt_df1')# T T S assign
X_train, X_test, y_train, y_test = train_test_split(X,Y, test_size=0.25, stratify=Y, random_state=7351)
....
skf = StratifiedKFold(n_splits=10)
grid = GridSearchCV(clf, params, cv=skf,scoring='recall',verbose=10)Future work / Sources
- Applying Simulation to the Problem of Detecting Financial Fraud
- No Smurfs: Revealing Fraud Chains in Mobile Money Transfers
- FraudMiner: A Novel Credit Card Fraud Detection Model Based on Frequent Itemset Mining
- Fraud Detection within Mobile Money
- The Pay Simulator Github
- Fine tuning a classifier in scikit-learn
Thank you! :)
How does it work?

This is a stock image to look at while I talk at you.
Can language be used to detect if a patent will go to court
By Zak White
Can language be used to detect if a patent will go to court
Exploring Probability of Patent litigation as a Proxy for Patent Scope using Doc2Vec and XGBOOST

