Retrospectives on Scaling Robot Learning
Andy Zeng
MIT CSL Seminar


"Dirty Laundry"
Symptoms of a larger problem
"Dirty Laundry"
Symptoms of a larger problem
The not-so-secret recipe to making a rockstar behavior cloning demo on real robots
"Dirty Laundry"
Symptoms of a larger problem
The not-so-secret recipe to making a rockstar behavior cloning demo on real robots
Step 1. collect your own "expert" data and don't trust anyone else to make it perfect
"Dirty Laundry"
Symptoms of a larger problem
The not-so-secret recipe to making a rockstar behavior cloning demo on real robots
Step 1. collect your own "expert" data and don't trust anyone else to make it perfect
Step 2. avoid "no action" data so your policy doesn’t just sit there
"Dirty Laundry"
Symptoms of a larger problem
The not-so-secret recipe to making a rockstar behavior cloning demo on real robots
Step 1. collect your own "expert" data and don't trust anyone else to make it perfect
Step 2. avoid "no action" data so your policy doesn’t just sit there
Step 3. It’s not working? Collect more data until "extrapolation" becomes "interpolation"
"Dirty Laundry"
Symptoms of a larger problem
The not-so-secret recipe to making a rockstar behavior cloning demo on real robots
Step 1. collect your own "expert" data and don't trust anyone else to make it perfect
Step 2. avoid "no action" data so your policy doesn’t just sit there
Step 3. It’s not working? Collect more data until "extrapolation" becomes "interpolation"
Step 4. Train and test on the same day because your setup might change tomorrow
"Dirty Laundry"
Symptoms of a larger problem
The not-so-secret recipe to making a rockstar behavior cloning demo on real robots
Step 1. collect your own "expert" data and don't trust anyone else to make it perfect
Step 2. avoid "no action" data so your policy doesn’t just sit there
Step 3. It’s not working? Collect more data until "extrapolation" becomes "interpolation"
Step 4. Train and test on the same day because your setup might change tomorrow
Mostly because we don't have a lot of data
Scaling Physical Robot Learning

Scaling robots ↔ cloud ↔ operator
Scaling Physical Robot Learning
Scaling robots ↔ cloud ↔ operator
+ Couple thousand episodes on a good week
- Still bottlenecked on rate of data collection
Scaling Physical Robot Learning
Scaling robots ↔ cloud ↔ operator
+ Couple thousand episodes on a good week
- Still bottlenecked on rate of data collection
10 robots: learn end-to-end pick and place
with objects the size of your palm
Scaling Physical Robot Learning
Scaling robots ↔ cloud ↔ operator
+ Couple thousand episodes on a good week
- Still bottlenecked on rate of data collection
10 robots: learn end-to-end pick and place
with objects the size of your palm
10x more robots = 10x dollars, manpower, space
VP: "but can you solve cooking though?"

Roboticist
Computer Vision
NLP
Internet-scale data
How do other fields scale up data collection?
Roboticist
Computer Vision
NLP
Internet-scale data
How do other fields scale up data collection?
Scripts that crawl the Internet
+ Autonomous
+ Easier to scale





– Maybe noisier
Many paths forward
Scaling Robot Learning
For practical applications
- Inductive biases of deep networks
- Prior structure (e.g. physics)
In pursuit of embodied AI
- Learning from the Internet


Make the most out of the data we have
How do we learn from the Internet?


MT-Opt, Kalashnikov, Varley, Hausman et al
XYZ Robotics
Many paths forward
For practical applications
- Inductive biases of deep networks
- Prior structure (e.g. physics)
In pursuit of embodied AI
- Learning from the Internet
Make the most out of the data we have
How do we learn from the Internet?











