Statistics in action
Insights from a bioinformatician in a public health department
Dec. 15th 2025
Guillaume DELEVOYE
Postdoc researcher, Karlstad University, Public health department
guillaume.delevoye@kau.se



Today's talk
Not a course
No grade, no evaluation
- What's research like ?
- What do public health researchers do ?
- Perspectives after the bachelor's degree ?
- Cool stuff in statistics ?
- Discuss together
Objectives :
About me
Postdoc researcher, bioinformatician
Public health department, KAU
2.000 pairs : pregnant woman + child
Study the impact of endocrine disruptors on children's health
My focus/background/expertise :
- Epigenetics
- DNA methylation data

What's a bioinformatician
A bioinformatician is a Jack-of-all-trades
- Not a medical doctor
- Not a geneticisit
- Not a software developer
- Not a statistician
- Not a chemist, or physicist
- Not an AI scientist
- Not a web designer
- Not an expert in IT and network infrastructure

... But must have some knowledge, in all of the above
How can you be knowledgeable on so many things ?
> You can't
- Bioinformatics, like stastistics, is a very humbling field
- You feel dumb, every day, several times a day
- The imposteur syndrome is real !
- You quickly learn to be brutally honest about your (relative) ignorance
Being curious and self-taught is key








Despite being very inter-disciplinary, bioinformatics is still a lot about statistics
Like public health
Learning statistics is not fun
- Spending years on learning how to read is not fun
- But reading books is fun !
- But reading books is fun !
- Spending years on learning a music instrument is not fun
-
Playing with your friends is fun !
-
Playing with your friends is fun !
- Learning statistics for years is hard, and not fun
- Making discoveries with statistics is fun !



Note
- I used to hate statistics
- Always failed statistics as a student
- I finished my bachelor without validating my statistics module
... Yet here I am.
Because, actually, it is fun !
""The best thing about being a statistician is that you get to play in everyone's backyard""

John Tukey (1915-2000)
- Fast-Fourrier Transform
- Box plots
- Tukey's test
- ANOVA
- "bit"
- "Software"
Other contributions :
Defense industry, telecommunications, sexual orientation research, Ozone layer damages, TV polls, analysis of elections, Education, Printer market, Pharmacy, ...
The better you are at statistics, the more fun you'll have in inter-disciplinary research
-
There is always something you know that your colleagues don't !
- And vice-versa.
- Including other bioinformaticians !
- It's a reciprocally enriching exchange !
You will always pale in comparison to an expert
Every bioinformatician is vastly self-taught :
But,

... And that's kind of OK actually
Statistics in action
Some of my past projects
Example n°1

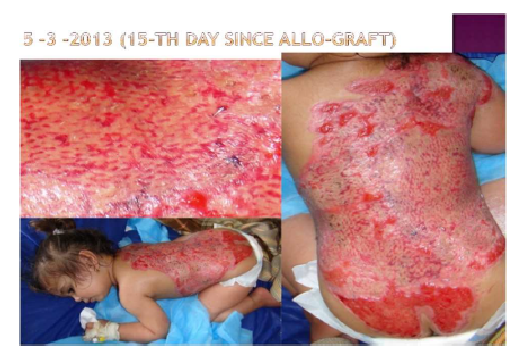
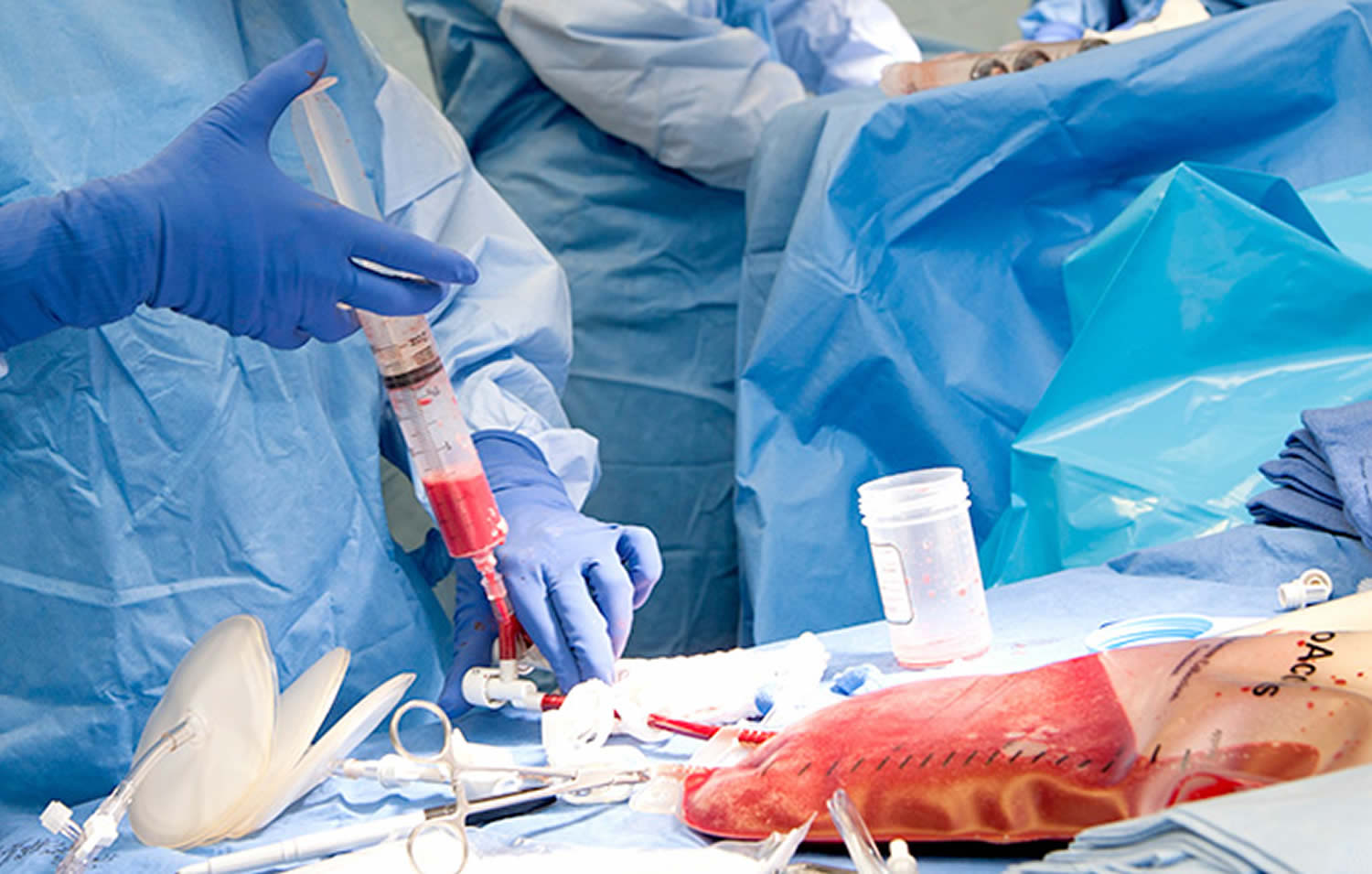
Developping a machine-learning web app to estimate the donor's compatibility in a blood marrow transplant
- Very advanced medical topic
- Can require very advanced genetic analysis
- Advanced machine-learning methods
There is so much to learn everyday !
Ex : Negative ages ?

Example of deliverable : Predict mortality at 5 year using machine-learning
Here : Random forest
Example of deliverable : Interpretable decision trees
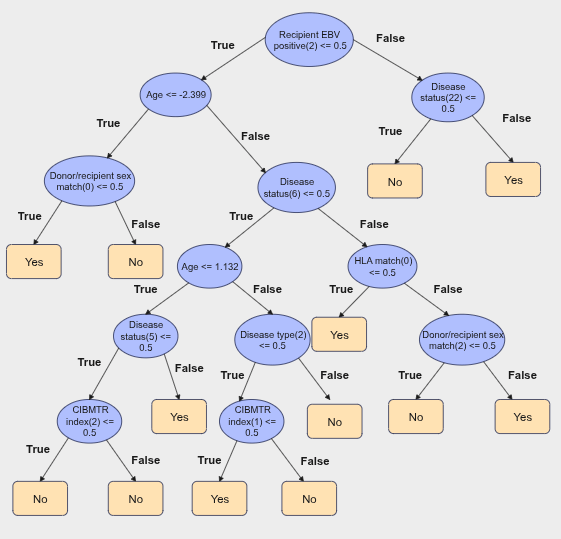
- Often, bioinformaticians have other missions as well
- Develop a web app
- Deploy it / Host it
- Setup the DNS, HTTPS, etc
- Maintain the server online
- Handle its cybersecurity
- Making sure the encryption is correct
- Fix the bugs
- Update drivers correctly
- Write documentations for the medical staff
- etc.
The IT-side of the job

