Artëm Sobolev
Research Scientist in Machine Learning
Standard VAE[1] has a fully factorized Gaussian proposal
Q.E.D.
These two look suspiciously similar!
Given all this evidence, it's time to question ourselves: Is this all just a coincidence? Or, is the (1) indeed a multisample \(\tau\)-variational upper bound on the marginal log-density \(\log q_\phi(z|x)\)?
Theorem: for \(K \in \mathbb{N}_0 \), any* \(q_\phi(z, \psi|x)\) and \(\tau_\eta(\psi|x,z)\) denote $$ \mathcal{U}_K := \mathbb{E}_{q_\phi(\psi_0|x, z)} \mathbb{E}_{\tau_\eta(\psi_{1:K}|z,x)} \log \frac{1}{K+1} \sum_{k=0}^K \frac{q_\phi(z,\psi_k| x)}{\tau_\eta(\psi_k \mid x, z)}$$Then the following holds
Proof: we will only prove the first statement by showing that the gap between the bound and the marginal log-density is equal to some KL divergence
Proof: consider the gap $$ \mathbb{E}_{q_\phi(\psi_0|x, z)} \mathbb{E}_{\tau_\eta(\psi_{1:K}|z,x)} \log \tfrac{1}{K+1} \sum_{k=0}^K \frac{q_\phi(z,\psi_k| x)}{\tau_\eta(\psi_k \mid x, z)} - \log q_\phi(z|x)$$
Multiply and divide by \(q_\phi(\psi_0|x,z) \tau_\eta(\psi_{1:K}|x,z)\) to get $$ \mathbb{E}_{q_\phi(\psi_0|x, z)} \mathbb{E}_{\tau_\eta(\psi_{1:K}|z,x)} \log \frac{q_\phi(\psi_0|x, z) \tau_\eta(\psi_{1:K}|z,x)}{\frac{q_\phi(\psi_0|x, z) \tau_\eta(\psi_{1:K}|z,x)}{\tfrac{1}{K+1} \sum_{k=0}^K \frac{q_\phi(\psi_k| z,x)}{\tau_\eta(\psi_k \mid x, z)}}} $$
Subtract the log $$ \mathbb{E}_{q_\phi(\psi_0|x, z)} \mathbb{E}_{\tau_\eta(\psi_{1:K}|z,x)} \log \tfrac{1}{K+1} \sum_{k=0}^K \frac{q_\phi(\psi_k| z,x)}{\tau_\eta(\psi_k \mid x, z)} $$
Which is exactly the KL divergence $$ D_{KL}\left(q_\phi(\psi_0|x, z) \tau_\eta(\psi_{1:K}|z,x) \mid\mid \frac{q_\phi(\psi_0|x, z) \tau_\eta(\psi_{1:K}|z,x)}{\tfrac{1}{K+1} \sum_{k=0}^K \frac{q_\phi(\psi_k| z,x)}{\tau_\eta(\psi_k \mid x, z)} }\right)$$
For the KL to enjoy non-negativity and be 0 when distributions match, we need the second argument to be a valid probability density. Is it? $$ \omega_{q,\tau}(\psi_{0:K}|x,z) := \frac{q_\phi(\psi_0|x, z) \tau_\eta(\psi_{1:K}|z,x)}{\tfrac{1}{K+1} \sum_{k=0}^K \frac{q_\phi(\psi_k| z,x)}{\tau_\eta(\psi_k \mid x, z)} }$$
We'll show it by means of symmetry:
$$ \int \frac{q_\phi(\psi_0|x, z) \tau_\eta(\psi_{1:K}|z,x)}{\tfrac{1}{K+1} \sum_{k=0}^K \frac{q_\phi(\psi_k| z,x)}{\tau_\eta(\psi_k \mid x, z)} } d\psi_{0:K} = \int \frac{\frac{q_\phi(\psi_0|x, z)}{\tau_\eta(\psi_0|x, z)} \tau_\eta(\psi_{0:K}|z,x)}{\tfrac{1}{K+1} \sum_{k=0}^K \frac{q_\phi(\psi_k| z,x)}{\tau_\eta(\psi_k \mid x, z)} } d\psi_{0:K} =$$
However, there's nothing special in the choice of the 0-th index, we could take any \(j\) and the expectation wouldn't change. Let's average all of them: $$= \int \frac{\frac{q_\phi(\psi_j|x, z)}{\tau_\eta(\psi_j|x, z)} \tau_\eta(\psi_{0:K}|z,x)}{\tfrac{1}{K+1} \sum_{k=0}^K \frac{q_\phi(\psi_k| z,x)}{\tau_\eta(\psi_k \mid x, z)} } d\psi_{0:K} = \frac{1}{K+1} \sum_{j=0}^K \int \frac{\frac{q_\phi(\psi_j|x, z)}{\tau_\eta(\psi_j|x, z)} \tau_\eta(\psi_{0:K}|z,x)}{\tfrac{1}{K+1} \sum_{k=0}^K \frac{q_\phi(\psi_k| z,x)}{\tau_\eta(\psi_k \mid x, z)} } d\psi_{0:K}$$
Q.E.D.