-> Highlight: "Socratic Models" (new!)
Many paths forward
For practical applications
- Inductive biases of deep networks
- Prior structure (e.g. physics)
In pursuit of embodied AI
- Learning from the Internet
Make the most out of the data we have
How do we learn from the Internet?
1
2
-> Highlight: "Socratic Models" (new!)
TossingBot
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
TossingBot


TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
TossingBot

TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
TossingBot
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
TossingBot

TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
TossingBot
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
Dense visual affordances are great for sample efficient grasping
Takeaway #1


Fully Conv Net
Orthographic
Projection
Grasping
Affordances

TossingBot
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
Dense visual affordances are great for sample efficient grasping
Takeaway #1
Fully Conv Net
Orthographic
Projection
Grasping
Affordances
f_g({\color{Green}s},{\color{Red}a})
Grasping value function
receptive field
grasp action
TossingBot
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
Dense visual affordances are great for sample efficient grasping
Takeaway #1
Fully Conv Net
Orthographic
Projection
Grasping
Affordances
f_g({\color{Green}s},{\color{Red}a})
Grasping value function
receptive field
grasp action
spatial action predictions anchored on visual features
- translation & rotation equivariance
TossingBot
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
Residual physics is great for sample efficient throwing
Takeaway #2
a={\color{Green}\pi}(s)
Physics-based controller

a={\color{Blue}f}(s)
a={\color{Green}\pi}(s)+{\color{Blue}f}(s,{\color{Green}\pi}(s))
Visuomotor policy
Residual physics
TossingBot
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
Residual physics is great for sample efficient throwing
Takeaway #2
a={\color{Green}\pi}(s)
Physics-based controller
Learns "residual" corrections
a={\color{Blue}f}(s)
a={\color{Green}\pi}(s)+{\color{Blue}f}(s,{\color{Green}\pi}(s))
Visuomotor policy
Residual physics

TossingBot
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
Interaction as a means to learn perception
Takeaway #3

TossingBot
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
Interaction as a means to learn perception
Takeaway #3
From learning manipulation affordances...
- Clusters form around visual features of similar objects
- Emerging perceptual representations from interaction
grounded on physics
Transporter Nets
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
CoRL 2020
Transporter Nets
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
CoRL 2020
Precise placing depends on the grasp


Transporter Nets
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
CoRL 2020

Precise placing depends on the grasp
Dense visual affordances for placing?
Transporter Nets
Geometric biases can be achieved by "modernizing" sliding window approach
Takeaway #1
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
CoRL 2020
f_\textrm{pick}(\mathbf{o}_t)\rightarrow \mathcal{T}_\textrm{pick}
f_\textrm{place}(\mathbf{o}_t,\mathcal{T}_\textrm{pick})\rightarrow \mathcal{T}_\textrm{place}
\mathcal{Q}_\textrm{place}(\tau|\mathbf{o}_t,\mathcal{T}_\textrm{pick}) = \psi(\mathbf{o}_t[\mathcal{T}_\textrm{pick}])*\phi(\mathbf{o}_t)[\tau]
\mathcal{T}_\textrm{place} = \argmax_{\{\tau_i\}} \mathcal{Q}_\textrm{place}(\tau_i|\mathbf{o}_t,\mathcal{T}_\textrm{pick})
Picking
Pick-conditioned placing
Cross-correlation of sliding window around the pick
Dense value function for placing
Transporter Nets
Softmax cross-entropy loss is great for behavior cloning
Takeaway #2
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
CoRL 2020

Expert label
Treat entire affordance map as a single probability distribution
Transporter Nets
Softmax cross-entropy loss is great for behavior cloning
Takeaway #2
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
CoRL 2020
Expert label
Behavior cloning
- Only one action label per timestep
- But true distribution is likely multimodal
Treat entire affordance map as a single probability distribution
Transporter Nets
Softmax cross-entropy loss is great for behavior cloning
Takeaway #2
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
CoRL 2020
- Surprisingly capable of capturing multimodal distributions with only one-hot labels
- Visual features provide a strong inductive bias for learning these modes

Implicit Behavioral Cloning
Softmax cross-entropy loss... actually in general...
Energy-based models are great for behavior cloning
Takeaway #1
Implicit Behavioral Cloning
Pete Florence et al., CoRL 2021

