

Robotics at Google
Language as Robot Middleware
Andy Zeng
Stanford Vision and Learning Lab

Robot Manipulation

Amazon Picking Challenge
"Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching"
ICRA '18 arc.cs.princeton.edu
Team MIT-Princeton
1st Place, Stow Task
Amazon Picking Challenge
"Robotic Pick-and-Place of Novel Objects in Clutter with Multi-Affordance Grasping and Cross-Domain Image Matching"
ICRA '18 arc.cs.princeton.edu

Team MIT-Princeton
1st Place, Stow Task
"The Beast from the East"


excel at simple things, adapt to hard things
How to endow robots with
"intuition" and "commonsense"?



TossingBot's intermediate representations
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020


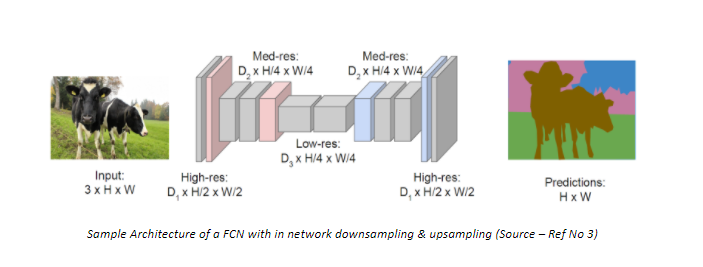
Fully Conv Net
Orthographic
Projection
Grasping
Affordances
f_g({\color{Green}s},{\color{Red}a})
Grasping value function
receptive field
grasp action

Throw Velocities
+Target location
TossingBot's intermediate representations
TossingBot: Learning to Throw Arbitrary Objects with Residual Physics
RSS 2019, T-RO 2020
Fully Conv Net
Orthographic
Projection
Grasping
Affordances
Throw Velocities
+Target location

what did TossingBot learn?
On the quest for the right intermediate representations
z
Perception
Control
what is the right representation?
Planning
Learned Visual Representations
Continuous-Time
Representations
Sumeet Singh et al., IROS 2022
Pretrained Representations
Lin Yen-Chen et al., ICRA 2020
Cross-embodied Representations
Kevin Zakka et al., CoRL 2021

defines the scope of generalization
z
Perception
Control
what is the right representation?
Planning
Learned Visual Representations
Continuous-Time
Representations
Sumeet Singh et al., IROS 2022
Cross-embodied Representations
Kevin Zakka et al., CoRL 2021
Andy Zeng, Peter Yu, et al., ICRA 2017

Pose-based Representations
On the quest for the right intermediate representations
defines the scope of generalization
z
Perception
Control
what is the right representation?
Planning
Learned Visual Representations
Continuous-Time
Representations
Sumeet Singh et al., IROS 2022
Cross-embodied Representations
Kevin Zakka et al., CoRL 2021
Andy Zeng, Peter Yu, et al., ICRA 2017
Pose-based Representations
general?
semantic?
compact?
compositional?
interpretable?
On the quest for the right intermediate representations
z
Perception
Control
what is the right representation?
Planning
Haochen Shi and Huazhe Xu et al., RSS 2022

NeRF Representations
Dynamics Representations

Danny Driess and Ingmar Schubert et al., arxiv 2022
Ben Mildenhall, Pratul Srinivasan, Matthew Tancik et al., ECCV 2020
Self-supervised Representations
Misha Laskin and Aravind Srinivas et al., ICML 2020

Object-centric Representations
Mehdi S. M. Sajjadi et al., NeurIPS 2022

general?
semantic?
compact?
compositional?
interpretable?
On the quest for the right intermediate representations
z
how to represent:
what about
language?
general?
semantic?
compact?
compositional?
interpretable?
On the quest for the right intermediate representations
z
how to represent:
what about
language?
general? ✓
semantic? ✓
compact? ✓
compositional? ✓
interpretable? ✓
On the quest for the right intermediate representations
z
how to represent:
what about
language?
general? ✓
semantic? ✓
compact? ✓
compositional? ✓
interpretable? ✓
advent of large language models
maybe this was the multi-task representation we've been looking for all along?
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin et al., "PaLM", 2022

