3D Vision & Language as Middleware
Andy Zeng
3D Scene Understanding, CVPR '23 Workshop

Manipulation


From structure to symmetries, etc.
\text{sign}(x)
Learning Precise 3D Manipulation from Multiple Uncalibrated Cameras
Akinola et al., ICRA 2020

Image credit: Dmitry Kalashnikov
4-3{x_1}{x_2}-4{x_2}^2+{x_1}{x_2}^3+2{x_2}^4
Non-linearities can be simpler to model in higher dims
Semi-Algebraic Approximation using Christoffel-Darboux Kernel
Marx et al., Springer 2021










From 3D vision to robotics
3D Vision
3D Vision for Robotics
Foundation Models for Robotics






6D Pose Est. (Amazon Picking)
Matterport3D
3DMatch
Pushing & Grasping
TossingBot
Transporter Nets
PaLM SayCan
Socratic Models
PaLM-E: Embodied Multimodal Language Model
From 3D vision to robotics
3D Vision
3D Vision for Robotics
Foundation Models for Robotics
6D Pose Est. (Amazon Picking)
Matterport3D
3DMatch
Pushing & Grasping
TossingBot
Transporter Nets
PaLM SayCan
Socratic Models
PaLM-E: Embodied Multimodal Language Model
Project Reach: scale up human teleop
Remote teleop robots to do useful work (amortize cost of data collection)
then automate with robot learning
+ sample efficient robot learning

Project Reach arm farm '21
Transporter Nets
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
CoRL 2020



Precise placing depends on the grasp
Dense visual affordances for placing?
Sample efficient pick & place
Transporter Nets
Geometric shape biases can be achieved by "modernizing" sliding window approach
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
CoRL 2020
f_\textrm{pick}(\mathbf{o}_t)\rightarrow \mathcal{T}_\textrm{pick}
f_\textrm{place}(\mathbf{o}_t,\mathcal{T}_\textrm{pick})\rightarrow \mathcal{T}_\textrm{place}
\mathcal{Q}_\textrm{place}(\tau|\mathbf{o}_t,\mathcal{T}_\textrm{pick}) = \psi(\mathbf{o}_t[\mathcal{T}_\textrm{pick}])*\phi(\mathbf{o}_t)[\tau]
\mathcal{T}_\textrm{place} = \argmax_{\{\tau_i\}} \mathcal{Q}_\textrm{place}(\tau_i|\mathbf{o}_t,\mathcal{T}_\textrm{pick})
Picking
Pick-conditioned placing
Cross-correlation of sliding window around the pick
Dense value function for placing
Transporter Nets
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
CoRL 2020

Expert label
Treat entire affordance map as a single probability distribution
Behavior cloning
- Only one action label per timestep
- But true distribution is likely multimodal
Softmax cross-entropy loss is great for behavior cloning
Implicit Behavior Cloning
CoRL 2021
Transporter Nets
Transporter Networks: Rearranging the Visual World for Robotic Manipulation
CoRL 2020
- Surprisingly capable of capturing multimodal distributions with only one-hot labels
- Visual features & shape priors provide a strong inductive bias for learning these modes

Softmax cross-entropy loss is great for behavior cloning
Transporter Nets Limitations
MIRA: Mental Imagery for Robotic Affordances
Lin Yen-Chen, Pete Florence, Andy Zeng, Jonathan T. Barron, Yilun Du, Wei-Chiu Ma, Anthony Simeonov, Alberto Rodriguez Garcia, Phillip Isola, CoRL 2022
- Only explored shape priors in 2D... can we go 3D?
- Only applied for pick & place... what about other things?
- Shape matching, scene generation, 3D reconstruction, 3D affordances, etc.
- Requires a 3D sensor... can we get away with only 2D images? (see MIRA)
- Naive multi-task did not yield positive transfer over single tasks
On the quest for shared priors
Interact with the physical world to learn bottom-up commonsense
i.e. "shared knowledge"
# Tasks
Data

