

Google DeepMind Robotics (formerly known as Brain)
From words to actions
Andy Zeng
UPenn GRASP Lab SFI Seminar Series


In the pursuit of generally intelligent machines...
Build decision-making agents that interact with the world and improve themselves over time
TossingBot
Transporter Nets
Implicit Behavior Cloning
closed-loop vision-based policies

Manipulation
w/ machine learning
TossingBot
Interact with the physical world to learn bottom-up commonsense
Transporter Nets
Implicit Behavior Cloning
i.e. "how the world works"
Manipulation
w/ machine learning
On the quest for shared priors
Interact with the physical world to learn bottom-up commonsense
w/ machine learning
i.e. "how the world works"

# Tasks
Data

MARS Reach arm farm '21
On the quest for shared priors
Interact with the physical world to learn bottom-up commonsense
w/ machine learning
i.e. "how the world works"
# Tasks
Data
Expectation
Reality
Complexity in environment, embodiment, contact, etc.
MARS Reach arm farm '21
Machine learning is a box
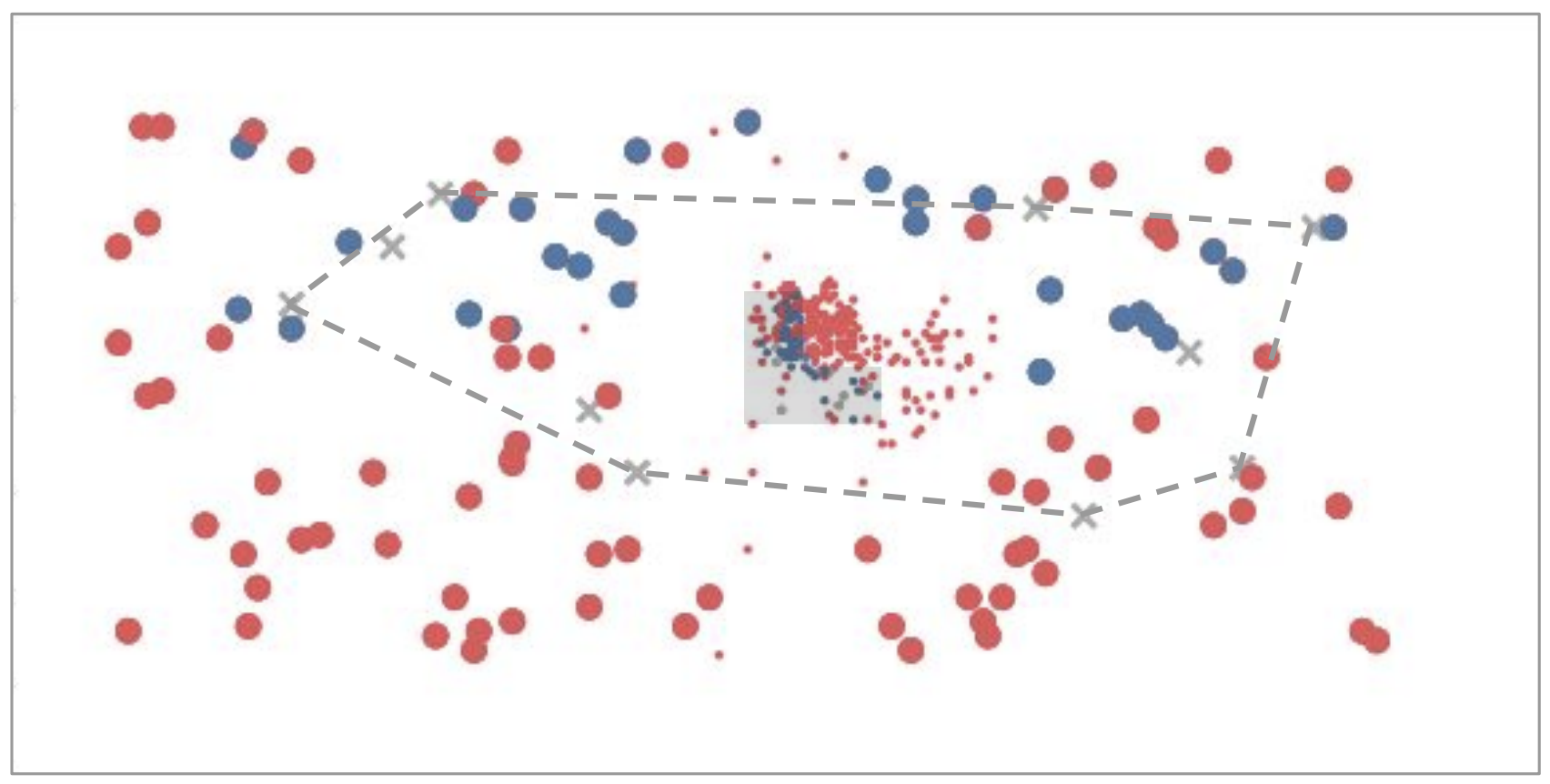
Interpolation
Extrapolation
adapted from Tomás Lozano-Pérez
Machine learning is a box
Interpolation
Extrapolation
Internet
Meanwhile in NLP...
Large Language Models

