Gestionando cent/miles de soluciones VoIP

Héctor Prieto
Gorka Gorrotxategi

Somos Irontec
16 años
60 personas en el equipo
Cientos de proyectos producidos con éxito
Miles de líneas de código escritas
Desde 2005 con el focus en VoIP
Varios productos importantes liberados:
IVOZProvider, SNGREP, IVOZBusiness ...


... y nosotros
Gorka Gorrotxategi
CTO
Héctor Prieto
Coordinador Soporte

Quizás nos conozcáis de otras charlas por aquí ;)


2009
Presentamos el MSCTL en primicia ;)
2016
Horizontal Escaling
Anycall2AnyAsterisk
2017
Automated Testing en aplicaciones VoIP/RTC
2018
Crónica de un viaje de Alta Disponibilidad

¿Por qué esta charla?
- Como en otras ocasiones, queríamos plantear algo técnico, pero sin alejarnos demasiado de la órbita terrestre ;)
- El año pasado, hablando con muchos de vosotros era el tipo de charla que nos pedíais, cómo gestionar las situaciones habituales, sin entrar en grandes escenarios avanzados ni nada especial.
- En 2019 los conceptos de los que hablaremos (automatismos, DevOps, escalado ...) están ya más que asentados.
- Y con ello, damos visibilidad a nuestro gran equipo de soporte, liderado por mi compañero Héctor Prieto, ¡gracias equipo!

Antes de empezar algunas de nuestras cifras...
- 5.000 Proyectos desplegados en total desde 2003.
-
Anualmente
- 1.800 clientes iteran con nosotros .
- 15.000 casos gestionados.
-
Infraestructuras
- 1.200 sistemas monitorizados.
- 36.000 servicios supervisados.
- Infra propia (AS BGP propio) y ajena, muchísimo networking.

¡Estas cifras no paran de crecer día a día gracias a nuestros clientes!
Nuestro equipo :)
- Técnic@s multidisciplinares
- Gente con ganas de hacerlo realmente bien
-
Somos técnicos y pensamos como tal (nada de 1,2,3)
- Cada problema puede resolverse de diferentes formas, hay que buscar la más eficiente o adecuada para cada cliente.
- Valor de equipo, mente colmena, la información reside en el organismo general
-
Objetivos basados en resultados de calidad
- Funcionando no significa resuelto.
- Apoyar la formación continua y certificaciones




- Mostrar flujos de trabajo habituales.
- Metodologias usadas y validadas por el equipo durante la resolución de problemas.
- Diferentes técnologias que explotamos para realizar diferentes tareas.
- Si quiere llevar a cabo cualquier tarea aqui mencionada consúltelo previamente con su equipo de técnico.
Consideraciones previas al consumo de VOIP

Los 3 Big Bosses a los que nos enfrentamos

- Cantidad
- Criticidad
- Diversidad

[I]Nuestras armas[I]
























Gestionando la cantidad...

- Se notifican decenas de situaciones constantemente:
- Alarmas generadas
- Intervenciones/nuevas solicitudes
- Consultas
- VoIP specifics
- Con todo lo que ello conlleva
El gran problema: la simultaneidad y variedad
Nuestro día a día
Entonces... ¿qué proponemos?

"El plan"
- Apostar por soluciones sostenibles SIEMPRE
- El problema de un cliente puede llegar a ser el de muchos
- Apostar por adelantarse:
- e.g. la calidad global de voz (MoS) es medible y debe hacerse
- Las claves:
- Procedimientos claros: Flujos que sigue la información
- Protocolos perfectamente definidos
- Desde Ingeniería debe hacerse llegar toda la información relativa a los despliegues, así como toda la documentación junto con la formación al equipo de soporte

La cantidad sólo se puede derrotar con: ORDEN ORDEN y ORDEN.
Distinguimos dos fases

- Fase Preventiva
- Fase Correctiva
Dentro de estos dos marcos de trabajo es dónde pondremos en práctica nuestro plan
Fase preventiva
-
Tareas desde el orden y la tranquilidad
-
Actualizaciónes de software
- Repositorios propios / externos
- Todo está paquetizado/dockerizado
-
Mantenimientos de hardware
- Checks propios basados en datos SMART/lifetime esperada
-
Gestión Documental
- Documentación actualizada
- Flujo continuo con ingeniería
-
Propuestas de mejora/updates
- Nada es para siempre
-
Actualizaciónes de software

Fase combativa correctiva
- Suenan las alarmas!
- We are working on it!
- Informar al cliente
- Análisis del problema
- Gráficos de estado/rendimiento
- Logs y capturas de los sistemas
- Diagnostico diferencial
-
Comprensión real del problema
-
¿Reinicia y listo?
NO, NO, NO, NO- JAMÁS!
- Bajo pena de prisión permanente revisable.
- Call GDB Ninjas!
-
¿Reinicia y listo?


