AI VT開發的各種坑
About Me
- 34屆網管兼教學
- 目前就讀師大學習科學學士學位學程雙主修資工
- NTNU VLSI 副社長
為什麼我要寫一個AI VT
為什麼我要寫一個AI VT
-
因為我沒辦法開發伊萊莎歡迎來到前線,指揮官 - 因為偉大的蜂群計畫主持人Neural Sama
沒錢玩不起預訓練- 在chatgpt爆火後我就開始研究怎麼自己寫一個類似copliot的本地個人助手,但當時我的電腦算力超爛,後來換新筆電後同時接觸到Neural Sama,我就決定先來搞個AI VT好了,畢竟當VT智力不一定要頂尖,可愛有趣就行,你說是不是?

AI VT的流程與原理
AI VT的流程與原理
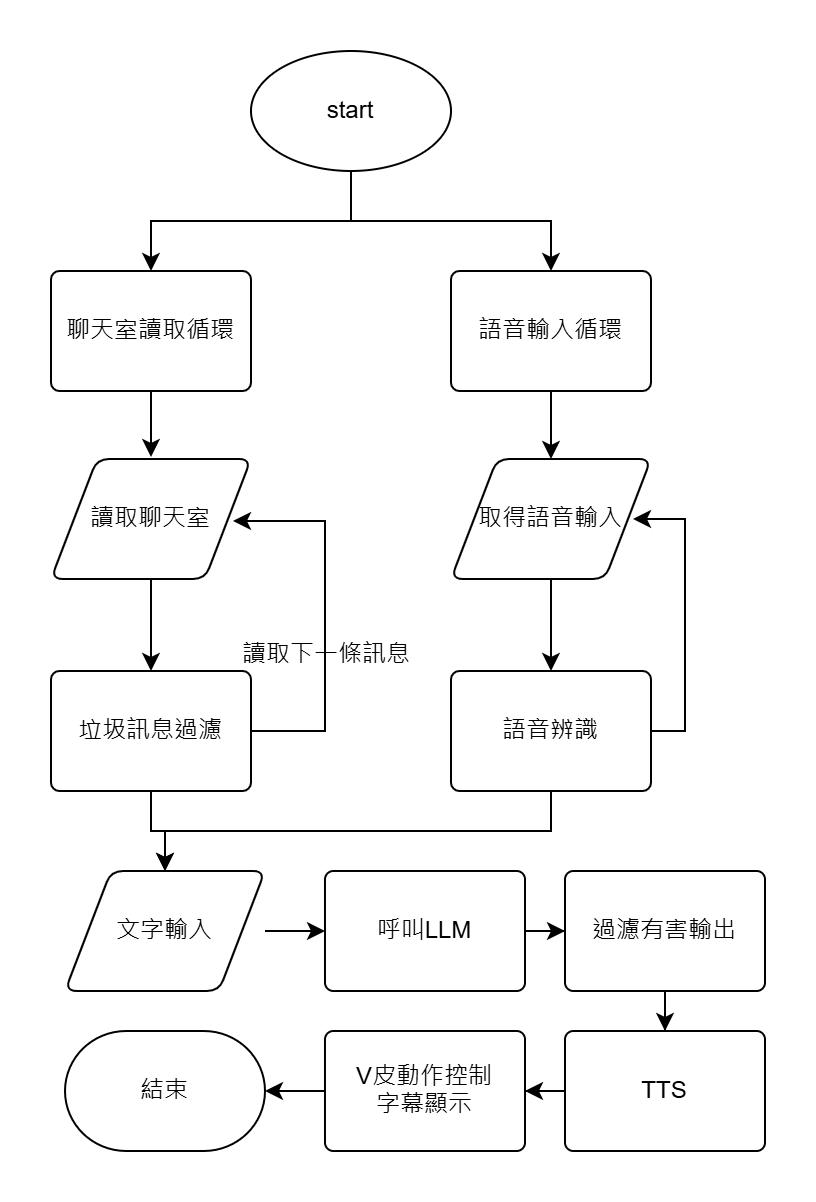
AI VT的流程與原理
圈起來的是call API的部分
剩下的流程會需要一個統一的控制介面來控制
第一個坑
該死的GUI
最早的控制台我是用tkinter寫,然後使用llama2 7b作為核心模型