Mohit Shridhar et al., "CLIPort", CoRL 2021
On the quest for the right intermediate representations
Does multi-task learning result in positive transfer of representations?
Recent work in multi-task learning...
Does multi-task learning result in positive transfer of representations?
Past couple years of research suggest: its complicated
Recent work in multi-task learning...
Does multi-task learning result in positive transfer of representations?
Past couple years of research suggest: its complicated
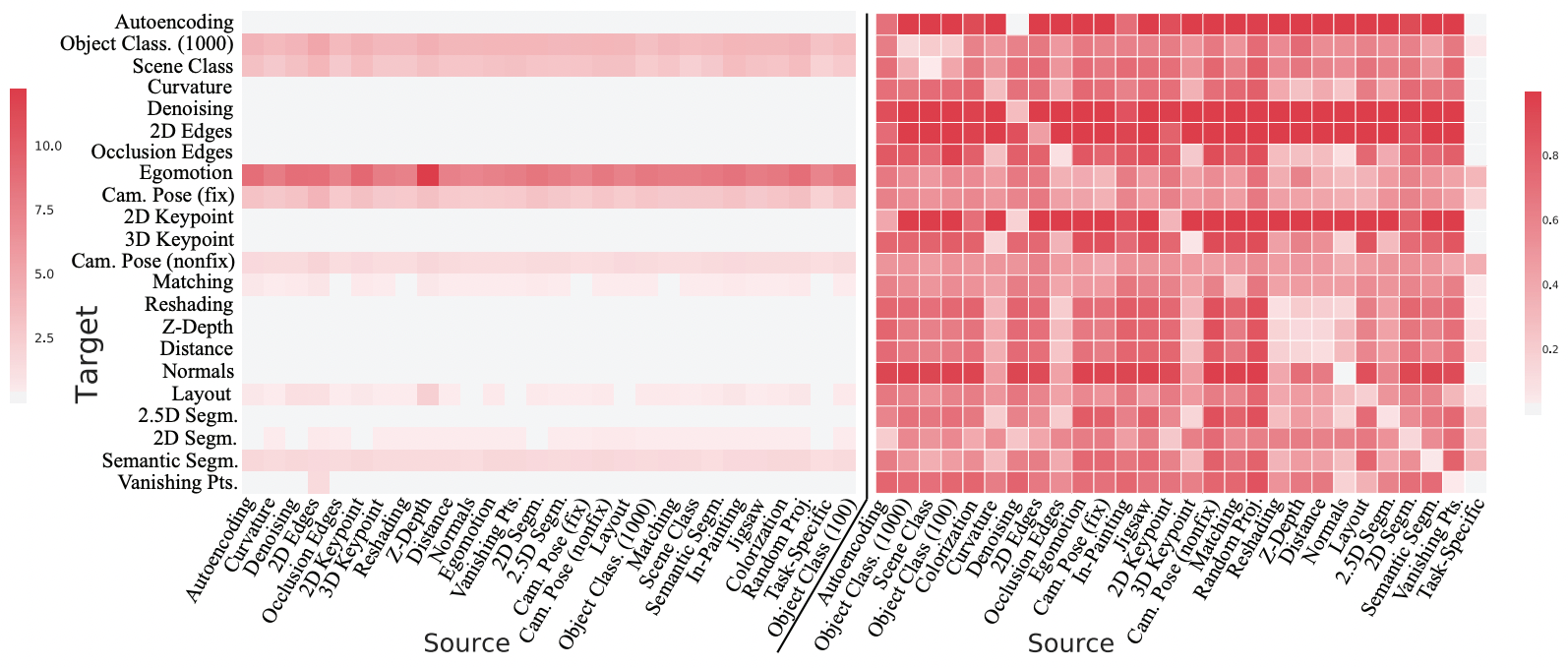
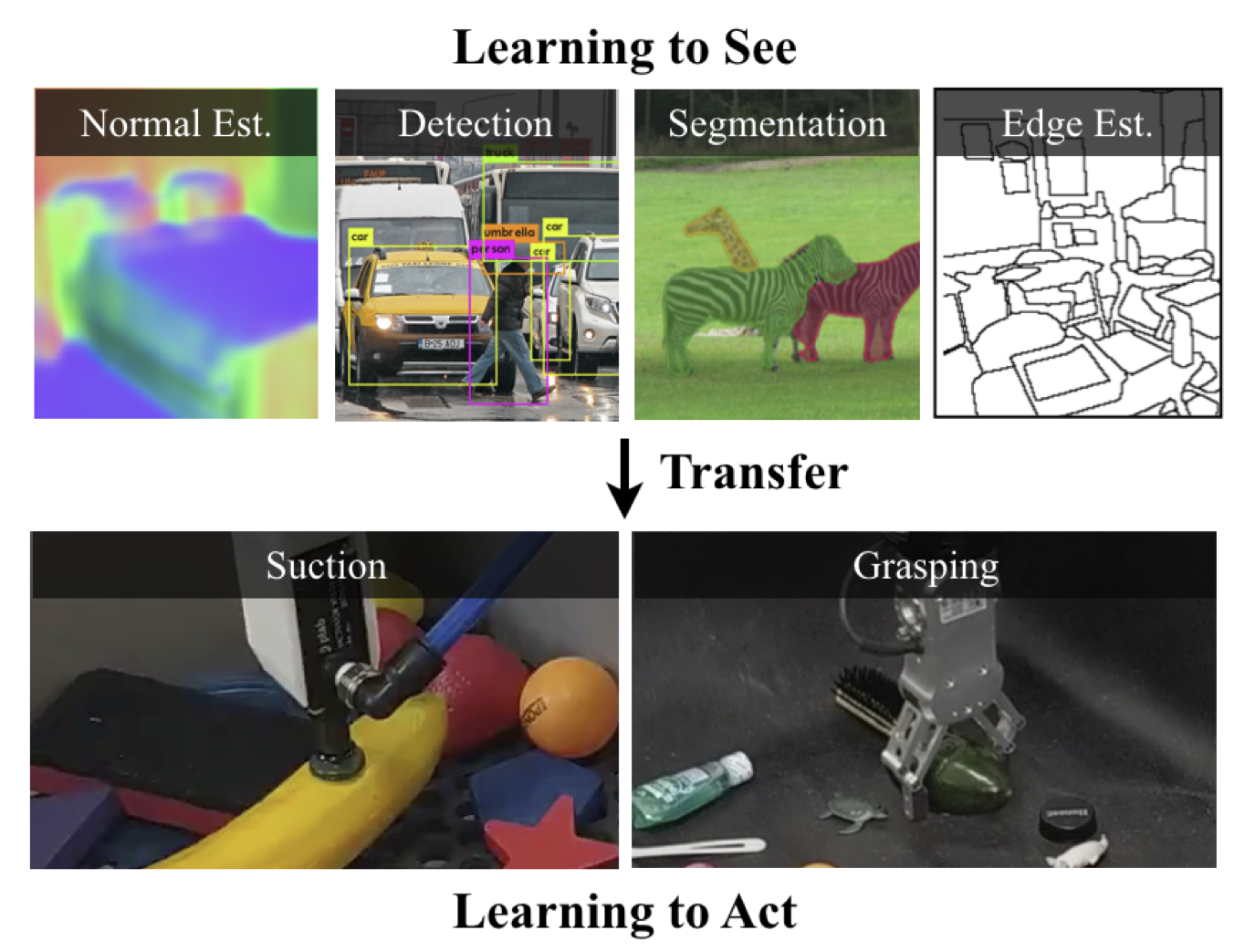
In computer vision...
Amir Zamir, Alexander Sax, William Shen, et al., "Taskonomy", CVPR 2018
Recent work in multi-task learning...
Does multi-task learning result in positive transfer of representations?
Past couple years of research suggest: its complicated
In computer vision...
Amir Zamir, Alexander Sax, William Shen, et al., "Taskonomy", CVPR 2018
Recent work in multi-task learning...