Vale, lo tengo... ¿Ahora qué?
- Evaluación del impacto de la solución
- Aplicación definitiva de la solución
- ¿Puede desplegarse ahora en el cliente?

- Una vez aplicada la solución:
- Tests funcionales
- Informar al cliente
- ¿Ya lo había dicho ? :)
- Documentar
- Si varios proveedores gestionan la solución, mantener informado al cliente es clave
Reflexiones post apocalípticas
- Está solucionado y funcionando. Pero JAMÁS se acaba ahí el proceso, hay que plantearse:
-
Problema NO detectado
- ¿Podría haberse detectado? ¡Seguro que sí!
- Opciones de control
- Generar marcadores o indicadores, entender si es algo tipo "abismo instantáneo" o "bañera que desborda" ;)
- Documentar, documentar y documentar
- ¿Podría haberse detectado? ¡Seguro que sí!
-
Problema detectado
- ¿Esto puede llegar a suceder en otro cliente?
- Propagar la solución al resto de clientes
- ¿Esto puede llegar a suceder en otro cliente?
-
Problema NO detectado
El trabajo NUNCA acaba aquí.
Conviviendo con la diversidad

Evolución de las infraestructuras VOIP
En Irontec hemos seguido el mismo path que much@s de vosotr@s:
- En los inicios pequeñas empresas, entornos con menos integraciones, menos networking.
- Evolucionando paulatinamente:
- Decenas de sedes, networking propio (MPLS, VPNs, L2's, ...)
- Integraciones complejas
- Arquitecturas HA, híbridas...
- Soluciones de operador, wholesale... alto tráfico en definitiva
Cada cliente requiere de un tipo de sistema de telefonía que puede acabar evolucionando y los tiempos cambian.


- Diferentes conceptos de arquitectura que evolucionan con el tiempo y específicos de cada criterio:
- Cloud propio, Cloud ajeno, híbrido, full in-House.
- Diferentes usos:
- Multitenancy, dedicado
- Diferentes enfoques
- Virtualizado, dockerizado ...
- Diferentes tecnologías
- VMWare, Citrix, Hyper-V, Proxmox(KVM)
- Diferentes proveedores (empresas partícipes)
- Cloud Storage, BBDD, Networking ...
- En definitiva, mucha ingenieria social :d





Arqui/Infra VoIP: Evolución continua


En búsqueda del Santo Grial

- Carta a los reyes magos
- Multi-entorno
- Fácil gestión
- Fácil uso
- Sin agentes
- Libre
- Flexible
- Algo actual, vivo, sin EOL
- Algunos de nuestros pasos para gestionar la diversidad
-
Puppet
- Requiere agente en todos los nodos
- Compleja programación de escenarios / no tan flexible
-
Lo seguimos usando:
- Integrar Foreman como inventariado de fácil acceso
-
Chef
- Poca flexibilidad, requiere de tareas programadas
- Uso complejo
-
SaltStack
- Requiere agente en todos los nodo
... por dónde hemos ido pasando

ANSIBLE, tu nuevo mejor amigo
- ¿Por qué ansible?
- No requiere de agentes, ssh y fin
- Flexible y programable, hooks por todos los lados
- Fácil de mantener
- Pocos Requerimientos de mantenimiento
- Gestionar listados de máquinas
- Integración con datos de negocio (ERP's) / herramientas de inventariado (Foreman)
- Gestionar Playbooks
- Definición de tareas/automatismos
- Gestionar listados de máquinas

Playbooks
- ¿Qué nos permite hacer?
- Básicamente: alcanzar la simultaneidad desde la centralización
- Despliegue de software
- Si lo queremos exclusivamente para esto quizás Puppet sea mejor camino
- Activación de automatismos (cambios config)
- Obtención de información que escapa al concepto de inventariado
- Todo ello de forma scripteable, con hooks, control de errores
- Despliegue de software
- Básicamente: alcanzar la simultaneidad desde la centralización

Entendiendo la criticidad

... criticidad es monitorización
- Es el corazón del equipo de soporte
- Aporta una visibilidad TOTAL de la salud de los sistemas
-
Herramienta vital para:
- Medir SLA's y actuar en consecuencia
- Ver evolución.
-
Podemos adelantarnos a los problemas
- Esto aporta un valor añadido increíble
-
Como todo, los excesos...
- Es mandatory tener bien controlado el bosque, evitar que la niebla nos nuble la vista ;)
Lo admitimos, estamos OBSESIONADOS.
Y creemos que así debe ser :)
- Monitorización/actuación local
- Monitorización remota
Diferenciamos dos tipos
¿Qué nos aporta cada una de ellas?
Monitorización local descentralizada
Nuestra visión:
- Nos permite obtener información del host de forma rápida
- Nos permiten actuar de forma local sin depender del entorno remoto (tipo watchdog)
-
Inconvenientes:
- Los entornos están tendiendo a containerización , donde todo es efímero y todo está orquestado "por alguien"
- En caso de desastre, pierdes el acceso a esa información [Forensic IT]
- Las alertas las genera el propio host donde esta instalado, en caso de fallo...

