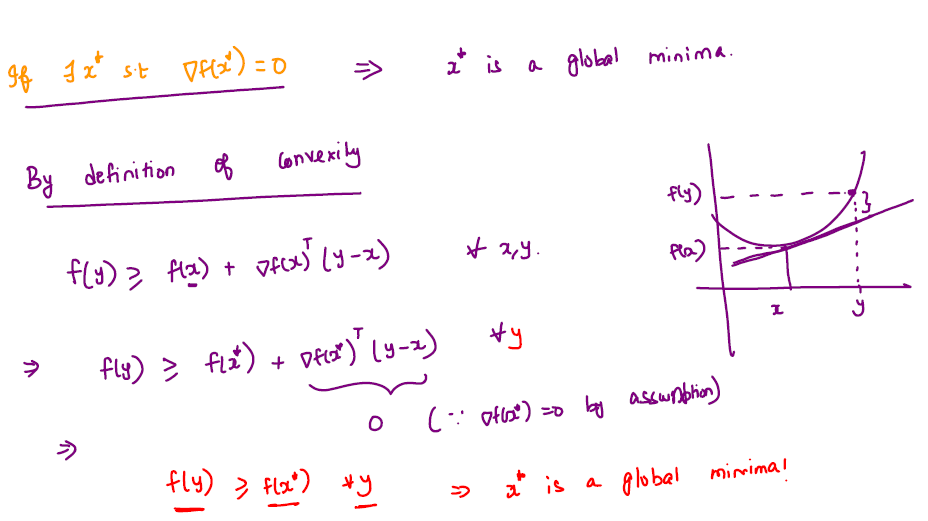
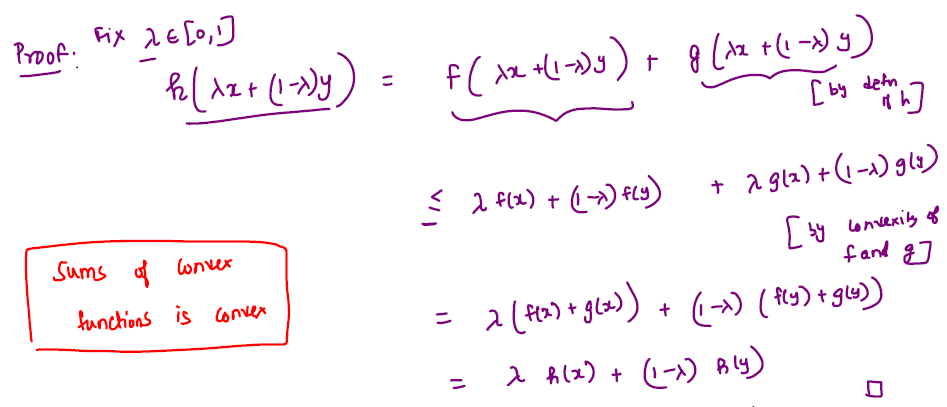
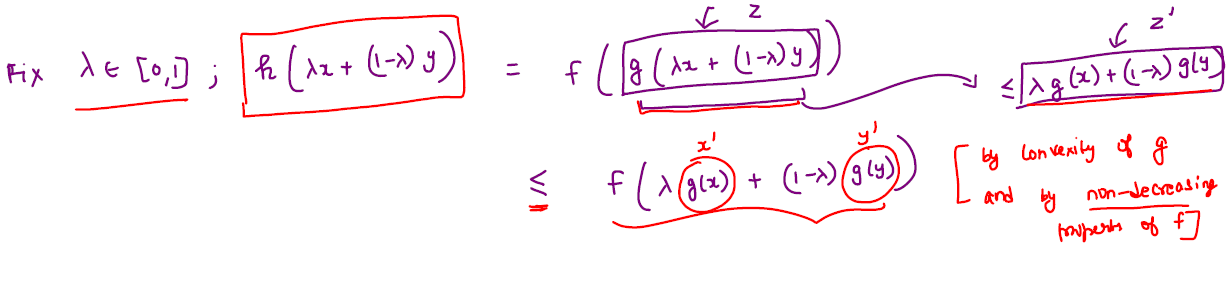
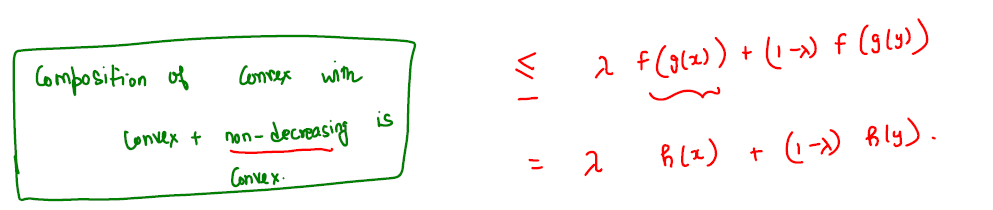
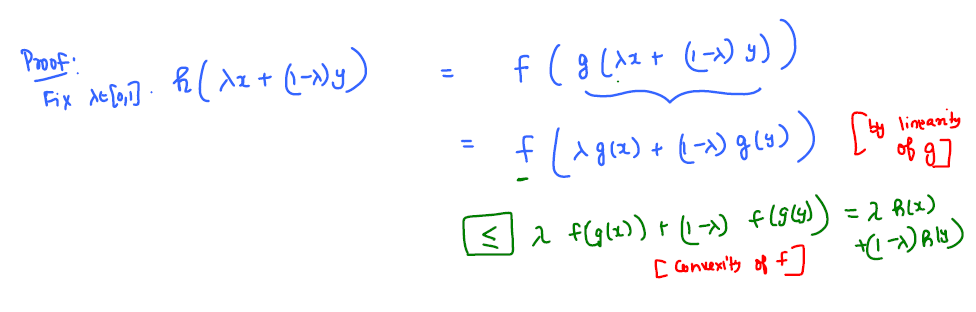
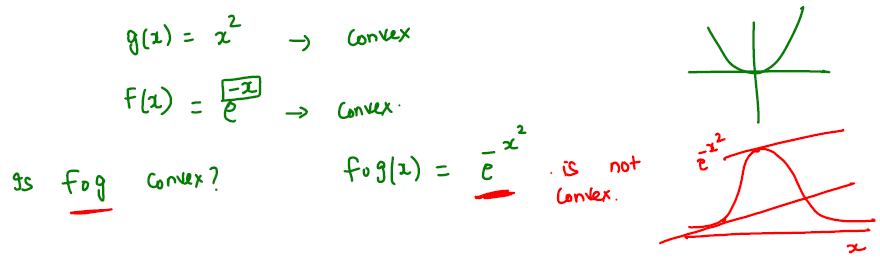
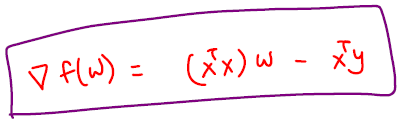
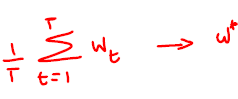