If you squint...
\hat{\textbf{a}} = \underset{\textbf{a} \in \mathcal{A}}{\arg\min} \ \ E_{\theta}(\textbf{o},\textbf{a})
BC policy learning as: instead of:
\hat{\textbf{a}} = F_{\theta}(\textbf{o})
Pretty sure that's an EBM
Implicit Behavioral Cloning
Softmax cross-entropy loss... actually in general...
Energy-based models are great for behavior cloning
Takeaway #1
Implicit Behavioral Cloning
Pete Florence et al., CoRL 2021
Learn a probability distribution over actions:
If you squint...
Pretty sure that's an EBM
\mathcal{L}_{\text{InfoNCE}} = \sum_{i=1}^N -\log \big( \tilde{p}_{\theta}( {\color{black} \mathbf{y}_i} | \ \mathbf{x}, \ {\color{red}\{\tilde{\mathbf{y}}^j_i\}_{j=1}^{N_{\text{neg.}}} } ) \big)
\tilde{p}_{\theta}( {\color{black} \mathbf{y}_i} | \ \mathbf{x}, \ {\color{red}\{\tilde{\mathbf{y}}^j_i\}_{j=1}^{N_{\text{neg.}}} } ) = \frac{e^{-E_{\theta}(\mathbf{x}_i, {\color{black} \mathbf{y}_i} )}} {e^{-E_{\theta}( \mathbf{x}_i, {\color{black} \mathbf{y}_i})} + {\color{red} \sum_{j=1}^{N_{\text{neg}}}} e^{-E_{\theta}(\mathbf{x}_i, {\color{red} \tilde{\mathbf{y}}^j_i} )} }
\hat{\textbf{a}} = \underset{\textbf{a} \in \mathcal{A}}{\arg\min} \ \ E_{\theta}(\textbf{o},\textbf{a})
BC policy learning as: instead of:
\hat{\textbf{a}} = F_{\theta}(\textbf{o})
Implicit Behavioral Cloning
Softmax cross-entropy loss... actually in general...
Energy-based models are great for behavior cloning
Takeaway #1
Implicit Behavioral Cloning
Pete Florence et al., CoRL 2021
Learn a probability distribution over actions:
If you squint...
\mathcal{L}_{\text{InfoNCE}} = \sum_{i=1}^N -\log \big( \tilde{p}_{\theta}( {\color{black} \mathbf{y}_i} | \ \mathbf{x}, \ {\color{red}\{\tilde{\mathbf{y}}^j_i\}_{j=1}^{N_{\text{neg.}}} } ) \big)
\tilde{p}_{\theta}( {\color{black} \mathbf{y}_i} | \ \mathbf{x}, \ {\color{red}\{\tilde{\mathbf{y}}^j_i\}_{j=1}^{N_{\text{neg.}}} } ) = \frac{e^{-E_{\theta}(\mathbf{x}_i, {\color{black} \mathbf{y}_i} )}} {e^{-E_{\theta}( \mathbf{x}_i, {\color{black} \mathbf{y}_i})} + {\color{red} \sum_{j=1}^{N_{\text{neg}}}} e^{-E_{\theta}(\mathbf{x}_i, {\color{red} \tilde{\mathbf{y}}^j_i} )} }
- Conditioned on observation (raw images)
- Uniformly sampled negatives
\hat{\textbf{a}} = \underset{\textbf{a} \in \mathcal{A}}{\arg\min} \ \ E_{\theta}(\textbf{o},\textbf{a})
BC policy learning as: instead of:
\hat{\textbf{a}} = F_{\theta}(\textbf{o})
Pretty sure that's an EBM
Implicit Behavioral Cloning
Energy-based models are great for behavior cloning
Takeaway #1
Implicit Behavioral Cloning
Pete Florence et al., CoRL 2021
+ Can represent multi-modal actions
\hat{\textbf{a}} = \underset{\textbf{a} \in \mathcal{A}}{\arg\min} \ \ E_{\theta}(\textbf{o},\textbf{a})
BC policy learning as: instead of:
\hat{\textbf{a}} = F_{\theta}(\textbf{o})

