
Artëm Sobolev
Research Scientist in Machine Learning
Artëm Sobolev, AI Engineer at Luka Inc
@art_sobolev | http://artem.sobolev.name/
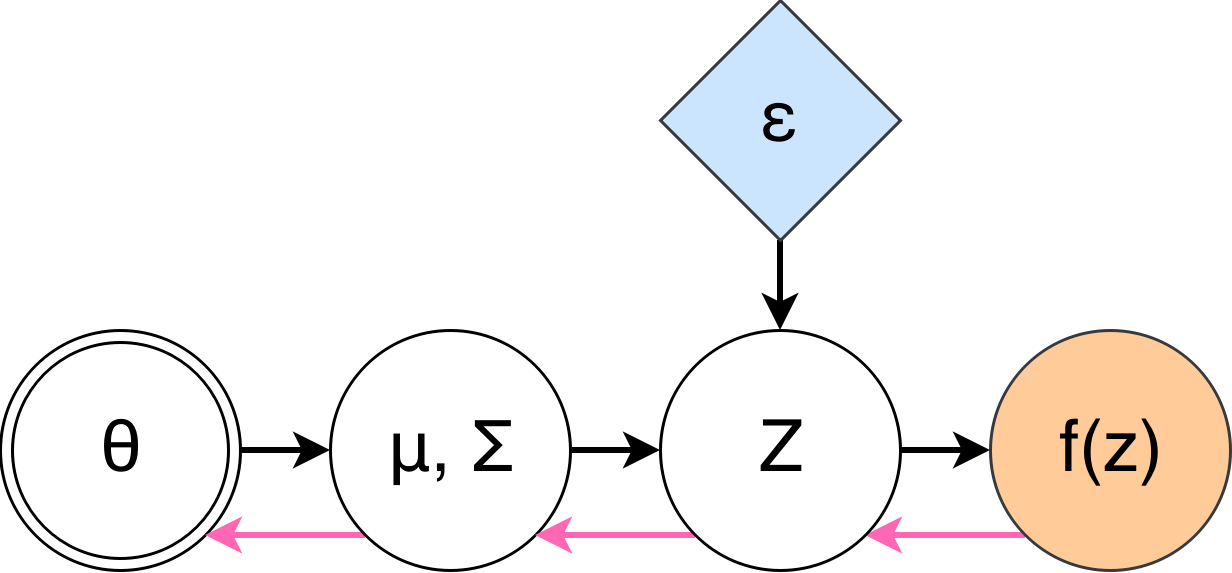
This talk: What if \(z \sim p(z|\theta)\)?
(and we'd like to find optimal \(\theta\) as well)
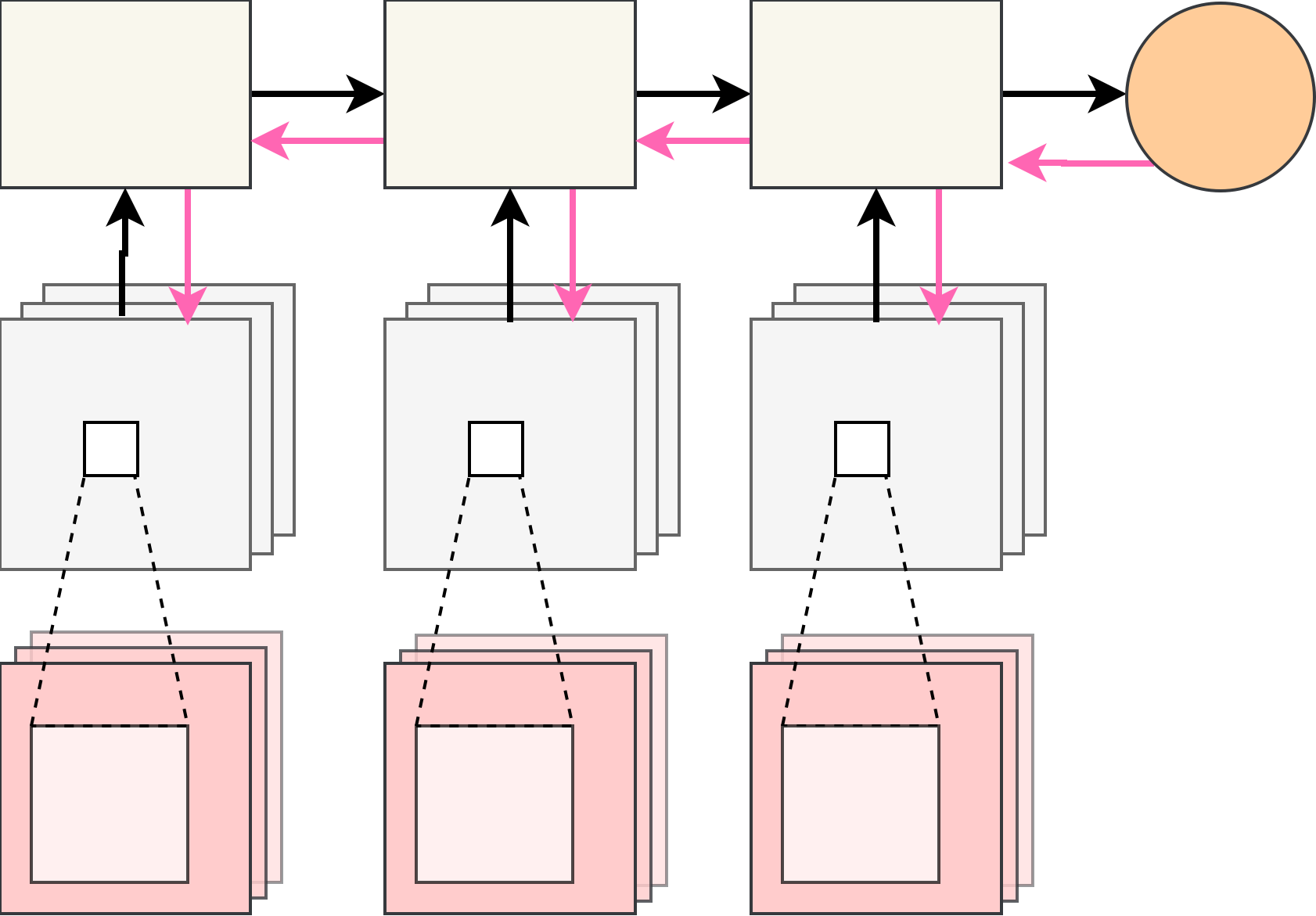
Let \(F(z) = L(f(x, z|\phi), y)\), then
$$ \nabla_\theta \mathbb{E}_{p(z|\theta)} F(z) = \nabla_\theta \int F(z) p(z|\theta) dz = \int F(z) \nabla_\theta p(z|\theta) dz $$ $$= \int F(z) \nabla_\theta \log p(z|\theta) p(z|\theta) dz = \mathbb{E}_{p(z|\theta)} \nabla_\theta \log p(z|\theta) F(z) $$
Intuition: push probabilities of good samples (as measured by \(F(z)\)) up.