但是tkinter有一個問題,這東西對emoji支援不完整
這導致了字幕中的emoji會變成"黑白emoji"
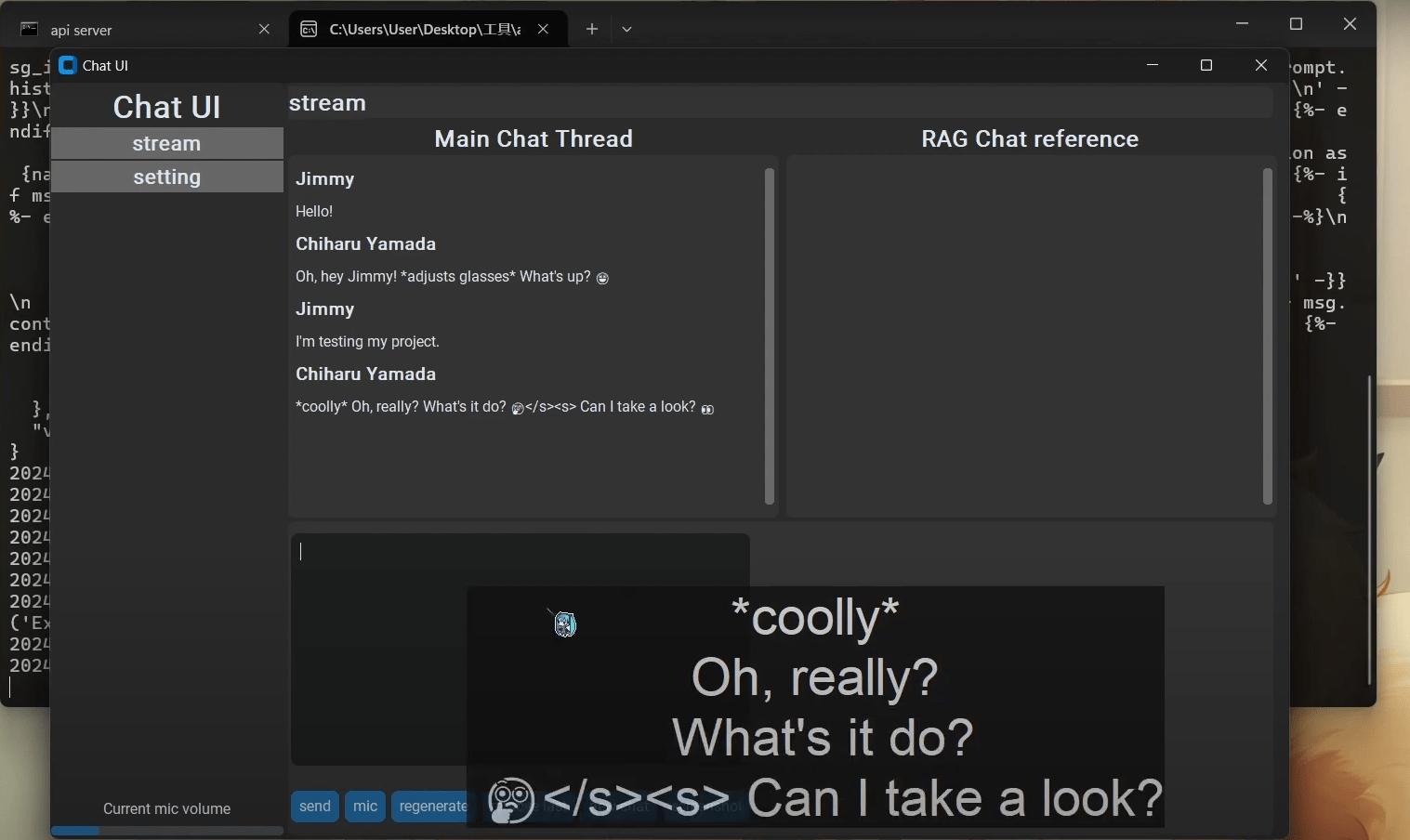
第一個坑
該死的GUI
我開發與實現功能的順序也是照著流程圖來的
因此當我注意到字幕的問題是tkinter本身的設計缺陷時已經太晚了
如果要換GUI引擎那就相當於要把我2000+行的程式碼全部重寫
我最初在寫摳的時候確實有邊寫邊想我將來維護的時候會不會完蛋
因此我都有好好的命名與寫注釋
但我沒想過會需要把整個GUI引擎都換掉
因此我的業務流程的摳與GUI渲染的摳基本上是混在一起的
哭阿
問題來了
換哪種GUI引擎?
Qt:
我可是有香香的Qt Designer喔?要不要體驗一下?
有沒有Python版?
雖然都是各種call api,但我還是不想寫C++......
Qt:
當然沒問題,PyQt、PySide任君挑選,如果你想轉戰Java那也當然沒問題!
PyQt5,啟動!