Fly left or right around the tree?
Implicit Behavioral Cloning
Energy-based models are great for behavior cloning
Takeaway #1
Implicit Behavioral Cloning
Pete Florence et al., CoRL 2021
+ Can represent multi-modal actions
+ More sample efficiently learn discontinuous trajectories
\hat{\textbf{a}} = \underset{\textbf{a} \in \mathcal{A}}{\arg\min} \ \ E_{\theta}(\textbf{o},\textbf{a})
BC policy learning as: instead of:
\hat{\textbf{a}} = F_{\theta}(\textbf{o})
Fly left or right around the tree?
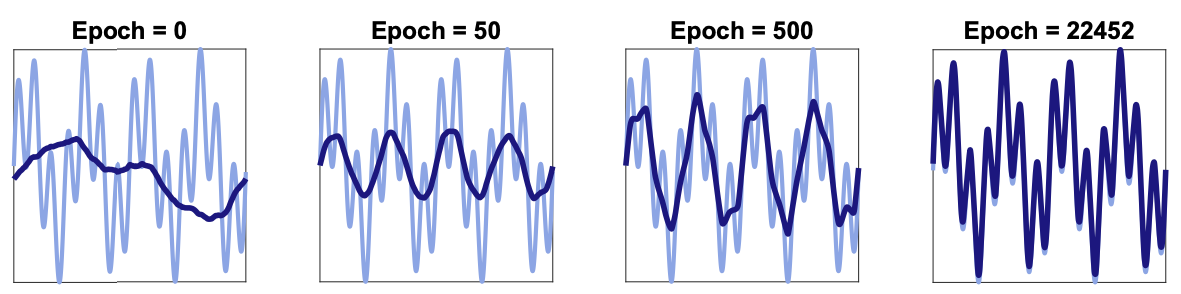
The Convergence Rate of Neural Networks for Learned Functions of Different Frequencies
Ronen Basri et al., NeurIPS 2019
subtle but decisive maneuvers
Implicit Kinematic Policies
Implicit policies give rise to better action representations for continuous control
Takeaway #2
Implicit Kinematic Policies: Unifying Joint and Cartesian Action Spaces in End-to-End Robot Learning
Aditya Ganapathi et al., ICRA 2022

Adi Ganapathi


Implicit Kinematic Policies
Implicit policies give rise to better action representations for continuous control
Takeaway #2
Implicit Kinematic Policies: Unifying Joint and Cartesian Action Spaces in End-to-End Robot Learning
Aditya Ganapathi et al., ICRA 2022
Adi Ganapathi


RSS Workshop on Action Representations for Learning in Continuous Control, 2020
Implicit Kinematic Policies
Implicit policies give rise to better action representations for continuous control
Takeaway #2
Implicit Kinematic Policies: Unifying Joint and Cartesian Action Spaces in End-to-End Robot Learning
Aditya Ganapathi et al., ICRA 2022
Adi Ganapathi
Which action space?
- Let the model decide:
\hat{\textbf{a}} = \underset{\textbf{a} \in \mathcal{A}}{\arg\min} \ \ E_{\theta}(\textbf{o},\textbf{a}_\textrm{joints},\textbf{a}_\textrm{cart})


Implicit Kinematic Policies
Implicit policies give rise to better action representations for continuous control
Takeaway #2
Implicit Kinematic Policies: Unifying Joint and Cartesian Action Spaces in End-to-End Robot Learning
Aditya Ganapathi et al., ICRA 2022
Adi Ganapathi
Which action space?
- Let the model decide:
\hat{\textbf{a}} = \underset{\textbf{a} \in \mathcal{A}}{\arg\min} \ \ E_{\theta}(\textbf{o},\textbf{a}_\textrm{joints},\textbf{a}_\textrm{cart})
Can also use (differentiable) forward kinematics to "fix" joint encoder errors:

\hat{\textbf{a}} = \underset{\textbf{a} \in \mathcal{A}}{\arg\min} \ \ E_{\theta}(\textbf{o},\textbf{a}_\textrm{joints},{\color{Blue}\textrm{FK}}(f(\textbf{a}_\textrm{joints})))

How much data do we need?
50 expert demos
How much data do we need?