Xiang Li et al., "Does Self-supervised Learning Really Improve Reinforcement Learning from Pixels?", 2022
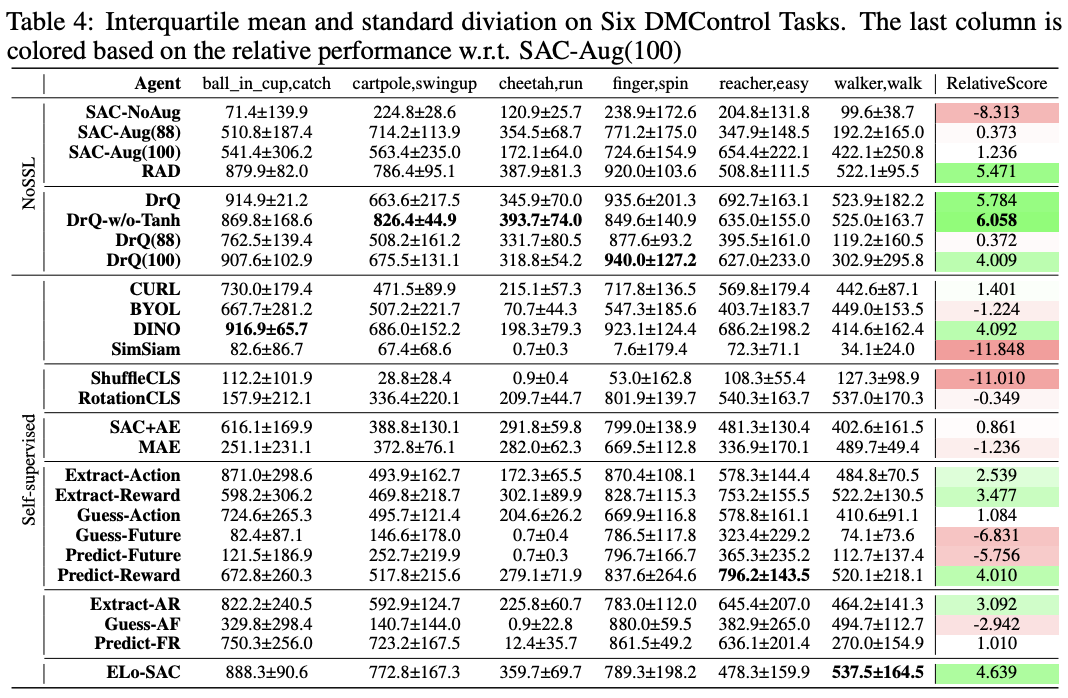
Does multi-task learning result in positive transfer of representations?
Past couple years of research suggest: its complicated
In computer vision...
Amir Zamir, Alexander Sax, William Shen, et al., "Taskonomy", CVPR 2018
In robot learning...
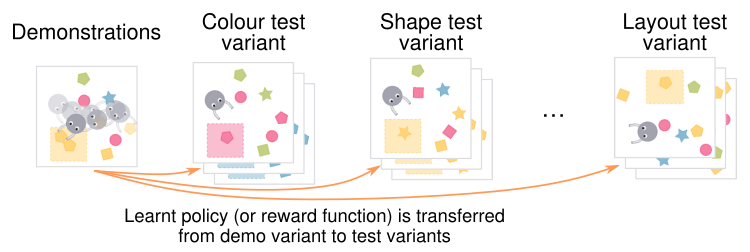
Sam Toyer, et al., "MAGICAL", NeurIPS 2020
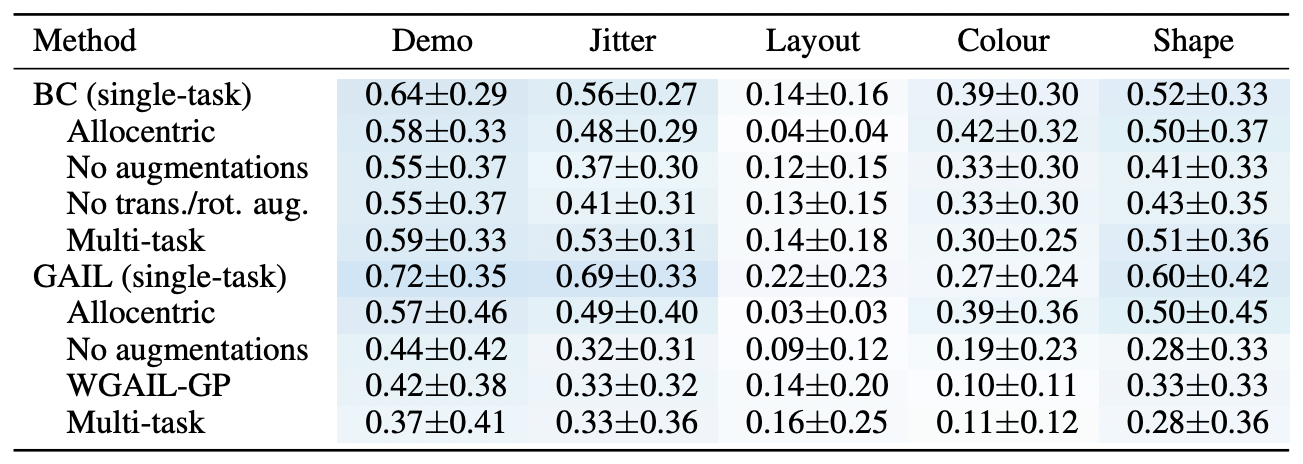
Recent work in multi-task learning...
Xiang Li et al., "Does Self-supervised Learning Really Improve Reinforcement Learning from Pixels?", 2022
Does multi-task learning result in positive transfer of representations?
Past couple years of research suggest: its complicated
In computer vision...
Amir Zamir, Alexander Sax, William Shen, et al., "Taskonomy", CVPR 2018
In robot learning...
Sam Toyer, et al., "MAGICAL", NeurIPS 2020
Scott Reed, Konrad Zolna, Emilio Parisotto, et al., "A Generalist Agent", 2022
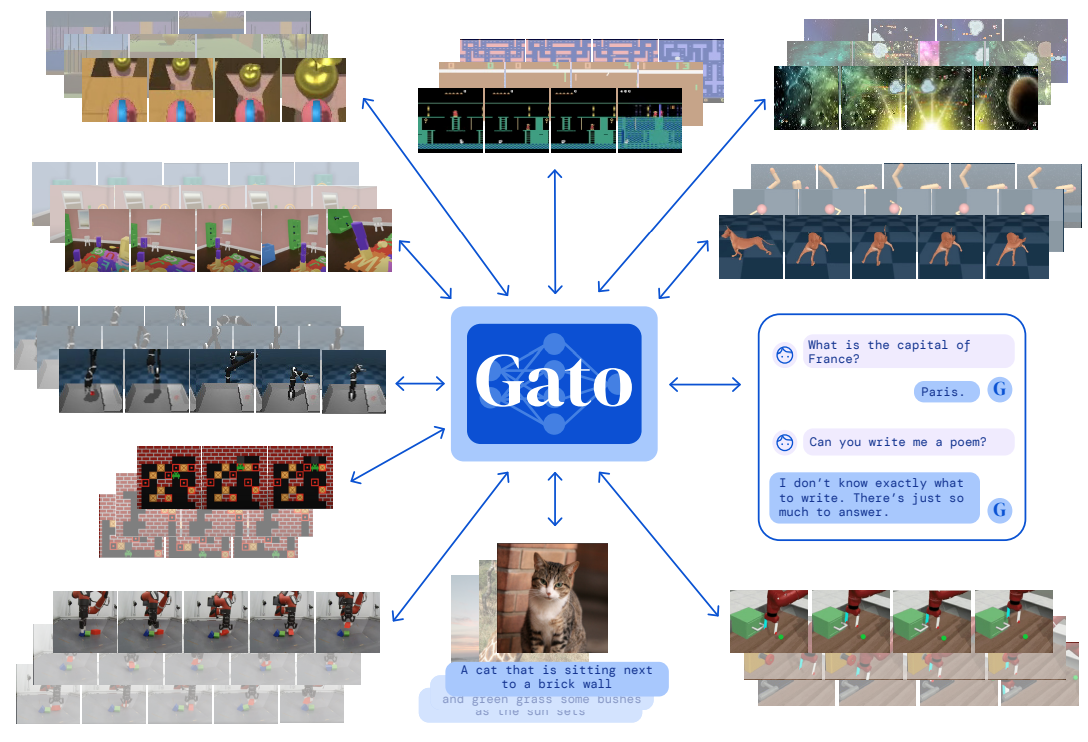