Example : doi: 10.1038/bmt.2016.162.
The domain-knowledge is key !
But ! It is impossible to start working on bone-marrow transplant without basic knowledge in :
- Hematology
- Immunology
- Genetics
- Oncology
- ...
- Medical doctors often have very limited time, and their meeting are often interrupted by emergencies
- You must come prepared to the meeting !
- The more you know on the topic, the better the interaction with the medical staff
A priori it's just statistics like any other
Example n°2
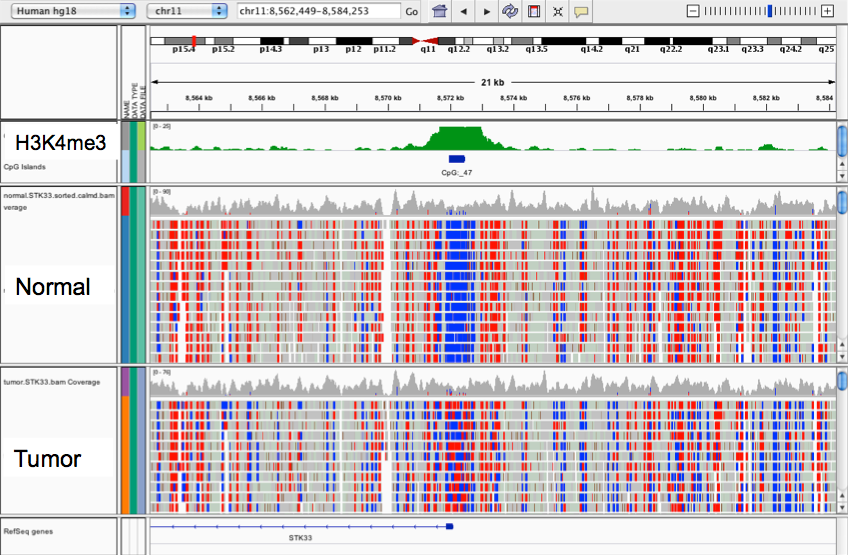
Looking for DNA-methylation markers of Endocrine Disruptors in children's blood
Example of deliverable : Quality control, outlier identification
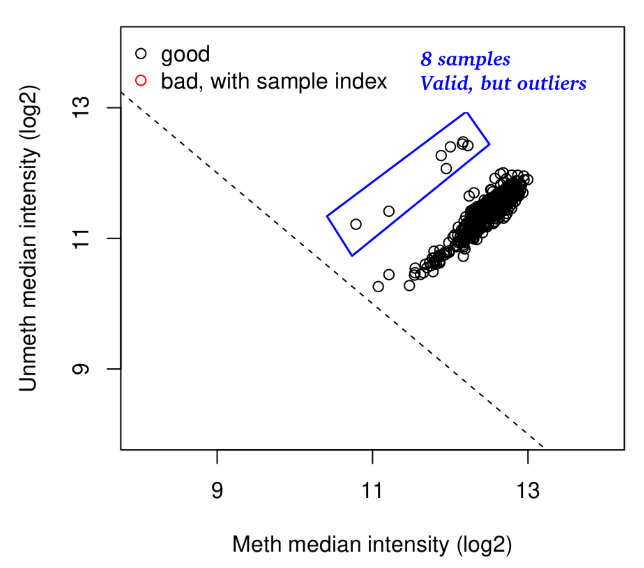
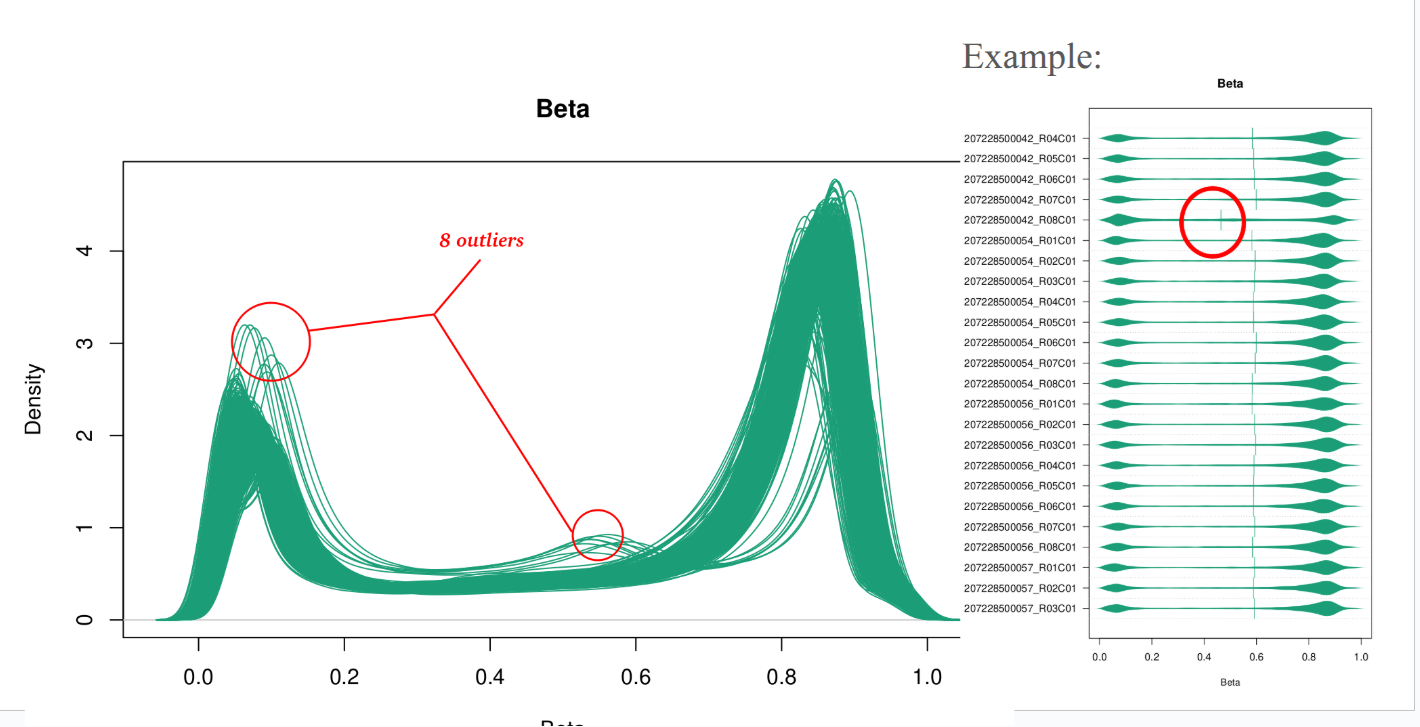
Outlier detection
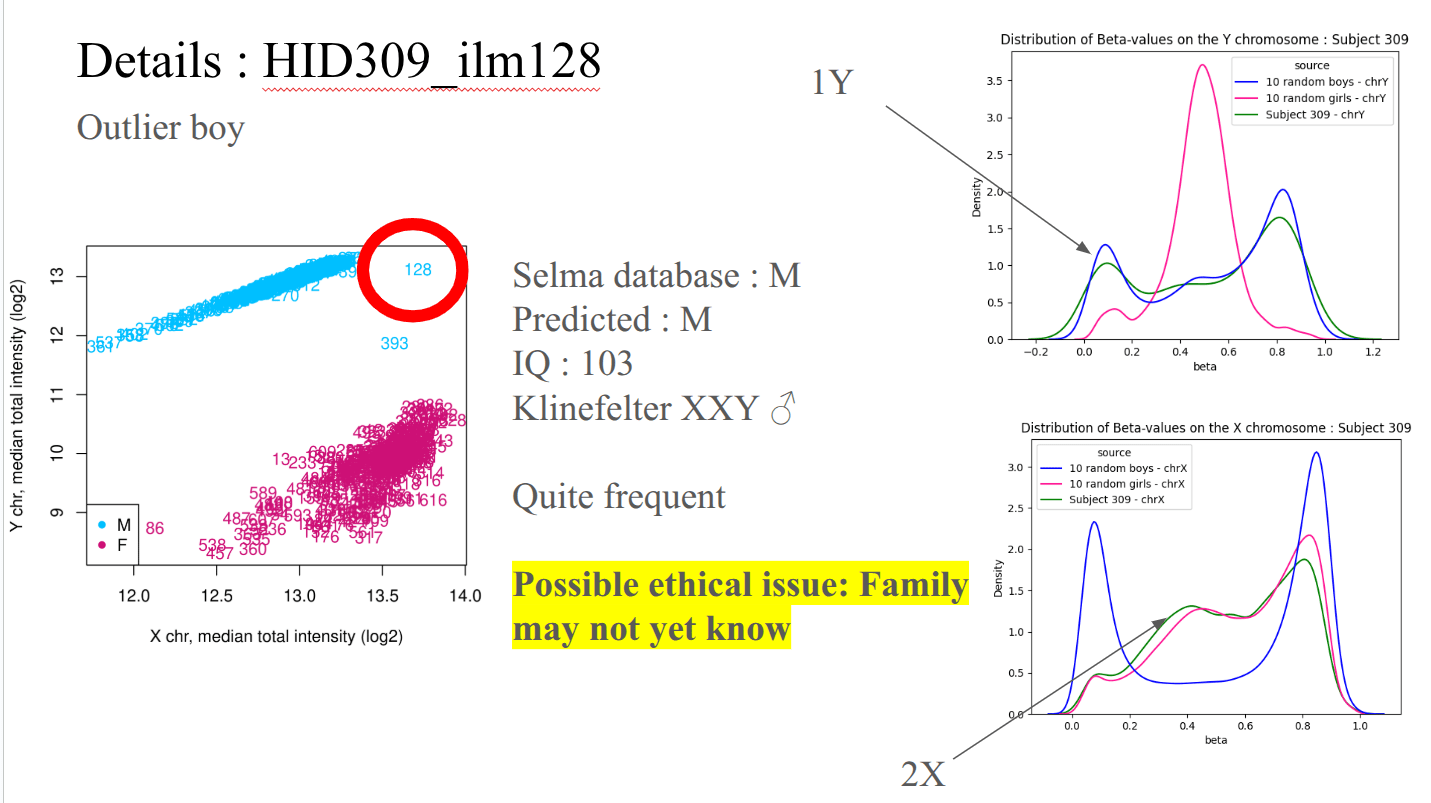
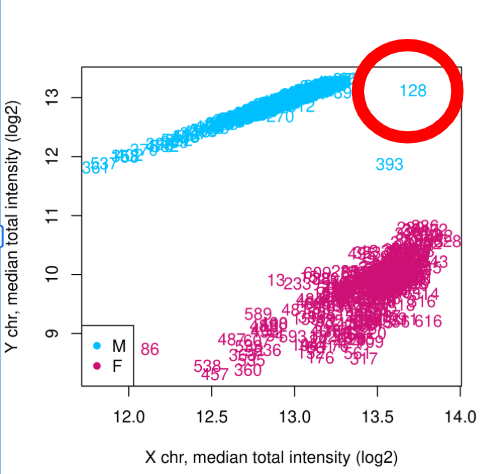
Ex : Identifying intersex participant in SELMA data
Domain-knowledge is key
Example of deliverable : Visualizing exposure to multiple chemicals, in 2D
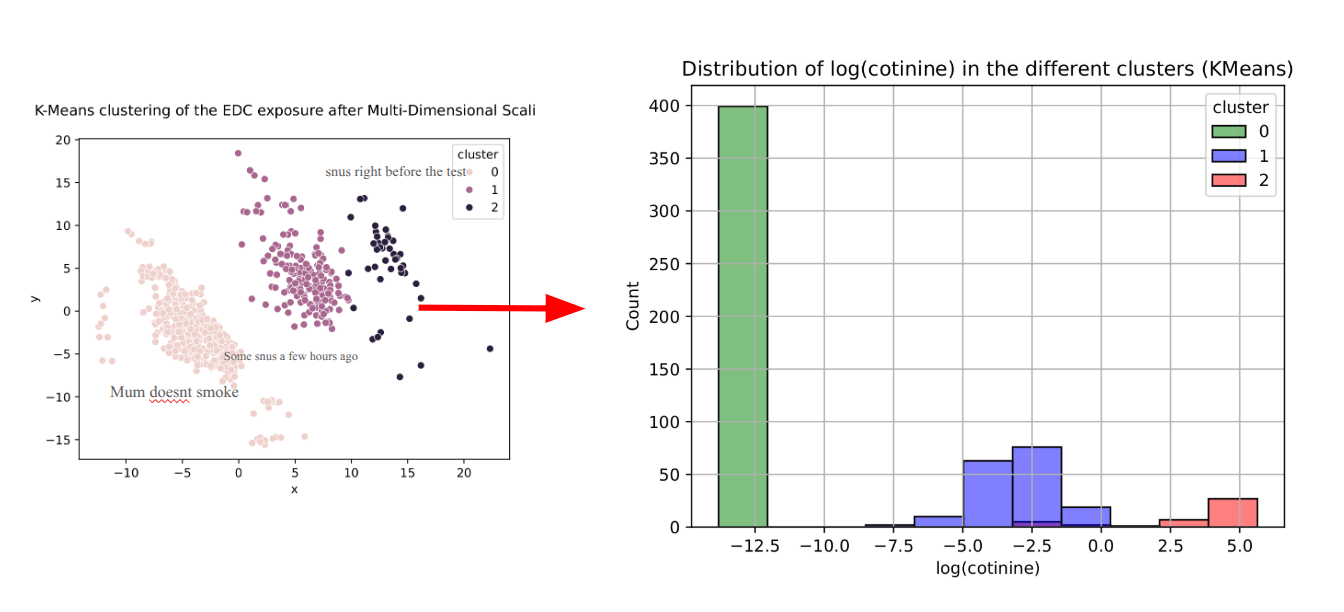
Example of deliverable :
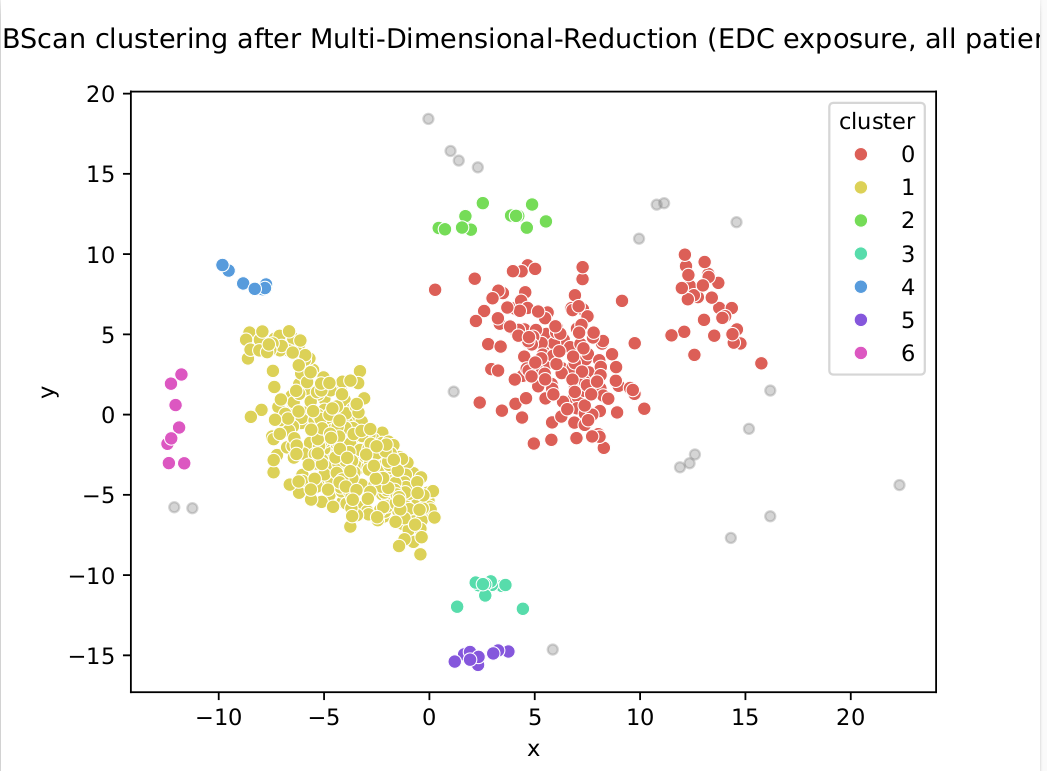
DBScan clustering, after projection in 2D of all the chemical exposures (SELMA data)
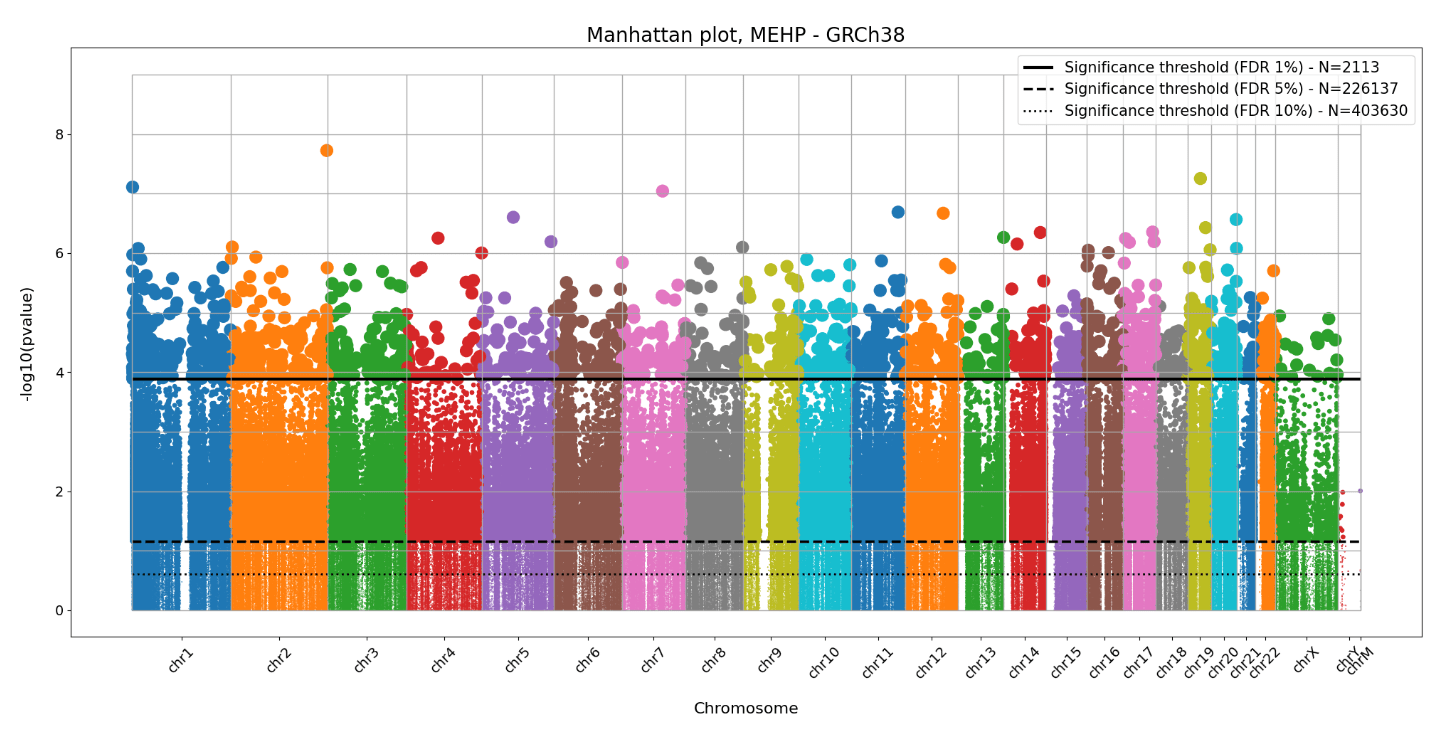
Positions in the human genome where DNA methylation of blood cells is affected by phtalates
False Discovery Rate control ...
Deconvolution of gaussian data
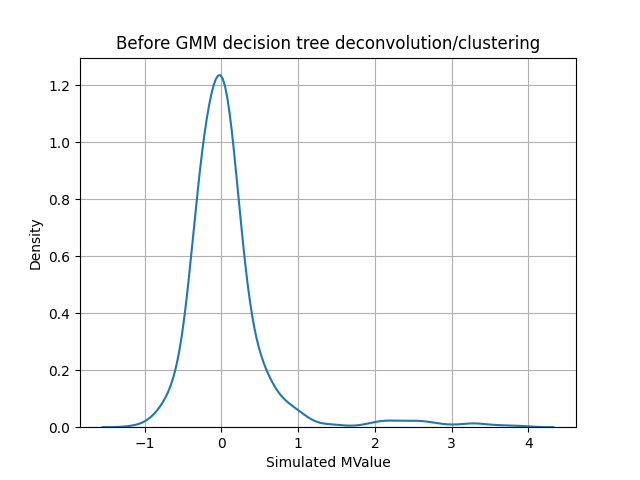
After deconvolution
Example n°3
Discordant diagnosis test among couples
Problematic
- Take a COVID-19 test
- Sensitivity: Se = 99%
- Specificity: Sp = 99%
- Test 1.000.000 couples
- 979.000 couples are D-/D-
- 1.000 couples are D+/D+
- 20.000 couples are D+/D-
... But the test is not perfect !
Se = Sp = 99%
Seamingly logical conclusion :
COVID-19 is not very transmissible ?!
Update quarantine guidelines ?!

