Ассоциативные правила для геренации
рекомендаций для решений в сфере eCommerce на базе технологий Big Data
Быковский Александр
Senior Java Developer
Grid Dynamics, Харьков
skype: alexandr_bikovskiy
email: control.eight@gmail.com
Что на повестке дня?
- Что такое ассоциативные правила в общем
- Популярность ассоциативных правил
- Майнинг ассоциативных правил
- Примеры
- Вопросы
Ассоциативные правила
X ⇒ Y
где X и Y являются наборами
Подгузники ⇒ Пиво

Нутелла + Хлеб


Примеры использования

Заявил об использовании ассоциативных правил в статье:

+

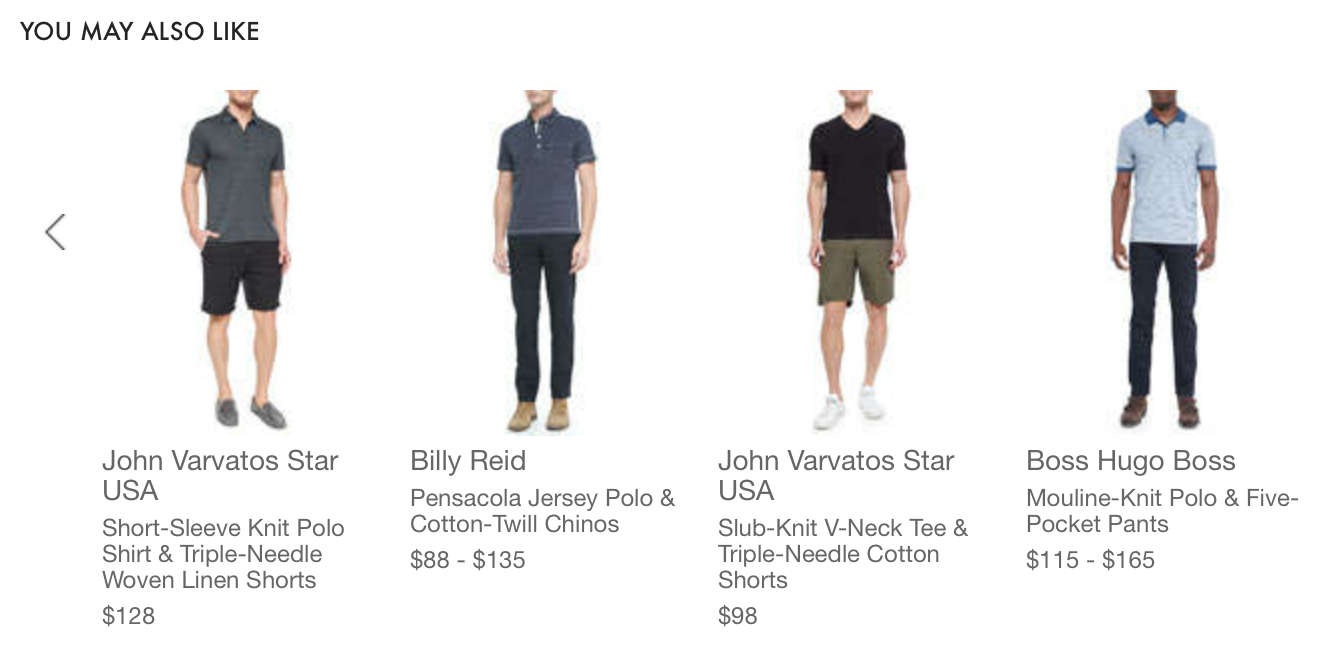