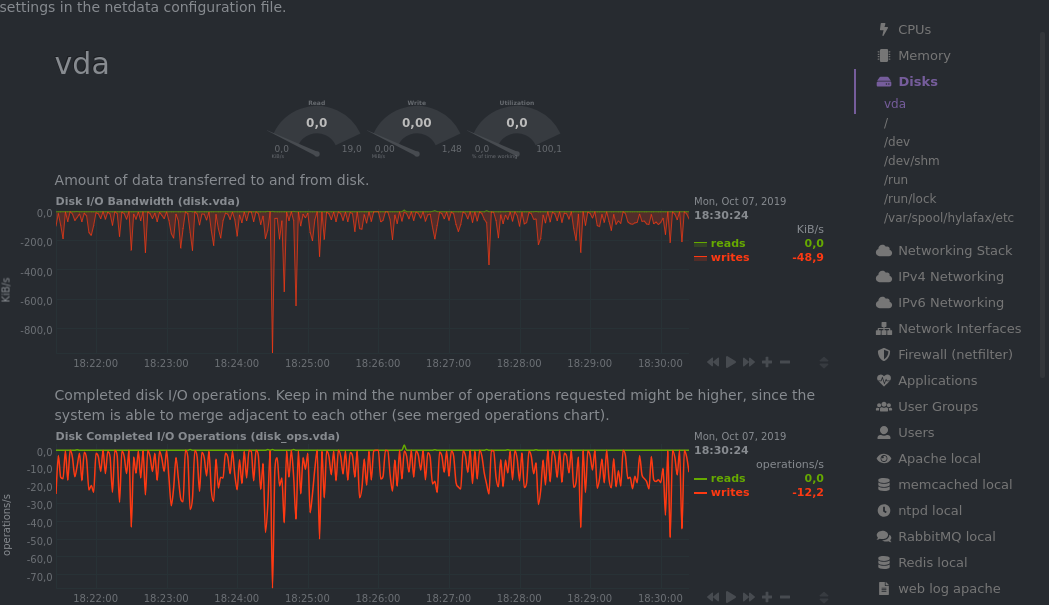
Netdata
- Standalone option
- Low footprint
- Tons of metrics
- Zeroconf ;)
- Very pluggable
- One-line install

Observium
- SNMP
- Network oriented
- Tons of metrics
- Auto discovery
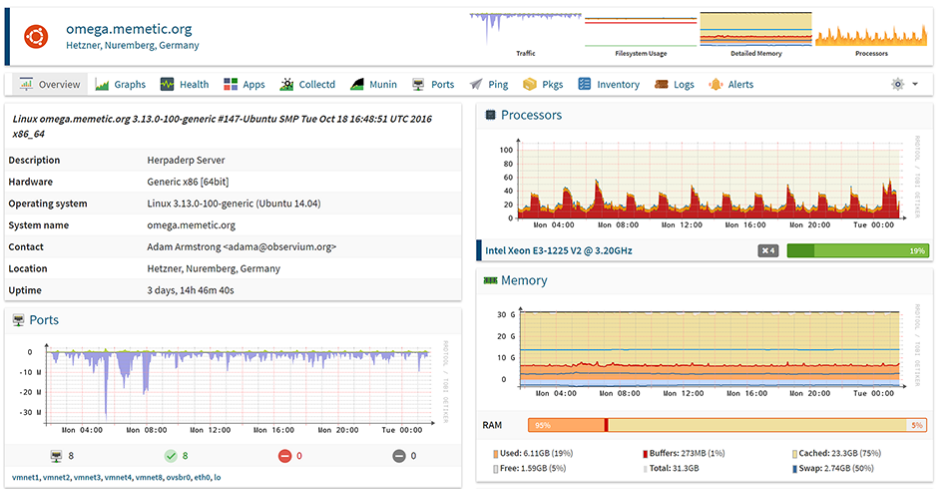


¿Los descartamos entonces no?
- Definitivamente no
- Pueden convivir perfectamente con otros sistemas centralizados mas avanzados
- Aportan información extra
- Bajo (ínfimo) consumo de recursos.
- En caso de total aislamiento [OON] seguimos recopilando información