Let's do the maths ! (1/2)
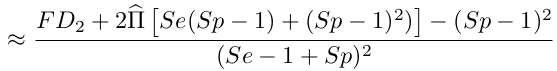
$$P(+/+)$$
Let
$$FD_2$$
is the observed proportion of +/+
Where
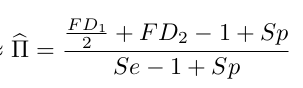
$$FD_1$$
is the observed proportion of -/+
The unbiased fraction of truly +/+ couples is then :
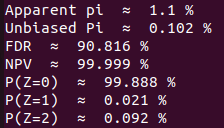
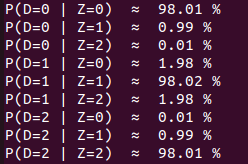
But : Almost 100% of the couples detected D+/D- are actually COVID-/COVID- !
979.000 couples are D-/D-
1.000 couples are D+/D+
20.000 couples are D+/D-
Let's do the maths ! (2/2)
Reason = Imperfect test (Se = 99%, Sp = 99%)
Applications in other fields
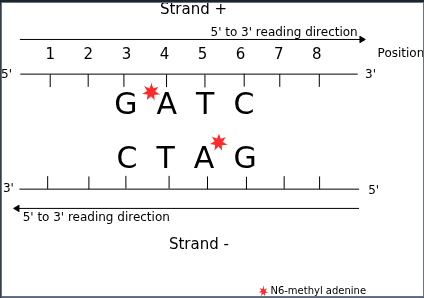
Ex:
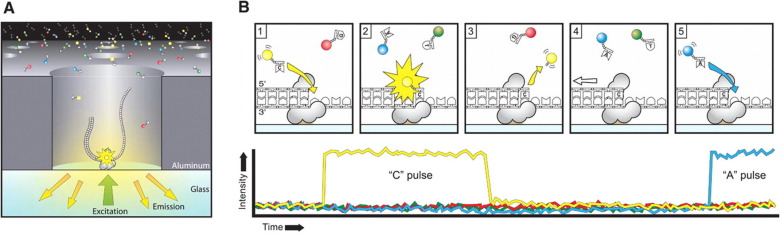
Detecting DNA methylation in palindromic motifs
Methylated adenines can also be called with Se = 99% and Sp = 99%, like our patients before
Since there are two adenines in the couple, same logic applies
Example n°4
A web app to study DNA methylation in ciliates


As part of my PhD
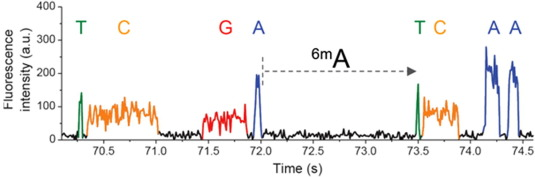
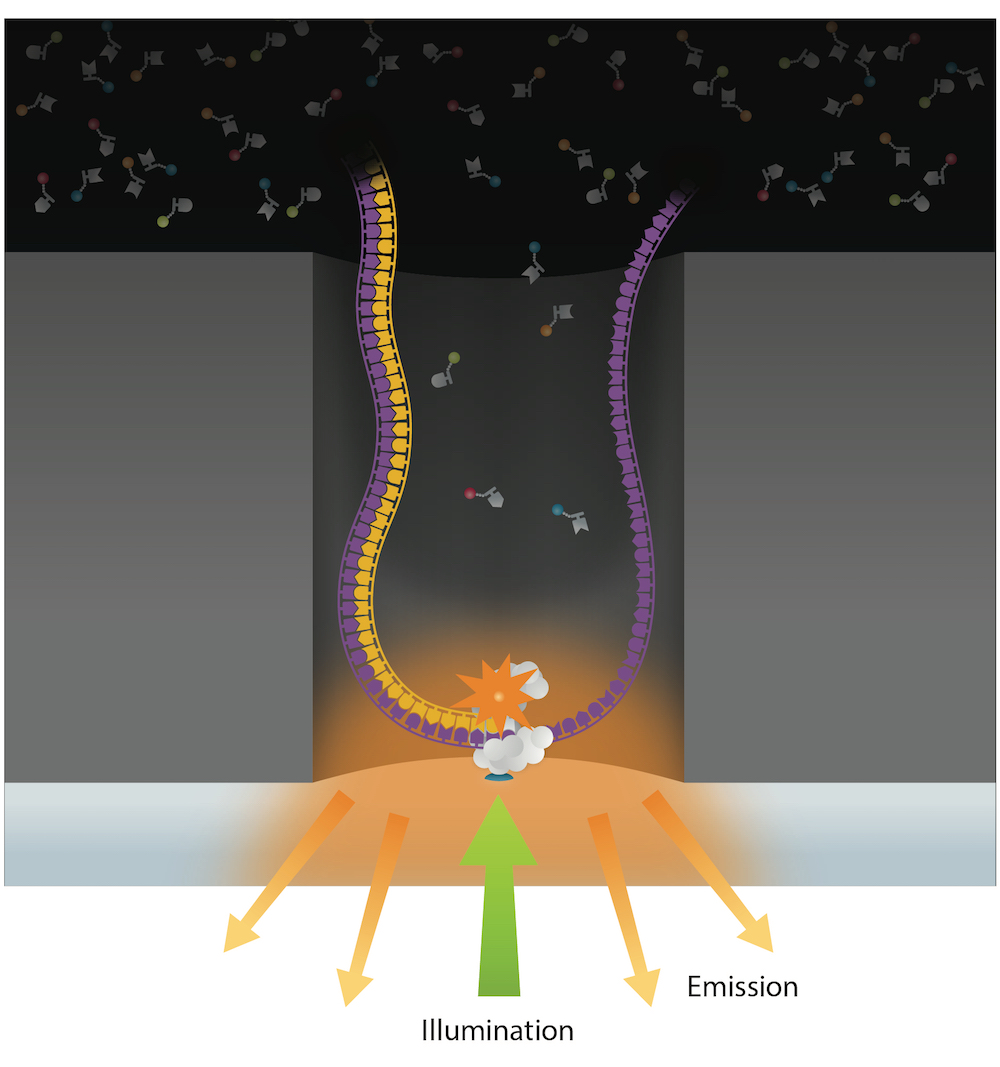
Each individual DNA molecule is immobilized and replicated by a DNA polymerase
Detecting DNA methylation
Nucleotide context (-3/+8nt)
Kinetic signatures
Depends on
DNA modifications
Detecting DNA methylation
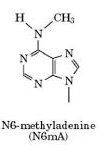
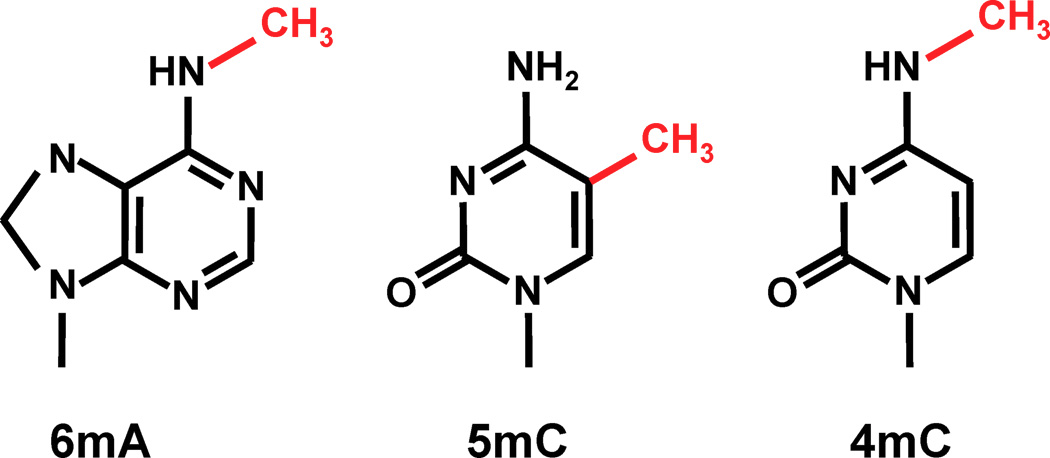
Adenine
6mA
ln(ipdRatio) ~ N(0,1)
log(ipdRatio)
1. Normalized by speed in unmethylated DNA :
2. Then : Usual parametric test
$$ipdRatio= \frac{MeanIPD_{experience}}{unmethylated\ control}$$
Example of deliverable : Web app

Exemple of deliverable :
An analysis package coded in python (several thousands of liness)
Exemple of deliverable :
4 years of extremely hard work for a harshly non-significant p-value
We can never exclude the hypothesis that 6mA comes from the MAC
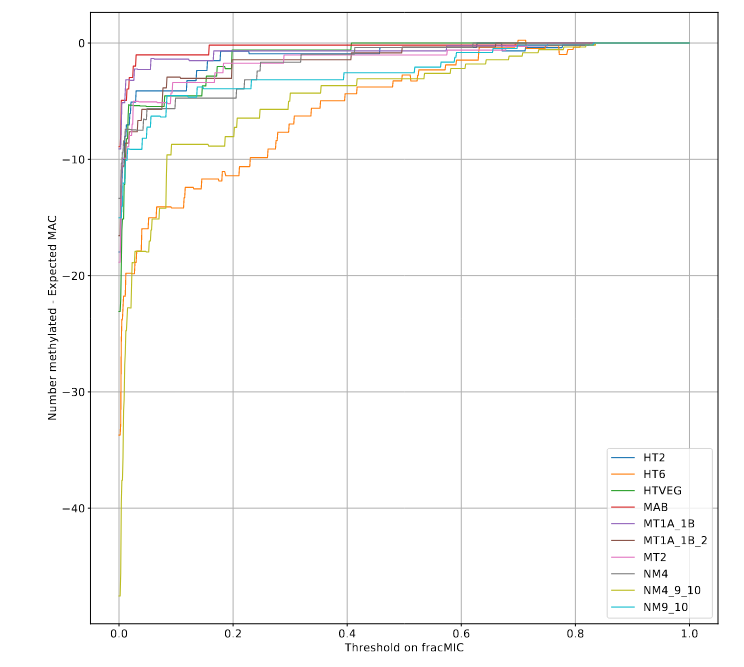
p ~ 0.99
Conclusion
In a nutshell :
Learn
Teach
Understand
collaborators
Communicate
Animate meeting,
work groups,
workshops
Be curious
Sometimes be diplomat
Understand training & cultural differences
Share data, methods, results
Sometimes stand your ground
- Bioinformaticians and statisticians often work in very interactive groups
- Social skills are extremely valued
You need to
How does one become a bioinformatician ?

> You don't
Almost 100% of bioinformaticians have a previous training in a different field :
Biology, medicine, chemistry, physics, public health, statistics, programmer, data scientist...
>You< could become a bioinformatician !
Example of background :
- 2017: Pharmacy (Lille)


-
2022: PhD degree at ENS Paris (bioinformatics)


-
2018: MSc Bioinformatics - Paris Diderot

- 2023 : Karlstad University, Public Health
About competition
- Academic and medical research can be ridiculously competitive
- Pressure to publish is somewhat lower for bioinformaticians
- You're much needed anyway
- Your skills are rare / niche
- Permanent positions are atteignable
- This tends to change

You can really play in many people's backyard !
University will teach you only what is extremely basic.
Don't forget to learn also by :
- Reading
- Watching videos
- Making mistakes
- Thinking about it in the shower
- Talking to people
- Inventing new weird methods
- Having fun
One last word

Thanks :)
Important note
I never passed my statistics exams
Not even
Part II / Statistics in action
Text
Current position

What
Code
Stats
Hematology (HSCT)
ML
Ciliates
NGS
Structural biology
Python C++ Bash R

1) Paramecium tetraurelia
3) DNA methylation
4) PacBio sequencing
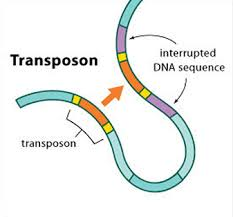
2) Transposable elements / IESs
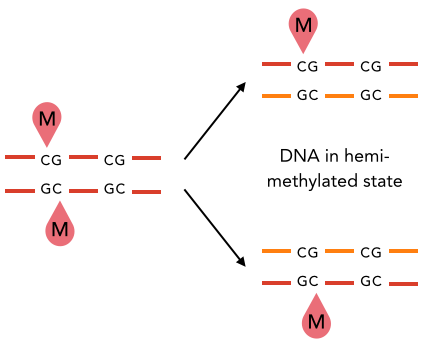
5) hemi-methylation of
palindromic motifs
(AT sites)
Methylase candidates in Paramecium tetraurelia
Candidates identified:
- NM4, NM9, NM10
- Another family: MT1a, MT1b, MT2
2) PacBio sequencing with short inserts | 6mA ++
1) Grouped silencings by sequence homology
PacBio SMRT (short inserts)
Inserts up to 350bp
Sequencing : unique molecule & both strands
Polymerase slowing ~ methylated adenine
The random sampling strategy
- Purify the MIC: Impossible
- Sequencing whole MIC from whole DNA : Impossible
-
Solution: Random sampling
- 1 among 200 molecules
- Not all with cary an IES at all
- ~20 to 100 IES only per experiment
Problem n°2
IESs are sometimes retained in the MAC
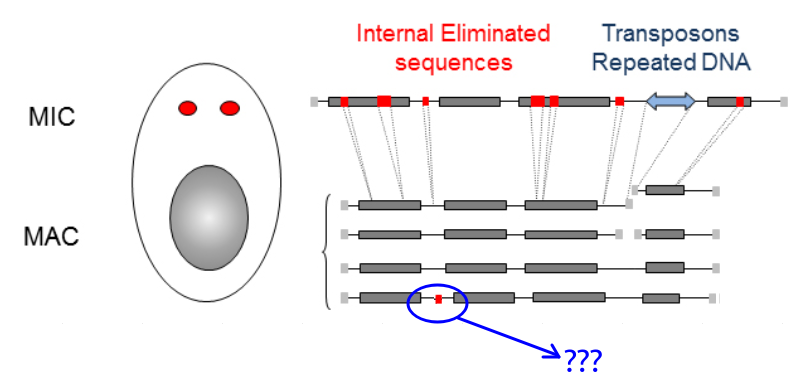
What is P(MIC|IES+) ?
Other analysis challenges
(skipped)
Details that I spare you (but don't hesitate to ask) :
- Random sampling of the MIC
- Sorting MIC and MAC
- Sorting IES specific and MIC non-IES sequences
- Filter IES retention
- Estimate Se and Sp
- Retro-ingineering PacBio's formats
- Recoding parts of the softwares for single molecules
- etc.