Заказчиками решения являются:


Популярность
12,541 результатов по запросу: "association rules"
9,464 результатов по запросу: "collaborative filtering"



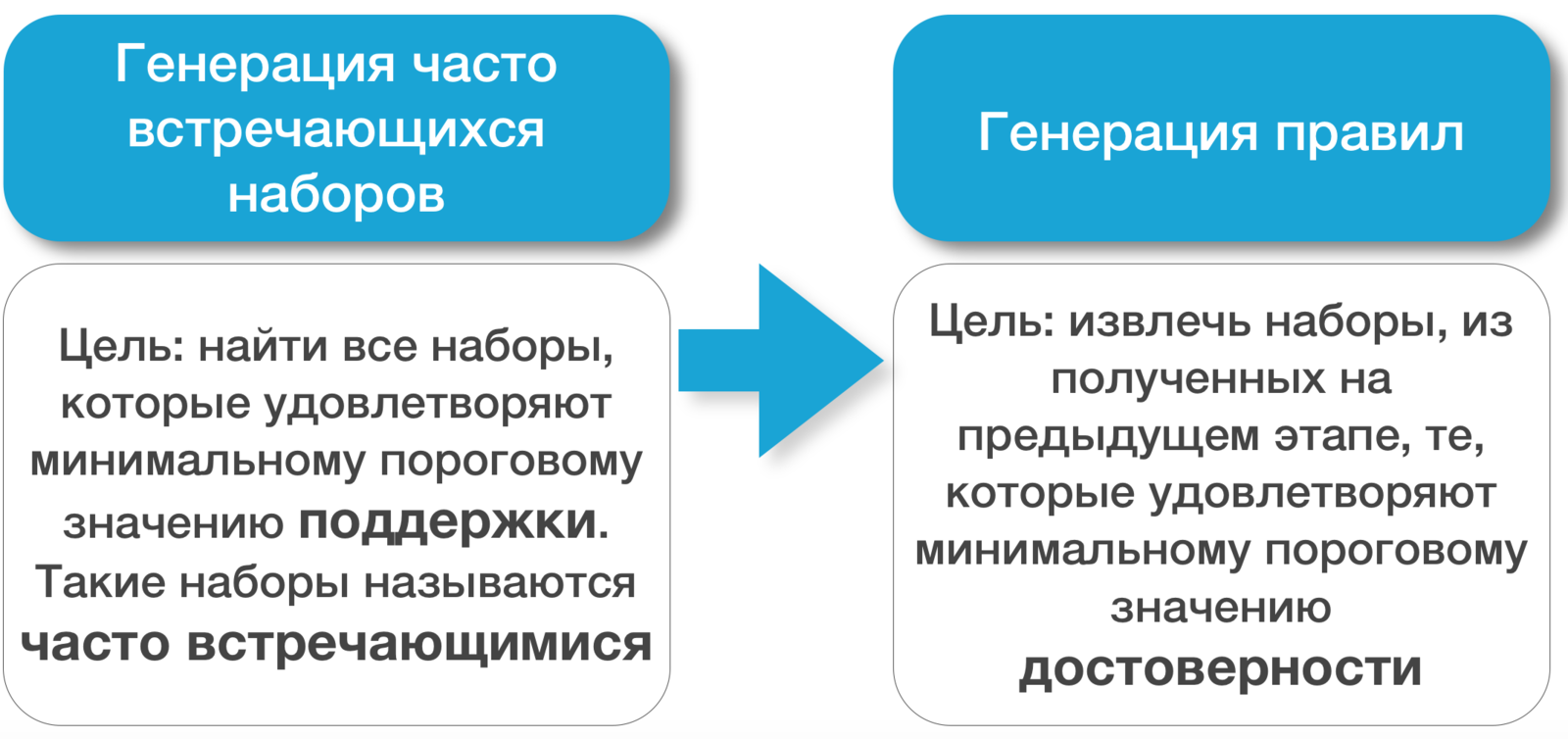
Самая распространенная стратегия майнинга ассоциативных правил:
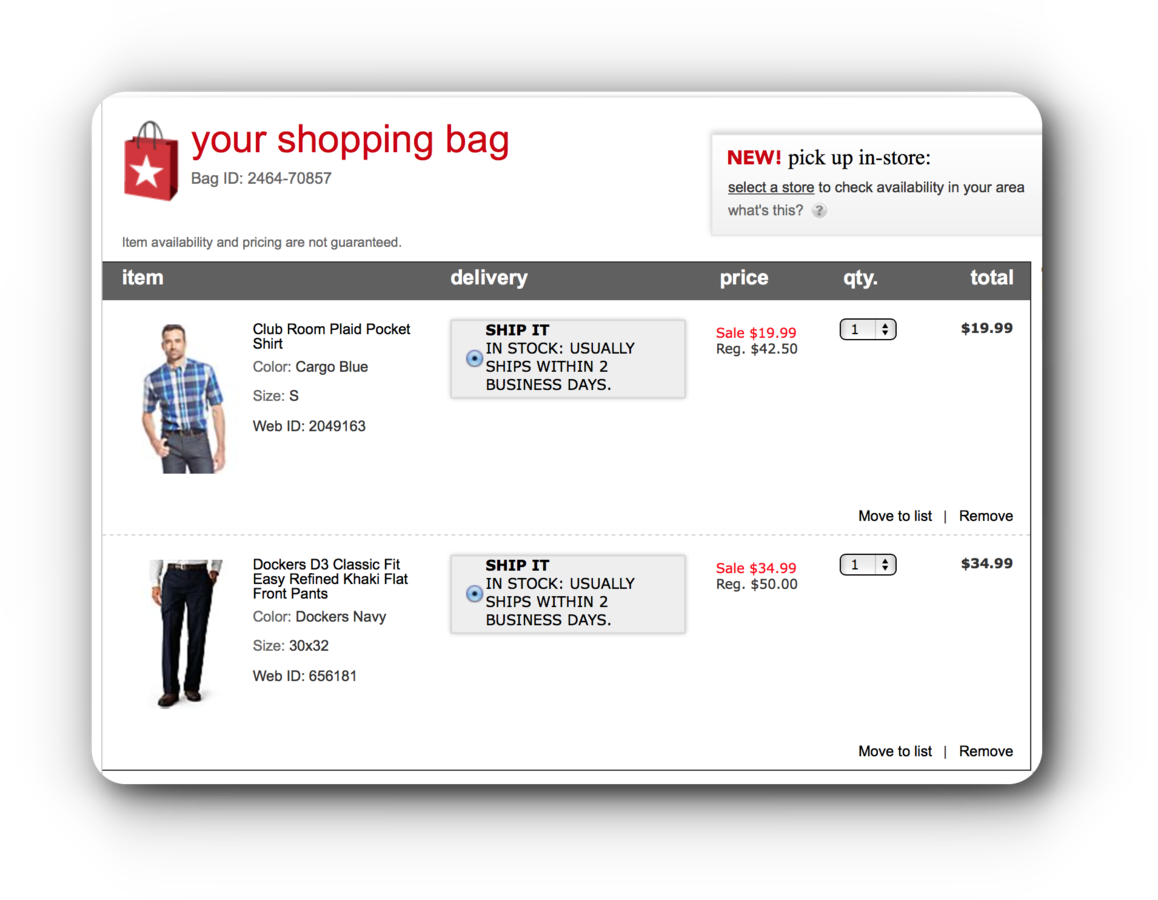
Анализ рыночной корзины
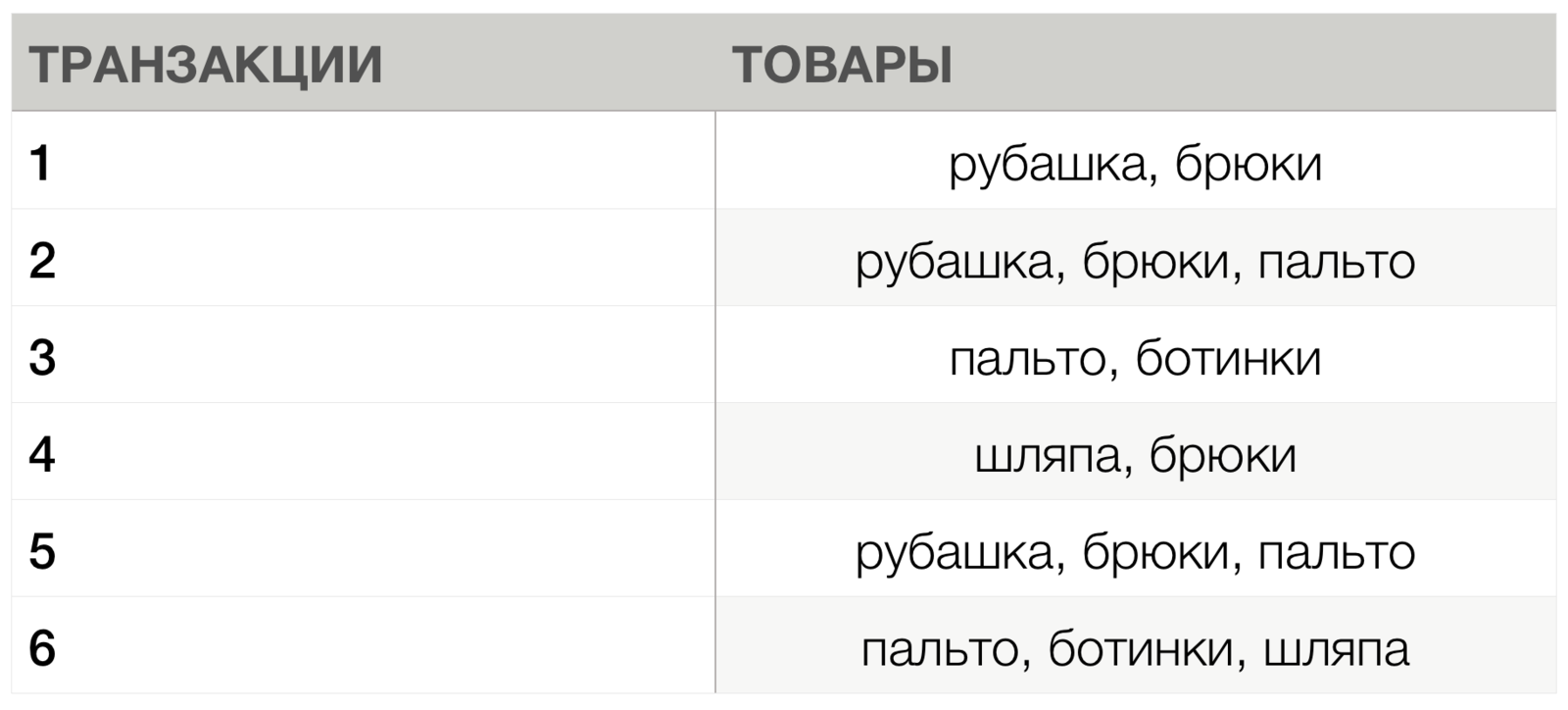
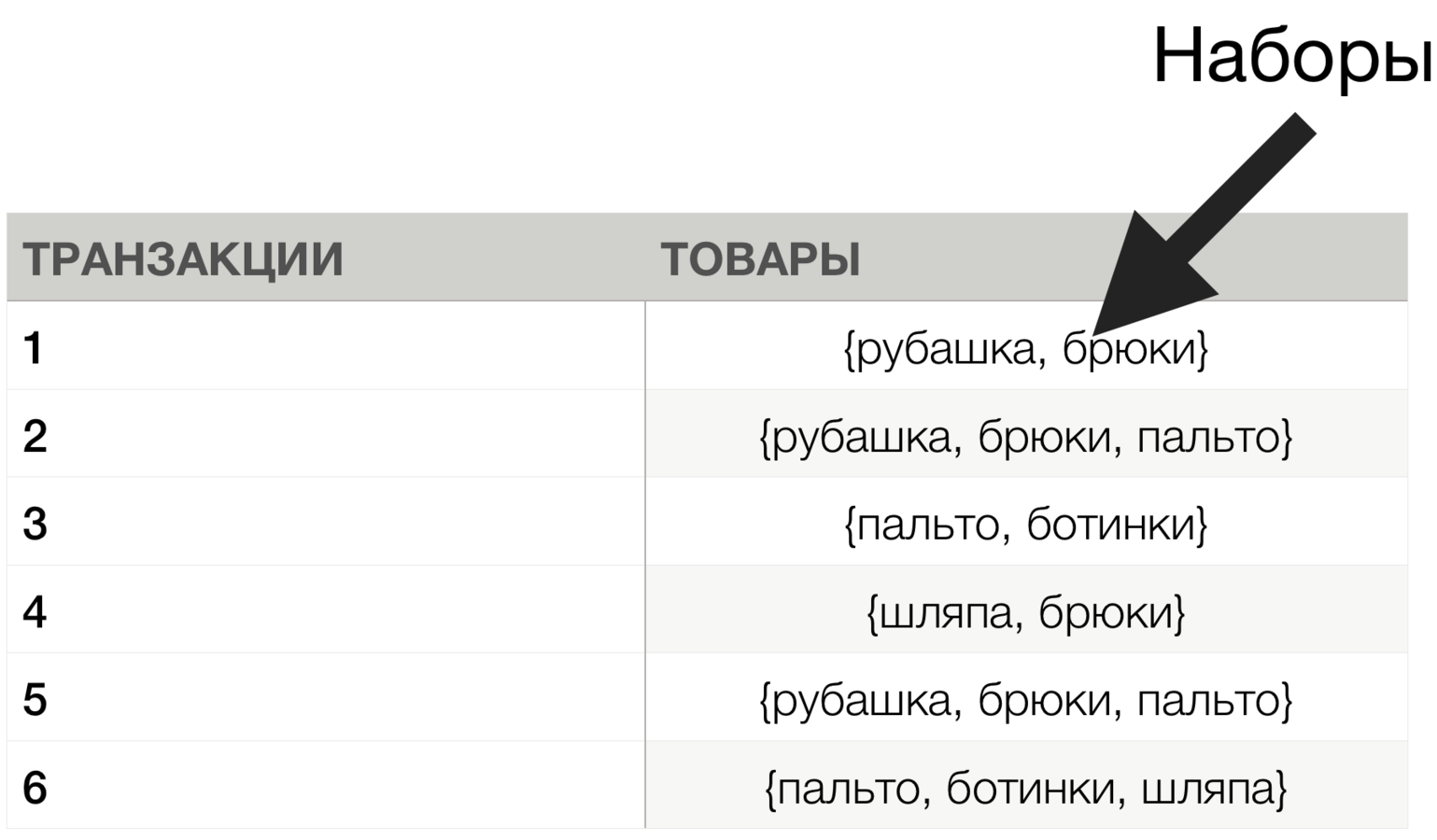
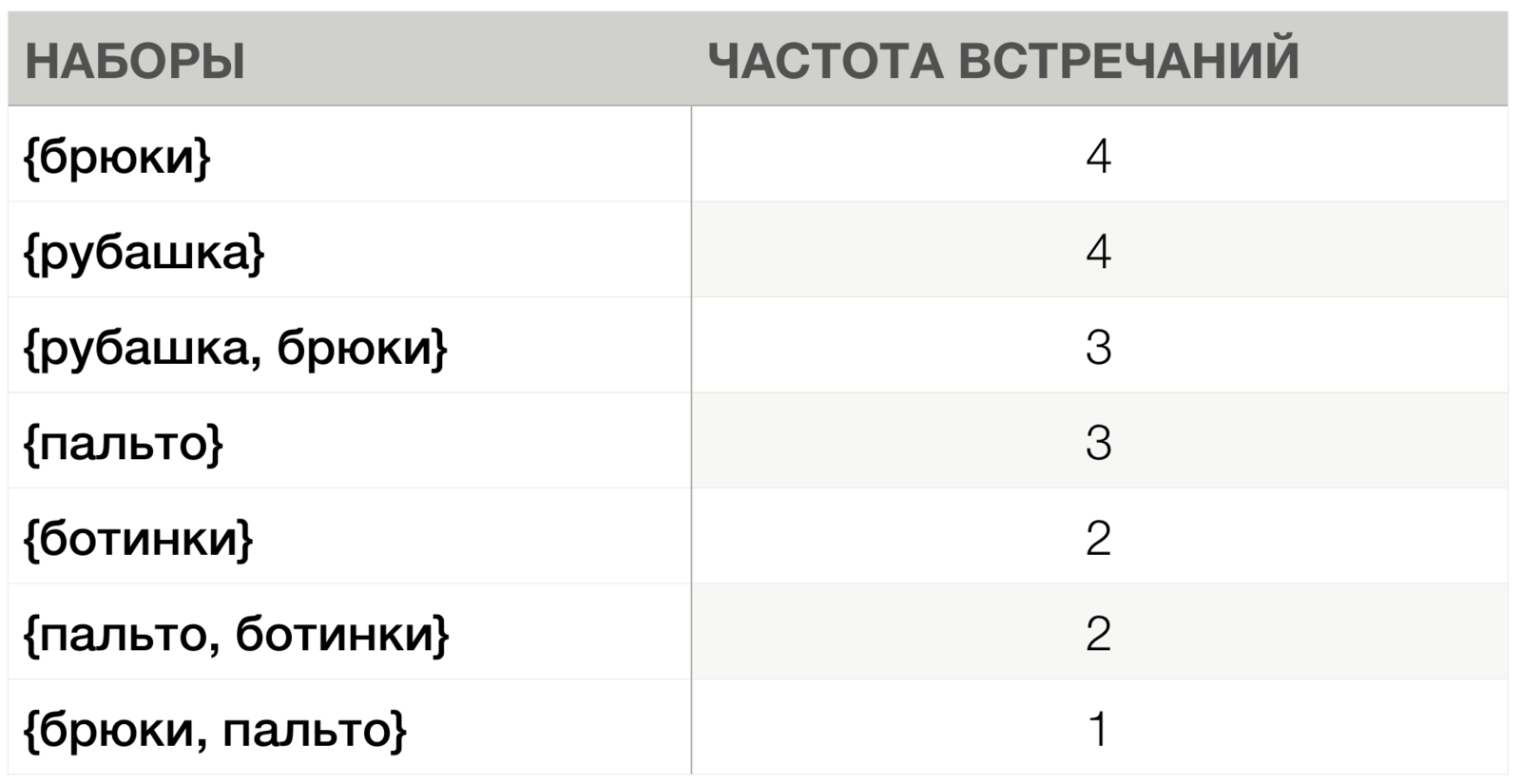
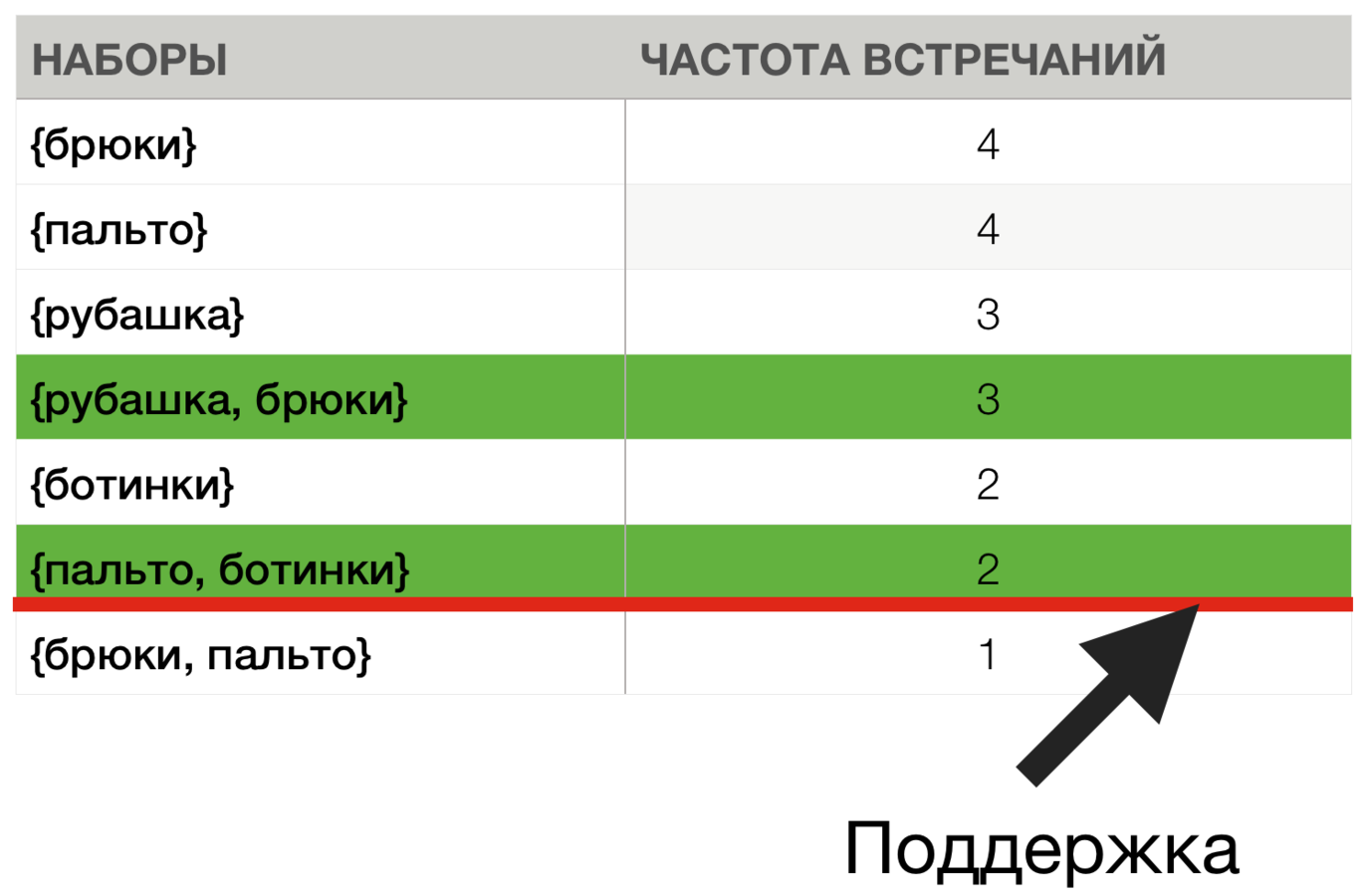
Мин. поддержка = 2
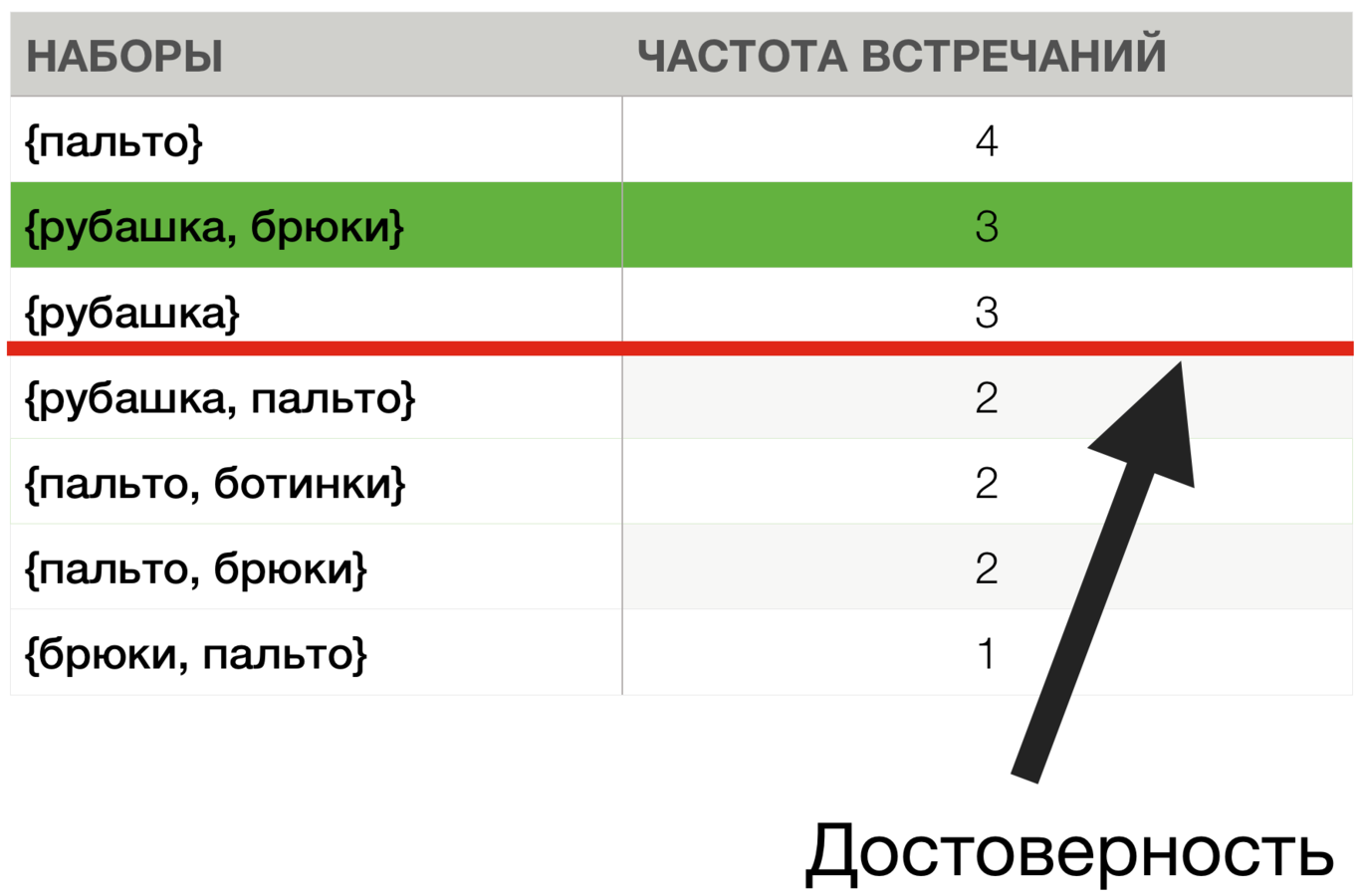
Мин. достоверность = 1.0 (100%)
{рубашка} ⇒ {брюки}