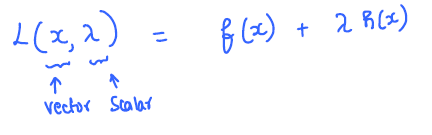
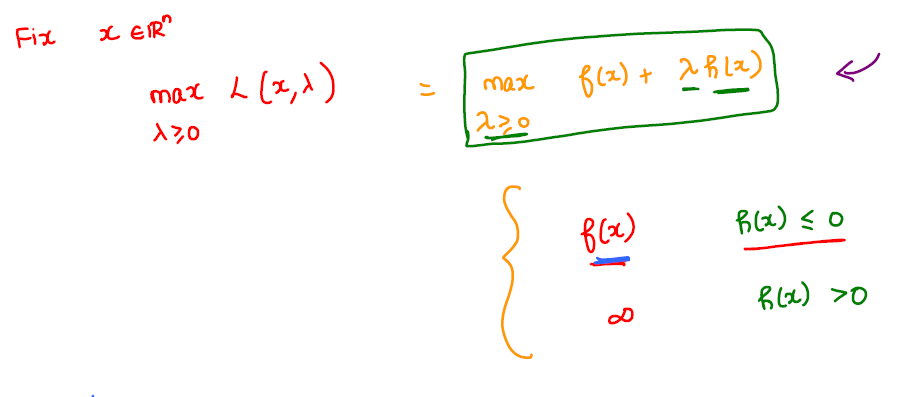
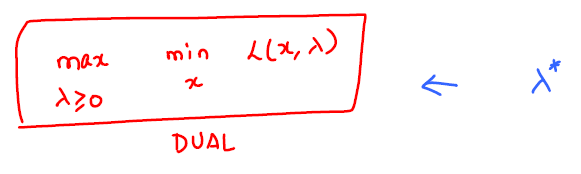
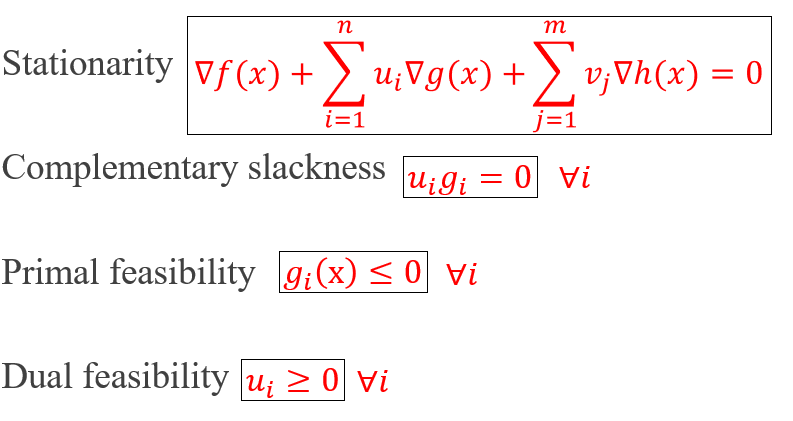
Amrutha
Course Content Developer for Deep Learning course by Professor Mitesh Khapra. Offered by IIT Madras Online degree - Programming and Data Science.