Detecting n6mA
Imperfect detections
No scientific method is perfectly reliable
In our case:
- Sensitivity = P(D | M) > 92%
- Specificity = P(ND | NM) > 99.8%
> Expect False Positives and False Negatives
Imperfect detections (2/2)
- Sensitivity = P(D | M) > 92%
- Specificity = P(ND | NM) > 99.8%
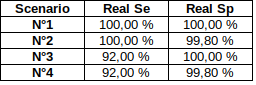
We can use 4 extreme scenarii :
... And see what is consistent no matter the scenario we place ourselves into
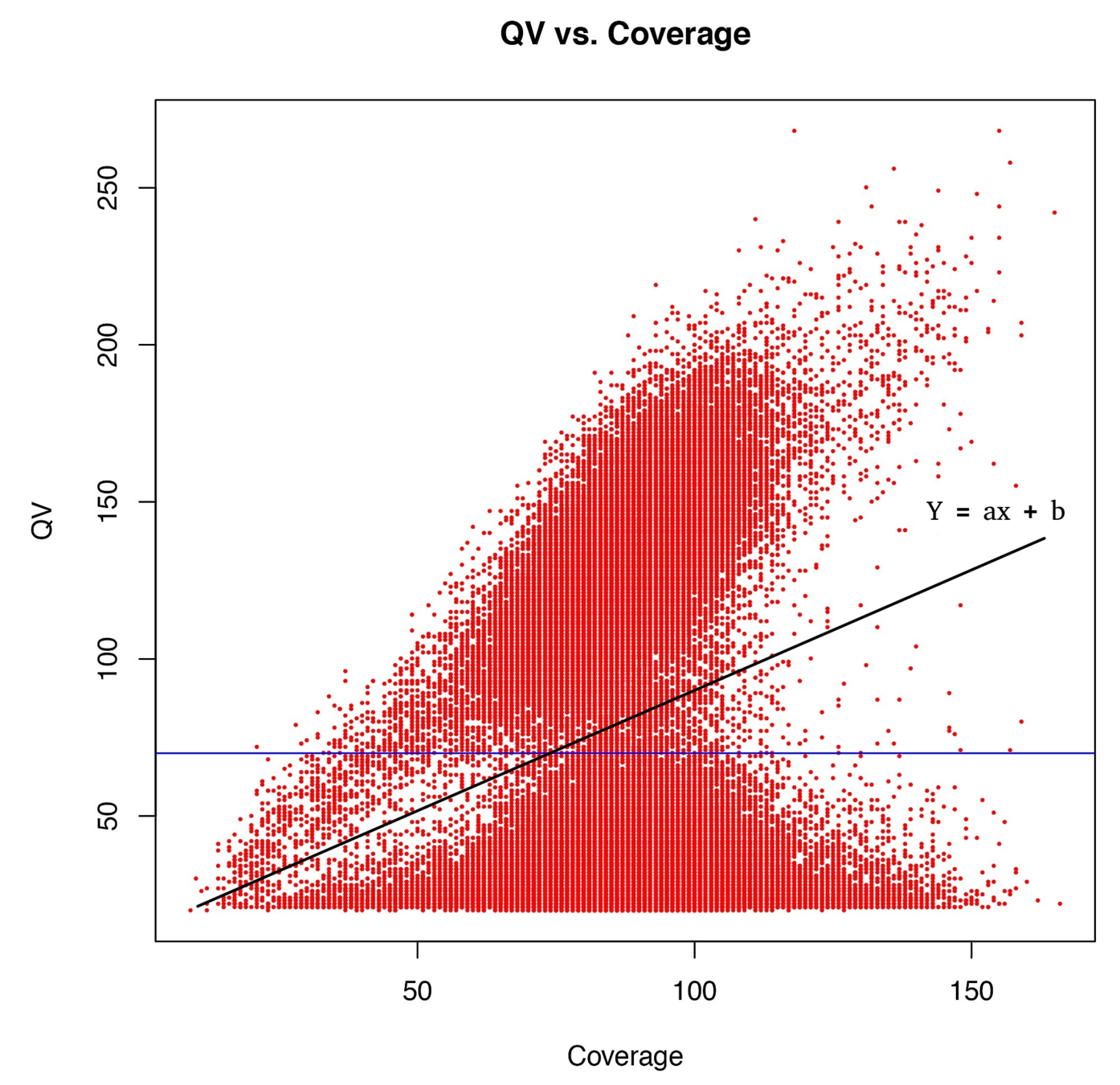
Finding unbiased estimators for and FDR
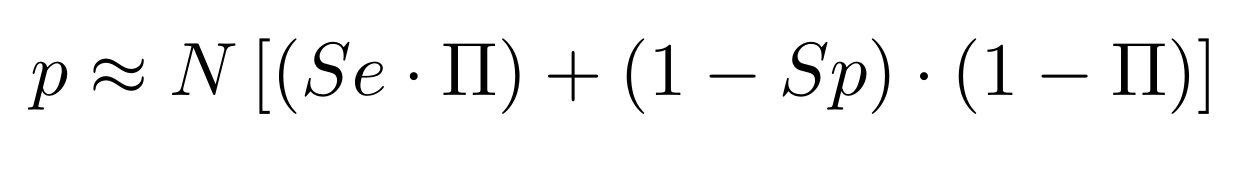
If p number of positive detections among N tests:
p = FP + TP
$$\pi$$
So,
Which means
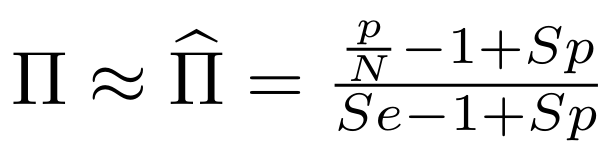
with fraction of 6mA
$$\pi =$$
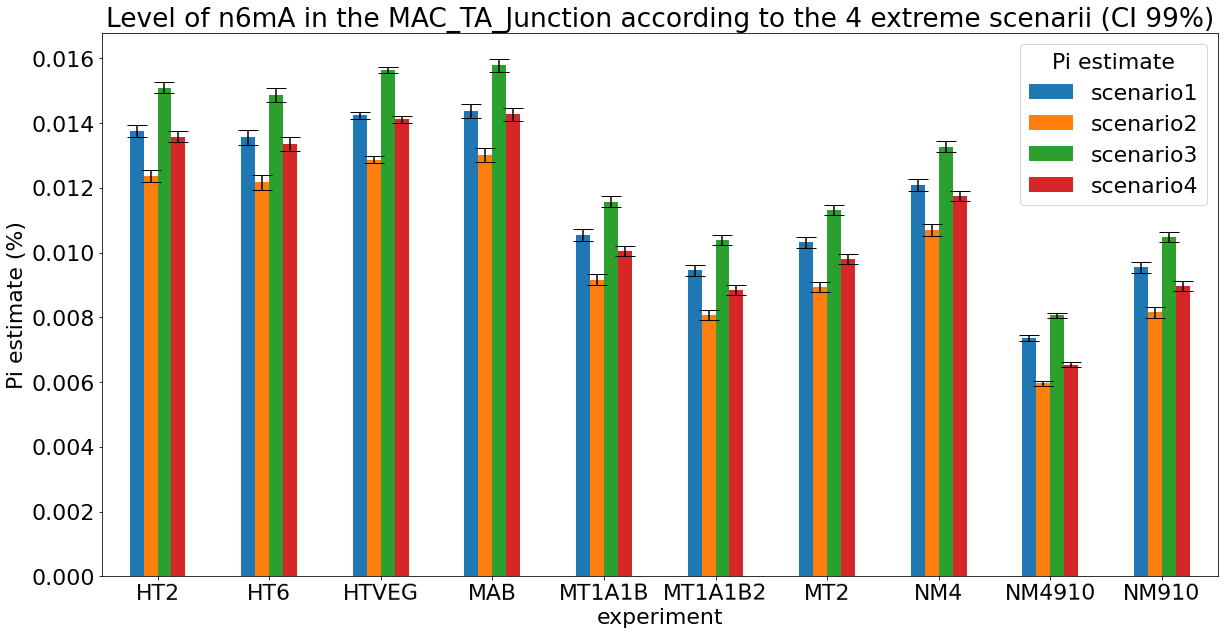
Debiased levels of m6A in the MAC
> 95% n6mA are located in AT sites
DNA n6-mA around/in the IESs
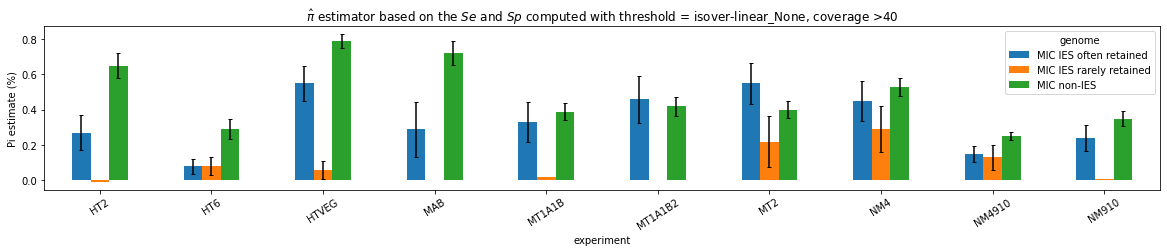
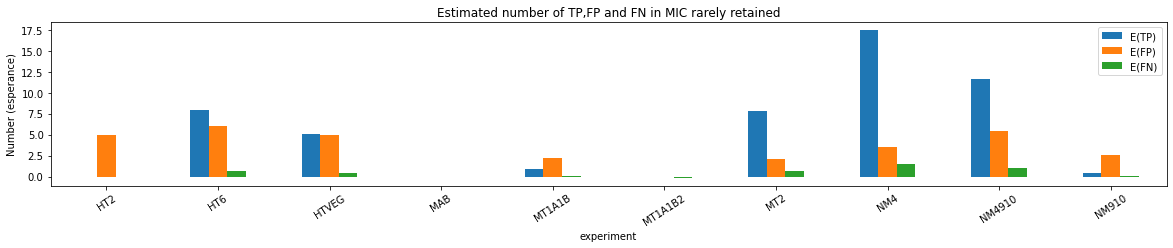
Results
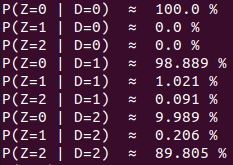
Methodological development to correct hemi-methylation detection
Let FD1 and FD2 be resp:
- Fraction of AT sites detected hemi-methylated
-
Fraction of AT sites detected symmetrically methylated
PZ0, PZ1, PZ2: unbiased estimators of non, hémi, symetrically methylated AT sites
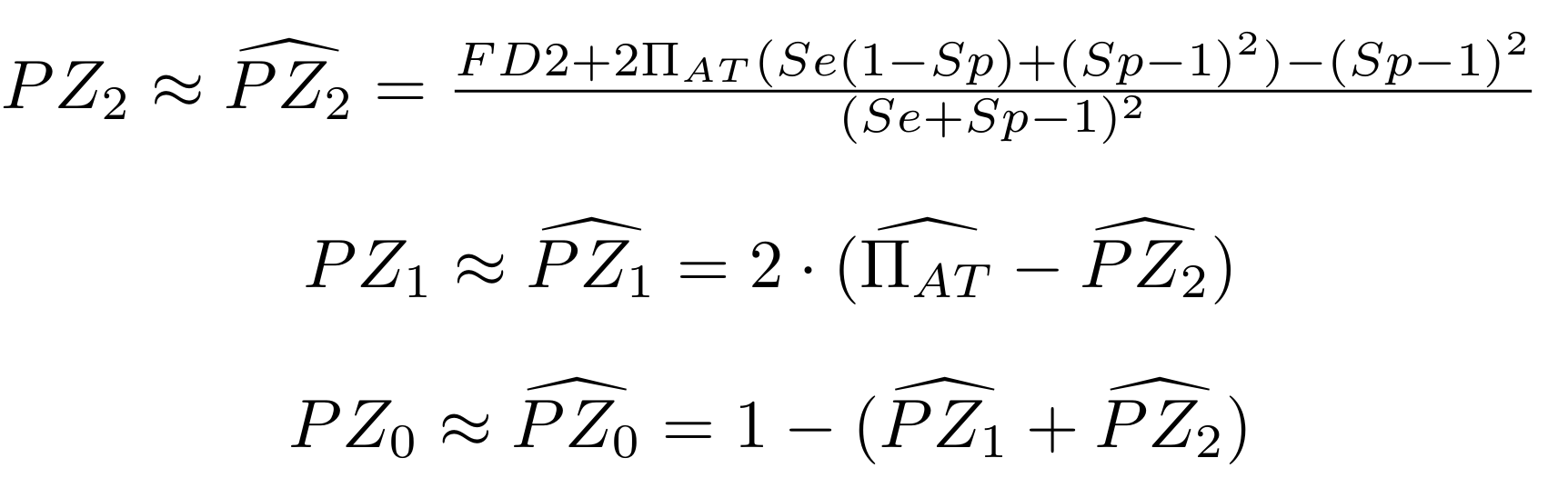
Then:
With
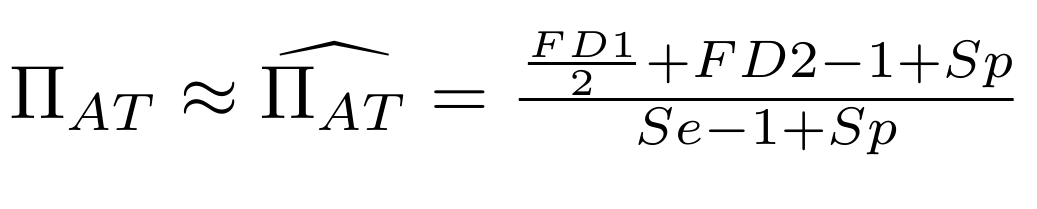
Debiased Hemi-methylation in MAC