選擇PyQt5的理由:
PyQt5我找到的教學比較多,文檔也比較完善
QtDesigner真香
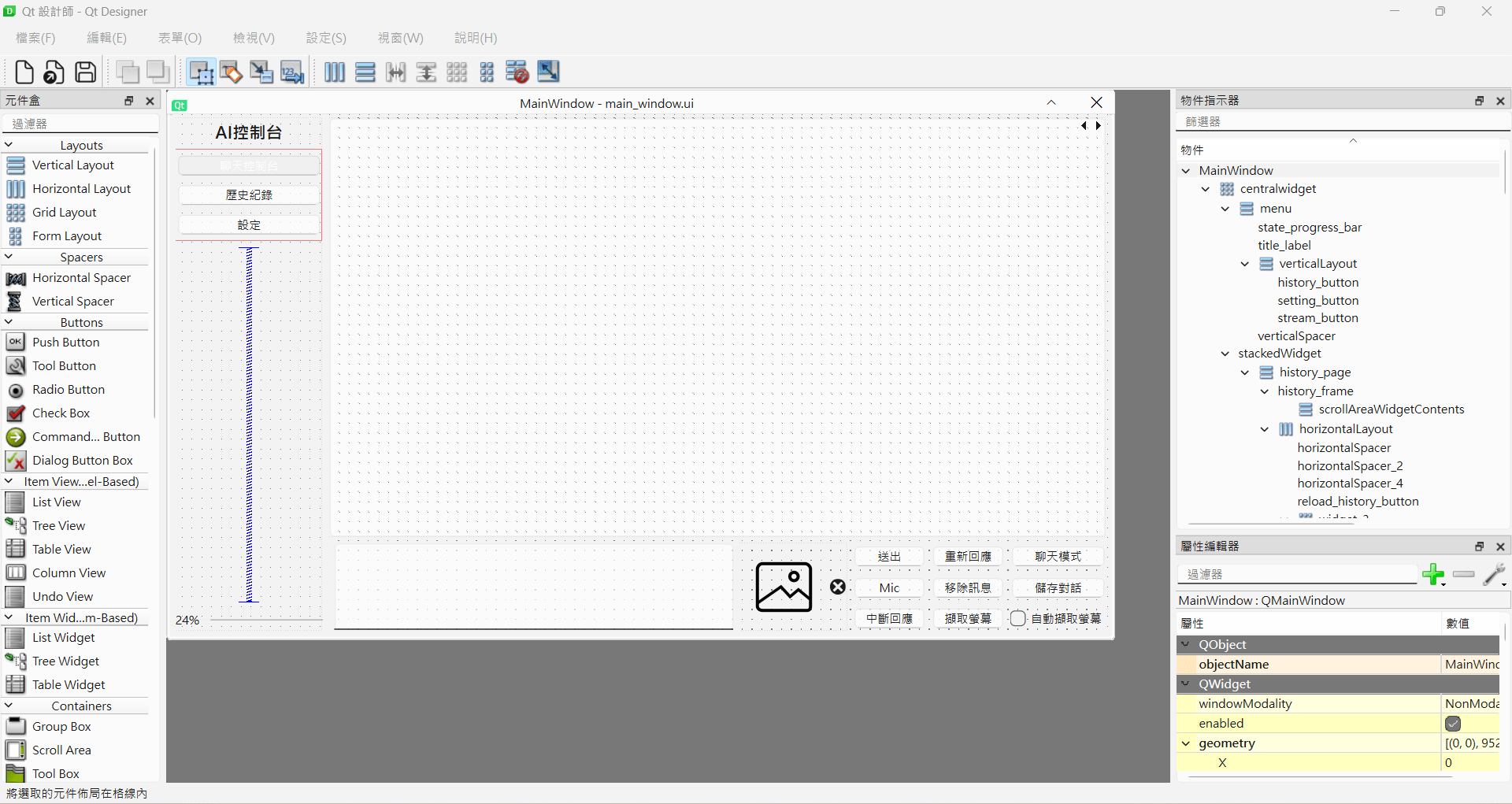
用這東西建立完GUI後還可以用pyqt提供的工具轉換成python code,真香
QtDesigner真香
我只需要再用一個物件來包裝我的業務邏輯程式碼,這樣就可以輕鬆改完我的摳了
不過,我還需要動態的修改這個GUI
因為我還需要顯示對話泡泡
bruh

第二個坑
PyQt5的空指標錯誤
因為我的模型是多模態的LLM
所以我也有做圖像輸入
輸入圖像沒有問題
問題出在把圖像顯示在對話泡泡中
只要一顯示圖像PyQt5就直接當機
然後丟一個莫名其妙的錯誤碼後崩潰
這個錯誤碼我拿去stackoverflow與gpt上問
都說是底層的Qt出現了NullPointer錯誤
但我用的是被python封裝起來的Qt啊?