Recent work in multi-task learning...
Xiang Li et al., "Does Self-supervised Learning Really Improve Reinforcement Learning from Pixels?", 2022
CLIPort
Multi-task learning + grounding in language seems more likely to lead to positive transfer
Mohit Shridhar, Lucas Manuelli, Dieter Fox, "CLIPort: What and Where Pathways for Robotic Manipulation", CoRL 2021
Multi-task learning + language grounding
Multi-task learning + grounding in language seems more likely to lead to positive transfer
Mohit Shridhar, Lucas Manuelli, Dieter Fox, "CLIPort: What and Where Pathways for Robotic Manipulation", CoRL 2021



z
how to represent:
what about
language?
general? ✓
semantic? ✓
compact? ✓
compositional? ✓
interpretable? ✓
advent of large language models
maybe this was the multi-task representation we've been looking for all along?
Aakanksha Chowdhery, Sharan Narang, Jacob Devlin et al., "PaLM", 2022
Mohit Shridhar et al., "CLIPort", CoRL 2021
On the quest for the right intermediate representations
How do we use "language" as a intermediate representation?
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Open research problem! but here's one way to do it...

Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Open research problem! but here's one way to do it...
Visual Language Model
CLIP, ALIGN, LiT,
SimVLM, ViLD, MDETR
Human input (task)
How do we use "language" as a intermediate representation?
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Open research problem! but here's one way to do it...
Visual Language Model
CLIP, ALIGN, LiT,
SimVLM, ViLD, MDETR
Human input (task)
Large Language Models for
High-Level Planning
Language-conditioned Policies
Do As I Can, Not As I Say: Grounding Language in Robotic Affordances say-can.github.io
Language Models as Zero-Shot Planners: Extracting Actionable Knowledge for Embodied Agents wenlong.page/language-planner
How do we use "language" as a intermediate representation?
Socratic Models: Robot Pick-and-Place Demo
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io

For each step, predict pick & place:
Describing the visual world with language
(and using for feedback too!)
Some limits of "language" as intermediate representation?
- loses spatial precision
- highly multimodal (lots of different ways to say the same thing)
- not as information-rich as in-domain representations (e.g. images)
Some limits of "language" as intermediate representation?
- loses spatial precision
- highly multimodal (lots of different ways to say the same thing)
- not as information-rich as in-domain representations (e.g. images)
Can we leverage continuous pre-trained word embedding spaces?