2) Transcient in the new forming MAC
1) Constant pattern in the MIC
Transcient ?
Our hypothesis:
Analysis showed that:
~2.5% of n6mA in Paramecium (MIC) : Cummings 1974
?
> Actually way lower (if any)
> Unexpectedly, NM and MT proteins play a whole another role in the MAC,
not the MIC
Conclusion
IGEM2014
MT and NM families :
In the MAC
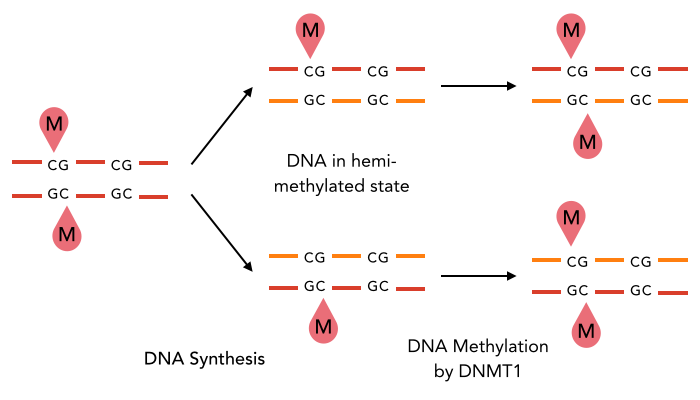
Convertase activity DNMT1-like
But: Hemi-methylated AT sites kept after many mitosis
New hypothesis:
Symmetrical methylation of AT sites = Mitotic clock or maturity indicator for the cell to be allowed to go enter meiosis
A bit more about me...
I don't like

Red socks

Fun

Windows 10 update of May 2021
Some keywords for my PhD
1) Paramecium tetraurelia
3) DNA methylation
4) PacBio sequencing
2) Transposable elements / IESs
5) hemi-methylation of
palindromic motifs
(AT sites)
P. tetraurelia
Unicellular eucaryote with 3 nuclei:
- 1xMAC nucleus (up to 800n)
- 2xMIC nuclei (2n)
DNA ratio: 1 MIC for 200 MAC
The difference ?
MAC genome compared to MIC =
- Amplified+++
- Free from TEs
- Transcriptionnally active
- Not transmitted to progeny
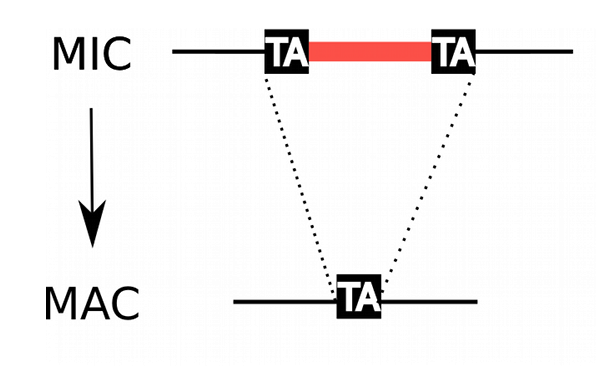
Genome invaders in Paramecium tetraurelia
In the MIC:
- 45.000 unique sequences
- Small (<27bp), Non-coding
- Lots present in the CDS
- Remnants of TE ?
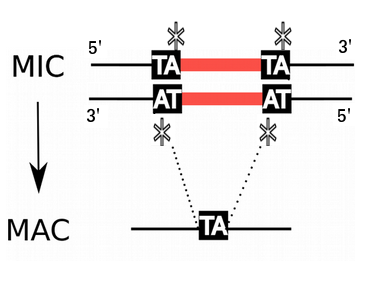
- 100% TA-bounded

--> How ?
Present in the MIC
Absent in the MAC
= Excised generation after generation
2) Transcient in the new forming MAC
1) Constant pattern in the MIC
Transcient ?
Recognition of IESs: Our hypothesis
Our hypothesis:
~2.5% of n6mA in Paramecium (MIC&MAC) : Cummings 1974
Methylase candidates
Candidates:
- NM4, NM9, NM10
- Another family: MT1a, MT1b, MT2
2) PacBio sequencing with short inserts | 6mA ++
1) Grouped silencings by sequence homology
PacBio SMRT principle
Reads up to 80 kbp
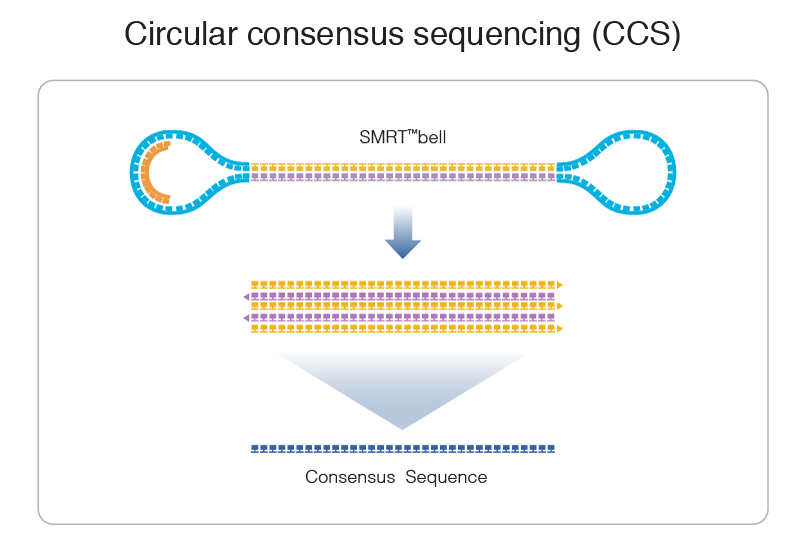
1) Sequencing (unique molecule)
2) High fidelity consensus
3) DNA methylation analysis
What are the results ?
2) Crosstalks in the new forming MAC
1) Constant pattern in the MIC
Transcient ?
Our hypothesis:
Prelimary analysis shows that:
~2.5% of n6mA in Paramecium (MIC&MAC) : Cummings 1974
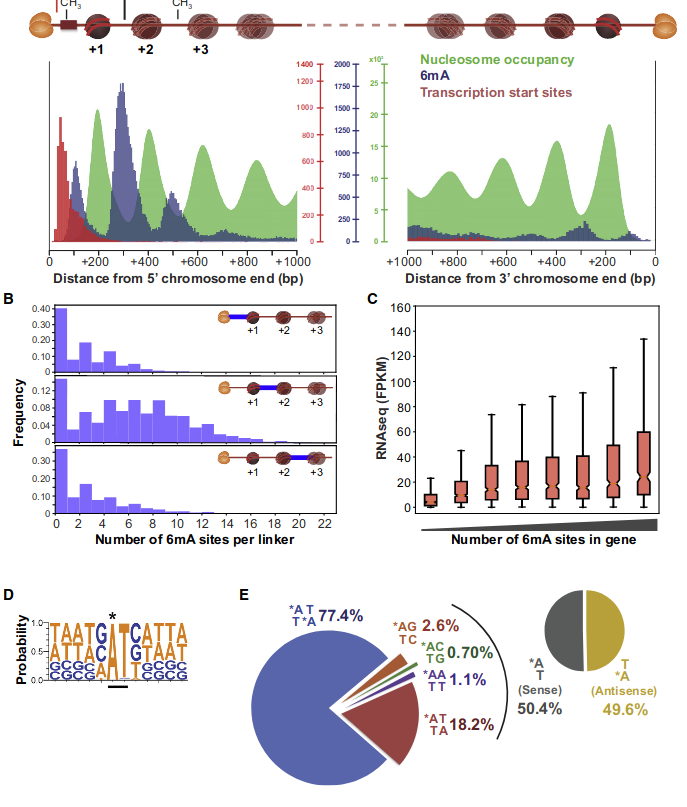
Details invegetative MAC
-
~95% of n6mA locates in AT dinucleotides in the MAC
-
75% of the methylation in an AT dinucleotide is actually symetrically modified
Bulk of methylation:
Total = 1.2 to 1.5% of adenines
0.6% of the adenines outside AT sites:
Now a bit more details...
Imperfect detections
No scientific method is perfectly reliable
- We don't care about Se and Sp
- We care about the fact that eventual mis-estimations of them doesn't really change anything

In our case:
- Sensitivity = P(D | M) > 92%
- Specificity = P(ND | NM) > 99.8%
Finding unbiased estimators for and FDR
If p number of positive detections among N tests:
p = FP + TP
$$\pi$$
So,
Which means
with fraction of 6mA
$$\pi =$$
Debiased levels of m6A in the MAC_TA inserts
Methodological development to correct hemi-methylation detection
Let FD1 and FD2 be resp:
- Fraction of AT sites detected hemi-methylated
-
Fraction of AT sites detected symmetrically methylated
PZ0, PZ1, PZ2: unbiased estimators of non, hémi, symetrically methylated AT sites
Then:
With
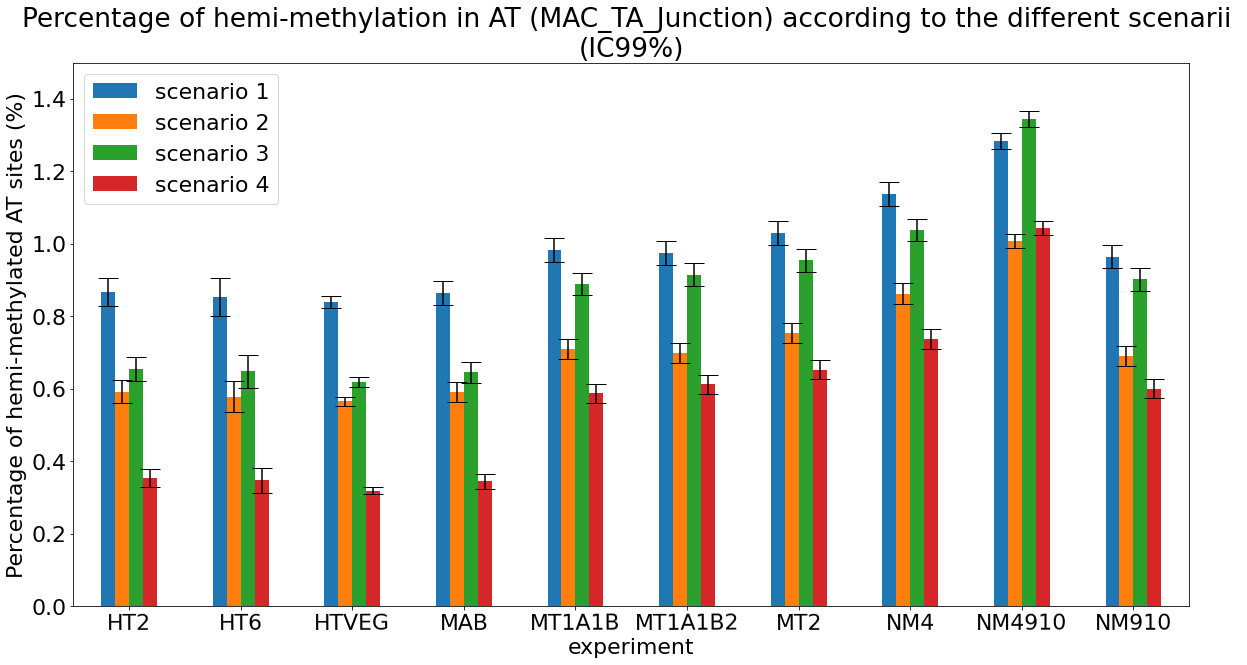
Debiased Hemi-methylation in MAC_TA
Conclusion
- In the MIC:
- Probably no m6A after all
- Hard to imagine a role in TE/IES excision
-
In the MAC
-
Our 6 genes are implied in the bulk of the MAC m6A
- Sym-methylated -> Hemi-methylated
-
MT and NM families: Functional analogs of DNMT1 ?
- Not really: Not kept after replication
-
Lots of questions raised by the MAC methylation:
- TSS ?
- IES excision Junctions ?
- Nucleosome positionning ?
-
Our 6 genes are implied in the bulk of the MAC m6A
-
One important phenotype:
- NM4-9-10 somehow makes the cell unable to go into autogamy
Thanks :)
Role of DNA-6mA in Paramecium tetraurelia