Monitorización remota centralizada
Es el modelo de monitorización por excelencia.
Toda la información agrupada en un único sistema lista para ser explotada.
- "Escalabilidad" -
En caso de desastre tenemos toda la información.
Existen multitud de opciones, todas ellas con sus pros y contras:
- Pandora FMS
- Icinga
- Zabbix
- Monit
- DataDog
- SpiceWorks
- Centreon



Pero antes....
El enfoque habitual es monitorizar los recursos/procesos del host/instancia sin tener en cuenta la finalidad de la misma:
ESTO NO GARANTIZA NADA
- CPU
- Load
- Memoria
- FS usage
- iface's status
- Process status

Monitorización sí, pero con SENTIDO
Una instancia es más que una máquina, es un servicio, es una funcionalidad y es precisamente así como lo tenemos que tratar

"Estar vivo no significa vivir"
- Un host que actúa como una PBX, tiene que ser capaz de llamar.
- Un host que actúa como GW tiene que ser capaz de encaminar.

Monitorización avanzada
-
Monitorización de tráfico por tipo
- Menos tráfico SIP|RTP del esperado puede ser un problema, más trafico lo mismo
-
Soluciones de storage remotas: NFS / CIFS / XXX en estado R/W correcto
- El talón de Aquiles de muchas plataformas es el I/O
- Media de calidad de llamadas!
- Control de llamadas de alta tarificación
- Actividad real de procesos
- Ocupación de canales en integraciones con PSTN via TDM-SIP
- CPU Idle Time
- BBDD accesible y con buena salud (CPS, Slow Queries ...9
- Llamadas reales BlackBox SIP (BBS! It's free!) [!] A pesar de todo, Alice tiene que ser capaz de llamar a Bob
Obtener la visión gráfica
- El ser humano es muy visual en general y sobre todo ante situaciones de stress
- Una tabla de 20 líneas y X columnas no aporta jerarquía ni concepto de arquitectura
- Un esquema siempre aporta información geográfica, datos de dependencias e información contextual vital
- Si esto lo unimos con la diversidad de entornos, arquitecturas, integraciones con empresas, verlo gráficamente es vital
Un esquema vale más que mil tablas
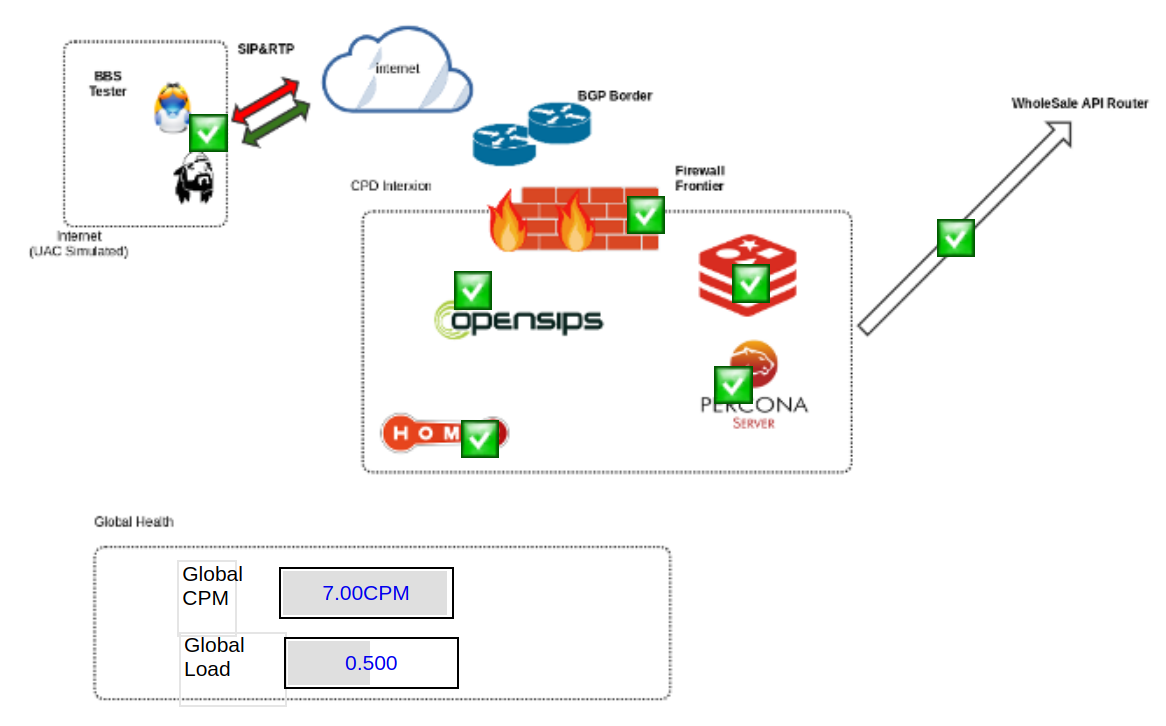
Obtener la foto del pasado
-
Es muy habitual que un problema sea reportado a tiempo pasado:
- Casos que no suceden constantemente
- No son reproducibles
- Gracias a toda la información que hemos recopilado durante todo este tiempo podemos analizar el caso concreto sin molestar al cliente