{брюки} ⇒ {рубашка}
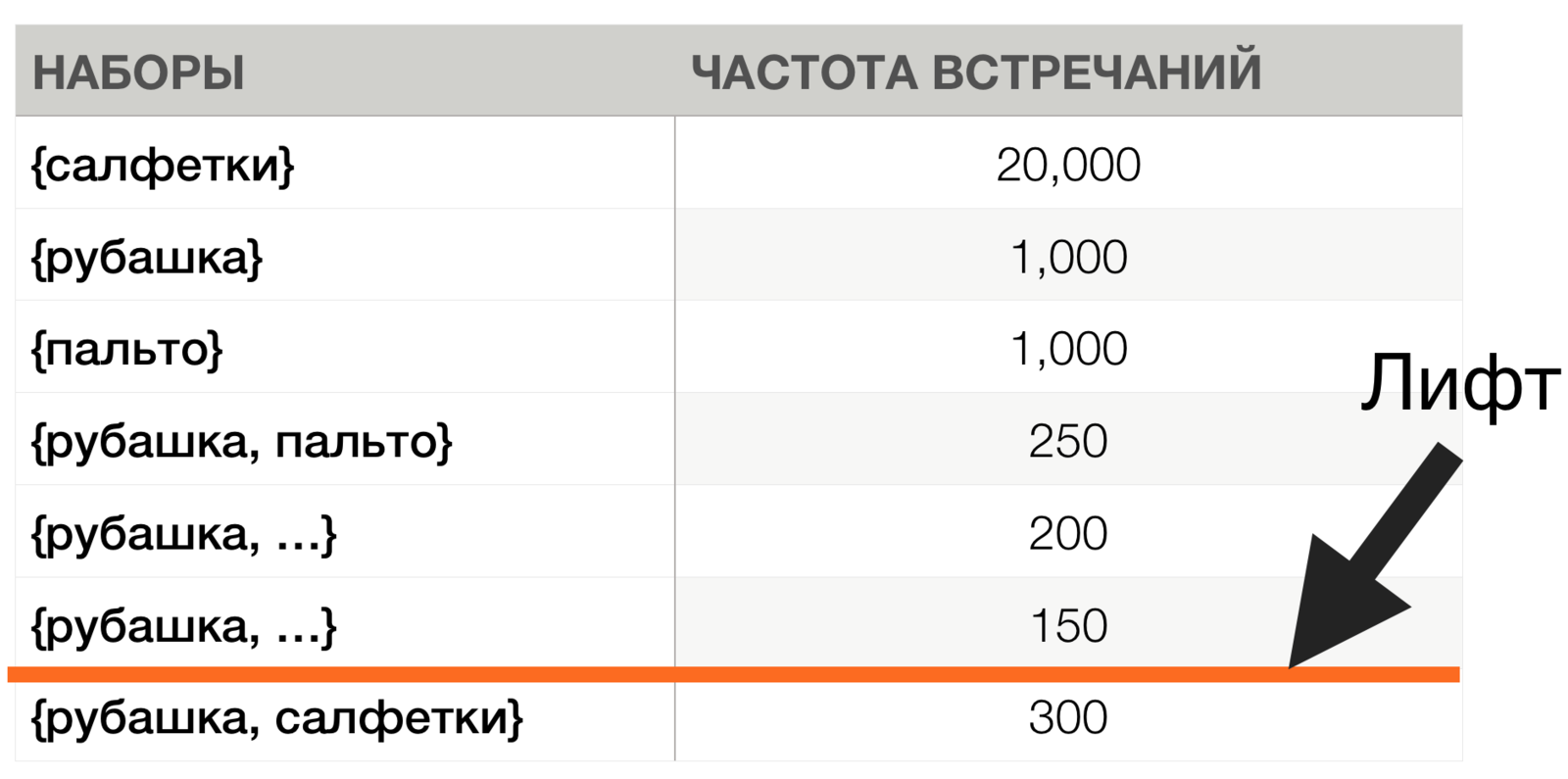
Ассоциативные правила
Общее кол-во транзакций = 100,000
Лифт({рубашка, пальто}) = 25
Лифт({рубашка, салфетки}) = 1.5
Минимум = 1.0 но лучше = 2.0
Формальное описание
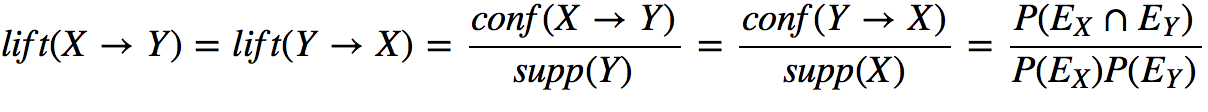
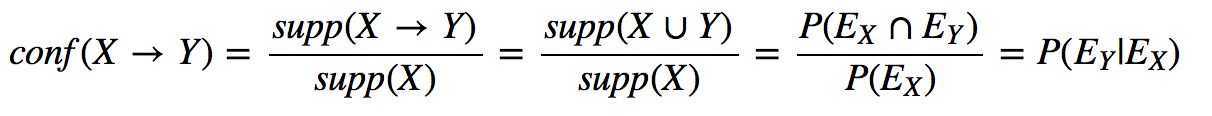


Анализ сложности

Кол-во транзакций = n
Размер наборов = k
Сочетания:
k <= 3



Тразакция (4) = {пальто, рубашка, брюки, шляпа}, n = 4
= 4
= 6
= 4
14 наборов
Тразакция (10) = 65,
Тразакция (100) = 5150
В сумме может достигать 5,000,000,000 наборов
Transaction (10) = {пальто, рубашка, брюки, футболка, ....}