Large Language Models?
Internet
Meanwhile in NLP...
Books
Recipes
Code
News
Articles
Dialogue
Demo
Quick Primer on Language Models
Tokens (inputs & outputs)
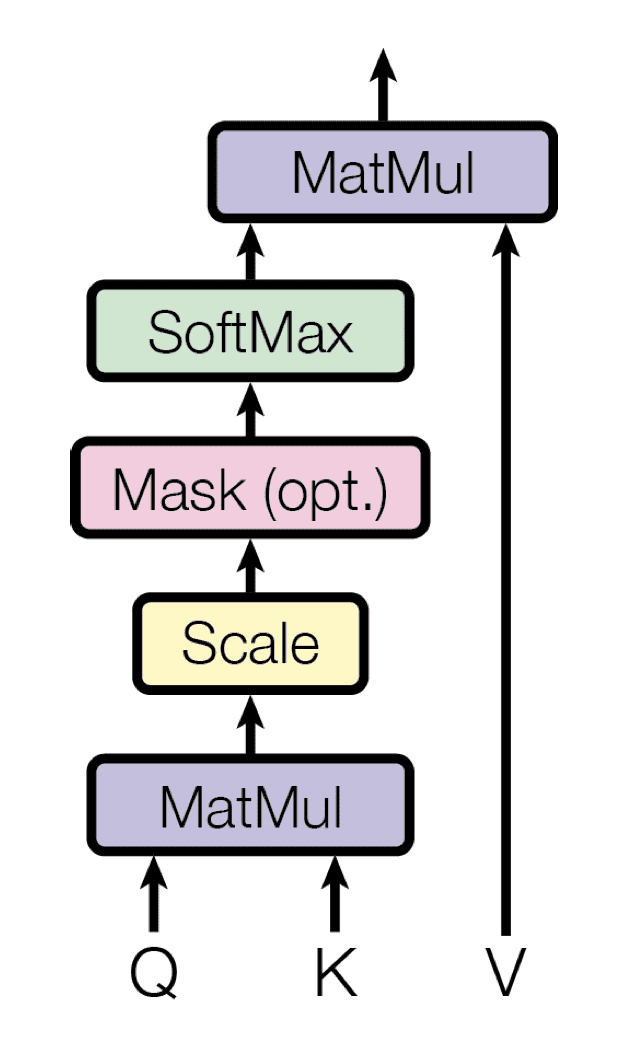
Transformers (models)
Attention Is All You Need, NeurIPS 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
Quick Primer on Language Models
Tokens (inputs & outputs)
Transformers (models)
Pieces of words (BPE encoding)
big
bigger
per word:
biggest
small
smaller
smallest
big
er
per token:
est
small
Attention Is All You Need, NeurIPS 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
Quick Primer on Language Models
Tokens (inputs & outputs)
Transformers (models)
Self-Attention
Pieces of words (BPE encoding)
big
bigger
per word:
biggest
small
smaller
smallest
big
er
per token:
est
small
y
x_1
x_3
x_2
Attention Is All You Need, NeurIPS 2017
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Lukasz Kaiser, Illia Polosukhin
\text{softmax}(\frac{QK^\intercal}{\sqrt{d_k}})V
Bigger is Better

Neural Language Models: Bigger is Better, WeCNLP 2018
Noam Shazeer
Bigger is Better
Neural Language Models: Bigger is Better, WeCNLP 2018
Noam Shazeer

Bigger is Better
Neural Language Models: Bigger is Better, WeCNLP 2018
Noam Shazeer

Bigger is Better
Neural Language Models: Bigger is Better, WeCNLP 2018
Noam Shazeer

Bigger is Better
Neural Language Models: Bigger is Better, WeCNLP 2018
Noam Shazeer

Robot Planning
Visual Commonsense
Robot Programming
Socratic Models
Code as Policies
PaLM-SayCan

Demo
Somewhere in the space of interpolation
Lives
Socratic Models & PaLM-SayCan
One way to use Foundation Models with "language as middleware"
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io

Socratic Models & PaLM-SayCan
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Visual Language Model
CLIP, ALIGN, LiT,
SimVLM, ViLD, MDETR
Human input (task)
One way to use Foundation Models with "language as middleware"
Socratic Models & PaLM-SayCan
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Visual Language Model
CLIP, ALIGN, LiT,
SimVLM, ViLD, MDETR
Human input (task)
Large Language Models for
High-Level Planning
Language-conditioned Policies
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances say-can.github.io
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents wenlong.page/language-planner
One way to use Foundation Models with "language as middleware"
Socratic Models: Robot Pick-and-Place Demo
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io