Expectation
MARS Reach arm farm '21
with machine learning
On the quest for shared priors
Interact with the physical world to learn bottom-up commonsense
i.e. "shared knowledge"
# Tasks
Data
Expectation
Reality
Complexity in environment, embodiment, contact, etc.
MARS Reach arm farm '21
with machine learning
Does multi-task learning result in positive transfer of representations?
Past couple years of research suggest: its complicated
Recent work in multi-task learning...
In robot learning...
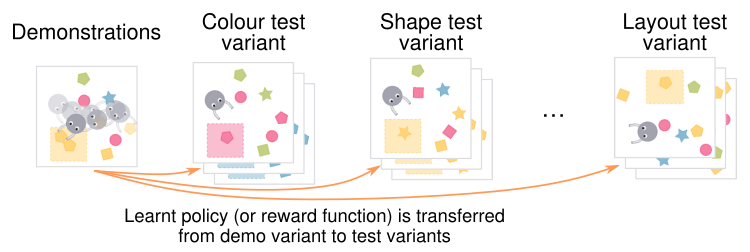
Sam Toyer, et al., "MAGICAL", NeurIPS 2020
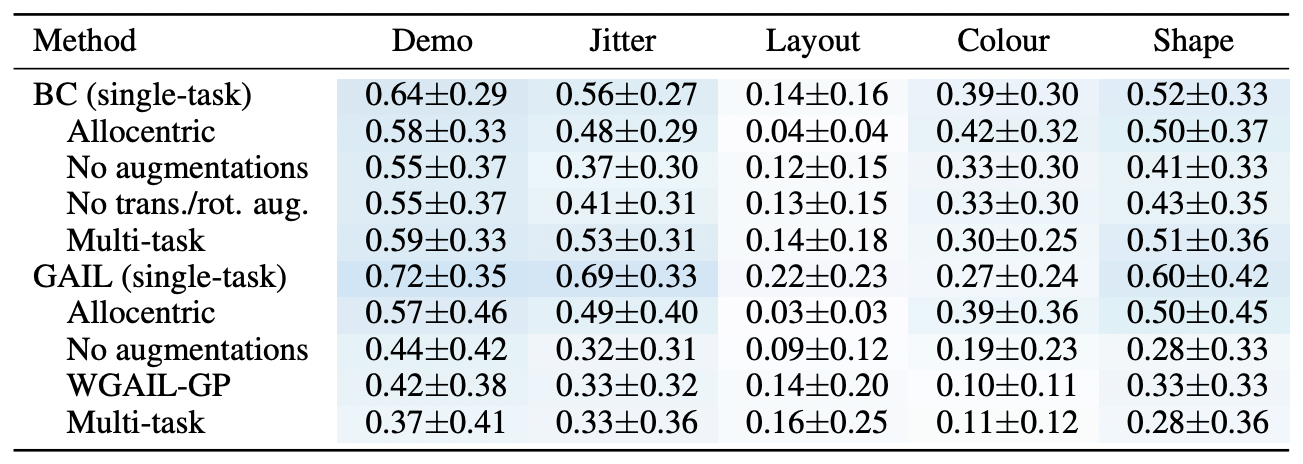
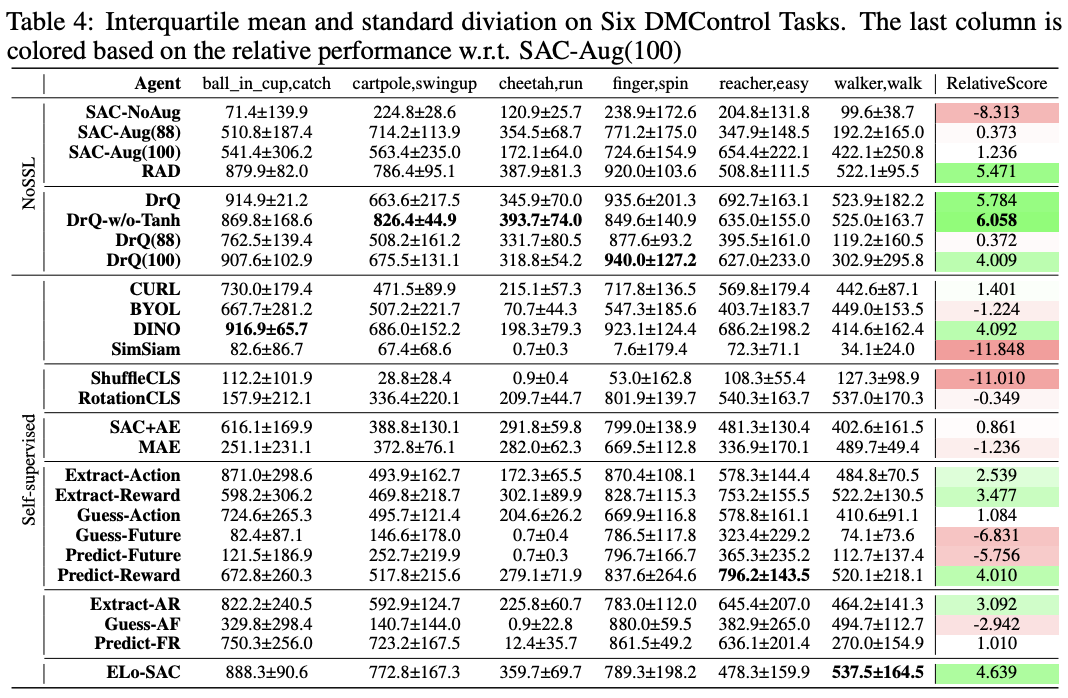
Xiang Li et al., "Does Self-supervised Learning Really Improve Reinforcement Learning from Pixels?", 2022
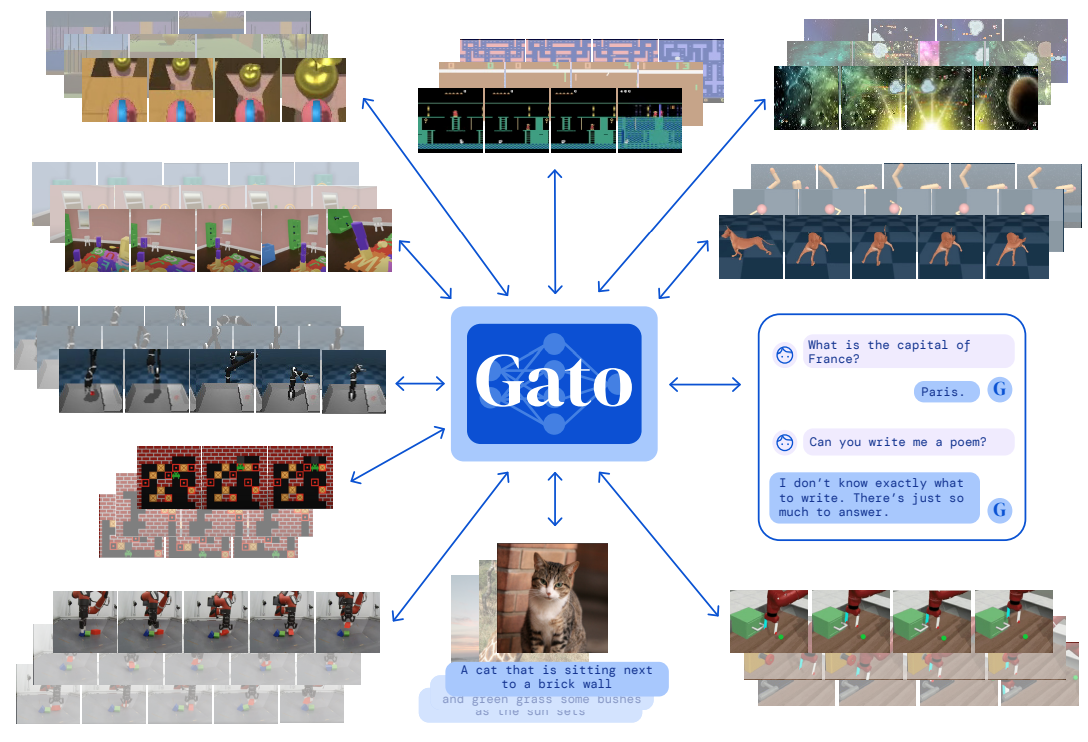
Scott Reed, Konrad Zolna, Emilio Parisotto, et al., "A Generalist Agent", 2022

