Talk About Representations
Andy Zeng
RSS Workshop on Implicit Representations for Robotic Manipulation


TossingBot's Representations

TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
TossingBot's Representations

TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
TossingBot's Representations
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
TossingBot's Representations
TossingBot's Representations

TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
TossingBot's Representations
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020


Fully Conv Net
Orthographic
Projection
Grasping
Affordances
f_g({\color{Green}s},{\color{Red}a})
Grasping value function
receptive field
grasp action

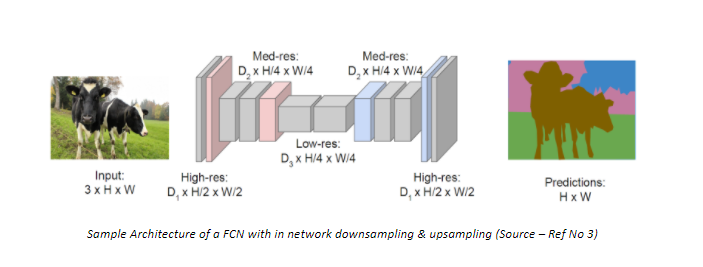
Throw Velocities
+Target location

TossingBot's Representations
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
Fully Conv Net
Orthographic
Projection
Grasping
Affordances
Throw Velocities
+Target location

what did TossingBot learn?
On the hunt for the "best" state representation
Learned Visual Representations
z
how to represent:
semantic?
compact?
general?
interpretable?
On the hunt for the "best" state representation
Haochen Shi and Huazhe Xu et al., RSS 2022
Learned Visual Representations
z
how to represent:
semantic?
compact?
general?
interpretable?
Dynamics Representations

Self-supervised Representations
Misha Laskin and Aravind Srinivas et al., ICML 2020

On the hunt for the "best" state representation
Haochen Shi and Huazhe Xu et al., RSS 2022
Learned Visual Representations

NeRF Representations
3D Reconstructions
z
how to represent:
semantic?
compact?
general?
interpretable?