= 10
= 45
= 10
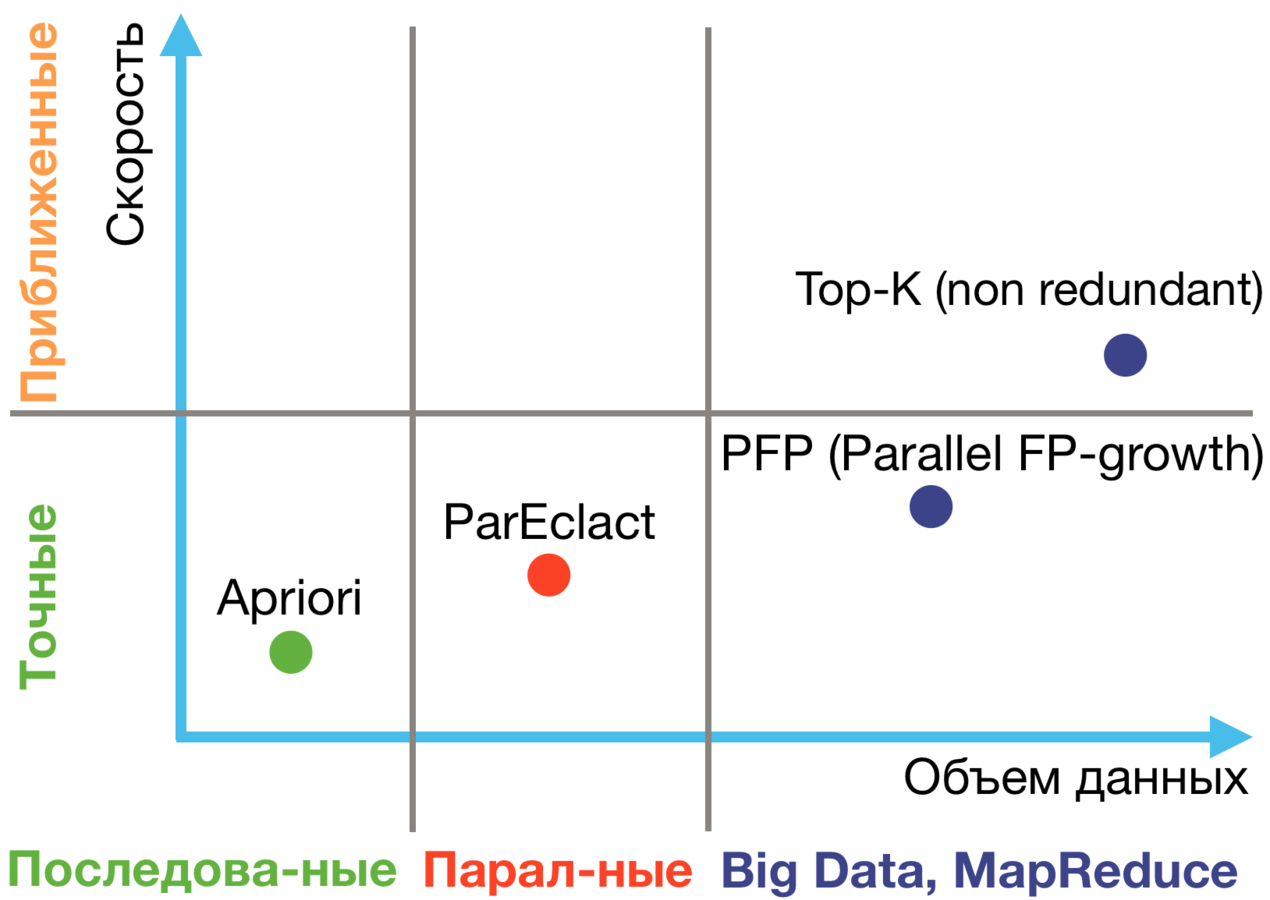
Алгоритмы
Apriori, Eclact (Equivalence CLAss Transformation) - классические алгоритмы
FP-growth - позволяет значительно экономить память, быстрее аналогов
Dist-Eclact, ParEclact, PFP (Parallel FP-growth) - аналоги, разработанные для параллельных вычислений, подходящий для BigData. PFP используется в Spark MLlib
Top-K (Non Redundant) Association Rules - подходящий для BigData. Используется в решении от Predictiveworks, реазизованного на Spark (spark-arules)
Примеры использования


Вначале пару слов о