$$ = \int \frac{\frac{1}{K+1} \sum_{j=0}^K \frac{q_\phi(\psi_j|x, z)}{\tau_\eta(\psi_j|x, z)} \tau_\eta(\psi_{0:K}|z,x)}{\tfrac{1}{K+1} \sum_{k=0}^K \frac{q_\phi(\psi_k| z,x)}{\tau_\eta(\psi_k \mid x, z)} } d\psi_{0:K} = \int \tau_\eta(\psi_{0:K}|z,x) d\psi_{0:K} = 1$$
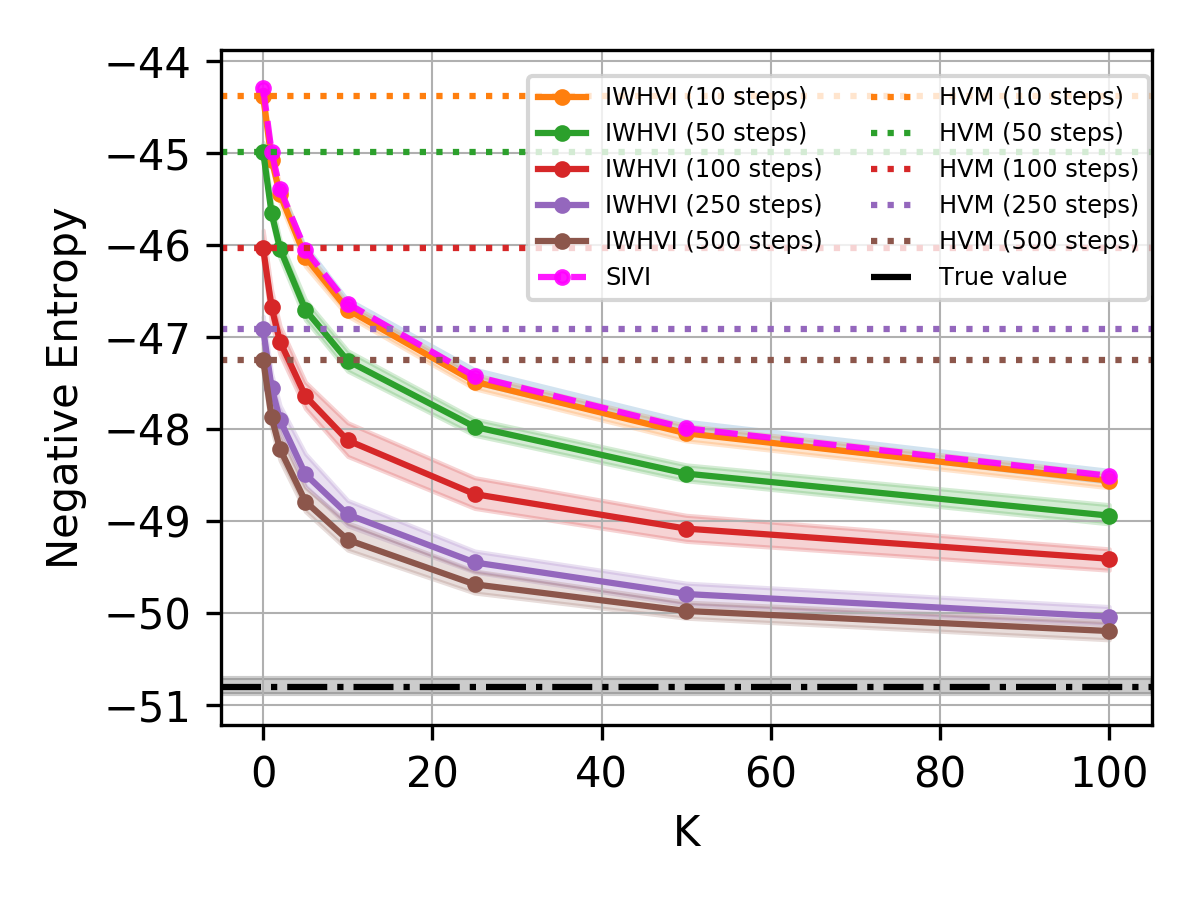
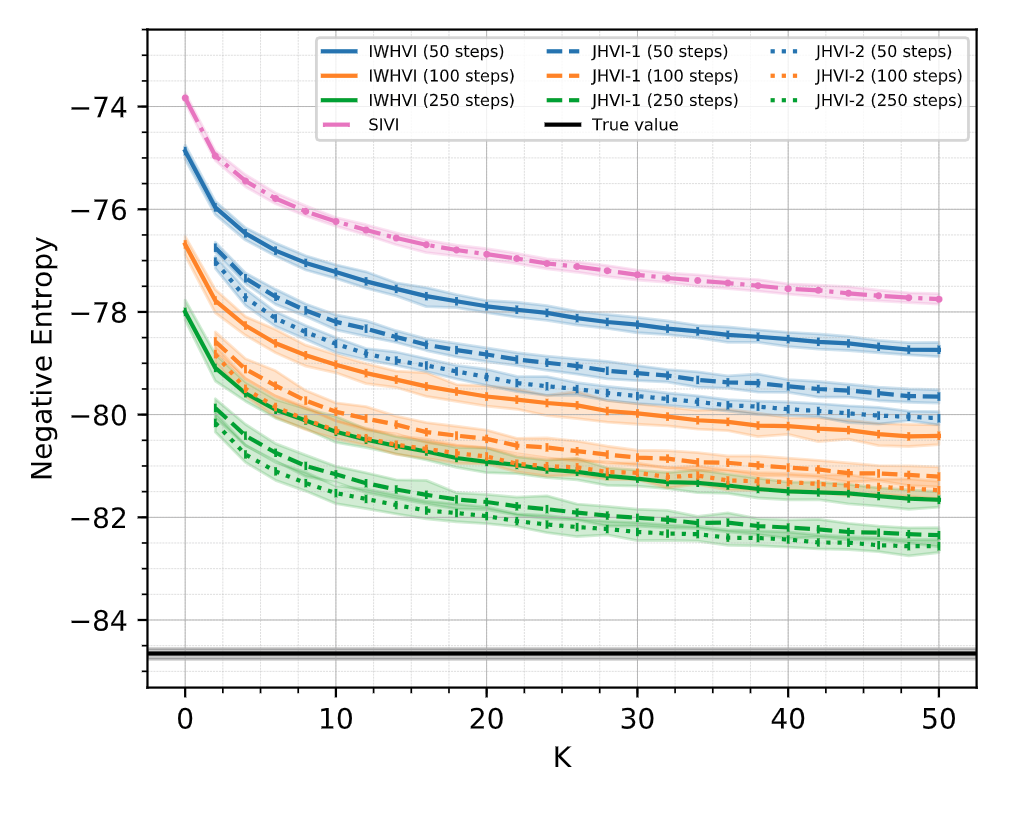
Lets see how our variational upper bound compares with prior work.
Corollary: for the case of two hierarchical distributions \(q(z) = \int q(z, \psi) d\psi \) and \(p(z) = \int p(z, \zeta) d\zeta \), we can give the following multisample variational bounds on KL divergence:
$$ \large D_{KL}(q(z) \mid\mid p(z)) \le \mathbb{E}_{q(z, \psi_0)} \mathbb{E}_{\tau(\psi_{1:K}|z)} \mathbb{E}_{\nu(\zeta_{1:L}|z)} \log \frac{\tfrac{1}{K+1} \sum_{k=0}^K \frac{q(z, \psi_k)}{\tau(\psi_k|z)}}{\frac{1}{L} \sum_{l=1}^L \frac{p(z, \zeta_l)}{\nu(\zeta_l|z)} } $$
