Amrutha
Course Content Developer for Deep Learning course by Professor Mitesh Khapra. Offered by IIT Madras Online degree - Programming and Data Science.
Compositionality principle: states that the meaning of word compounds is derived from the meaning of the individual words, and the manner in which those words are combined.
Hierarchical structure of language: states that through analysis, sentences can be broken down into simple structures such as clauses. Clauses can be broken down into verb phrases and noun phrases and so on.
Successive compositions yield the meaning of the sentence.
Example:
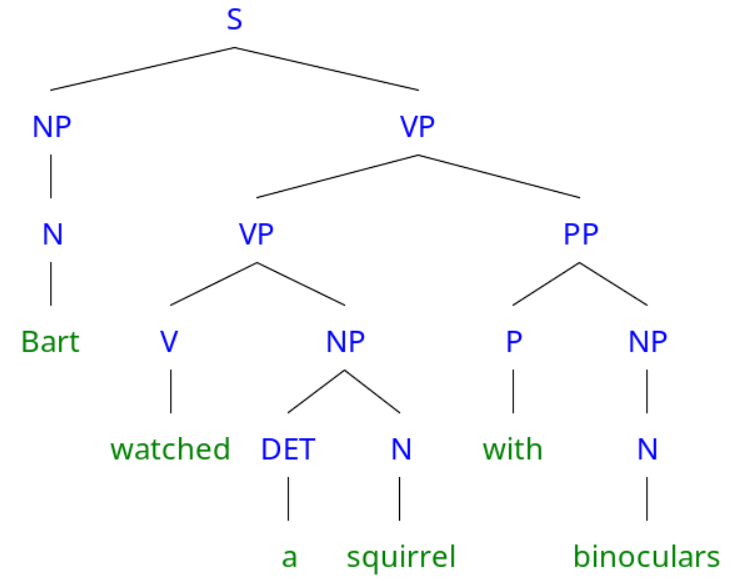
composing “a” and “squirrel”, “watched” with “a squirrel”, “watched a squirrel” and “with binoculars”
Parse tree 1
Composition relies on the result of parsing to determine what ought to be composed.
Composition and parsing are both hard tasks, and they need one another.
"Bart watched a squirrel with binoculars"
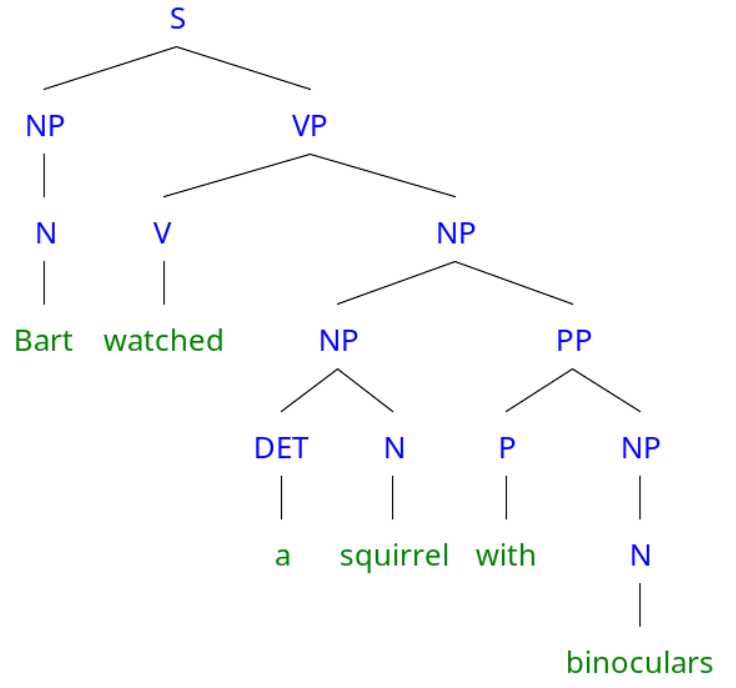
"Bart watched a squirrel with binoculars"
Parse tree 1
Parse tree 2
Several models have tried to put the combination of parsing and composition in practice.
BERT is a bidirectional model.
More powerful than either a left-to-right model or the shallow concatenation of a left-to-right and a right-to-left model.