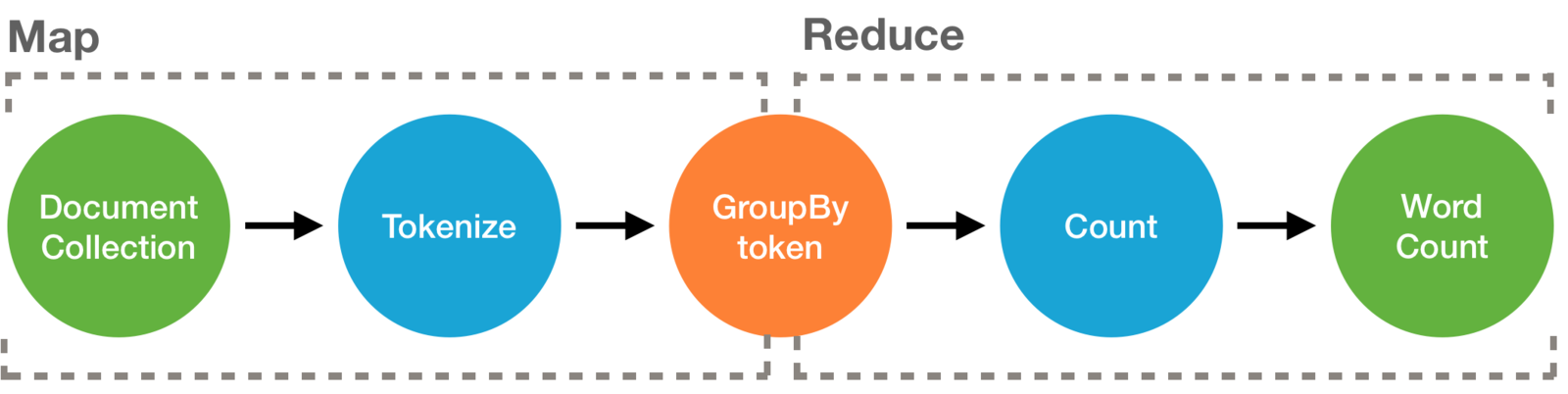
class WordCountJob(args: Args) extends Job(args) {
TypedPipe.from(TextLine(args("input")))
.flatMap { line => tokenize(line) }
.groupBy { word => word } // use each word for a key
.size // in each group, get the size
.write(TypedTsv[(String, Long)](args("output")))
// Split a piece of text into individual words.
def tokenize(text : String) : Array[String] = {
// Lowercase each word and remove punctuation.
text.toLowerCase.replaceAll("[^a-zA-Z0-9\\s]", "").split("\\s+")
}
}Пример кода для решения классической задачи "Word count"



базируется на следующих технологиях