500 expert demos
50 expert demos
How much data do we need?
500 expert demos
5000 expert demos
50 expert demos
How much data do we need?

500 expert demos
5000 expert demos
50 expert demos
Many paths forward
For practical applications
- Inductive biases of deep networks
- Prior structure (e.g. physics)
In pursuit of embodied AI
- Learning from the Internet
Make the most out of the data we have
How do we learn from the Internet?
Learning to See before Learning to Act
Pre-training on large-scale offline datasets (e.g., ImageNet, COCO) can help affordance models
Takeaway #1
Learning to See before Learning to Act: Visual Pre-training for Manipulation
Lin Yen-Chen et al., ICRA 2020
Lin Yen-Chen



Learning to See before Learning to Act
Pre-training on large-scale offline datasets (e.g., ImageNet, COCO) can help affordance models
Takeaway #1
Learning to See before Learning to Act: Visual Pre-training for Manipulation
Lin Yen-Chen et al., ICRA 2020
Lin Yen-Chen

XIRL
XIRL: Cross-embodiment Inverse Reinforcement Learning
Kevin Zakka et al., CoRL 2021
Kevin Zakka

XIRL
Learning from Internet-scale videos (e.g., YouTube) may require embodiment-agnostic methods
Takeaway #1
XIRL: Cross-embodiment Inverse Reinforcement Learning
Kevin Zakka et al., CoRL 2021
Kevin Zakka

Schmeckpeper et al., CoRL '20
XIRL
Learning from Internet-scale videos (e.g., YouTube) may require embodiment-agnostic methods
Takeaway #1
XIRL: Cross-embodiment Inverse Reinforcement Learning
Kevin Zakka et al., CoRL 2021
Kevin Zakka
Schmeckpeper et al., CoRL '20

XIRL
Learning from Internet-scale videos (e.g., YouTube) may require embodiment-agnostic methods
Takeaway #1
XIRL: Cross-embodiment Inverse Reinforcement Learning
Kevin Zakka et al., CoRL 2021
Kevin Zakka
Schmeckpeper et al., CoRL '20

Task: "put all pens in the cup, transfer to another"
XIRL
Learning from Internet-scale videos (e.g., YouTube) may require embodiment-agnostic methods
Takeaway #1
XIRL: Cross-embodiment Inverse Reinforcement Learning
Kevin Zakka et al., CoRL 2021
Kevin Zakka
Schmeckpeper et al., CoRL '20

Task: "put all pens in the cup, transfer to another"
XIRL
Learning from Internet-scale videos (e.g., YouTube) may require embodiment-agnostic methods
Takeaway #1
XIRL: Cross-embodiment Inverse Reinforcement Learning
Kevin Zakka et al., CoRL 2021
Kevin Zakka

XIRL
Learning from Internet-scale videos (e.g., YouTube) may require embodiment-agnostic methods
Takeaway #1
XIRL: Cross-embodiment Inverse Reinforcement Learning
Kevin Zakka et al., CoRL 2021
Kevin Zakka
Learn generic visual reward function
-
Temporal Cycle Consistency
- Self-supervised embedding

\widetilde{V_{ij}^t} = \sum_k^{L_j} \alpha_k V_j^k
\alpha_k = \frac{e^{-\Vert V_i^t-V_j^k\Vert^2}}{\sum_k^{L_j} e^{-\Vert V_i^t-V_j^k \Vert^2}}
\beta_{ijt}^{k} = \frac{e^{-\Vert\widetilde{V_{ij}^t}-V_i^k\Vert^2}}{\sum_k^{L_i} e^{-\Vert\widetilde{V_{ij}^t} - V_i^k\Vert^2}}
XIRL
Learning from Internet-scale videos (e.g., YouTube) may require embodiment-agnostic methods
Takeaway #1
XIRL: Cross-embodiment Inverse Reinforcement Learning
Kevin Zakka et al., CoRL 2021
Kevin Zakka
Learn generic visual reward function
-
Temporal Cycle Consistency
- Self-supervised embedding
\widetilde{V_{ij}^t} = \sum_k^{L_j} \alpha_k V_j^k
\alpha_k = \frac{e^{-\Vert V_i^t-V_j^k\Vert^2}}{\sum_k^{L_j} e^{-\Vert V_i^t-V_j^k \Vert^2}}
\beta_{ijt}^{k} = \frac{e^{-\Vert\widetilde{V_{ij}^t}-V_i^k\Vert^2}}{\sum_k^{L_i} e^{-\Vert\widetilde{V_{ij}^t} - V_i^k\Vert^2}}