An Image is Worth One Word: Personalizing Text-to-Image Generation using Textual Inversion
Rinon Gal et al. 2022
Call to action: perception wishlist #1
- hierarchical visual-language representations?
Office space

Conference room
Desk, Chairs
Coke bottle
Bottle label
Nutrition facts
Nutrition values
w/ spatial info?
Call to action: perception wishlist #1
- hierarchical visual-language representations?
Office space
Conference room
Desk, Chairs
Coke bottle
Bottle label
Nutrition facts
Nutrition values
w/ spatial info?
- open-vocab is great, but can we get generative?
Call to action: perception wishlist #1
- hierarchical visual-language representations?
Office space
Conference room
Desk, Chairs
Coke bottle
Bottle label
Nutrition facts
Nutrition values
w/ spatial info?
- open-vocab is great, but can we get generative?
- ground visual / contact / control dynamics to language?

Some limits of "language" as intermediate representation?
- Only for high level? what about control?
Perception
Planning
Control
Socratic Models
Inner Monologue
ALM + LLM + VLM
SayCan
Wenlong Huang et al, 2022
LLM
Imitation? RL?
Engineered?
Intuition and commonsense is not just a high-level thing
Intuition and commonsense is not just a high-level thing
Applies to low-level behaviors too
- spatial: "move a little bit to the left"
- temporal: "move faster"
- functional: "balance yourself"
Behavioral commonsense is the "dark matter" of robotics:
Intuition and commonsense is not just a high-level thing
Seems to be stored in the depths of in language models... how to extract it?
Applies to low-level behaviors too
- spatial: "move a little bit to the left"
- temporal: "move faster"
- functional: "balance yourself"
Behavioral commonsense is the "dark matter" of robotics:
Language models can write code
Code as a medium to express low-level commonsense
Live Demo
Language models can write code
Code as a medium to express more complex plans

Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control


Live Demo
Language models can write code
Code as a medium to express more complex plans
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control
Live Demo
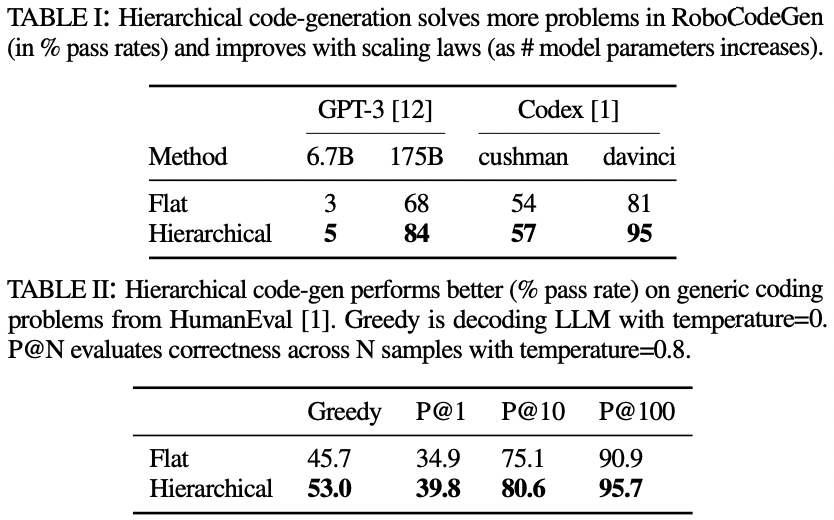
Language models can write code
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control
use NumPy,
SciPy code...
Language models can write code
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control
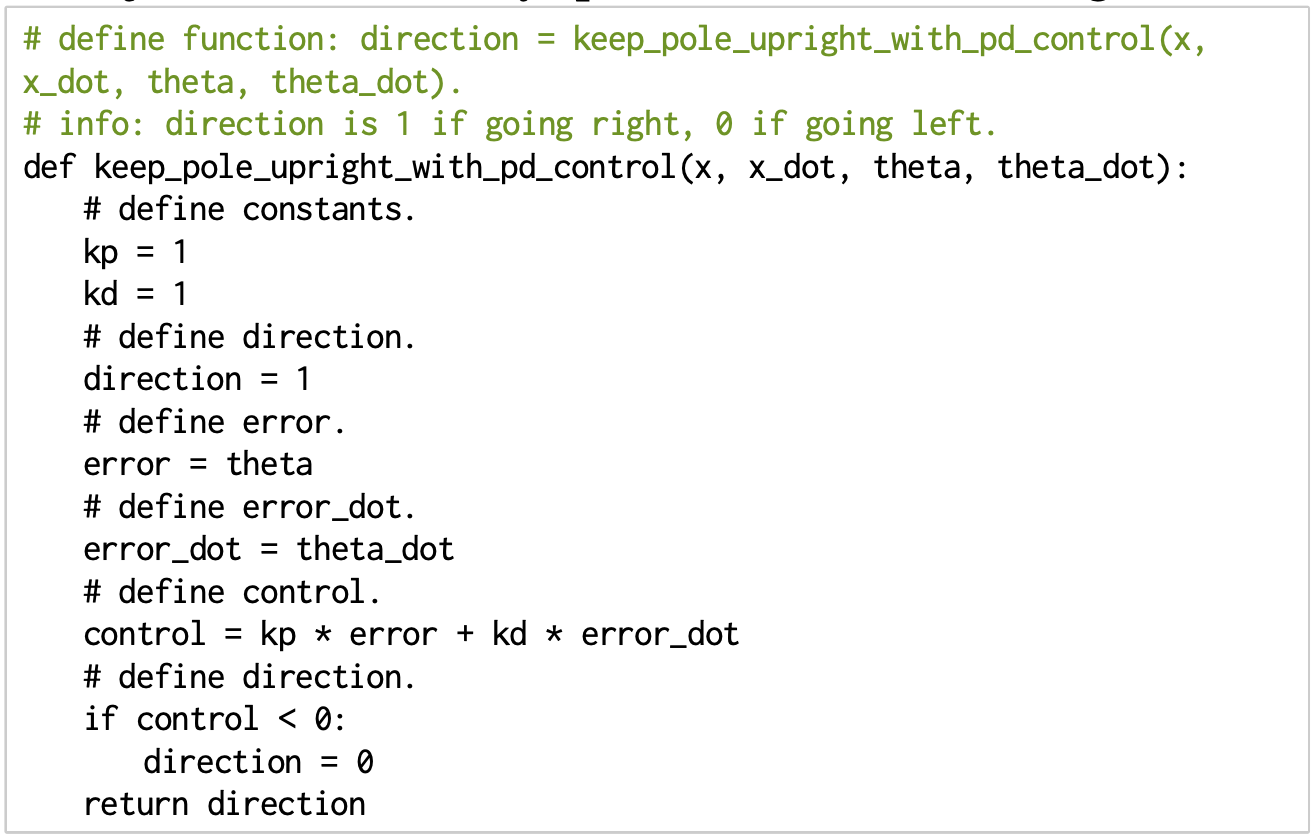

