
Artëm Sobolev
Research Scientist in Machine Learning
| Unknown p(z) | Known p(z) | |
|---|---|---|
| Unknown p(x|z) | Hard | Doable |
| Known p(x|z) | Hard | Good |
| Unknown p(z) | Known p(z) | |
|---|---|---|
| Unknown p(x|z) | Hard | Hard |
| Known p(x|z) | Doable | Good |
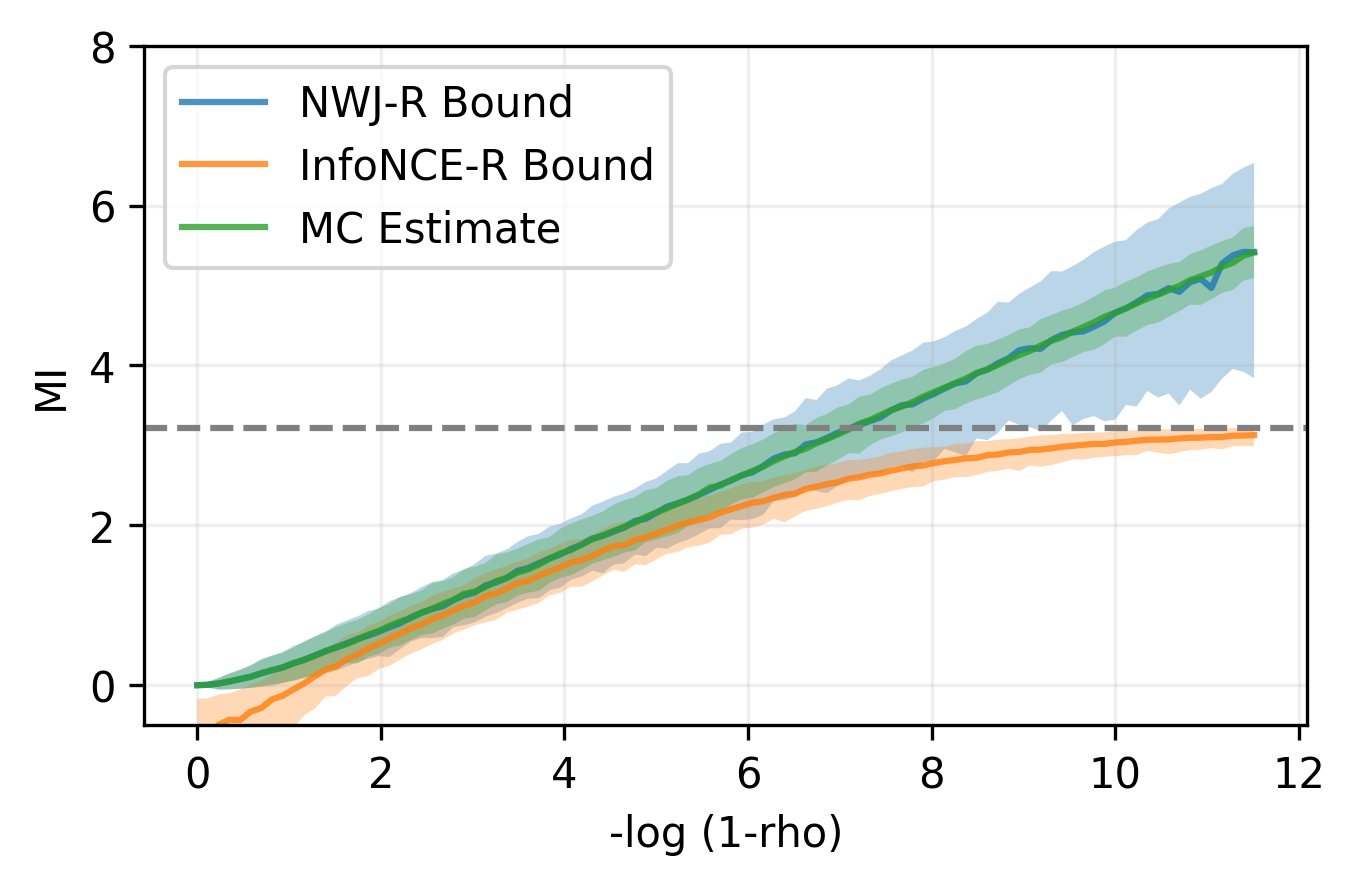
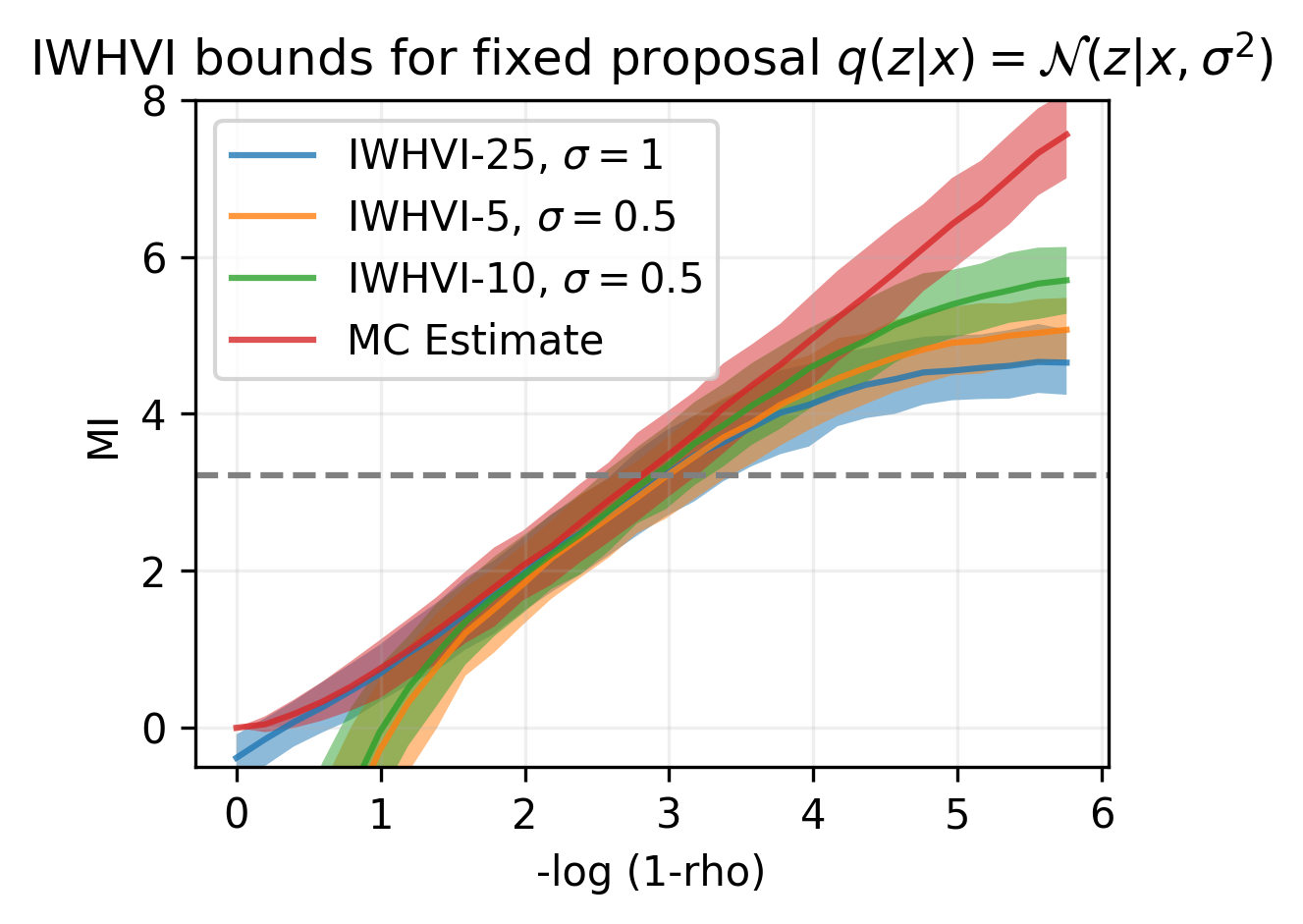
All these lower bounds have been shown to be very poor!