Pros: very general, does not require differentiable \(F\).
Cons: known to have large variance, sensitive to values of \(F\).
We'll get back to this estimator later in the talk.
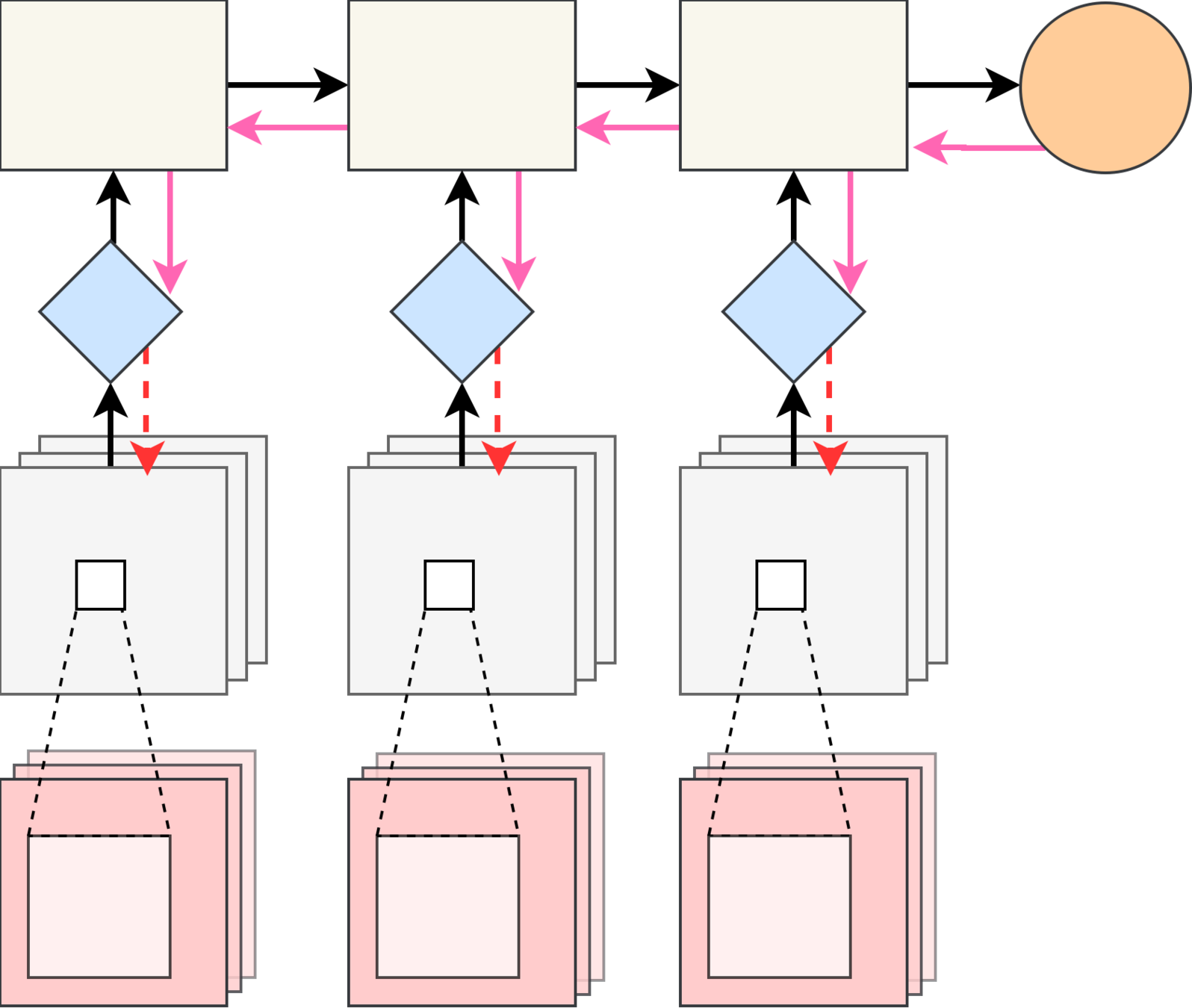
Pros: backprop through sample
Cons: requires ability to differentiate CDF w.r.t. \(\theta\)
⇒
$$ \nabla_\theta \mathbb{E}_{p(\varepsilon|\theta)} F(z) = \mathbb{E}_{p(\varepsilon|\theta)} \nabla_\theta F(\mathcal{T}_\theta(\varepsilon)) + \mathbb{E}_{p(\varepsilon|\theta)} \nabla_\theta \log p(\varepsilon|\theta) F(\mathcal{T}_\theta(\varepsilon))$$
The formula $$ \nabla_\theta \mathbb{E}_{p(\varepsilon|\theta)} F(z) = \mathbb{E}_{p(\varepsilon|\theta)} \nabla_\theta