¿Puedes repetir la secuencia que ha provocado el error mientras el resto del mundo se comporta exactamente igual que cuando ha sucedido, por favor?
Métricas, métricas y métricas sobre las métricas
La diferencia entre...
- "Esto no va muy fino..."
- "El proceso principal está atorado"
- "No se qué pasa, pero algo pasa"
... y...
- El proceso XXX tiene un memory leak y está consumiendo más y más memoria
- El cliente X tiene un pico de llamadas anormal
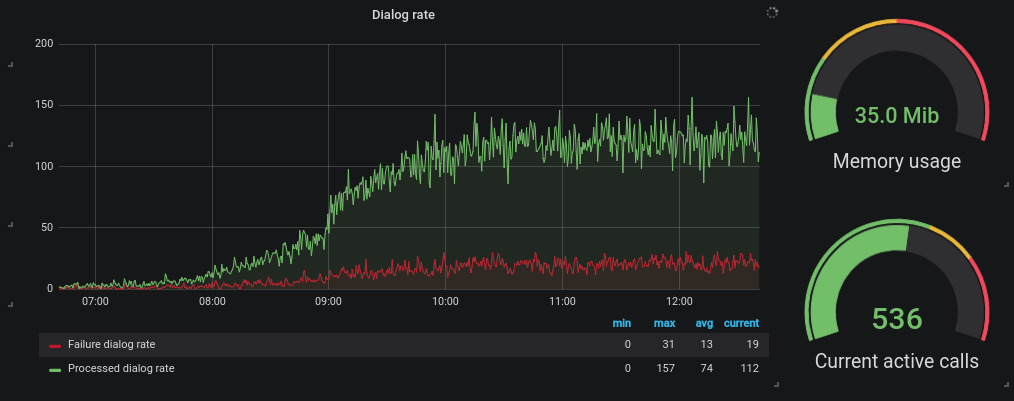
Señalización SIP
-
Homer Sip Capture
- Resumen de flujos RTP
- Jittter
- Packet Loss

Crash debug
- GNU Debugger (GDB)
Logs de actividad
- ELK Stack!
Métricas
- TICK stack (y variantes ;)