Theorem [1]: Let \(B\) be any distribution-free high-confidence lower bound on \(\mathbb{H}[p(x)]\) computed from a sample \(x_{1:N} \sim p(x)\). More specifically, let \(B(x_{1:N}, \delta)\) be any real-valued function of a sample and a confidence parameter \(\delta\) such that for any \(p(x)\), with probability at least \((1 − \delta)\) over a draw of \(x_{1:N}\) from \(p(x)\), we have $$\mathbb{H}[p(x)] \ge B(x_{1:N}, δ).$$ For any such bound, and for \(N \ge 50\) and \(k \ge 2\), with probability at least \(1 − \delta − 1.01/k\) over the draw of \(x_{1:N}\) we have $$B(x_{1:N}, \delta) ≤ \log(2k N^2)$$
Good black-box lower bounds on \(\mathbb{H}\) require exponential number of samples!
$$ I(X, Z) = {\color{red} H(X)} - H(X|Z) \overset{\text{discrete } X}{\le} {\color{red} H(X)} $$
Does not agree with the MI-maximizing interpretation
$$ \text{MI}[p(x, z)] \ge \mathbb{E}_{p(x, z_0)} \mathbb{E}_{q(z_{1:K}|x)} \log \frac{\hat\rho(x, z_0)}{\tfrac{1}{K+1} \sum_{k=0}^K \frac{\hat\rho(x, z_k)}{q(z_k|x)} } - \mathbb{E}_{p(z)} \log p(z)$$
$$\mathbb{E}_{p(x, z_0)} \mathbb{E}_{q(z_{1:K}|x)} \frac{p(x|z_0)}{\tfrac{1}{K+1} \sum_{k=0}^K \tfrac{p(x,z_k)}{q(z_k|x)} } \le \text{MI}[p(x,z)] \le \mathbb{E}_{p(x, z_0)} \mathbb{E}_{q(z_{1:K}|x)} \frac{p(x|z_0)}{\tfrac{1}{K} \sum_{k=1}^K \tfrac{p(x,z_k)}{q(z_k|x)} } $$
[1]: David McAllester, Karl Stratos. Formal Limitations on the Measurement of Mutual Information.
[2]: Aaron van den Oord, Yazhe Li, Oriol Vinyals. Representation Learning with Contrastive Predictive Coding.
[3]: R Devon Hjelm, Alex Fedorov, Samuel Lavoie-Marchildon, Karan Grewal, Phil Bachman, Adam Trischler, Yoshua Bengio. Learning deep representations by mutual information estimation and maximization.
[4]: Philip Bachman, R Devon Hjelm, William Buchwalter. Learning Representations by Maximizing Mutual Information Across Views.
[5]: Naftali Tishby, Noga Zaslavsky. Deep Learning and the Information Bottleneck Principle.
[6]: Ben Poole, Sherjil Ozair, Aaron van den Oord, Alexander A. Alemi, George Tucker. On Variational Bounds of Mutual Information.
[7]: Donsker, M. D. and Varadhan, S. S. Asymptotic evaluation of certain markov process expectations for large time.
[8]: Nguyen, X., Wainwright, M. J., and Jordan, M. I. Estimating divergence functionals and the likelihood ratio by convex risk minimization.
[9]: Barber, D. and Agakov, F. The im algorithm: A variational approach to information maximization.
[10]: Justin Domke, Daniel Sheldon. Importance Weighting and Variational Inference.
[11]: Yuri Burda, Roger Grosse, Ruslan Salakhutdinov. Importance Weighted Autoencoders.
[12]: Artem Sobolev, Dmitry Vetrov. Importance Weighted Hierarchical Variational Inference.
[13]: Mingzhang Yin, Mingyuan Zhou. Semi-Implicit Variational Inference.
[14]: Sherjil Ozair, Corey Lynch, Yoshua Bengio, Aaron van den Oord, Sergey Levine, Pierre Sermanet. Wasserstein Dependency Measure for Representation Learning.
[15]: Daniel P. Palomar, Sergio Verdu. Lautum Information.
[16]: Roger B. Grosse, Zoubin Ghahramani, Ryan P. Adams. Sandwiching the marginal likelihood using bidirectional Monte Carlo.
[17]: AmirEmad Ghassami, Sajad Khodadadian, Negar Kiyavash. Fairness in Supervised Learning: An Information Theoretic Approach.
By Artëm Sobolev
See also http://artem.sobolev.name/tags/mutual%20information.html




