Nearly Optimal Register Allocation using PBQP
New register Allocator
for
Nvidia Compiler
-
Modelling Irregular Architecture
-
FP 16, 32, 64 and vector registers
-
-
Improving Runtime Performance
Terminologies
- Virtual Register
-
Mapping Vreg to
- Physical Register
- Spill
- Cost Vector
- Cost Matrix
- FP 16, 32, 64
- Vector
- Interference graph
1) INITIALIZE VIRTUAL REGISTERS
-
Data Structure
-
Array
-
-
initialize Cost Vector
-
How does Constraints affects Cost vector?
2) Populate Cost Matrix
- For each edge in graph
- uses Cost vectors of Source and Destination
- What is Global Cost Matrix ?
- Why to use ?
- Data Structure
- 2D array for storing Cost matrix for each edge
- GCM for fast Retrieval.
3) Reduce Graph
-
What is reduce graph ?
-
reduce1, reduce2, reduceN
-
-
Data Structure
-
Singly Linked List for each Degree
-
Why to go for Separate Lists ?
-
-
Populate virtual registers in appropriate Degree List
-
Add Vector Constraints
-
While No DegreeList in Empty
-
Perform reduce1()
-
Perform reduce2()
-
Perform reduceN()
-
-
Propagate Solution
Reduce 1
- For Adjacent Y of X
- Y.CostVector += X.CostVector
Reduce 2

Reduce N
- Called when degree > 2
-
For i = 0 to |cx|
-
For node y in adjacent node(x)
- cy(i) += min( Cxy(i,:) + cy)
-
For node y in adjacent node(x)
Propagate Solution
Naive
-
For each Node X in degree0 List
- X.registerAssignment = minIndex(X.CostVector)
-
For each Adjacent Y of X
- Y.CostVector[X.registerAssignment] = INFINITY
Minima Based
-
For each Node X in degree0 List
- tempCostVector = X.CostVector
- For each Adjacent Y of X
- minY= minIndex(Y.CostVector)
- From Cost Matrix of X and Y
- Add minY 'th Column to tempCostVector
- X.registerAssignment = minIndex(tempCostVecor)
-
For each Adjacent Y of X
- Y.CostVector[X.registerAssignment] = INFINITY
Results
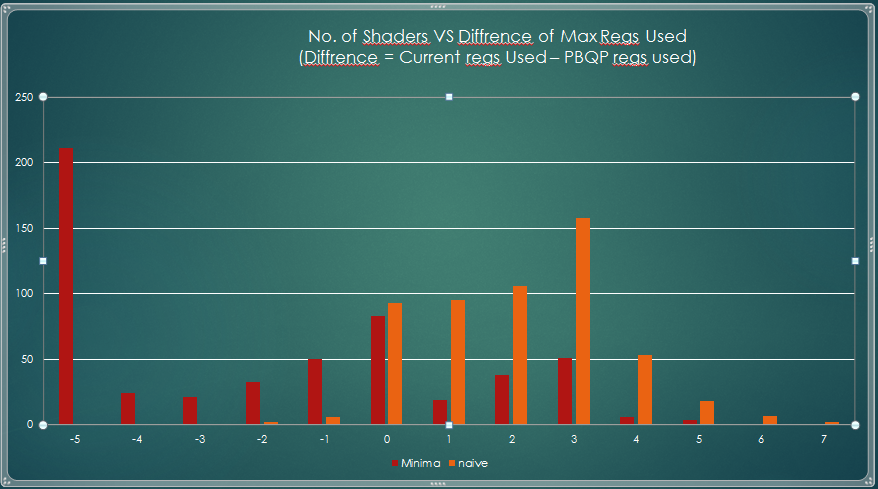
Highest Register used
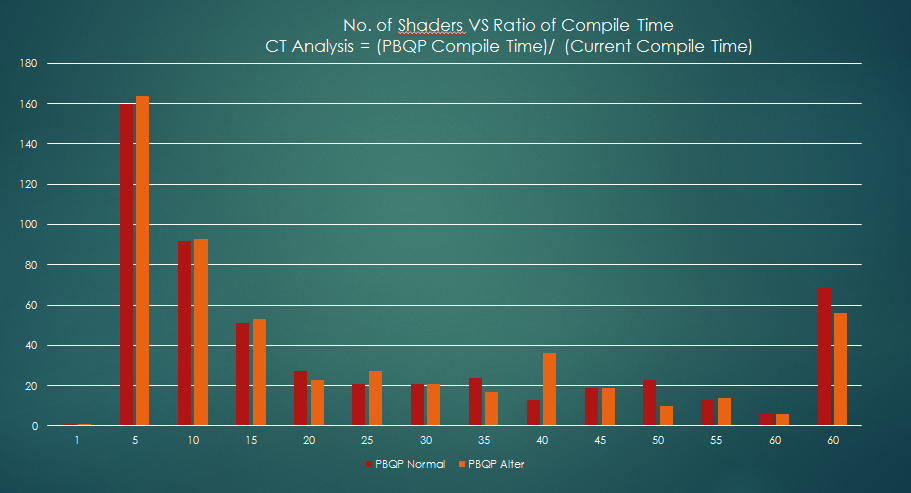
Compile Time
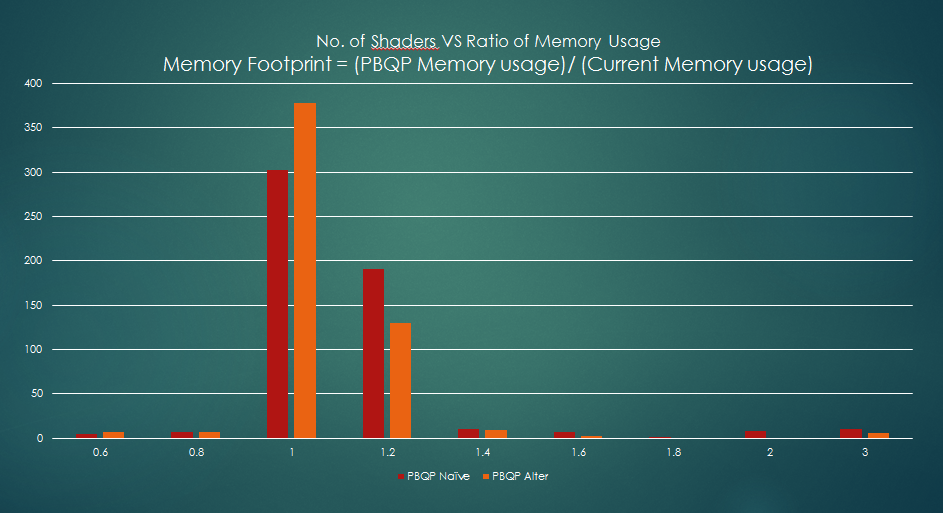
Memory Usage
THANK YOU
BHUSHAN SONAWANE
SIDDHARTH KUMAR
Internal guide: Prof. M. V. Kulkarni
External guide: Shekhar Divekar
Understanding Algorithm And NVIDIA Compiler Infrastructure
Modelling Vector Instructions
Modelling FP16 and 64 bit registers
Implementation of Basic Register Allocator for sm50
Perf Tuning
What Next
Nearly Optimal Register Allocation using PBQP
By Bhushan Sonawane
Nearly Optimal Register Allocation using PBQP
Nvidia internship project presentation



