Under the Hood of Black-Box Models
Ahcène Boubekki
UCPH
Pioneer Centre
vision⤴
Motivation
Motivation


Objective: Learning Causal Relationships
How do we do that
for complex data?
Rios, F. L., Markham, A., & Solus, L. (2024).
Scalable Structure Learning for Sparse Context-Specific Causal Systems.
arXiv preprint arXiv:2402.07762.
What are the features?
Certainly not the pixels...
Motivation

What did you see?
Where did you look?
Where were
the eyes?
How many eyes
were there?
How would you explain this image
using 5 concepts?
How would you decompose this image?
Motivation
Objective: Learning Causal Relationships
How do we do that
for complex data?
Rios, F. L., Markham, A., & Solus, L. (2024).
Scalable Structure Learning for Sparse Context-Specific Causal Systems.
arXiv preprint arXiv:2402.07762.
What are the features?
Certainly not the pixels...
Semantics?
Concepts?
How to see what
a model sees?
Lightweight? Interpretable?
How to see what a model sees?

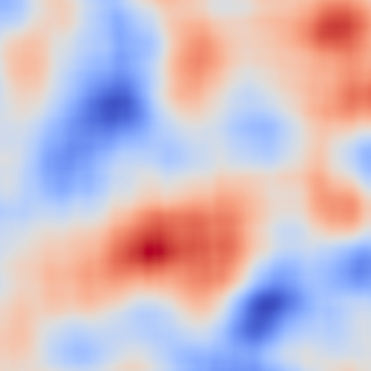
RISE
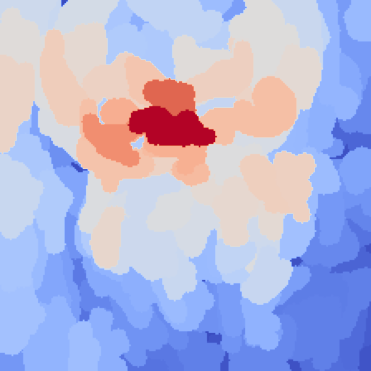
XRAI

GradCAM

LRP

IG





Dingo or Lion
These do not answer directly
what does the model see?
Deep Dream?
What makes it more a tiger than a tiger?
Too slow, impossible to train, not really useful.
What is important for the prediction?
Inconsistent, difficult to read, objective unclear.
Saliency Maps?
How is the neighborhood in the embedding?
Inspection of the embedding, "biaised" justification..
Prototypes/Concepts?
Counterfactual?
What should I change to change class?
Tricky to compute, but nice!
How to see what a model sees?
Standard Image Classifier

\rbrace
Encoder
convolutions, pooling, non-linearity, skip-connections, attention, etc.
\rbrace
Classifier
Single linear layer... eventually a softmax
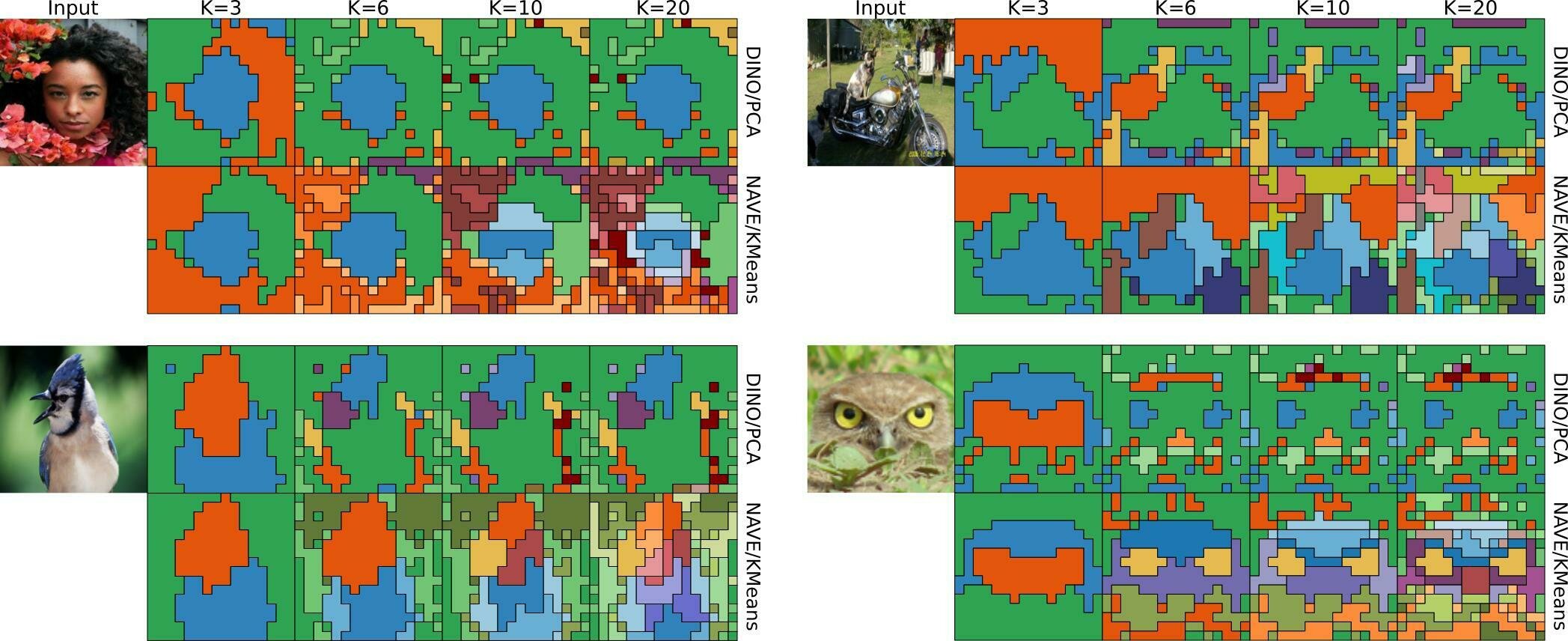
clustering
k=10
k=5


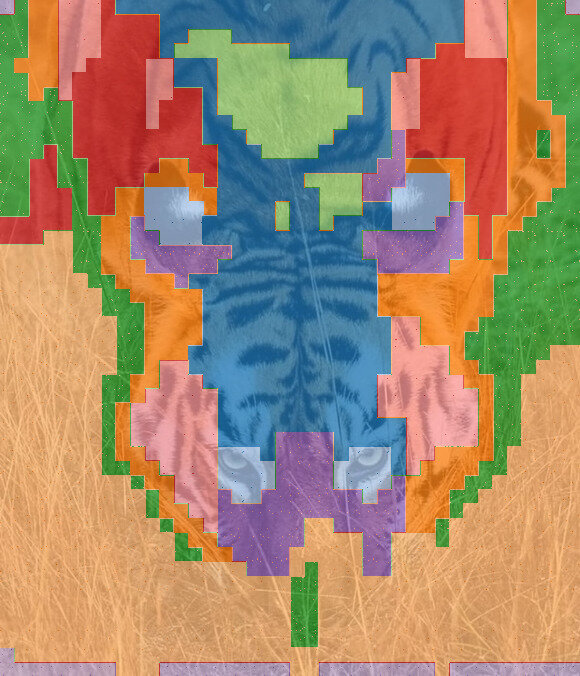
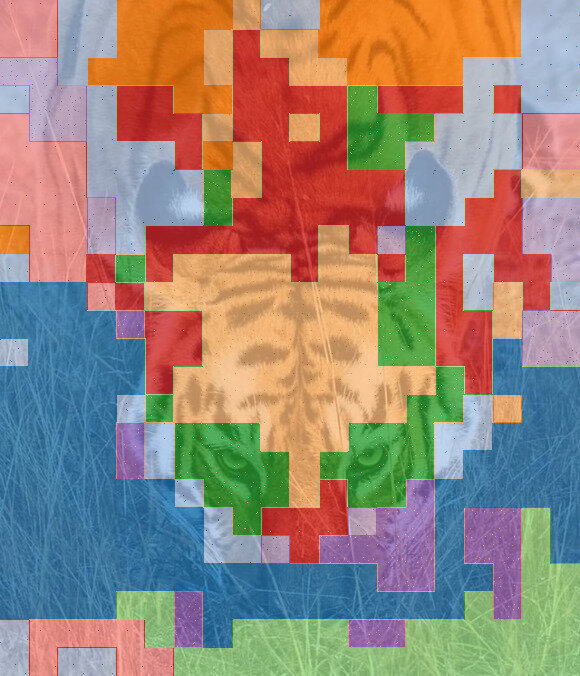





k=20
How to see what a model sees?
Standard Image Classifier
\rbrace
Encoder
convolutions, pooling, non-linearity, skip-connections, attention, etc.
\rbrace
Classifier
Single linear layer... eventually a softmax
k-means
k=10
k=5
k=20
Same Color
Same Representation
Same Cluster
Same Meaning
How to see what a model sees?
k=10
k=5
k=20
clustering
How to see what a model sees?