Guillaume DELEVOYE
3rd Year PhD student
Bioinformatics
P. tetraurelia: Genomic architecture
Unicellular eucaryote with 3 nuclei:
-
2xMIC nuclei (2n)
- Germline nucleus
-
Contains: TE & IES
- No transcription outside meiosis
-
1xMAC nucleus (up to 800n)
- Somatic nucleus
- Amplified and "fixed" version of the MIC
- Free from TE and IES
- Transcriptionnally active
DNA ratio: 1 MIC for 200 MAC
+ DIfficult to purify the MIC DNA
Profiling the IESs
- Non-coding
- Excised after sexual processes
- Remnant of TE ?
- Most recent IES are very short (< 27bp), and are the majority of IESs
45.000 Unique sequences
How are IESs recognized ?
(1/2)
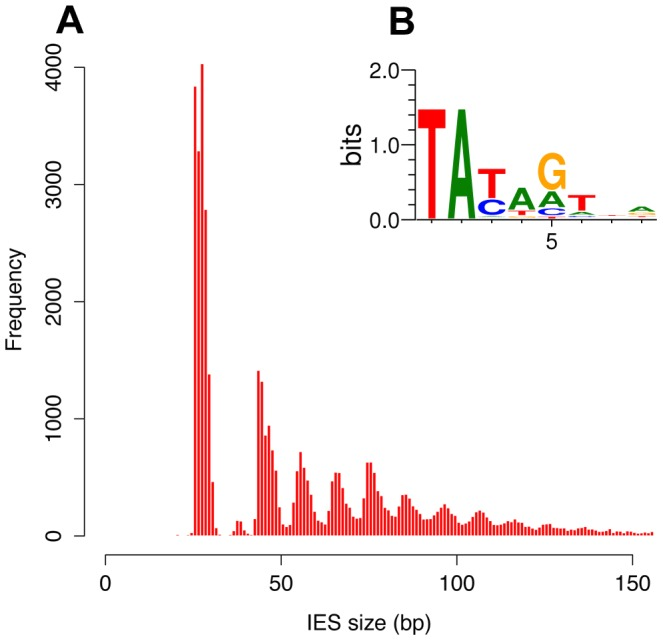
- 100% TA-Bounded
-
Weak consensus TAYAG
- Degenerated TC1-Mariner TE insertion site
- Not sufficient
- Periodic size distribution
30% of IESs only are small-ncRNA dependant (shown by DICER-like2-3 silencing)
- What about the majority remaining ?
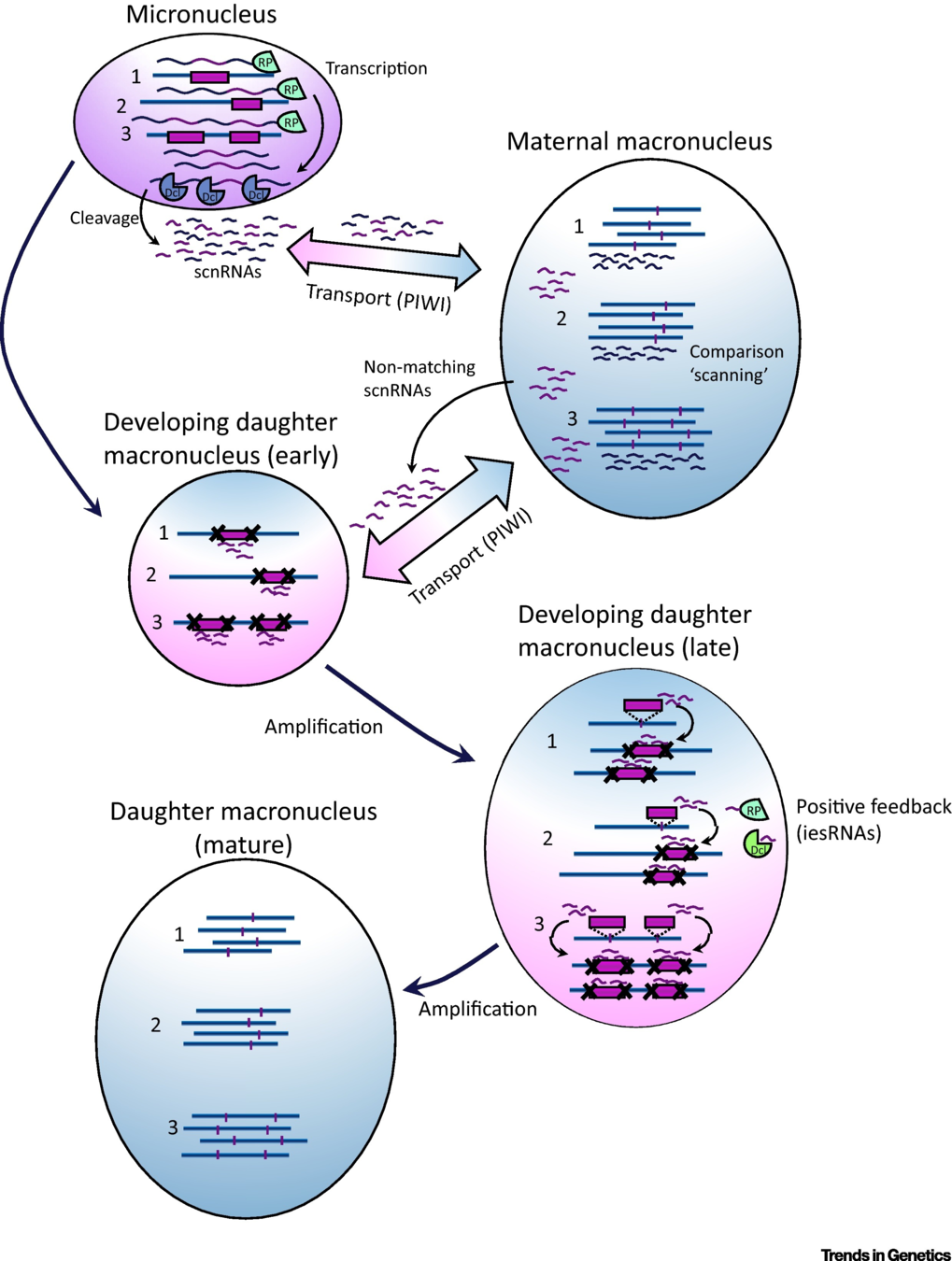
How are IES recognized ? (2/2)
The sc-RNA pathway
The DNA methylation hypothesis
6mA likely to be abundant in Paramecium:
-
Suspected 2.5% in the MAC of P. aurelia by Cummings et Al (1975)
-
Also documented 6mA in the MIC
-
-
-
Detected methylation by SMRT in the MAC in our lab (unpublished data)
-
Detection by SMRT in the MAC by Sandra Duharcourt's lab (unpublished)
- Detection in Oxytrichia by L. Landweber et Al (2019)
- no 5mC, 4mC in the MAC a priori
2) Crosstalks in the new forming MAC
1) Constant pattern in the MIC
Transcient ?
Methylase candidates
Candidates:
- NM4, NM9, NM10
- Another family: MT1a, MT1b, MT2
2) PacBio sequencing with short inserts | 6mA ++
1) Grouped silencings by sequence homology
PacBio
TL;DR overview
PacBio SMRT principle
Reads up to 80 kbp
1) Sequencing (unique molecule)
2) High fidelity consensus
3) DNA methylation analysis
PacBio SMRT principle (2)
- Strategy 1: Long inserts (long reads)
- Ideal for assembly of long repeated sequences
-
Poor resolution for DNA methylation analysis
-
Strategy 2 : Short inserts (long reads)
- Much higher resolution for DNA methylation analysis
Step 1: Consensus
99% accuracy
Max
75% accuracy
Because our inserts are circular and shorts, we can make CCS of high accuracy despite a 15% error-rate
Step 2: Sorting