Dynamics Representations
Multisensory Representations
Danny Driess and Ingmar Schubert et al., arxiv 2022
Ben Mildenhall, Pratul Srinivasan, Matthew Tancik et al., ECCV 2020
Self-supervised Representations
Richard Newcombe et al., ISMAR 2011
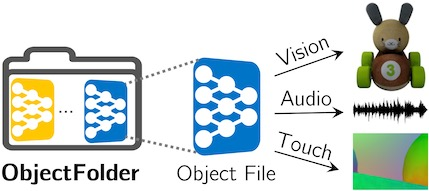
Ruohan Gao, Zilin Si, Yen-Yu Chang et al., CVPR 2022
Misha Laskin and Aravind Srinivas et al., ICML 2020
On the hunt for the "best" state representation
Haochen Shi and Huazhe Xu et al., RSS 2022
Learned Visual Representations
NeRF Representations
3D Reconstructions
z
how to represent:
semantic?
compact?
general?
interpretable?
Dynamics Representations
Multisensory Representations
Danny Driess and Ingmar Schubert et al., arxiv 2022
Ben Mildenhall, Pratul Srinivasan, Matthew Tancik et al., ECCV 2020
Self-supervised Representations
Richard Newcombe et al., ISMAR 2011
Ruohan Gao, Zilin Si, Yen-Yu Chang et al., CVPR 2022
Misha Laskin and Aravind Srinivas et al., ICML 2020
Continuous-Time
Representations
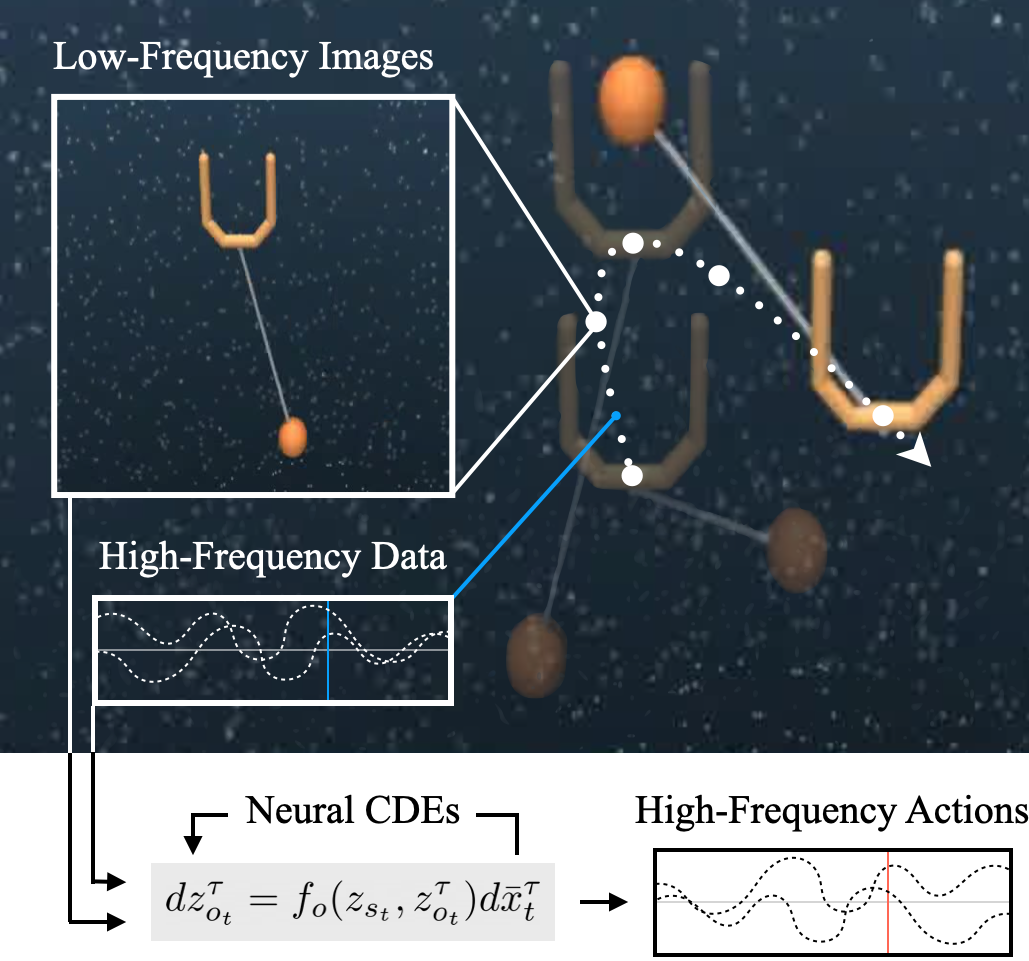
Sumeet Singh et al., IROS 2022
Pretrained Representations
Lin Yen-Chen et al., ICRA 2020
Cross-embodied Representations
Kevin Zakka et al., CoRL 2021

On the hunt for the "best" state representation
what about
z
how to represent:
semantic?
compact?
general?
interpretable?
language?
On the hunt for the "best" state representation
z
how to represent:
semantic? ✓
compact? ✓
general? ✓
interpretable? ✓
what about
language?
On the hunt for the "best" state representation
z
how to represent:
semantic? ✓
compact? ✓
general? ✓
interpretable? ✓
what about
language?
advent of large language models
maybe this was the multi-task representation we've been looking for all along?
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin et al., "PaLM", 2022