Improving Robot Learning with Internet-Scale Data



Existing offline datasets
Videos
Improving Robot Learning with Internet-Scale Data
Foundation Models

Existing offline datasets
Videos
Socratic Models
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io (new!)

Socratic Models
New multimodal capabilities via guided "Socratic dialogue" between zero-shot foundation models
Takeaway #1
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io (new!)
Socratic Models
New multimodal capabilities via guided "Socratic dialogue" between zero-shot foundation models
Takeaway #1
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io (new!)

Socratic Models
Example output from CLIP + GPT-3: "This image shows an inviting dining space with plenty of natural light."
Example
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io (new!)


Socratic Models
New multimodal capabilities via guided "Socratic dialogue" between zero-shot foundation models
Egocentric perception!
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io (new!)

Socratic Models
Video Question Answering as a Reading Comprehension problem
Takeaway #2
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io (new!)


Socratic Models
Video Question Answering as a Reading Comprehension problem
Takeaway #2
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io (new!)

Demo?
Video Question Answering as a Reading Comprehension problem
Takeaway #2
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io (new!)
Socratic Models
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io (new!)



Socratic Models
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io (new!)
Socratic Models
Build reconstructions of the visual world with language for our robot/AR assistants to use
Takeaway #3
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io (new!)

Reconstruction Representations
- 3D meshes
- 3D point clouds
- Volumetric grids
- 2D Height-maps
- Learned latent space
- Language?
Socratic Models
Build reconstructions of the visual world with language for our robot/AR assistants to use
Takeaway #3
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io (new!)
Reconstruction Representations
- 3D meshes
- 3D point clouds
- Volumetric grids
- 2D Height-maps
- Learned latent space
- Language?
Allow robots to interface with models trained on Internet-scale data that store "commonsense knowledge"
In pursuit of embodied AI
Zero-shot Perception
Zero-shot Planning


Recipe for robot intelligence?

SayCan
Socratic Models
wenlong.page/language-planner
In pursuit of embodied AI
Zero-shot Perception
Zero-shot Planning
Recipe for robot intelligence?
wenlong.page/language-planner
Toddlers
Commonsense
SayCan
Socratic Models
In pursuit of embodied AI
Zero-shot Perception
Zero-shot Planning
Recipe for robot intelligence?
wenlong.page/language-planner
Toddlers
Commonsense
Internet-scale data
SayCan
Socratic Models
In pursuit of embodied AI
What's next? Your work!
Zero-shot Perception
Zero-shot Planning
Recipe for robot intelligence?
wenlong.page/language-planner
Toddlers
Commonsense
Internet-scale data
SayCan
Socratic Models
Thank you!
Pete Florence
Tom Funkhouser
Adrian Wong
Kaylee Burns
Jake Varley
Erwin Coumans
Alberto Rodriguez
Johnny Lee





























Vikas Sindhwani
Ken Goldberg
Stefan Welker
Corey Lynch
Laura Downs
Jonathan Tompson
Shuran Song
Vincent Vanhoucke
Kevin Zakka
Michael Ryoo
Travis Armstrong
Maria Attarian
Jonathan Chien
Dan Duong
Krzysztof Choromanski
Phillip Isola
Tsung-Yi Lin
Ayzaan Wahid
Igor Mordatch
Oscar Ramirez
Federico Tombari
Daniel Seita
Lin Yen-Chen
Adi Ganapathi
2022-MIT-CSL
By Andy Zeng