How to see what a model sees?
Seems like a déjà-vu?
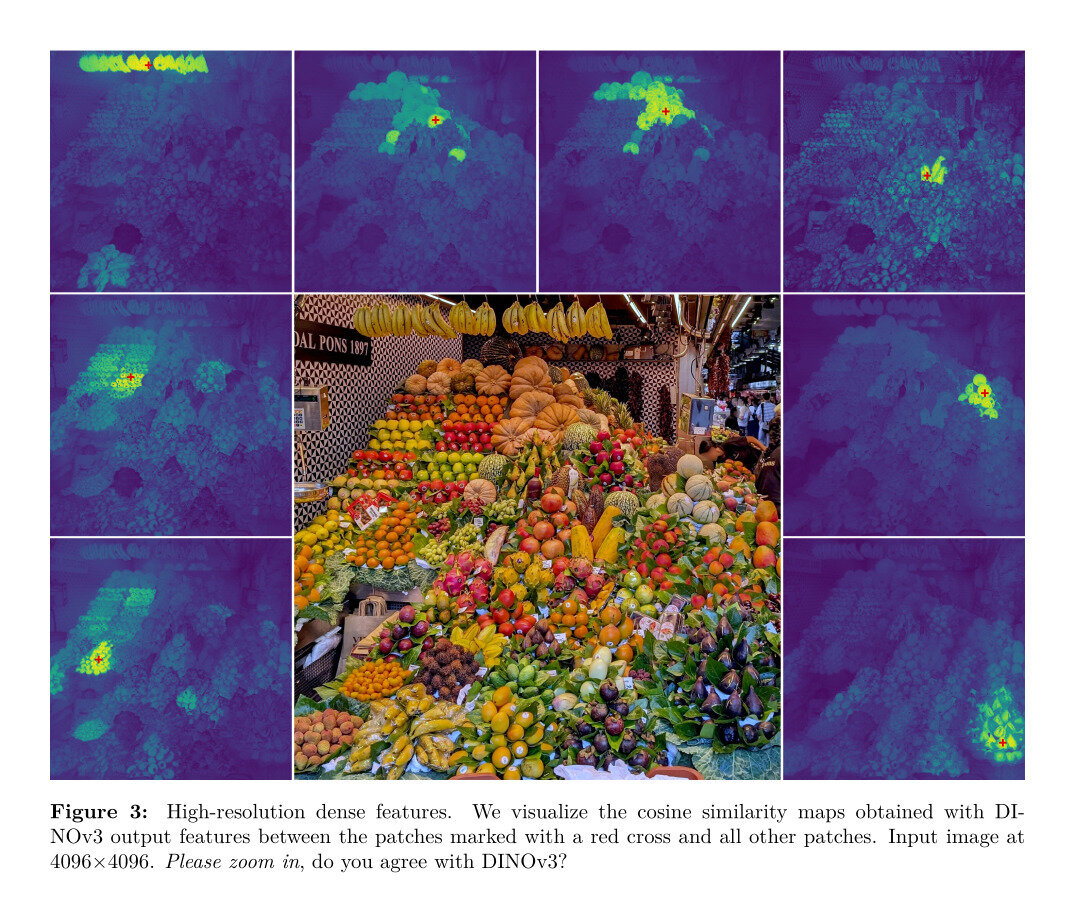


One object at a time
Limited to 3 directions
For K=3,
PCA and k-means are similar
K-means provides
some hierarchy!
Siméoni, Oriane, et al. "Dinov3." arXiv preprint arXiv:2508.10104 (2025).
Siméoni, Oriane, et al. "Dinov3." arXiv preprint arXiv:2508.10104 (2025).
Deng, Jia, et al. "Imagenet: A large-scale hierarchical image database." 2009 IEEE CVPR, 2009.
What can we
do with it?
What can we "explain"?
What can we explain?
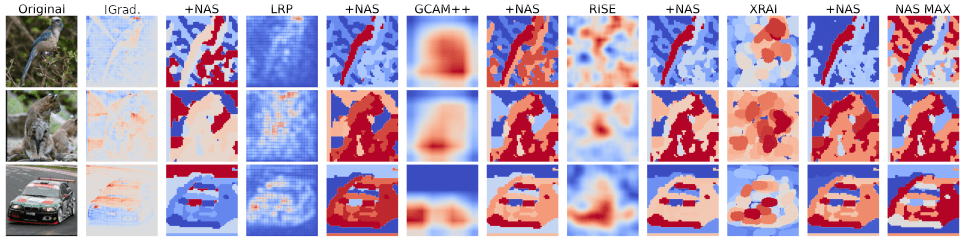
Explain explanations





IG
LRP
GradCAM
RISE
XRAI
color gradient ~ rank
What can we explain?
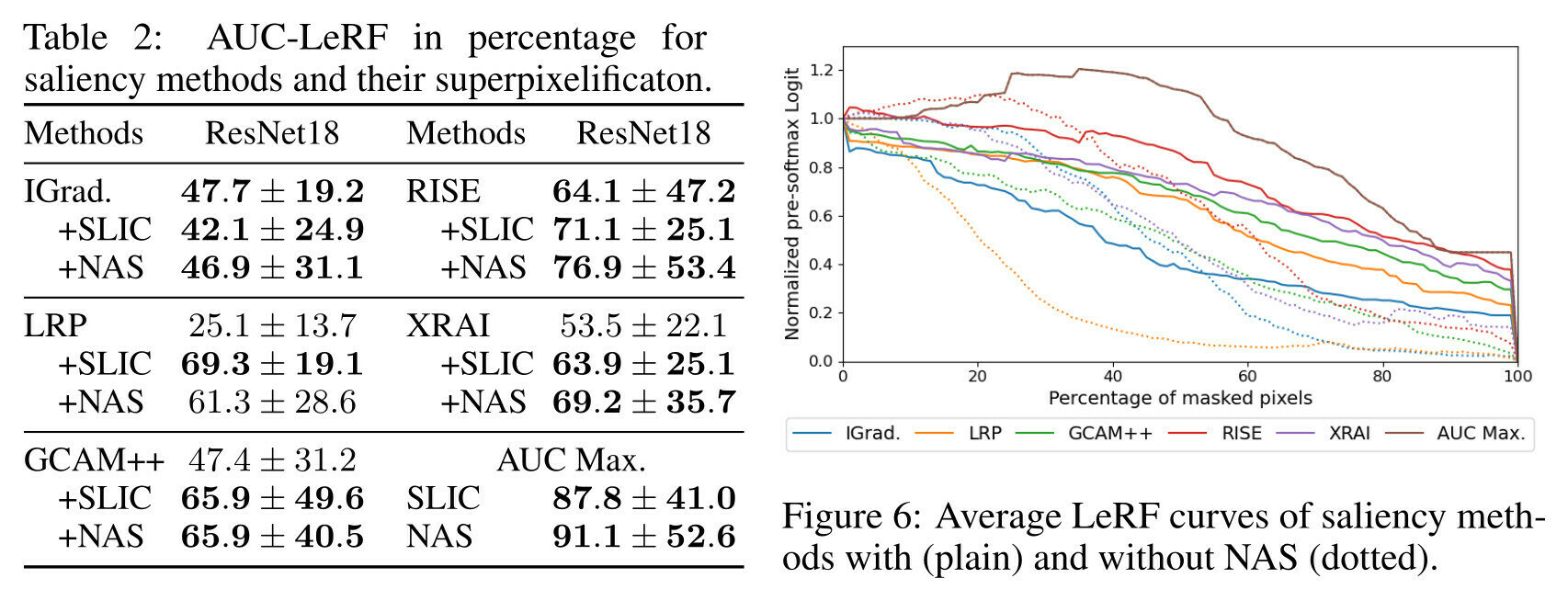
Maximize the AUC-LeRF
Superpixelif.
improves AUC
SLIC and NAVE
return same perf?
AUC-LeRF is the problem!
Negative image of the bird max the AUC
\text{+NAVE}
\text{+NAVE}
\text{+NAVE}
\text{+NAVE}
\text{+NAVE}
\text{NAVE}
AUC MAX
Connect Explanations and Semantics

Replace class-wise explanations



Wah, Catherine, et al. "The caltech-ucsd birds-200-2011 dataset." (2011).
Concept Extraction
What can we explain?
Connect Explanations and Semantics
Replace class-wise explanations
Concept Extraction
Wah, Catherine, et al. "The caltech-ucsd birds-200-2011 dataset." (2011).