Goal : \(\min \limits_x f(x)\)
Let \(f\) be a differentiable and convex function from \(\mathbb R^d \rightarrow \mathbb R\), \(x^* \in \mathbb R^d\) is a global minimum of \(f\) if and only if \(\nabla f(x^*) = 0\).
If \( f: \mathbb{R}^d \rightarrow \mathbb{R}, g: \mathbb{R}^d \rightarrow \mathbb{R}\) are both convex functions, then \( f(x) + g(x)\) is a convex function
https://katex.org/docs/supported.html
Let \(f: \mathbb{R} \rightarrow \mathbb{R}\) is a convex and non-decreasing function and \(g: \mathbb{R}^d \rightarrow \mathbb{R}\) be a convex function, then their composition \(h = f(g(x))\) is also a convex function.
Let \(f: \mathbb{R} \rightarrow \mathbb{R}\) is a convex function and \(g: \mathbb{R}^d \rightarrow \mathbb{R}\) be a linear function, then their composition \( h = f(g(x))\) is also a convex function.
In general, if \(f\) and \(g\) are both convex functions, then \(h=fog\) may not be convex function.
Note: \(g\) is concave if and only if \(f=-g\) is convex.
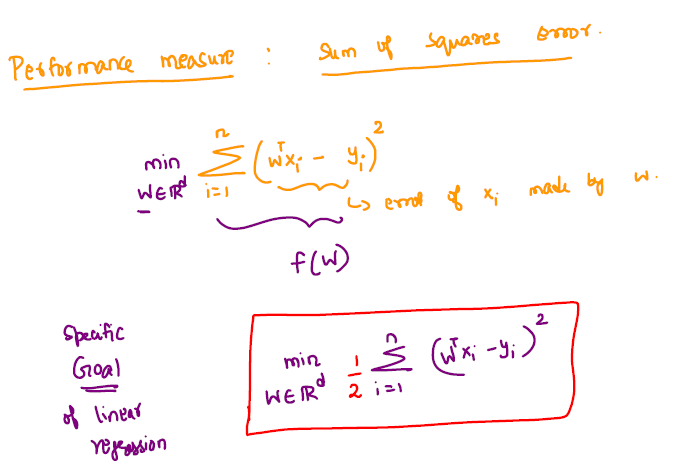
Linear Regression:
Training data \(\rightarrow\) \({X_1,X_2,...,X_n}\) with corresponding outputs \({y_1,y_2,...,y_n}\), where \(X_i \in \mathbb R^d \) and \( y_i \in \mathbb R \), \( \forall i \).
Gradient of the sum of squares error
Analytical or closed form solution of coefficients \(w^*\) of a linear regression model
In linear regression, the gradient descent approach avoids the inverse computation by iteratively updating the weights.
Stochastic gradient descent:
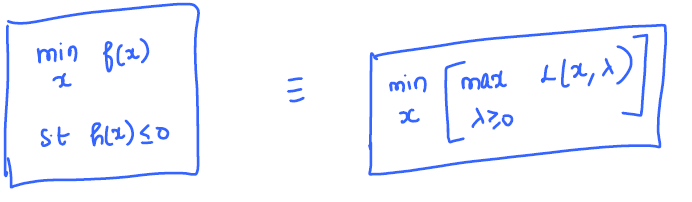
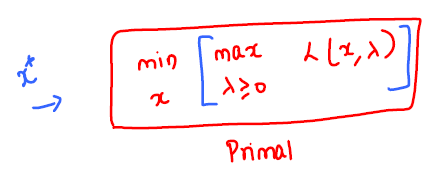
Consider the constrained optimization problem as follows:
Lagrangian function:
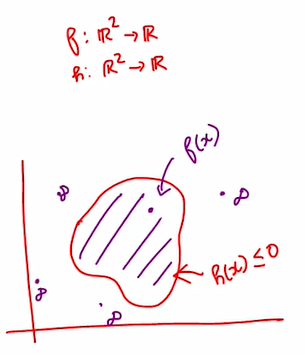
Note: depending upon if \(x\) is inside or outside the constrained set, we will get the objective value to be \(f(x)\) or \(\inf\).
| Weak Duality | Strong Duality |
|---|---|
|
|
If f and g are convex functions. |
Consider the optimization problem with multiple equality and inequality constraints as follows:
The Lagrangian function is expressed as follows:
Karush-Kuhn-Tucker Conditions:
Example:
minimize
\(f(x) = 2(x_1+1)^2 + 2(x_2-4)^2\)
subject to
\(x_1^2+x_2^2 \le 9\)
\(x_1+x_2 \ge 2\)
By Amrutha