Mohit Shridhar et al., "CLIPort", CoRL 2021
Recent work in multi-task learning...
Does multi-task learning result in positive transfer of representations?
Does multi-task learning result in positive transfer of representations?
Past couple years of research suggest: its complicated
Recent work in multi-task learning...
Does multi-task learning result in positive transfer of representations?
Past couple years of research suggest: its complicated
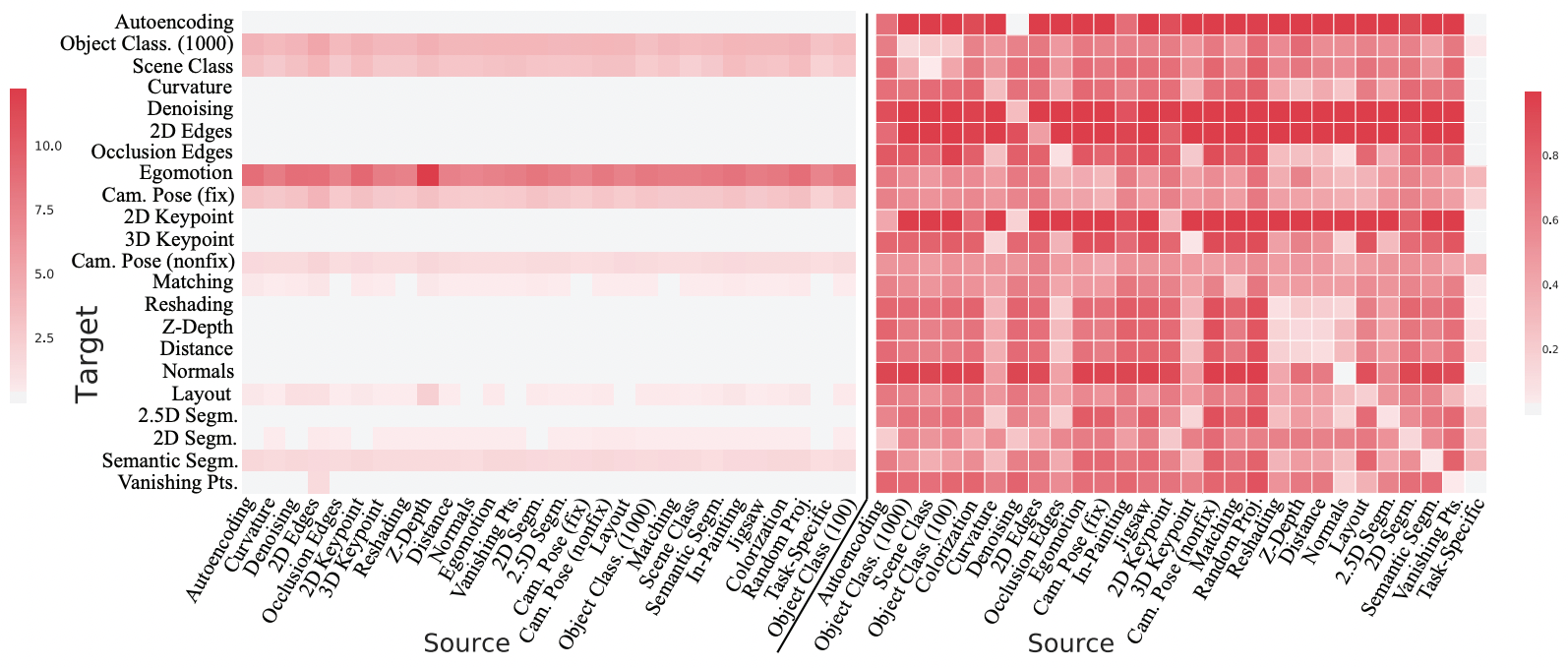