F(\mathcal{T}_\theta(\varepsilon)) + \mathbb{E}_{p(\varepsilon|\theta)} \nabla_\theta \log p(\varepsilon|\theta) F(\mathcal{T}_\theta(\varepsilon))$$ requires us to sample \( \varepsilon|\theta\). With a bit of algebra we can rewrite these addends in terms of samples \(z|\theta\): $$ \mathbb{E}_{p(z|\theta)} \nabla_z F(z) \nabla_\theta h_\theta(\mathcal{T}^{-1}_\theta(z)) $$ $$\mathbb{E}_{p(z|\theta)} F(z) \left[ \nabla_\theta \log p(z|\theta) + \nabla_z\log p(z|\theta) h_\theta(\mathcal{T}^{-1}_\theta(z)) + u_\theta(\mathcal{T}^{-1}_\theta(z))\right]$$
Where
Pros: interpolates between reparametrisation and REINFORCE
Cons: need to come up with differentiable \(\mathcal{T}_\theta\)
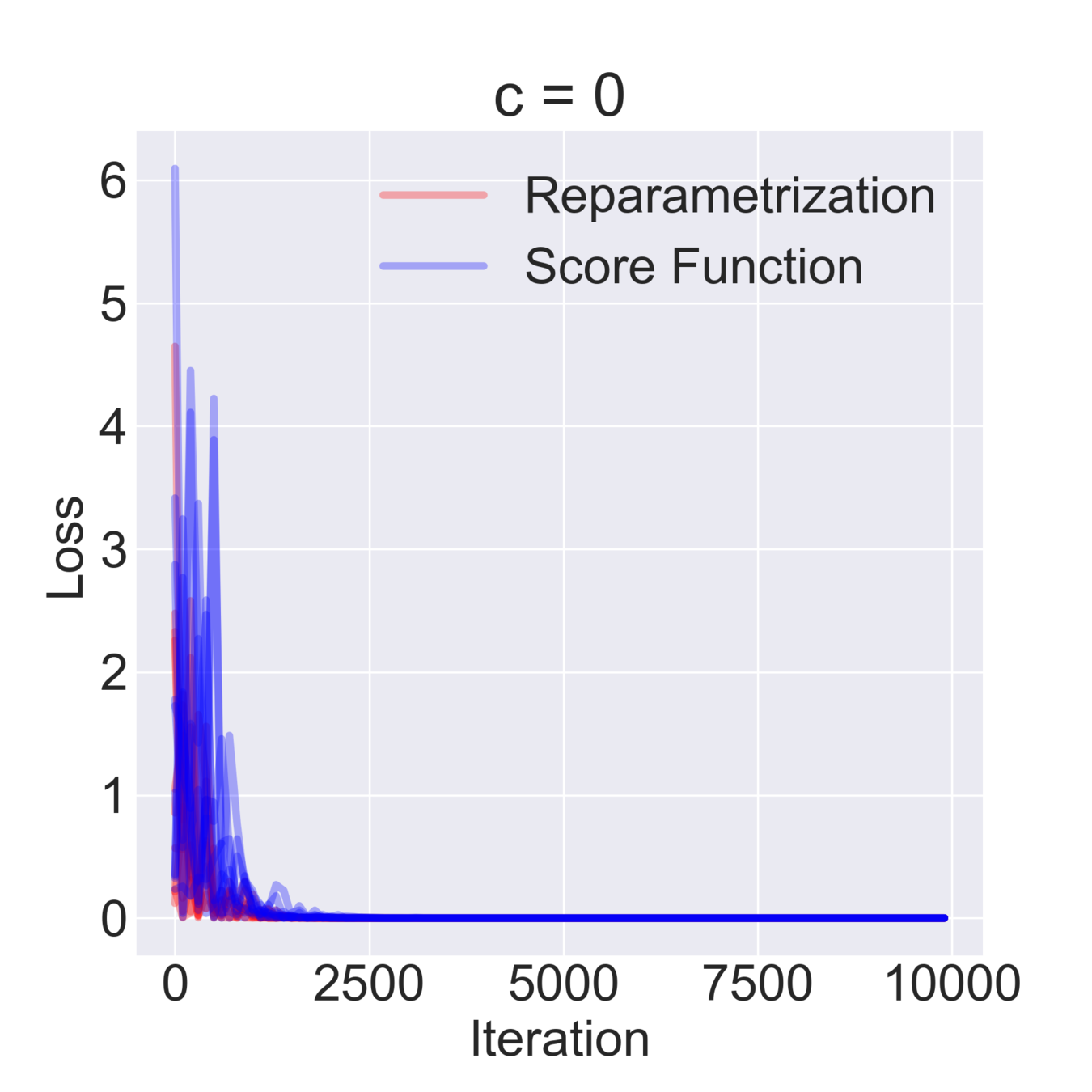
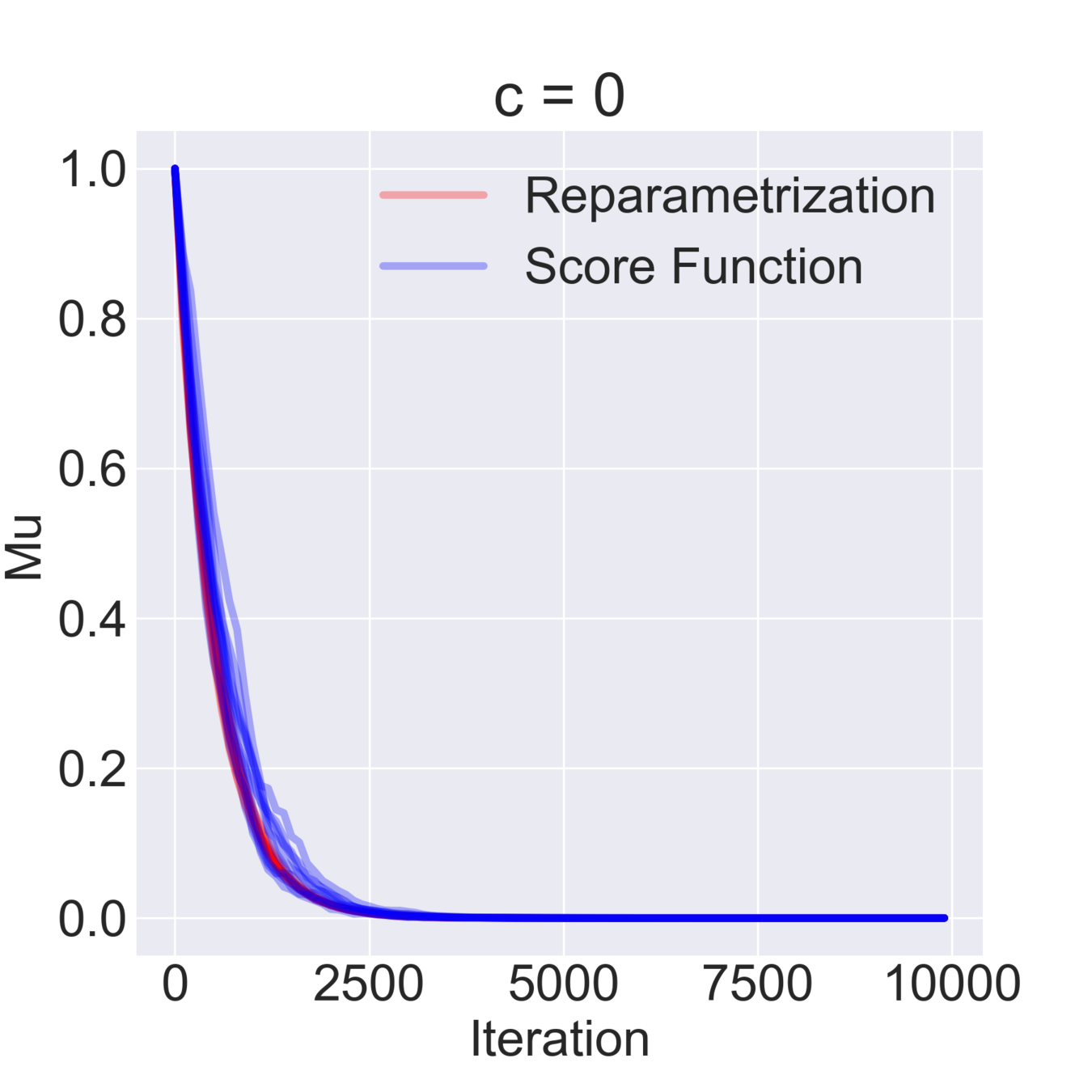
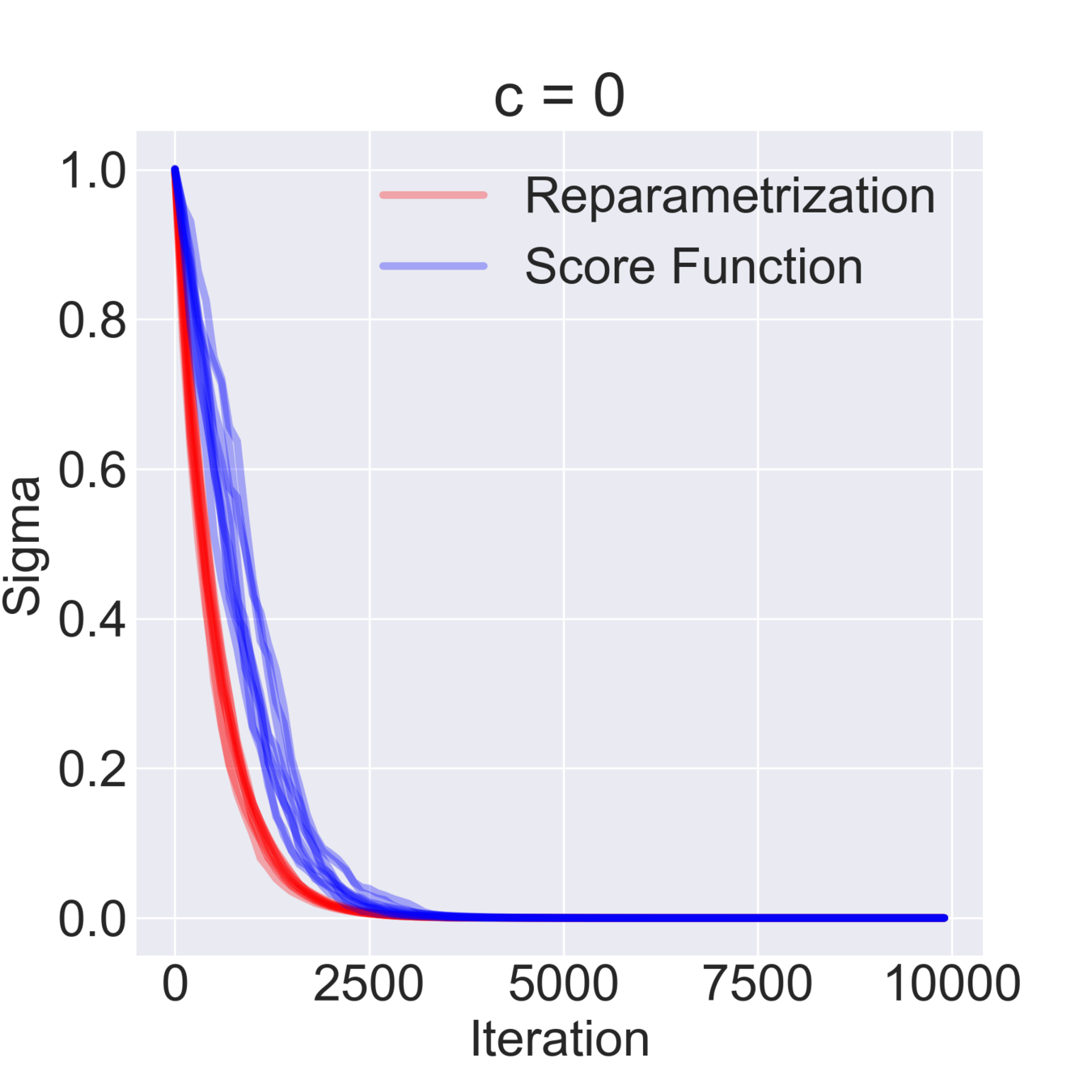
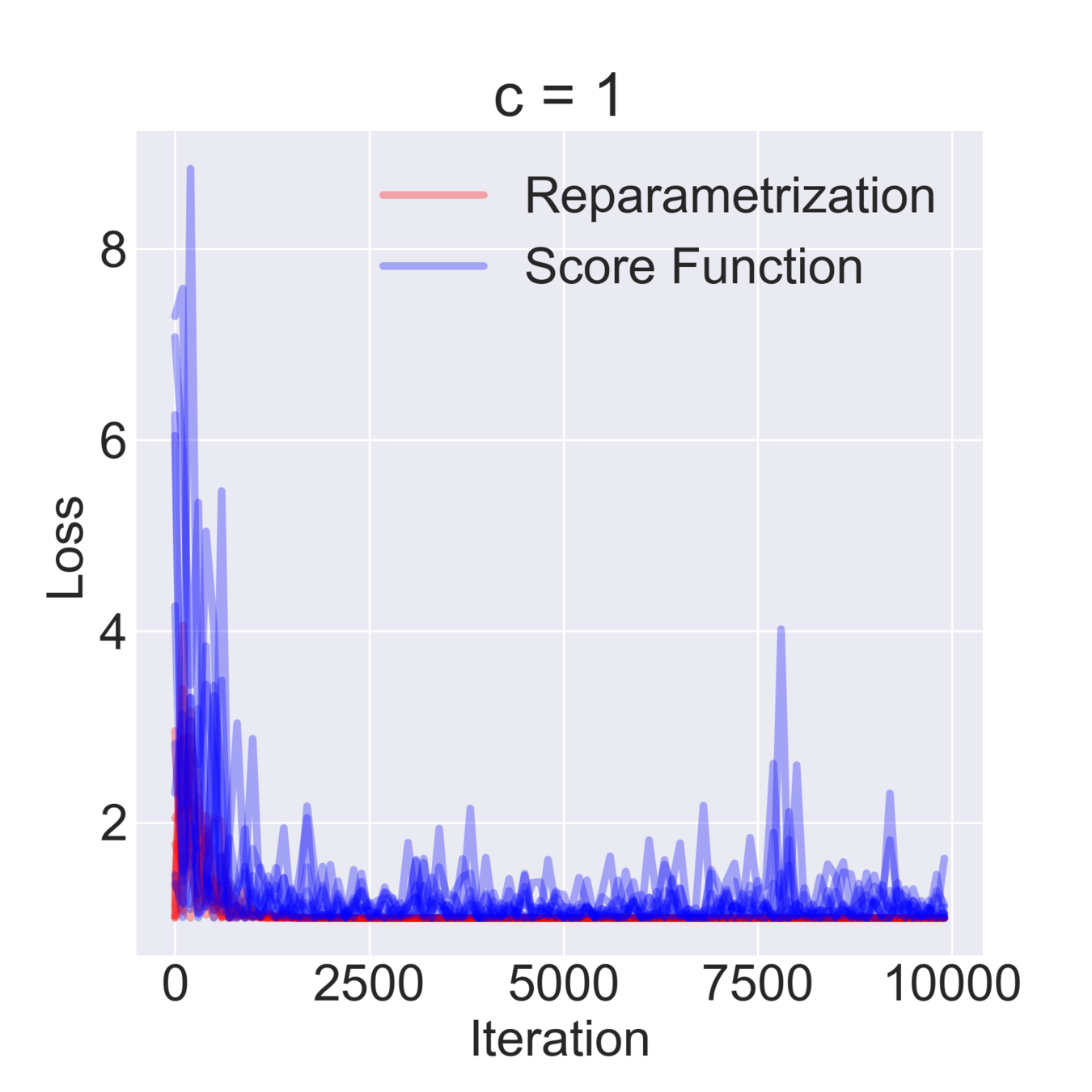
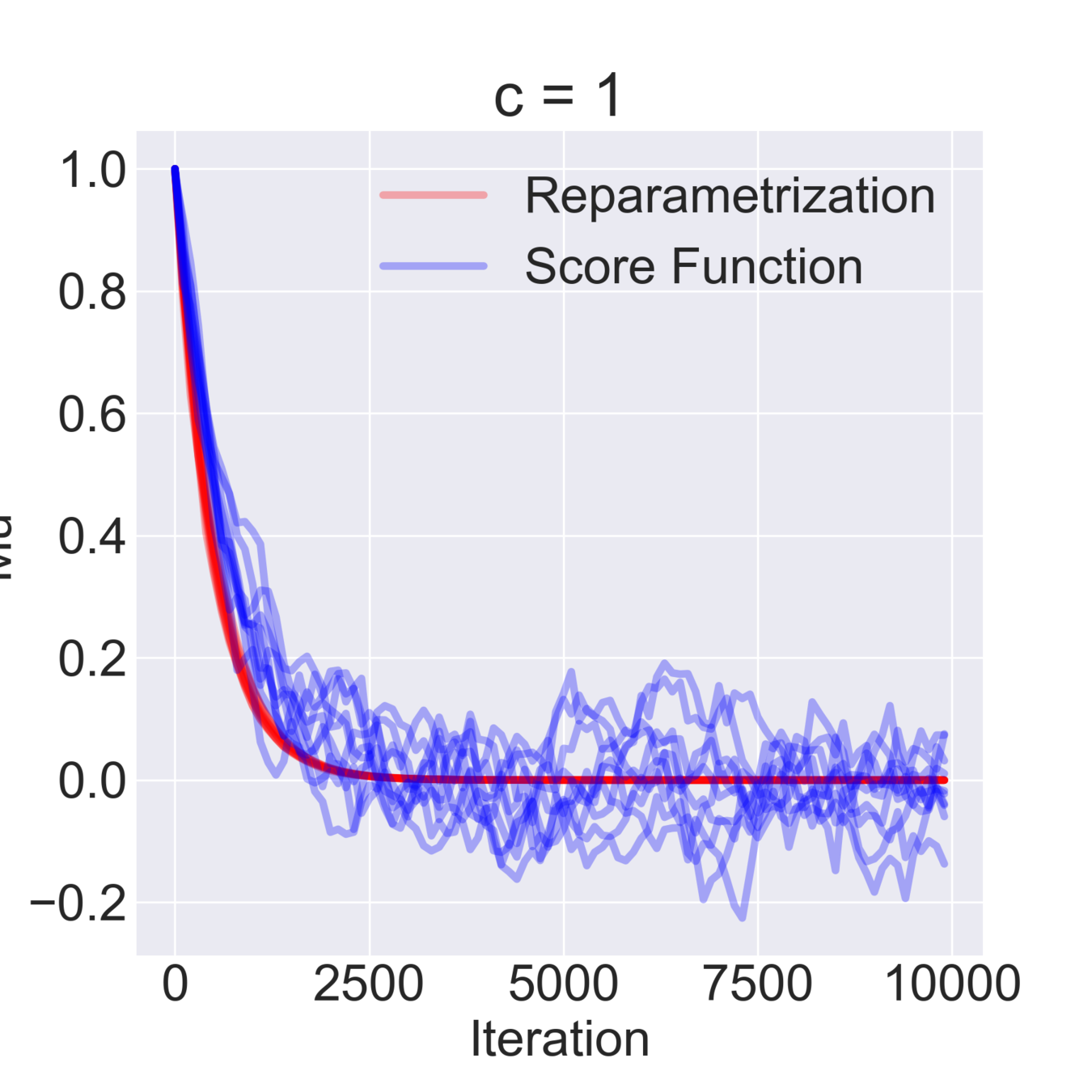
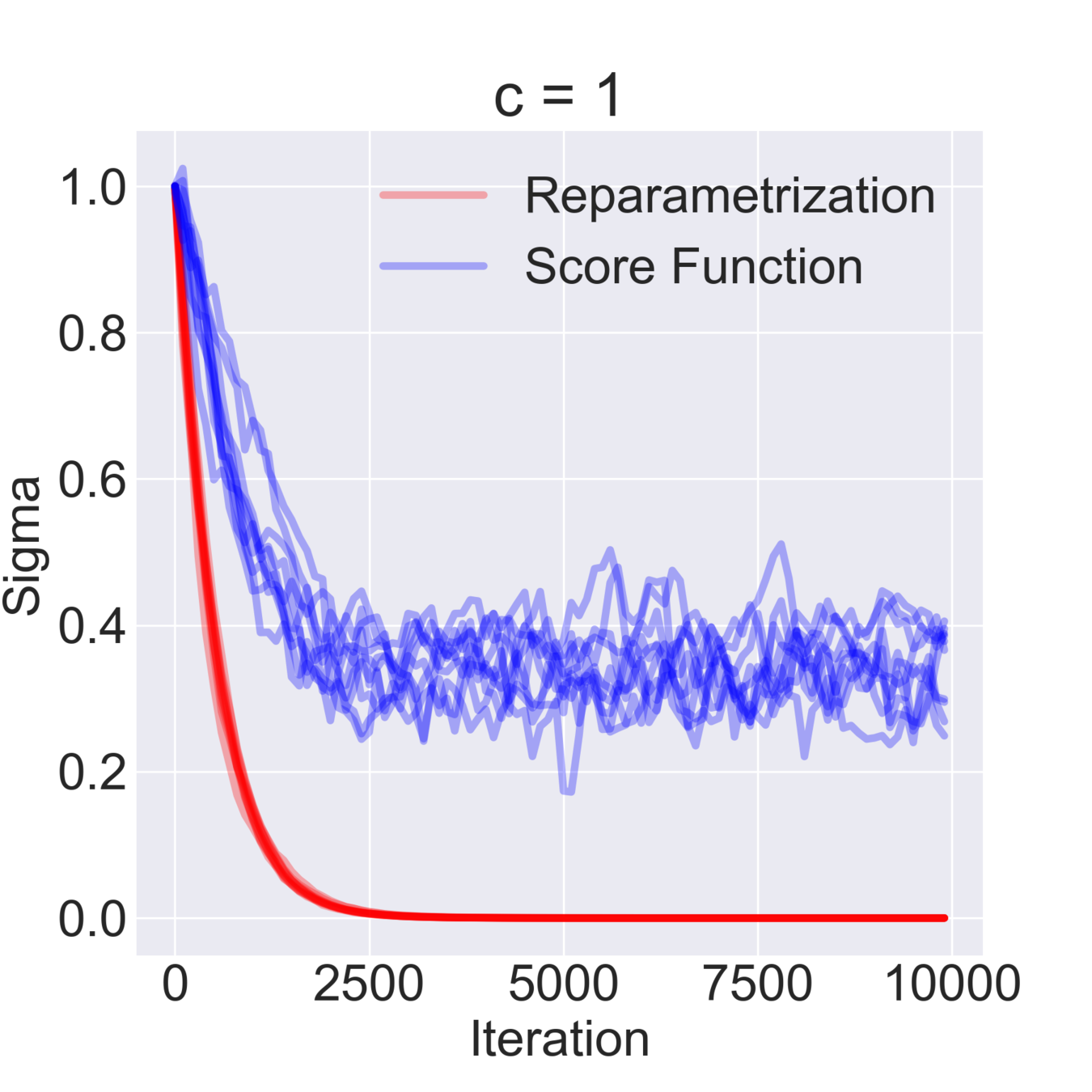
$$ \mathcal{F}(\mu, \sigma) = \mathbb{E}_{z \sim \mathcal{N}(\mu, \sigma^2)} [z^2 + c] = \mathbb{E}_{\varepsilon\sim\mathcal{N}(0, 1)} [(\mu + \varepsilon \sigma)^2 + c] \to \min_{\mu, \sigma} $$
$$ \hat \nabla_\mu \mathcal{F}^{\text{rep}}(\mu, \sigma) = 2 (\mu + \sigma \varepsilon) \quad\quad \hat\nabla_\mu \mathcal{F}^\text{SF}(\mu, \sigma) = \frac{\varepsilon}{\sigma} ((\mu+\sigma \varepsilon)^2+c) $$