Amir Zamir, Alexander Sax, William Shen, et al., "Taskonomy", CVPR 2018
In computer vision...
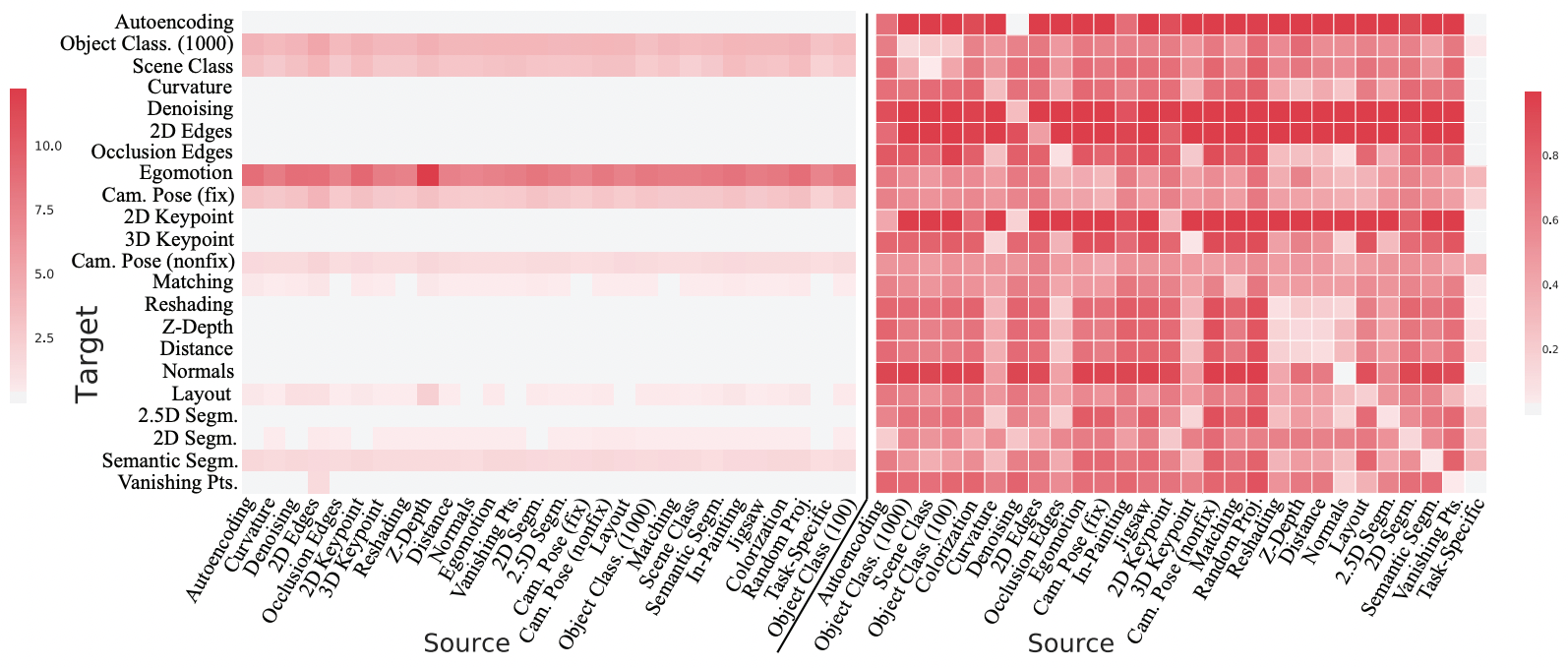
Multi-task learning grounded in language
Multi-task learning grounded in language seems more likely to lead to positive transfer
Mohit Shridhar, Lucas Manuelli, Dieter Fox, "CLIPort: What and Where Pathways for Robotic Manipulation", CoRL 2021
Multi-task learning grounded in language
Multi-task learning grounded in language seems more likely to lead to positive transfer
Mohit Shridhar, Lucas Manuelli, Dieter Fox, "CLIPort: What and Where Pathways for Robotic Manipulation", CoRL 2021



