

Brad Langhorst
New England Biolabs
Gautam Naishadham and Brad Langhorst - New England Biolabs
UMI added here
technical factors related to observed abundance
UMIs duplicated here
technical factors related to observed abundance
BRCA1
p53
Original
Library
+ UMI
Fragments
2
1
3
4
5
6
7
9
1
2
3
4
5
PCR
1
1
1
2
2
3
4
4
4
4
4
4
5
6
7
8
9
5
6
7
8
9
1
2
3
4
5
1
2
3
4
5
2
3
4
5
4
4
4
5
9
9
8
8
25/18 = 1.8
9/5 = 1.4
BRCA1/p53 ratio
4/3 = 1.3
Dedup
1
1
1
2
2
8
9
8
9
9
9
8
Using UMI
No UMI
BRCA1
Alignment
1
2
9
= 12
= 3
1
1
1
2
2
8
9
8
9
9
9
8
1
2
8
9
= 4
= 12
BRCA1
BRCA1
BRCA1
C. Devoe, K. Krishnan, D. Rodriguez
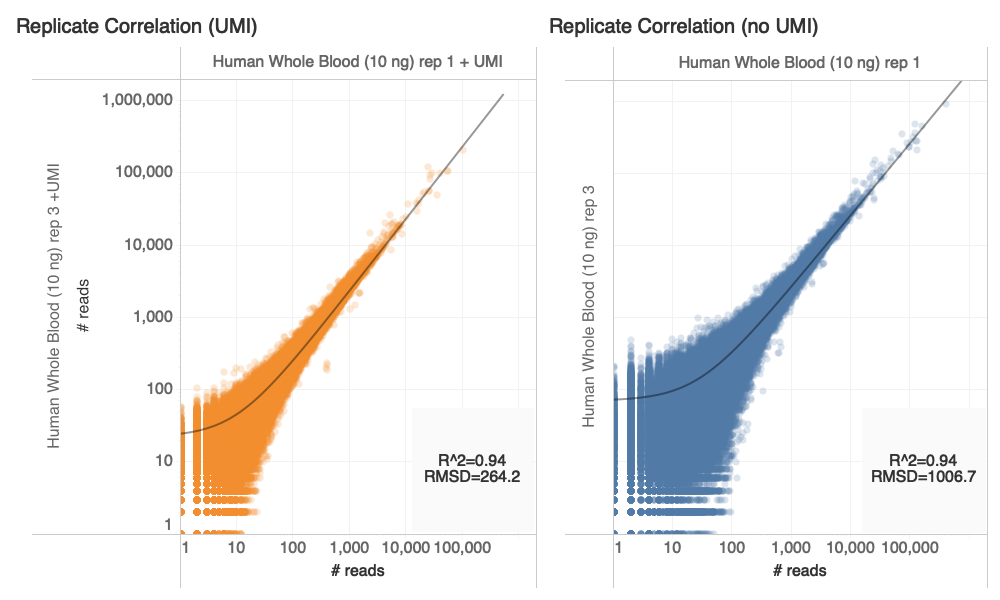
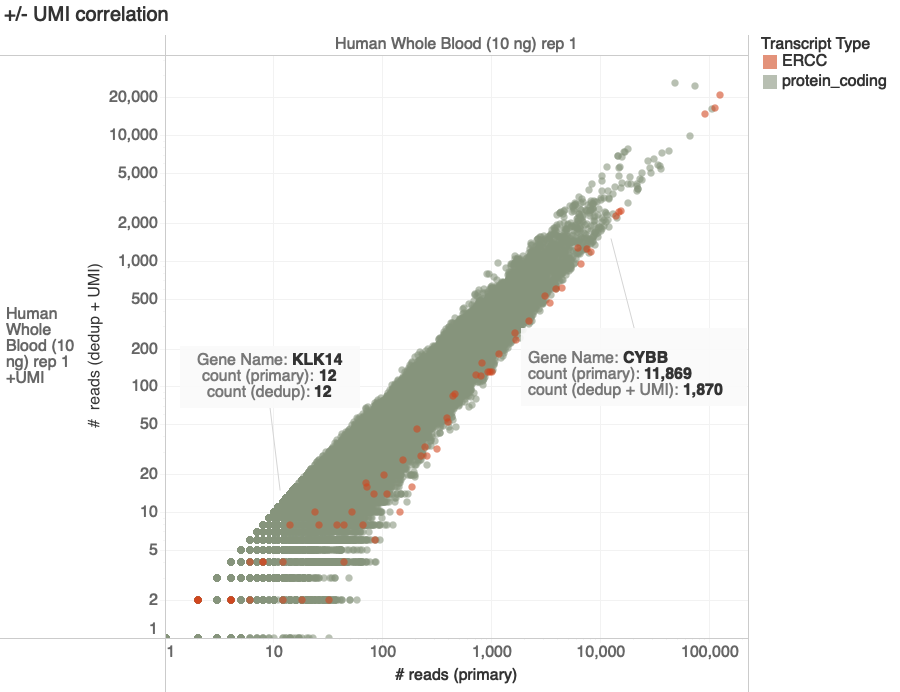
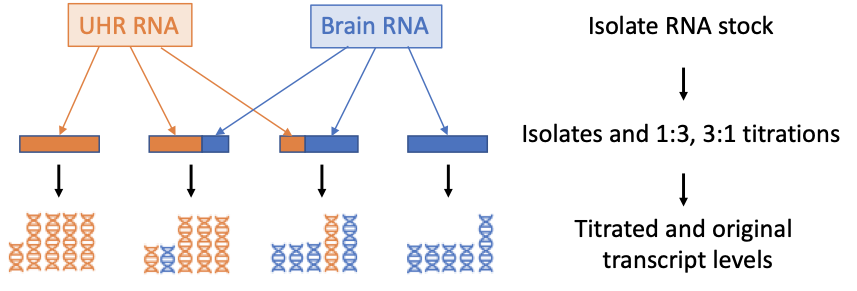
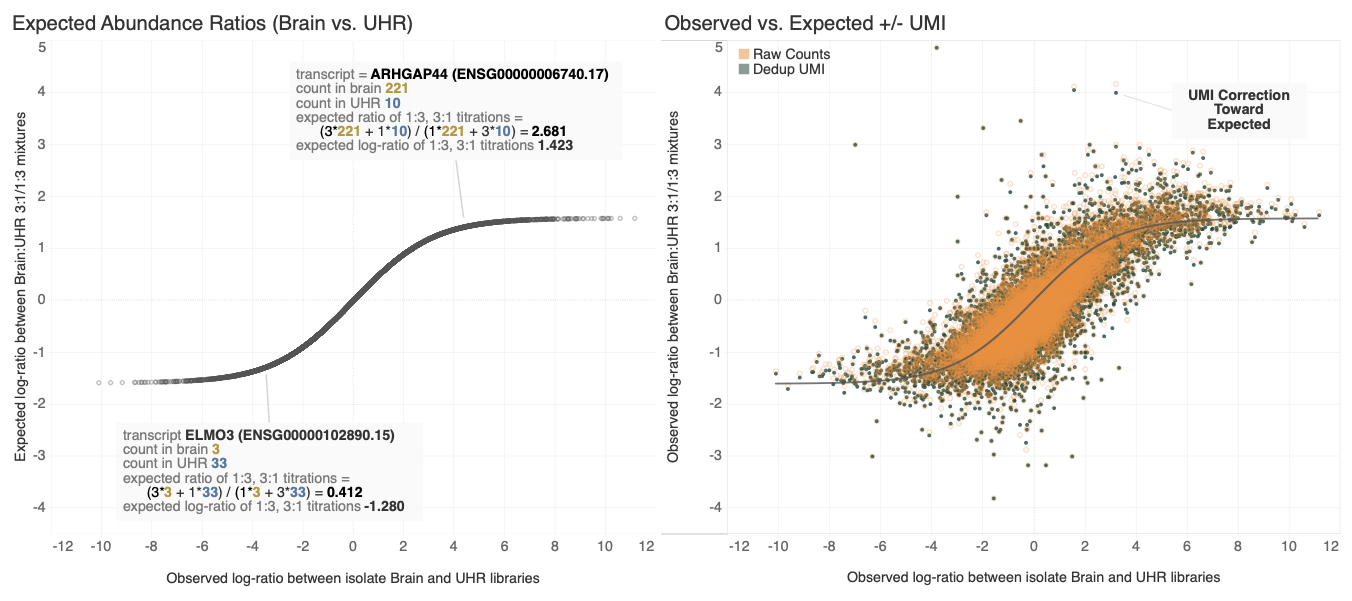
