




Kevin Song
I'm a student at UT (that's the one in Austin) who studies things.
In-Class Activity
File header points to each data block directly (that's it!)
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
IB
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
IB
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
IB
CPU
How many disk reads to access the first block?
(We always start with the block# of the file header)
IB
CPU
How many disk reads to access the third block?
(We always start with the block# of the file header)
CPU
How many disk reads to access the third block?
(We always start with the block# of the file header)
CPU
How many disk reads to access the third block?
(We always start with the block# of the file header)
IB
CPU
How many disk reads to access the third block?
(We always start with the block# of the file header)
IB
How fast is sequential access? How about random access?
How bad is fragmentation?
What if we want to grow the file?
Does this support small files? How about large files?
First, calculate how many pointers can be stored in a block if you have 4-byte pointers and 4KB blocks. Call this number N. Also answer what kind of data a disk-pointer is. A floating point? A string?
Next, choose an allocation scheme for each of the following block ranges:
Finally, analyze your new filesystem! Answer some of the following questions:
[1] Remember that we can corrupt any file layout by breaking its header block. We want to ask about whether we can corrupt the file by breaking any non-header block.
Next, choose an allocation scheme for each of the following file sizes:
Note: the folks at Berkeley write a mean UNIX system, but their idea of mad libs is apparently pretty boring.
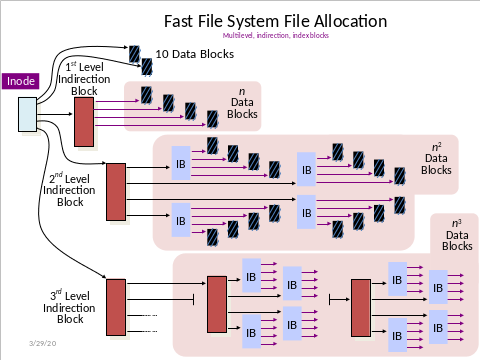
This filesystem was invented at UC Berkeley in the early 80s for the Berkeley Software Distribution.
It was usable on MacOS (formerly OSX) as late as 2012 (!!)
Survives in modern FreeBSD as UFS2, its design inspired many other filesystems including the ext family used by Linux
| Pointer Type | # Ref Blocks | Total Size At Level |
|---|---|---|
| Direct | 10 * 1 = 10 | 40 KB |
| Single Indirect | 1 * 512 = 512 | 2 MB |
| Double Indirect | 512 * 512 = 2^18 | 1 GB |
| Triple Indirect | 512*512*512 = 2^24 | 512 GB |
| Total | ~513 GB |
FFS: assuming 4KB blocks, 8-byte pointers = 512 pointers/block
General workflow:
Expensive
Hint: Programmers are lazy...
By Kevin Song