For each step, predict pick & place:
Socratic Models & PaLM-SayCan
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Visual Language Model
CLIP, ALIGN, LiT,
SimVLM, ViLD, MDETR
Human input (task)
Large Language Models for
High-Level Planning
Language-conditioned Policies
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances say-can.github.io
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents wenlong.page/language-planner
One way to use Foundation Models with "language as middleware"

Inner Monologue
Inner Monologue: Embodied Reasoning through Planning with Language Models
https://innermonologue.github.io
Limits of language as information bottleneck?
- Loses spatial (numerical) precision
- Highly (distributional) multimodal
- Not as information-rich as other modalities
Limits of language as information bottleneck?
- Loses spatial (numerical) precision
- Highly (distributional) multimodal
- Not as information-rich as other modalities
- Only for high level? what about control?
Perception
Planning
Control
Socratic Models
Inner Monologue
PaLM-SayCan
Wenlong Huang et al, 2022
Imitation? RL?
Engineered?
Intuition and commonsense is not just a high-level thing
Intuition and commonsense is not just a high-level thing
Applies to low-level behaviors too
- spatial: "move a little bit to the left"
- temporal: "move faster"
- functional: "balance yourself"
Behavioral commonsense is the "dark matter" of robotics:
Intuition and commonsense is not just a high-level thing
Can we extract these priors from language models?
Applies to low-level behaviors too
- spatial: "move a little bit to the left"
- temporal: "move faster"
- functional: "balance yourself"
Behavioral commonsense is the "dark matter" of robotics:
Language models can write code
Code as a medium to express more complex plans

Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control


Live Demo
In-context learning is supervised meta learning
Trained with autoregressive models via "packing"

x_1, f(x_1), x_2, f(x_2), ..., x_\textrm{query} \rightarrow
f(x_\textrm{query})
f \in \mathcal{F} \quad \textrm{drawn i.i.d. from} \quad D_\mathcal{F}
In-context learning is supervised meta learning
Trained with autoregressive models via "packing"
x_1, f(x_1), x_2, f(x_2), ..., x_\textrm{query} \rightarrow
f(x_\textrm{query})
f \in \mathcal{F} \quad \textrm{drawn i.i.d. from} \quad D_\mathcal{F}
Better with non-recurrent autoregressive sequence models

Transformers at certain scale can generalize to unseen (i.e. tasks)

f
"Data Distributional Properties Drive Emergent In-Context Learning in Transformers"
Chan et al., NeurIPS '22
"General-Purpose In-Context Learning by Meta-Learning Transformers" Kirsch et al., NeurIPS '22
"What Can Transformers Learn In-Context? A Case Study of Simple Function Classes" Garg et al., '22
Language models can write code
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control
use NumPy,
SciPy code...
Language models can write code
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control
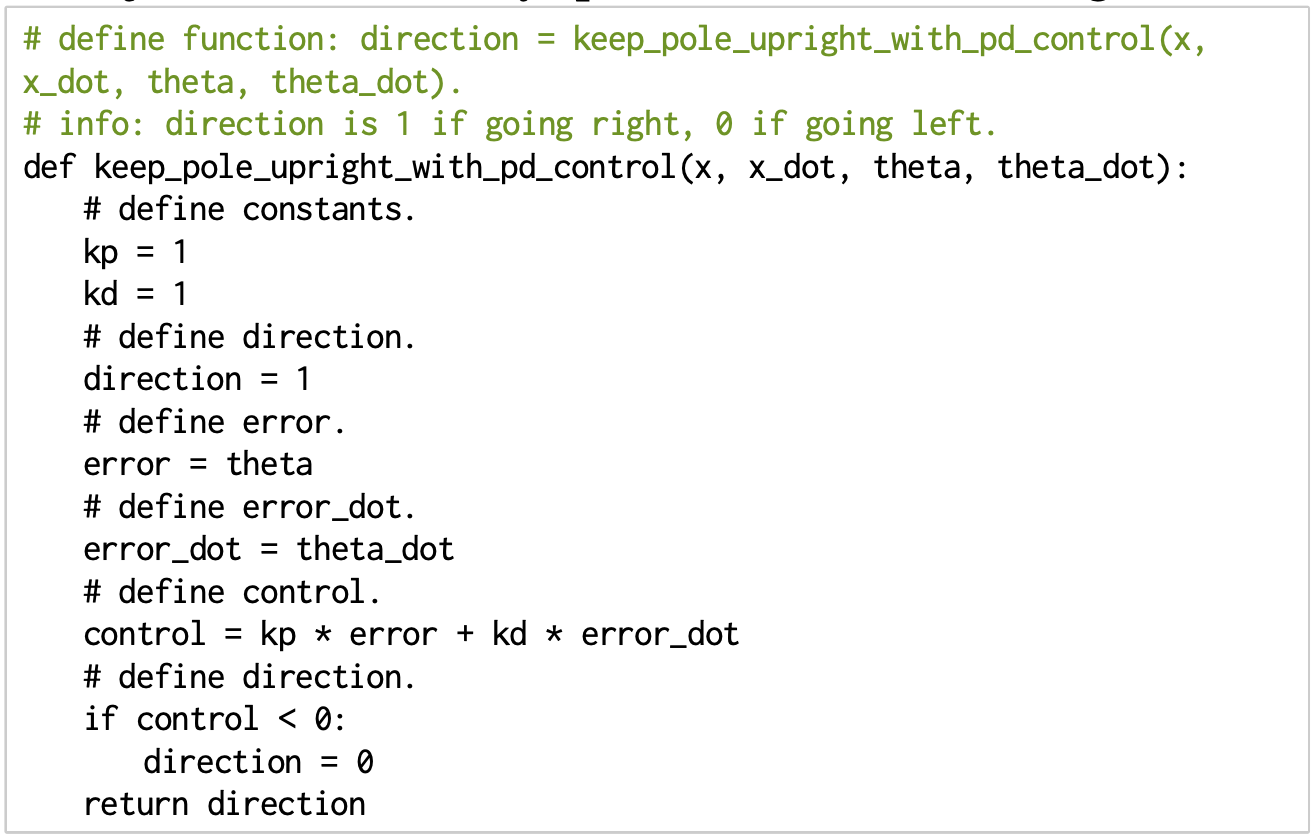