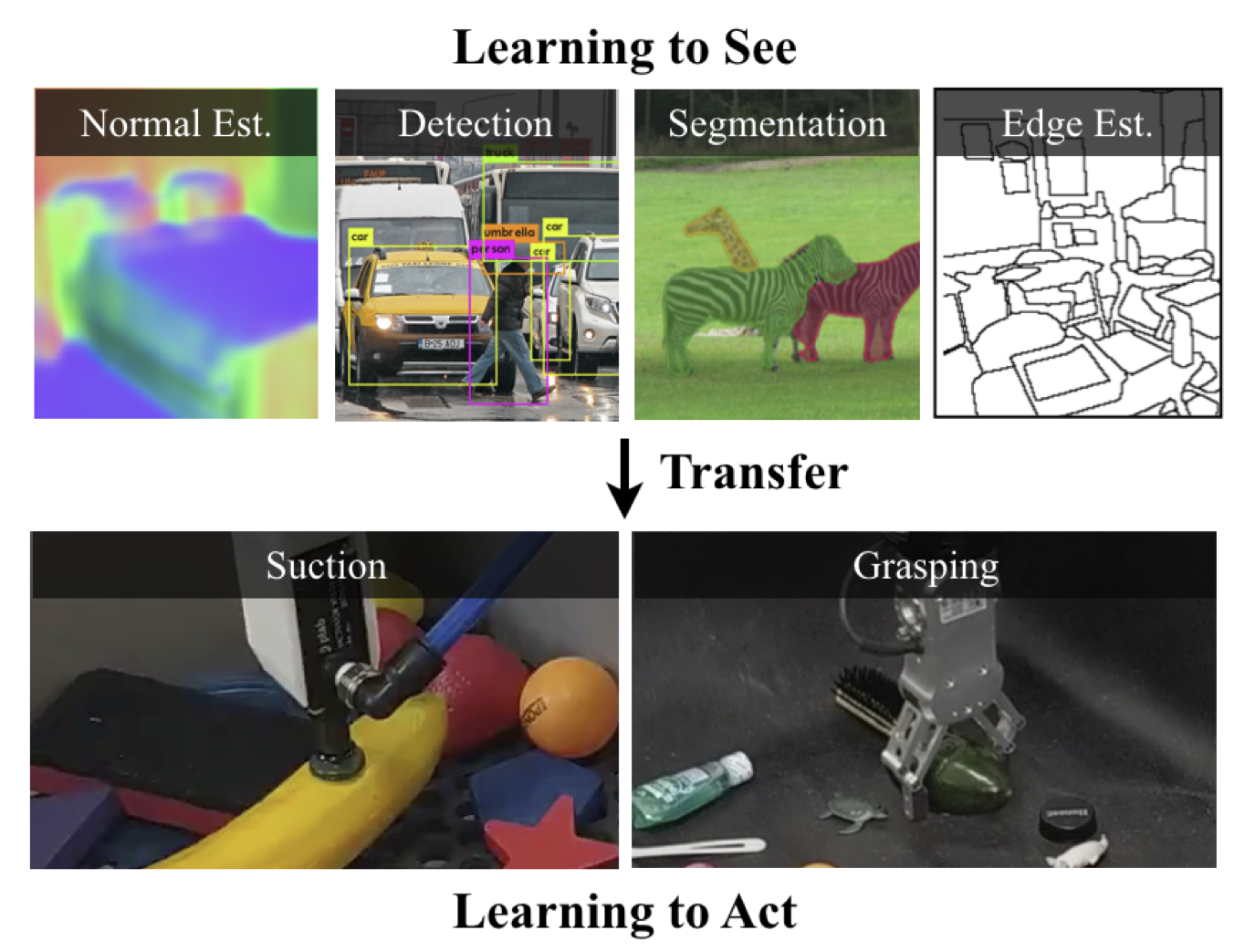
In computer vision...
Amir Zamir, Alexander Sax, William Shen, et al., "Taskonomy", CVPR 2018
Recent work in multi-task learning...
Does multi-task learning result in positive transfer of representations?
Past couple years of research suggest: its complicated
In computer vision...
Amir Zamir, Alexander Sax, William Shen, et al., "Taskonomy", CVPR 2018
In robot learning...
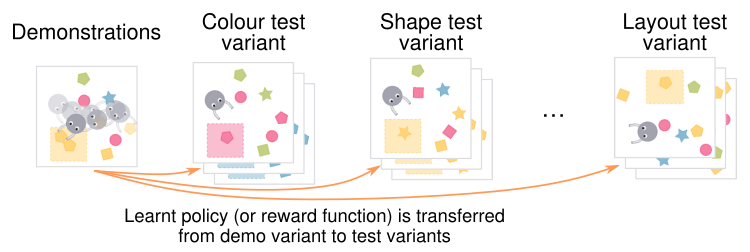
Sam Toyer, et al., "MAGICAL", NeurIPS 2020