Deduced origin
MIC DNA
Alignment of consensus
TA
TA
TA
Step 3 : DNA methylation analysis
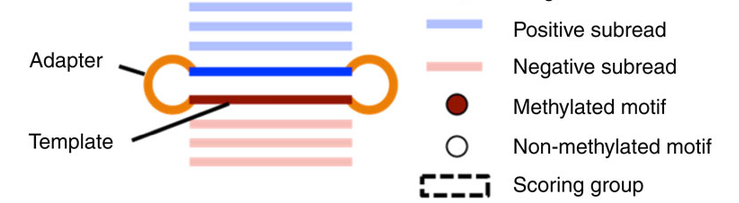
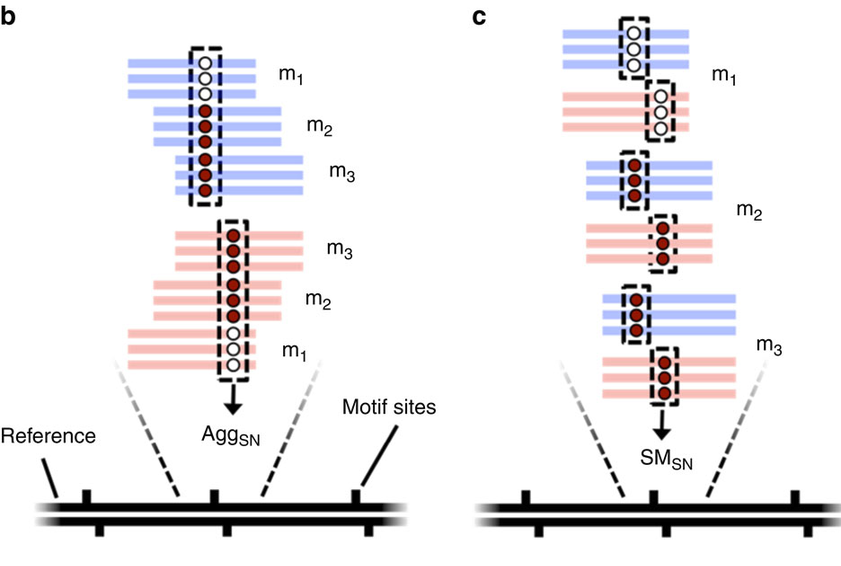
- Single-molecule
- Single-nucleotide resolution
- Independant yet pairable analysis on both strands
Some more details:
the random sampling approach
Deduced origin
MIC DNA
Alignment of consensus
Only a few remaining: ~ 10 to ~200 sequences
100% should carry a methylation pattern
-
1 out of 200 comes from the MIC
-
1/6 of MIC inserts will carry an IES
-
For 50% of IESs, we cannot be sure whether it come from the MIC or from the MAC
- 30% of the remnants are scanRNA dependant
Final categories
- MDS
- = "MAC" for 99% of sequences
- MAC_IES
- "true" MAC_IES (never seen retained)
- other MAC_IES (sometimes retained)
- MIC
- Other MIC specific (TE, repeated sequences)
- MAC (TA Junction)
- Overlap a TA junction of excision
- rDNA
- mtDNA
-
Other:
- Contaminants
- Alternative excision boundaries ("LOWID")
- low identity consensus ("Trash")
"genome"
Total Paramecium
Total sequencing
Little bug to be corrected
30%
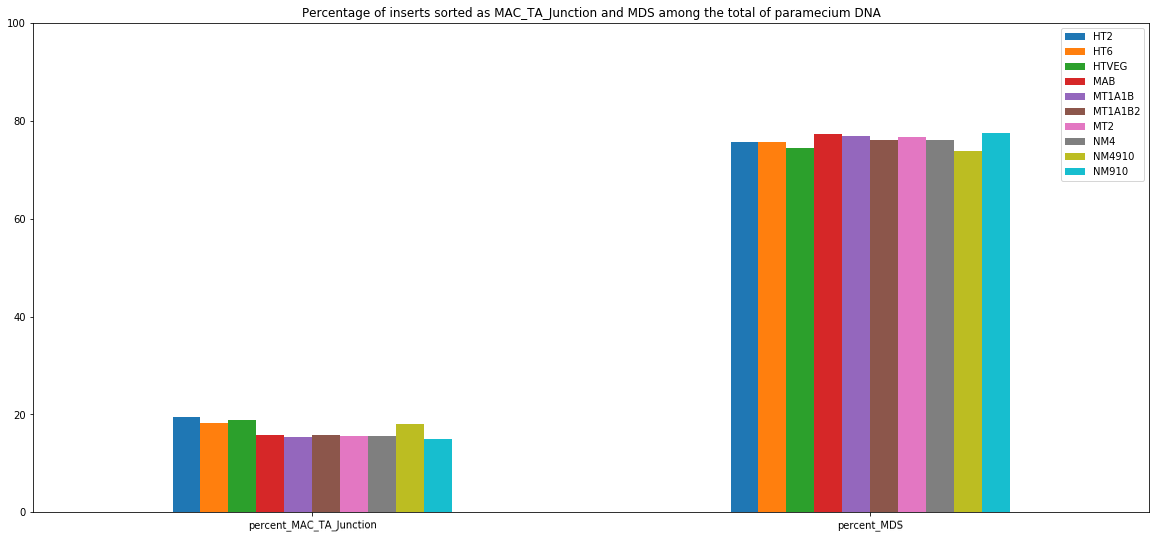
MDS and MAC_TA_Junction represent a vast majority
MIC specific and IES are as rare as expected
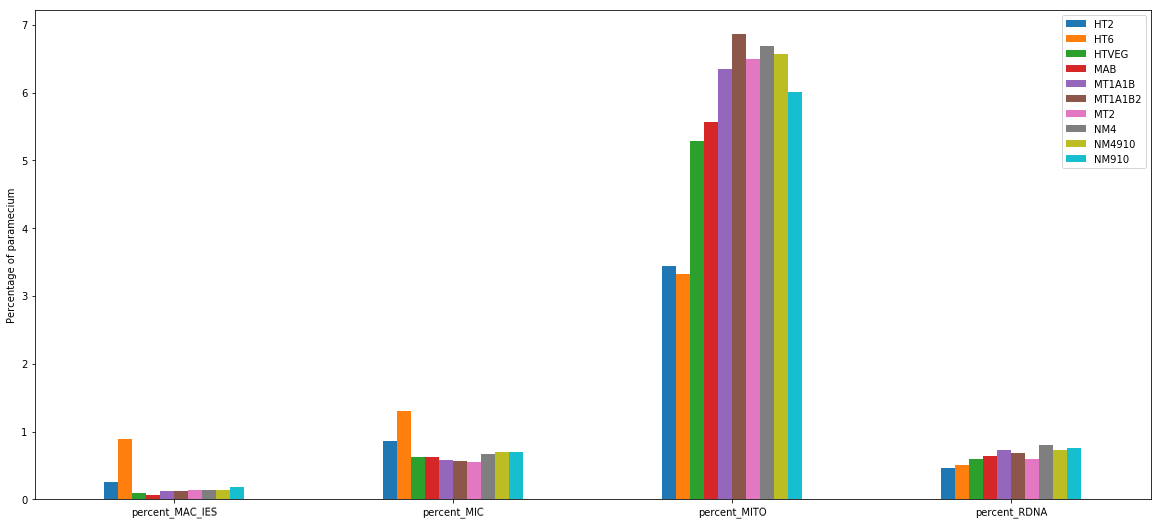
+ Applying the retention filter divides the number of "MAC_IES" approximately by 50%
Detecting m6A in details
Detecting m6A optimally
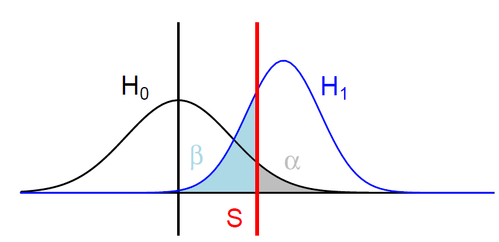
H0: ipdRatio of umethylated-Adenines
H1: ipdRatio of 6mA
S: Threshold on the pvalue
--> Specificity
--> Sensitivity
$$\alpha$$
$$1 - \beta $$
Adenine
6mA
ln(ipdRatio) ~ N(0,1)
log(ipdRatio)
A pvalue is just the probability that log(ipdRatio) in the tail of H0
Using E.coli as ground truth
E.coli:
- Feeds paramecium: contaminants+++
- Nearly 100% symetrically-methylated with m6A
- GATC
- EcoK
- Few others
- Depends a lot of the strain
- Outside of GATC and EcoK: very low levels of m6A
I investigated the PacBio's output on it's GATC & EcoK VS other sites
How log(ipdRatios) look in E.coli
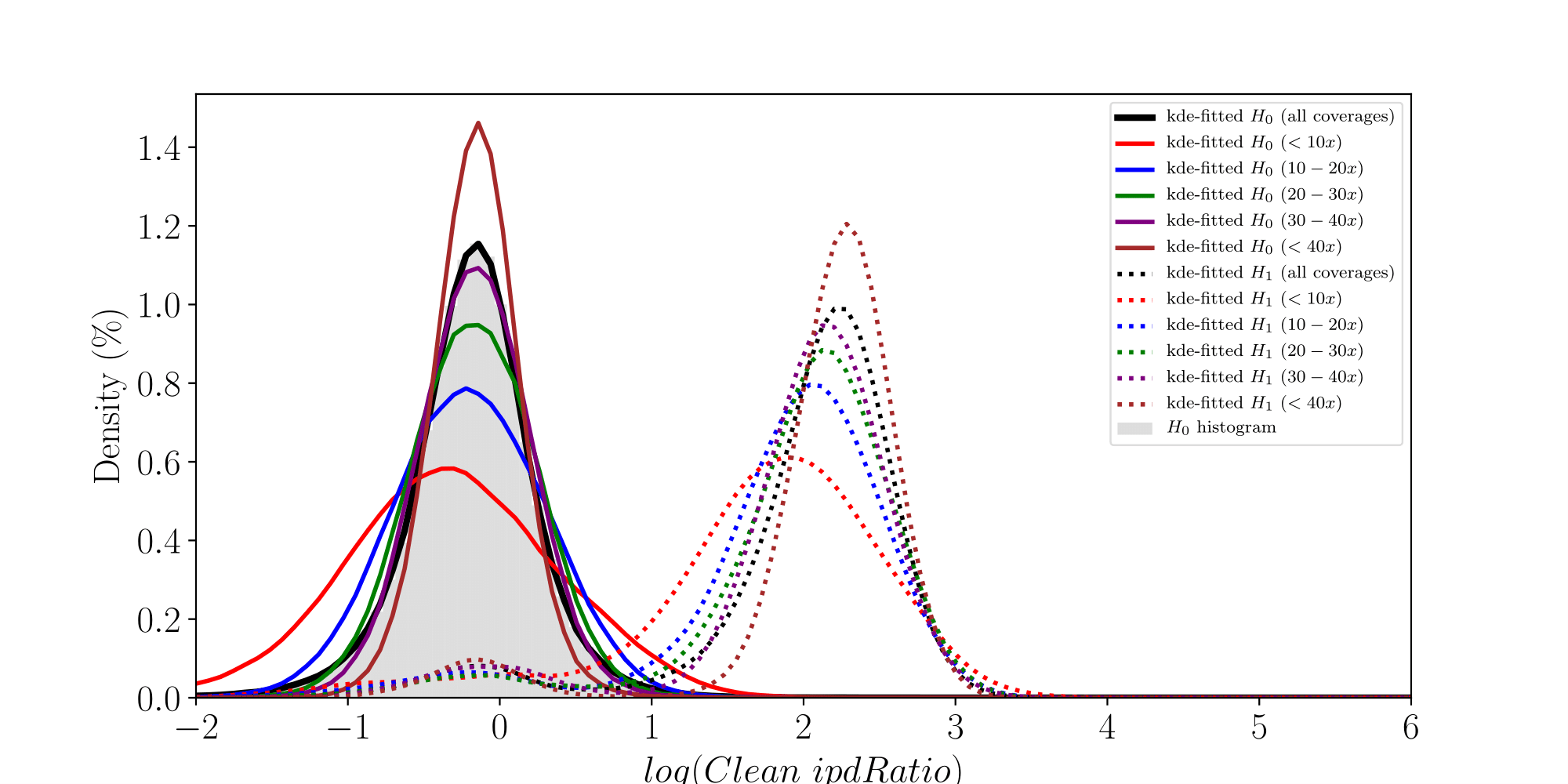
Separability raises with coverage, which is expected
PacBio pvalues do have some biological meaning
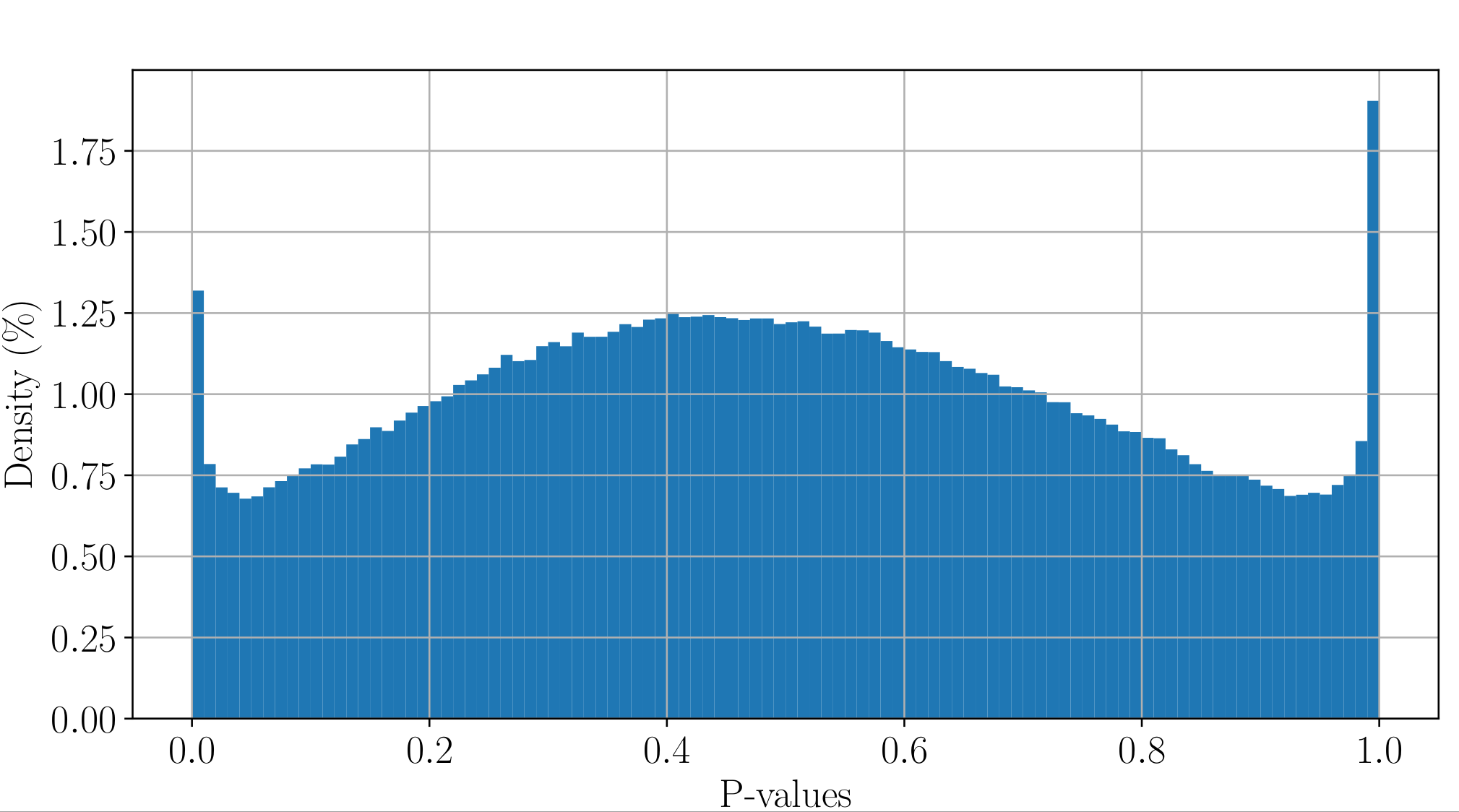
PacBio pvalues do have a meaning...
...but are not ideally distributed
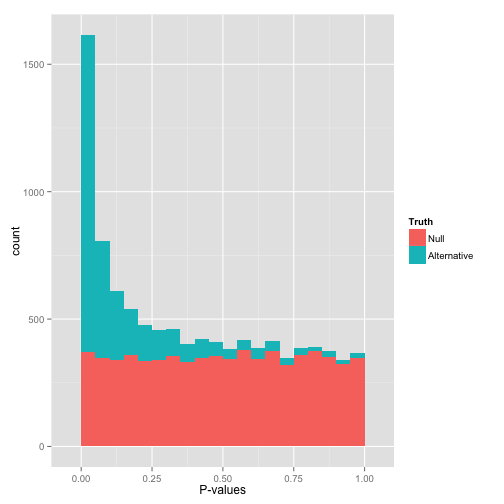
Ideal pvalues
--> Allows magic !
PacBio's
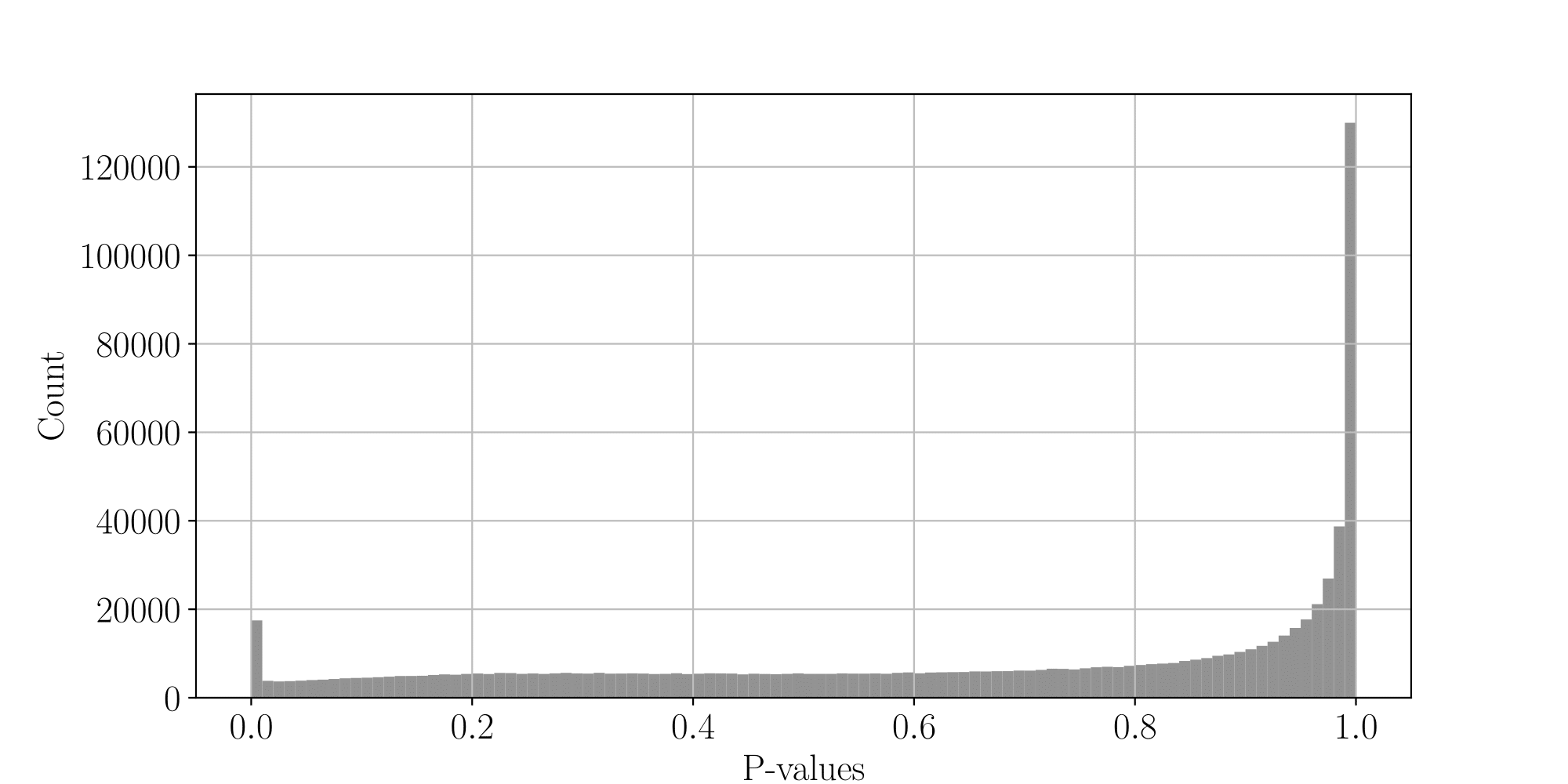
- Allow estimation of
- Allows optimal, adaptative FDR control
$$\pi_{0}, \pi_{1}$$
- Just don't
-
Obvious point n°1:
- log(ipdRatio < 1) -> -inf
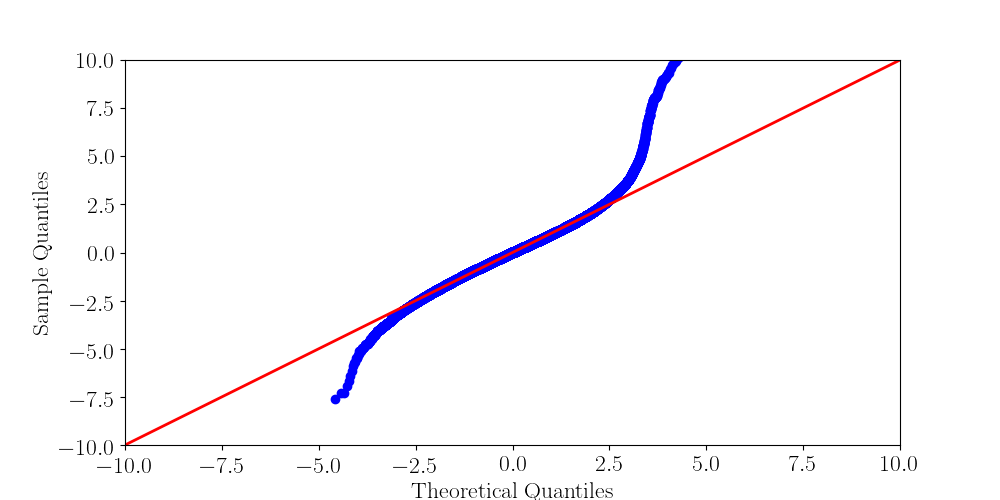
Normality assumptions under H0 are broken under high coverages
- The higher the coverage, the worse (here, >40x)
-
Will cause bell-shaped pvalues under null
- Hidden phenomena on the previous curve
Normality assumption matters
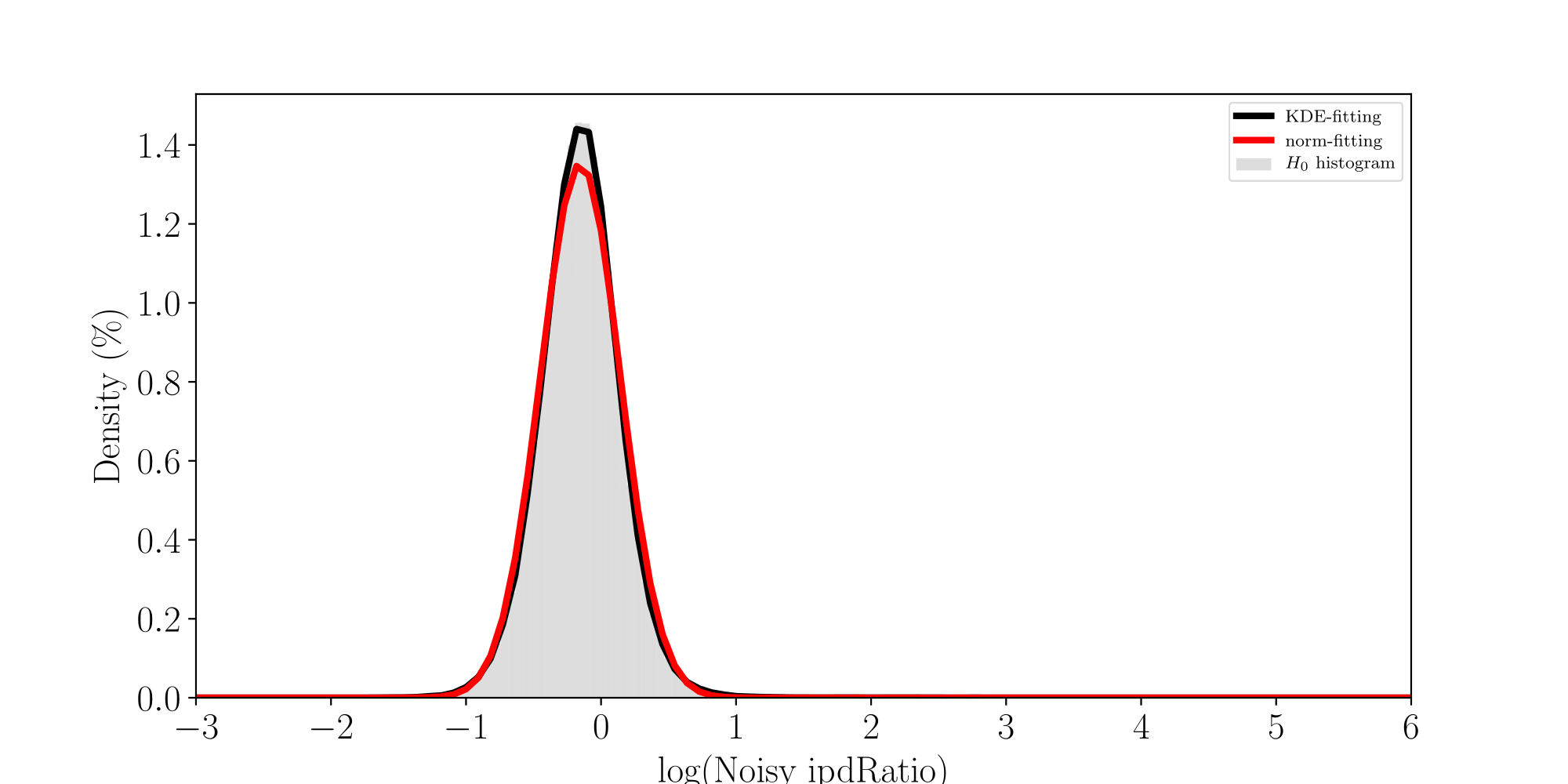
All Adenines' pvalues [E.coli] coverage > 40X
Long story short
PacBio's pvalues:
- Are biologically relevant
- We can build a reliable ad-hoc system with them
- Are produced by a linear combinations of > 150 different coverages
- Which forbids the usual statistical treatments
- Are somehow broken on a coverage-dependant manner
- Which forbids a simple fix for point 2
- We can't use the classical statistical treatments directly on pvalues
Other PBio's scores for m6A
For n6mA, PacBio produces:
-
A modification score --> Slowing of the polymerase
- pvalue against H0 only (the one we presented earlier)
-
An identification score --> Kinetic signature of a modification
-
loglikelihood between H0 and H1 (H1 = Other modifications or secondary peaks)
-
loglikelihood between H0 and H1 (H1 = Other modifications or secondary peaks)
They are PHRED-transformed p-values of two different statistical tests, that rely on the mean of the IPDs
PHRED scores
The scores (Qv) are PHRED-transformed p-values
Typical covscore plot
Modification score / coverage
Using flat threshold on modification score = Hudge lack of power
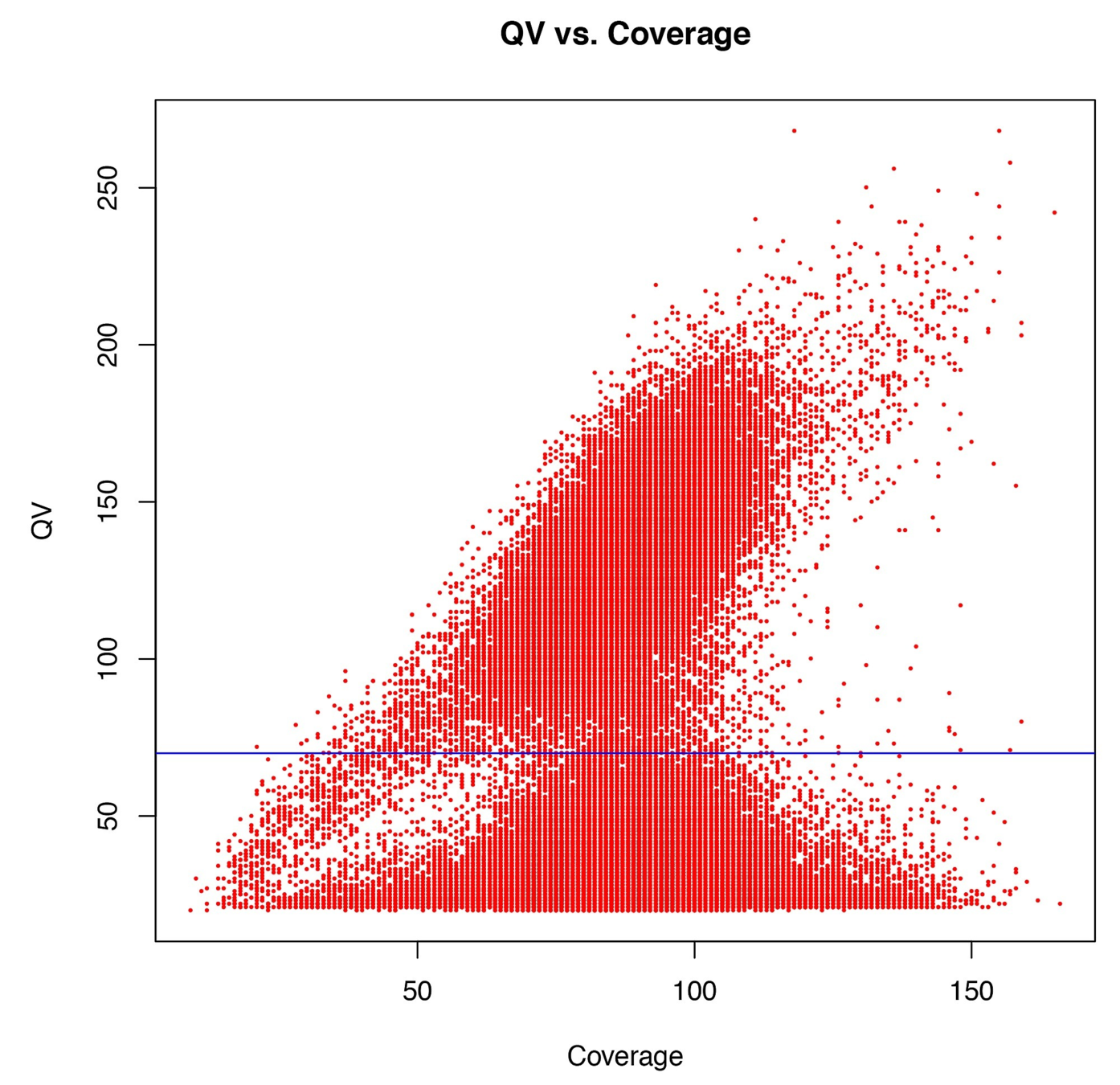
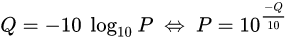
Solution : A coverage-dependant threshold on the scores
From now on
"positive detection"
=
score > linear thershold
(only >25X considered)
Benchmarking
How good (or bad) is our method ?
$$Se = P(D^+|M) ~ 92\%$$
$$Sp = P(D^-|NM) ~ 99.8\%$$
Starting from sufficient coverages (~20X to ~30X), Se and Sp don't depend on the coverage anymore
The 4 scenarii for Se and Sp
- We don't care about Se and Sp
- We care about the fact that eventual mis-estimations of them doesn't really change anything
Finding unbiased estimators for and FDR
If p number of positive detections among N tests:
p = FP + TP
$$\pi$$
So,
Which means
And:
What it gives in Paramecium
Debiased levels of m6A in the MAC_TA inserts
Details in MAC HTVEG
-
~95% of the methylation locates in AT dinucleotides in the MAC
-
True in any condition
-
-
75% of the methylation in an AT dinucleotide is actually symetrically modified, independantly from being in the MAC or the MIC
Kept in MIC and MAC
All conditions
MAC_TA outside of AT sites
Detections outside AT sites are likely to be at least partly true positives
Present in all samples
Never erased
Conclusion: We are either in scenario 1 or 3
(Sp largely underestimated)
Was expected but confirmed
Methodological development to correct hemi-methylation detection (1/2)
Let FD1 and FD2 be resp:
- Fraction of AT sites detected hemi-methylated
-
Fraction of AT sites detected symmetrically methylated
PZ0, PZ1, PZ2: unbiased estimators of non, hémi, symetrically methylated AT sites
Then:
With
What it gives in Paramecium
Debiased Hemi-methylation in MAC_TA
n6mA in the MIC (preliminary)
Pure MIC sequences: Cannot yet be trusted (error in the pipeline)
Coverage >= 40X made us lose too many materials, should restart with >=20X
n6mA in the MAC_IES rarely retained ("TRUE MAC IES")