Arquitectura
- 4 componentes:
-
Collectors
- Telegraf, Netdata, custom...
-
Time series databases
- InfluxDB, Prometheus
-
Frontales web
- Chronograf, Grafana
-
Alert systems
- Prometheus Alertmanager, Kapacitor, Grafana
-
Collectors
- Cada punto es un mundo
- Las alternativas son compatibles entre sí
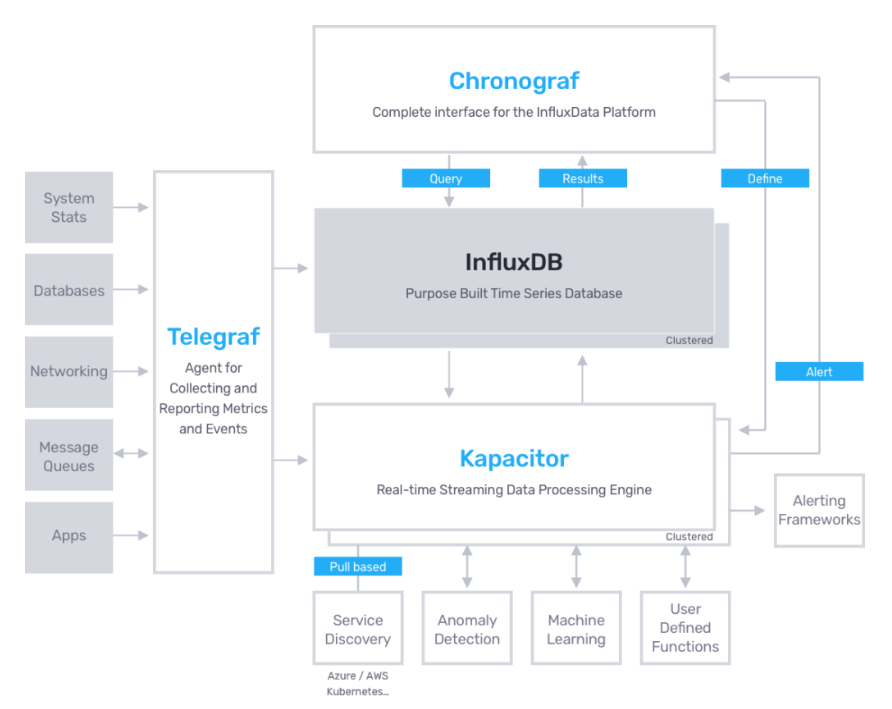
TICK stack example architecture
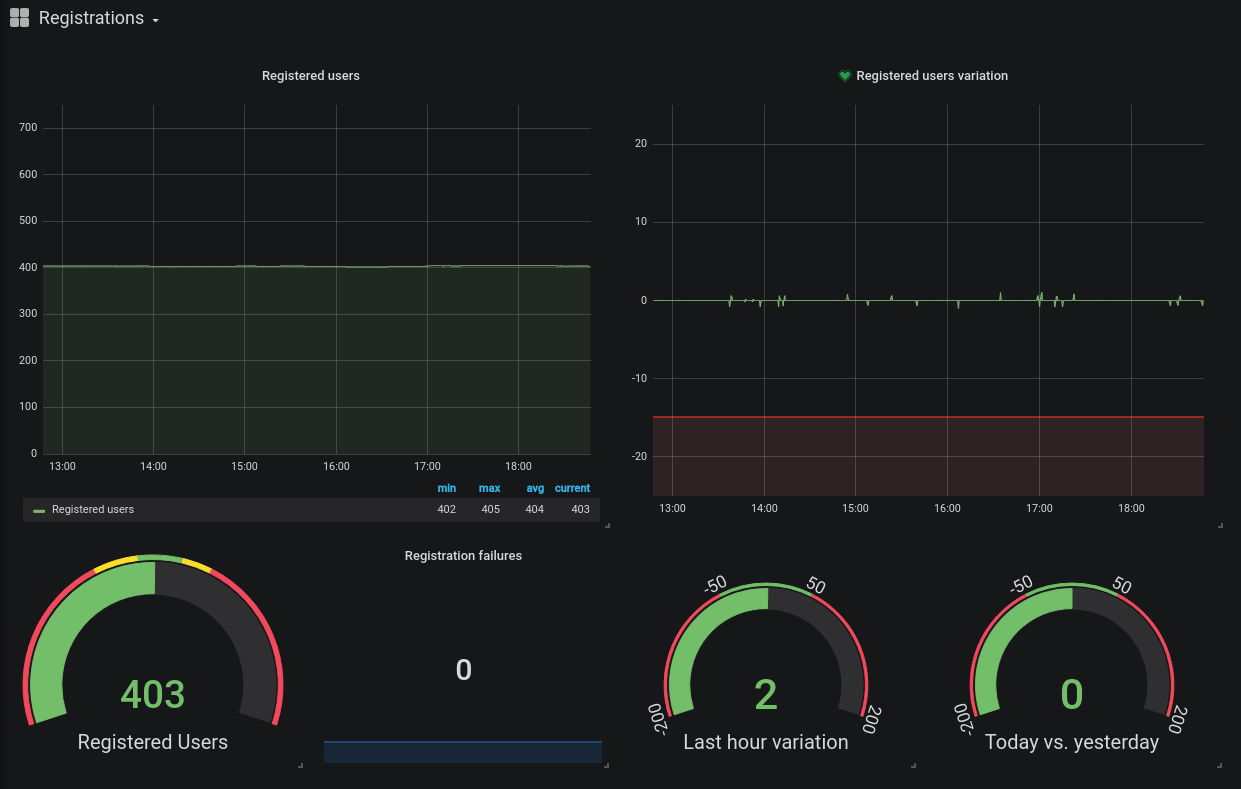
Ejemplo 1 - Registros SIP
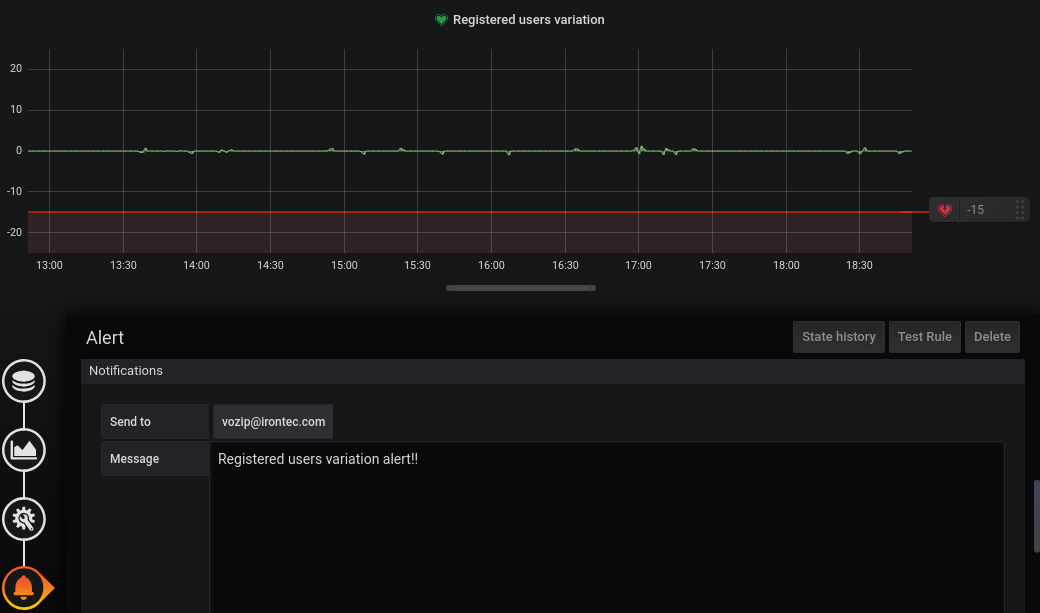
Ejemplo 2 - Alertar ante caídas abruptas del número de registros SIP
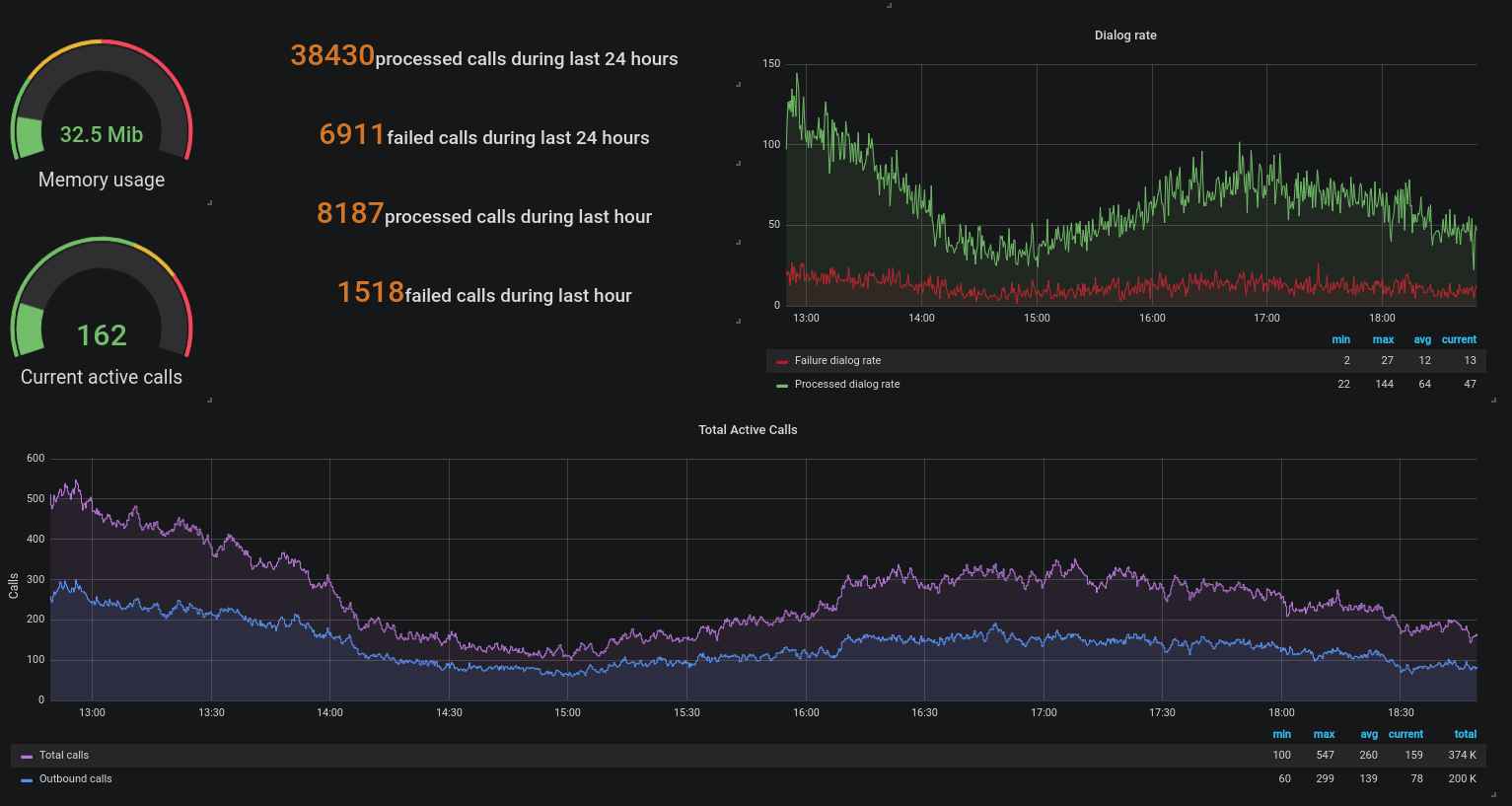
Ejemplo 3 - Uso de canales
En conclusión...
- Claramente marca la diferencia:
- Podemos dar una explicación sólida, técnica y racional de QUÉ y POR QUÉ ha sucedido
- Los datos nos avalan:
- Un respuesta sólida acompañada de toda esta información aporta al cliente SEGURIDAD
- Trasladar con todo lujo de detalles el tratamiento del caso.
- El análisis detallado del problema siempre aporta (+), nunca resta (-).
- NO es una pérdida de tiempo
- Podemos descubrir la punta del Iceberg
- Nos hace crecer como profesionales y como proveedores
- Siempre tenemos que valorar peso del servicio vs debug control
- No podemos parar un callcenter de 500 personas para debuggear tranquilamente ;)