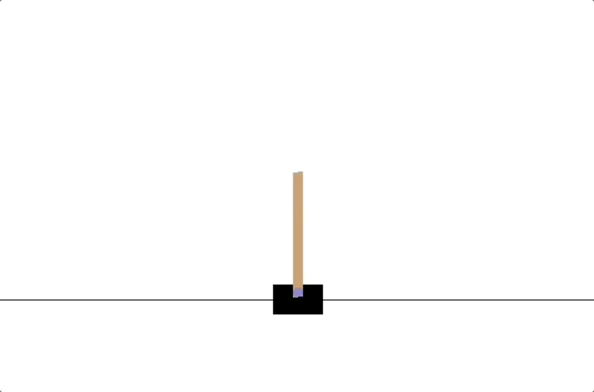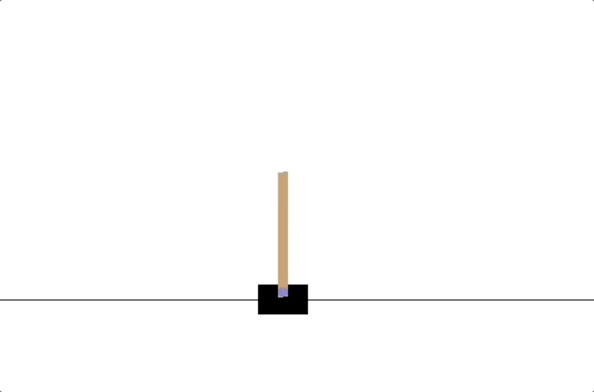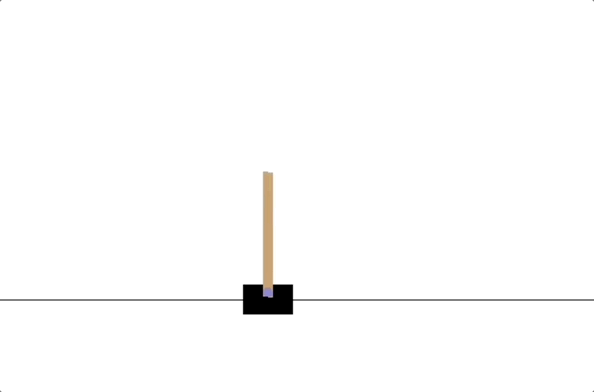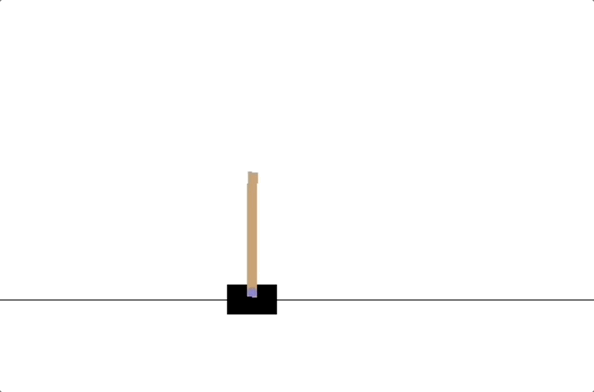
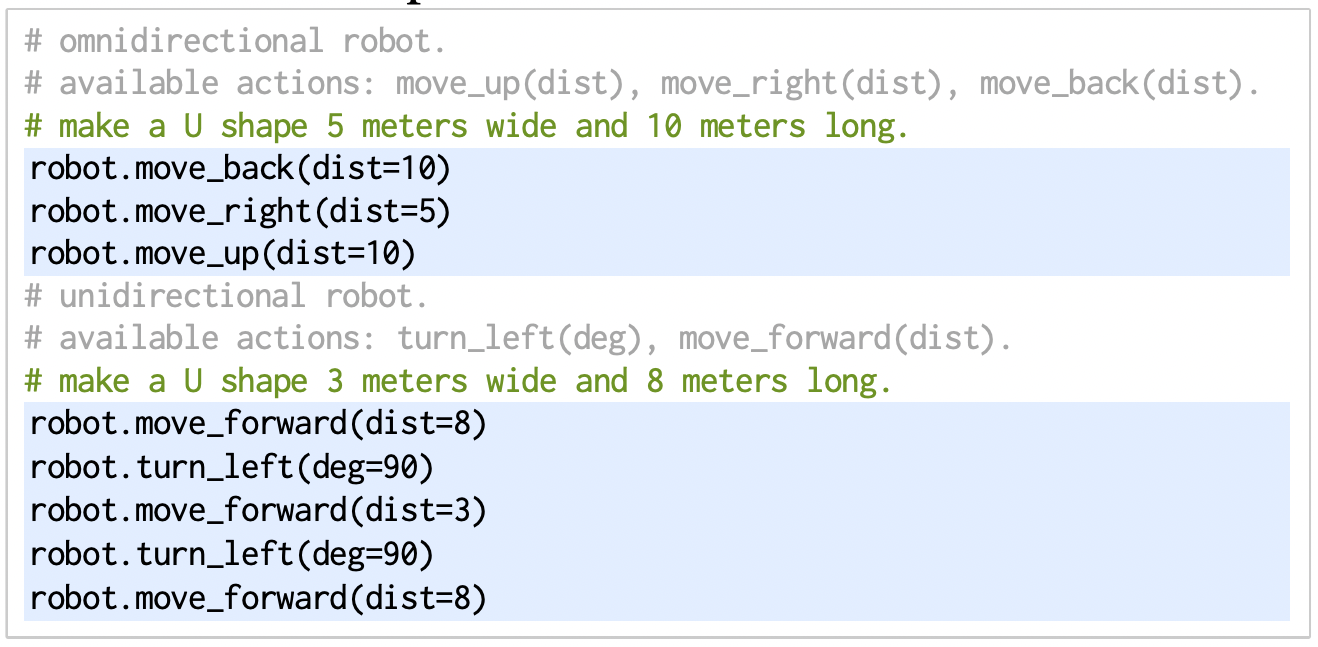
- PD controllers
- impedance controllers
Language models can write code
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control