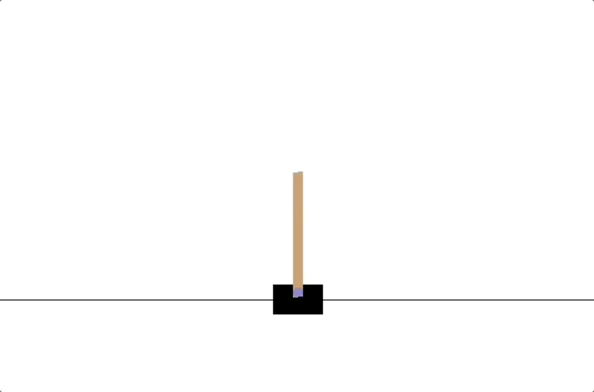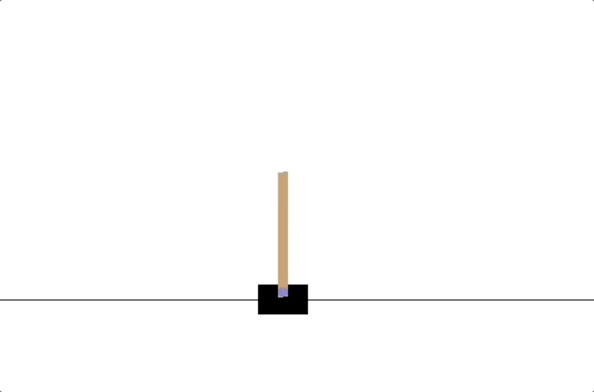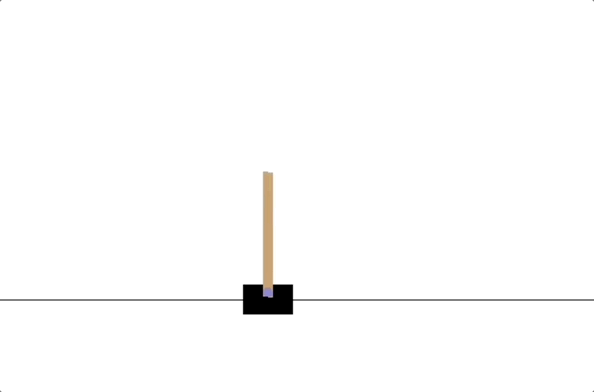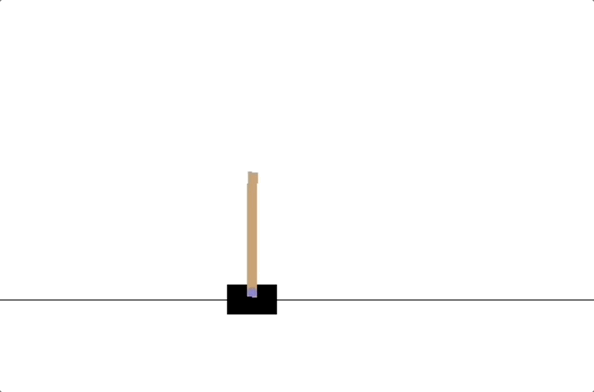
- PD controllers
- impedance controllers
Language models can write code
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control