$$ \hat \nabla_\sigma \mathcal{F}^\text{rep}(\mu, \sigma) = 2 \varepsilon (\mu + \sigma \varepsilon) \quad\quad \hat \nabla_\sigma \mathcal{F}^\text{SF}(\mu, \sigma) = \frac{\varepsilon^2-1}{\sigma}((\mu+\sigma \varepsilon)^2+c)$$
$$ \mathbb{D}[\hat \nabla_\mu \mathcal{F}^\text{rep}(\mu, \sigma)] = 4 \sigma^2 \quad\quad \mathbb{D} [\hat \nabla_\sigma \mathcal{F}^\text{rep}(\mu, \sigma)] = 4 \mu^2 + 8 \sigma^2 $$
$$ \mathbb{D}[\hat \nabla_\mu \mathcal{F}^\text{SF}(\mu, \sigma)] = \frac{(\mu^2 + c)^2}{\sigma^2} + 15 \sigma^2 + 14 \mu^2 + 6 c $$
$$ \mathbb{D}[\hat \nabla_\sigma \mathcal{F}^\text{SF}(\mu, \sigma)] = \frac{2 (\mu^2 + c)^2}{\sigma^2} + 74 \sigma^2 + 60 \mu^2 + 20 c $$
Mu
$$ z = \text{argmax}_k \left[\gamma_k + \log p_k\right] $$
$$ \zeta = \text{softmax}_\tau \left(\gamma_k + \log p_k\right) $$
⇒
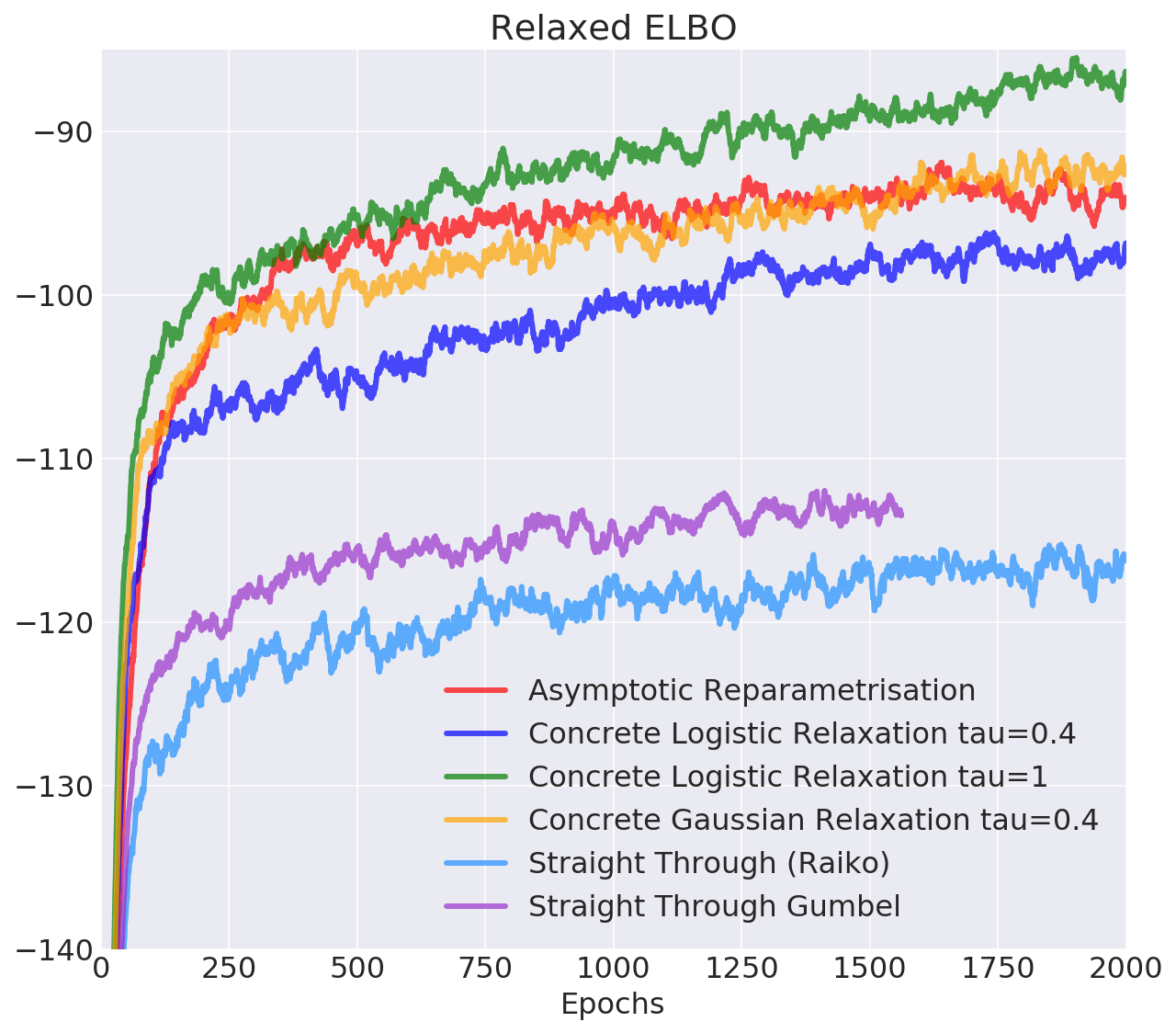
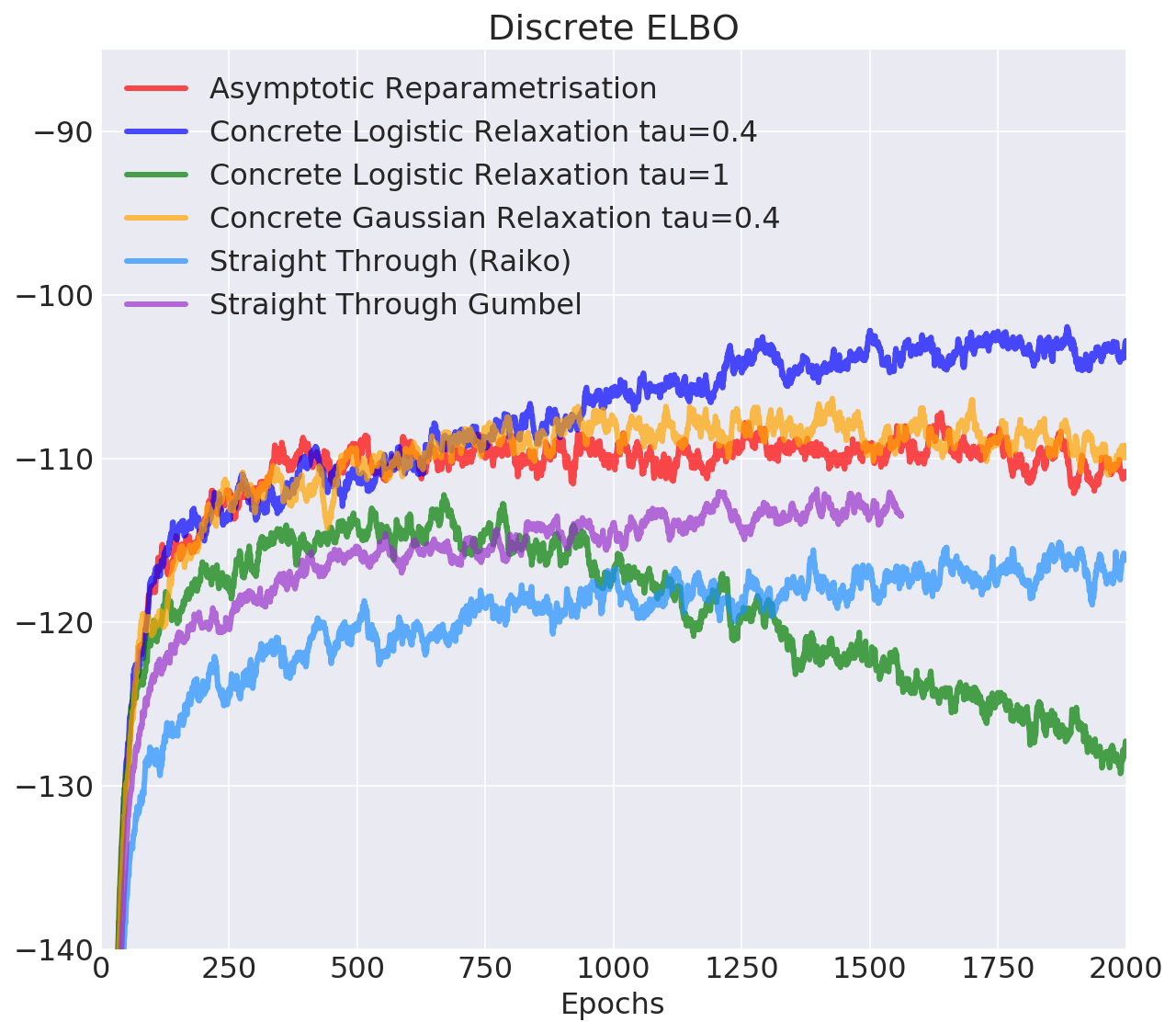
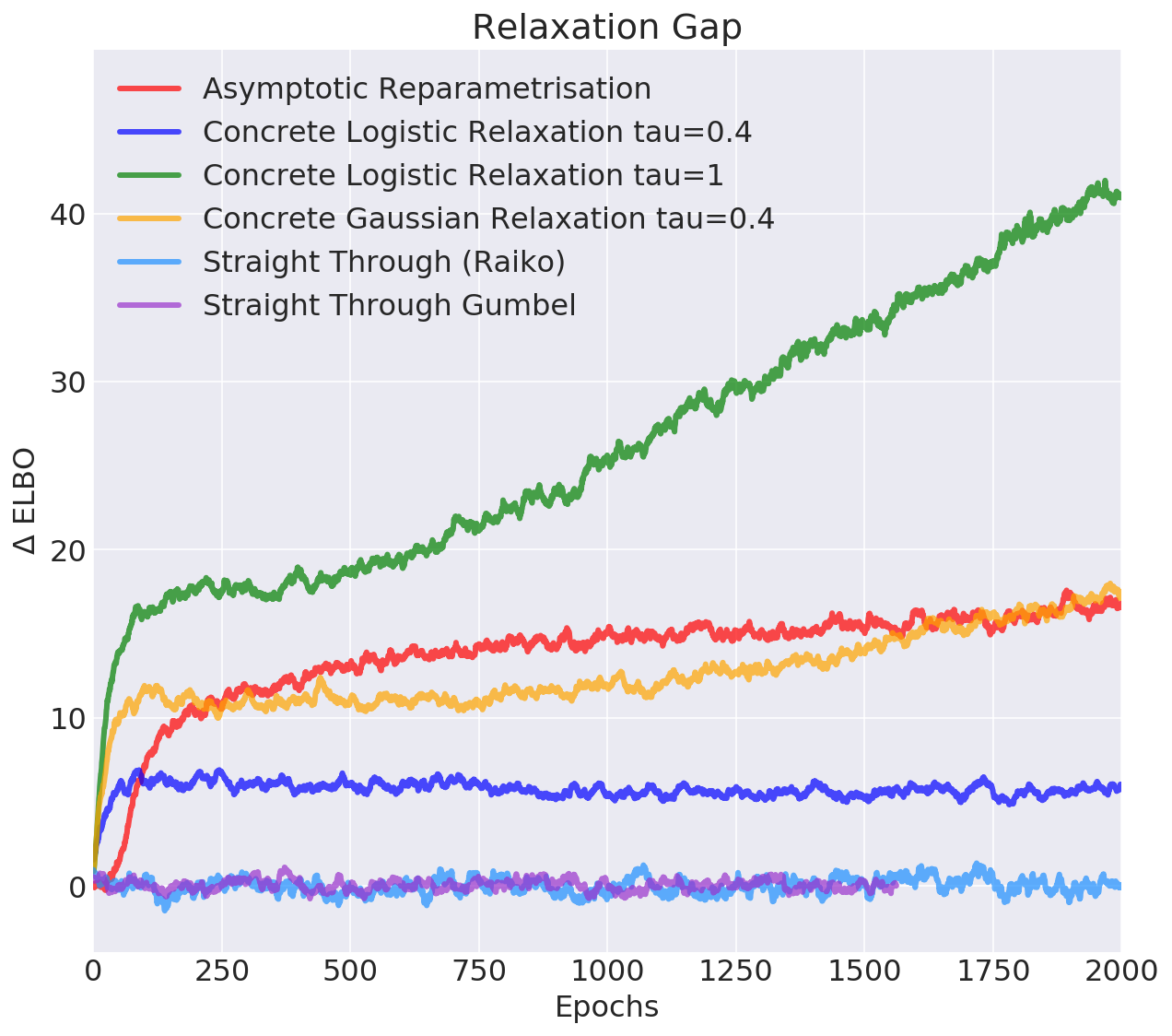
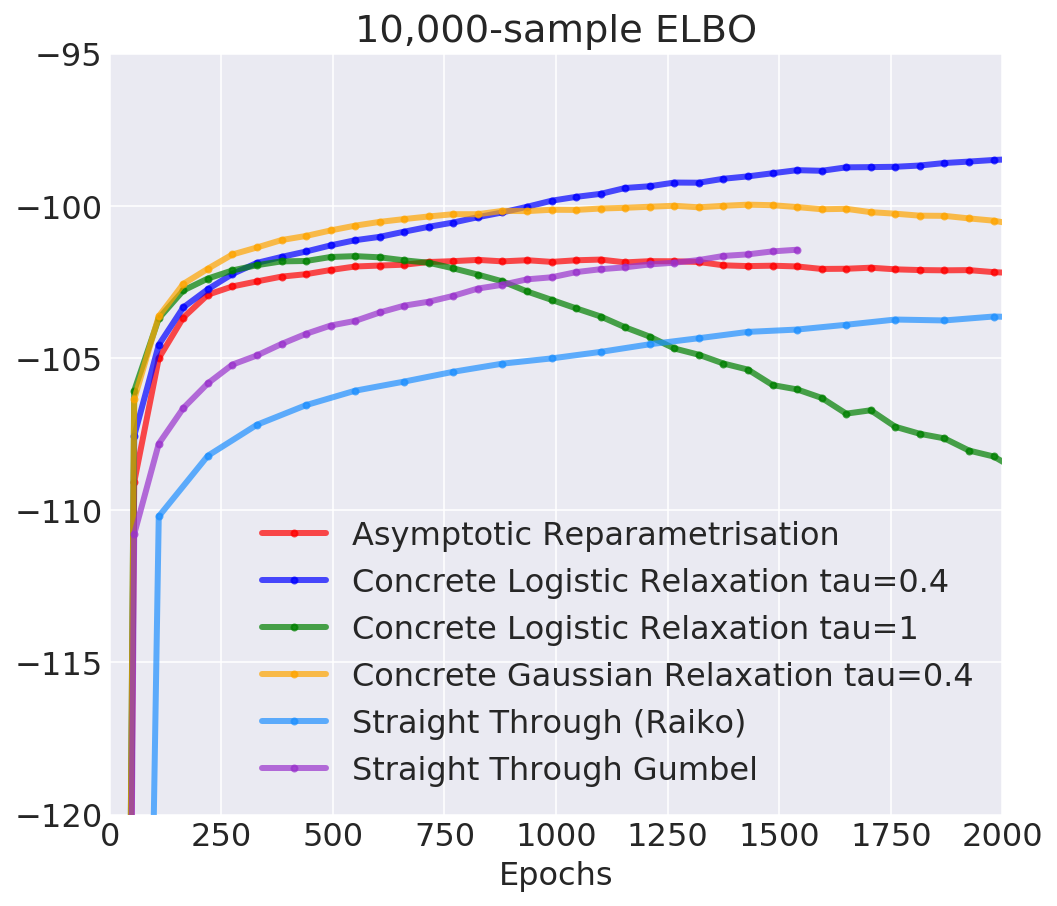
Pros: works in categorical case, temperature controls bias
Cons: still biased, not clear how to tune temperature
Many other estimators only relax the backward pass
Pros: don't see any
Cons: mathematically unsound ¯\_(ツ)_/¯
How to design a control variate?
Pros: more efficient, still easy to implement