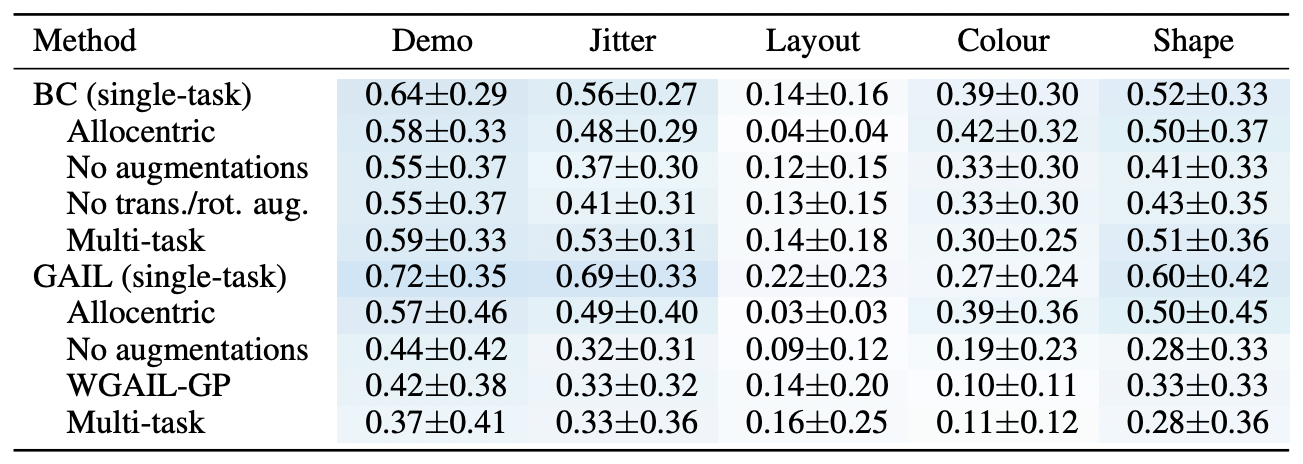
Recent work in multi-task learning...
Does multi-task learning result in positive transfer of representations?
Past couple years of research suggest: its complicated
In computer vision...
Amir Zamir, Alexander Sax, William Shen, et al., "Taskonomy", CVPR 2018
In robot learning...
Sam Toyer, et al., "MAGICAL", NeurIPS 2020
Scott Reed, Konrad Zolna, Emilio Parisotto, et al., "A Generalist Agent", 2022
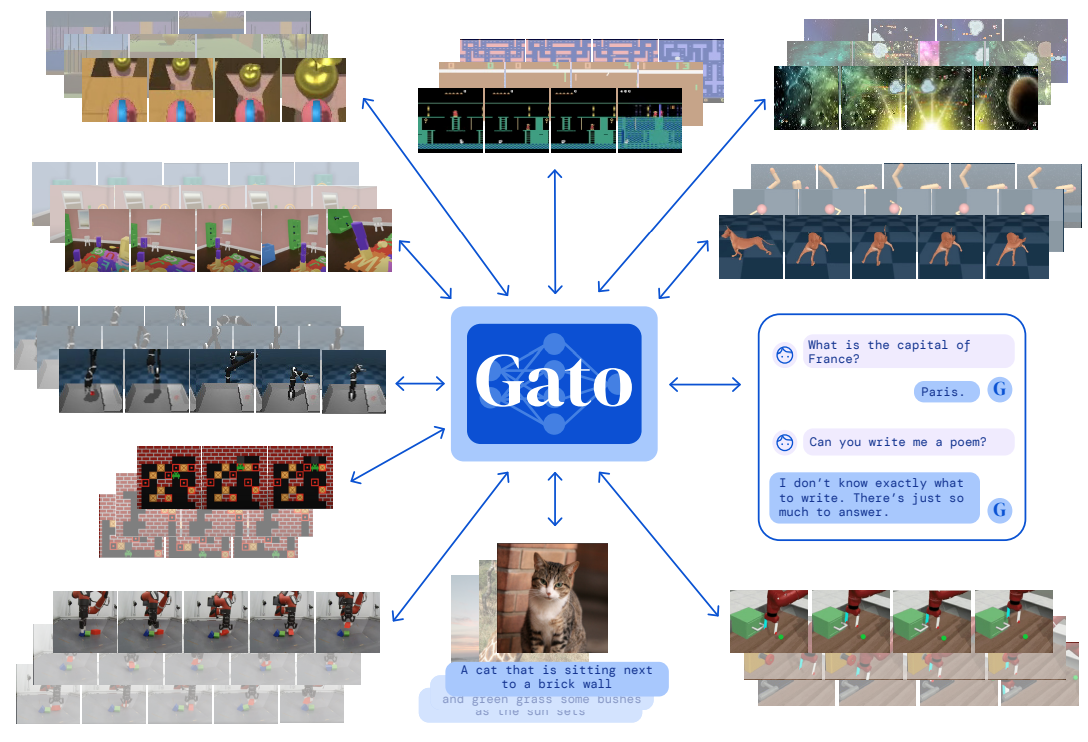