HTVEG

MT2
--> Some molecules carry all the detections, in sym-A*T
Very likely to be sequences comming from the MAC to my opinion
At first look, seems like the same in all samples
Conclusion
- Lots of sweat spent on methods : Now we start the cool things
-
In the MAC
- Quantification in the MAC is well-characterized in all the samples
- Our 6 genes are implied in the bulk of the MAC m6A
- MT and NM families: Functional analogs of DNMT1 ?
- Lots of questions raised by the MAC methylation: TSS, IES Junctions, nucleosome positionning...
-
In the MAC IES
- Very preliminary analysis between TRUE mac IES and other MAC IES tends to show that all detections could come from accidental retention in the MAC, and the MIC could actually carry 0% m6A or very lower levels than 1%. Really to premature to be sure
- HT2 and HT6 are still potentially full of surprises
- TE in the MIC: No idea yet
- It's just a question of time now ! Which we asked (prolongation LABEX memolife)
Sorry for the headaches !! Thanks for your time :)
Ciliates are great model organisms

1862 - Pasteur: Refutation of the spontaneous generation theory with infusoria


1937 - Sonneborn: Non-mendelian inheritance of sexual type in paramecium


Elizabeth blackburn & Carol Greider: 1985 - Telomeres and telomerases in Tetrahymena (Nobel Prize 2009)

Eric Meyer, Sandra Duharcourt
(IBENS, I. Jacques Monod 2014)
Sexual type in paramecium are transmitted by maternal RNAs, not by DNA
2.1 Retroingineering
The capping of IPDs
-
modelPrediction is the predicted IPD value by the model in a given context of nucleotides at this position
-
globalIPD is the mean of all the IPD values of the read.
-
localIPD represents all IPDs that have been mapped at a given position in the genome, including those from other sequences
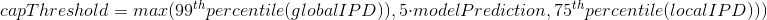
Conclusion on the capping
- Isn't coded as advertized by PacBio
- The way it's implemented for AggSN is problematic and doesn't really make sense
- Paradoxally, it should be more relevant for our approach than for the default one
- We expect no methylation to be undetected due to the capping
Laura landwebehr 2020
Oxytrichia trifallax
p values (A)
p-values (A score >20)
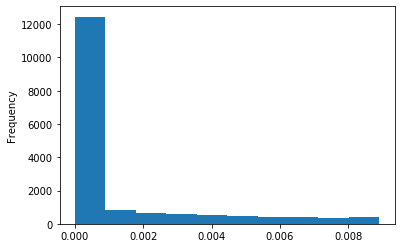
Out GATC score < 20
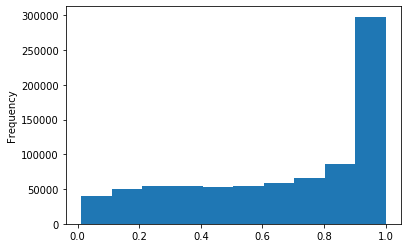
Out GATC
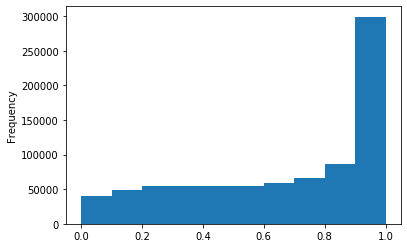
ipdRatio score 20
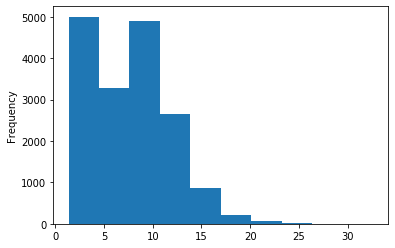
ipdRatio idv20/score20
A outAT score 20 isQv20 (812 seq)
A outAT score20 idQv20 + Strong BH correction (176 seq)
ipdRatio out GATC before filtering BH vs after (qv20/idqv20)
In GATC

Statistics in action
By biocompibens
Statistics in action
28/02/19