$$ \large D_{KL}(q(z) \mid\mid p(z)) \ge \mathbb{E}_{q(z)} \mathbb{E}_{\tau(\psi_{1:K}|z)} \mathbb{E}_{p(\zeta_0|z)} \mathbb{E}_{\nu(\zeta_{1:L}|z)} \log \frac{\tfrac{1}{K} \sum_{k=1}^K \frac{q(z, \psi_k)}{\tau(\psi_k|z)}}{\frac{1}{L+1} \sum_{l=0}^L \frac{p(z, \zeta_l)}{\nu(\zeta_l|z)} } $$
Where \(\tau(\psi|z)\) and \(\nu(\zeta|z)\) are variational approximations to \(q(\psi|z)\) and \(p(\zeta|z)\), correspondingly
Note: actually, variational distributions in the lower and upper bounds optimize different divergences, thus technically they should be different
| Method | MNIST | OMNIGLOT |
|---|---|---|
| AVB+AC | −83.7 ± 0.3 | — |
| IWHVI | −83.9 ± 0.1 | −104.8 ± 0.1 |
| SIVI | −84.4 ± 0.1 | −105.7 ± 0.1 |
| HVM | −84.9 ± 0.1 | −105.8 ± 0.1 |
| VAE+RealNVP | −84.8 ± 0.1 | −106.0 ± 0.1 |
| VAE+IAF | −84.9 ± 0.1 | −107.0 ± 0.1 |
| VAE | −85.0 ± 0.1 | −106.6 ± 0.1 |
Test log-likelihood on dynamically binarized MNIST and OMNIGLOT with 2 std. interval
By Artëm Sobolev