Cons: requires training an extra model \(b(x)\) (unless VIMCO), does not use \(z\) in the baseline, doesn't use gradient \(\nabla_z F(z)\)
Pros: uses gradient information \(\nabla_z F(z)\)
Cons:
\( \nabla_\theta \mathbb{E}_{p(X|\theta)} F(\sigma_\tau(X)) = \nabla_\theta \mathbb{E}_{p(X, z|\theta)} F(\sigma_\tau(X)) = \)
$$ \mathbb{E}_{p(z|\theta)} \left[\nabla_\theta \mathbb{E}_{p(X|z, \theta)} F(\sigma_\tau(X|z))\right] + \mathbb{E}_{p(z|\theta)} \mathbb{E}_{p(X|z,\theta)} [F(\sigma_\tau(X|z))] \nabla_\theta \log p(z|\theta) $$
We arrive to the following formula
$$\nabla_\theta \mathbb{E}_{p(z|\theta)} F(z) = \mathbb{E}_{u, v} \left[ \left(F(z) - \eta F(\zeta|z) \right) \nabla_\theta \log p(z|\theta) + \eta \nabla_\theta F(\zeta) - \eta \nabla_\theta F(\zeta|z) \right]$$
Where \(z=H(X)\), \(\zeta = \sigma_\tau(X)\), \(\zeta|z = \sigma_\tau(X|z)\)
\( X = \log \frac{u}{1-u} + \log \tfrac{\mu(\theta)}{1-\mu(\theta)} \)
\(\eta\) and \(\tau\) are tuneable parameters, optimised to reduce the variance
Pros:
Cons:
What if \(F(z)\) is not differentiable or we don't know its gradients (like in RL)?
The \(\tilde{F}\) is optimized to minimize the variance $$\text{Var} \hat{g}_i = \mathbb{E} \hat{g}_i^2 - \left(\mathbb{E} \hat{g}_i\right)^2$$ \(\hat{g}_i\) is unbiased, hence the second term does not depend on \(\tilde{F}\)
By Artëm Sobolev
My talk on stochastic computation graphs for BayesGroup seminar




