Word2Bit-Quantized Word Vectors
- Reduction of the memory space taken by Word Vectors in mobile phones and GPUs.
- This done by introducing a quantization function to Word2Vec
What is a Word2Vec?
- In simple words, word2vec is a two-layer neural network which processes text
- Its main job is to recognize patterns in a text.
- Given enough data, usage and contexts, Word2vec can make highly accurate guesses about a word’s meaning based on past appearances.
- And since the words are being treated as vectors their output can be used in deep learning model to perform mathematical computations on it.
Disadvantages of using Word2Vec
- Memory Issues-Takes up to 3-6 GB of memory/storage – a massive amount relative to other portions of a deep learning model. These requirements pose issues to memory/storage limited devices like mobile phones and GPUs
- Overfitting-Standard Word2Vec may be prone to overfitting; the quantization function acts as a regularizer against it.
- Problems with current networks: Adding an extra layer of compression on top of pretrained word vectors which may be computationally expensive and degrade accuracy.
Quick Recap of Quantization
- Compression of neural networks has been the fascination of many researchers since the 90s.
- But previously many methods were used including network pruning, deep compression etc. but as discussed before they are computationally expensive.
- But researchers instead found an easier way of including arithmetic operations and using low precision floating points on hardware devices called quantization.
CBOW-Continuous Bag of Words
- There are two types of word2vec algorithm popularly used-one is Skip Gram and other is CBOW.
- In typical word embeddings, we try to find a relationship between words.
- But in a CBOW we try to find a relationship between several input words to a single output word
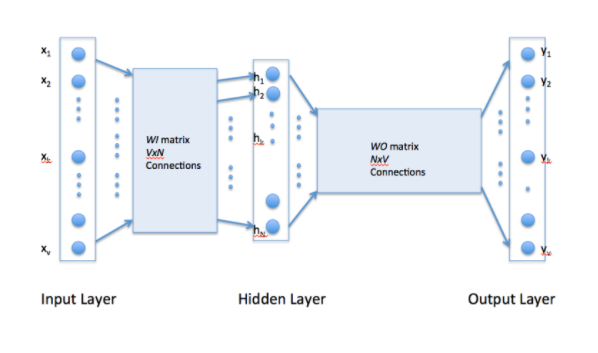
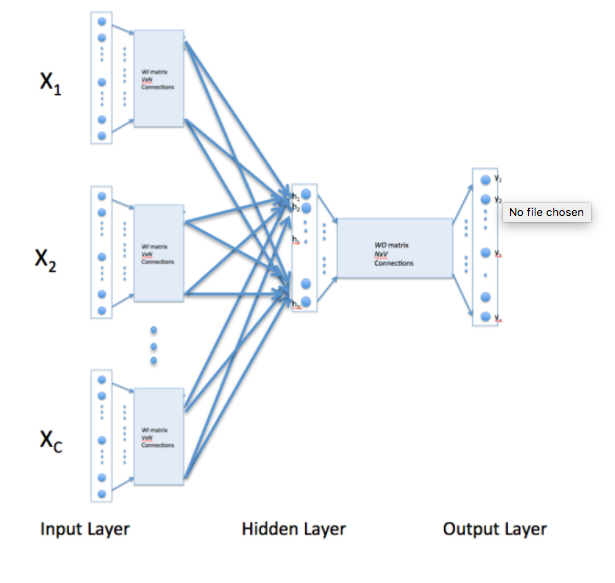
CBOW-Minimising the loss function

So what is basically doing is trying to me understand the relationship between the centre and context words
Process of Minimising

Introducing Qauntized bit Vector in the loss function/ Comparison to the original equation

Quantization Methodology-I
- Hilton's straight through estimator- It is based on a certain threshold value for calculating the gradient in a typical backprop network. So instead of using the derivative of the gradient as 0, they are using it with respect to a specific value to an outgoing gradient as compared to the incoming gradient.
- Similarly, they defined the Qbitlevel function which is a discrete function; they used the derivative of the function as an identity function

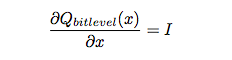

- The final vector for each word is Qbitlevel(ui + vi); thus each parameter is one of 2 bit-level values and takes bit-level bits to represent.
- While we are still training with full precision 32-bit arithmetic operations and 32-bit floating point values, the final word vectors we save to disk are quantized.
Quantization Methodology-II
Methodology for Training
- Dataset used: 2017 English Wikipedia dump (24G of text).
- 25 epochs.
- hyperparameters: window size = 10,
- negative sample size = 12,
- min count = 5,
- subsampling = 1e-4,
- learning rate = .05 (which is linearly decayed to 0.0001).
- Our final vocabulary size is 3.7 million after filtering words that appear less than min count = 5 times.
Word2Bit
By archana iyer