Language models can write code
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control
What is the foundation models for robotics?
Extensions to Code as Policies
1. Fuse visual-language features into robot maps
2. Use code as policies to do spatial reasoning for navigation
"Visual Language Maps" Chenguang Huang et al., ICRA 2023
Extensions to Code as Policies
1. Fuse visual-language features into robot maps
2. Use code as policies to do spatial reasoning for navigation
"Visual Language Maps" Chenguang Huang et al., ICRA 2023
1. Language to code for cost/reward functions
2. Optimize control trajectories with MPC/RL
"Language to Rewards" Wenhao Yu et al., CoRL 2023
Extensions to Code as Policies
1. Fuse visual-language features into robot maps
2. Use code as policies to do spatial reasoning for navigation
"Visual Language Maps" Chenguang Huang et al., ICRA 2023
1. Language to code for cost/reward functions
2. Optimize control trajectories with MPC/RL
"Language to Rewards" Wenhao Yu et al., CoRL 2023
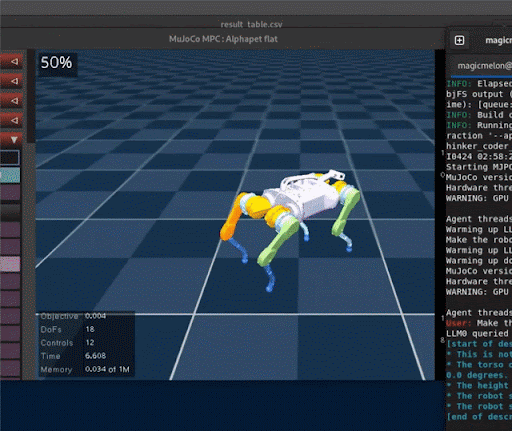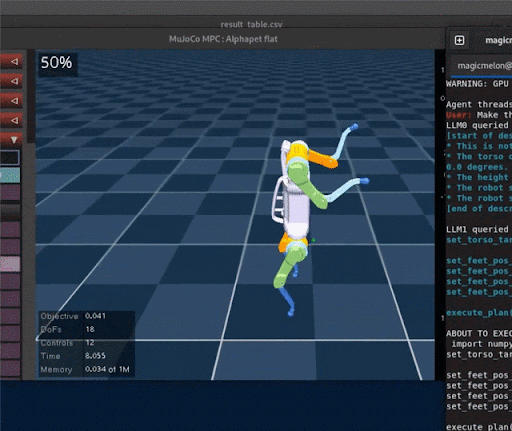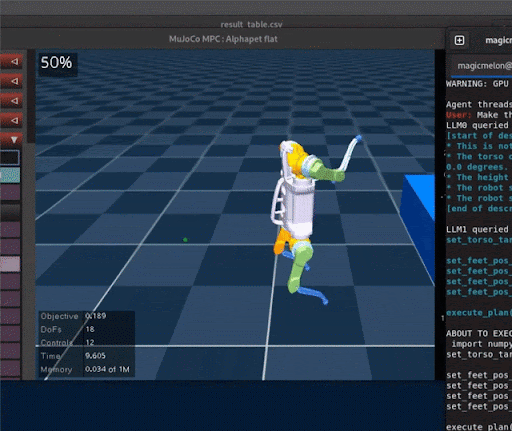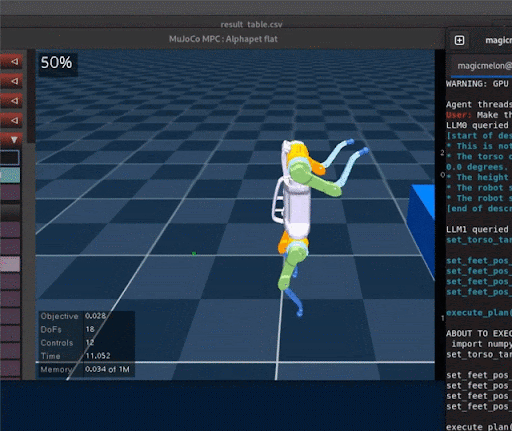
Extensions to Code as Policies
1. Fuse visual-language features into robot maps
2. Use code as policies to do spatial reasoning for navigation
"Visual Language Maps" Chenguang Huang et al., ICRA 2023
1. Language to code for cost/reward functions
2. Optimize control trajectories with MPC/RL
"Language to Rewards" Wenhao Yu et al., CoRL 2023
Scaling robotics with Foundation Models
Robot Learning
Not a lot of robot data
Lots of Internet data