Recent work in multi-task learning...
CLIPort
Multi-task learning + grounding in language seems more likely to lead to positive transfer
Mohit Shridhar, Lucas Manuelli, Dieter Fox, "CLIPort: What and Where Pathways for Robotic Manipulation", CoRL 2021
On the hunt for the "best" state representation
z
how to represent:
semantic? ✓
compact? ✓
general? ✓
interpretable? ✓
what about
language?
advent of large language models
maybe this was the multi-task representation we've been looking for all along?
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin et al., "PaLM", 2022
Mohit Shridhar et al., "CLIPort", CoRL 2021
How do we use "language" as a state representation?
How do we use "language" as a state representation?
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Open research problem! but here's one way to do it...

How do we use "language" as a state representation?
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Open research problem! but here's one way to do it...
Visual Language Model
CLIP, ALIGN, LiT,
SimVLM, ViLD, MDETR
How do we use "language" as a state representation?
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Open research problem! but here's one way to do it...
Visual Language Model
CLIP, ALIGN, LiT,
SimVLM, ViLD, MDETR
Human input (task)
How do we use "language" as a state representation?
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Open research problem! but here's one way to do it...
Visual Language Model
CLIP, ALIGN, LiT,
SimVLM, ViLD, MDETR
Human input (task)
Large Language Model for Planning (e.g. SayCan)
Language-conditioned Policies
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances
https://say-can.github.io/
Live demo
Describing the visual world with language
Perception
Planning
Control
Towards grounding everything in language
Language
Perception
Planning
Control
Towards grounding everything in language
Language
Perception
Planning
Control
Humans
Towards grounding everything in language
Language
Perception
Planning
Control
Humans
A path not just for general robots,
but for human-centered robots!
Some limits of "language" as intermediate representation?
- loses spatial precision
- highly multimodal (lots of different ways to say the same thing)
- not as information rich as in-domain representations (e.g. images)
Some limits of "language" as intermediate representation?
- loses spatial precision
- highly multimodal (lots of different ways to say the same thing)
- not as information-rich as in-domain representations (e.g. images)
NeRF Representations
Danny Driess and Ingmar Schubert et al., arxiv 2022
Perhaps this is where other representations can help us: e.g.,

Language Representations?
+
Thank you!
Pete Florence
Tom Funkhouser
Adrian Wong
Kaylee Burns
Jake Varley
Erwin Coumans
Alberto Rodriguez
Johnny Lee































Vikas Sindhwani
Ken Goldberg
Stefan Welker
Corey Lynch
Laura Downs
Jonathan Tompson
Shuran Song
Vincent Vanhoucke
Kevin Zakka
Michael Ryoo
Travis Armstrong
Maria Attarian
Jonathan Chien
Brian Ichter
Krzysztof Choromanski
Phillip Isola
Tsung-Yi Lin
Ayzaan Wahid
Igor Mordatch
Oscar Ramirez
Federico Tombari
Daniel Seita
Lin Yen-Chen
Adi Ganapathi

2022-RSS-Implicit-Workshop
By Andy Zeng