Language may provide an inductive bias for compositional generalization in multi-task robot learning
Language may provide an inductive bias for compositional generalization in multi-task robot learning
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin et al., "PaLM", 2022
Advent of Large Language Models
Language as Middleware
2 ways to use it as intermediate representation for robot learning
Implicit (finetune with lots of data)
Explicit (not as much data)
PaLM SayCan
Socratic Models
PaLM-E: Embodied Multimodal Language Model
Language as Middleware
2 ways to use it as intermediate representation for robot learning
Implicit (finetune with lots of data)
Explicit (not as much data)
PaLM SayCan
Socratic Models
PaLM-E: Embodied Multimodal Language Model
Socratic Models & PaLM-SayCan
One way to use Foundation Models with "language as middleware"
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io

Socratic Models & PaLM-SayCan
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Visual Language Model
CLIP, ALIGN, LiT,
SimVLM, ViLD, MDETR
Human input (task)
One way to use Foundation Models with "language as middleware"
Socratic Models & PaLM-SayCan
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Visual Language Model
CLIP, ALIGN, LiT,
SimVLM, ViLD, MDETR
Human input (task)
Large Language Models for
High-Level Planning
Language-conditioned Policies
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances say-can.github.io
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents wenlong.page/language-planner
One way to use Foundation Models with "language as middleware"
Socratic Models: Robot Pick-and-Place Demo
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io

For each step, predict pick & place:
Socratic Models & PaLM-SayCan
Open research problem, but here's one way to do it
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Visual Language Model
CLIP, ALIGN, LiT,
SimVLM, ViLD, MDETR
Human input (task)
Large Language Models for
High-Level Planning
Language-conditioned Policies
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances say-can.github.io
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents wenlong.page/language-planner

Inner Monologue
Inner Monologue: Embodied Reasoning through Planning with Language Models
https://innermonologue.github.io
Limits of language as information bottleneck?
- Loses spatial (numerical) precision
- Highly (distributional) multimodal
- Not as information-rich as other modalities
Limits of language as information bottleneck?
- Loses spatial (numerical) precision
- Highly (distributional) multimodal
- Not as information-rich as other modalities
- Only for high level? what about low-level?
Perception
Planning
Control
Socratic Models
Inner Monologue
PaLM-SayCan
Wenlong Huang et al, 2022
Imitation? RL?
Engineered?
Intuition and commonsense is not just a high-level thing
Intuition and commonsense is not just a high-level thing
Applies to low-level reasoning too
- spatial: "move a little bit to the left"
- temporal: "move faster"
- functional: "balance yourself"
Behavioral commonsense is the "dark matter" of interactive intelligence:

Intuition and commonsense is not just a high-level thing
Can we extract these priors from language models?
Applies to low-level reasoning too
- spatial: "move a little bit to the left"
- temporal: "move faster"
- functional: "balance yourself"
Behavioral commonsense is the "dark matter" of interactive intelligence:
Language models can write code
Code as a medium to express low-level commonsense
Live Demo
In-context learning is supervised meta learning
Trained with autoregressive models via "packing"

x_1, f(x_1), x_2, f(x_2), ..., x_\textrm{query} \rightarrow
f(x_\textrm{query})
f \in \mathcal{F} \quad \textrm{drawn i.i.d. from} \quad D_\mathcal{F}
In-context learning is supervised meta learning
Trained with autoregressive models via "packing"
x_1, f(x_1), x_2, f(x_2), ..., x_\textrm{query} \rightarrow
f(x_\textrm{query})
f \in \mathcal{F} \quad \textrm{drawn i.i.d. from} \quad D_\mathcal{F}
Better with non-recurrent autoregressive sequence models

Transformers at certain scale can generalize to unseen (i.e. tasks)

f
"Data Distributional Properties Drive Emergent In-Context Learning in Transformers"
Chan et al., NeurIPS '22
"General-Purpose In-Context Learning by Meta-Learning Transformers" Kirsch et al., NeurIPS '22
"What Can Transformers Learn In-Context? A Case Study of Simple Function Classes" Garg et al., '22
Language models can write code
Code as a medium to express more complex plans

Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control


Live Demo
https:youtu.be/byavpcCRaYI
Outstanding Paper Award in Robot Learning Finalist, ICRA 2023
Language models can write code
Code as a medium to express more complex plans
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control
Live Demo
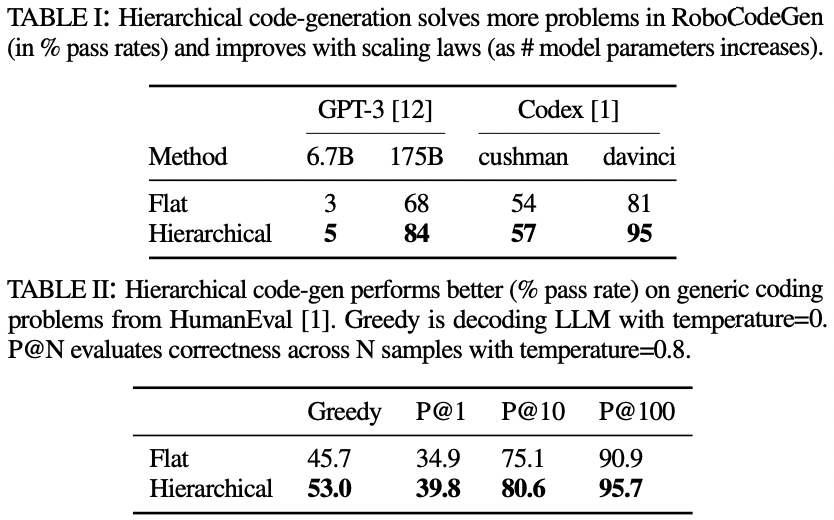
Outstanding Paper Award in Robot Learning Finalist, ICRA 2023
Language models can write code
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control
use NumPy,
SciPy code...
Outstanding Paper Award in Robot Learning Finalist, ICRA 2023
Language models can write code
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control
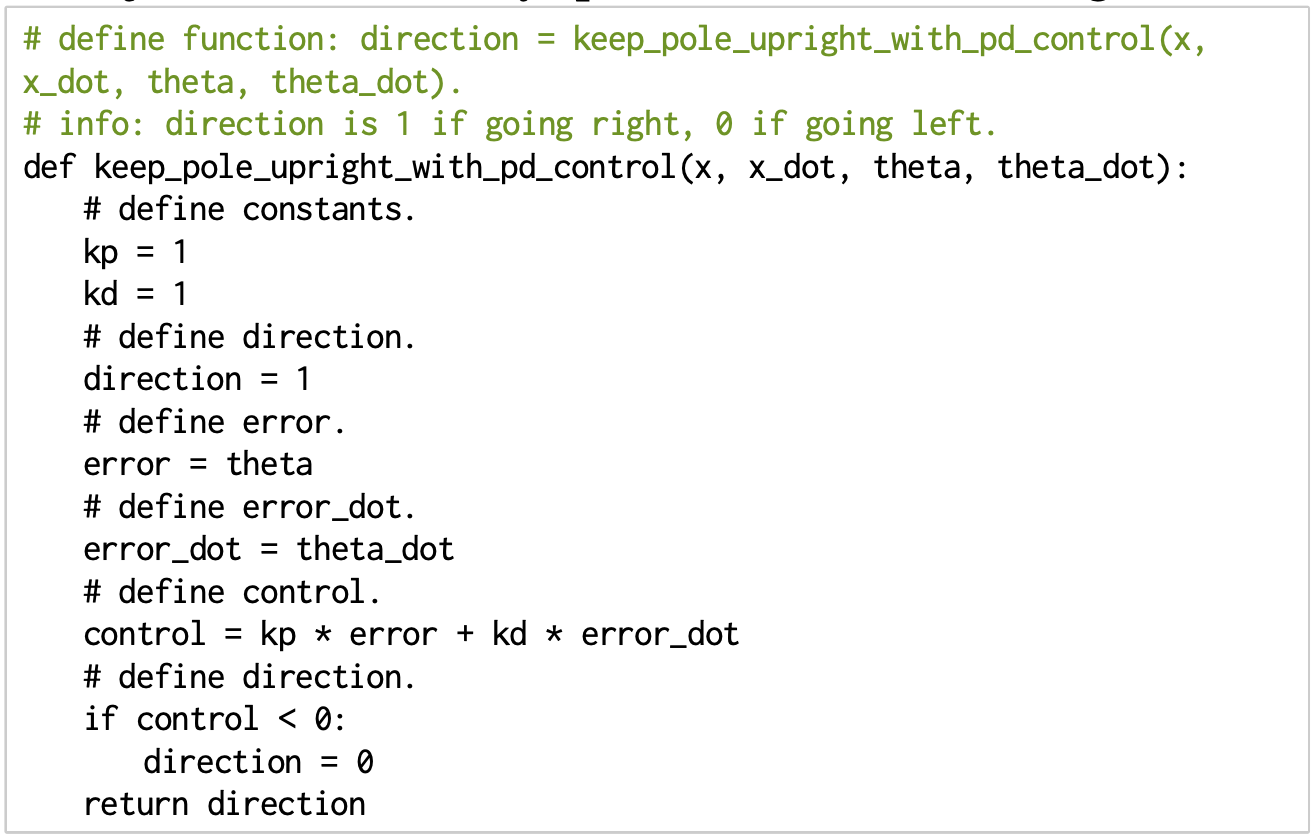

- PD controllers
- impedance controllers
Outstanding Paper Award in Robot Learning Finalist, ICRA 2023
Language models can write code
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control