500 expert demos
5000 expert demos
50 expert demos
Foundation Models
Robot Learning
Not a lot of robot data
Lots of Internet data

500 expert demos
5000 expert demos
50 expert demos
Scaling robotics with Foundation Models
Foundation Models
Robot Learning
Not a lot of robot data
Lots of Internet data

256K token vocab w/ word embedding dim = 18,432
collecting (mostly) diverse data
Scaling robotics with Foundation Models
Foundation Models
PaLM-sized robot dataset = 100 robots for 24 yrs
Robot Learning
- Finding other sources of data (sim, YouTube)
- Improve data efficiency with prior knowledge
Not a lot of robot data
Lots of Internet data
256K token vocab w/ word embedding dim = 18,432
collecting (mostly) diverse data
Scaling robotics with Foundation Models
Foundation Models
PaLM-sized robot dataset = 100 robots for 24 yrs
Robot Learning
Foundation Models
- Finding other sources of data (sim, YouTube)
- Improve data efficiency with prior knowledge
Not a lot of robot data
Lots of Internet data
Embrace foundation models to help close the gap!
256K token vocab w/ word embedding dim = 18,432
collecting (mostly) diverse data
Scaling robotics with Foundation Models
PaLM-sized robot dataset = 100 robots for 24 yrs
Robot Learning
- Finding other sources of data (sim, YouTube)
- Improve data efficiency with prior knowledge
Not a lot of robot data
Lots of Internet data
Scaling robotics with Foundation Models
Phase 1
Build with off-the-shelf models
< 100 robots
Phase 2
Finetune off-the-shelf models
100 < number of robots < 1000
Phase 3
Train our own models
1000+ robots (over 2 yrs)
Foundation Models
Embrace foundation models to help close the gap!

Building PaLM-E: An Embodied Multimodal Language Model

Building PaLM-E: An Embodied Multimodal Language Model
Finetuning pre-trained models helps

Larger models retain pre-trained performance

Limited compute budget (TPU chips for 10 days), higher learning rates, smaller batch sizes
More recent threads
Modeling uncertainty "know when they don't know"
General pattern completion machines