¡¡¡ DEMO TIME !!!

¡¡¡ DEMO TIME !!!
-
Queremos ilustrar/enseñar:
-
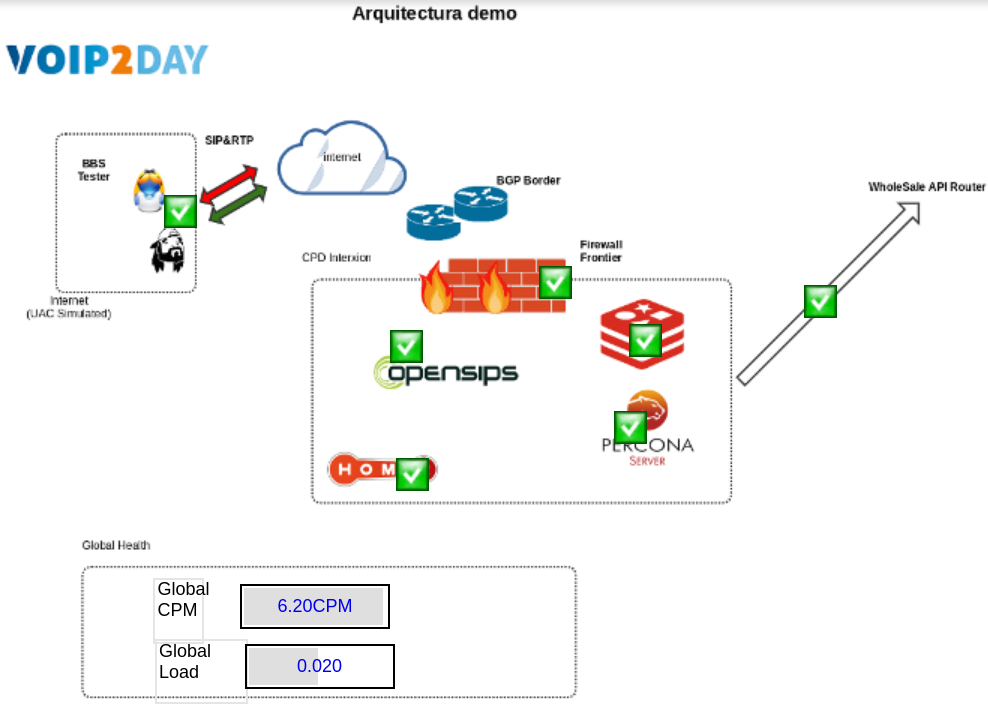
Monitorización externa automática tipo "blackbox" SIP End to End
- Y todo con contextualización de la información de soporte, de forma integrada
- Facilidad de obtener gráficas de rendimiento con todas las herramientas basadas en bbdd time series (InfluxDB)
-
Monitorización externa automática tipo "blackbox" SIP End to End

CONCLUSIONES FINALES
- Bajo nuestra experiencia:
- Las plataformas VoIP no difieren de otros sistemas "tics" en cuanto a diversidad y cantidad se refieren.
- Su gestión diaria se resuelve con el mismo enfoque que aplicaríamos en los casos generales.
- Los problemas habituales de las plataformas de voz son muchas efímeros:
- Es fundamental tener knowhow y herramientas que aporten:
- Visión en tiempo real de forma gráfica y aplicada de forma concisa a todo lo relacionado con la calidad de voz.
- Foto en el pasado enriquecida.
- Es fundamental tener knowhow y herramientas que aporten:
- Las plataformas VoIP no difieren de otros sistemas "tics" en cuanto a diversidad y cantidad se refieren.
¡Muchas gracias!


Gestionando centenares de soluciones VoIP
By zgor
Gestionando centenares de soluciones VoIP
Presentación Irontec en el VoIP2Day 2019.