Goal: Compare counts of transcripts with and without UMI
C. Devoe, K. Krishnan, D. Rodriguez
C. Devoe, K. Krishnan, D. Rodriguez
Hard to Amplify
Easy to Amplify
C. Devoe, K. Krishnan, D. Rodriguez
G. Naishadham
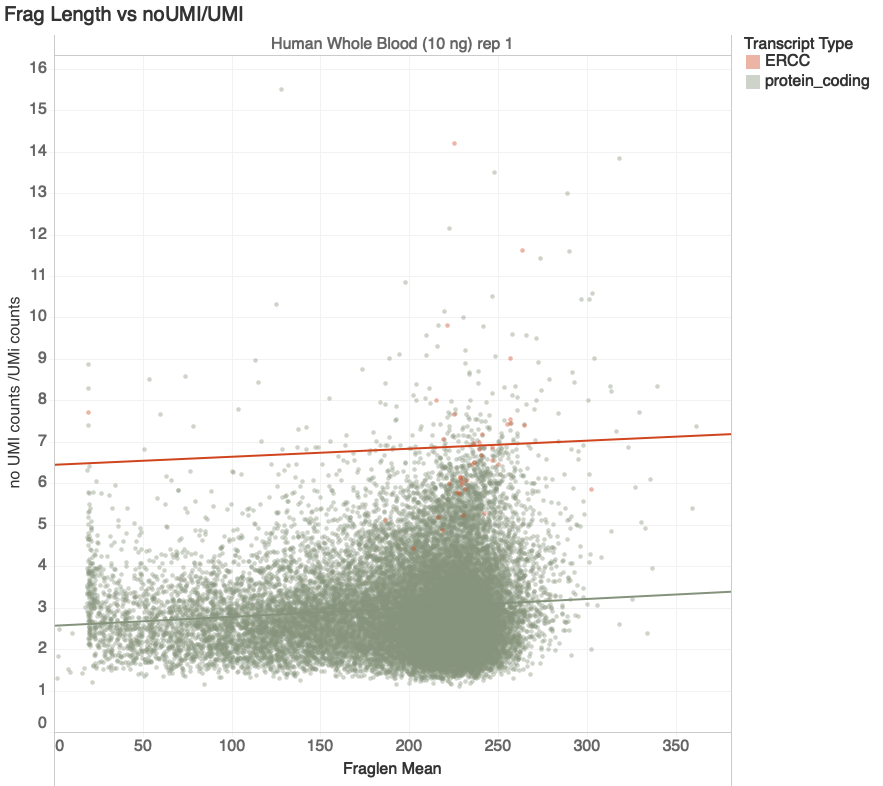
Goal: Compare counts of transcripts to expectation
G. Naishadham
G. Naishadham
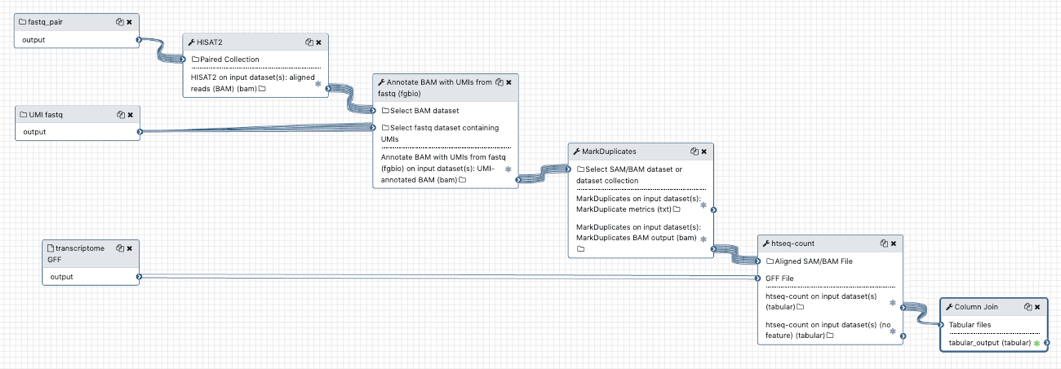
Challenges: 3 reads R1, R2 + UMI