Outstanding Paper Award in Robot Learning Finalist, ICRA 2023
Language models can write code
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control
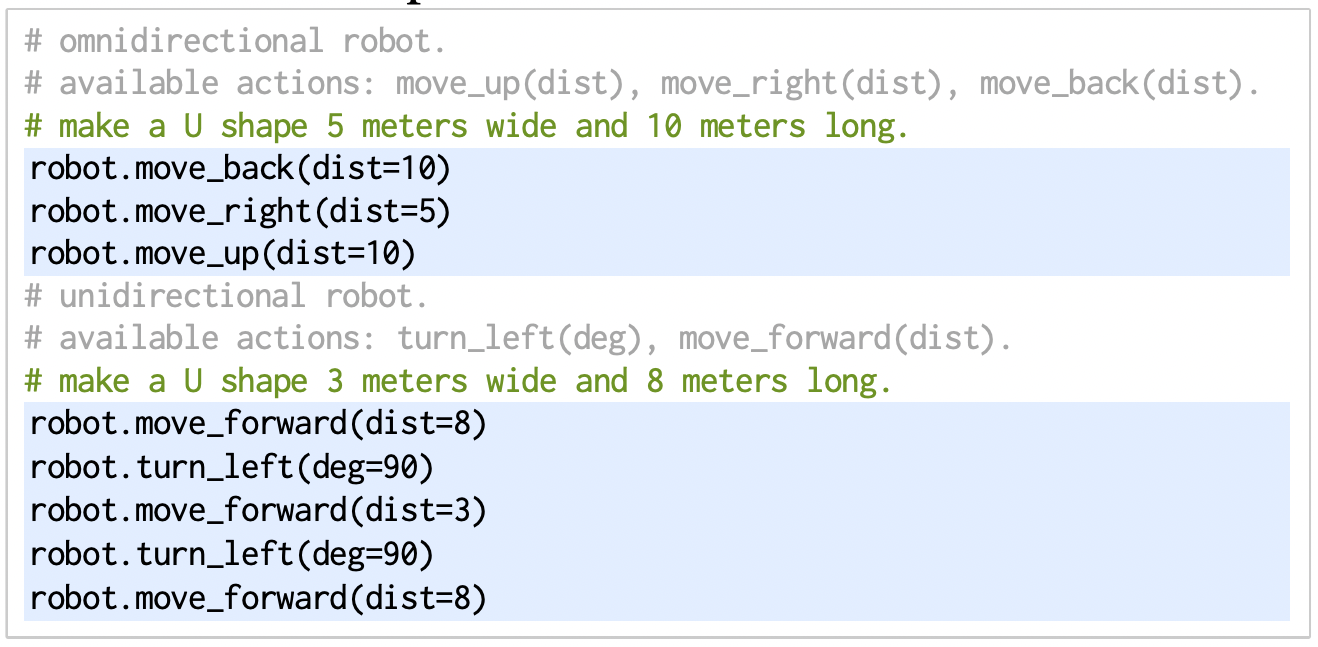
What is the foundation models for robotics?
Outstanding Paper Award in Robot Learning Finalist, ICRA 2023
VLMaps + Code as Policies for more spatial reasoning
1. Fuse visual-language features into robot maps
2. Use code as policies to do spatial reasoning for navigation
"Visual Language Maps" Chenguang Huang et al., ICRA 2023

"Audio Visual Language Maps" Chenguang Huang et al., 2023
Fuse all the modalities! (including audio)
(i.e. semantic memory with Foundation Models)
3D Vision Wishlist
- How 3D reasoning can enable language to inform low-level control?
- How to ground shapes/geometry in language?
- How can we use code-writing LLMs for 3D reasoning?

Language
Symmetries
PaLM-E
PaLM-SayCan
Socratic Models
Code as Policies
VLMaps
CLIPort
Transporter Nets
End2end BC
3D vision work...
Thank you!
Pete Florence
Adrian Wong
Johnny Lee











Vikas Sindhwani
Stefan Welker
Vincent Vanhoucke
Kevin Zakka
Michael Ryoo
Maria Attarian
Brian Ichter
Krzysztof Choromanski
Federico Tombari

Jacky Liang
Aveek Purohit

Wenlong Huang
Fei Xia
Peng Xu
Karol Hausman





and many others!
2023-CVPR-workshop-scene-understanding-talk
By Andy Zeng