根本除錯不了
第二個坑
PyQt5的空指標錯誤
後來怎麼解決的?
我上網查說pyside才是Qt官方作的python封裝
pyqt是社群開發者們自己搞的
那就試試pyside看看能不能解決
笑死
一模一樣的摳,只改import路徑改成pyside後
所有問題都消失了
世界突然就和平了
第二個坑
PyQt5的空指標錯誤
但pyside有一個致命的問題
就是他的文檔就跟沒有一樣
她的文檔是用qt c++"機器翻譯"成python版本的
因此你可以把文檔當不存在
第三個坑
pyside6的Qt全局鎖與python GIL
大多數的GUI都是"事件驅動"的方式在實現的
Qt的信號與信號槽在某種程度上也可以這麼認為
至少肯定會有一個主線程迴圈去不停地跑各種更新
我們理所當然的需要將耗時操作轉移到多線程甚至多進程中
不然就會出現"xxx已沒有回應"這種東西
第三個坑
pyside6的Qt全局鎖與python GIL
現在離譜的來了
qt的python封裝在啟動GUI後會有一個python主線程與Qt主線程
這兩個線程是各自獨立的
同時是各自使用不同的鎖
因此你在python的多線程的GUI更新事件並不會同步到qt主線程中
你得用信號槽機制把更新從python多線程中塞到qt主線程中
上鎖/解鎖也是
你會需要兩把鎖來保證線程安全
第四個坑
python request的連接建立延遲
我注意到我的語音合成模型總是會有一個約2~3秒的奇怪延遲
我原本想說是我的語音模型太大
算力不夠才會這樣
但我自己用別的工具測試時卻發現並沒有
我的語音模型已經夠小了
對於短句子可以做到毫秒級合成
第四個坑
python request的連接建立延遲
經過排查才知道原來request預設每次發請求時都會建立一個session來記錄連接狀態
這個session的建立時間就是約2~3秒
哭阿
好,前面的都是GUI後端的坑
現在我們要來提煉丹時的坑了
有了GUI,接下來就要微調LLM了
微調當然可以用transformers套件手刻
刻起來也不複雜,就是0優化而已
那我們就需要一個優秀的微調框架來幫我們搞優化
Llama-Factory
支援各種推理/訓練加速的微調框架
她很好心的幫你把你能在github上找到的大多數加速技術都整合在一起
諸如deepspeed、unsloth、flash attention...
雖然但是
llama-factory框架本身支援windows與linux
畢竟框架本身只是一堆python腳本
但底下的優化技術是實實在在的c/c++
第一個坑
Windows開發者沒人權
一堆底層優化技術都只支援linux,甚至微軟自己開發的deepspeed也是如此
偉哉WSL
不然就要搞麻煩的雙系統了
第二個坑
gguf量化
我雖然有一張4060ti 16G
4060ti 16G作為AI微調與推理的敲門磚足夠了
用transformers + 8int量化就可以輕鬆順跑
但這速度用在實際直播時可不行
一句話要講個1分鐘這太慢了
第二個坑
gguf量化
若使用gguf量化後,Q8量化可以來到11~16 token/s的速度
狠一點Q4或Q3量化可以達到將近20 token/s的速度
拿來直播綽綽有餘了
而且對VRAM的需求也大大減少
這樣我就有額外的VRAM可以跑語音合成模型了
第二個坑
gguf量化
問題來了:
如何量化一個融合了clip與llama3的全新模型?
gguf支援llava1.5 -> 融合llama2與clip
gguf支援llama3
所以我們需要將用transformers標準格式儲存的權重轉換成gguf格式
第二個坑
第二個坑
gguf量化
直接說結論
我通過魔改llava1.5的gguf轉換腳本使其能把llava-llama3的llama3轉換成正確的gguf格式
但我到現在依舊不知道該怎麼將gguf多模態模型的mm_project轉換出來
去他們的官方dc問只有一個奇怪的傢伙向我展示了他那炫炮無比的個人網站
我到現在依舊不知道怎麼把clip模型與投影矩陣正確地轉換成gguf格式
第二個坑
gguf量化
最後我只能使用xtuner團隊轉換出來的mm_proj作為我的多模態gguf模型
因為我在使用llama-factory微調模型時並不會動到投影矩陣與clip模型
因此湊合著用還行
大概吧...
啊踩了那麼多坑
最後成果長怎樣?
AI VT開發的各種坑
By asadfgglie