What can we explain?
Connect Explanations and Semantics
Replace class-wise explanations
Concept Extraction
Wah, Catherine, et al. "The caltech-ucsd birds-200-2011 dataset." (2011).
Coates, Adam, et al., An analysis of single-layer networks in unsupervised feature learning. AISTATS, (2011).
Concept Explanation: Manually?

Wah, Catherine, et al. "The caltech-ucsd birds-200-2011 dataset." (2011).



Edge Effect
Larger Than Expected

Concept Explanation: NAVE + CAM
What can we explain?
Concept Explanation:
Wah, Catherine, et al. "The caltech-ucsd birds-200-2011 dataset." (2011).
Concept Explanation: Manually?
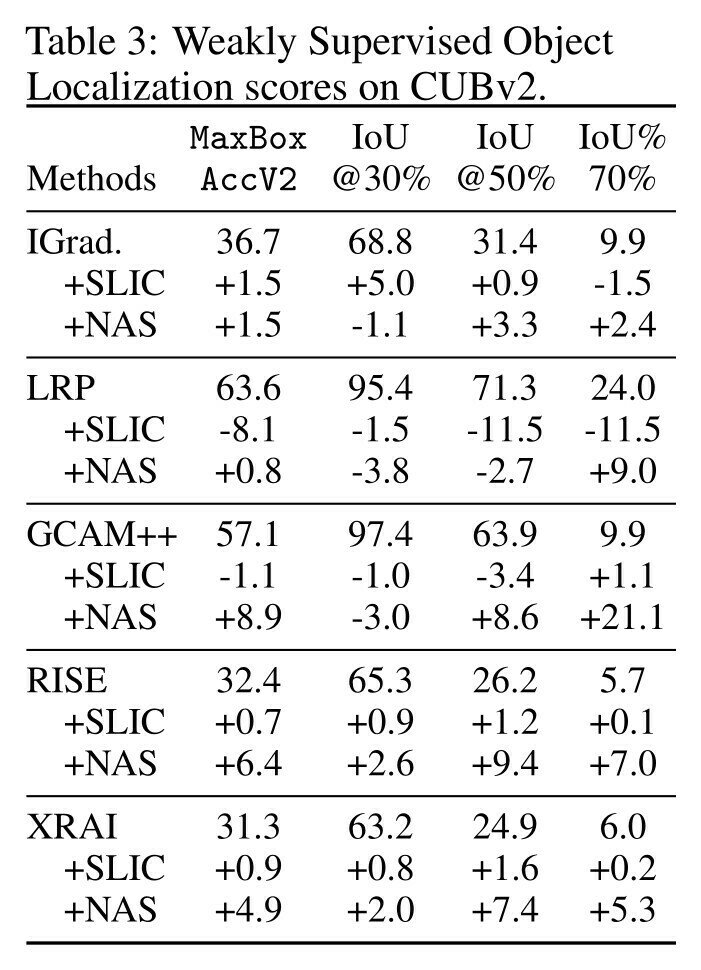
Object Localization
NAVE always improves MaxBox
but not all thresholded IoU
Always improves the most difficult IoU@70%
\text{+NAVE}
\text{+NAVE}
\text{+NAVE}
\text{+NAVE}
\text{+NAVE}
+
+
+
+
+
+
+
++
+
+
+
-
+
+
+
-
-
-
+
+
Annotation Masks

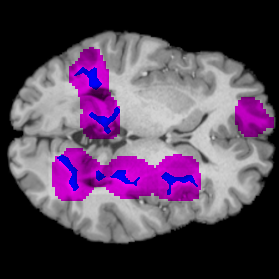

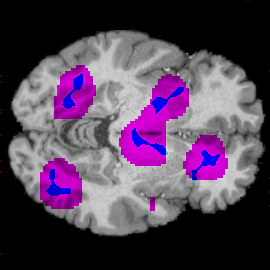
Model train for binary classif.
All lesions recovered
Can we use NAVE for medical annotations?
You need well performing model!
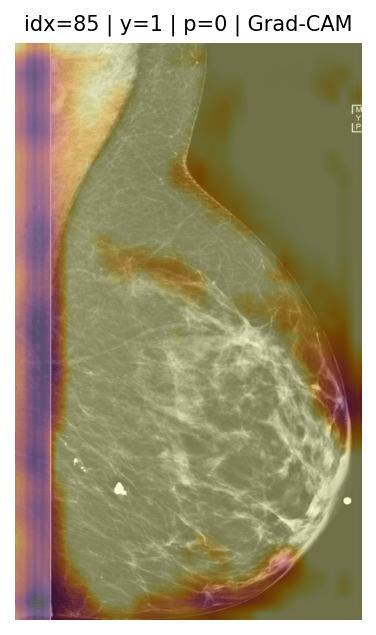
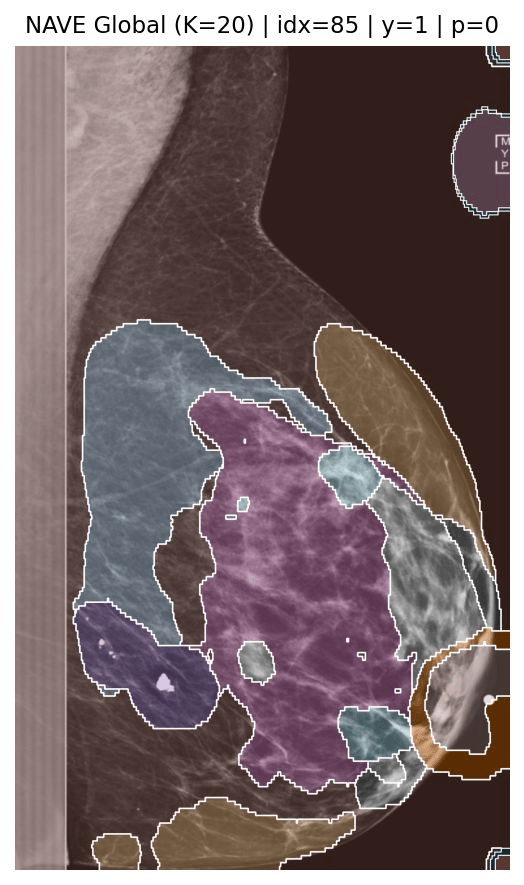
Nguyen, H. Q., et al., VinDr-CXR: An open dataset of chest X-rays with radiologist's annotations. Scientific Data, 9(1), 429, (2022).
What can we explain?
Inspect Artifacts in ViT and Registers