User: "remove some chip bags"
Robot: "how many?"
1-\alpha \leq \mathbb{P} (Y_\textrm{test} \in C(X_\textrm{test})) \leq 1 - \alpha + \frac{1}{n+1}
42: 52 51, 1, 52 46, 1, 51 41, 1, 49 36, 1, 45 31, 0, 41 36, 1, 37 31, 0, 33 35, 1, 29 30, 0, 25 34, 0, 21 38, 0, 18 43, 0, 16 46, 0, 15 50, 0, 15 54, 1, 16 49, 0, 16 53, 1, 17 47, 1, 16 41, 0, 14 45, 0, 13 49, 1, 12 43, 0, 11 47, 0, 10 51, 0, 10 54, 1, 11 49, 0, 11 52, 1, 11 47, 0, 11 50, 0, 11 54, 1, 12 48, 0, 11 52, 0, 12 56, 0, 13 60, 1, 16 54, 1, 16 48, 1, 16 43, 0, 14 46, 0, 13 50, 1, 13 45, 1, 12 39, 0, 9 43, 1, 8 37
43: 43 50, 1, 43 45, 0, 42 50, 0, 42 55, 0, 43 59, 0, 45 64, 1, 49 59, 1, 51 54, 1, 52 49, 1, 52 44, 0, 50 49, 1, 50 44, 0, 49 49, 1, 49 44, 0, 47 49, 0, 47 54, 0, 48 59, 0, 50 64, 1, 53 59, 1, 55 54, 1, 56 49, 1, 56 45, 1, 55 40, 0, 52 45, 1, 51 40, 0, 49 45, 0, 48 50, 0, 48 55, 1, 49 50, 0, 49 54, 0, 50 59, 0, 52 64, 0, 55 69, 1, 60 64, 1, 63 60, 1, 66 55, 0, 67 60, 0, 69 66, 1, 73 61, 0, 76 67, 1, 80 63, 0, 83 68, 0, 87 74, 0, 93 80
45: 46 50, 0, 46 55, 0, 47 60, 0, 49 64, 0, 53 69, 1, 57 64, 1, 61 60, 1, 63 55, 0, 64 60, 1, 67 56, 1, 68 51, 1, 69 47, 1, 68 43, 0, 66 48, 1, 66 44, 1, 64 39, 0, 62 44, 1, 60 40, 0, 58 45, 0, 57 50, 0, 57 55, 1, 58 50, 1, 58 46, 1, 57 41, 0, 55 46, 1, 54 41, 0, 52 46, 0, 51 51, 1, 51 46, 1, 50 42, 0, 48 46, 1, 47 41, 1, 45 37, 0, 42 41, 1, 40 36, 0, 37 41, 1, 34 36, 0, 31 40, 0, 29 44, 0, 27 49, 1, 27 43, 1, 25 38, 1, 22 32, 1, 18 27, 1, 13 21, 1, 6 15
47: 57 50, 1, 57 45, 1, 55 40, 1, 53 35, 0, 49 40, 1, 47 35, 1, 44 31, 0, 39 35, 0, 35 40, 0, 33 44, 0, 32 49, 0, 31 53, 1, 32 48, 0, 32 52, 0, 32 57, 1, 34 51, 1, 34 46, 0, 33 50, 0, 33 55, 0, 34 59, 1, 36 54, 0, 37 58, 0, 39 63, 1, 42 58, 0, 44 62, 1, 47 57, 0, 49 62, 1, 52 57, 1, 54 52, 1, 54 48, 1, 54 43, 0, 52 48, 1, 52 43, 1, 50 38, 0, 47 43, 0, 45 48, 0, 45 53, 0, 46 57, 0, 47 62, 0, 50 67, 0, 54 72, 1, 60 67, 0, 64 72, 0, 69 77, 0, 76 83, 1, 83 79, 1, 90 75, 1, 96 71
51: 55 49, 0, 55 54, 0, 56 59, 0, 58 64, 0, 61 69, 0, 66 75, 1, 72 70, 1, 77 66, 1, 80 62, 1, 83 58, 1, 85 54, 1, 86 50, 1, 86 46, 1, 85 42, 1, 83 38, 0, 80 44, 1, 79 40, 1, 76 36, 1, 73 32, 0, 69 37, 1, 66 33, 0, 61 38, 1, 59 34, 1, 55 29, 0, 50 34, 0, 46 39, 0, 43 43, 0, 41 48, 1, 41 43, 1, 39 38, 1, 36 33, 0, 32 37, 0, 29 42, 0, 27 46, 1, 26 41, 0, 24 45, 0, 23 49, 0, 23 53, 1, 23 48, 0, 23 52, 0, 23 56, 1, 24 50, 0, 24 54, 1, 26 49, 0, 25 53, 1, 26 48, 1, 25 42, 1, 24 37, 1, 20 31, 0, 16 35, 1, 12 29, 0, 7 33
52: 40 50, 0, 40 54, 1, 41 49, 0, 41 54, 0, 42 59, 1, 44 53, 1, 45 48, 1, 45 43, 0, 43 48, 1, 42 43, 0, 41 48, 0, 40 52, 1, 41 47, 1, 40 42, 0, 38 47, 0, 37 51, 1, 38 46, 0, 37 51, 1, 37 45, 0, 36 50, 1, 36 45, 0, 35 49, 1, 34 44, 0, 33 48, 0, 33 53, 1, 33 48, 0, 33 52, 0, 33 56, 0, 35 61, 0, 37 65, 1, 41 60, 1, 43 55, 1, 45 50, 1, 44 45, 0, 43 50, 1, 43 45, 1, 42 39, 0, 39 44, 1, 38 39, 0, 35 44, 0, 34 48, 1, 33 43, 1, 31 37, 1, 28 32, 0, 24 36, 0, 21 41, 0, 19 45, 0, 17 49, 1, 17 43, 1, 15 37, 0, 12 41, 1, 10 35, 1, 7 30
60: 45 50, 1, 45 45, 0, 44 50, 1, 44 45, 0, 42 50, 1, 42 45, 0, 41 49, 0, 41 54, 1, 42 49, 0, 41 53, 1, 42 48, 1, 42 43, 1, 40 38, 1, 37 33, 0, 33 38, 0, 30 42, 0, 28 46, 1, 27 41, 0, 25 45, 0, 24 49, 0, 24 53, 0, 25 58, 1, 26 52, 1, 27 47, 0, 26 51, 1, 26 45, 0, 25 50, 0, 25 54, 1, 26 48, 1, 26 43, 0, 24 47, 0, 23 51, 0, 24 55, 0, 25 59, 0, 27 64, 1, 30 58, 1, 32 53, 1, 33 48, 0, 32 52, 0, 33 56, 0, 34 61, 0, 37 65, 0, 41 70, 1, 45 65, 1, 49 60, 1, 51 55, 1, 52 50, 0, 52 55, 0, 53 60, 0, 56 65, 1, 59 60, 0, 62 65, 1, 65 61, 1, 68 56, 0, 69 61, 1, 72 57, 0, 74 62, 0, 77 68, 0, 81 73, 0, 87 79, 0, 94 85
75: 52 50, 0, 52 55, 1, 53 50, 1, 53 46, 1, 52 41, 0, 50 46, 1, 49 41, 0, 47 46, 0, 46 51, 0, 46 55, 1, 47 50, 1, 47 45, 1, 46 40, 0, 44 45, 0, 43 50, 0, 43 55, 1, 44 50, 0, 44 54, 1, 45 49, 0, 44 54, 1, 45 49, 1, 45 44, 0, 44 49, 1, 43 44, 0, 42 48, 1, 41 43, 0, 40 48, 1, 39 43, 1, 37 38, 1, 34 32, 0, 30 37, 0, 27 41, 0, 25 45, 1, 24 40, 1, 21 34, 0, 18 38, 0, 15 42, 0, 13 46, 0, 12 50, 0, 12 54, 1, 13 48, 0, 13 52, 0, 13 56, 1, 14 50, 0, 14 54, 0, 15 58, 1, 17 52, 0, 18 56, 1, 19 50, 0, 19 54, 0, 20 58, 0, 22 62, 0, 25 66, 1, 29 61, 1, 32 56, 0, 33 60, 1, 35 55, 1, 36 49, 1, 36 44, 1, 35 39, 0, 32 43, 1, 31 38, 0, 28 42, 0, 26 47, 0, 25 51, 1, 25 45, 1, 24 40, 0, 22 44, 0, 20 48, 0, 20 52, 1, 20 47, 1, 19 41, 1, 17 35, 1, 14 30, 0, 9 34, 0, 5 37
98:

Self-improving LLM-based policies w/o training
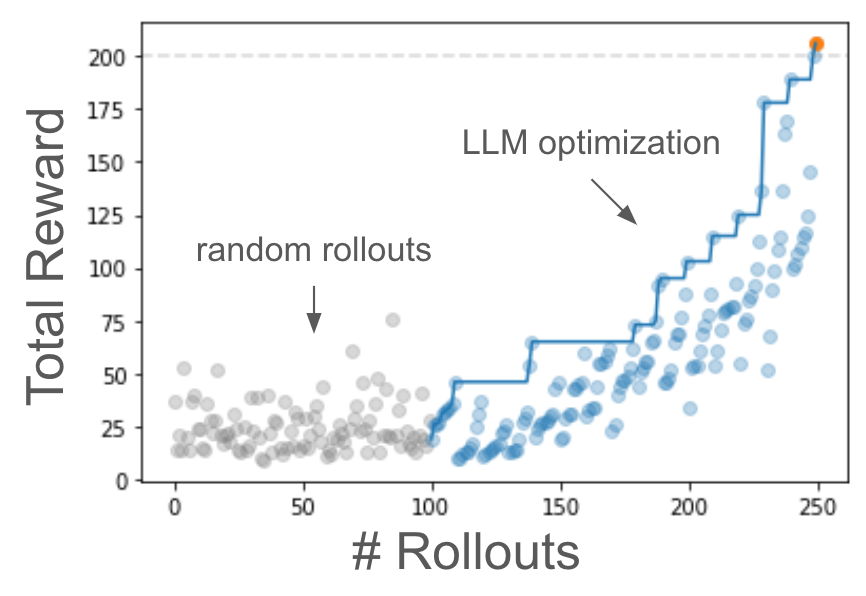
Thank you!
Pete Florence
Adrian Wong
Johnny Lee











Vikas Sindhwani
Stefan Welker
Vincent Vanhoucke
Kevin Zakka
Michael Ryoo
Maria Attarian
Brian Ichter
Krzysztof Choromanski
Federico Tombari

Jacky Liang
Aveek Purohit

Wenlong Huang
Fei Xia
Peng Xu
Karol Hausman





and many others!
2023-UPenn-GRASP-lab-talk
By Andy Zeng