memory = f(umilen)*num reads
G. Naishadham
G. Naishadham
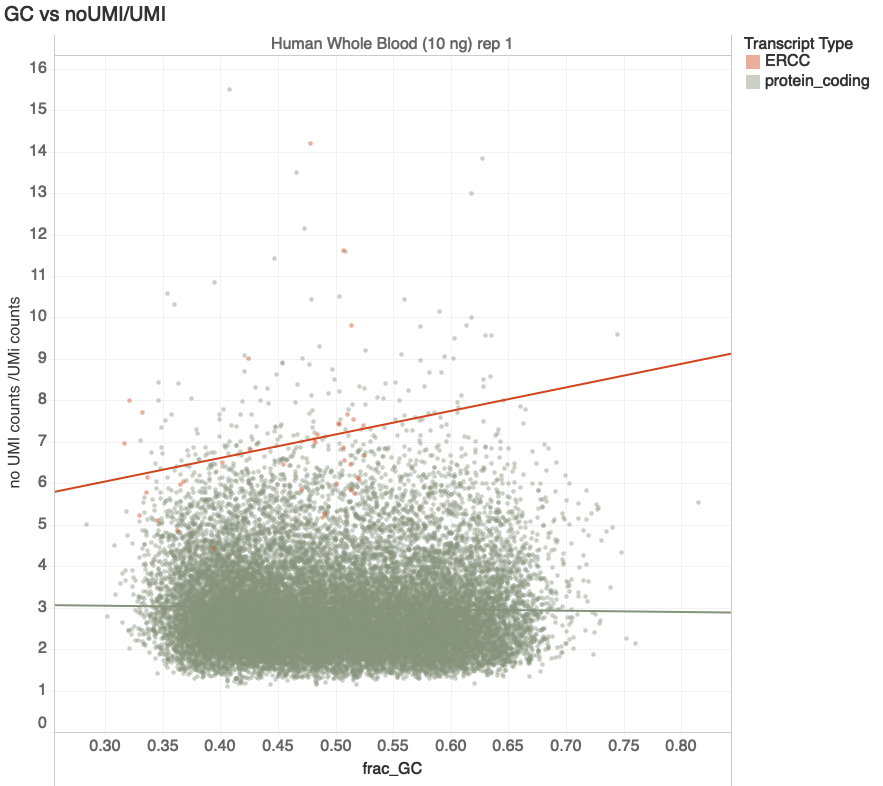
Increasing Duplication
transcripts with > 100 reads
Increasing Duplication
G. Naishadham
transcripts with > 100 reads
Increasing Duplication
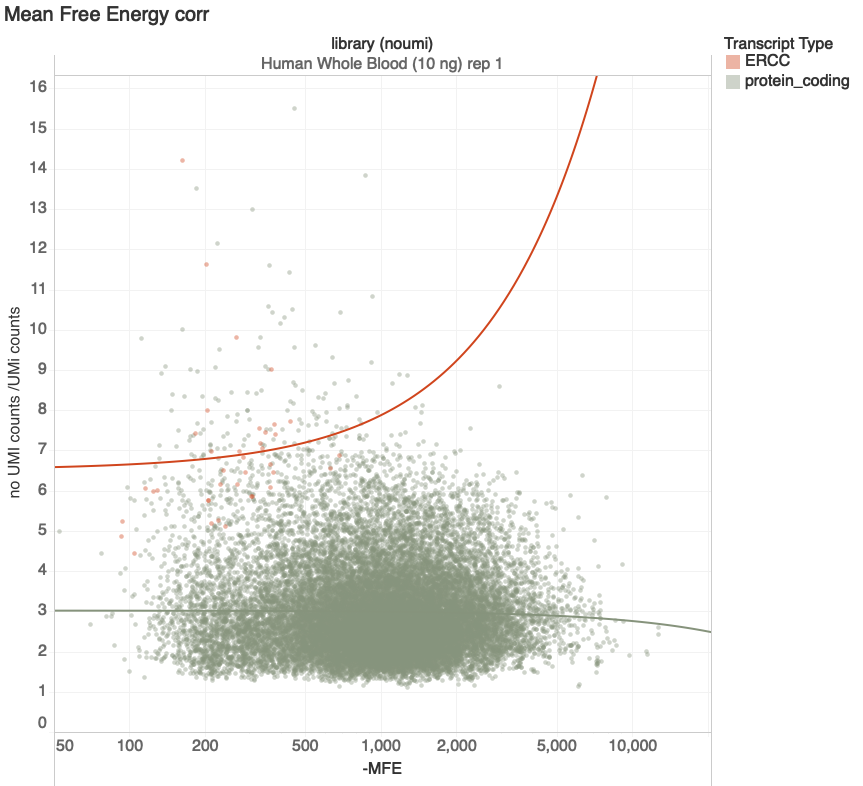
Increasing Predicted Stability
transcripts with > 100 reads
G. Naishadham
By Brad Langhorst