Sometimes it works
for small ViT
Often it doesn't work
for big ViT
Shortcut Saturation Inspection
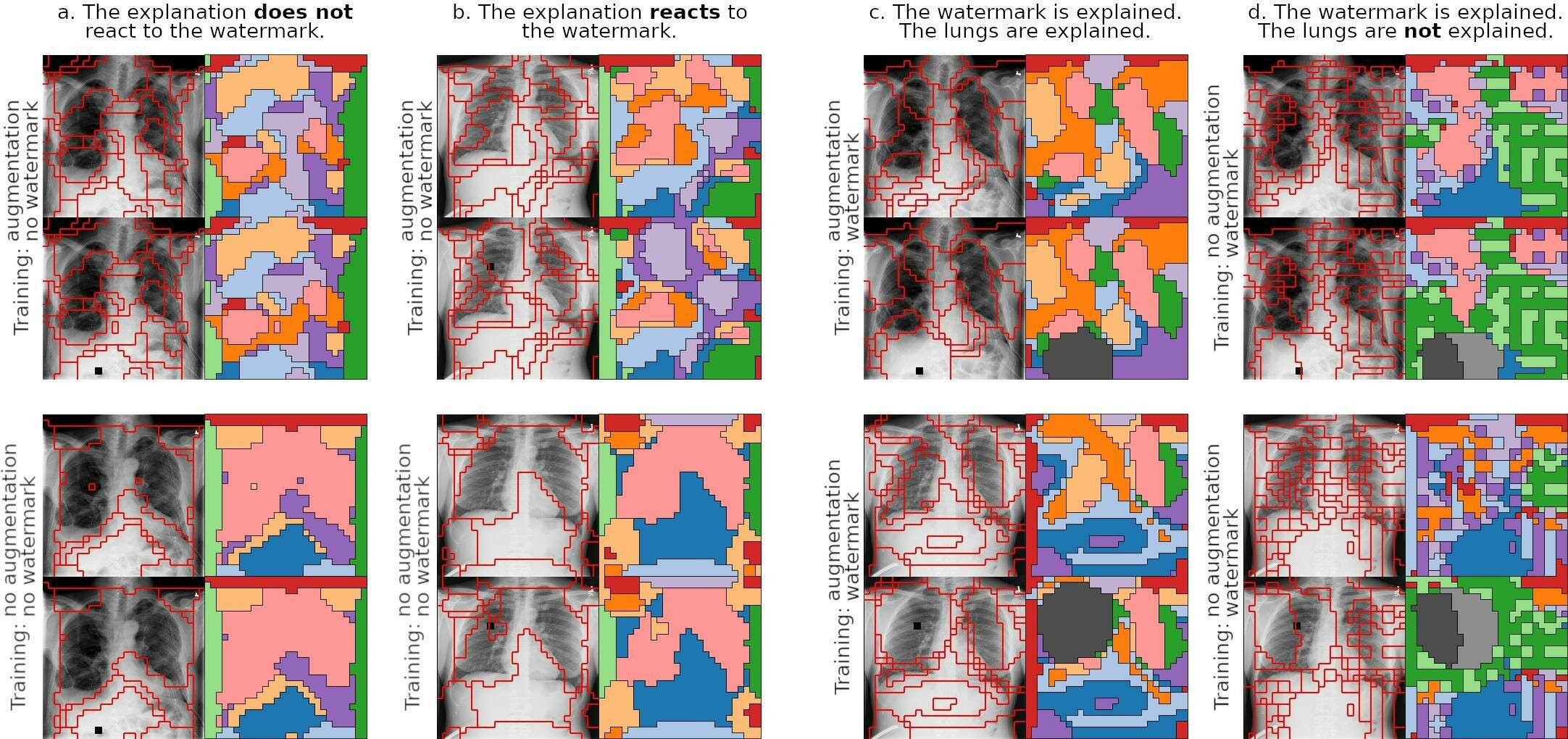
Wang, X., et al., ChestX-ray8: Hospital-scale chest X-ray database and benchmarks on weakly-supervised classification and localization of common thorax diseases. CVPR, (2017).
What else?
In-Distribution Intervention
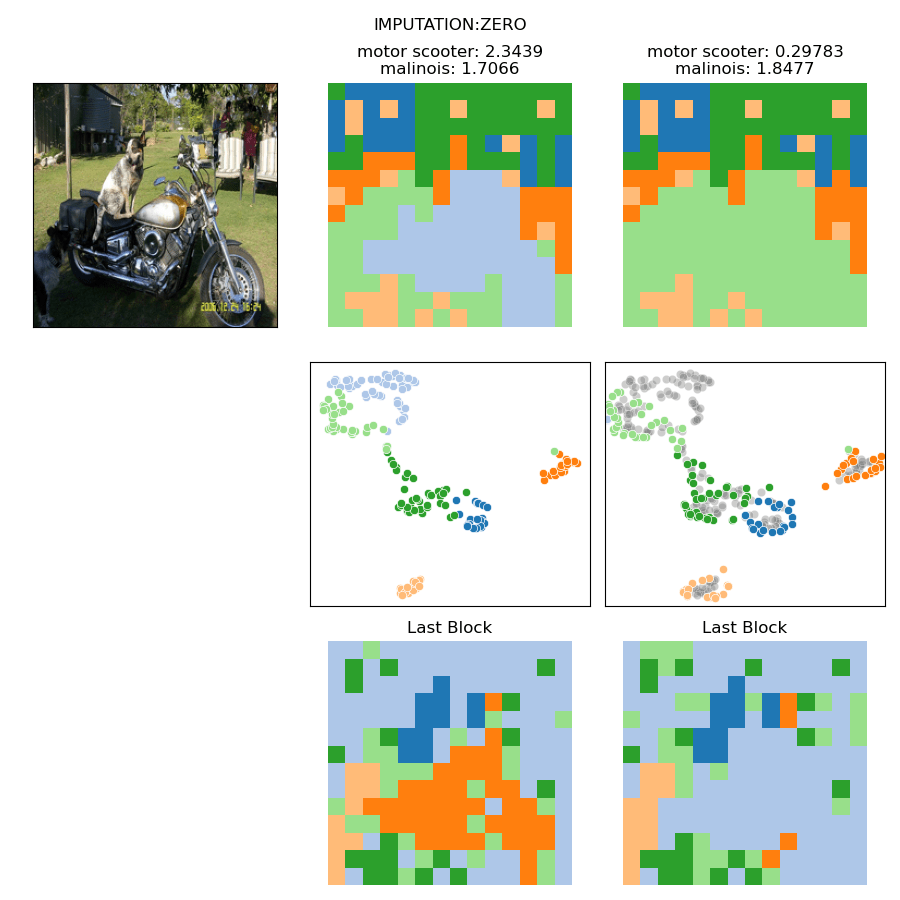