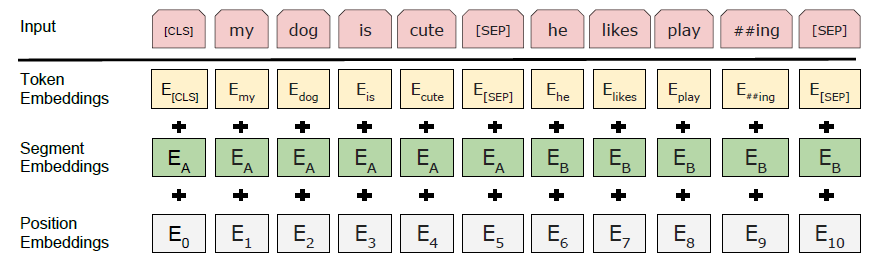
BERT Input representation:
Example: <Question, Answer>
[CLS]: a special classification token which is the first token of every sequence.
[SEP]: a special token to separate sentence pairs packed together in a single sequence
E: input embedding
C: final hidden vector of the special [CLS] token, \( C \in \mathbb R^H\)
\(T_i\): final hidden vector for the \(i^{th}\) input token, \( T_i \in \mathbb R^H\)
For a given token, its input representation is constructed by summing the corresponding token, segment, and position embeddings.
BERT input representation
Task #1: Masked LM
Input: "this movie is great"
If “great” is selected to be masked and predicted, then it will be replaced with:
Task #2: Next Sentence Prediction (NSP)
Input: sentences A and B
When generating sentence pairs for pretraining,
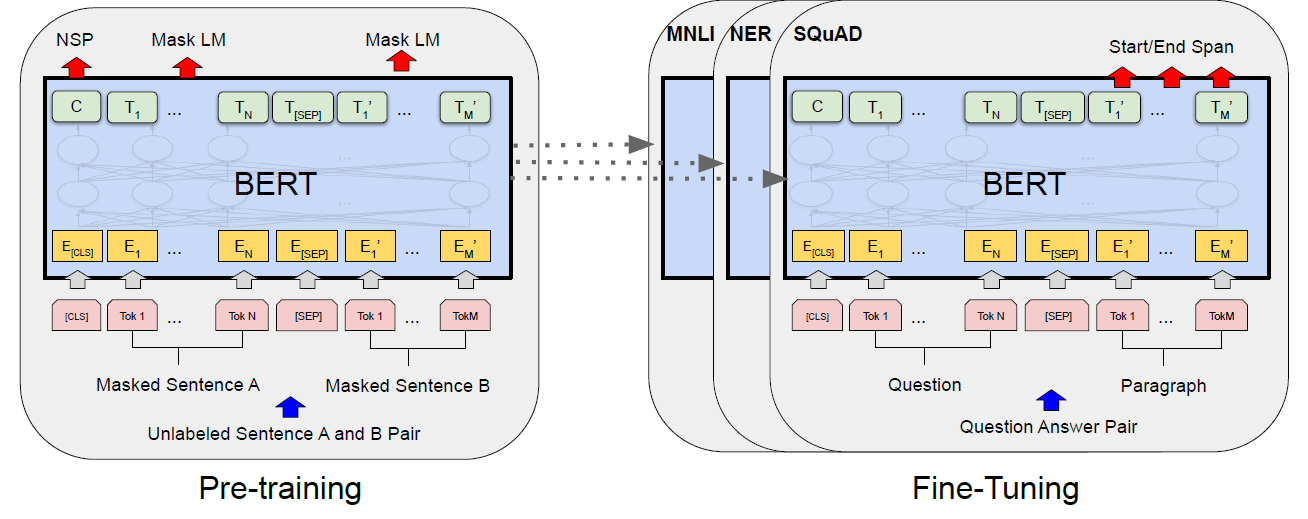
The self attention mechanism in the Transformer allows BERT to model many downstream tasks.
For each task, we simply plug in the task specific inputs and outputs into BERT and finetune all the parameters end-to-end.
At the input, sentence A and sentence B from pre-training are analogous to
At the output,
There are two model sizes based on,
\(\mathbf {BERT_{BASE}}\)
\(\mathbf {BERT_{LARGE}}\)
These models are fine-tuned on General Language Understanding Evaluation (GLUE) benchmark.
By Amrutha