Language models can write code
Jacky Liang, Wenlong Huang, Fei Xia, Peng Xu, Karol Hausman, Brian Ichter, Pete Florence, Andy Zeng
code-as-policies.github.io
Code as Policies: Language Model Programs for Embodied Control
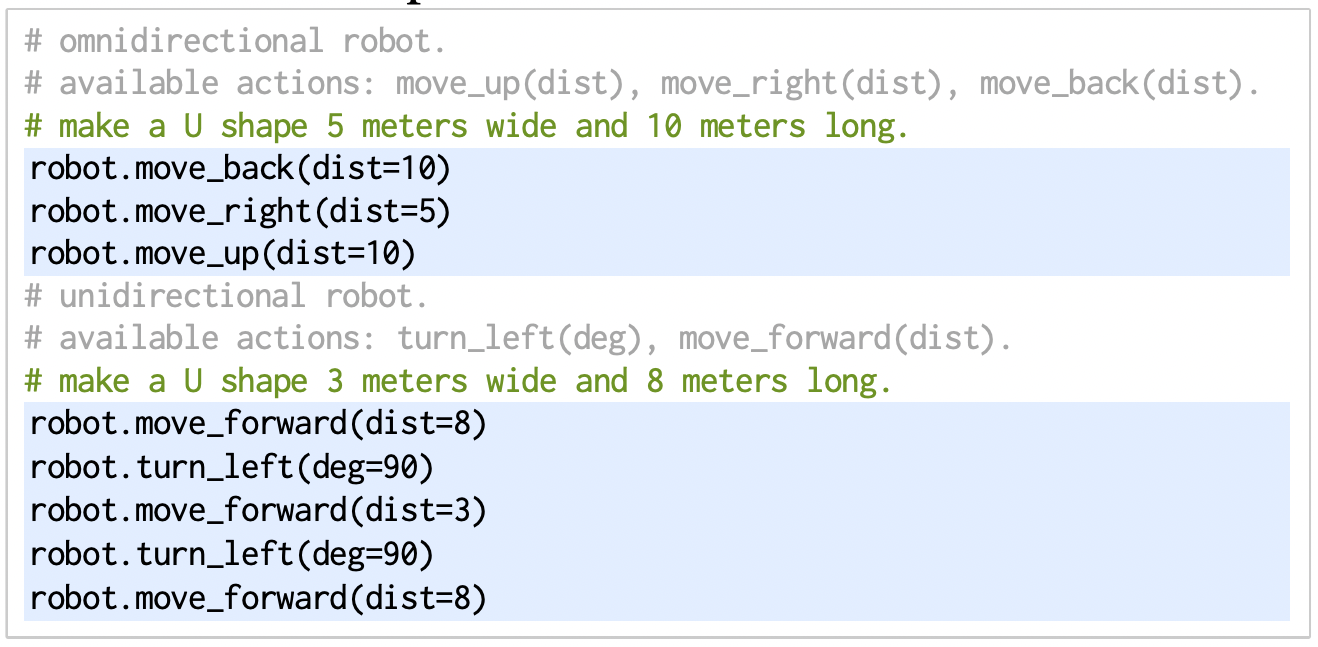
What is the foundation models for robotics?
Extensions to Code as Policies
1. Fuse visual-language features into a robot map
2. Use code as policies to do various navigation tasks
"Visual Language Maps" Chenguang Huang et al., ICRA 2023
Extensions to Code as Policies
1. Fuse visual-language features into a robot map
2. Use code as policies to do various navigation tasks
"Visual Language Maps" Chenguang Huang et al., ICRA 2023
1. Write code to do visual reasoning
2. Few-shot SOTA improvements on VQA
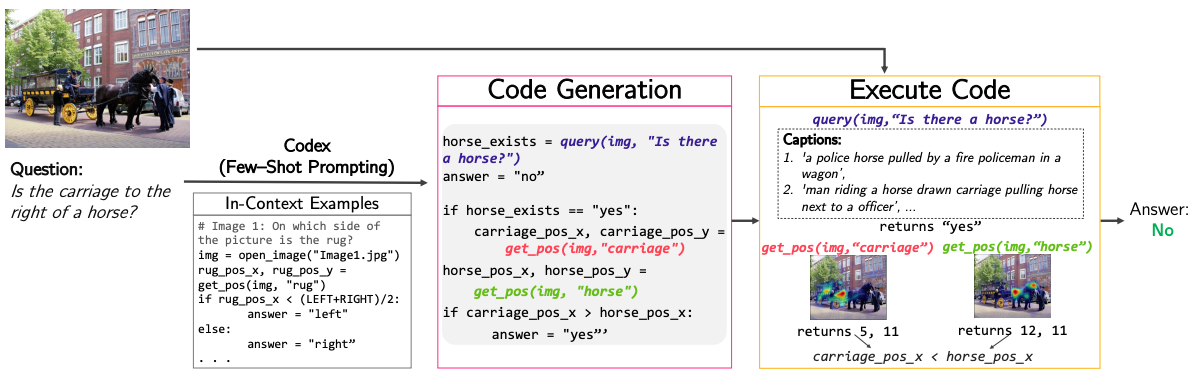
"Modular VQA via Code Generation"
Sanjay Subramanian et al., 2023
On the road to robot commonsense
Robot Learning
Language Models
Not a lot of robot data
Lots of Internet data




500 expert demos
5000 expert demos
50 expert demos
On the road to robot commonsense
Robot Learning
Language Models
Not a lot of robot data
Lots of Internet data