How to hide an object?
Swap clusters
Enlarge another cluster
Swap between images
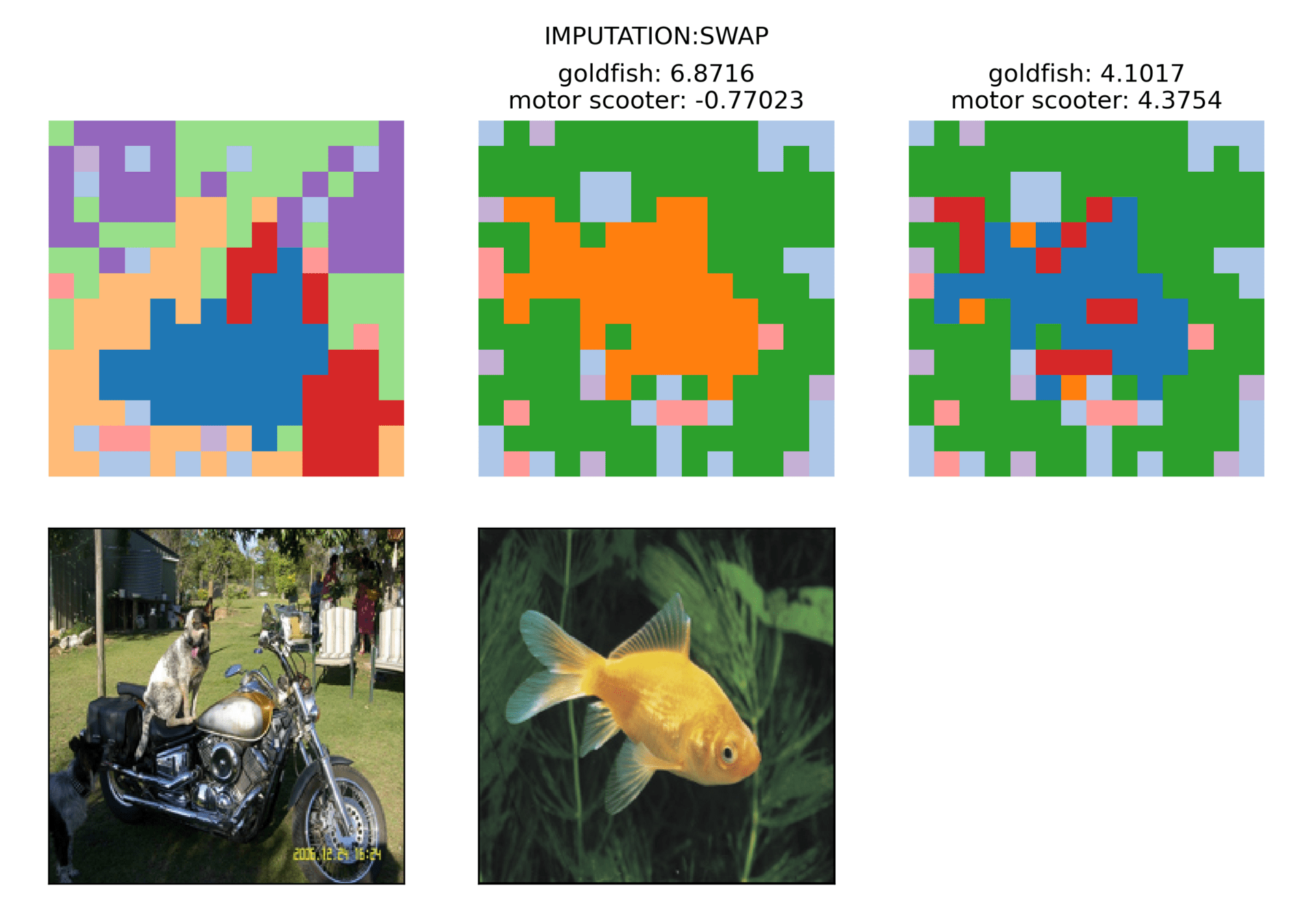
Class Score:
Fish: 6.8
Bike:-0.7
Fish: 4.1
Bike: 4.3
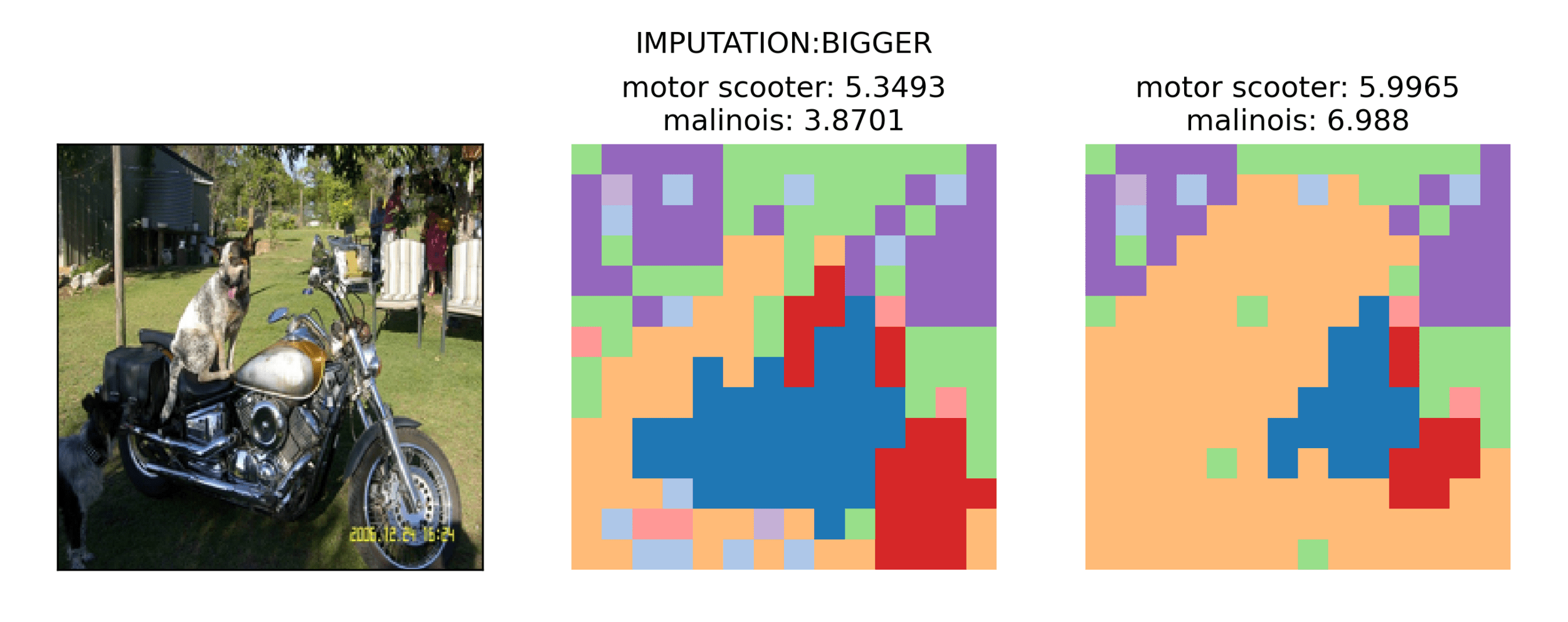
Class Score:
Bike: 5.3
Dog: 3.8
Bike: 5.9
Dog: 6.9
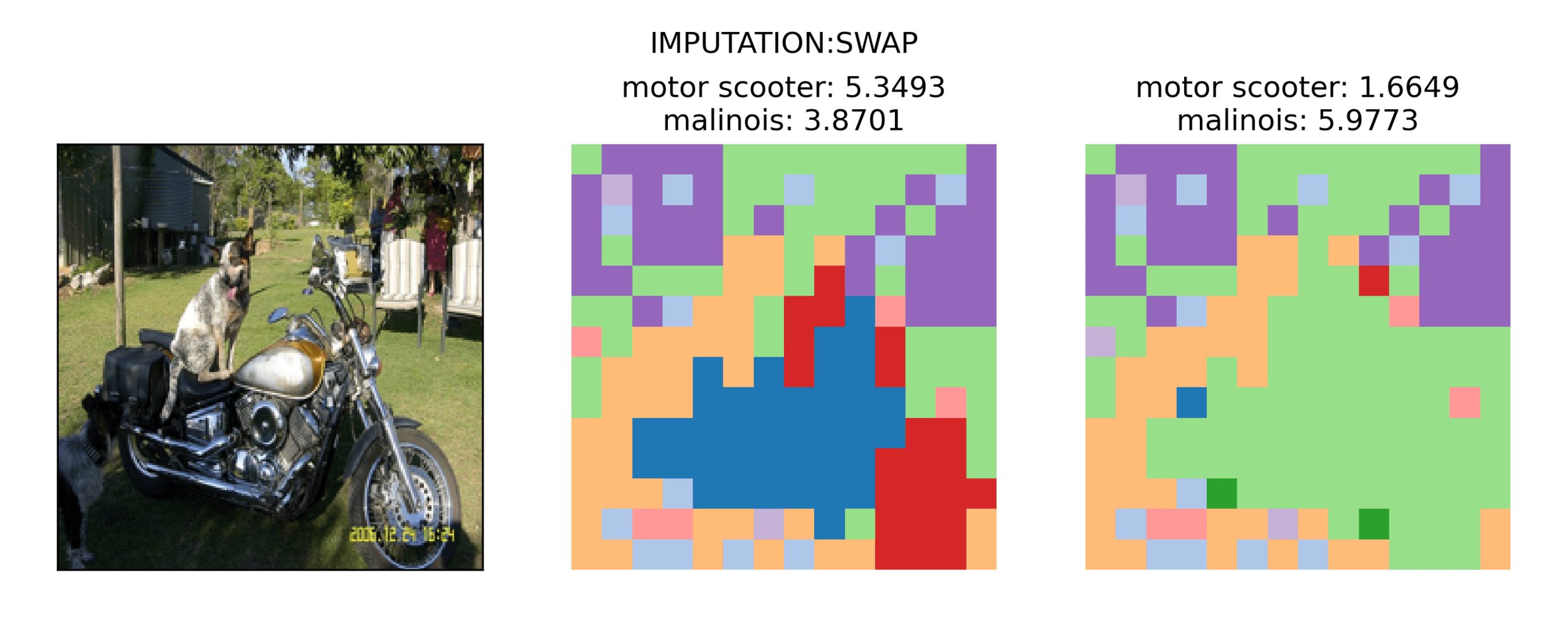
Class Score:
Bike: 5.3
Dog: 3.8
Bike: 1.6
Dog: 5.9
In-Distribution Intervention