org.kiji.modeling.lib.RecommendationPipe
val itemSetsPipe: Pipe = {
transactions
.prepareItemSets[Long](
'products -> 'itemset,
minSetSize=1,
maxSetSize=3,
separator=","
).support(
'itemset -> ('frequency, 'support),
totalsPipe,
None,
'norm
).confidenceAndLift(
('itemset, 'support) -> ('lhs, 'rhs, 'confidence, 'lift),
lhsMinSize = 1,
lhsMaxSize = 1,
rhsMinSize = 1,
rhsMaxSize = 2
)
}
itemSetsPipe.write(Tsv(
p=path,
fields=('lhs, 'rhs, 'count, 'support, 'confidence, 'lift),
writeHeader=true
))Hbase structure. Multiple columns

SerializedRecord {
count,
support,
confidence,
lift
}
Hbase structure. Single column
SerializedRecord {
list<SerializedRecord1>
}
SerializedRecord1 {
rhs,
count,
support,
confidence,
lift
}Spark Examples
val transactions = sc.textFile("../data/mllib/sample_fpgrowth.txt").map(_.split(" ")).cache()
println(s"Number of transactions: ${transactions.count()}")
>> Number of transactions: 6
import org.apache.spark.mllib.fpm.FPGrowth
val model = new FPGrowth().setMinSupport(0.8).setNumPartitions(2).run(transactions)
println(s"Number of frequent itemsets: ${model.freqItemsets.count()}")
>> Number of frequent itemsets: 1
model.freqItemsets.collect().foreach { itemset =>
println(itemset.items.mkString("[", ",", "]") + ", " + itemset.freq)
}
>> [z], 5
val model = new FPGrowth().setMinSupport(0.5).setNumPartitions(2).run(transactions)
model.freqItemsets.collect().foreach { itemset =>
println(itemset.items.mkString("[", ",", "]") + ", " + itemset.freq)
}
>> [t], 3
>> [t,x], 3
>> [t,x,z], 3
...r z h k p
z y x w v u t s
s x o n r
x z y m t s q e
z
x z y r q t p"../data/mllib/sample_fpgrowth.txt"
Вопросы
Ассоциативные правила для геренации рекомендаций для решений в сфере eCommerce на базе технологий Big Data
By Alexander Bykovsky