500 expert demos
5000 expert demos
50 expert demos
On the road to robot commonsense
Robot Learning
Language Models
- Finding other sources of data (sim, YouTube)
- Improve data efficiency with prior knowledge
Not a lot of robot data
Lots of Internet data
500 expert demos
5000 expert demos
50 expert demos
On the road to robot commonsense
Robot Learning
Language Models
- Finding other sources of data (sim, YouTube)
- Improve data efficiency with prior knowledge
Not a lot of robot data
Lots of Internet data
500 expert demos
5000 expert demos
50 expert demos
Embrace language to help close the gap!
Towards grounding everything in language
Language
Control
Vision
Tactile
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
Lots of data
Less data
Less data
Call to action: perception wishlist #2
- Language-grounded foundation models for other sensors (e.g. tactile)
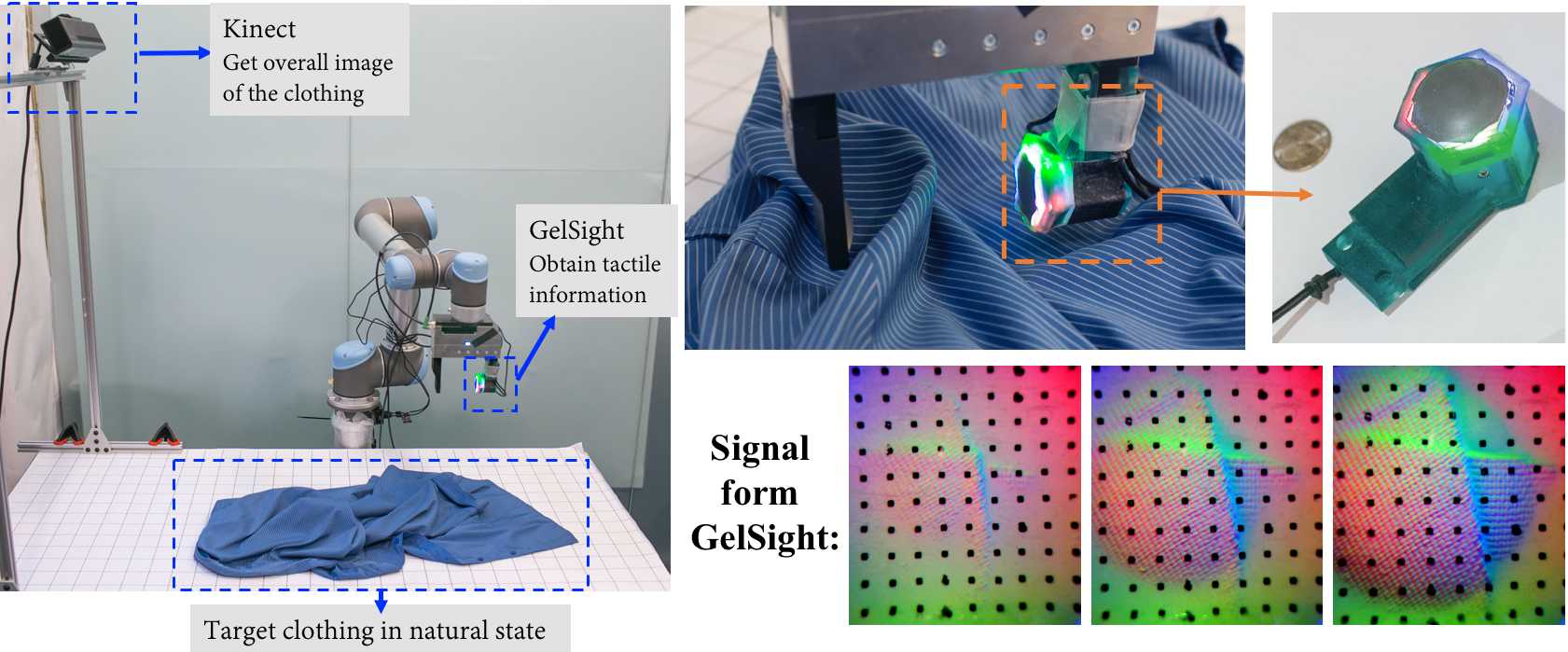

Wenzhen Yuan et al.
Call to action: perception wishlist #2
- Language-grounded foundation models for other sensors (e.g. tactile)
- Foundation model for sounds, not just speech and music, but also "robot noises"
Wenzhen Yuan et al.
Revisiting modularity is a step towards the endgame
Today
1960s
End-to-end is the endgame, but we need useful robots everywhere first
End-to-End
10^6+ robots
Tomorrow
Revisiting modularity is a step towards the endgame
Modular Systems
2007
1960s
ROS
End-to-end is the endgame, but we need useful robots everywhere first
End-to-End
out of necessity
10^6+ robots
Tomorrow
Revisiting modularity is a step towards the endgame
Modular Systems
2007
2015
1960s
ROS
End-to-end is the endgame, but we need useful robots everywhere first
End-to-End
End-to-End
out of necessity
thx deep learning
10^6+ robots
Tomorrow
Revisiting modularity is a step towards the endgame
Modular Systems
2007
2015
Today
1960s
ROS
Modular Systems
End-to-end is the endgame, but we need useful robots everywhere first
End-to-End
End-to-End
out of necessity
thx deep learning
advent of LLMs
10^6+ robots
Tomorrow
compositional generality
"Language" as the glue for intelligent machines
Language
Perception
Planning
Control
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
"Language" as the glue for intelligent machines
Language
Perception
Planning
Control
Socratic Models: Composing Zero-Shot Multimodal Reasoning with Language
https://socraticmodels.github.io
We have some reason to believe that
"the structure of language is the structure of generalization"
To understand language is to understand generalization
https://evjang.com/2021/12/17/lang-generalization.html
Sapir–Whorf hypothesis
Towards grounding everything in language
Language
Perception
Planning
Control
Humans
Not just for general robots,
but for human-centered intelligent machines!
Thank you!
Pete Florence
Adrian Wong
Johnny Lee











Vikas Sindhwani
Stefan Welker
Vincent Vanhoucke
Kevin Zakka
Michael Ryoo
Maria Attarian
Brian Ichter
Krzysztof Choromanski
Federico Tombari

Jacky Liang
Aveek Purohit

Wenlong Huang
Fei Xia
Peng Xu
Karol Hausman





and many others!
2023-SVL-talk
By Andy Zeng