Input
Explanation without watermark
Explanation with watermark
Original
Repaired

In-Distribution Intervention
Pneumonia?
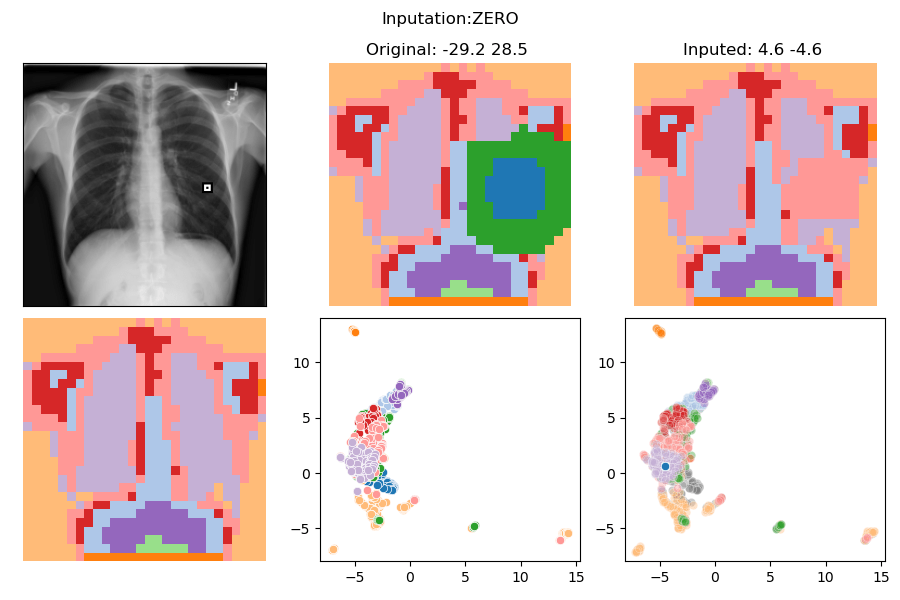
No | Yes
-29.2 28.5
No | Yes
4.6 -4.6
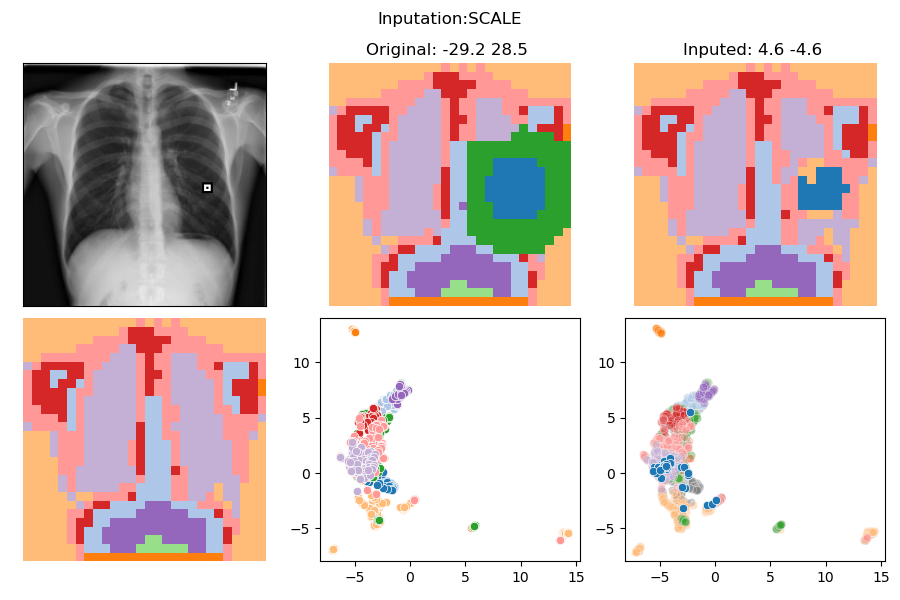
No | Yes
-29.2 28.5
No | Yes
4.6 -4.6
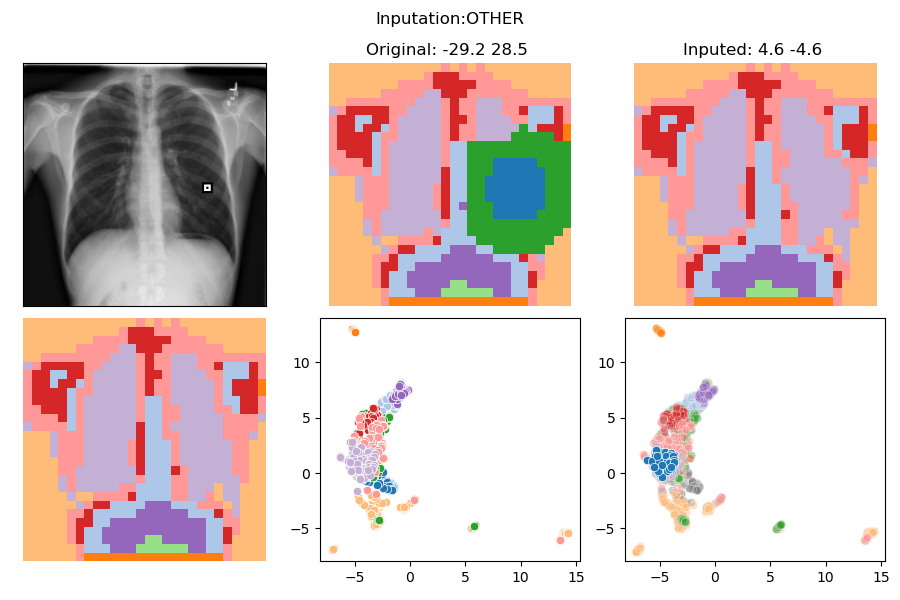
No | Yes
-29.2 28.5
No | Yes
4.6 -4.6
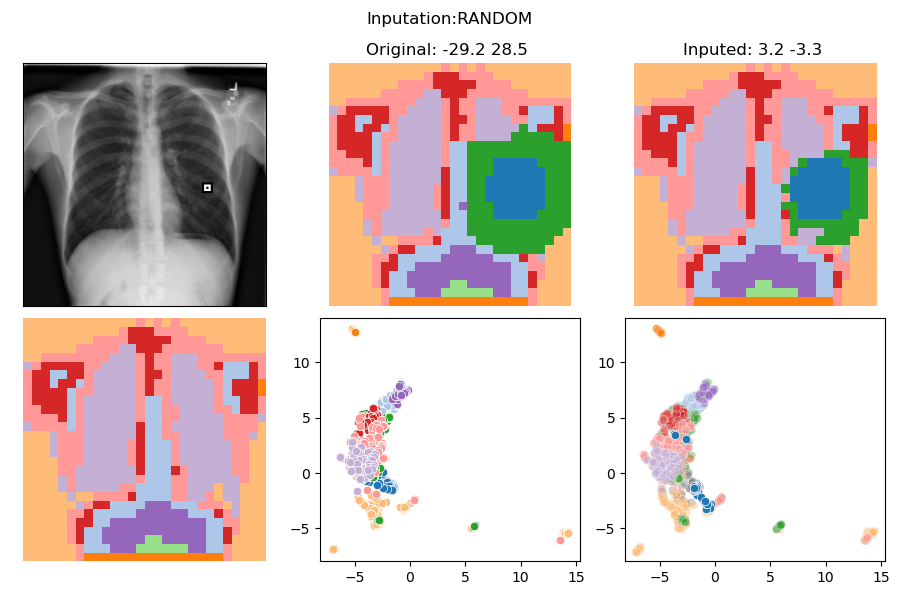
No | Yes
-29.2 28.5
No | Yes
3.2 -3.3
Intervention:
ZERO
SCALING
RANDOM
SWAP
In-Distribution Intervention
Pneumonia?
No | Yes
-29.2 28.5
No | Yes
4.6 -4.6
No | Yes
-29.2 28.5
No | Yes
4.6 -4.6
No | Yes
-29.2 28.5
No | Yes
4.6 -4.6
No | Yes
-29.2 28.5
No | Yes
3.2 -3.3
Intervention on
ZERO
SCALING
RANDOM
SWAP
Interventions?
Bike: 2.3
Dog: 1.7

Fish: 6.7
Bike: -1.0
Fish: 0.5
Bike: 2.6

Bike: 2.3
Dog: 1.7
Bike: 0.9
Dog: 2.3
Class score:
Test set: No watermark
Yes
No
Yes
No
Truth
Pred.
Accuracy: 26.7%
Test set: Watermarked
Yes
No
Yes
No
Truth
Pred.
Accuracy: 100%
Test set: Watermark
+ Swap
Yes
No
Yes
No
Truth
Pred.
Accuracy: 26.7%
Train set: Watermarked
Yes
No
Yes
No
Truth
Pred.
Accuracy: 100%
Unlearning?
Shortcut Unused!
Repairing? In-Painting?
Original
Repaired
"Adversarial" Attack?
Bike: 2.3
Dog: 1.7
Fish: 6.7
Bike: -1.0
Fish: 0.5
Bike: 2.6
Bike: 2.3
Dog: 1.7
Bike: 0.9
Dog: 2.3
Class score:
What else?
In-Distribution Masking?
Really? Just Vision?
Time series
ECG Explanation: Heart Condition
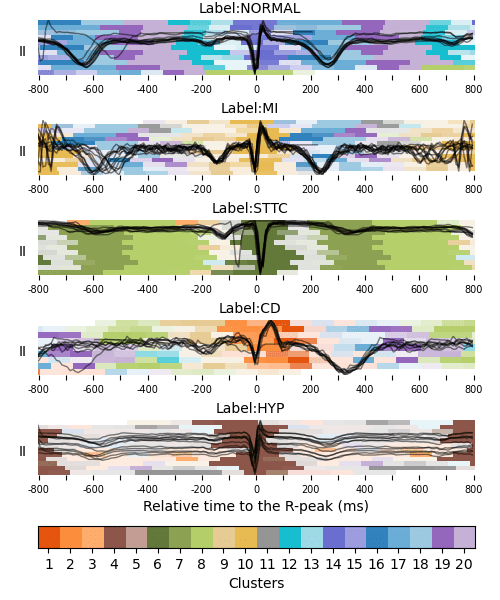
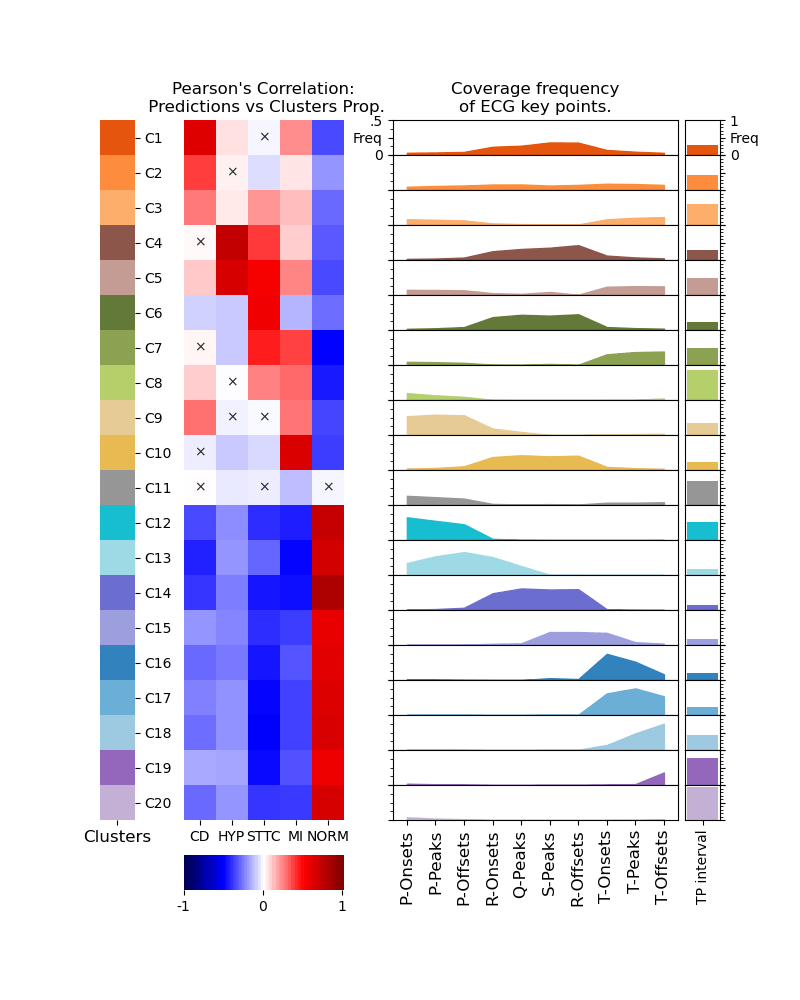

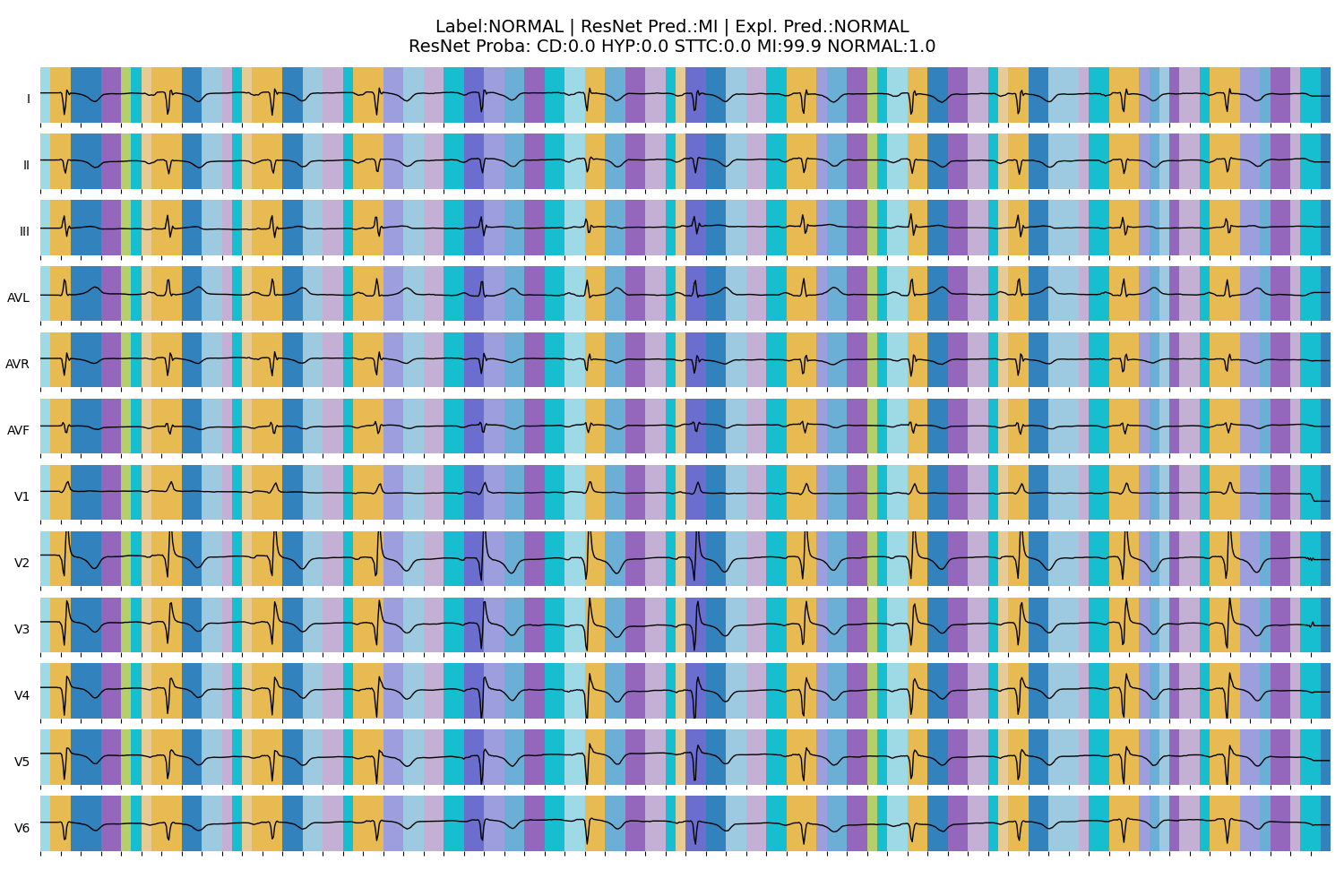
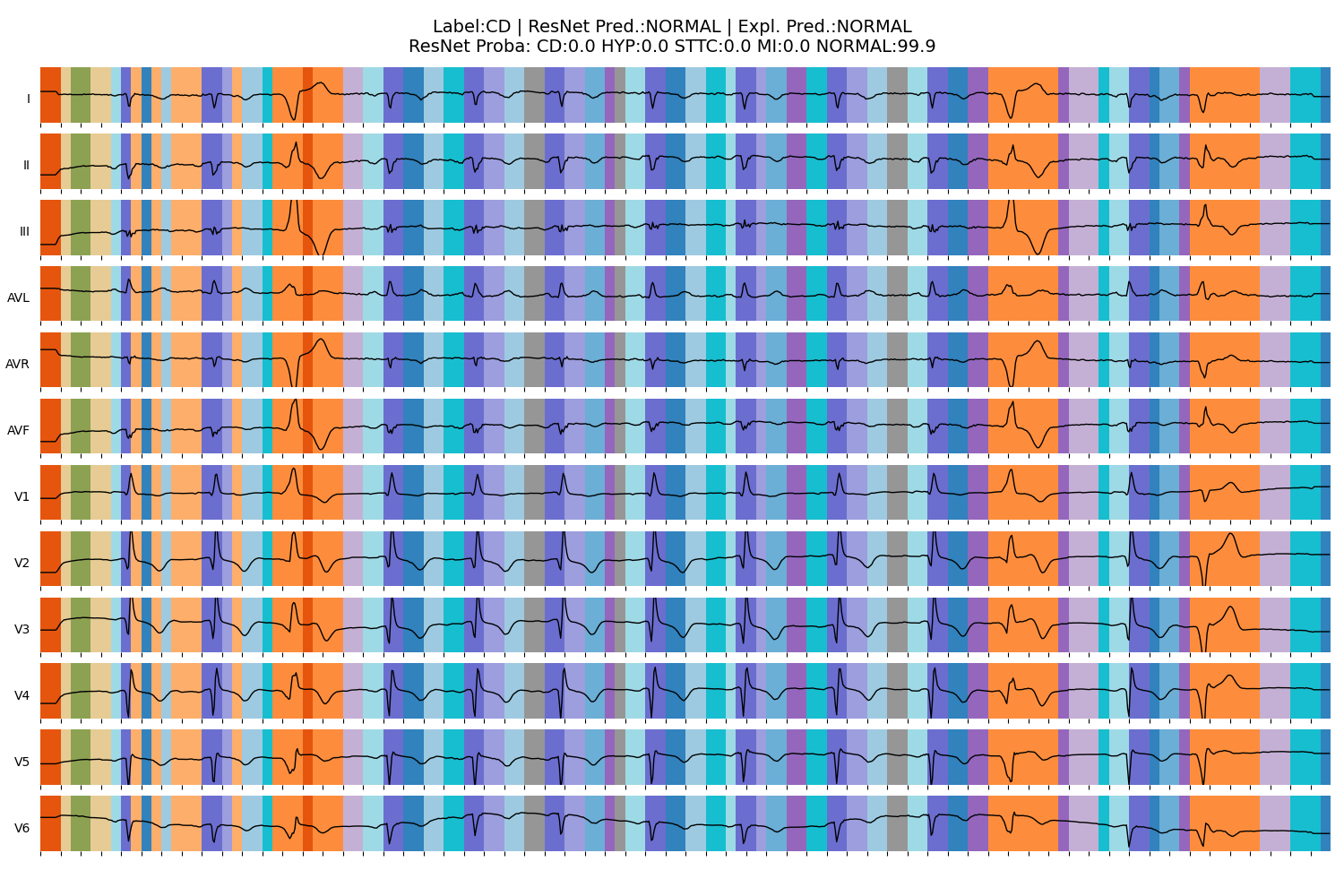
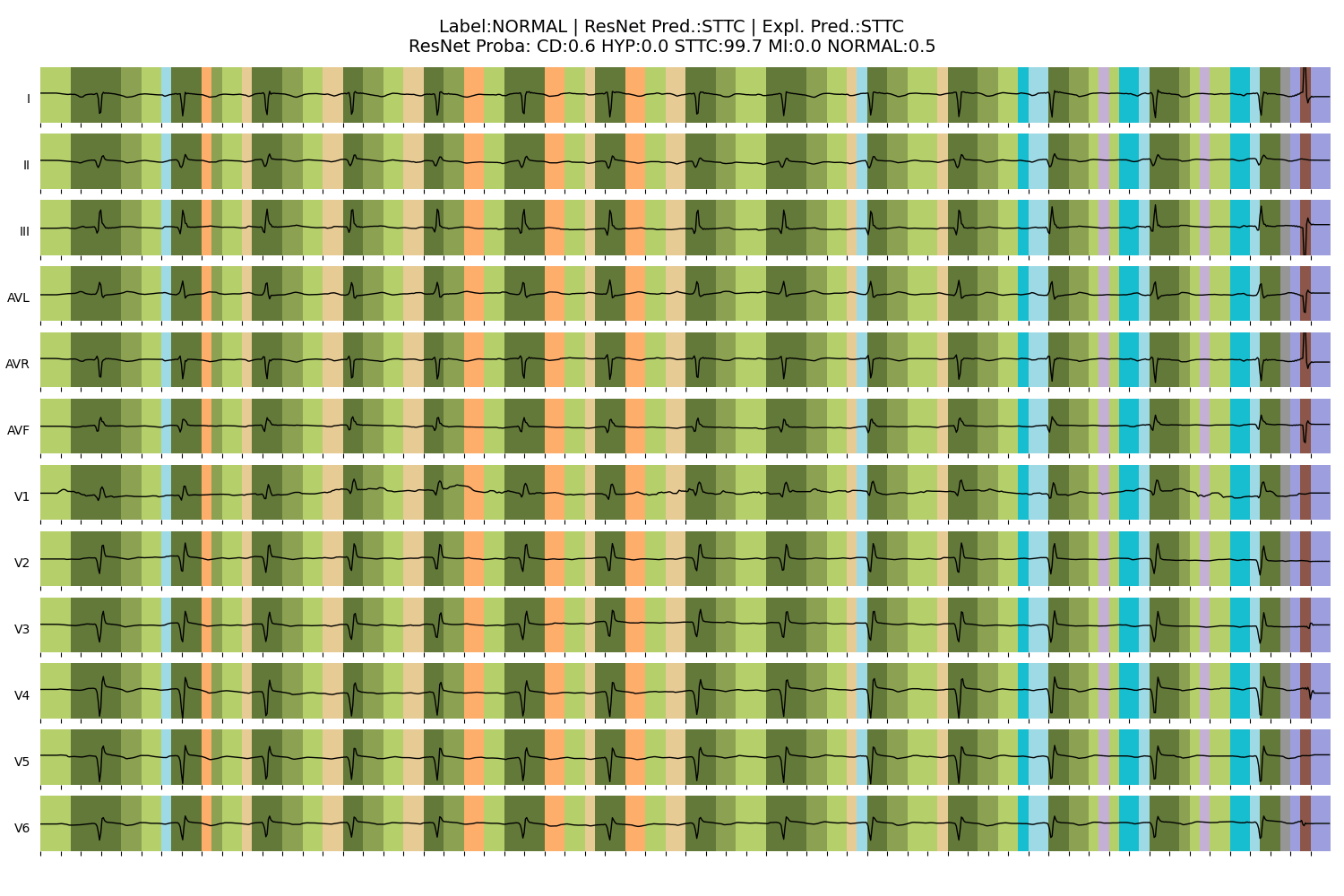
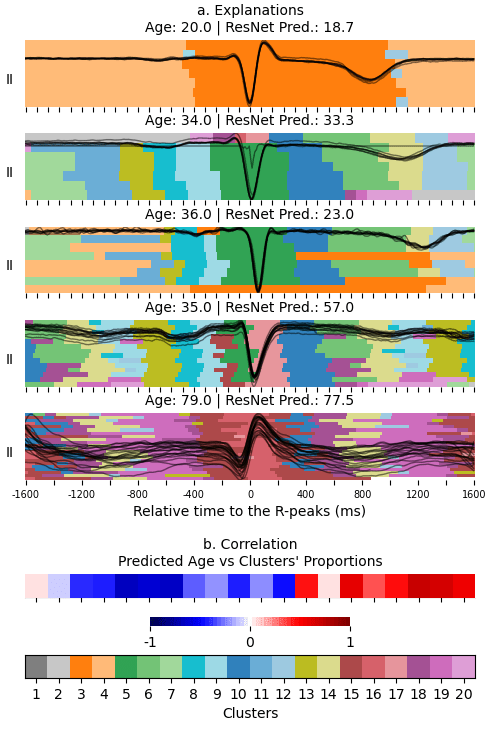
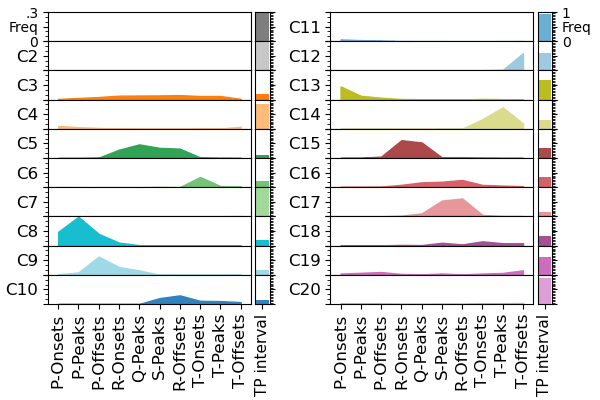
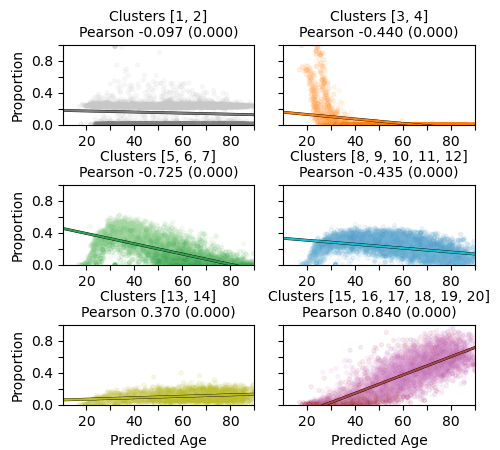
Wagner, P., et al., PTB-XL, a large publicly available electrocardiography dataset. Scientific Data, (2020).
ECG Explanation: Age
Text?
Not Yet
How to see what a model sees? (details)
Extract
Upsample
Concatenate
Cluster
Summary
Summary
Does it capture semantics?
Yes
Can we see what the model sees?
Yes
- Ease interpretation of saliency maps.
- Concept extraction
- Unsupervised evaluation of local explanations.
- Object localization
- Annotations masks from labels
- Model inspection
- Shortcut saturation
- Unlearning
- Adversarial attacks
- etc.
What can we explain?
- Feature attribution?
- Causality?
- Concept injection?
- Any other idea?
What else?
Summary
Do we capture semantics?
Yes
Can we see what the model sees?
Yes
- Concept extraction
- Object localization
- Model inspection
- Annotations masks from labels
- Shortcut saturation
What can we do with it?
- Feature attribution?
- Causality?
- Concept injection?
- Any other idea?
What else?
Under the Hood of Black-Box Models
Ahcène Boubekki
UCPH
Pioneer Centre
Under the Hood of Black-Box Models (draft)
By ahcene




